多模态RAG工程化实践:三种主流方案详解与选型指南
本文深入探讨了多模态RAG的工程化实现,从概念解析到三种主流技术路线的详细阐述。针对纯文本场景的局限性,文章介绍了如何将RAG能力扩展至包含图片、表格等非文本数据类型。通过对比分析基于多模态向量模型、多模态大模型及优化方案的特点,结合实际案例展示了各自的实现流程与效果验证。最终,文章提出根据数据特点、准确性要求和成本预算进行综合选型的建议,为多模态RAG的实际应用提供参考。
一、概述
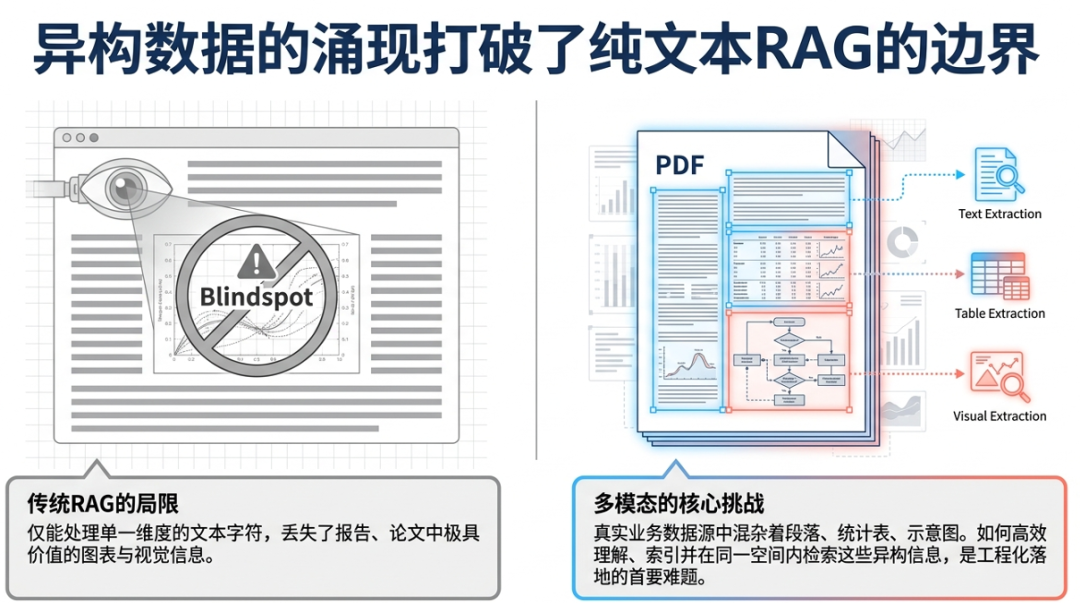
在前几篇文章中,我们从工程化视角系统介绍了RAG(检索增强生成)的核心实践,内容涵盖基础RAG的实现、预检索优化、检索优化以及后检索优化技术。这些方案主要聚焦于纯文本场景下的RAG系统。本文作为该系列的延伸,将聚焦于多模态RAG的工程化实现,探讨如何将RAG能力从单一文本模态扩展至包含图片、表格等多种数据类型的复杂场景。
二、多模态RAG
2.1 什么是多模态RAG
多模态RAG是指在传统RAG架构基础上,引入对图片、表格、图表等多种非文本数据类型的处理能力。相较传统RAG,多模态RAG面临更大的技术挑战——数据源中混杂着文本段落、统计表格、示意图等多种异构信息,如何高效理解、索引并检索这些多模态内容,成为核心难点。
2.2 主流实现方案
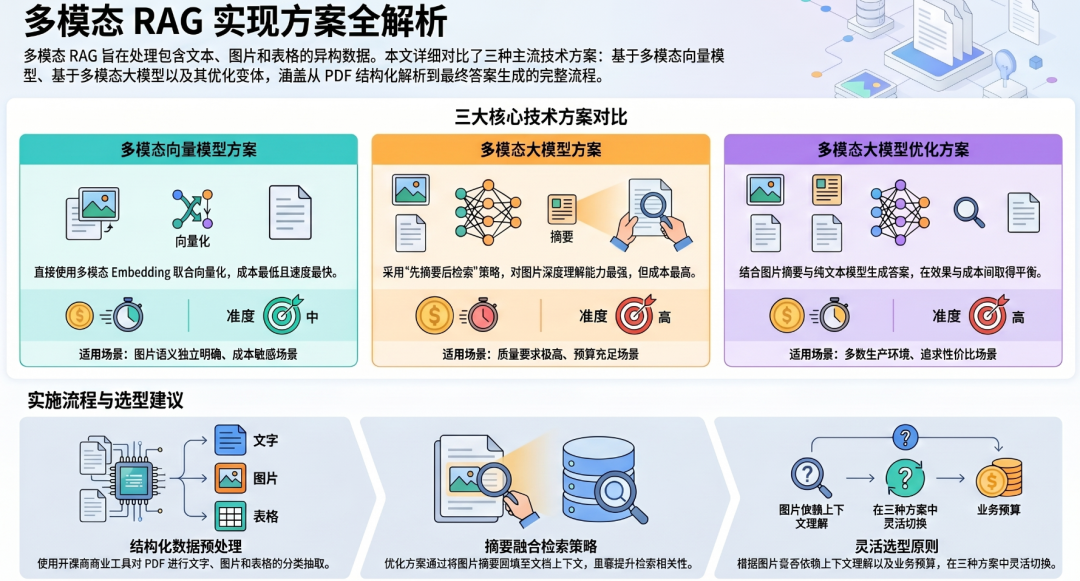
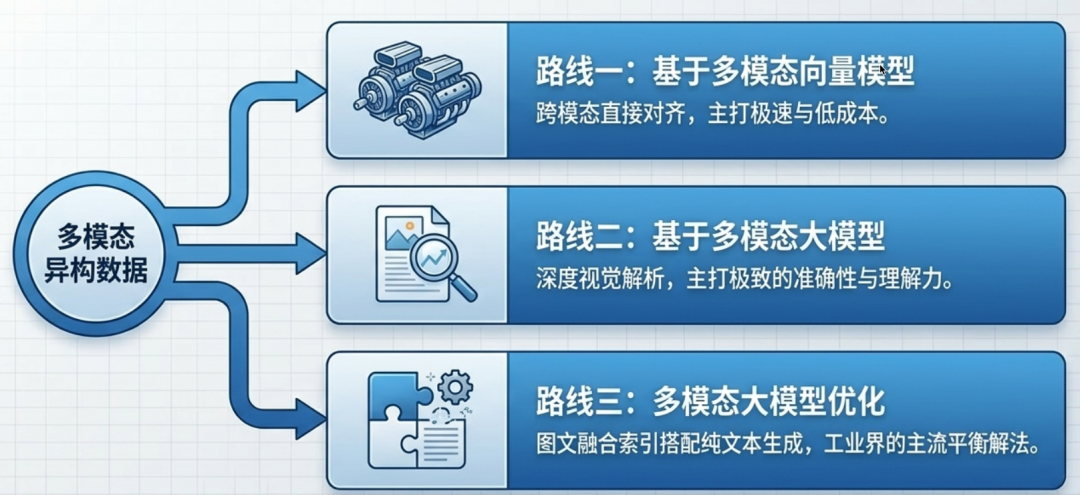
针对多模态数据的RAG建设,业界主要形成了三种技术路线,分别面向不同的业务场景与成本约束:
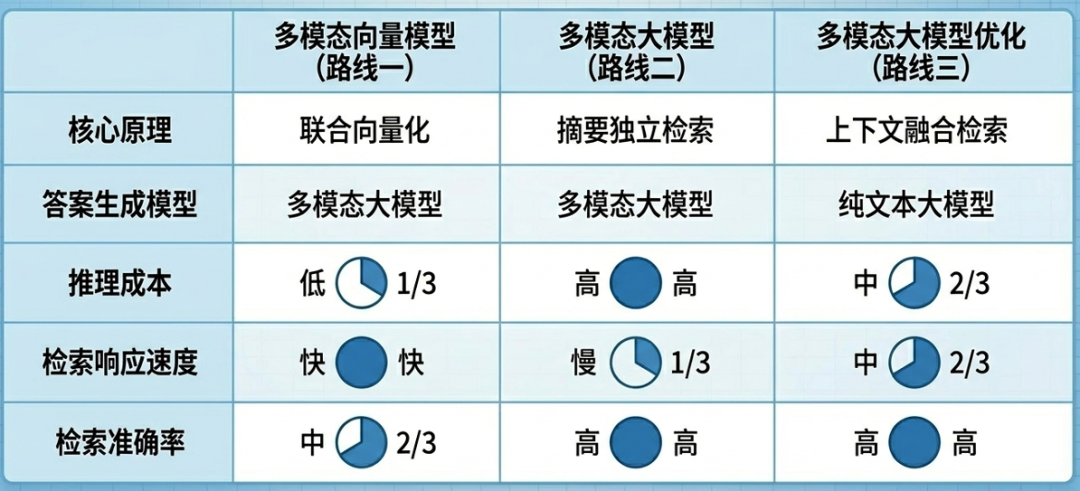
| 方案类型 | 核心依赖 | 检索方式 | 答案生成方式 | 成本 | 速度 | 适用场景 |
|---|---|---|---|---|---|---|
| 多模态向量模型 | 多模态Embedding模型 | 向量相似度检索 | 多模态大模型合成答案 | 低 | 快 | 图片语义明确、无需额外文字辅助理解的场景 |
| 多模态大模型 | 多模态大模型 | 图片摘要向量检索 | 多模态大模型合成答案 | 高 | 慢 | 图片需要深度理解、对准确性要求极高的场景 |
| 多模态大模型优化 | 多模态大模型生成摘要 + 文本大模型 | 文档摘要向量检索 | 文本大模型合成答案 | 中 | 中 | 图片需要上下文辅助理解,追求成本与效果平衡的场景 |
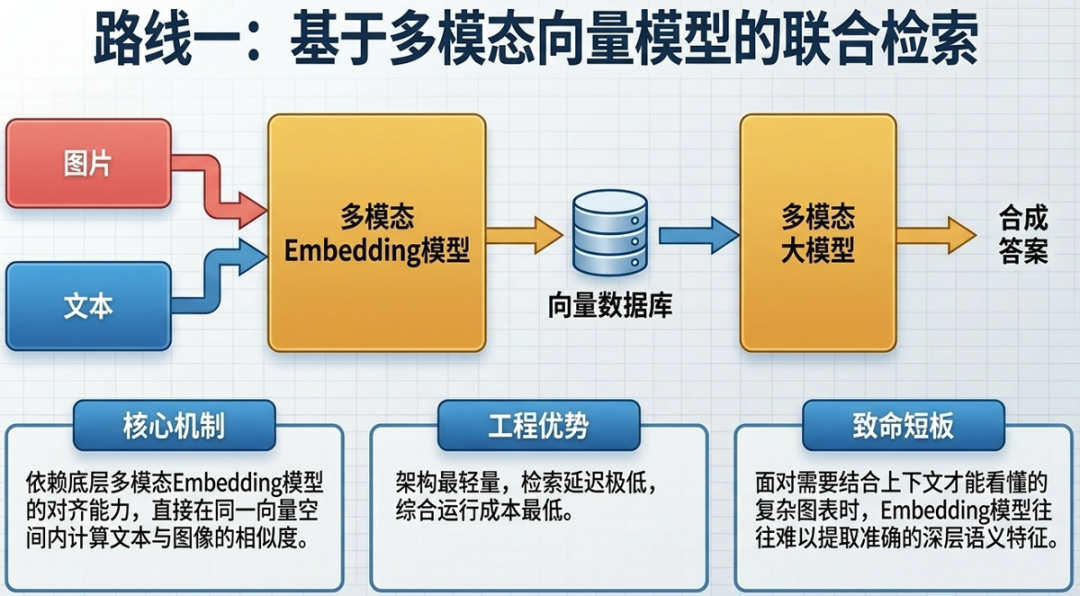
2.2.1 基于多模态向量模型方案
该方案的核心思路是直接使用多模态向量模型对图像和文本进行联合向量化,实现跨模态的语义检索。整体成本较低,检索质量高度依赖嵌入模型的能力。实现流程如下:
- 使用多模态嵌入模型对图像和文本分别进行向量化处理。
- 基于向量相似度检索与用户问题最相关的图像和文本片段。
- 将检索到的原始图像和文本块输入多模态大模型,进行最终答案合成。
2.2.2 基于多模态大模型方案
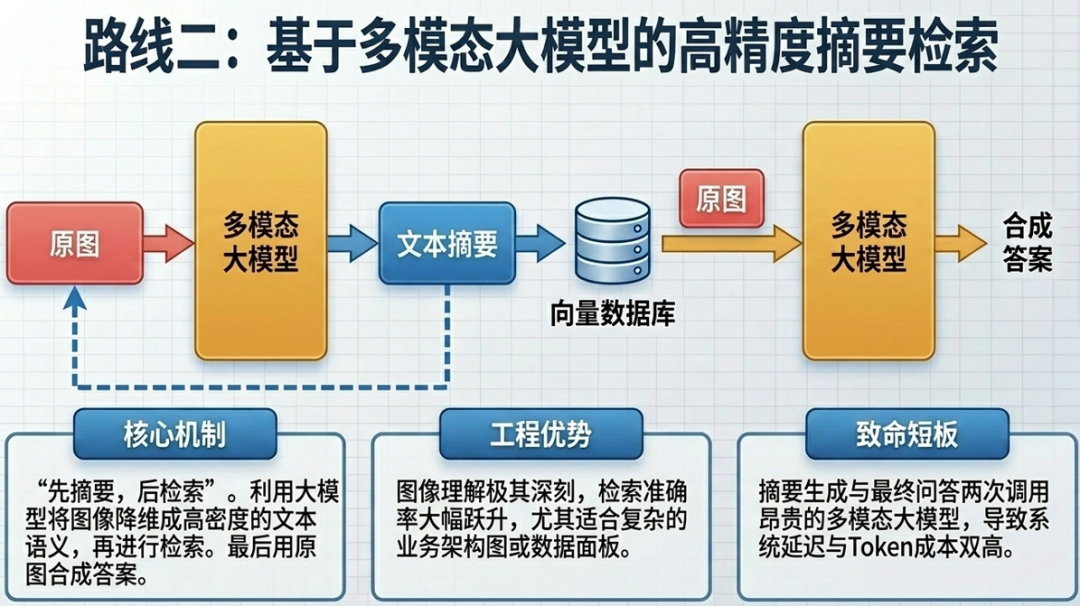
该方案采用“先摘要、后检索”的策略,利用多模态大模型强大的图像理解能力,将图片内容转化为文本摘要后再进行索引。该方案检索准确率较高,但调用多模态大模型生成摘要和答案的环节会带来较高的延迟与成本。实现流程如下:
- 使用多模态大模型从图像生成文本摘要。
- 对图像摘要进行向量化后建立索引,同时保留对原始图片文件的引用。
- 将检索到的原始图像和文本块一并输入多模态大模型进行答案合成。
2.2.3 基于多模态大模型优化的方案
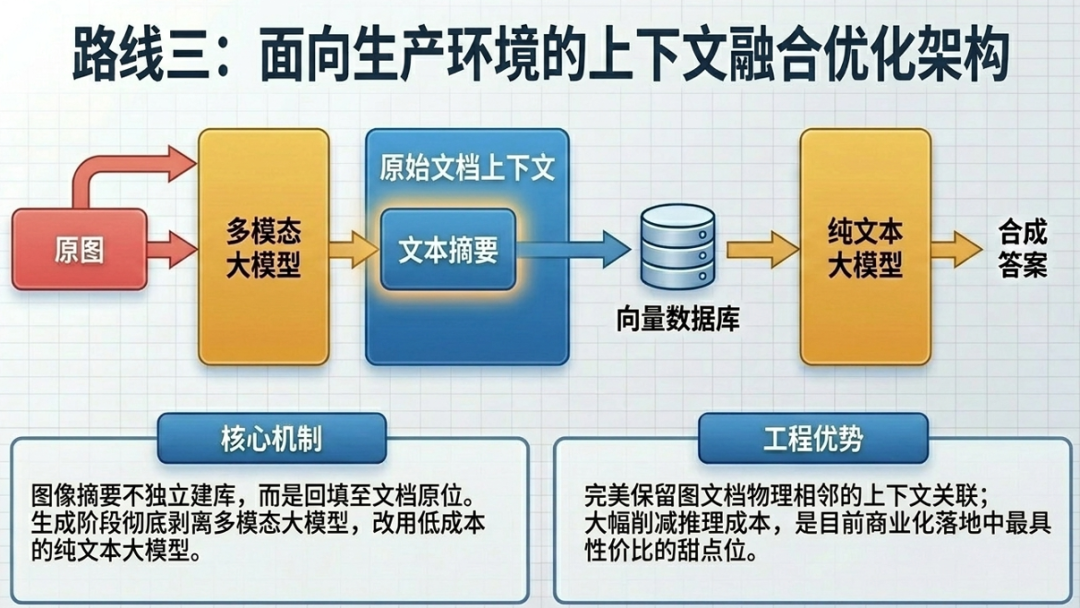
该方案是对方案二的优化变体,核心区别在于答案生成阶段不再依赖多模态大模型,而是使用成本更低的纯文本大模型。该方案在保证较好效果的同时,显著降低了推理成本。实现流程如下:
- 使用多模态大模型从图像生成文本摘要。
- 对文本摘要进行向量化并建立索引。
- 将检索到的文本块输入纯文本大模型进行答案合成。
2.3 三种方案对比
三种方案各有优劣,实际应用中可根据具体场景灵活选型,详细对比如下:
三、实现方式
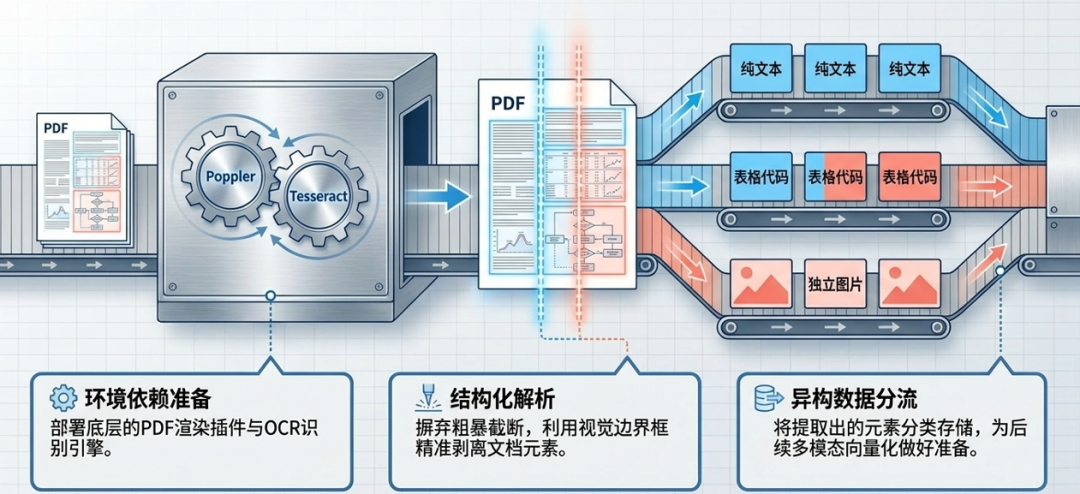
在正式实现多模态RAG之前,首先需要对原始数据进行预处理。本文使用的示例数据是一份包含文本、图片和表格的PDF文档,核心任务是对该文档进行结构化解析,完成文字、图片、表格的分类抽取与切分。
3.1 数据处理
处理PDF文档时,常见的技术路径包括将PDF转换为Markdown或Word格式后再解析,或直接使用商业化PDF解析服务。
目前主流的商业化文档解析方案如下:
- 阿里智能文档解析:https://www.aliyun.com/product/ai/docmind
- 百度文档解析: https://cloud.baidu.com/doc/OCR/s/Klxag8wiy
- 字节火山文档解析:https://www.volcengine.com/docs/6492/2165189?lang=zh
- TextIn:https://docs.textin.com/xparse/parse-quickstart
这里将采用开源的 unstructured 库,使用其 partition_pdf 方法完成PDF元素的抽取。
3.1.1 PDF文档加载
使用 partition_pdf 从PDF中提取元素前,需要先安装所需的系统依赖。不同平台的安装方式如下:
3.1.1.1 Windows平台
首先安装PDF渲染插件poppler,下载后解压,将 bin 目录路径添加到系统环境变量。
然后安装OCR识别引擎tesseract,下载安装后同样将安装路径添加到环境变量。
下载地址如下:
https://github.com/oschwartz10612/poppler-windows/releases/download/v24.08.0-0/Release-24.08.0-0.ziphttps://github.com/tesseract-ocr/tesseract/releases/download/5.5.0/tesseract-ocr-w64-setup-5.5.0.20241111.exe
3.1.1.2 Mac平台
Mac系统可通过Homebrew一键安装:
brew install poppler tesseract
3.1.1.3 Linux平台
Linux系统根据包管理器选择对应命令:
# Debian/Ubuntu系列apt install poppler-utils tesseract-ocr# CentOS/RHEL系列yum install poppler-utils tesseract-ocr
3.1.2 提取数据
