大模型入门干货|大模型学习你必须懂的10个核心概念
10个大模型学习你必须要懂的核心概念

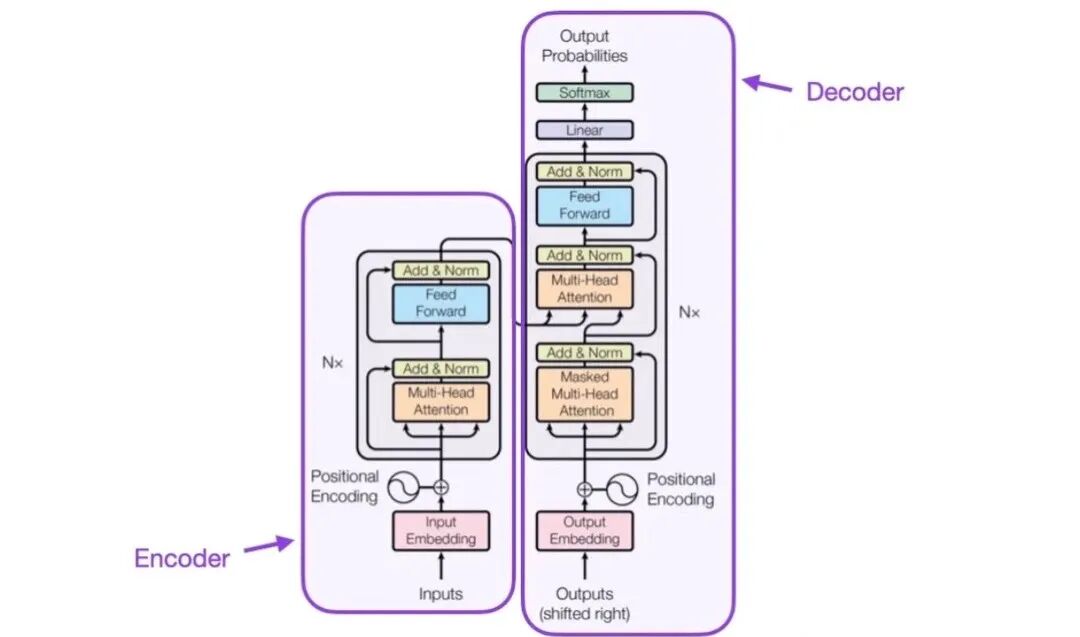
*1、LLM(大语言模型)*
全称 Large Language Model,直译就是 “大语言模型”,是所有大模型应用的基础,相当于我们开发中的 “核心服务”,所有功能都围绕它展开。
通俗理解:LLM 就像一个 “学识渊博但有点随性的大脑”,通过海量文本训练,能理解自然语言、生成内容、做逻辑推理,但它本身不会主动 “干活”,需要我们引导和约束。
实战关联:我们开发中常用的 GPT、文心一言、通义千问、DeepSeek-V2 等,都是 LLM;我们做的所有应用(对话机器人、文档分析、代码生成),本质都是 “调用 LLM 的能力,解决具体业务问题”。它是一个概率性组件,需通过容错与回退机制保障应用稳定性,是智能涌现的核心引擎。
*2、Prompt(提示词)*
Prompt 即提示词 / 提示工程,是我们向 LLM 传递需求、引导它输出符合预期结果的 “指令”,相当于传统开发里的 “接口参数”,但更灵活、更侧重 “自然语言表达”。
通俗理解:你想让 LLM 写一段代码、总结一篇文章,或者分析一个问题,说给它听的 “话”,就是 Prompt;好的 Prompt 能让 LLM 少走弯路,输出更精准,反之则会出现 “答非所问”。
实战关联:Prompt 不是 “随便说句话”,有明确的设计原则 —— 清晰性、结构化、约束性,比如 “作为一名 Java 后端开发者,用 FastAPI 写一个简单的接口,要求返回 JSON 格式,包含状态码和数据字段”,就是一个合格的 Prompt;它贯穿大模型应用开发全程,直接影响 RAG、Agent 等技术的落地效果,是连接开发者与 LLM 的核心桥梁。
