DeepSeek-V4 技术报告深度解析
发布时间:2026年4月24日
报告来源:DeepSeek-V4 Technical Report (HuggingFace PDF)
整理日期:2026年4月27日
DeepSeek-V4 技术报告深度解析
发布时间:2026年4月24日
报告来源:DeepSeek-V4 Technical Report (HuggingFace PDF)
整理日期:2026年4月27日
一、概览:DeepSeek-V4 是什么?
DeepSeek-V4 是 DeepSeek-AI 于 2026年4月 发布的超大规模 混合专家(MoE)语言模型系列,是继 DeepSeek-V3.2 之后的重大升级版本。
本次发布包含两个模型:
两个模型都原生支持百万 token 上下文(1M Context),在 Agent 能力、世界知识和推理性能上均实现开源领域领先。
核心发布亮点
- 百万 token 上下文:首次以 MoE 架构实现原生 1M context,且效率极高
- 架构三大创新:CSA+HCA 混合注意力、mHC 流形约束超连接、Muon 优化器
- 极致效率:1M token 下,V4-Pro 推理 FLOPs 仅为 V3.2 的 27%,KV 缓存仅 10%
- 三档推理模式:非思考 / Think High / Think Max,适配不同计算预算
- 完全开源:模型权重与推理代码开源,Agentic Coding 实用表现接近闭源前沿
二、架构详解
2.1 混合注意力机制(CSA + HCA)
问题背景:传统 Transformer 注意力在超长上下文下计算开销呈 O(n²) 增长,1M token 的计算量极其巨大。
DeepSeek-V4 设计了两种新型注意力机制交替叠加:
2.1.1 压缩稀疏注意力(Compressed Sparse Attention, CSA)
核心思路:先压缩 KV 缓存,再稀疏选择最相关的条目进行注意力计算。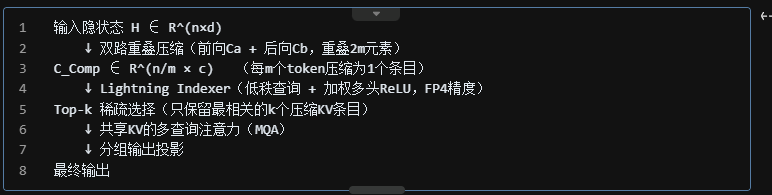
Lightning Indexer 使用 FP4 精度加速索引计算,top-k 选择后 KV 召回率维持 99.7%。
2.1.2 重度压缩注意力(Heavily Compressed Attention, HCA)
2.1.3 CSA vs HCA 对比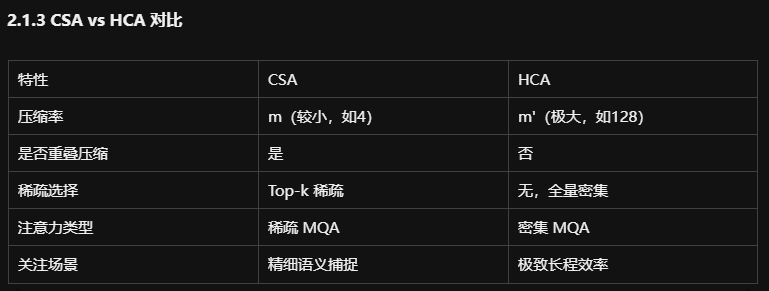
2.1.4 其他注意力细节
● 查询归一化:对查询和压缩KV条目执行额外 RMSNorm,防止 logit 爆炸