使用partition_pdf来对PDF文件内容进行结构化解析处理,相关代码如下:
from unstructured.partition.pdf import partition_pdffrom dotenv import load_dotenvimport osimport shutil_ = load_dotenv()# 工作目录路径resource_path = "./files/"# 图片提取存放路径image_out_dir = resource_path + "images/"# pdf文件路径pdf_path = resource_path + ("source.pdf")# 如果图片提取目录存在则删除重建if os.path.exists(image_out_dir): shutil.rmtree(image_out_dir)os.makedirs(image_out_dir)pdf_data = partition_pdf( filename=pdf_path, extract_images_in_pdf=True, # 提取图片 infer_table_structure=True, # 启用表格结构识别 max_characters=4000, # 每个文本块最大字符数 new_after_n_chars=3800, # 达到3800字符后分新块 combine_text_under_n_chars=2000, # 合并小于2000字符的文本块 chunking_strategy = "by_title", # 按标题分块 extract_image_block_output_dir=image_out_dir, #图片提取路径)print(pdf_data)
运行结果如下,可以看到文档已成功解析,提取的图片被保存至 images 目录:

3.1.3 提取表格与文本内容
完成文档加载后,需要将解析结果中的表格和文本分类提取,便于后续分别处理:
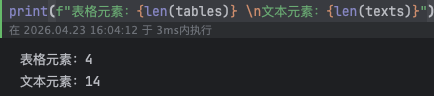
from unstructured.documents.elements import Table,CompositeElementtables = []texts = []for element in pdf_data: if isinstance(element,Table): tables.append(str(element)) elif isinstance(element,CompositeElement): texts.append(str(element)) print(f"表格元素:{len(tables)} \n文本元素:{len(texts)}")
运行结果如下:
3.2 基于多模态向量模型(方案一)
完成数据预处理后,接下来就是基于多模态向量模型构建RAG系统。
3.2.1 多模态数据处理
首先需要定义一个支持文本和图像双模态的向量化类,这里使用的是阿里的多模态向量模型:
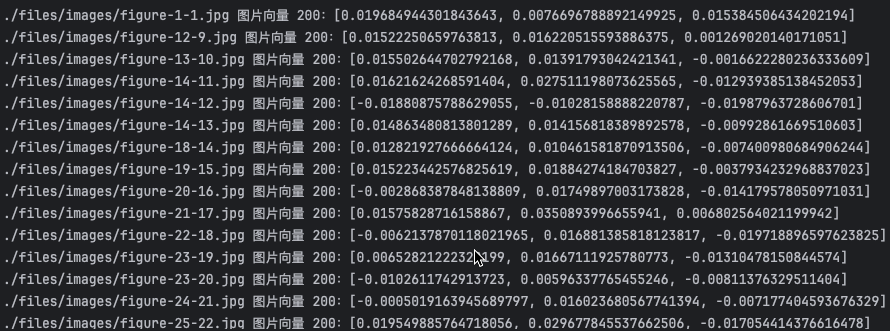
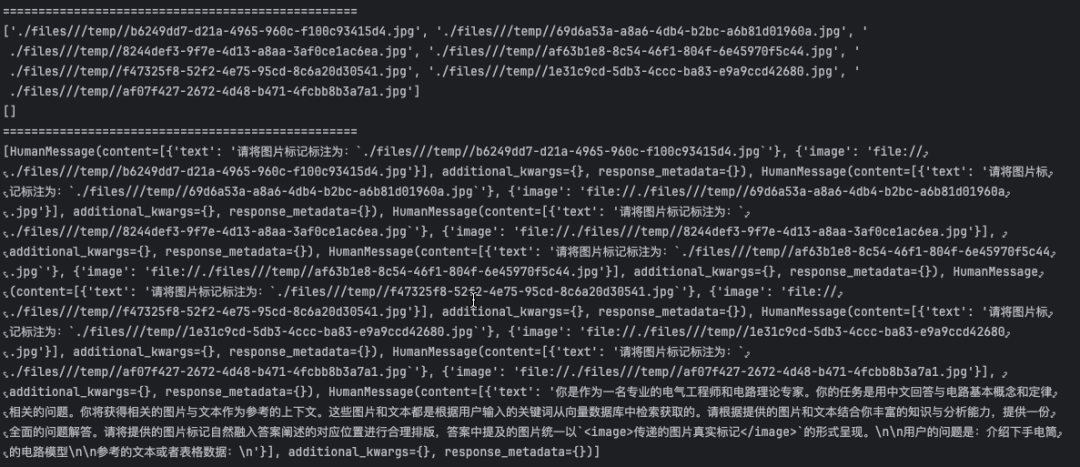
from typing import Listfrom langchain_community.embeddings.dashscope import DashScopeEmbeddingsfrom langchain_core.embeddings import Embeddingsfrom pydantic import BaseModelimport dashscopeclass MultiDashScopeEmbeddings(BaseModel, Embeddings): '''多模态向量模型''' model: str = "multimodal-embedding-v1" def embed_documents(self, texts: List[str]) -> List[List[float]]: text_features = [] for text in texts: resp = dashscope.MultiModalEmbedding.call( model=self.model, input= [{'text': text}] ) embeddings_list = resp.output['embeddings'][0]['embedding'] text_features.append(embeddings_list) return text_features def embed_query(self, text: str) -> List[float]: resp = dashscope.MultiModalEmbedding.call( model=self.model, input= [{'text': text}] ) embeddings_list = resp.output['embeddings'][0]['embedding'] return embeddings_list def embed_image(self, uris: List[str]) -> List[List[float]]: image_features = [] for uri in uris: # 阿里dashscope SDK要求传递图片的地址,对于本地图片dashscope SDK会将图片上传到OSS服务中: local_image_uri = f"file://{uri}" resp = dashscope.MultiModalEmbedding.call( model=self.model, input=[{"image":local_image_uri}] ) embeddings_list = resp.output['embeddings'][0]['embedding'] print(f"{uri} 图片向量 {resp.status_code}:{embeddings_list[:3]}") image_features.append(embeddings_list) return image_features
接下来对图片和文本数据分别进行向量化,并存入向量数据库:
