何恺明谢赛宁参与,Google新工作证明,图像生成器天生就是理解大师!
推荐理由
如果说Transformer统一了语言模型,那么这篇来自Google(含Kaiming He大神)的重磅力作,或许正在统一视觉模型。它石破天惊地证明了:图像生成模型在学会“画图”的那一刻,其实就已经悄悄学会了“看懂世界”。仅需极简的指令微调,就能吊打一众SOTA专用模型,这绝对是所有视觉研究者今年不可不读的“圣杯”级论文!
为了给方便大家更好的复现,我给大家准备了完整版的技术资料、代码和复现路径,如有需要点击链接自取!
论文信息:

- 论文标题: Image Generators are Generalist Vision Learners
- 发表单位: Google (Nano Banana Pro团队)
- 论文链接: https://arxiv.org/pdf/2604.20329v1
- 项目主页: vision-banana.github.io
一、 为什么说这是视觉界的“GPT时刻”?
一直以来,视觉领域存在着“生成”与“理解”两条泾渭分明的技术路线。我们总怀疑:一个靠概率蒙像素的生成器,真的懂物理结构吗?
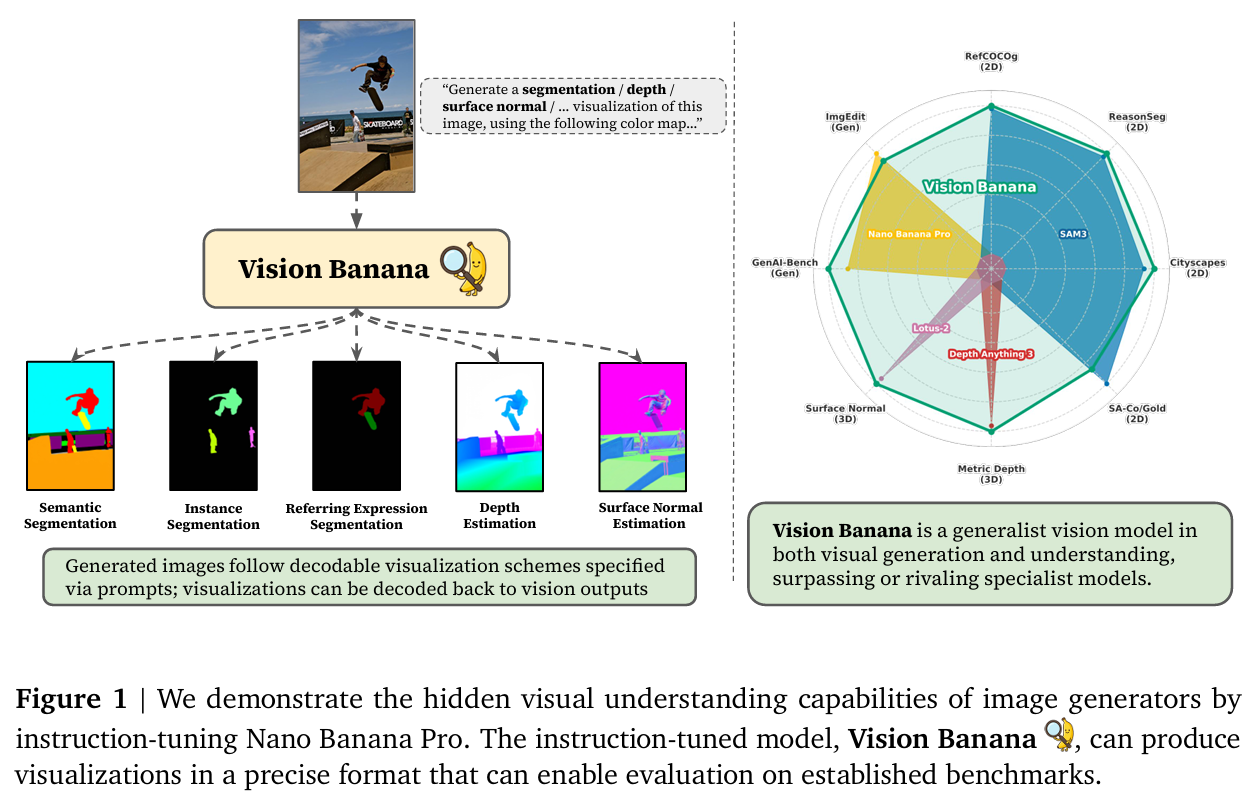
但这篇论文给出了肯定的答案。作者认为,图像生成模型的预训练过程,本质上等同于LLM的生成式预训练——模型在构建画面的过程中,必须深刻理解光影、几何、语义和空间关系。为了唤醒这种“沉睡”的理解力,Google团队基于顶级的生成模型 Nano Banana Pro (NBP),通过极轻量的指令微调(Instruction Tuning),直接让它摇身一变,成为了全能的视觉理解专家——Vision Banana。
二、 核心魔法:RGB即一切,指令即任务
Vision Banana最巧妙的地方在于“统一接口”。它没有引入任何复杂的任务头,而是将所有视觉任务的输出映射为RGB图像。
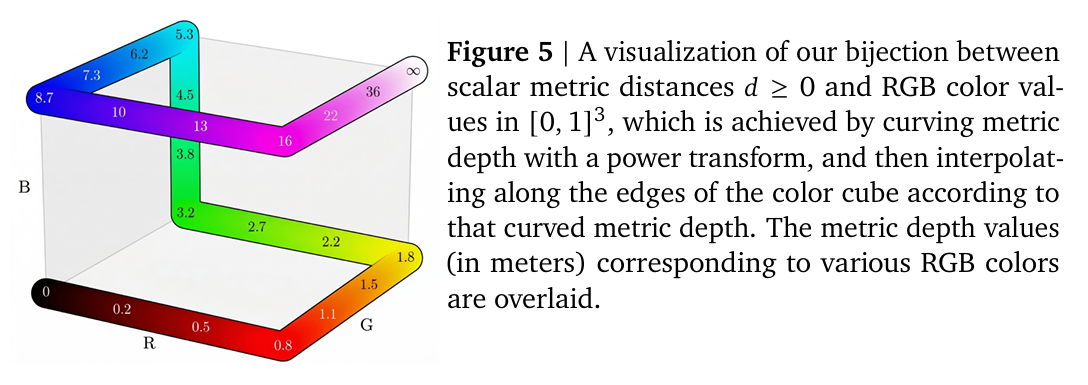
以深度估计为例,为了把连续物理距离编码成RGB颜色,作者设计了一个巧妙的双射映射。
三、 性能表现:正面硬刚专用模型
数据最能说明问题。在指令微调后,Vision Banana在多个标准基准上实现了“跨级”超越:
1. 2D语义理解:精准到“猫的胡须”
在语义分割和指代分割上,Vision Banana表现惊人。它不仅能理解复杂的文本指令,还能处理极其细微的边缘。