*3、Token(词元)*
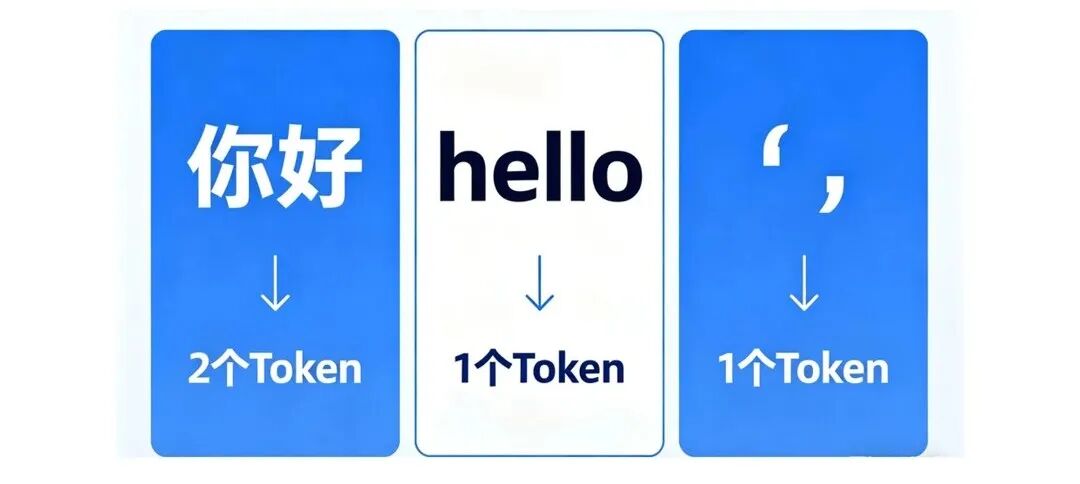
Token 是 LLM 处理文本的最小单位,相当于我们开发中的 “字节”,用来衡量输入 / 输出的文本量,也是大模型 API 计费的核心依据。
通俗理解:一个 Token 可以是****一个汉字、一个英文单词,也可以是一个标点符号****;比如 “你好” 是 2 个 Token,“hello” 是 1 个 Token,“,” 是 1 个 Token。
实战关联:开发时必须关注 Token 限制 —— 每个 LLM 都有 “上下文长度”(最大 Token 数),比如 GPT-4 普通版上下文长度是 8k Token,超过这个长度,模型会 “忘记” 前面的内容(断片);同时,Token 越多,API 调用成本越高,日志分析中也需要重点追踪 Token 消耗,优化成本与性能。
*4、RAG(检索增强生成)*
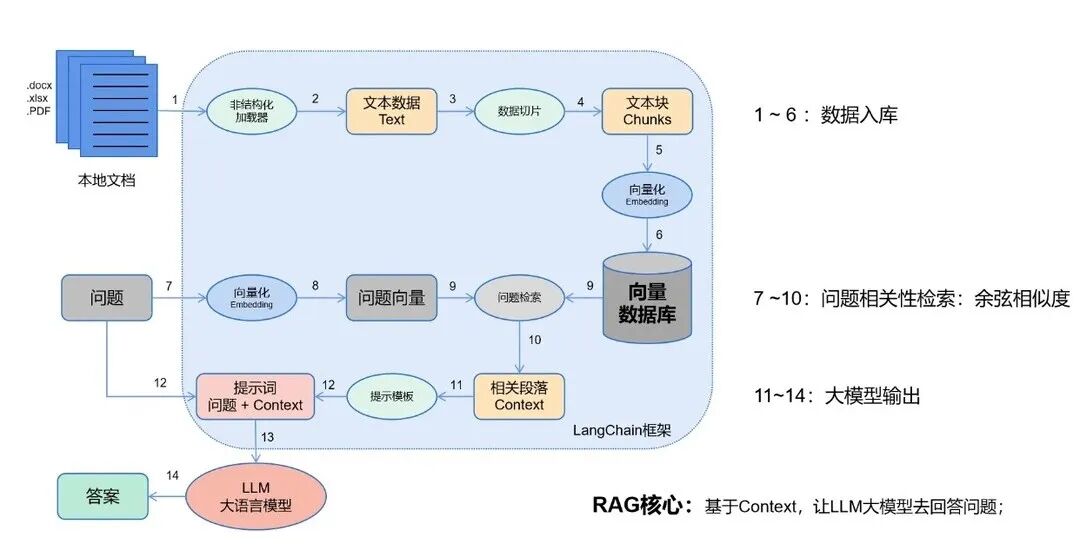
全称 Retrieval-Augmented Generation,直译 “检索增强生成”,是大模型应用开发中最常用的技术之一,核心作用是 *“给 LLM 提供参考资料,避免它瞎编乱造”*。
通俗理解:LLM 的知识有 “保质期”(训练数据截止到某个时间),而且容易编造不存在的信息(幻觉),RAG 就相当于给 LLM 配了一个 “专属知识库”—— 用户提问时,先从知识库中检索相关资料,再让 LLM 基于资料生成回答,相当于 “开卷考试”。
