大模型API连续对话交互:上下文持久化、会话状态管理与轻量化Token节流实践.159
一、引言
在大模型应用实际落地场景中,单次独立问答已经无法满足实际业务需求。无论是办公协同智能体、行业咨询机器人、专属业务问答系统,还是私有化部署的大模型应用,都需要支撑连续多轮对话、跨会话二次访问、长周期上下文关联问答等核心能力。
在实际对话应用时,都会遇到共性问题:第一轮提问正常回复,第二轮提问无法关联上一轮对话内容;长时间多轮对话后请求Token暴增、接口响应变慢、调用成本大幅上升;不同用户、不同会话之间上下文混乱,出现状态串扰;会话无状态隔离,无法实现会话过期、重置、封存、恢复等基础运维能力。
造成这些问题的核心根源,在于缺少一套标准化、精细化的智能体状态管理体系。大模型本身无记忆能力,天然属于无状态服务,所有的上下文关联、对话记忆、用户会话状态,都需要业务层手动进行存储、裁剪、拼接、分发与销毁。 查了很多资料说的头头是道,但实际操作真的很困难,确实是实践是检验真理的唯一标准,今天结合实际实现一个最能实现、最简单的办法,后续在基于此逐步迭代升级。

二、基础概念
1. 大模型无状态运行底层逻辑
主流大模型包括开源模型与闭源API模型,统一遵循无状态设计范式。模型本身不会主动存储任意用户的对话记录、交互行为、临时参数与业务状态,每一次接口请求都是独立的隔离请求。
模型的回复结果,完全依赖当前请求传入的Prompt内容,包括系统提示词、用户历史问答上下文、当前问题、限定规则等全部文本信息。如果两次独立请求之间,不手动拼接历史对话内容,模型无法识别两次提问的关联关系,自然无法实现上下文连贯回复。
这种无状态设计是大模型服务的优势,也是开发难点:
- 优势在于模型服务可以横向无限扩容、负载均衡、分布式部署,不存在会话绑定节点的问题;
- 劣势在于所有记忆能力、状态控制能力,必须由应用服务侧自行实现,对业务架构设计提出了明确要求。
2. 会话状态的完整组成结构
一套完整的AI智能体状态,不只是简单的历史聊天记录,而是由多维度数据共同组成的集合,也是后续状态管理的核心管控对象,主要分为四大模块:
2.1 对话上下文状态
包含系统角色设定、历史用户提问、智能体历史回复、临时对话指令、场景限定条件等文本类数据,是实现多轮关联问答的核心,这部分内容直接参与Prompt拼接,消耗Token最多,也是优化的核心目标。
2.2 会话基础属性状态
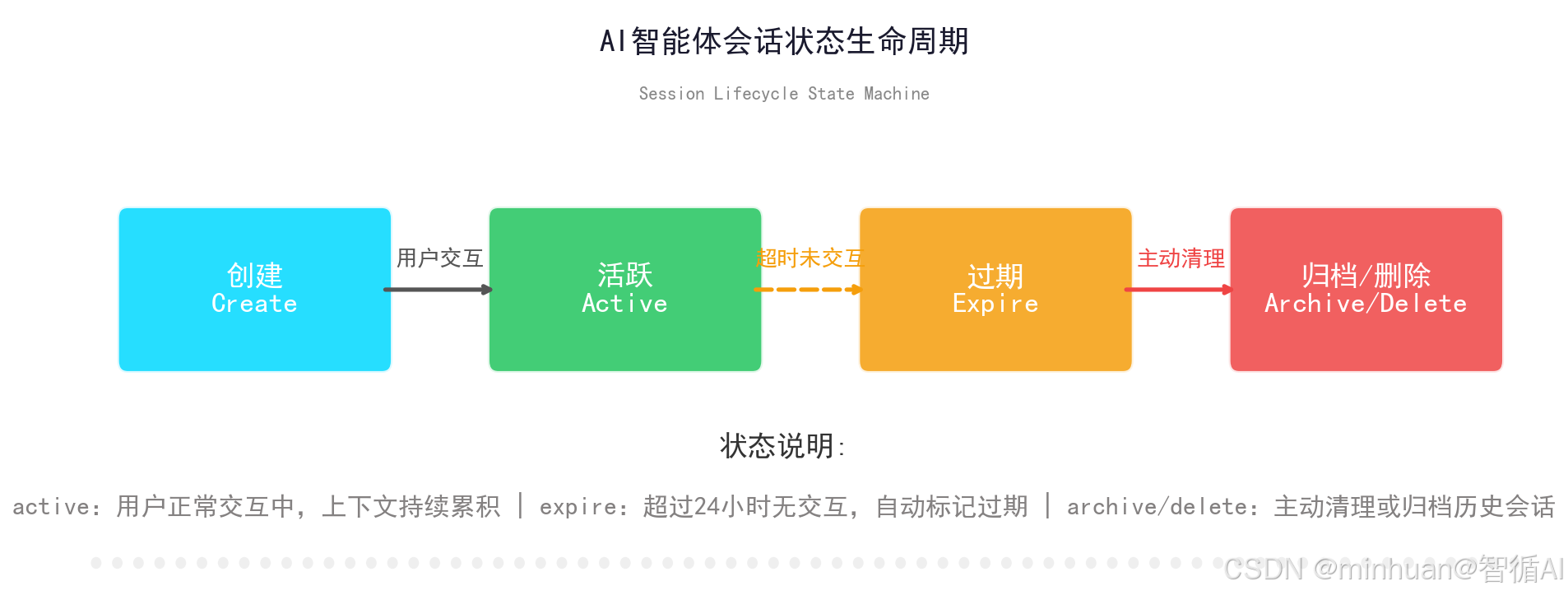
唯一会话ID、用户唯一标识、会话创建时间、最后交互时间、会话过期时长、会话状态标记,如正常、已冻结、已归档、已删除,用于区分不同用户、不同对话窗口,实现会话隔离与生命周期管控。
2.3 业务临时状态
智能体执行过程中的临时参数、工具调用记录、函数执行结果、中间计算数据、用户偏好配置、权限标签等非文本类业务数据,多用于工具型智能体、任务型智能体的连续任务执行。
2.4 全局配置状态
单会话独立的模型参数,如温度系数、最大生成长度、回复格式、知识库绑定范围、权限控制规则等,支持同一智能体不同会话差异化配置。
3. 多轮对话与多次多轮场景区别
在实际落地中,需要区分两种核心交互场景,二者的状态管理策略与Token优化方案完全不同。
3.1 单次多轮对话
- 指用户在单次打开对话窗口后,连续进行数十轮以内的连续提问,会话持续在线,无长时间中断,对话主题相对统一。
- 该场景特点是上下文短中期关联强,数据更新频繁,需要实时拼接历史内容;
- 核心诉求是保证回复连贯性。
3.2 多次多轮对话