● 部分旋转位置编码(Partial RoPE):对向量最后64维应用 RoPE,保留相对位置语义
● 滑动窗口补充分支:每个 query 额外保留 128 个未压缩 KV,增强局部建模
● 注意力 Sink:可学习的 sink logits,允许注意力得分总和趋近于0
● KV 缓存精度:RoPE维度用 BF16,其余维度用 FP8,相比纯 BF16 节省约 50% 存储
2.1.5 效率收益
在 1M token 上下文下:
2.2 流形约束超连接(mHC)
问题背景:标准超连接(HC)在深层堆叠时频繁发生数值不稳定,限制了 HC 的规模化能力。
mHC 核心创新:双随机矩阵流形约束
将残差变换矩阵 B_l 约束到 双随机矩阵流形(Birkhoff多面体):
每行和每列的元素之和均为1,且元素非负。
数学保证:
● 谱范数 ‖B_l‖₂ ≤ 1(非扩张变换,信号不会爆炸)
● M 在乘法下封闭(深层堆叠时稳定性传递)
● A_l、C_l 通过 Sigmoid 约束为非负有界(防止信号相消)
Sinkhorn-Knopp 投影算法(20次迭代实现双随机矩阵投影):交替行归一化和列归一化,快速收敛。
动态参数化:参数由输入动态生成(小值初始化 + 静态偏置 + 可学习门控因子),大幅增强表达能力。
意义:在保持模型表达力的同时,从数学根本上解决了深层残差连接的不稳定问题。
2.3 DeepSeekMoE 结构升级
DeepSeek-V4 继承 DeepSeekMoE 框架,相比 V3 有以下关键改动: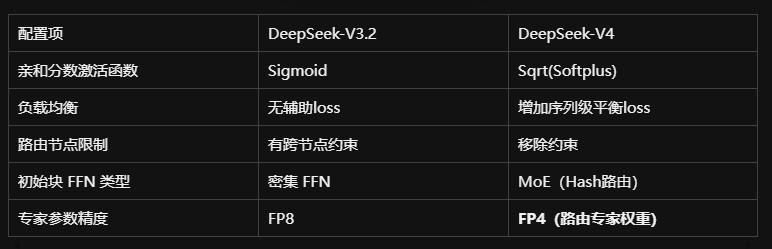
模型配置参数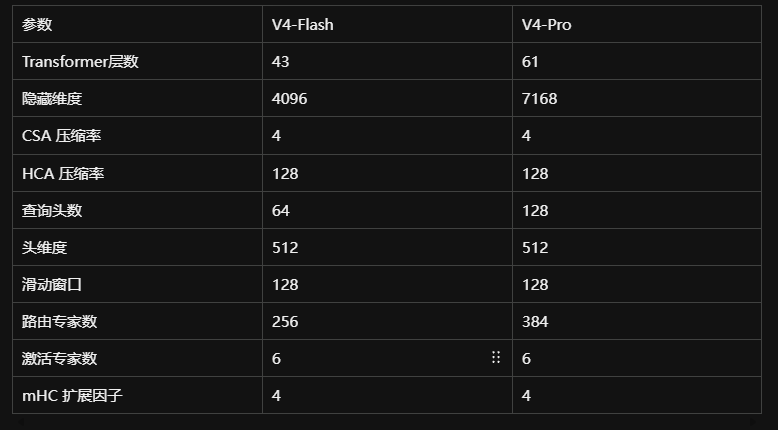
三、训练方法
3.1 预训练
数据规模
模型 预训练 Token 数
数据构成:网页、数学、代码、长文档(科学论文/技术报告)、多语言语料(长尾文化知识)
关键改进:
● 引入样本级注意力掩码(更精细的样本边界控制)
● 加强长文档数据整理,优先科学论文等高信息密度材料
● 中期训练阶段加入 Agentic 数据增强 coding 能力
● 128K 词表(继承 V3 分词器,增加少量特殊 token)
Muon 优化器
传统问题:AdamW 收敛慢,训练不稳定
Muon 核心:对权重梯度执行矩阵正交化后更新,让不同参数方向相互独立。
混合 Newton-Schulz 正交化(10次迭代,两阶段):
● 前8步:(a,b,c) = (3.4445, -4.7750, 2.0315)——快速收敛
