【评价模型】别只知道熵权法!深度解锁多准则决策利器:CRITIC 模型
在多准则决策分析(MCDA)中,如何科学地给各项指标“赋权”始终是核心痛点。传统的熵权法(Entropy Weight Method)只考虑了数据本身的离散程度,却忽略了指标之间的相关性。
今天,我们要深度拆解一个更全面、更智能的客观赋权模型——CRITIC 评价模型。
一、模型简介
CRITIC (Criteria Importance Through Intercriteria Correlation) 法是由 Diakoulaki 等人在 1995 年提出的一种客观赋权方法。
它的核心思想不仅仅是看某个指标“变动大不大”(对比强度),还要看这个指标与其他指标之间的“冲突大不大”(冲突性)。
核心逻辑总结: 一个指标的权重,取决于它的波动性和独立性。
波动性强 = 包含信息量大
独立性强(与其他指标相关性低)= redundancy(冗余)小,不可替代性强。
二、模型原理
设有 n个待评价对象(方案),m个评价指标,原始数据矩阵为:
步骤1:数据无量纲化(标准化)
因指标间常有量纲与数量级差异,需先做正向化与标准化。使用极差标准化(0–1 区间):

其他为混合极性指标,此处忽略。
步骤2:计算指标变异性
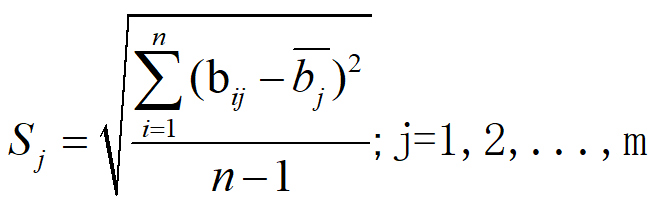
变异性用标准差衡量的是 “这个指标能不能把不同评价对象区分开”,即描述数据 围绕平均值的离散程度。
标准差大 → 数值散布得开 → 指标能拉开方案档次 → 这个指标在评价中“有发言权”
举个例子,假设有三个方案在某个指标上的标准化得分:
| 方案A | 方案B | 方案C | 标准差 | 含义 |
|---|---|---|---|---|
| 0.1 | 0.3 | 0.8 | 大 | 方案差距明显,指标鉴别力强 |
| 0.5 | 0.51 | 0.49 | 极小 | 方案几乎没区别,指标没鉴别 |
步骤3:计算指标冲突性
如果一个指标与其他指标高度正相关
说明它提供的区分信息,其他指标也能提供。它的存在是冗余的,应该降权。如果一个指标与其他指标不相关,甚至负相关
说明它提供了其他指标没有的、独立的区分视角。它的存在是“不可替代”的,应该提权。
因此,步骤3中引入冲突性就是为了量化指标的不可取代性,若指标j与其他指标的关联系很低,则说明其独立性高,在模型中就更具有代表性。说明这个指标更能代表一个独立、不可舍弃的评价维度,具体计算如下:
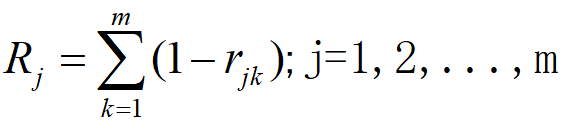
此处的 为标准化后的指标
和指标
的皮尔逊相关系数,用于刻画指标之间线性相关的方向和强度,不是泛泛地衡量两个变量有没有关系,而是专门衡量它们是否在同一条直线上变化,即指标间信息的重叠度。一个指标即使变异很大,如果和其他指标完全重合,冲突性为零,那它也只是在重复已知信息,不应重复计分。
以下为皮尔逊相关系数的计算公式:
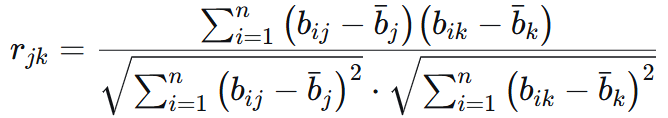
皮尔逊相关系数的取值范围为[-1,1],相当于从数学上就是在问:“你(指标j)高于均值的时候,我(指标k)也倾向于高于均值吗?” 这种“同涨同跌”的倾向有多强。
- 若
则说明知道一个指标的值,就能精确推算另一个,两个指标传递的信息完全等价,是完美的正相关;
- 若
则说明两个指标为完美的负相关,传递的信息也是完全等价的,只是方向相反;
- 若
则说明两个指标传递的信息在线性意义上完全独立、不重叠,两个指标间的增减没有任何固定的比例关系;
- 若
则说明两个指标的数据点大致沿着一条直线分布,但有离散,若
越大,则离散情况越小,指标的重叠度越大。反之,则重叠度/关联度越小。
综上,若 (j≠k)越小,则
越大,那么指标
越独立。
步骤4:计算指标信息量
根据步骤2和步骤3,我们知道:
变异系数大 → 指标区分度高 → 对方案的鉴别力强
冲突性大→ 指标独立性强 → 提供不可替代的独特评价维度
因此,引入信息量C,即用一个乘积公式,将变异系数和冲突性强制绑定,输出一个同时反映这两方面品质的单一数值,为最终赋权提供直接依据:
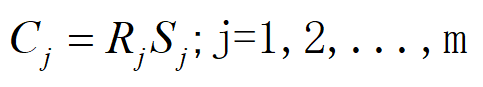
步骤5:计算指标权重
把每个指标的信息量,除以所有指标信息量的总和,进而完成归一化的操作,使得所有权重取值都在0到1之间,并且所有权重之和为1。权重其实就是该指标在整个评价体系中所占的信息份额:
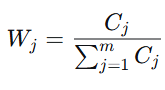
三、案例分析
评价 4 款手机的综合表现
| 手机 | 充电功率 (W) |
屏幕尺寸 (英寸) |
价格 (元) |
|---|---|---|---|
| A | 20 | 6.1 | 2000 |
| B | 120 | 6.2 | 5000 |
| C | 80 | 6.15 | 3500 |
| D | 60 | 6.18 | 2800 |
step1:数据无量纲化(标准化)