- 指用户间隔数小时、数天甚至更久,重复进入同一个会话继续提问,或是跨设备访问同一会话,对话主题可能延伸、变更,历史上下文体量庞大。
- 该场景特点是会话生命周期长,历史数据量大,不能完整拼接全部历史内容;
- 核心诉求是状态持久化、超长上下文裁剪、历史内容摘要压缩。
充分理解两种场景的差异,才能设计出兼顾体验、性能与成本的状态管理方案,避免一刀切的上下文拼接方式导致资源浪费或对话断裂。常规开发中,我们如果仅存储用户问答文本,忽略系统提示词与配置状态的持久化,会导致会话重启后智能体角色丢失、回复风格错乱。同时,无状态模型对接时,若缺少会话唯一标识,极易出现多用户上下文交叉污染,在多租户场景中会引发严重的数据安全问题。
三、上下文关联原理
1. 上下文关联的核心原理
想要让AI智能体记住历史对话,核心操作只有一步:将历史对话结构化拼接至当前请求的Prompt中。
标准的Prompt结构分为三层固定格式:
- 第一层为固定系统提示词,定义智能体身份、能力、回复规则、约束要求;
- 第二层为结构化历史上下文数组,按时间顺序存储每一轮的用户输入与智能体输出;
- 第三层为当前最新的用户提问内容。
大模型读取完整分层 Prompt 后,结合历史交互内容理解对话语境、用户需求背景、上一轮的结论与问题,结合当前提问进行综合推理,从而输出具备上下文关联的精准回复。
在结构化数据格式上,主流模型统一采用角色区分格式,通过user、assistant、system三类角色标签区分内容归属,保证模型可以精准识别对话主体,避免上下文内容混淆。这种标准化格式也是后续状态统一管理、批量处理、压缩裁剪的基础规范。
2. 传统上下文管理基础方案
早期以及大量入门级项目中,普遍使用简易的上下文管理方式,实现门槛低,但无法适配复杂生产场景:
2.1 内存临时存储方案
- 直接使用程序运行内存中的列表、字典临时存储当前用户的历史对话,服务运行期间会话有效,服务重启、页面刷新、程序退出后,所有上下文状态全部丢失。
- 该方案仅适合本地测试、单机临时演示,完全无法用于线上生产环境。
2.2 全量拼接持久化方案
- 将每一轮对话完整拼接,以字符串形式存入文件、本地数据库,每次提问时读取全部历史内容完整拼接发送给模型。
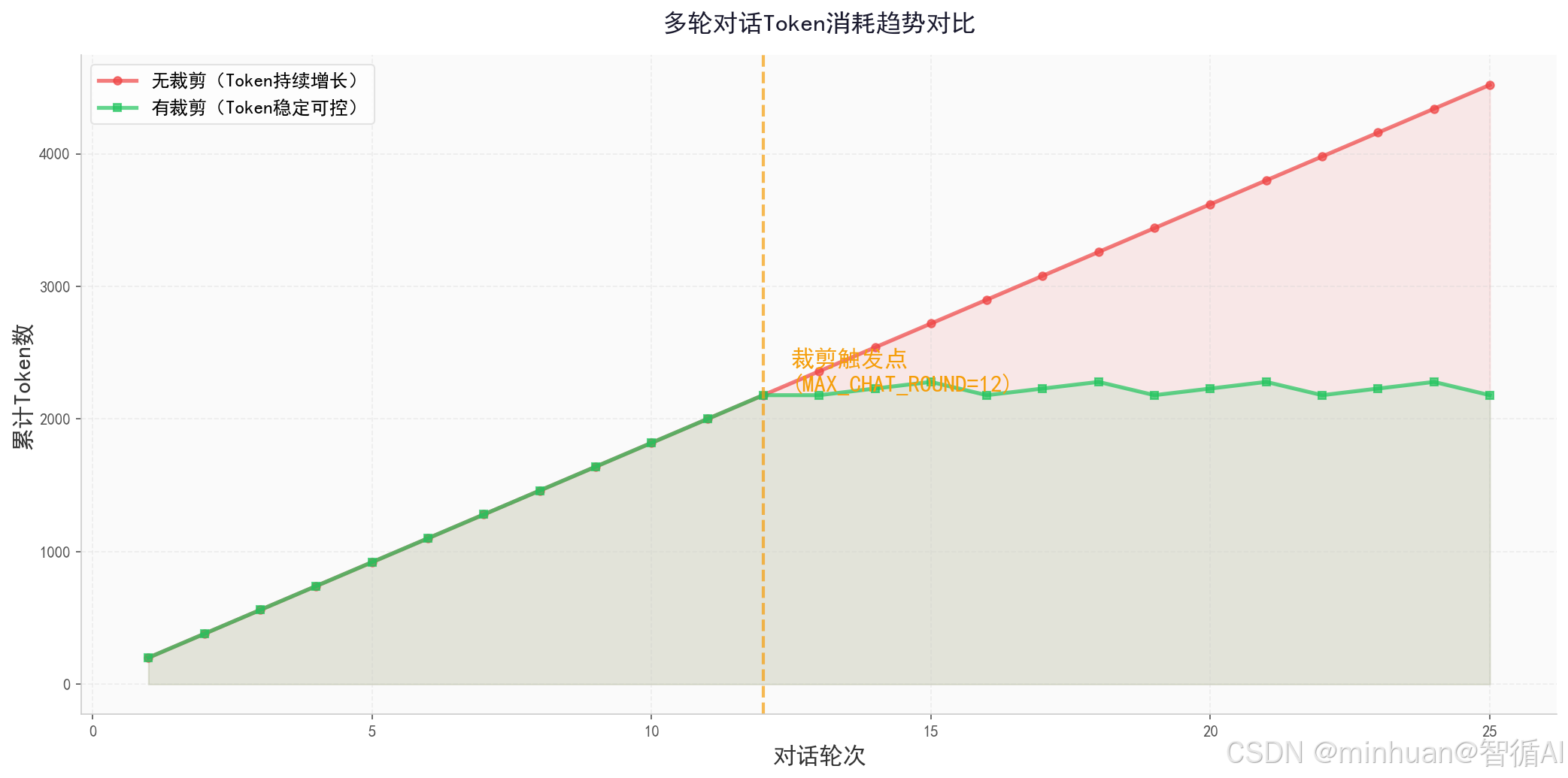
- 该方案可以实现永久会话记忆,但随着对话轮次增加,Prompt长度线性暴涨,Token消耗成倍增加。
2.3 固定轮次截断方案
- 限制最大保存对话轮数,例如只保留最近10轮问答,超出轮次自动删除最早的对话记录。
- 该方案可以简单控制Token上限,但会丢失早期关键上下文信息,长对话场景下容易出现逻辑断裂,无法满足深度连续问答需求。
3. 传统方案的核心痛点
3.1 Token消耗不可控,调用成本极高
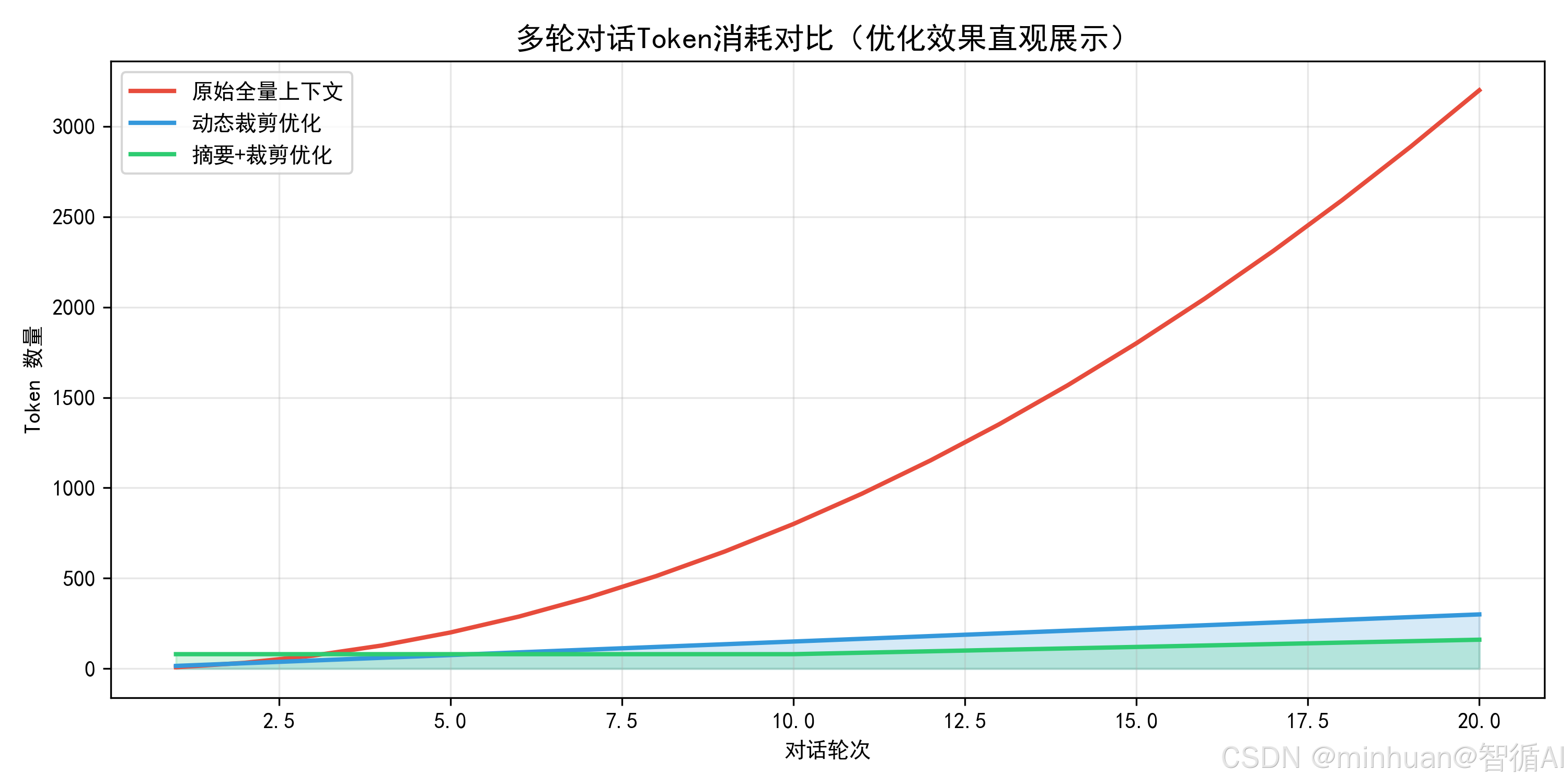
大模型接口调用费用、推理算力消耗均以Token为计量单位,全量拼接模式下,50轮以上对话的上下文Token数量会达到数千甚至上万,高频使用场景会直接拉高项目运营成本。
3.2 响应延迟持续升高
Prompt文本越长,模型预处理、语义理解、推理生成的耗时就越长,长上下文会直接导致对话响应变慢,用户交互体验大幅下降。
3.3 状态管理混乱,无生命周期管控
简易方案缺少会话过期、闲置回收、无效数据清理机制,长期运行会产生大量冗余垃圾数据,占用存储资源。
3.4 容错性差,异常场景无法适配
遇到超长文本提问、批量指令交互、跨天接续对话等场景,传统方案直接失效,无法灵活适配业务变化。