实战关联:做企业知识库、产品咨询、文档分析等应用,必须用 RAG;它能解决 LLM 知识时效性、事实准确性的问题,而且无需对模型进行昂贵的微调,只需更新知识库即可让 LLM 掌握新知识,是企业级大模型应用的 “标配”,其核心依赖向量数据库实现高效检索。
*5、Embedding(嵌入)—— 实现 “语义检索”*
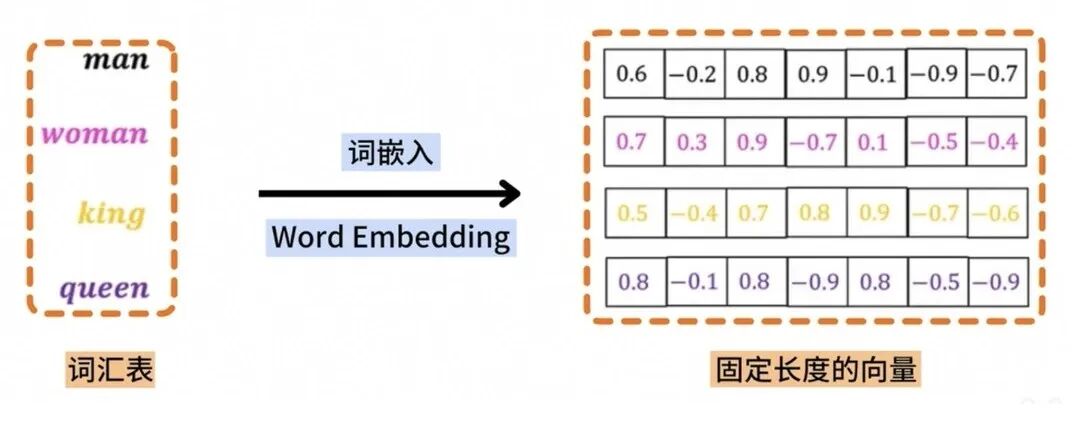
Embedding 即 “嵌入”,简单说就是将文本、图片等****非结构化数据,转化为计算机能理解的** *“数值向量”***(一串数字),是 RAG 实现 “语义检索” 的核心。
通俗理解:我们平时搜索 “苹果手机”,传统搜索会匹配关键词,而 Embedding 能理解 “苹果手机” 和 “iPhone” 是一个意思,因为它们转化后的向量 “很像”(距离很近);它捕捉了内容的深层语义特征,让检索更精准。
实战关联:开发 RAG 应用时,需要将知识库中的文档、用户的提问,都转化为 Embedding,再通过向量数据库存储和检索;常用的 Embedding 模型有 OpenAI 的 text-embedding-ada-002、国产的通义千问 Embedding 等,是连接非结构化数据与大模型的关键纽带。
*6、向量数据库*
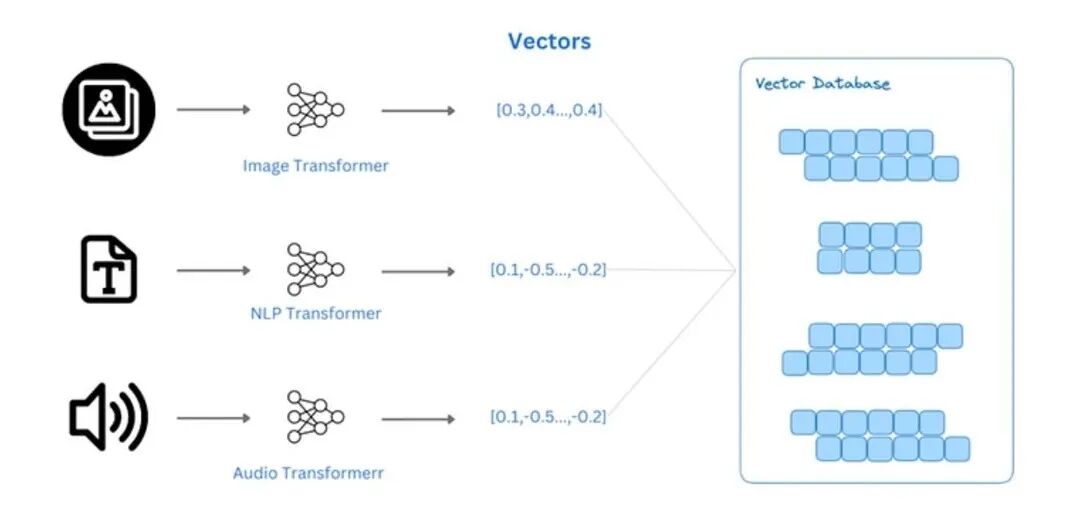
专门用来存储、管理 Embedding 向量的数据库,和我们传统开发中用的 MySQL、Redis 不同,它擅长 “计算向量相似度”,核心作用是 “快速找到与用户提问最相关的资料”。