import osfrom langchain_chroma import Chromafrom langchain_core.documents import Documentvectorstore = Chroma( collection_name="multi-vector", embedding_function= MultiDashScopeEmbeddings())# 获得图片的地址image_uris = sorted( [ os.path.join(image_out_dir, image_name) for image_name in os.listdir(image_out_dir) if image_name.endswith(".jpg") ])# 添加图片 (存储图像base64数据与其向量数据)vectorstore.add_images(uris=image_uris)# 添加文本与表格vectorstore.add_documents([Document(page_content=table) for table in tables])vectorstore.add_documents([Document(page_content=text) for text in texts])retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
执行结果如下,可知图片和文本数据已都被向量化:
3.2.2 RAG系统构建
数据向量化完成后,即可构建完整的RAG检索生成链路。考虑到多模态大模型的上下文长度限制,首先需要对图片进行缩放处理:
import base64import iofrom PIL import Imageimport uuid import shutil'''缩放图片ChatTongyi是对阿里DashScope SDK的封装,要求传递图片的地址,对于本地图片阿里SDK会将图片上传到OSS服务中{"text": "需求"},{"image":f"file://{图片的绝对地址}"}'''def resize_base64_image(base64_string, size=(250, 250)): # 解析图片 img_data = base64.b64decode(base64_string) img = Image.open(io.BytesIO(img_data)) # 缩放 resized_img = img.resize(size, Image.LANCZOS) buffered = io.BytesIO() resized_img.save(buffered, format=img.format) # base64编码 return base64.b64encode(buffered.getvalue()).decode("utf-8")save_path = resource_path+"/temp/"if os.path.exists(save_path): shutil.rmtree(save_path)os.makedirs(save_path)def resize_base64_image4tongyi(base64_string, max_size=(640, 480)): # 解析图片 img_data = base64.b64decode(base64_string) img = Image.open(io.BytesIO(img_data)) width, height = img.size ratio = min(max_size[0] / width, max_size[1] / height) # 计算按比例缩放后的宽高 new_width = int(width * ratio) new_height = int(height * ratio) # 缩放 resized_img = img.resize((new_width,new_height), Image.LANCZOS) # 保存图片到指定路径 out_path = save_path + str(uuid.uuid4())+ ".jpg" resized_img.save(out_path) # 图片地址 return out_path"""检查是否为base64数据:图片"""def is_base64(s): try: return base64.b64encode(base64.b64decode(s)) == s.encode() except Exception: returnFalsedef split_image_text_types(docs): """缩放图片(防止图片过大,超过多模态大模型的窗口限制)""" images = [] text = [] for doc in docs: content = doc.page_content if is_base64(content): # 缩放图片 resize_image = resize_base64_image4tongyi(content) images.append(resize_image) else: text.append(content) return {"images": images, "texts": text}
定义检索增强的问答链路:
from langchain_core.messages import HumanMessagefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnableLambda, RunnablePassthroughfrom langchain_community.chat_models.tongyi import ChatTongyidef prompt_func(data_dict): # 提取图片与文本 images = data_dict["context"]["images"] texts = data_dict["context"]["texts"] print("=" * 50) print(images) print(texts) print("=" * 50) messages = [] # 装载图片数据 for image in images: messages.append( HumanMessage( content=[ {"text":f"请将图片标记标注为:`{image}`"}, {"image":f"file://{image}"} ] ) ) # 装载文本数据 formatted_texts = "\n\n".join(texts) messages.append( HumanMessage(content=[ { "text": "你是作为一名专业的电气工程师和电路理论专家。你的任务是用中文回答与电路基本概念和定律相关的问题。" "你将获得相关的图片与文本作为参考的上下文。这些图片和文本都是根据用户输入的关键词从向量数据库中检索获取的。" "请根据提供的图片和文本结合你丰富的知识与分析能力,提供一份全面的问题解答。" "请将提供的图片标记自然融入答案阐述的对应位置进行合理排版,答案中提及的图片统一以`<image>传递的图片真实标记</image>`的形式呈现。\n\n" f"用户的问题是:{data_dict['question']}\n\n" "参考的文本或者表格数据:\n" f"{formatted_texts}" } ] ) ) print(messages) return messages# 千问视觉模型(多模态)llm = ChatTongyi(model="qwen-vl-max")# RAG pipelinechain = ( { "question": RunnablePassthrough(), "context": retriever | RunnableLambda(split_image_text_types) } | RunnableLambda(prompt_func) | llm | StrOutputParser())
