第二周-4.28
正则化
(减少参数量):保持模型简单,避免过拟合
原因:过拟合和欠拟合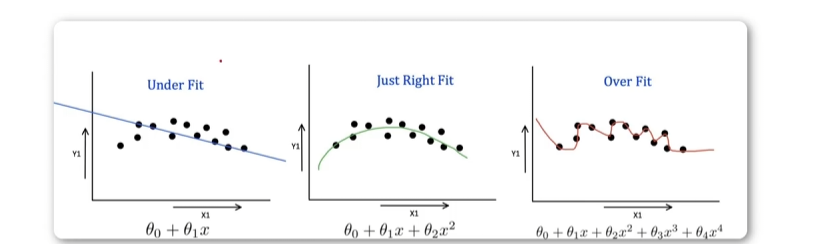
达到刚好拟合的效果,能泛化到新的数据
训练误差:模型对训练数据的误差。
泛化误差:模型对未知数据的误差。
方法:损失函数中添加一个正则化项,这个正则化项会根据模型参数大小来惩罚模型的复杂度。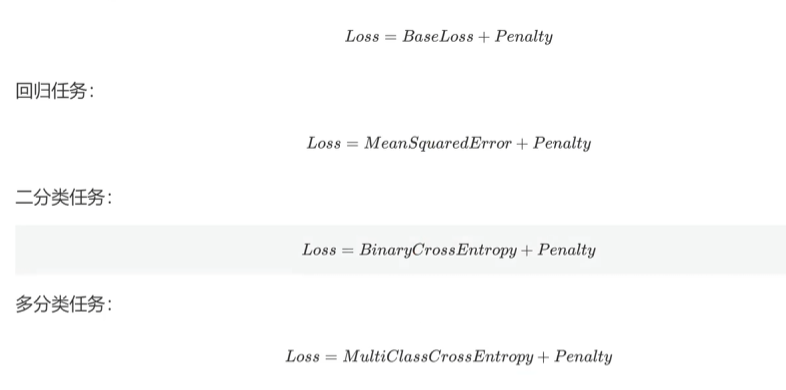
Penalty:惩罚项
L1和L2正则项
Penalty为L1或L2
L1:让一些特征的权重变为0,用来进行特征选择,(可能会过度惩罚某些项,使得有用的特征被舍弃)
L2:让所有特征的权重的变得特别小,但不为0,不能用于特征选择


实操
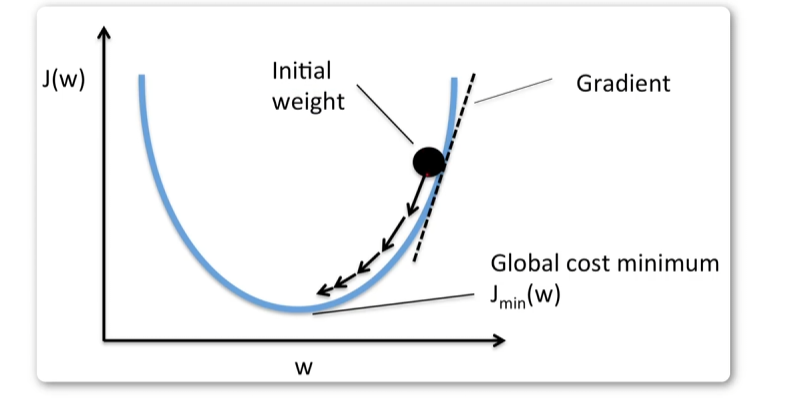
梯度下降法
在机器学习中,我们也需要找到一个函数的最小值。这个函数表示一个损失函数,表示模型预测与真实值之间的差距,我们需要找到最小化损失函数的参数。梯度下降法就是一种常用的优化算法,可以帮助我们找到函数的最小值。
步骤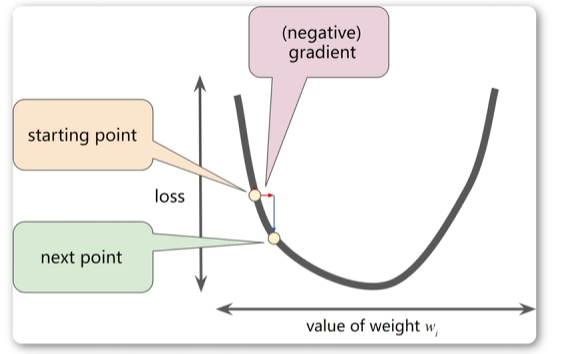

直到到达谷底
学习率太小和太大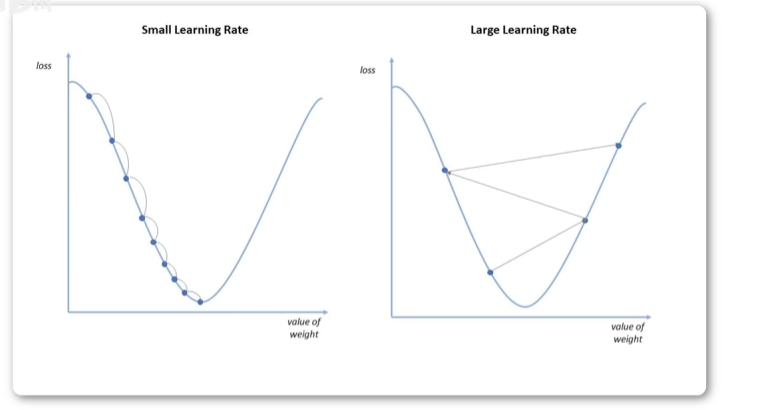
总之,梯度下降法是一种非常重要的优化算法,它能够帮助我们在大规模的数据集上求解复杂的机器学习模型,通过不断的调参来逼近最优解模型。
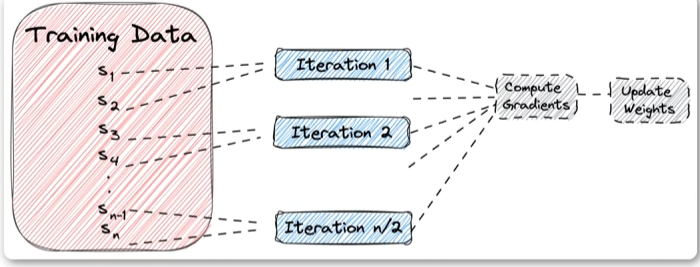
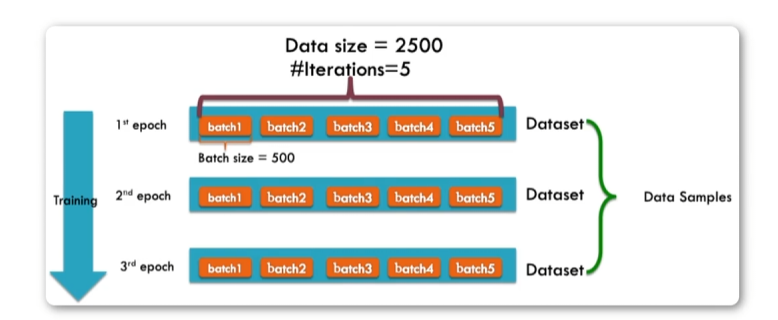
小批量梯度下降
机器学习训练模型的过程中是要不断地通过梯度下降法来调整大量不同的参数[w0,w1,w2,··,wn}
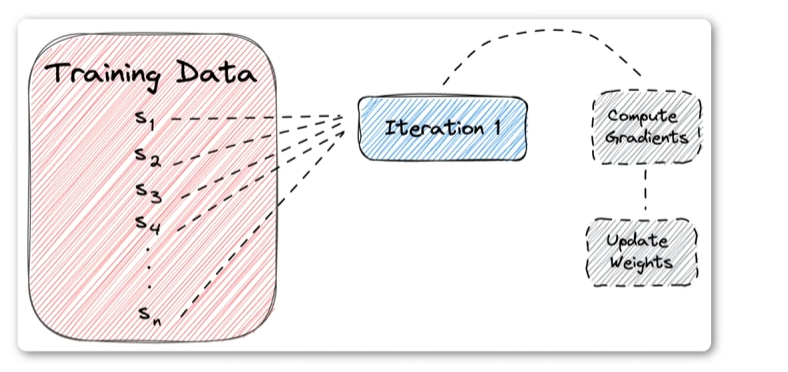
