SPARSE AUTOENCODERS REVEAL SELECTIVE REMAPPING OF VISUAL CONCEPTS DURING ADAPTATION
ICLR 2025

abstract
针对特定任务适配基础大模型,已成为构建下游应用机器学习系统的主流范式。然而,模型适配过程中究竟发生了何种内在作用机制,目前尚无明确答案。本文针对 CLIP 视觉 Transformer 设计了一种全新稀疏自编码器(SAE),命名为 PatchSAE,用以细粒度提取可解释视觉概念(例如物体的形状、颜色、语义特征),并捕捉这些概念在图像分块层面的空间归因信息。
本文探究了这类视觉概念如何影响下游图像分类任务的模型输出,并研究了当前主流的提示词适配方法,会如何改变模型输入与上述视觉概念之间的关联映射。实验发现:适配前后的模型,其概念激活值仅有小幅差异;模型在各类适配任务上的性能提升,绝大部分都源于预训练基础模型中原本就已存在的固有视觉概念。
本研究为视觉 Transformer 搭建了一套完整可行的稀疏自编码器训练与应用框架,同时为解析模型适配的底层内在机制提供了全新研究洞察。
introduction
基础模型仅依靠少量额外训练数据,就能快速适配全新任务与应用领域,表现十分出色(Radford 等人,2021;Caron 等人,2021;Touvron 等人,2023)。在视觉 - 语言模型领域中,CLIP(Radford 等人,2021)已成为众多下游应用的核心骨干网络(Liu 等人,2024;Li 等人,2023;Rombach 等人,2022)。CLIP 模型由两个 Transformer 网络构成,分别用于编码文本与图像输入。
目前学界已提出多种参数高效适配方法(例如引入可学习词元),可针对性优化文本编码器或图像编码器。早期研究主要聚焦文本编码器的适配(Zhou 等人,2022a,b);而近期研究证实,对图文双编码器进行联合适配,能够进一步提升分类任务性能(Khattak 等人,2023a,b)。
尽管模型适配技术已取得长足进步,但基础模型的表征在适配过程中会发生何种内在变化,仍是尚未解开的开放性问题。
近年来,稀疏自编码器(SAE)在主流大语言模型中展现出优异效果后(Bricken 等人,2023;Lieberum 等人,2024),逐渐成为机制可解释性研究的核心工具,受到广泛关注(Bricken 等人,2023;Cunningham 等人,2023;Templeton, 2024;Yun 等人,2021)。模型原始的稠密表征存在多语义纠缠问题,大量无关概念相互耦合,难以解释;而 SAE 可将这类稠密表征映射为稀疏、单义、可解释的独立视觉概念。
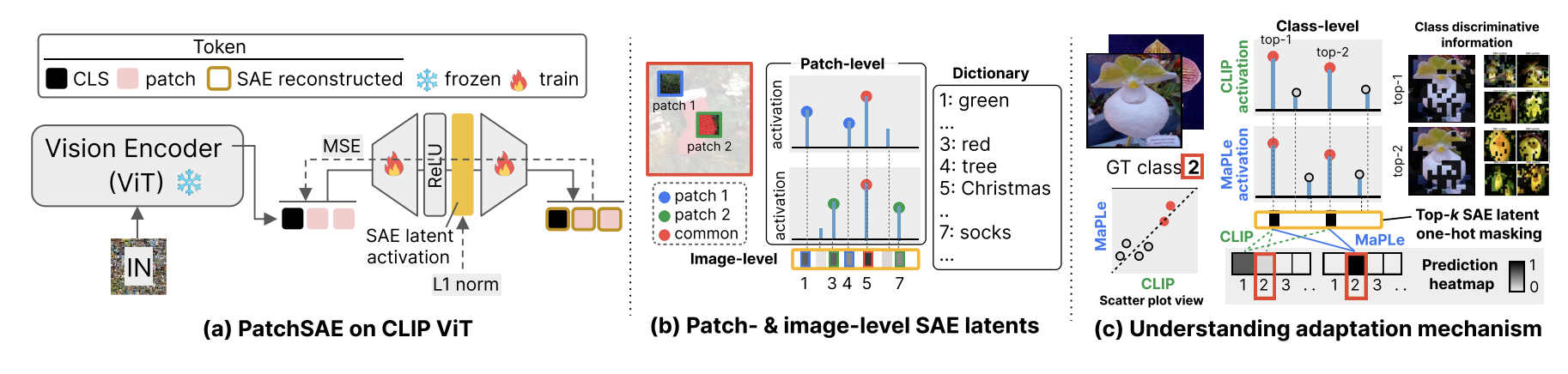
本文面向 CLIP 视觉 Transformer(ViT),提出全新稀疏自编码器架构 PatchSAE(见图 1 (a))。PatchSAE 能够提取可解释视觉概念,并输出图像分块级的空间归因信息,实现精细化局部解读:单张图像的不同区域可同时拆解出多种独立视觉概念(见图 1 (b))。在利用 SAE 分析模型行为之前,本文首先验证了 PatchSAE 作为可解释性工具的有效性。实验表明,PatchSAE 可识别丰富多样的可解释概念、提供精细化局部解释,且在多类数据集上具备良好泛化能力(3.3 节)。随后,本文依托分类任务,探究了各类可解释概念对 CLIP 模型最终输出结果的影响。
本文借助 PatchSAE,深入剖析基础模型在适配任务中的底层内在机制。当前主流的 CLIP 适配方案(Zhou 等人,2022a,b;Khattak 等人,2023a,b),会为特定数据集添加可学习的专属词元完成适配,原理与大语言模型中的系统提示词类似。
