【深度复盘】DeepSeek V4 落地实战:从多智能体编排到高精度 RAG 的工程化“避坑”指南
最近 DeepSeek V4 刷屏了开发者社区。相比于铺天盖地的跑分评测,作为真正在一线做 SaaS 业务和企业级“数字员工”落地的开发者,我更关心的是它的工程化边界:V4 的 API 到底能不能撑起复杂的业务拓扑?在 LangChain 和 Dify 这种成熟框架里,它会不会出现水土不服?
过去几周,我们在内部的自动化营销智能体和多应用协同架构中,全量测试了 DeepSeek V4。这篇文章不谈虚的,直接拆解我们在接入 LangChain、Dify 以及构建高可用 RAG 系统时踩过的坑和沉淀的架构范式。
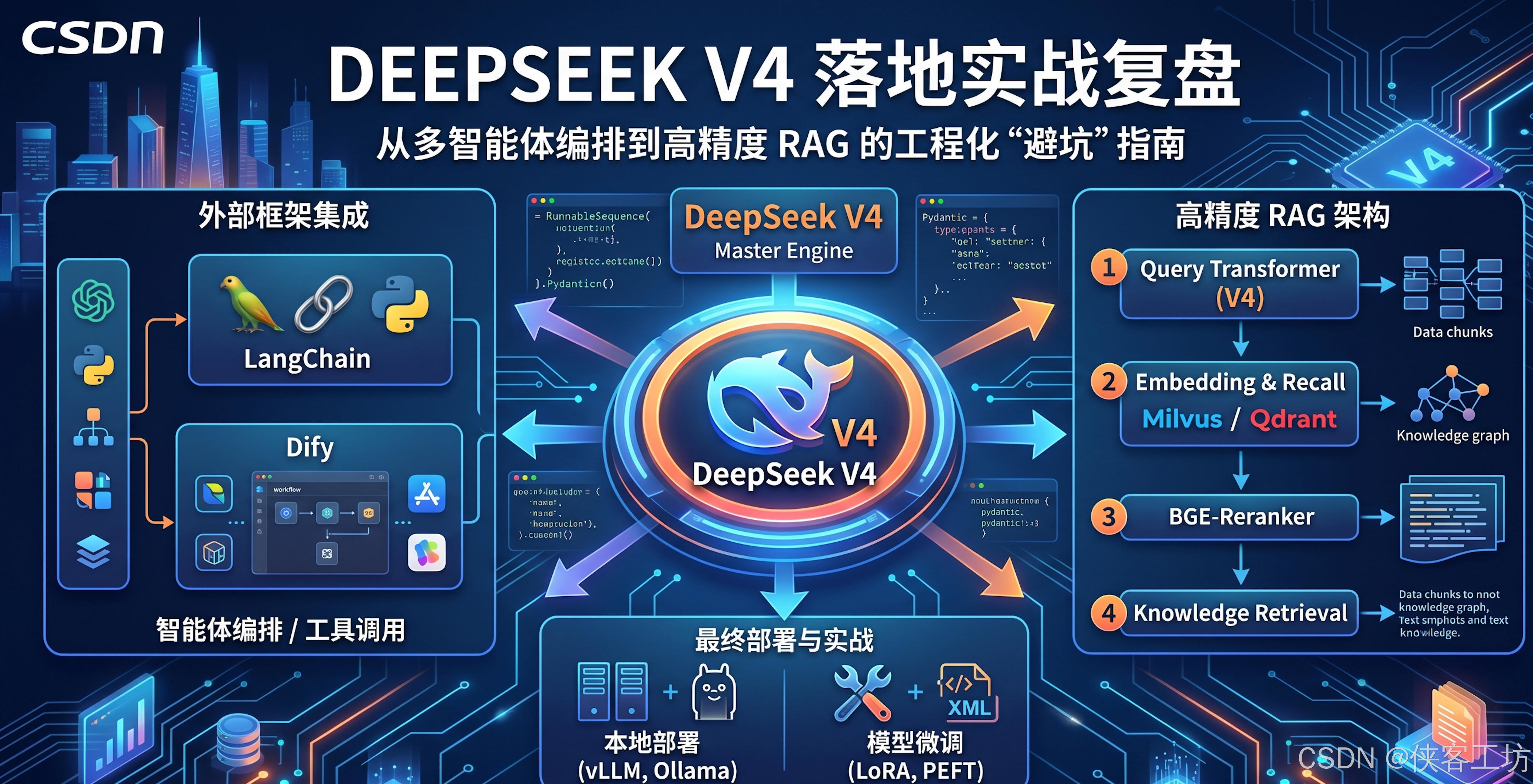
一、 认知对齐:DeepSeek V4 在工程框架中的定位
在将 V4 接入现有系统前,我们必须明确一点:不要把 V4 当作单纯的文本生成器,它在系统中的最优角色是“决策路由引擎”。
得益于其 MoE 架构的进一步演进,V4 在复杂逻辑推理和 Tool Calling(工具调用)上的稳定性有了质的飞跃。但在接入 LangChain 时,很多开发者习惯性地直接平替原有的 OpenAI 节点,这其实是一种降维使用。
1. LangChain 深度集成:告别“Prompt 依赖症”
在 LangChain 中,V4 最大的优势在于其对结构化输出(JSON Mode)的绝对掌控力。我们在做多端应用协同调度时,经常需要 LLM 输出极度严苛的 DSL(领域特定语言)。
避坑指南:V4 对 System Prompt 的权重感知非常敏锐。如果你在 LangChain 中使用了过深的 ConversationBufferMemory,历史对话的噪音很容易污染 V4 的当前决策。 实战建议:采用 RunnableSequence 进行链式解耦。将记忆抽取与核心推理分开,利用 V4 强大的单次推理能力,配合 Pydantic 强制约束输出格式。
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI # DeepSeek 兼容 OpenAI 协议
class AgentAction(BaseModel):
tool_name: str = Field(description="目标应用或工具的名称")
parameters: dict = Field(description="执行该动作所需的参数字典")
reasoning: str = Field(description="决策链路说明")
# 强烈建议将 temperature 降至 0.1 以保证业务调度的确定性
llm = ChatOpenAI(
model="deepseek-chat-v4",
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v1",
temperature=0.1
)
# 配合 output_parsers 即可实现极高成功率的路由分发
2. Dify 编排:构建“数字员工”的视觉化中枢
Dify 是目前做业务落地的首选框架。在 Dify 中接入 V4,最大的爽点在于构建“多智能体(Multi-Agent)”工作流。
我们的业务场景中包含大量的本地生活服务数据分析和自动化内容分发。我们将 V4 作为 Dify 工作流中的“主节点(Master Node)”,专门负责意图识别和任务拆解,而后挂载多个轻量级模型或固定 API 节点执行子任务。实测发现,V4 在 Dify 的 Iterate(迭代)节点和 Condition(条件分支)中表现出的上下文连贯性,已经足以支撑构建一个完整的“数字员工”闭环。