将训练数据分成多个批次(batch),每个批次所包含数据量(samples)叫做
批次大小(batch_size),梯度下降每次迭代使用一个批次的数据。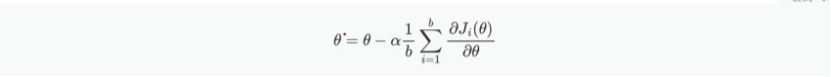
调整时用b,表示分批次
训练数据交给机器从头到尾学习一遍往往是不够的,需要学习很多遍,每学习一遍称
之为学习一个轮次(epoch),所以小批量梯度下降就是分轮次分批次的训练。
数据归一化
数据归一化就是将数据中的每个特征按照一定的比例进行缩放,使得不同特征之间的值在相同的范围内波动,从而消除特征之间的量纲(单位)差异。
在一个线性回归问题中,如果某个特征的范围很大,那么它对结果的影响就会比范围较小的特征更大,这可能会导致算法的结果出现偏差。
最大值最小值归一化
标准归一化(用的更多)

·异:最大值最小值归一化依赖某两个值最大和最小,标准归一化则依赖所有值
·异:最大值最小值归一化变成[0-1]的区间内,标准归一化没有这个区间限制只是数据的均值为0方差为1
·同:归一化目的都是为了使得不同度量的特征具有可比性
例子 
KMeans聚类
KMeans聚类就是一种常用的算法,它可以帮助我们对数据进行分组。
作为一种通用的无监督学习算法,KMeans聚类可以应用于各种不同的领域,比如图像分割、社交网络分析和推荐系统。
算法具体流程
将数据分为k组(自己设定)
1、一开始,我们随机选择K个数据点作为聚类中心。
2、然后,对于每个数据点,我们计算它和每个聚类中心的距离,将它分配到距离最近的那个聚类中心所在的组。
3、接下来,我们更新每个组的聚类中心,计算每个组中所有数据点的平均值,并将其作为该组的新聚类中心。
4、然后,我们重新计算每个数据点和每个新的聚类中心之间的距离,并将数据点重新分配到距离最近的那个组。
5、我们重复这个过程,直到聚类中心不再变化,或者我们达到了设定的迭代次数。最终,我们得到了K个不同的聚类组。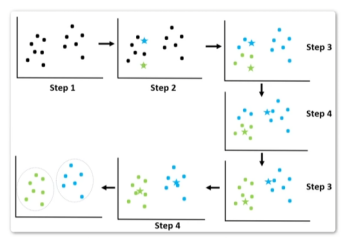
