Hermes Agent:真正的升级,是让经验变成可复用 Skill

[插图:Hermes Agent 自我进化的技能系统]
开头
AI Agent 最尴尬的地方,不是不会做事。
而是今天踩过的坑,明天可能还会再踩一次。
你让它部署一个项目,它查资料、试命令、修错误,最后终于跑通。
但下一次遇到类似任务,它可能又从头摸索。
这就像一个工程师每天都在加班复盘,但第二天醒来,笔记本被清空了。
真正有价值的 Agent,不应该只是“这次做对”,而应该是“下次更快做对”。
👉 Hermes Agent 值得关注的地方就在这里:
它不是单纯给 Agent 加更多工具,而是让 Agent 把经验沉淀成 Skill。
也就是:
把一次任务中的成功路径、踩坑经验、验证方式,变成下一次可复用的程序化能力。
本质是什么
先说结论:Hermes 的本质,不是一个工具调用框架,而是一套 Agent 经验沉淀系统。
很多 Agent 框架解决的是“现在能不能调用工具”。
Hermes 进一步追问的是:
这次调用工具形成的经验,能不能留下来?
人话说,Hermes 想让 Agent 像工程师一样工作。
不是每次都靠临场发挥,而是把稳定做法写成 SOP,把容易出错的地方写成注意事项,把验证步骤写成检查清单。
这就是 Skill。
一句话定义:Skill 是 Agent 的程序化记忆。
Memory 记住的是事实。
Skill 记住的是做法。
这两个东西一分开,Agent 才开始从“会聊天”走向“会成长”。

[插图:记忆与技能的分工]
它解决什么问题
先说结论:Hermes 解决的不是“Agent 有没有记忆”,而是“Agent 的经验能不能复用”。
① 重复任务不再从零开始。
部署、构建、调试、数据处理、环境配置,这类任务往往不是难在一个命令,而是难在一串步骤。
Skill 把这串步骤保存下来,下一次直接复用。
② 踩坑经验不再只停留在一次对话里。
比如某个工具在特定平台下会报错,某个命令需要先设置环境变量,某个部署流程必须最后验证接口。
这些都不适合只放在临时上下文里。
③ Agent 不再只靠长 Prompt 硬撑。
如果所有经验都塞进 System Prompt,token 会膨胀,加载会变慢,还会干扰判断。
Hermes 的做法是:先放索引,命中后再加载完整 Skill。