2. 3D场景理解:无需内参的“黑科技”
最惊艳的是单目深度估计。它甚至不需要相机内参,完全依赖预训练中学到的物体尺寸先验,就能预测绝对物理距离。

为了验证泛化能力,作者甚至直接用手机拍了张金阁寺的照片进行实测:

四、提问
这篇论文解决了什么痛点?
它解决了视觉模型“碎片化”的问题。以前我们需要不同的模型做不同的事,现在证明了一个强大的生成模型通过微调就能成为“全能战士”。
为什么它能做到“无需相机内参”预测深度?
因为它学习的是“语义级别的三维关系”。它对物体尺寸的先验知识极强,通过RGB颜色编码的方式,直接把语义理解转化成了度量空间。
普通人/学生能复现吗?
目前基座模型 NBP 尚未开源,复现门槛极高。但这种“生成即理解”的思路完全可以借鉴到现有的开源大模型(如SD系列)中。
五、 总结:范式的转移
由于采用了极轻量的指令微调,Vision Banana在进化为“理解大师”的同时,并没有丢掉作为“画师”的本职工作。

评价:
这项研究可能会像 GPT 对 NLP 的影响一样,带来 CV 领域的范式转移。它告诉我们,通向 AGI 的路径可能比预想的更统一:生成即理解。虽然目前复现门槛较高,但它为构建统一的视觉基础模型指明了新方向。
为了给方便大家更好的复现,我给大家准备了完整版的技术资料、代码和复现路径,如有需要点击链接自取!
本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)