3.2.3 效果验证
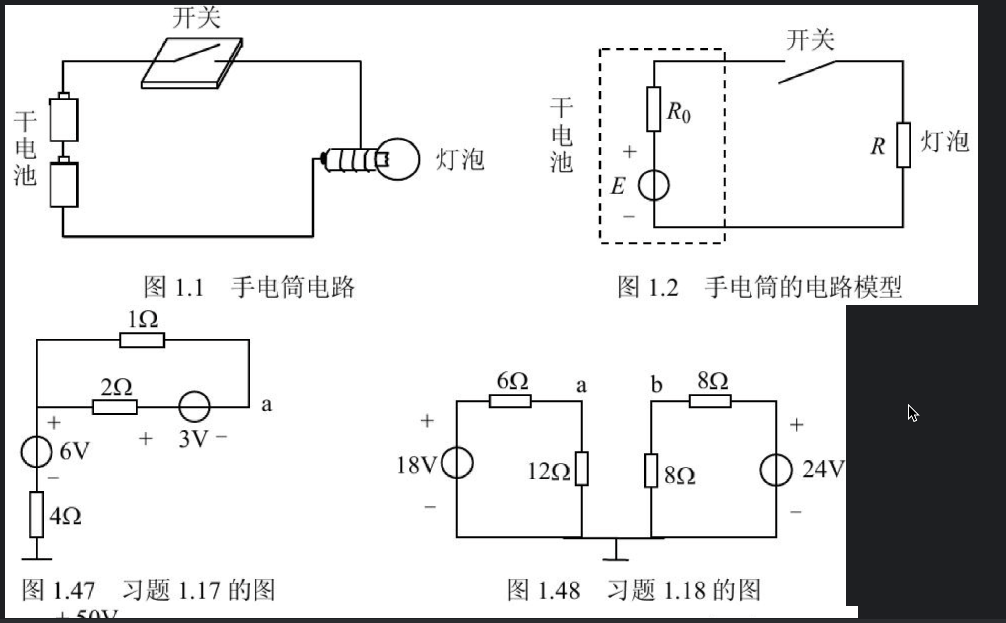
首先验证检索效果,确认向量库能否返回与查询相关的图片:
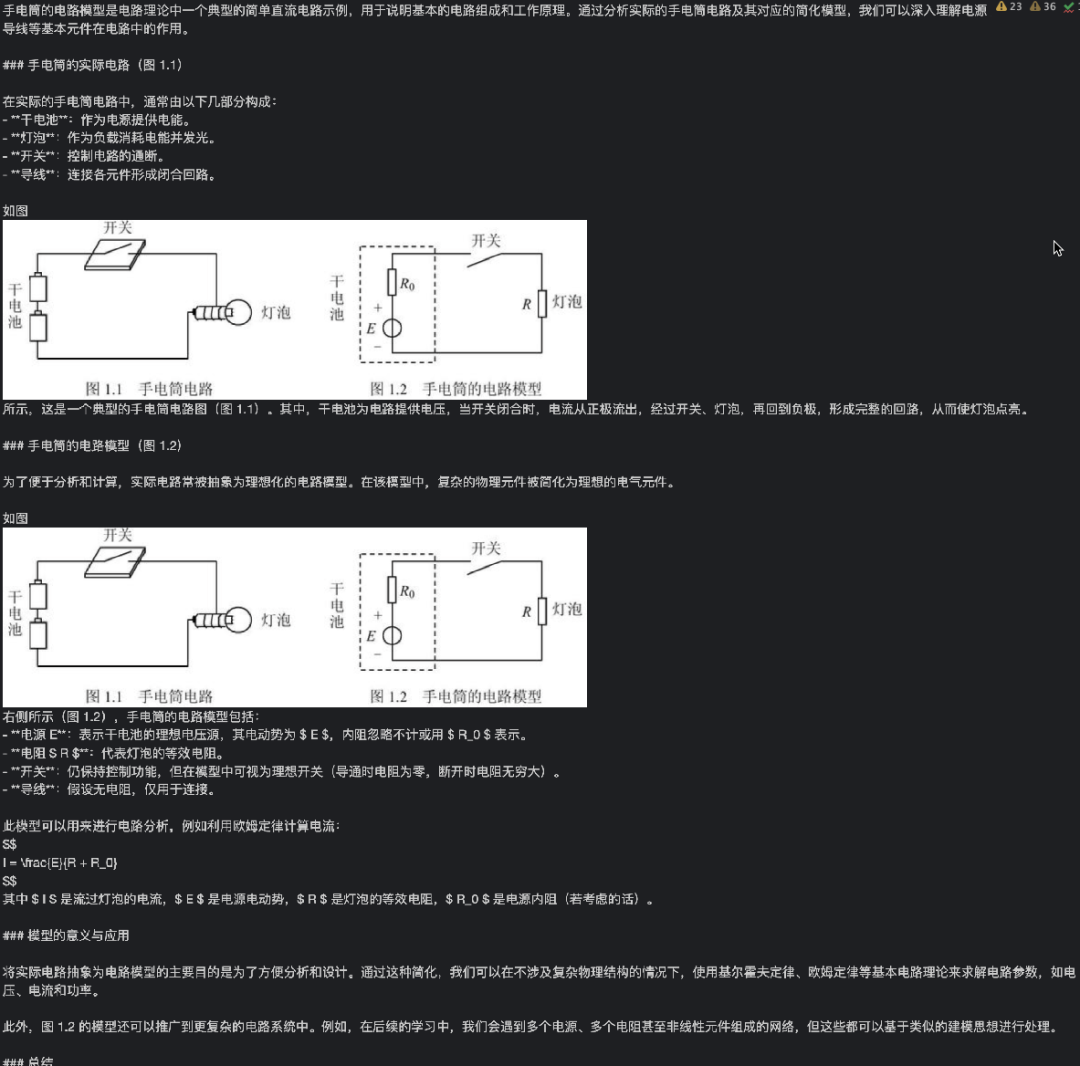
from IPython.display import HTML, display#为了便于查看,定义显示图片函数def show_plt_img(img_base64): image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />' display(HTML(image_html))query = "手电筒的电路模型"docs = retriever.invoke(query)for doc in docs: if is_base64(doc.page_content): show_plt_img(doc.page_content)
运行结果如下,可以看到相关图片被成功检索:
执行完整的问答链路:
result = chain.invoke(query)
最终生成的答案如下:
为了更友好地展示包含图片的答案,可以使用以下可视化函数:
import base64from IPython.display import HTML, displaystart_tag = "<image>"end_tag = "</image>"def encode_image(img_path): with open(img_path, "rb") as img_file: img_data = img_file.read() img_base64 = base64.b64encode(img_data).decode('utf-8') return img_base64def display_answer(text:str): # 根据<image>标签 分割文本:xxx<image>xxx</image> => ['xxx','xxx</image>'] parts = text.split(start_tag) for part in parts: # 再根据</image>标签 分割文本:xxx => ['xxx'], xxx</image> => ['xxx',''] chunks = part.split(end_tag) if len(chunks) > 1: # 存在图片 image_path = chunks[0] context = chunks[1] img_base64 = encode_image(image_path) display(HTML(f'\n<img src="data:image/jpeg;base64,{img_base64}"/>\n')) display(HTML(context.replace("\n", "<br/>"))) else: display(HTML(part.replace("\n", "<br/>"))) display_answer(result)
运行后,图文混排的答案展示效果如下:
3.3 基于多模态大模型(方案二)
承接3.1章节的数据处理结果,本节将探讨如何基于多模态大模型实现RAG。本方案的核心思路是:先用多模态大模型为图片生成文本摘要,再对摘要进行向量检索,最终将检索到的原始图片与文本一并送入多模态大模型生成答案。
3.3.1 多模态数据摘要生成
首先,使用纯文本大模型对文本和表格内容生成摘要,便于后续检索:
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_community.chat_models.tongyi import ChatTongyiprompt = PromptTemplate.from_template( "你是一位负责生成表格和文本摘要以供检索的助理。" "这些摘要将被嵌入并用于检索原始文本或表格元素。" "请提供表格或文本的简明摘要,该摘要已针对检索进行了优化。表格或文本:{document}")#使用大模型生成文本摘要model = ChatTongyi(model="qwen-max")summarize_chain = {"document": lambda x: x} | prompt | model | StrOutputParser()text_summaries = summarize_chain.batch(texts, {"max_concurrency": 5})table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
然后,使用多模态大模型对图片生成摘要:
def image_summarize(image_path): """生成图片摘要""" chat = ChatTongyi(model="qwen-vl-max") local_image_path = f"file://{image_path}" response = chat.invoke( [ HumanMessage( content=[ {"text" : "你是一名负责生成图像摘要以便检索的助理。这些摘要将被嵌入并用于检索原始图像。请生成针对检索进行了优化的简洁的图像摘要。"}, {"image": local_image_path} ] ) ] ) return response.content# 检索图片摘要获得图片地址img_list = []image_summaries = []for img_file in sorted(os.listdir(image_out_dir)): if img_file.endswith(".jpg"): img_path = os.path.join(image_out_dir, img_file) img_list.append(img_path) # 生成图片摘要 image_summaries.append(image_summarize(img_path)[0]["text"])