通俗理解:如果把 Embedding 向量比作 “坐标”,向量数据库就相当于 “地图”,能快速找到和当前 “坐标” 最接近的其他 “坐标”,也就是和用户提问最相关的知识库内容;它解决了传统数据库无法高效处理语义相似性检索的痛点。
实战关联:做 RAG 应用必用向量数据库,常用的有 Pinecone、Milvus、Chroma、FAISS 等;它的性能直接影响 RAG 的检索速度和准确率,是大模型应用中 “知识存储与检索” 的核心载体,也是 Agent 记忆模块的重要支撑。
*7、Function Calling(函数调用)*
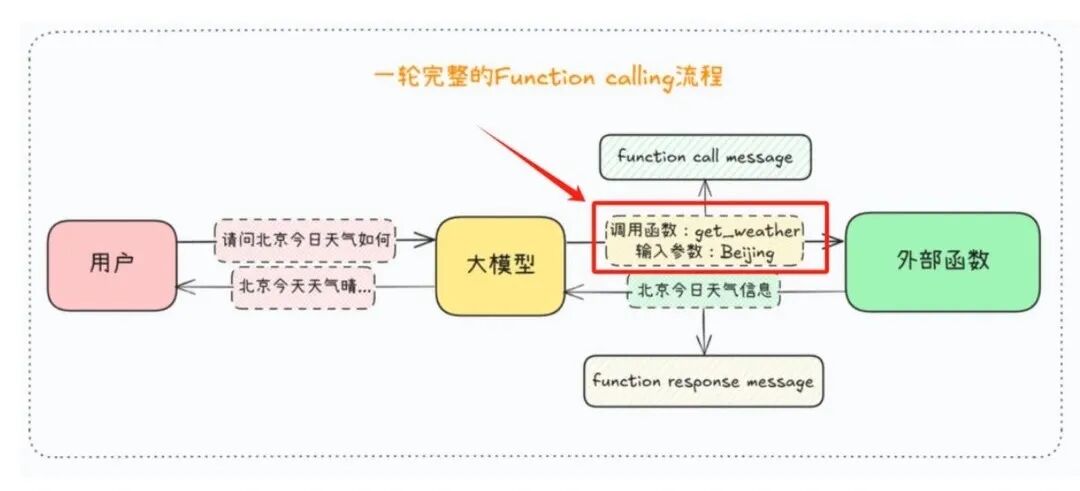
全称 “函数调用”,是 LLM 的核心能力之一,允许 LLM 解析用户需求后,自动调用预设的外部函数(接口、工具),执行具体操作,再根据操作结果生成回答。
通俗理解:LLM 擅长 “思考”,但不会 “操作”—— 比如查询天气、调用数据库、发送邮件,这些都需要通过 Function Calling,让 LLM 像 “调用接口” 一样,触发外部工具执行,再把结果返回给 LLM,完成完整的任务闭环。
实战关联:开发 “智能助手” 类应用(比如自动查订单、生成报表),必须用 Function Calling;它打破了 LLM “闭门造车” 的局限,让大模型能联动业务系统、第三方工具,是实现 “AI 自主干活” 的基础,目前主流大模型均原生支持该能力,也可通过 MCP 协议实现跨模型通用调用。
*8、Agent(智能体)*
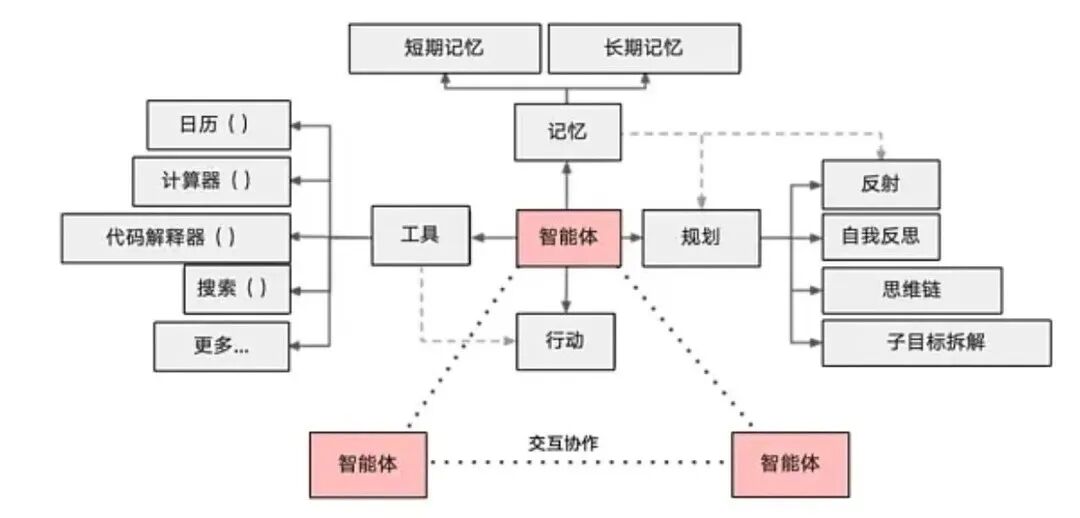