④ 自我进化有了工程边界。
Agent 可以创建 Skill,也可以修补 Skill。
但它不能无约束地乱学。
所以安全扫描、来源分级、路径隔离就变得非常关键。
这一段你可以记住:Agent 的长期价值,不是多回答一次,而是少重复犯错一次。
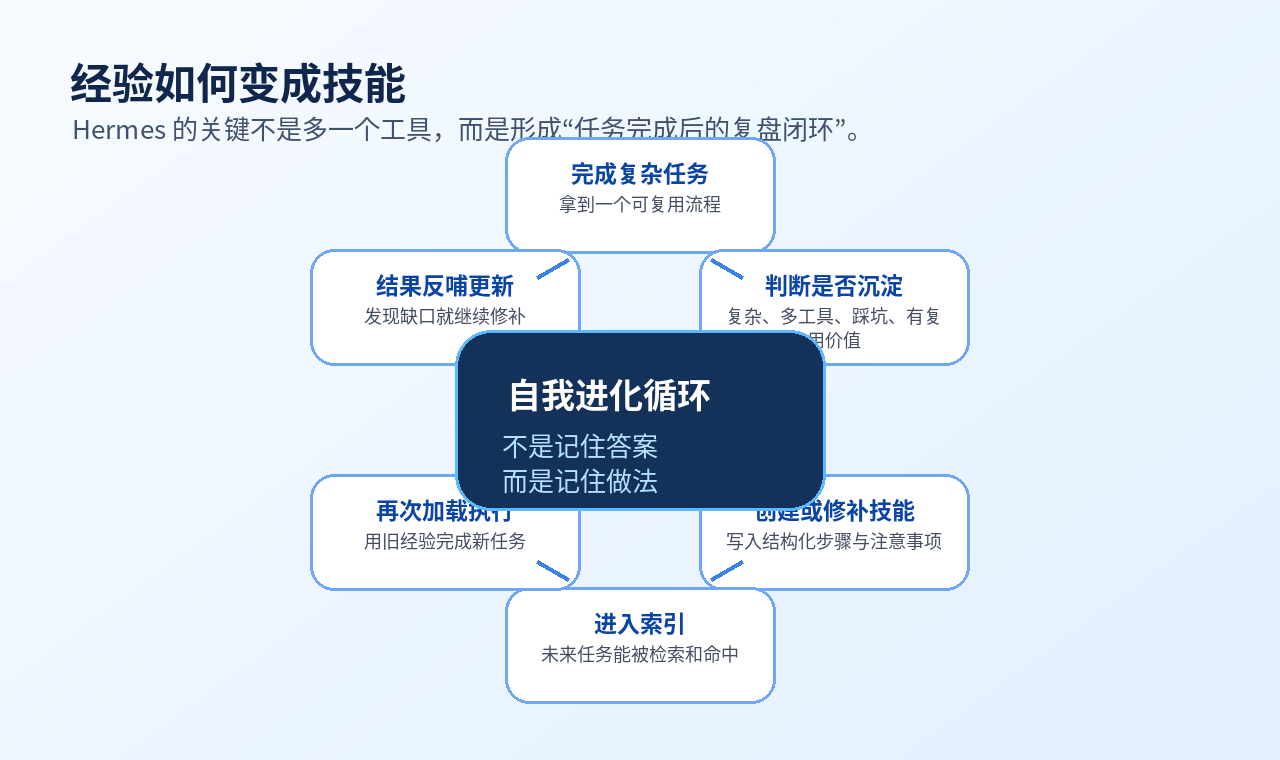
[插图:经验如何变成技能]
核心内容拆解
一、Skill 创建:不是人工写文档,而是任务后自动沉淀
先说结论:Hermes 最关键的动作,是让 Agent 在任务完成后主动判断:这段经验值不值得保存。
不是每一次对话都要生成 Skill。
真正值得沉淀的,通常是这几类场景:
① 执行了复杂任务。
② 调用了多个工具。
③ 解决了棘手错误。
④ 发现了非显而易见的流程。
⑤ 未来可能再次遇到。
这很像工程团队里的复盘机制。
普通问题当场解决即可。
复杂问题要写成文档。
高频问题要变成 SOP。
Hermes 只是把这个动作交给了 Agent 自己。
并且它不是随便写一个文本文件,而是把 Skill 做成结构化格式:名称、描述、平台、工具依赖、触发条件、步骤、验证方式、注意事项。
说白了:Skill 不是聊天记录,而是可复用的操作说明书。
二、Skill 存储:原子写入的价值,是避免“学坏半截”
先说结论:Agent 自己写 Skill,最怕的不是不会写,而是写到一半出错。
如果一个 Skill 文件写了一半,系统突然失败,下一次 Agent 加载到残缺内容,就可能执行错误步骤。
这就是工程系统里典型的“半成品污染”。
Hermes 的思路是原子写入。
先写临时文件,再替换正式文件。
写入后还要重新扫描和校验。
如果扫描失败,就回滚。
这个设计很工程化。
因为 Agent 的自我进化不能只看“能不能写”,还要看“写坏了怎么办”。
一个能自我修改的系统,必须先有自我保护能力。
三、Skill 索引:不是把所有经验都塞进 Prompt
先说结论:Hermes 的可扩展性,来自“索引先行,按需加载”。
如果一个用户有几十个、上百个 Skill,每次对话都全量注入上下文,系统很快就会变得又慢又贵。
更严重的是,太多不相关 Skill 会干扰模型判断。
Hermes 采用的是渐进式披露:
先把轻量目录放进上下文。
包括 Skill 名称、描述、分类、触发条件。
当 Agent 判断某个 Skill 相关时,再通过专门工具加载完整内容。
这就像 IDE 不会一次性把整个代码仓全部展开,而是先给你目录树。
你需要哪个文件,再打开哪个文件。
真正好的上下文管理,不是让模型看得更多,而是让模型只看该看的。
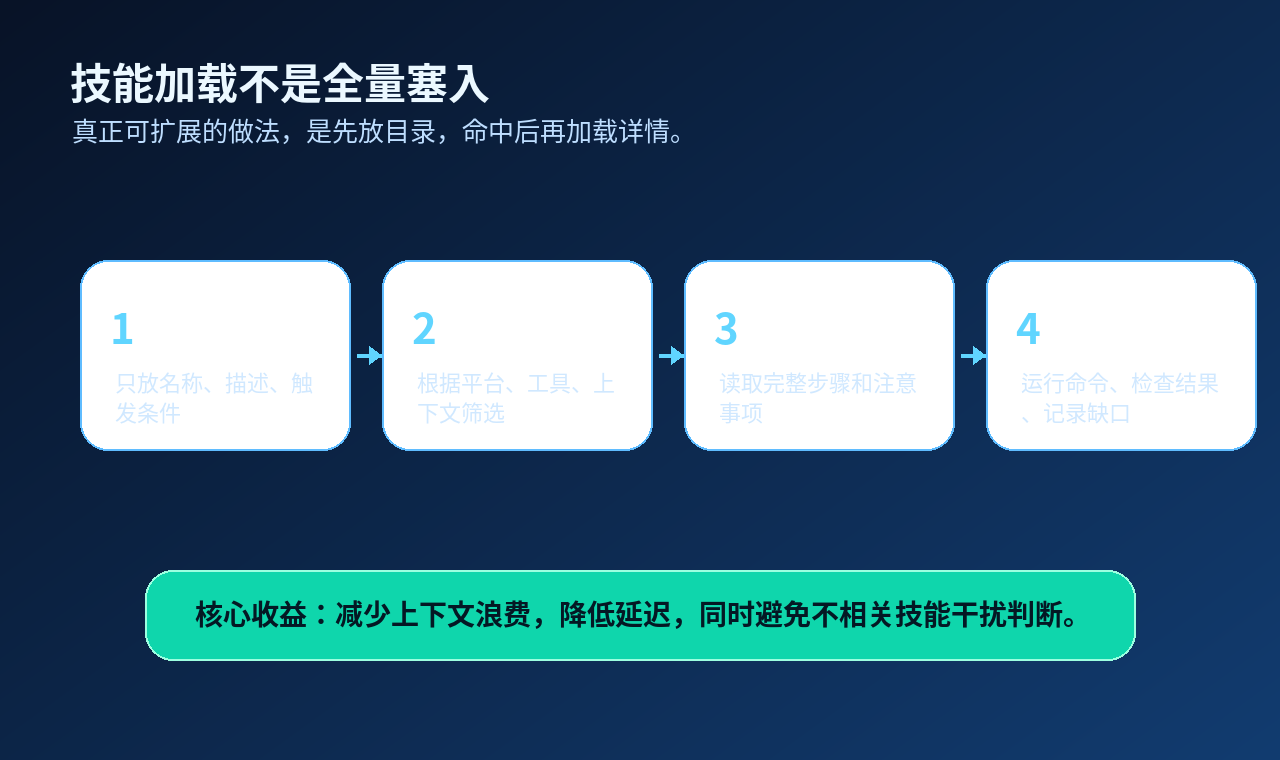
[插图:技能加载不是全量塞入]
四、条件加载:Skill 不是越多越好,而是越准越好
先说结论:Skill 系统的难点,不是存得多,而是用得准。
一个 Docker 相关 Skill,不应该在没有终端工具时加载。
一个 macOS 平台 Skill,不应该在 Linux 服务器上误触发。
一个 Web 搜索替代方案,只有在搜索工具不可用时才应该出现。
所以 Skill 需要有条件。
平台条件、工具条件、兜底条件、环境变量条件,都应该写进结构化元数据里。
这件事非常重要。
因为 Agent 一旦加载了不适用的 Skill,就可能不是“没帮助”,而是“带偏方向”。
Skill 的价值,不在于存在,而在于被正确触发。
五、自我修补:Agent 真正成长,靠的是 Patch 循环
先说结论:Hermes 最像“学习”的地方,不是创建 Skill,而是修补 Skill。
第一次写下来的经验,很可能不完整。
某个步骤漏了。
某个命令在不同平台下不兼容。
某个错误只有实际执行时才暴露。
如果 Agent 使用某个 Skill 时发现问题,Hermes 的思路不是等人来维护,而是让 Agent 在任务结束前主动修补。
这就形成了一个闭环:
当前任务调用旧 Skill。
执行中发现缺口。
结束前 Patch Skill。
下一次加载到新版本。
这比传统文档更接近真实工程迭代。
因为很多 SOP 不是一次写完的,而是在一次次使用中被打磨出来的。
Agent 的进化,不是突然变聪明,而是把每一次踩坑都变成下一次的捷径。
六、安全护栏:Skill 是能力,也是攻击面
先说结论:Skill 一旦能被执行,它就不再是普通笔记,而是潜在攻击面。
这也是 Hermes 最值得警惕的部分。
如果一个 Skill 里被写入恶意命令,Agent 下一次加载后就可能照着执行。