得到的模型是每个簇的中心点
例子
高斯混合模型
高斯混合模型(GaussianMixtureModel,简称GMM)是一种常用的机器学习算法,用于对数据进行聚类或者拟合。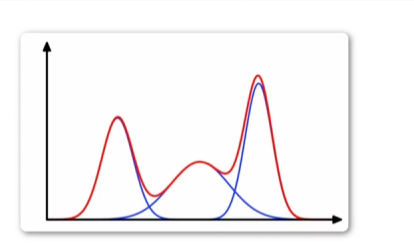
对有/无标签的数据集,可以使用高斯混合模型进行聚类;
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(ncomponents=16,covariancetype='diag',maxiter=200,ninit=10)#n_components表示用的高斯分布的个数,covariance_type表示协方差矩阵的类型,diag表示对角矩阵,full表示任意矩阵,tied表示所有高斯分布的协方差矩阵相同,spherical表示所有高斯分布的协方差矩阵为 Identity矩阵的平方
感知机
神经网络的起点
感知机的基本结构类似于生物神经元。它有多个输入,每个输入都有一个权重,表示这个输入的重要性。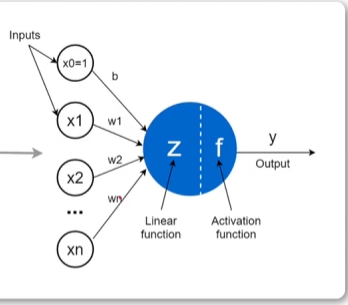
感知机将所有输入与它们的权重相乘,并将结果相加,然后使用阀值函数来确定输出是否激活。如果输出激活,则感知机会产生一个信号,否则它会保持静默。
感知机的一个重要特点是它可以学习。学习过程中,感知机会根据输入和输出之间的误差来调整权重,以改进其预测能力。这个过程被称为感知机学习规则,它使用了梯度下降算法来优化权重。
从神经元到神经网络
神经网络多层感知机(MultilayerPerceptron,简称MLP)是一种比感知机更为复杂的神经网络结构,它是通过多层神经元来处理信息的。
在多层感知机中,你可以直接将原始数据输入到模型中,而模型会自动提取出数据中的关键特征。这是因为多层感知机由多个层组成,每个层都由多个神经元组成,每个神经元都会对前一层的输出进行加权和,然后将这些加权和输入到激活函数中进行处理,输出结果。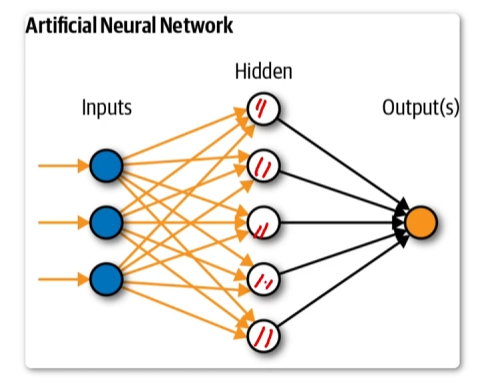