Agent 即 “智能体”,是大模型应用的 “高级形态”,核心是 “基于 LLM,结合记忆、规划、工具调用能力,自主完成复杂任务”,相当于一个 *“能自主思考、自主行动的 AI 打工人”*。
通俗理解:你让 Agent “帮我写一篇大模型应用开发的文章,配图、排版,发布到公众号”,它会自主拆解任务(写文案→找配图→排版→发布),调用对应的工具(文案生成工具、图片工具、公众号接口),全程无需你干预;它整合了 LLM、RAG、Function Calling 等技术,是大模型从 “问答” 到 “自主执行” 的关键。
实战关联:2026 年 Agent 是大模型应用开发的热门赛道,常用的框架有 LangChain、LangGraph、MetaGPT、CrewAI 等;开发复杂任务(比如自动处理工单、数据分析、代码生成),Agent 能大幅提升效率,其核心架构包含规划、记忆、工具调用、反思四大模块,是多技术融合的高级形态。
*9、微调(Fine-tuning)*
微调是指用 “特定领域的数据集”,对预训练好的 LLM 进行二次训练,让 LLM 更适配具体业务场景,相当于 “给通用大脑做专项培训”。
通俗理解:通用 LLM 懂很多领域,但在你的业务(比如金融、医疗、法律)里,可能不够精准;微调就是用你业务中的数据(比如金融合同、医疗病历),让 LLM 专门学习这个领域的知识和语气,输出更贴合业务的结果。
实战关联:如果 RAG 无法满足业务精度需求(比如专业领域的问答、特定语气的生成),就需要微调;但微调成本高、技术门槛高,通常优先用 RAG 优化,只有 RAG 无法解决时,再考虑微调,是大模型定制化落地的重要手段,与模型蒸馏共同构成大模型优化的核心路径之一。