3.5 无结构化治理,难以二次开发
纯字符串存储的上下文无法实现精准裁剪、摘要压缩、关键词提取、权限隔离,后续叠加工具调用、知识库检索等拓展功能时会产生严重架构冲突。
Token的消耗分为输入Token与输出Token,上下文全部计入输入Token。通常中文文本1个汉字约对应1.3个Token,英文单词约1个单词对应1个Token,长对话场景下,无效历史内容的冗余占比会超过40%。传统方案未做内容过滤与精简,大量重复语句、无效客套内容、无关描述持续占用上下文空间,是资源浪费的主要原因。
四、状态管理设计方案
1. 整体架构分层设计
本次落地方案采用四层分层架构,职责拆分清晰,耦合度低,便于后续迭代拓展、功能新增与分布式部署,完全适配单次多轮、多次多轮全部场景。
1.1 第一层:接入层
负责接收用户提问、会话ID校验、用户身份鉴权、请求参数校验,拦截非法请求与异常参数,保证上层服务稳定性。
1.2 第二层:状态管理层
整个方案的核心核心模块,包含会话CRUD管理、上下文读写、状态更新标记、过期检测、数据封存恢复、多租户隔离等核心能力。
1.3 第三层:上下文优化层
专注Token俭省优化,包含轮次动态截断、关键信息摘要、无效内容过滤、短文本压缩、上下文权重分级等优化策略。
1.4 第四层:模型交互层
拼接优化后的精简Prompt,调用大模型接口,接收模型回复,完成新一轮对话内容的结构化存储与状态更新,形成闭环。
四层架构相互独立,任意模块可以单独升级改造,例如后期更换数据库、更换大模型、新增 RAG 知识库联动、新增工具调用能力,都不会破坏整体状态管理逻辑。
2. 会话状态全生命周期管理规则
针对会话从创建到销毁的完整流程,制定标准化管控规则,覆盖多次多轮长周期会话场景。
2.1 会话创建
用户发起首次提问时,自动生成全局唯一UUID作为会话ID,绑定用户ID、创建时间、初始系统提示词,初始化空上下文列表,写入持久化存储。
2.2 状态实时更新
每完成一轮问答,自动追加结构化对话数据,更新最后交互时间、会话更新版本号,实时同步存储。
2.3 闲置过期管控
配置全局闲置过期时间,例如24小时无交互自动标记为过期,7天过期会话自动压缩摘要,30天长期闲置会话自动归档封存,减少热数据存储压力。
2.4 会话操作能力
支持手动重置上下文、清空历史、锁定会话、归档会话、恢复历史归档会话、复制会话上下文等运维与用户侧操作。
2.5 数据销毁机制
提供主动删除与定时清理双机制,用户主动删除会话立即清理数据;超期归档数据定期批量清理,合规释放存储资源。
3. 结构化上下文存储设计
摒弃传统纯字符串存储模式,采用JSON结构化数组存储每一轮对话,每条对话单元固定字段:角色类型、内容文本、创建时间、关键词标签、是否核心内容标记。
结构化存储的优势极强:
- 可以精准按轮次删除、按时间筛选、标记关键对话、批量过滤无效内容、单独提取核心问题与结论,为后续精细化Token优化提供数据基础。
同时区分冷热数据存储:
- 近期活跃会话的完整上下文存入高性能数据库,保证读写速度;
- 过期归档会话仅存储摘要内容,原始完整上下文转入低成本冷存储,平衡性能与存储成本。
4. 多场景差异化状态适配策略
针对单次多轮与多次多轮两大场景,配置差异化的上下文加载与拼接策略。
4.1 单次短周期多轮
优先加载完整近期上下文,保证对话连贯性,采用轻量截断策略,仅过滤重复内容与无效语句,最大程度保留对话细节。
4.2 多次跨时长多轮