3.3.2 构建摘要索引
将所有摘要存入向量库,原始内容存入文档存储,实现摘要到原始内容的映射:
import uuidfrom langchain.retrievers.multi_vector import MultiVectorRetrieverfrom langchain.storage import InMemoryStorefrom langchain_chroma import Chromafrom langchain_core.documents import Documentfrom langchain_community.embeddings.dashscope import DashScopeEmbeddingsembeddings_model = DashScopeEmbeddings( model="text-embedding-v1",)# 创建向量数据库(用于存储摘要)vectorstore = Chroma( collection_name="multi_model", embedding_function=embeddings_model)# 创建内存存储(用于存储原内容)docstore = InMemoryStore()# 将摘要存储入库id_key = "doc_id"def add_documents( doc_summaries, doc_contents): doc_ids = [str(uuid.uuid4()) for _ in doc_contents] summary_docs = [ Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(doc_summaries) ] vectorstore.add_documents(summary_docs) docstore.mset(list(zip(doc_ids, doc_contents)))add_documents(text_summaries, texts)add_documents(table_summaries, tables)add_documents(image_summaries, img_list)# 构建多向量检索(摘要索引)retriever = MultiVectorRetriever( vectorstore=vectorstore, docstore=docstore, id_key=id_key, search_kwargs={"k": 7})
3.3.3 RAG链路构建
构建好摘要索引后,接下来就该构建RAG系统了。首先定义检索结果的拆分与处理逻辑,代码如下:
from pathlib import Pathfrom PIL import Imageimport shutilimport ossave_path = resource_path+"/temp/"if os.path.exists(save_path): shutil.rmtree(save_path)os.makedirs(save_path)''' 判断是否为图片地址 '''def is_image_path(filepath): try: path = Path(filepath) return all([ path.exists(), path.is_file(), path.suffix.lower() == '.jpg' ]) except Exception: returnFalse def resize_base64_image4tongyi(image_path, max_size=(640, 480)): try: # 打开图片 img = Image.open(image_path) width, height = img.size ratio = min(max_size[0] / width, max_size[1] / height) # 计算按比例缩放后的宽高 new_width = int(width * ratio) new_height = int(height * ratio) # 缩放 resized_img = img.resize((new_width, new_height), Image.LANCZOS) # 保存图片到指定路径 out_path = save_path + str(uuid.uuid4()) + ".jpg" resized_img.save(out_path) # 图片地址 return out_path except Exception as e: print(f"处理图片时出错: {e}") returnNonedef split_image_text_types(docs): """ 拆分图像和文本 """ images = [] texts = [] # docs:文本内容和图片地址 for doc in docs: if is_image_path(doc): doc = resize_base64_image4tongyi(doc) images.append(doc) else: texts.append(doc) return {"images": images, "texts": texts}
然后构建完整的RAG链路,代码如下:
from langchain_core.runnables import RunnableLambda, RunnablePassthroughfrom langchain_core.output_parsers import StrOutputParserfrom langchain_community.chat_models.tongyi import ChatTongyidef img_prompt_func(data_dict): # 提取图片与文本 images = data_dict["context"]["images"] texts = data_dict["context"]["texts"] messages = [] # 装载图片数据 for image in images: messages.append( HumanMessage( content=[ {"text":f"请将图片标记标注为:`{image}`"}, {"image":f"file://{image}"} ] ) ) # 装载文本数据 formatted_texts = "\n\n".join(texts) messages.append( HumanMessage(content=[ { "text": "你是作为一名专业的电气工程师和电路理论专家。