● 后2步:(a,b,c) = (2, -1.5, 0.5)——精确稳定到奇异值为1
优化器分配策略:
通信优化:MoE 梯度量化为 BF16 传输(减半通信量),two-phase reduce-scatter 避免低精度累积误差。
训练稳定性技巧
预期路由(Anticipatory Routing):用稍旧参数计算路由索引,解耦主干网络和路由网络的同步更新,显著提升训练稳定性。系统自动检测 loss spike 时触发短暂回滚和预期路由模式,之后恢复正常训练。
SwiGLU 钳位:线性分量钳位到 [-10, 10],门控分量上限设为 10,消除异常值,稳定训练,且不损害性能。
训练阶段:序列长度从 4K 逐步扩展到 16K → 64K → 1M;1T token 密集注意力预热,之后引入稀疏注意力。
3.2 FP4 量化感知训练(QAT)
应用范围:
- MoE 路由专家权重(GPU 显存主要消耗来源)
- CSA Lightning Indexer 的 QK 路径(长文本场景加速)
FP4→FP8 无损转换原理:
● FP8(E4M3) 比 FP4(E2M1) 多2个指数位,动态范围更大
● 可完全吸收 FP4 子块(1×32 tiles)内的精细尺度信息
● 实验验证:FP4 子块内 max/min scale 之比满足阈值条件(无损转换成立)
实际训练:高精度权重先量化为 FP4,再反量化为 FP8 参与计算——完全复用现有 FP8 框架,无需修改。
RL 一致性:RL rollout 阶段直接使用真实 FP4 量化权重,确保训练和推理行为完全一致。
3.3 后训练:两阶段范式
在策略蒸馏(OPD)优势:
● 避免传统权重合并或多任务 RL 中的负迁移问题
● 完整词表 logit 蒸馏:梯度方差低,训练稳定
● 来自不同专家的知识通过 logit 级对齐融入统一参数空间
推理努力模式
三种模式(均通过 RL 训练,不同的长度惩罚和上下文窗口):
模式 特点 适用场景 格式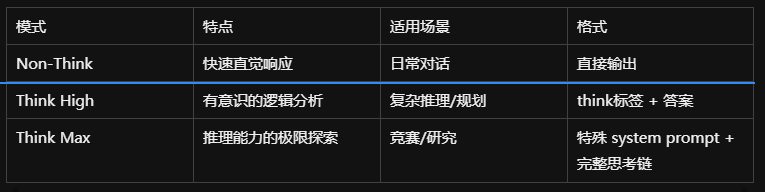
生成式奖励模型
创新:不使用传统人工标注奖励模型,直接整理"指导性 RL 数据",用生成式奖励模型(即模型本身)评估轨迹质量,并对奖励模型本身也应用 RL 优化。
优势:模型内部推理能力天然融入评估过程,高度鲁棒,仅需少量人工标注即可达到优越性能。
工具调用与交错思考
● 新工具调用架构:引入特殊 |DSML| token + XML 格式(缓解转义失败,减少工具调用错误)