通过大量实验分析,本文以 PatchSAE 为可解释性工具,全面挖掘了 CLIP 多层次的可解释概念 —— 从基础视觉纹理模式到高层抽象语义(见图 1 (b))。通过逐词元解析 SAE 隐空间激活值,实现视觉概念的空间定位,并进一步拓展至图像级、类别级、任务级的全方位行为解读。同时,消融实验证明:SAE 隐层特征对分类任务的模型预测结果起到决定性作用。最后,本文证实:基于提示词的模型适配,本质是通过调整视觉概念与任务类别之间的映射关系,从而实现性能提升(见图 1 (c))。
本文整体章节安排如下:首先,详细介绍 PatchSAE 稀疏自编码器。该架构可为视觉 Transformer 的每个图像词元挖掘独立概念,并输出空间归因信息(第 3 节)。本文基于 CLIP 完成 PatchSAE 训练,验证了在 ImageNet 尺度下训练的 SAE,在域偏移、细粒度等各类评测数据集上的可解释性与泛化能力。其次,依托 PatchSAE,探究 CLIP 在分类任务中的内在行为规律,以及引入可学习提示词后模型行为的变化机制(第 4 节)。最后,总结全文结论,并讨论该研究的拓展价值与广泛应用意义(第 5 节)。
related work
面向机制可解释性的稀疏自编码器
机制可解释性(Elhage 等人,2021)旨在阐释神经网络生成输出的内在推理逻辑。为实现这一目标,就需要深入厘清:神经网络中每个神经元究竟识别了何种特征(概念)(Olah 等人,2020)。例如,对数概率透镜(Logit Lens) 方法通过将中间层输出映射至最终分类层或解码层,以此理解模型中间表征。但由于神经元普遍存在多语义叠加特性(Elhage 等人,2022)—— 单个神经元会被多个无关概念共同激活,因此很难用人类可理解的方式解读神经元行为。该现象源于特征叠加编码机制:神经网络所能表征的特征数量,远超其向量维度总数。
为解决神经网络可解释性研究中的特征叠加问题,稀疏自编码器(SAE) 近年来受到广泛关注(Sharkey 等人,2022;Bricken 等人,2023)。稀疏自编码器将模型原始激活值拆解至稀疏隐空间,以高维向量字典的形式完成表征解耦。已有多项研究将稀疏自编码器应用于大语言模型(Yun 等人,2021;Cunningham 等人,2023)。借助 SAE 技术,Templeton(2024)在大语言模型中识别出偏见、安全相关的关键特征,并证明可通过调控这类特征,定向改变大模型的输出行为。后续研究进一步将 SAE 拓展至 CLIP 等视觉 - 语言跨模态模型(Radford 等人,2021):Fry(2024)与 Daujotas(2024a)从 CLIP 视觉编码器中提取可解释视觉概念;Daujotas(2024b)利用这类特征实现扩散模型的图像生成内容编辑;Rao 等人(2024)结合 CLIP 文本编码器的词嵌入为 SAE 概念命名,并构建了基于概念瓶颈的约束模型。
与现有工作不同,本文以图像块级视觉词元作为稀疏自编码器的输入,能够直观、局部化地解析 SAE 隐变量,并可灵活拓展至图像级、类别级、数据集级等更高维度的分析。同时,本文采用SAE 隐变量掩码方法,定量分析可解释概念与下游任务求解能力之间的关联。借此,本文首次系统性探究:基础模型在适配过程中的内在行为变化,以及视觉概念在不同数据集之间的复用规律。
基于提示词的模型适配