你的任务是用中文回答与电路基本概念和定律相关的问题。" "你将获得相关的图片与文本作为参考的上下文。这些图片和文本都是根据用户输入的关键词从向量数据库中检索获取的。" "请根据提供的图片和文本结合你丰富的知识与分析能力,提供一份全面的问题解答。" "请将提供的图片标记自然融入答案阐述的对应位置进行合理排版,答案中提及的图片统一以`<image>传递的图片真实标记</image>`的形式呈现。\n\n" f"用户的问题是:{data_dict['question']}\n\n" "参考的文本或者表格数据:\n" f"{formatted_texts}" } ] ) ) return messages# 千问视觉模型(多模态)llm = ChatTongyi(model="qwen-vl-max")# RAG pipelinechain = ( { "question": RunnablePassthrough(), "context": retriever | RunnableLambda(split_image_text_types) } | RunnableLambda(prompt_func) | llm | StrOutputParser())
3.3.4 效果验证
首先验证图片检索效果,代码如下:
from IPython.display import HTML, display#显示图片def show_plt_img(img_base64): image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />' display(HTML(image_html))def encode_image(img_path): with open(img_path, "rb") as img_file: img_data = img_file.read() img_base64 = base64.b64encode(img_data).decode('utf-8') return img_base64 query = "介绍下手电筒的电路模型"# query = "导体中的电流方向是什么"docs = retriever.invoke(query)# 注意:这里检索出来的是图片地址或文本内容,而不是Documentfor doc in docs: if is_image_path(doc): show_plt_img(encode_image(doc))
运行结果表明相关图片被成功检索:
执行完整问答链路,生成最终答案:
result = chain.invoke(query)
可视化结果查看:
import base64from IPython.display import HTML, displaystart_tag = "<image>"end_tag = "</image>"def display_answer(text:str): # 根据<image>标签 分割文本:xxx<image>xxx</image> => ['xxx','xxx</image>'] parts = text.split(start_tag) for part in parts: # 再根据</image>标签 分割文本:xxx => ['xxx'], xxx</image> => ['xxx',''] chunks = part.split(end_tag) if len(chunks) > 1: # 存在图片 image_path = chunks[0] context = chunks[1] img_base64 = encode_image(image_path) display(HTML(f'\n<img src="data:image/jpeg;base64,{img_base64}"/>\n')) display(HTML(context.replace("\n", "<br/>"))) else: display(HTML(part.replace("\n", "<br/>"))) display_answer(result)

3.4 基于多模态大模型优化
前两种方案各有利弊,但在某些场景下存在明显短板:
- 基于多模态向量模型:当图片仅起辅助展示作用,或需要结合文字才能理解时,多模态向量模型难以提取有效的语义特征,检索准确率受限。
- 基于多模态大模型:图片摘要的质量直接影响检索效果,若摘要生成不准确,检索精度同样难以保证。此外,全程调用多模态大模型成本较高。
针对上述问题,业界演进出了多模态大模型优化方案,在检索准确性和成本之间寻求更优平衡。其核心思路是:利用多模态大模型为图片生成摘要,然后将这些摘要融合到文档的对应位置(而非独立存储),最终答案由成本更低的纯文本大模型生成。这样做的好处是:
- 图片摘要作为文档的有机组成部分参与检索,保留了图文之间的上下文关联
- 答案生成阶段使用纯文本模型,显著降低推理成本
实现要点:
- 解析PDF文档时,通过
metadata.orig_elements获取当前元素由哪些子元素合并而成(记录了原始元素的组合关系) - 对文本数据建立摘要索引,对图片仅生成摘要,但不独立建索引;而是将图片摘要融合到图片所在位置的文本中,格式为:
[文本][<image src="图片地址">图片摘要</image>] - 使用纯文本大模型生成答案,在提示词中要求模型在答案中包含相关图片的引用标签:
<image src="图片地址"></image>
3.4.1 文本加载
数据加载逻辑与前文基本一致,重点在于利用 orig_elements 获取文档的细粒度结构信息:
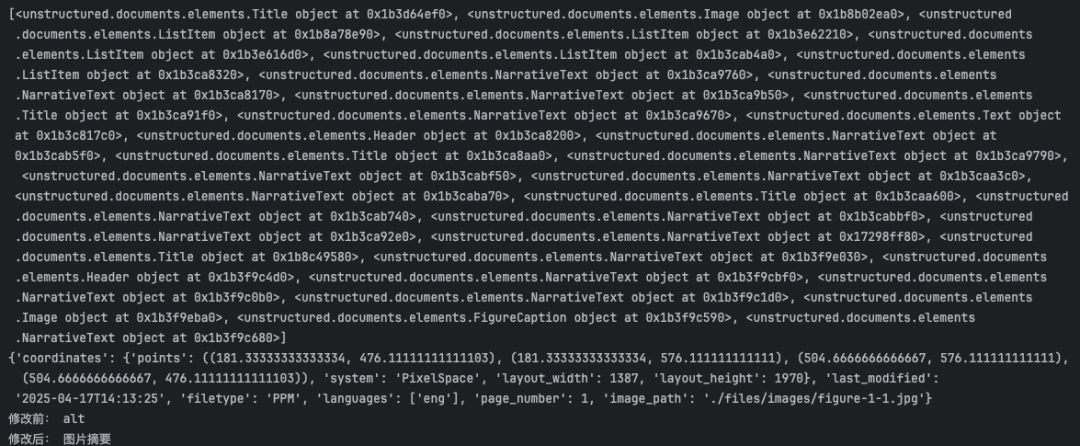
from unstructured.partition.pdf import partition_pdffrom dotenv import load_dotenvimport osimport shutil_ = load_dotenv()# 工作目录路径resource_path = "./files/"# 图片提取存放路径image_out_dir = resource_path + "images/"# pdf文件路径pdf_path = resource_path + ("source.pdf")# 如果图片提取目录存在则删除重建if os.path.exists(image_out_dir): shutil.rmtree(image_out_dir)os.makedirs(image_out_dir)# 使用unstructured库解析PDF文档(需要科学上网) pdf_data = partition_pdf( filename=pdf_path, extract_images_in_pdf=True, infer_table_structure=True, # 