● 交错思考(Interleaved Thinking):在工具调用场景中,所有推理内容在整个对话中完全保留(跨越用户消息边界),充分利用 1M context 优势
● 快速指令(Fast Instructions):将辅助任务(意图识别、是否触发搜索等)编码为特殊 token,直接复用已计算的 KV 缓存,完全避免冗余预填充,显著降低首 token 延迟
四、基准测试结果
4.1 DeepSeek-V4-Pro-Max vs 前沿闭源模型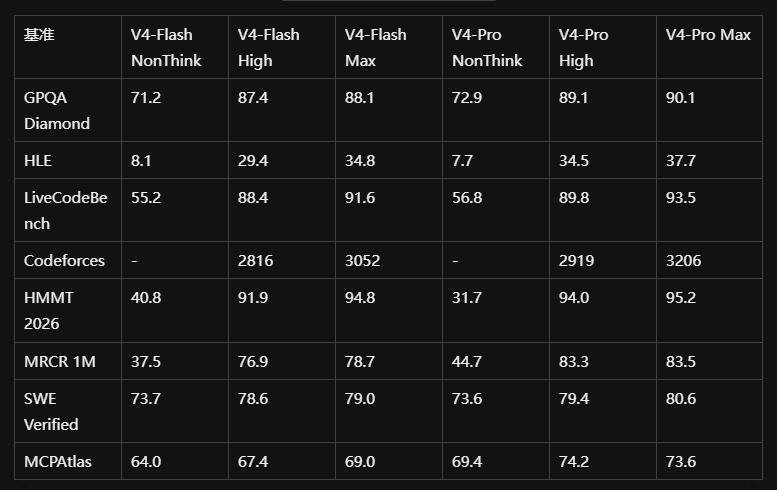
4.2 各模式横向对比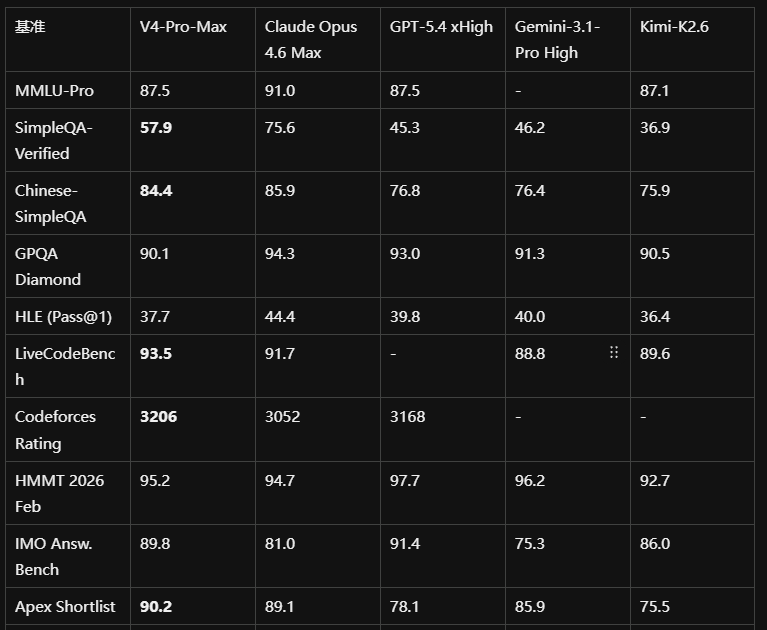
结论:V4-Flash-Max 在较大 thinking budget 下,推理性能可以媲美 V4-Pro High;但在纯知识任务和最复杂 Agentic 工作流上仍逊于 V4-Pro。
4.3 预训练基础模型对比
五、工程实现亮点
5.1 专家并行(EP)细粒度通信计算重叠
问题:MoE All-to-All 通信是严重的吞吐量瓶颈。
解决方案:Wave-based 专家调度 + 融合 Mega-Kernel
在稳态下,当前 wave 的计算、下一 wave 的数据传输、已完成专家的结果发送同时进行,形成完整流水线。
关键理论:每 GBps 互连带宽可隐藏 6.1 TFLOP/s 的计算通信。
性能提升:
● 通用推理:1.50–1.73× 加速
● RL rollout 等延迟敏感场景:最高 1.96× 加速
开源:MegaMoE(DeepGEMM 的一部分)
5.2 TileLang 灵活高效内核开发
TileLang 是 DeepSeek 用于 GPU 内核开发的领域特定语言(DSL),三大核心技术:
● Host Codegen:CPU 验证开销从数十~百微秒 → <1微秒
● Z3 SMT 求解器辅助整数分析:形式化分析整数表达式,支持向量化/内存冒险检测/边界分析
● 数值精度与位级可重现性:默认禁用 fast-math,提供 IEEE-754 合规内在函数
5.3 批次不变且确定性内核
目标:确保预训练、后训练、推理之间位级完全对齐。
注意力层批次不变性:
● 问题:标准 split-KV 方法导致输出依赖 batch 位置(非确定性)
● 解决:双内核策略(高吞吐内核 + 低延迟内核,两者累积顺序完全一致)
矩阵乘法:端到端替换 cuBLAS 为 DeepGEMM,放弃 split-k,通过其他优化补偿性能。
确定性反向传播:
● 注意力:为每个SM分配独立累积缓冲区,之后确定性全局求和
● MoE:token顺序预处理 + 多 rank 缓冲区隔离