禁止加载全部历史内容,采用“核心摘要 + 近期少量轮次”组合模式,用历史摘要替代早期海量对话,既保留长期对话核心信息,又大幅压缩上下文Token数量。
5. 核心注意事项
- 会话ID采用UUID生成规则,避免自增ID带来的安全风险与多服务部署冲突;
- 状态更新采用增量写入模式,每次仅新增单轮对话数据,不覆盖全量内容,减少数据库写入压力。
- 增加版本号机制,避免并发提问导致的上下文数据覆盖错乱,适配高并发线上业务场景。
五、Token 优化核心策略
1. 基础过滤:无效内容精简优化
对话过程中会产生大量无意义冗余内容,是Token浪费的主要来源,通过规则化过滤可以快速实现基础节流:
- 首先过滤智能体回复中的客套话术、无意义修饰词、重复解释、多余换行空格、冗余标点符号,在不影响核心语义的前提下精简文本长度。
- 其次过滤用户输入中的重复提问、无关情绪表述、无效指令内容,只保留核心业务问题。
- 同时统一格式规范,压缩系统提示词冗余描述,精简角色定义话术,保留核心约束规则,删除情绪化、描述性过长的提示内容。
该类优化无任何体验损耗,优化比例可达15%-25%,是性价比最高的优化手段。
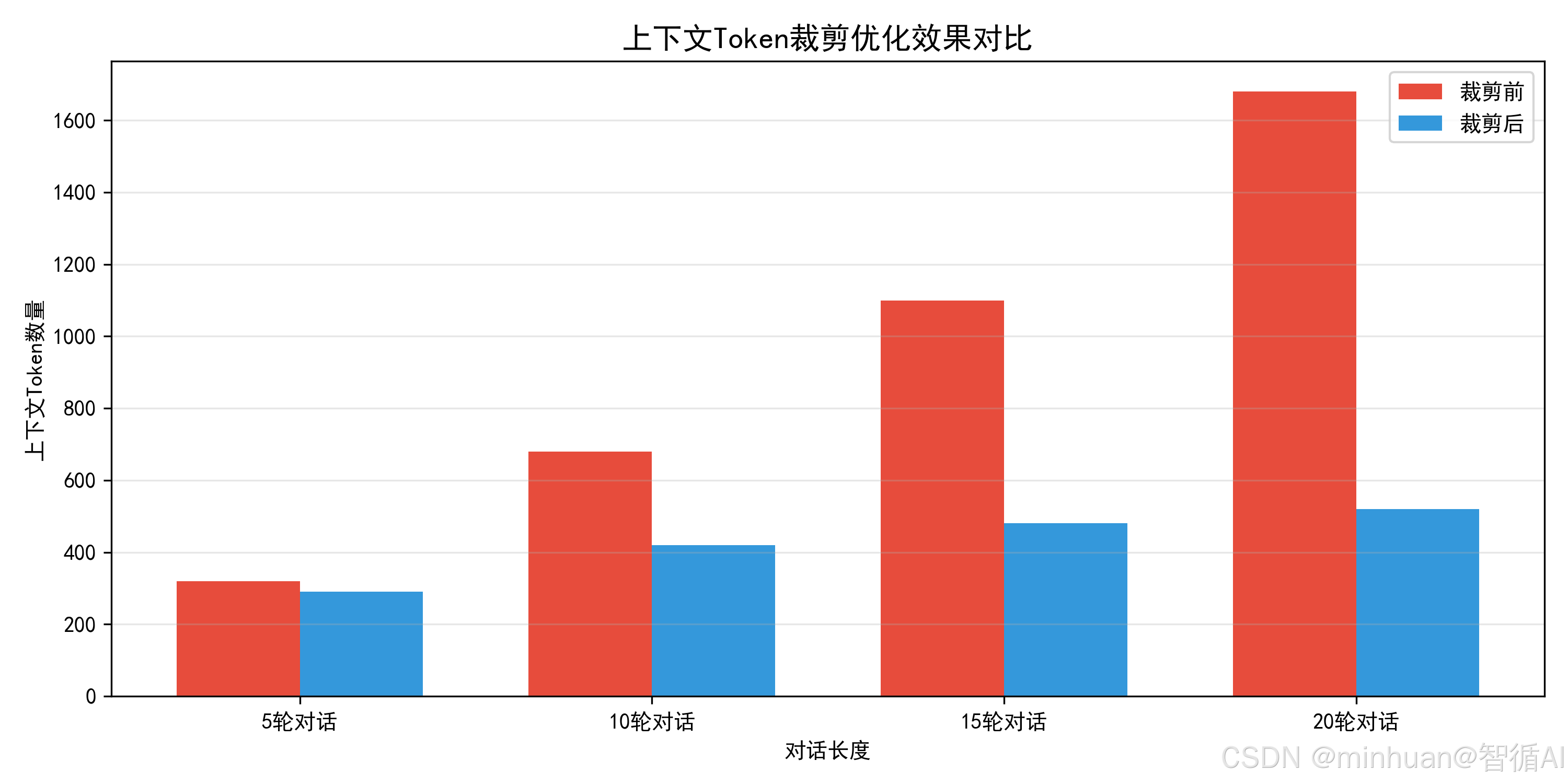
2. 动态轮次截断 + 权重分级机制
摒弃固定轮次截断的死板模式,采用动态自适应截断。根据当前模型最大上下文限制、实时Token占用数量,动态调整保留轮次。
同时引入上下文权重分级,将对话内容分为核心级、普通级、次要级:
- 业务核心问题、关键结论、限定条件标记为核心级优先保留;
- 常规问答内容为普通级;
- 闲聊、辅助解释内容为次要级。
当上下文超出阈值时,优先删减次要级内容,再压缩普通级内容,最后保留全部核心级内容。既控制整体Token上限,又保障关键信息不丢失,解决固定截断导致的逻辑断裂问题。
3. 长上下文摘要压缩技术
针对多次多轮超长会话,引入摘要压缩策略:
- 对超过20轮以上的早期历史对话,调用轻量大模型或本地小模型,将数十轮对话浓缩为百字以内的核心摘要,替代原始海量对话内容。
- 摘要内容会记录对话主题、核心诉求、关键结论、约定规则等核心信息,后续对话拼接时,使用摘要 + 最近5-10轮完整对话的组合形式。
该方案可以将上万Token的历史内容压缩至数百Token,压缩比例超过80%,是长周期会话优化的核心手段。
4. 局部缓存与复用优化
- 对于固定不变的内容,实现全局缓存复用,避免重复占用Token。固定系统提示词、通用规则、角色描述全局缓存,每次拼接直接读取缓存内容,不重复生成与解析。
- 对于高频重复的用户提问、通用业务问题回复,建立向量缓存库,命中缓存后直接返回结果,无需带入完整上下文调用大模型,双重降低 Token 消耗与接口请求量。
5. 细节说明
- 不同模型的上下文窗口大小差异极大,主流开源模型上下文窗口从4K、8K到32K不等,优化策略需要动态适配窗口上限。
- 输入Token的压缩不仅可以降低成本,还能有效避免超长Prompt 触发模型截断报错、接口请求失败等线上异常,提升系统稳定性。
六、应用实践
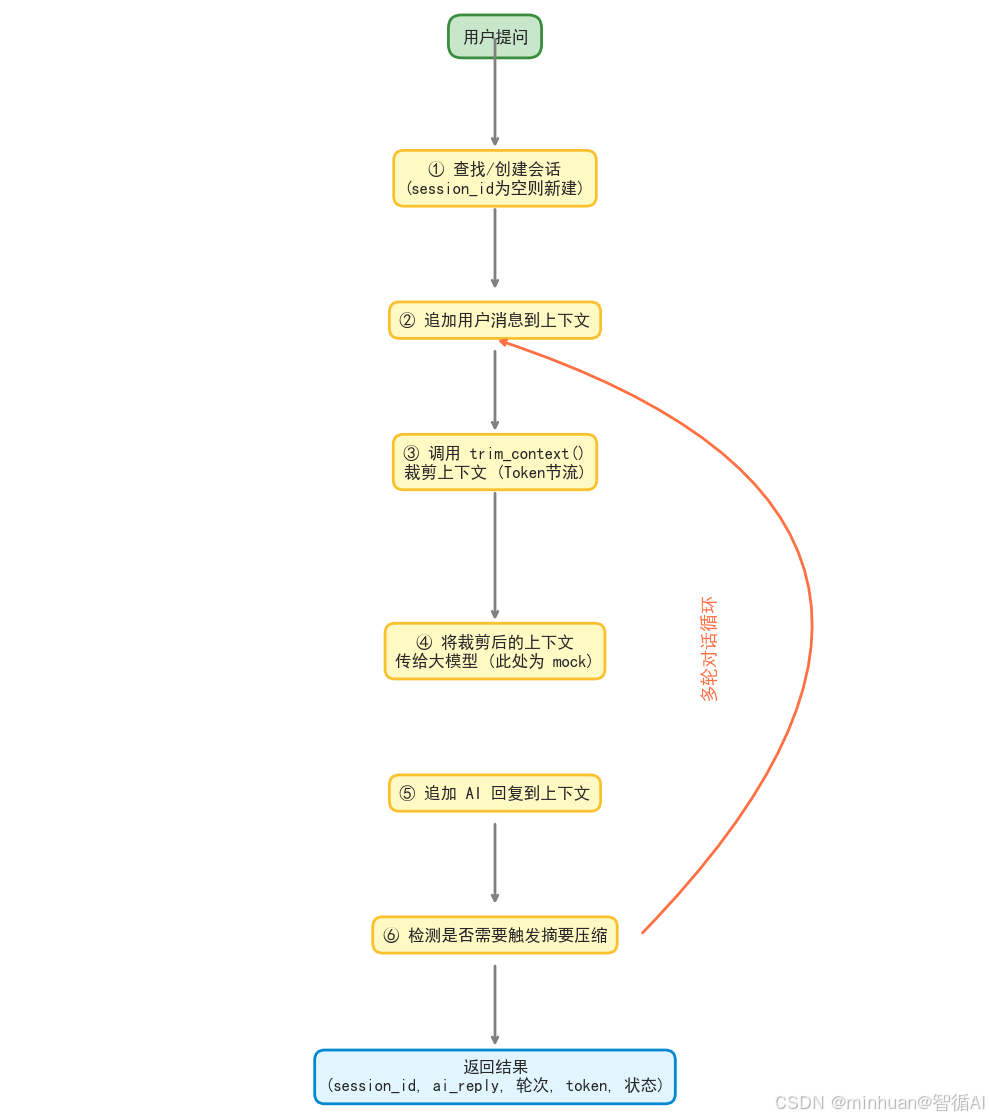
这个示例摘取了应用中实现的AI智能体的会话状态管理完整流程,解决的核心问题是:多轮对话中如何管理上下文、控制Token成本、处理会话生命周期。
应用实践的核心设计思想:
- 上下文滑动窗口:防止长对话导致Token爆炸
- 会话四态管理:规范会话生命周期,支持自动过期清理
- 摘要触发机制:超长对话用摘要替代原文,兼顾连贯性和成本
应用执行的核心流程:
import uuid
import time
import json
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyBboxPatch, Circle, FancyArrowPatch
from typing import List, Dict, Optional
# ===================== 全局配置项 可自定义修改 =====================
# 单会话最大保留完整轮次
MAX_CHAT_ROUND = 12
# 闲置过期时间 单位秒 24小时
EXPIRE_SECONDS = 24 * 60 * 60
# 摘要触发轮次 超出后压缩历史内容
SUMMARY_TRIGGER_ROUND = 20
# 基础系统提示词
BASE_SYSTEM_PROMPT = "你是专业的智能业务助手,回复精准简洁,结合上下文连贯回答用户问题。"
# 简单Token估算系数 中文通用系数
TOKEN_RATE = 1.3
# ===================================================================
class ChatSession:
"""单会话对象 管理独立会话状态与上下文"""
def __init__(self, user_id: str):
self.session_id = str(uuid.uuid4()) # 唯一会话ID
self.user_id = user_id
self.create_time = time.time()
self.last_interact_time = time.time()
self.status = "active" # active/expire/archive/delete
# 结构化上下文: list[dict] role:system/user/assistant
self.context: List[Dict[str, str]] = [
{"role": "system", "content": BASE_SYSTEM_PROMPT}
]
self.chat_round = 0 # 当前对话轮次
def update_interact_time(self):
"""更新最后交互时间"""
self.last_interact_time = time.time()
def add_chat_content(self, role: str, content: str):
"""新增单轮对话内容"""
self.context.append({
"role": role,
"content": content.strip()
})
if role == "assistant":
self.chat_round += 1
self.update_interact_time()
def is_expire(self) -> bool:
"""判断会话是否过期"""
now = time.time()
return now - self.last_interact_time > EXPIRE_SECONDS
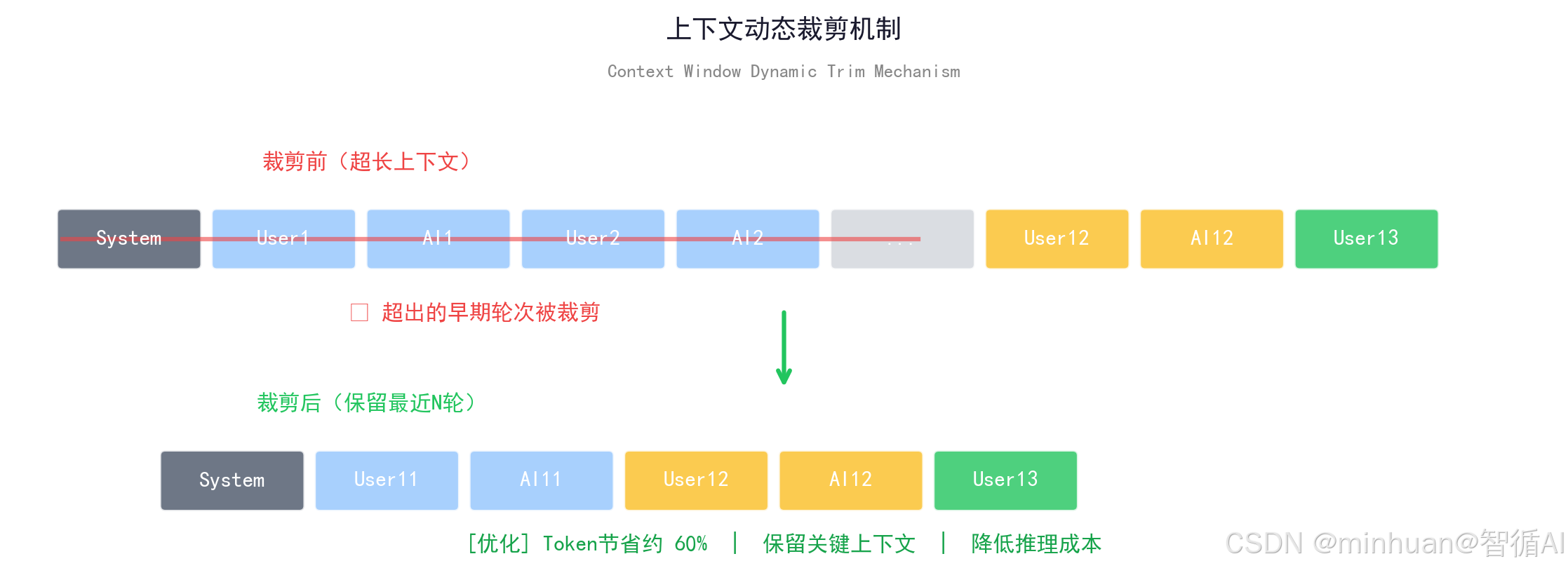
def trim_context(self) -> List[Dict[str, str]]:
"""上下文动态裁剪 控制轮次 优化Token"""
# 保留system提示词
system_content = self.context[0:1]