启用表格结构识别 max_characters=4000, # 每个文本块最大字符数 new_after_n_chars=3800, # 达到3800字符后分新块 combine_text_under_n_chars=2000, # 合并小于2000字符的文本块 chunking_strategy = "by_title", # 按标题分块 extract_image_block_output_dir=image_out_dir, #图片提取路径)'''合并后的元素类型:Table,CompositeElement'''# 哪些元素合并成当前元素print(pdf_data[0].metadata.orig_elements)# Image元素image = pdf_data[0].metadata.orig_elements[1]print(image.metadata.to_dict())# 提取的图片元素会进行OCR识别,所以text属性会包含图片的文字信息print("修改前:",image.text)# 不需要ocr的识别结果,在后面生成图片摘要时,会通过多模态大模型生成图片摘要,记录在text属性中image.text = "图片摘要"print("修改后:",image.text)
运行结果如下:
3.4.2 摘要生成
对文本元素生成摘要:
from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_community.chat_models.tongyi import ChatTongyiprompt = PromptTemplate.from_template( "你是一位负责生成表格和文本摘要以供检索的助理。" "这些摘要将被嵌入并用于检索原始文本或表格元素。" "请提供表格或文本的简明摘要,该摘要已针对检索进行了优化。表格或文本:{document}")#使用大模型生成文本摘要model = ChatTongyi(model="qwen-max")summarize_chain = {"document": lambda x: x.text} | prompt | model | StrOutputParser()summaries = summarize_chain.batch(pdf_data, {"max_concurrency": 5})
对图片元素生成摘要,并将摘要回填至图片元素的 text 属性:
from unstructured.documents.elements import Image as ImageElementfrom langchain_core.messages import HumanMessagefrom langchain_community.chat_models.tongyi import ChatTongyidef image_summarize(image_path): """生成图片摘要""" chat = ChatTongyi(model="qwen-vl-max") local_image_path = f"file://{image_path}" response = chat.invoke( [ HumanMessage( content=[ {"text" : "你是一名负责生成图像摘要以便检索的助理。这些摘要将被嵌入并用于检索原始图像。请生成针对检索进行了优化的简洁的图像摘要。"}, {"image": local_image_path} ] ) ] ) return response.contentimage_summaries = []image_list = []for element in pdf_data: orig_elements = element.metadata.orig_elements length = len(orig_elements) for i, orig_element in enumerate(orig_elements): # 图片元素 if isinstance(orig_element, ImageElement): image_path = orig_element.metadata.to_dict()["image_path"] image_list.append(orig_element) # 将图片摘要记录在图片元素的text属性中 summarizes = image_summarize(image_path)[0]["text"] orig_element.text = summarizes image_summaries.append(summarizes)
3.4.3 构建索引
将包含图片摘要的完整文档元素建立索引:
import uuidfrom langchain.retrievers.multi_vector import MultiVectorRetrieverfrom langchain.storage import InMemoryStorefrom langchain_chroma import Chromafrom langchain_core.documents import Documentfrom langchain_community.embeddings.dashscope import DashScopeEmbeddingsembeddings_model = DashScopeEmbeddings( model="text-embedding-v1",)# 创建向量数据库(用于存储摘要)vectorstore = Chroma( collection_name="multi_model_optxx", embedding_function=embeddings_model)# 创建内存存储(用于存储原内容)docstore = InMemoryStore()# 将摘要存储入库id_key = "doc_id"def add_documents( doc_summaries, doc_contents): doc_ids = [str(uuid.uuid4()) for _ in doc_contents] summary_docs = [ Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(doc_summaries) ] vectorstore.add_documents(summary_docs) docstore.mset(list(zip(doc_ids, doc_contents)))# 不再单独放入图片摘要add_documents(summaries, pdf_data) #PDF Element# 构建多向量检索(摘要索引)retriever = MultiVectorRetriever( vectorstore=vectorstore, docstore=docstore, id_key=id_key, search_kwargs={"k": 5})