5.4 RL 百万 token 上下文扩展
专门框架支持 1M token 上下文的强化学习训练,关键技术:
● 可抢占容错 Rollout 服务(支持 RL 过程中的故障容忍)
● 高效教师调度(全词表 OPD 的通信优化)
● Agent AI 专用沙箱基础设施(支持代码执行、工具调用验证)
六、真实场景评测
6.1 代码 Agent(内部评测)
从50+名内部工程师收集约200个真实任务(功能开发/Bug修复/重构/诊断),涵盖 PyTorch/CUDA/Rust/C++:
结果:DeepSeek-V4-Pro 显著优于 Claude Sonnet 4.5,接近 Claude Opus 4.5 水平。
调查(85名工程师):
● 52% 表示 V4-Pro 可作为主力编码模型(媲美前沿模型)
● 39% 倾向于是
● <9% 反对
6.2 中文写作
配对评估 DeepSeek-V4-Pro vs Gemini-3.1-Pro:
● 功能性写作:V4-Pro 以 62.7% vs 34.1% 的胜率领先
● 创意写作(指令遵循):V4-Pro 胜率 60.0%
● 创意写作(写作质量):V4-Pro 胜率 77.5%
注:仅限最难提示的评估中,Claude Opus 4.5 仍以 52% vs 45.9% 优势领先。
6.3 搜索增强问答
DeepSeek-V4-Pro vs V3.2(客观+主观问答):
● V4-Pro 以显著优势胜出
● 最大提升在:单值搜索(精确事实定位)和规划策略任务(结构化计划合成)
● Agent 搜索始终优于 RAG,且成本仅略高于 RAG
6.4 白领任务(中文)
30个高难度中文专业任务(深度分析/文档生成/细致编辑,跨13个行业):
DeepSeek-V4-Pro-Max vs Claude Opus 4.6 Max(盲评):
● 总体:V4-Pro-Max 实现 63% 非失败率(多维度胜出)
● 优势维度:任务完成 + 内容质量
● 表现一致:分析、生成、编辑任务均有优势
七、技术贡献总结
创新层次矩阵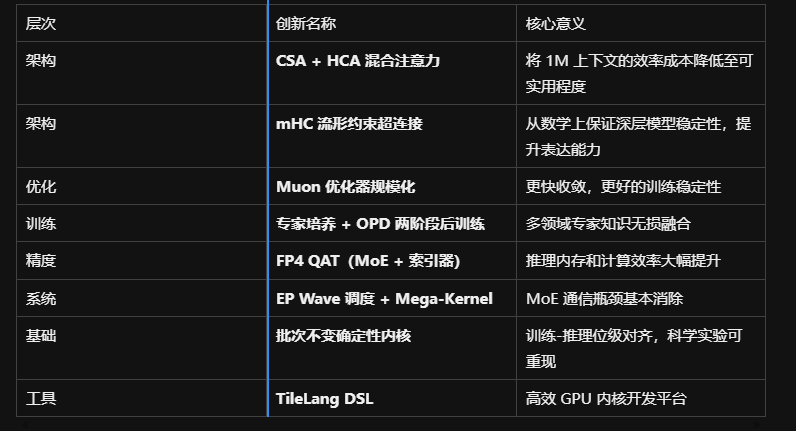
开放贡献
资源 链接
模型权重(HuggingFace集合) https://huggingface.co/collections/deepseek-ai/deepseek-v4
V4-Pro 推理代码 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/tree/main/inference