Hidden(隐藏层):进行特征抽取,维度增加
加入隐藏层,引入非线性变化
可以有更多隐藏层,引入更加复杂的非线性变化(可以拟合更加复杂的模型);
也可以同时预测多个输出(n分类);
通过这种方式,多层感知机可以处理非常复杂的数据,如图像、音频和文本等。例如,如果你想训练一个机器来识别手写数字,你可以将手写数字的像素值作为输入,然后使用多层感知机来提取关键特征,最终输出该数字的标签。
激活函数
当我们在神经网络中传递数据时我们需要一种函数来帮助我们在每一层中转换数据。这就是激活函数(Activation Function)
激活函数是一种非线性函数,它可以把输入的数据映射到一个新的输出值,这个输出值可以在下一层被用作输入。
激活函数的主要作用是为神经网络引入非线性因素,使得神经网络可以处理更加复杂的数据,提高网络的表示能力。如果没有激活函数,神经网络将只是一组线性方程的组合,无法处理非线性数据。
每个隐藏层都有一个激活函数,每一个网络中的激活函数一致。
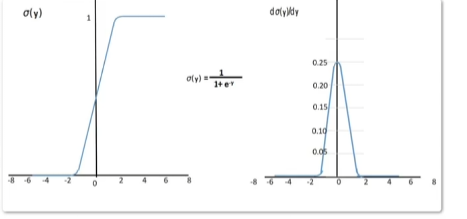
Sigmoid函数:这个函数的形状像一个”S”形,通常被用于二分类问题。当输入趋近于正无穷时,它的输出会趋近于1;当输入趋近于负无穷时,它的输出会趋近于0。然而,Sigmoid函数的导数在接近边缘处变得非常小,这使得梯度消失问题变得更加明显。
Tanh函数:这个函数的形状类似于Sigmoid函数,但是它的输出范围是[-1,1]。,与Sigmoid函数类似,当输入趋近于正无穷时,它的输出会趋近于1;当输入趋近于负无穷时,它的输出会趋近于-1。与Sigmoid函数相比,Tanh函数具有更强的非线性特性。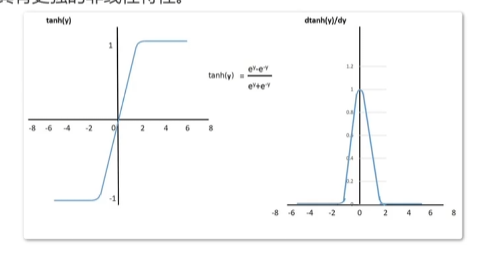