3.4.4 RAG链路构建
构建最终的问答链路,使用纯文本大模型生成答案:
from langchain_core.runnables import RunnableLambda, RunnablePassthroughfrom langchain_core.output_parsers import StrOutputParserfrom langchain_community.chat_models.tongyi import ChatTongyifrom unstructured.documents.elements import Image as ImageElementdef split_image_text_types(docs): texts = [] # 注意:doc为PDF Element for doc in docs: text = '' # 获得所有子元素 orig_element = doc.metadata.orig_elements for element in orig_element: # 是否为图片元素 if isinstance(element, ImageElement): # 图片元素用标记包裹 print("文档上下文中图片:",element.metadata.image_path) text += f'<image src="{element.metadata.image_path}">{element.text}</image>' else: # 其他元素直接放入文本 text += element.text texts.append(text) return textsdef prompt_func(data_dict): question = data_dict["question"] context = data_dict["context"] # 装载数据 formatted_texts = "\n\n".join(context) prompt = ("你是作为一名专业的电气工程师和电路理论专家。你的任务是用中文回答与电路基本概念和定律相关的问题。" "你将获得相关文档作为参考的上下文。这些文档都是根据用户输入的关键词从向量数据库中检索获取的。" "请根据提供的文档结合你丰富的知识与分析能力,提供一份全面的问题解答。" "请将提供的文档中的图片`<image src='...'></image>`(不包括图片标签包围的文字),自然融入答案阐述的对应位置进行合理排版。\n\n" f"用户的问题是:{question}\n\n" "参考的文本或者表格数据:\n" f"{formatted_texts}") print("完整提示词:\n",prompt) return prompt# 文本通用大模型llm = ChatTongyi(model="qwen-max")# RAG pipelinechain = ( { "question": RunnablePassthrough(), # retriever:检索器搜索的结果为:PDF Element "context": retriever | RunnableLambda(split_image_text_types) } | RunnableLambda(prompt_func) | llm | StrOutputParser())
3.4.5 效果展示
执行问答,得到相关结果:
result = chain.invoke("介绍下电路模型")result
结果如下:

可视化展示:
import base64from IPython.display import HTML, displayimport restart_tag = "<image "middle_tag = "src="end_tag = "</image>"def encode_image(img_path): with open(img_path, "rb") as img_file: img_data = img_file.read() img_base64 = base64.b64encode(img_data).decode('utf-8') return img_base64def display_answer(text:str): # 正则表达式:用于匹配 <image src="xxx"> 并捕获 src 属性的值 pattern = r'(<image src="([^"]*)">)' # abc<image src="xxx">def -》 ["abc", "<image src="xxx">", "xxx", "def"] chunks = re.split(pattern, text) for i, chunk in enumerate(chunks): # 文本内容 if i % 3 == 0: display(HTML(chunk.replace("\n", "<br/>").replace("</image>", ""))) elif i % 3 == 2: # image_path = re.search(r'src="([^"]*)"', chunk).group(1) 1% 3==1 img_base64 = encode_image(chunk) display(HTML(f'\n<img src="data:image/jpeg;base64,{img_base64}"/>\n')) display_answer(result)
最终展示效果:

四、总结
本文系统介绍了多模态RAG的三种主流工程化实现方案:基于多模态向量模型的方案成本低、检索速度快,适合图片语义独立明确的场景;基于多模态大模型的方案理解能力强但成本较高,适用于对答案质量有极致要求的场景;基于多模态大模型优化的方案通过图片摘要融合与纯文本大模型生成,在效果与成本之间取得了较好平衡,适合大多数生产环境。三种方案各有优劣,实际应用中应根据数据特点(图片是否需要上下文辅助理解)、业务对准确性的要求以及成本预算进行综合选型,希望本文能为读者在多模态RAG的工程化实践中提供有价值的参考。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
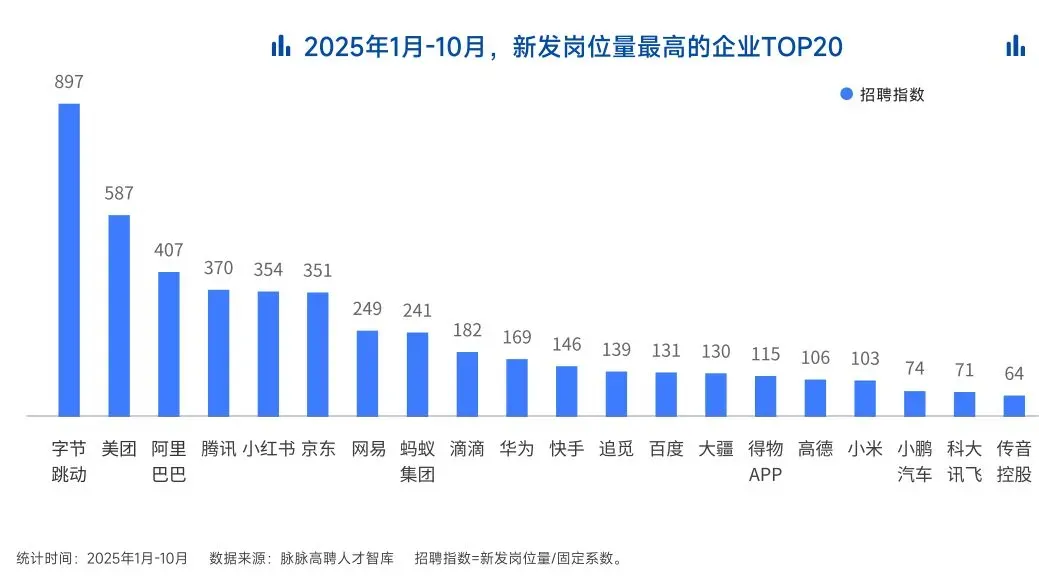
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)