MegaMoE 内核(DeepGEMM) https://github.com/deepseek-ai/DeepGEMM/pull/304
技术报告 PDF https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
八、个人分析与思考
8.1 DeepSeek-V4 最大意义是什么?
百万 token 上下文的普惠化。不是首个支持 1M context 的模型,但是第一个让 1M context 变得计算上可行且开源的模型。
● V3.2 在 1M token 下:FLOPs 和 KV 缓存极高,实际部署成本巨大
● V4 在 1M token 下:FLOPs 降至 27%,KV 缓存降至 10%,真正实用
这一突破对以下场景影响深远:
● 长文档理解:整本书、完整代码库、长期对话上下文
● 复杂 Agent 工作流:长时程多步推理,完整历史轨迹保留
● 大规模代码 Agent:整个仓库作为上下文
8.2 CSA + HCA:为什么是混合设计?
这是一个稀疏精度与效率的权衡:
● 只用 CSA:Top-k 稀疏可能漏掉全局低频重要信息
● 只用 HCA:极度压缩(128:1)虽高效但可能丢失细粒度语义
● 混合:CSA 负责精细语义捕捉,HCA 提供极低成本的全局粗粒度注意力,二者互补
这种设计哲学(粗细粒度互补)在神经网络中并不新鲜,但首次被如此系统地应用于超长上下文注意力机制。
8.3 mHC 的核心价值
双随机矩阵约束是一个优雅的数学解:既保证了信号不爆炸(谱范数≤1),又保证了信息路由的"守恒性"(行列和均为1,类似交通流守恒),同时不强制特征对齐。
这种思路值得在其他深层网络稳定性问题中借鉴。
8.4 OPD(在策略蒸馏)的范式价值
专家独立培养 + 统一整合解决了多任务学习的核心矛盾:不同领域最优策略往往相互冲突。
OPD 的解法:各自训练到极致,然后在 logit 分布层面蒸馏融合。理论上这是目前最理想的多专家整合方式——既保留了各专家的领域专注,又通过蒸馏实现了统一的语用层面学习。
8.5 与竞争对手对比分析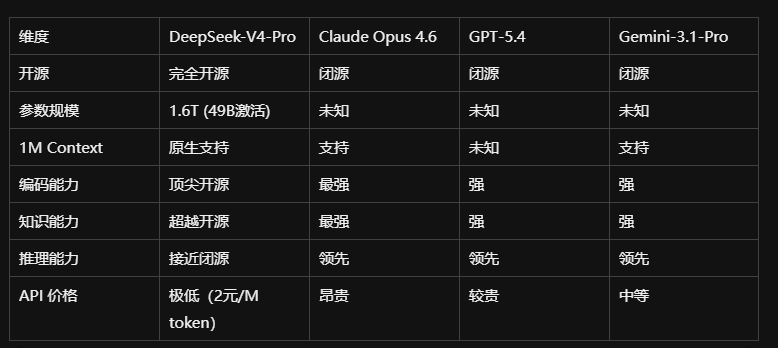
核心差距:V4-Pro 在 HLE(Humanity’s Last Exam)上仍落后于 Claude Opus 4.6(37.7 vs 44.4),说明在最顶尖的知识推理边界,闭源模型仍有约6个月左右的技术优势。
8.6 对 UMMs/多模态研究的启发
- 长上下文压缩注意力思路迁移:CSA/HCA 的核心思想(压缩→稀疏选择)可以迁移到多模态 token 压缩:大量视觉/音频 token 可以用类似方式压缩,减少 LMM 的计算开销
- 专家培养范式:UMMs 研究中,不同模态能力(视觉、音频、文本)可以用类似"专家独立培养 + OPD 整合"的方式训练
- mHC 稳定性方案:深层多模态网络中,信号传播稳定性是关键挑战,双随机矩阵约束是一个值得探索的通用方案
参考资料
● DeepSeek-V4 技术报告:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
● DeepSeek-V4 HuggingFace 集合:https://huggingface.co/collections/deepseek-ai/deepseek-v4
● MegaMoE 内核开源 PR:https://github.com/deepseek-ai/DeepGEMM/pull/304
本文档由 AI 助手基于 DeepSeek-V4 官方技术报告整理,最后更新:2026年4月27日

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)