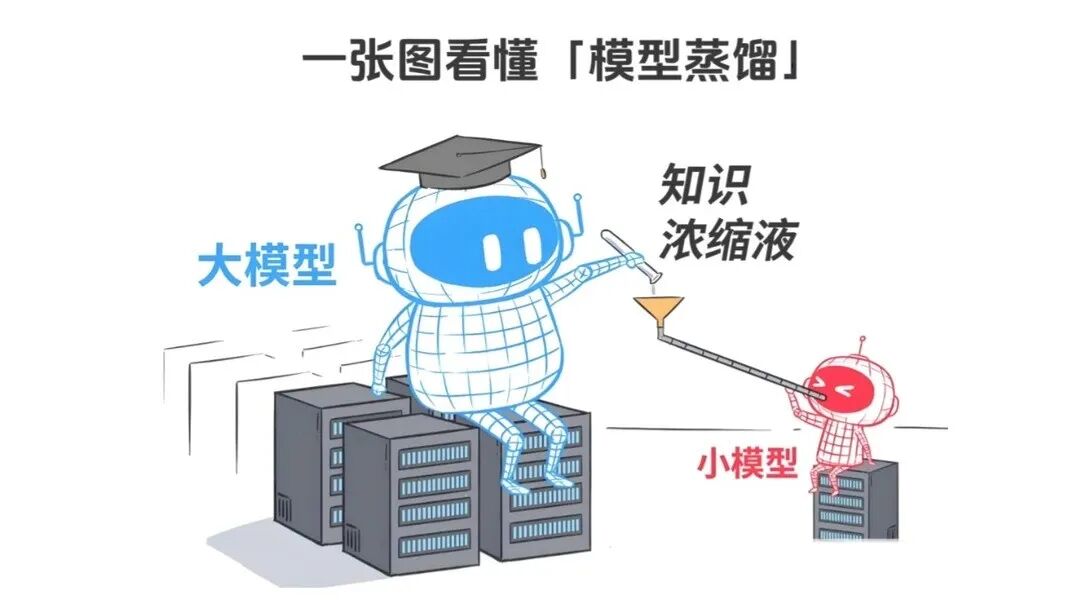
*10、模型蒸馏(Model Distillation)*
模型蒸馏,简单说就是将 “大而复杂的大模型”(教师模型)的知识,迁移到**“小而高效的模型”(学生模型)中,**核心是*“保留核心能力,降低模型体积和推理成本”,相当于 “给笨重的大脑‘瘦身’,让它能跑在更多设备上”。*
通俗理解:我们常用的 LLM(比如 GPT-4、文心一言)体积大、推理慢、成本高,无法部署在手机、边缘设备等资源有限的场景;模型蒸馏就像 “提炼精华”,把大模型的核心能力(理解、生成)保留下来,压缩成小模型,既保证效果,又能快速推理、降低成本。
实战关联:做 ToC 端应用(比如手机 APP 内的 AI 助手)、边缘设备部署,必须用模型蒸馏;它能解决大模型 “部署难、成本高、推理慢” 的痛点,与微调相辅相成 —— 微调负责 “定制化”,蒸馏负责 “轻量化”,是大模型应用落地(尤其是终端场景)的关键技术,常用的蒸馏方式有知识蒸馏、量化蒸馏等。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

*AI大模型学习路线规划*



2026年AI风口已来!转岗大模型应用开发超合适!懂RAG/Agent/Prompt,求职直接加分!全套学习包已经整理好了【RAG开发/Agent设计/面试题/AI产品经理…】

👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
所有评论(0)