二、 RAG 架构演进:不仅是“向量检索”,更是“语义重构”
如果说大模型是引擎,RAG 就是外挂油箱。DeepSeek V4 的长上下文能力虽然惊艳,但如果在生产环境中真的把几十万 Token 的原始文档硬塞给它,不仅 API 成本会原地爆炸,还会遭遇严重的“大海捞针(Needle in a Haystack)”性能衰减。
我们在处理 B2B 领域的专业文档和法律合规条文时,总结了一套基于 V4 的 “双重路由 RAG 架构”。
核心实践 1:Query 降维与重写
用户输入的 Query 往往是模糊的。我们利用 V4 的低延迟特性,在 RAG 链路的最前端加了一层 Query Transformer。
-
做法:让 V4 先把用户的口语化提问,拆解、重写为 2-3 个具备严格技术语义的检索词。这能让后续的向量检索(Recall)召回率提升至少 40%。
核心实践 2:BGE-Reranker 与 V4 的混合双打
不要盲目相信单一的 Embedding 模型。我们的落地方案是:
-
使用轻量级 Embedding(如 BGE-m3)在 Milvus 或 Qdrant 中进行粗排(Top 20)。
-
引入 BGE-Reranker 模型进行交叉编码精排(Top 5)。
-
关键点:将精排后的高质量 Chunk 交给 DeepSeek V4 进行最终的逻辑缝合与生成。V4 极其擅长处理这种“半结构化的信息碎片”,它能够准确识别 Chunk 之间的矛盾点,并在输出时给出合理的解释,而不是像早期模型那样胡言乱语(Hallucination)。
三、 本地部署与微调(Fine-tuning)的务实考量
对于数据敏感型业务(比如涉及企业内部财务、客户隐私数据),公有云 API 永远是一道红线。
关于本地部署: 对于绝大多数中小团队,不要去碰全量参数的本地部署。通过 vLLM 配合多卡推理是目前的标配。如果算力有限,强烈建议关注针对特定垂直领域(如医疗、法律、代码)蒸馏过的 V4-MoE 小参数量版本(如果有的话),配合 Ollama 能够快速在单台 A100/A800 服务器上跑通闭环。
关于微调(LoRA): 实话说,目前 V4 的基础能力已经足够应付 90% 的场景。我们仅在一种情况下建议做 LoRA 微调:输出格式的极度定制化。 例如,我们需要模型输出完全符合内部老旧系统接口规范的古怪 XML 结构。这时候,准备 500-1000 条高质量的 {"instruction", "input", "output"} 对,通过 PEFT 库对 V4 进行轻量级微调,投资回报率(ROI)是最高的。不要试图通过微调给模型灌输“知识”,知识应该交给 RAG;微调的目的是改变模型的“行为范式”。
写在最后
技术的浪潮一波接着一波,DeepSeek V4 提供了一个极具性价比且能力拔尖的底层基座。但作为工程师,我们要清醒地认识到:模型只是积木,真正的护城河在于你如何用 LangChain、Dify 这些粘合剂,把 RAG、知识图谱、API 调度编排成一个能解决实际业务痛点、能产生商业价值的“系统”。
不要沉迷于跑分,去真实的工作流里踩踩坑吧。欢迎在评论区交流你们在接入 V4 时遇到的奇葩 Bug,咱们一起探讨。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)