chat_content = self.context[1:]
# 超出最大轮次 截断早期内容
if len(chat_content) > MAX_CHAT_ROUND * 2:
cut_index = len(chat_content) - MAX_CHAT_ROUND * 2
chat_content = chat_content[cut_index:]
return system_content + chat_content
def get_need_summary(self) -> bool:
"""判断是否需要生成历史摘要"""
return self.chat_round >= SUMMARY_TRIGGER_ROUND
def get_context_token_num(self) -> int:
"""简易估算上下文Token数量"""
total_text = "".join([item["content"] for item in self.context])
return int(len(total_text) * TOKEN_RATE)
class SessionManager:
"""全局会话状态管理器 核心调度类"""
def __init__(self):
# 会话存储字典 生产环境替换为Redis/数据库
self.session_pool: Dict[str, ChatSession] = {}
def create_session(self, user_id: str) -> str:
"""创建新会话 返回session_id"""
session = ChatSession(user_id)
self.session_pool[session.session_id] = session
return session.session_id
def get_session(self, session_id: str) -> Optional[ChatSession]:
"""获取会话 过期自动标记"""
session = self.session_pool.get(session_id)
if not session:
return None
# 过期检测
if session.is_expire():
session.status = "expire"
return session
def delete_session(self, session_id: str) -> bool:
"""删除指定会话"""
if session_id in self.session_pool:
del self.session_pool[session_id]
return True
return False
def clear_expire_session(self):
"""批量清理过期会话"""
expire_list = []
for sid, session in self.session_pool.items():
if session.is_expire():
expire_list.append(sid)
for sid in expire_list:
del self.session_pool[sid]
class AIAgentCore:
"""AI智能体核心交互类"""
def __init__(self):
self.session_manager = SessionManager()
