【硬核干货】Windows环境下llama.cpp部署 Gemma-4-26B 全流程指南:从环境搭建到 API 调用
·
如何在显存有限的情况下,利用 llama.cpp 实现超长上下文(128K)的 Gemma-4 模型推理?本文为你提供从下载到配置的完整解决方案。
随着 Gemma-4 系列模型的发布,如何在消费级硬件(如 RTX 2080Ti)上高效运行大参数模型成为了很多开发者关注的焦点。本文将详细介绍如何通过 llama.cpp 结合量化技术(GGUF),实现高效的本地推理。
一、 环境准备
推荐配置:
- GPU: NVIDIA RTX 2080Ti (11GB VRAM)
- RAM: 32GB (建议大内存以支持模型卸载)
- OS: Windows 10/11
二、 软件与模型获取
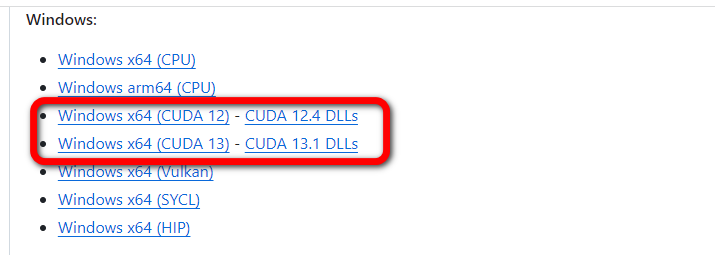
- llama.cpp 下载: 访问 GitHub Releases
 https://github.com/ggml-org/llama.cpp/releases根据 CUDA 版本下载对应的预编译包(本文环境为 CUDA 12)。
https://github.com/ggml-org/llama.cpp/releases根据 CUDA 版本下载对应的预编译包(本文环境为 CUDA 12)。
- 模型获取(关键): 由于模型文件体积庞大,建议通过网盘下载以保证速度。
- 模型资源(GGUF格式): https://pan.quark.cn/s/989fef54d24a
- 注:请确保下载包含
mmproj的多模态组件,以获得视觉理解能力。
三、 部署指令详解
将模型放置于 D:\AI\models 目录下,在 llama.cpp 目录通过 PowerShell 执行以下命令:
.\llama-server.exe `
--model "D:\AI\models\gemma-4-26B-A4B-it-UD-IQ3_S.gguf" `
--mmproj "D:\AI\models\mmproj-gemma-4-26B-A4B-it-bf16.gguf" `
--ctx-size 131072 `
--batch-size 512 `
--ubatch-size 256 `
--n-gpu-layers 21 `
--threads 8 `
--cache-type-k q8_0 `
--cache-type-v q8_0 `
--flash-attn on `
--mlock `
--temp 0.7 `
--top-p 0.8 `
--top-k 20 `
--min-p 0.05 `
--reasoning off `
--port 8088 `
--host 0.0.0.0 `
--api-key sk-123456 `🚀 参数优化核心说明:
| 参数 | 定义 | 说明 |
|---|---|---|
--model |
模型路径 | 指定要加载的 GGUF 模型文件的绝对路径。 |
--mmproj |
多模态投影器路径 | 加载用于视觉理解(Vision)的模型组件,使模型具备“看图”能力。 |
--ctx-size |
上下文窗口大小 | 设置模型能处理的最大 Token 数量(此处设为 131,072,即 128K,非常大)。 |
--batch-size |
批处理大小 | 训练/推理时一次处理的 Token 总数,影响吞吐量。 |
--ubatch-size |
微批处理大小 | 将 batch-size 进一步拆分后的计算单元,有助于平衡显存和速度。 |
--n-gpu-layers |
GPU 层数卸载 | 指定将多少层模型权重加载到显存中(此处为 21 层)。 |
--threads |
CPU 线程数 | 指定用于处理非 GPU 计算任务(如 CPU 卸载部分)的 CPU 核心数。 |
--cache-type-k |
K-Cache 量化格式 | 对 Key Cache 进行量化(此处为 8-bit),以节省显存并提升长文本处理能力。 |
--cache-type-v |
V-Cache 量化格式 | 对 Value Cache 进行量化(此处为 8-bit),与 K-Cache 配合减少显存占用。 |
--flash-attn |
闪速注意力机制 | 开启 Flash Attention 优化,大幅提升长文本下的计算速度并降低显存占用。 |
--mlock |
内存锁定 | 强制将模型加载到物理内存中,防止操作系统将其交换(Swap)到硬盘,保证速度。 |
--temp |
采样温度 | 控制生成随机性(0.7 为适中,越高越有创意,越低越严谨)。 |
--top-p |
核采样 (Nucleus Sampling) | 在概率累积达到 p 的 Token 集合中进行采样,用于控制生成质量。 |
--top-k |
Top-K 采样 | 仅从概率最高的前 K 个 Token 中进行采样,过滤掉低概率词。 |
--min-p |
Min-P 采样 | 一种比 Top-P 更先进的采样策略,根据最高概率的比例过滤 Token,效果更自然。 |
--reasoning |
推理模式开关 | 是否开启模型内置的思维链(CoT)显式输出(此处设为关闭)。 |
--port |
监听端口 | 服务启动后在本地监听的端口号(此处为 8088)。 |
--host |
监听地址 | 指定服务绑定的 IP(0.0.0.0 表示允许局域网内所有设备访问)。 |
--api-key |
API 密钥 | 为 API 请求设置的身份验证令牌(此处为 sk-123456)。 |
四、 如何使用
- Web 端: 浏览器访问
http://127.0.0.1:8088,输入 API Keysk-123456。 - 第三方客户端(如 Cherry Studio):
- 类型选择:
OpenAI-Response - 接口地址:
http://ip:8088/v1 - API Key:
sk-123456
- 类型选择:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)