需进行正向化与标准化处理,首先正向指标有充电功率、屏幕尺寸,而负向指标是价格,先将指标正向化,再标准化即可得到标准化矩阵B:
| 手机 | 充电 |
屏幕 |
价格 |
|---|---|---|---|
| A | 0.00 | 0.00 | 1.00 |
| B | 1.00 | 1.00 | 0.00 |
| C | 0.60 | 0.50 | 0.50 |
| D | 0.40 | 0.80 | 0.7333 |
step2:计算指标变异性
| 指标 | 变异性/标准差 |
|---|---|
| 充电 | 0.3606 |
| 屏幕 | 0.3766 |
| 价格 | 0.3677 |
step3:计算指标冲突性
| 指标 | 冲突性 |
|---|---|
| 充电 | 2.0965 |
| 屏幕 | 2.0982 |
| 价格 | 3.9251 |
step4 :计算指标信息量
| 指标 | 信息量 |
|---|---|
| 充电 | 0.7560 |
| 屏幕 | 0.7902 |
| 价格 | 1.4434 |
step5:计算权重
| 指标 | 权重 |
|---|---|
| 充电 | 0.2529 |
| 屏幕 | 0.2643 |
| 价格 | 0.4828 |
结果整合:
| 指标 | 变异性(区分度) | 冲突性(独立性) | 信息量 | 权重 |
|---|---|---|---|---|
| 充电功率 | 0.3606 | 2.0965 | 0.7560 | 25.29% |
| 屏幕尺寸 | 0.3766 | 2.0982 | 0.7902 | 26.43% |
| 价格 | 0.3677 | 3.9251 | 1.4434 | 48.28% |
结果分析:
-
三个指标的变异性非常接近,说明它们的自身鉴别力(区分度)差不多。
-
但价格的冲突性远高于另外两者,因为价格与充电、屏幕均呈强负相关,提供了完全独立的评价维度。
-
最终价格获得近一半的权重,体现了 CRITIC 对独立信息的奖励机制。
四、模型优缺点对比
| 方法 | 优点 | 缺点 |
|---|---|---|
| CRITIC | ① 同时考虑指标的 区分度(变异)与 独立性(冲突),赋权更全面 ② 完全基于数据驱动,不受主观偏好影响 ③ 能自动压低高度相关指标的重复权重,避免信息冗余 |
① 仅能捕捉线性重叠,对非线性相关信息不敏感 ② 计算出的权重依赖样本,样本变化可能引起权重波动 ③ 无法融入专家经验或决策偏好 |
| 主观赋权法 (AHP/专家评分) |
① 可充分反映决策者意图与专业经验 ② 适用于数据缺乏或指标重要性有明确业务共识的场景 |
① 主观性强,结果因人而异 ② 指标数量多时判断矩阵复杂,一致性难以保证 ③ 无法反映指标在实际样本中的鉴别能力 |
| 熵权法EWM | ① 基于信息熵衡量指标信息量,能捕捉离散程度 ② 计算简单,易于实现 |
① 完全忽略指标间的相关性,重复信息会被重复赋权 ② 仅关注变异度,不评价指标间是否“说同一件事” |
| 等权法 | ① 计算最简单,不引入任何偏差 ② 作为基准模型,透明易懂 |
① 无视指标的实际区分能力和独立价值,可能淹没重要指标 ② 冗余指标会成倍放大其共同维度的影响 |
五、模型应用场景
最后再总结一下,CRITIC具有客观性,因此应用的场景也非常多!
| 应用领域 | 具体场景举例 | 为什么适用 CRITIC |
|---|---|---|
| 经济与管理决策 | 企业综合绩效评价、供应商选择、上市公司财务竞争力分析 | 财务指标间常存在较强相关性(如利润率与净资产收益率),CRITIC 可自动降低冗余指标权重,突出独立信息源。 |
| 环境与资源评价 | 水质综合评价、大气环境质量评价、土地生态安全评估 | 环境监测指标往往相互关联(如 COD 与氨氮),CRITIC 能识别信息重叠,避免重复计分。 |
| 工程技术 | 材料性能综合评价、机械加工工艺参数优选、电网电能质量评价 | 多种性能指标间可能存在共线性,CRITIC 通过对冲突性的度量,保留关键的差异性指标。 |
| 医药与健康 | 中药质量综合评价、医院医疗质量排名、药物疗效多指标优选 | 中药指纹图谱中多个成分含量常高度相关,CRITIC 可找出最具化学区分度的成分,赋予更高权重。 |
| 农业与食品 | 农产品品质综合评价、不同品种果实品质比较、食品感官与理化指标融合评价 | 感官指标与理化指标之间存在重复描述,CRITIC 有助于精简评价指标体系。 |
| 教育与社科 | 高校科研绩效评估、城市综合发展水平评价、人才竞争力分析 | 评价指标繁杂且维度重叠严重,CRITIC 在无主观经验介入下,客观筛选高鉴别力指标。 |
| 风险管理 | 信贷风险评级、供应链风险评估、自然灾害脆弱性评价 | 风险因子之间通常高度相互关联,CRITIC 可确保综合得分不会因重复计算相似风险而失真。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)