def mock_llm_answer(self, context: List[Dict[str, str]], user_input: str) -> str:
"""模拟大模型调用 实际项目替换为真实API请求"""
trim_ctx_len = len(context)
token_num = int("".join([c["content"] for c in context]).__len__() * TOKEN_RATE)
return (
f"已关联上下文完成回复\n"
f"当前上下文片段数量:{trim_ctx_len}\n"
f"估算输入Token:{token_num}\n"
f"结合你提问:{user_input},给出连贯回答结果。"
)
def chat(self, session_id: str, user_id: str, user_input: str) -> Dict:
"""单轮对话入口 完整状态管理流程"""
# 1. 会话不存在则自动创建
session = self.session_manager.get_session(session_id)
if not session:
session_id = self.session_manager.create_session(user_id)
session = self.session_manager.get_session(session_id)
# 2. 新增用户提问上下文
session.add_chat_content("user", user_input)
# 3. 上下文裁剪优化 Token节流
trim_context = session.trim_context()
# 4. 调用模型获取回复
ai_reply = self.mock_llm_answer(trim_context, user_input)
# 5. 保存智能体回复 完成状态更新
session.add_chat_content("assistant", ai_reply)
# 6. 检测是否需要摘要压缩
need_summary = session.get_need_summary()
return {
"session_id": session_id,
"ai_reply": ai_reply,
"current_chat_round": session.chat_round,
"context_token": session.get_context_token_num(),
"need_summary": need_summary,
"session_status": session.status
}
# ===================== 案例演示 模拟多轮对话 =====================
if __name__ == "__main__":
print("\n" + "="*60)
print(" AI智能体状态管理 - 完整演示")
print("="*60 + "\n")
# 初始化智能体
agent = AIAgentCore()
test_user_id = "user_001"
# 第一轮提问
print("-" * 60)
print("[第一轮对话]")
print("-" * 60)
print("用户: 什么是AI智能体状态管理?\n")
res1 = agent.chat("", test_user_id, "什么是AI智能体状态管理?")