如果 Skill 里藏了提示注入,它可能诱导模型忽略系统规则。
如果 Skill 里包含路径穿越、密钥读取、外部上传,就可能直接造成安全事故。
所以 Skill 系统必须有安全护栏。
包括:
① Prompt Injection 检测。
② 路径穿越拦截。
③ 密钥和环境变量保护。
④ 危险命令识别。
⑤ 来源信任分级。
⑥ 高风险 Skill 人工确认。
这一段你可以记住:可学习的 Agent,必须同时是可约束的 Agent。
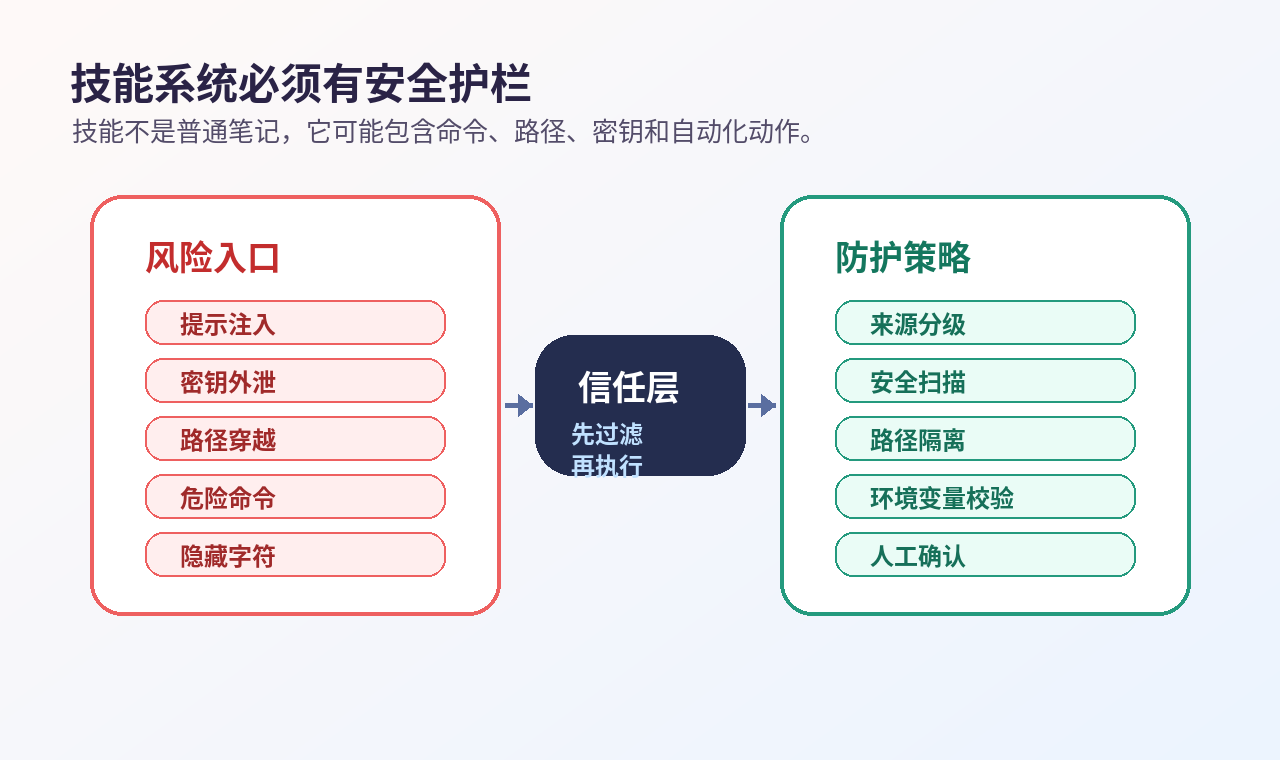
[插图:技能系统必须有安全护栏]
和传统方案区别
先说结论:传统 Agent 更像“工具调用器”,Hermes 更像“经验进化器”。
旧逻辑:
① 用户提出任务。
② Agent 调用工具。
③ 得到结果。
④ 对话结束。
⑤ 经验丢在上下文里。
新逻辑:
① 用户提出任务。
② Agent 调用工具。
③ 得到结果。
④ 判断是否沉淀 Skill。
⑤ 下次任务复用 Skill。
⑥ 使用中继续修补 Skill。
这就是区别。
旧逻辑把任务当成一次性执行。
新逻辑把任务当成能力训练样本。
说白了:传统 Agent 解决“这次怎么做”,Hermes 解决“下次如何更会做”。
值不值得做
先给判断:值得做,但不能盲目做成“自动学习一切”。
值得做的场景很明确。
如果你的 Agent 面向研发、运维、部署、数据分析、内容生产、企业流程自动化,那么 Skill 系统非常值得上。
因为这些任务都有一个共同点:
步骤多。
坑点多。
重复频率高。
人工经验很贵。
但不值得盲目做的场景也很明确。
如果任务高度随机、复用率低、没有沙箱、没有审查机制、没有成功率评测,那自动沉淀 Skill 可能会带来反效果。
Agent 可能学到错误流程。
也可能把一次性的临时解决方案固化成长期规则。
❗最危险的不是 Agent 不学习。
而是它学错了,还被系统默认相信。
越接近工程工作流,越值得做 Skill;越缺少安全边界,越不能急着全自动。
如果是我来做
先说结论:我不会一开始就追求“完全自我进化”,而会先做一个可审查的 Skill 闭环。
① 先定义 Skill 模板。
每个 Skill 至少包含:触发条件、适用平台、所需工具、执行步骤、验证方式、失败处理、风险等级。