ReLU函数:这是一种非常流行的激活函数,它的全称是“整流线性单元”。ReLU函数的特点是在输入大于0时,输出等于输入;在输入小于等于0时,输出等于0。它不仅速度快,而且很容易优化,因为它的导数恒为1或0。然而,ReLU函数的一个缺点是可能会出现“神经元死亡”问题,这是因为当神经元的输入小于0时,该神经元的梯度将始终为0。
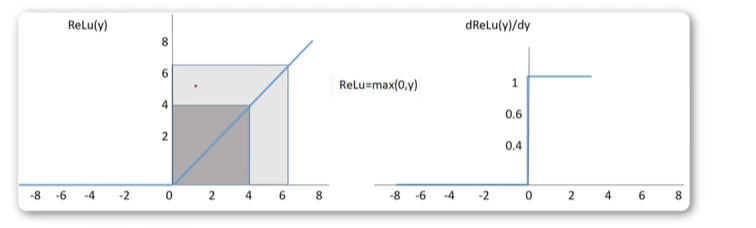
LeakyReLU函数:这是一种对ReLU函数的改进。当输入小于0时,它的输出等于输入的一个小的斜率。这个小斜率通常设置为0.01或0.001。相对于ReLU函数,LeakyReLU函数的优势是可以避免神经元死亡问题。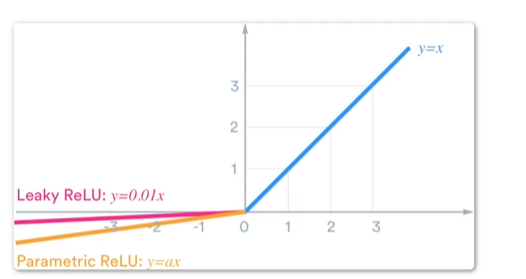
正向传播
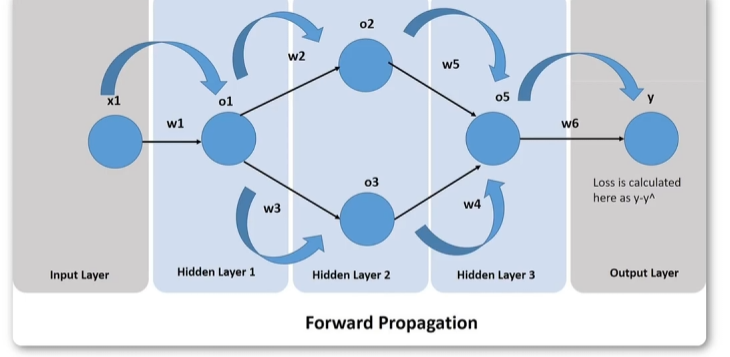

因此,正向传播整体上就是从X->Loss的过程,如果把Forward Propagation看成是一个函数的话,那么它无非就是一个复合函数
反向传播
神经网络中反向传播是为了去调整参数使得损失函数值可以最小化
同时通过反向传播也是一种方式知道每个节点该对损失值负责多少
梯度是一个计算出来的数值,它可以帮助我们去知道如何调整神经网络的参数;一次迭代包含一次正向传播(计算predictions与loss)和一次反向传播(求梯度与调参),所谓训l练就是多次迭代直到达到局部最小值
梯度下降法
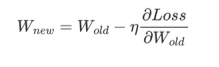
Loss是之前正向传播得到的,因此,对参数求导实际就是复合函数求导,复合函数求导应用chainrule,即链式求导法则。
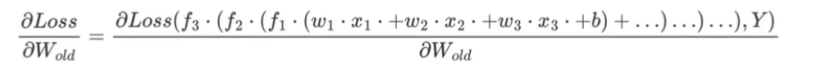
例如
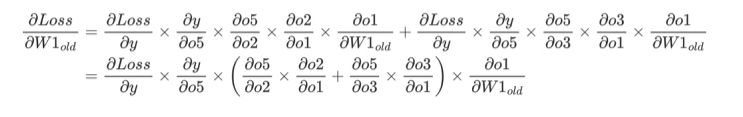

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)