print("AI回复:")
print(res1['ai_reply'])
print(f"\n状态信息: 轮次={res1['current_chat_round']}, Token={res1['context_token']}, 状态={res1['session_status']}")
print(f" Session ID: {res1['session_id'][:16]}...")
# 第二轮关联提问
print("\n" + "-" * 60)
print("[第二轮对话(上下文关联)]")
print("-" * 60)
print("用户: 它的核心作用是什么?\n")
res2 = agent.chat(res1["session_id"], test_user_id, "它的核心作用是什么?")
print("AI回复:")
print(res2['ai_reply'])
print(f"\n状态信息: 轮次={res2['current_chat_round']}, Token={res2['context_token']}, 状态={res2['session_status']}")
# 第三轮深度追问
print("\n" + "-" * 60)
print("[第三轮对话(持续关联)]")
print("-" * 60)
print("用户: 如何做Token优化降低成本?\n")
res3 = agent.chat(res1["session_id"], test_user_id, "如何做Token优化降低成本?")
print("AI回复:")
print(res3['ai_reply'])
print(f"\n状态信息: 轮次={res3['current_chat_round']}, Token={res3['context_token']}, 状态={res3['session_status']}")
# 显示是否需要摘要
if res3['need_summary']:
print("提示: 对话轮次已达阈值,建议生成历史摘要!")
# 会话重置演示
print("\n" + "-" * 60)
print("[会话销毁演示]")
print("-" * 60)
agent.session_manager.delete_session(res1["session_id"])
print(f"会话 {res1['session_id'][:16]}... 已销毁")
print("下次提问将自动新建会话\n")重点说明:
- trim_context():Token节流的核心
- 始终保留system提示词;超出 MAX_CHAT_ROUND*2 条时,裁剪最早的历史;
- 保留最近N轮,实现滑动窗口效果
- is_expire():过期检测
- 当前时间 - 最后交互时间 > 24小时 → 自动标记 expire
- get_need_summary():摘要触发判断
- 对话超过20轮时返回True,触发上游生成历史摘要,用简短摘要替代冗长原文
输出结果:
============================================================
AI智能体状态管理 - 完整演示
============================================================------------------------------------------------------------
[第一轮对话]
------------------------------------------------------------
用户: 什么是AI智能体状态管理?AI回复:
已关联上下文完成回复
当前上下文片段数量:2
估算输入Token:59
结合你提问:什么是AI智能体状态管理?,给出连贯回答结果。状态信息: 轮次=1, Token=144, 状态=active
Session ID: 126d087b-e0a5-46...
------------------------------------------------------------
[第二轮对话(上下文关联)]
------------------------------------------------------------
用户: 它的核心作用是什么?AI回复:
已关联上下文完成回复
当前上下文片段数量:4
估算输入Token:157
结合你提问:它的核心作用是什么?,给出连贯回答结果。状态信息: 轮次=2, Token=239, 状态=active
------------------------------------------------------------
[第三轮对话(持续关联)]
------------------------------------------------------------
用户: 如何做Token优化降低成本?AI回复:
已关联上下文完成回复
当前上下文片段数量:6
估算输入Token:258
结合你提问:如何做Token优化降低成本?,给出连贯回答结果。状态信息: 轮次=3, Token=347, 状态=active
------------------------------------------------------------
[会话销毁演示]
------------------------------------------------------------
会话 126d087b-e0a5-46... 已销毁
下次提问将自动新建会话
七、总结
结合实际应用经验来说,智能体的上下文状态管理,并不是复杂的高阶技术,却是决定智能体落地效果的核心底座。大模型本身天生无记忆、无状态,所有多轮对话的连贯能力,全都需要我们在业务层手动搭建、维护和优化。
日常开发里,我们通常会以解决问题的形式简单拼接聊天记录,短期使用看不出问题,但对话轮次变多、跨天接续会话后,就会出现逻辑断裂、Token暴涨、响应变慢等一系列问题。后期必定会考虑状态管理方案,把会话生命周期、结构化上下文存储、动态裁剪、摘要压缩、过期治理全部整合起来,想方设法的补齐了传统写法的短板。打好状态管理的基础,后续开发工具调用、长会话智能体、多租户系统都会更加得心应手。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)