没有这些字段,就不要让它进入自动执行链路。
② 严格区分 Memory 和 Skill。
用户偏好、环境信息、长期约定放进 Memory。
操作步骤、命令序列、排障流程放进 Skill。
事实和流程混在一起,后面一定会乱。
③ 先做半自动创建,再逐步放权。
早期不要让 Agent 创建的 Skill 直接进入高权限执行。
可以先生成草稿,由人审核后进入正式库。
低风险技能可以自动启用,高风险技能必须确认。
④ 把安全扫描做成强制流程。
所有 Skill 入库前,都要经过注入检测、路径检测、危险命令检测、密钥检测和来源分级。
安全不是后置功能,而是 Skill 系统的入口门槛。
⑤ 用指标判断它有没有价值。
不要只看“Agent 好像更聪明了”。
要看重复任务耗时是否下降,人工干预次数是否减少,执行成功率是否提升,错误回滚是否更清楚。
工程上最可靠的进化,不是让系统自由发挥,而是让系统在边界内持续变好。

[插图:如果我来落地 Hermes 思路]
总结
Hermes Agent 真正有意思的地方,不是它又做了一个 Agent。
而是它把 Agent 的成长路径讲清楚了。
不是只靠更长上下文。
不是只靠更多工具。
不是只靠更复杂 Prompt。
而是把经验沉淀为 Skill,把 Skill 做成索引,把索引变成按需加载,把执行结果继续反哺 Skill。
这套机制背后的判断很简单:
未来的 Agent,不只是会调用工具,而是会积累自己的工作方法。
但越是这样,信任体系越重要。
因为一个会学习的系统,也可能学错。
一个能自我修改的系统,也可能被污染。
所以 Hermes 给我的最大启发不是“Agent 终于有记忆了”。
而是:
Agent 的下一阶段竞争,不在于是否会做事,而在于能否把做事经验安全地沉淀下来。
金句
Agent 的长期价值,不是多回答一次,而是少重复犯错一次。
Memory 记住事实,Skill 记住做法。
传统 Agent 解决“这次怎么做”,Hermes 解决“下次如何更会做”。
可学习的 Agent,必须同时是可约束的 Agent。
未来的 Agent,不只是会调用工具,而是会积累自己的工作方法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)