对 CLIP 等视觉 - 语言基础模型进行全量微调,不仅需要大规模训练数据与高昂计算资源,还容易损害模型的泛化能力。在此背景下,基于提示词的适配方法应运而生:冻结预训练模型全部权重,仅训练少量可学习词元,实现轻量化下游适配。CoOp(Zhou 等人,2022b)针对小样本场景,仅在 CLIP 文本分支引入可学习提示词元完成适配;Bahng 等人(2022)则将提示词适配方案应用于视觉分支;MaPLe 通过在视觉、文本双分支同步添加可学习词元,大幅提升小样本适配性能,也成为后续各类多模态提示学习方法的基础框架(Khattak 等人,2023a、2023b)。
尽管现有研究已验证提示学习对 CLIP 适配的有效性,但提示学习究竟如何、为何能实现模型能力迁移,其底层机制仍缺乏深入探究。本文基于视觉 Transformer,利用稀疏自编码器聚焦解析 CLIP 图像编码器的内部运作逻辑;并选取多模态提示适配的代表性方法 MaPLe 作为研究对象,系统性揭示各类模型适配方案的内在工作机理。
method
3 PatchSAE:视觉语言模型中概念的空间归因
本章首先回顾稀疏自编码器(SAE)的基础原理,并在3.1 节介绍本文提出的全新 PatchSAE 模型。随后在3.2 节阐述如何挖掘具备可解释性的 SAE 隐空间特征方向。分析内容包括:统计 SAE 隐变量的整体分布指标(反映单个隐单元的激活频率与激活强度)、通过查看高激活参考图像识别模型学到的视觉概念,以及在图像空间中对 SAE 概念做空间定位(见图 2)。
3.1 PatchSAE 结构与训练目标
标准稀疏自编码器通常由单层线性编码层、ReLU 非线性激活函数与单层线性解码层构成(Bricken 等人,2023;Cunningham 等人,2023)。为在 CLIP 视觉 Transformer(ViT)上训练 SAE,本文劫持预训练 CLIP ViT 的中间层输出,将其作为自监督训练数据。我们取自注意力模块残差流输出中的全部词元(包含分类 CLS 词元与图像块词元),输入至 SAE 网络(图 9 (c))。
形式化定义:取 ViT 劫持层输出作为 SAE 输入特征 z;将其与编码器权重 相乘,经过 ReLU 激活
,再与解码器权重
相乘。编码器 / 解码器的列(或行)向量(维度为 RdViT,共 dSAE 个)对应候选视觉概念,即 SAE 隐特征方向;激活层输出向量(维度 dSAE)称为SAE 隐激活值。为简化表达,记编码函数为 f、解码函数为 g,整体计算如下:
z=ViT(x)[hook layer], SAE(z)=(g∘ϕ∘f)(z)=WD⊤ϕ(WE⊤z)(1)
SAE 训练以均方误差(MSE) 作为重构损失,同时对 SAE 隐激活施加 L1 正则,约束特征稀疏性、学习单义概念向量(图 1 (a)):
理想的 SAE 编码器可将模型稠密纠缠表征,拆解为若干单义独立概念;理想解码器则通过线性融合这些差异化概念,精准复原原始输入特征。
训练细节
本文采用 ViT-B/16 版本 CLIP 图像编码器,输入包含 14×14 个图像块词元与 1 个 CLS 分类词元;模型共 12 层注意力层,骨干维度 dViT=768。
PatchSAE 扩张系数设为 64,因此 SAE 隐空间维度:
dSAE=768×64=49152
劫持 ** 倒数第二层(第 11 层)** 注意力模块的残差流输出作为训练信号。本文保留全部图像块词元参与计算,因此 SAE 输入 / 输出形状为:(样本数, 词元长度, 模型维度d_ViT)。训练损失在所有独立词元上取平均。
实验从重构能力、稀疏性两个维度评估训练完成的 SAE;附录中给出不同超参配置的训练结果(附录 A.1),以及在不同网络层部署 SAE 的性能差异(附录 A.2)。
3.2 分析方法与实验设置
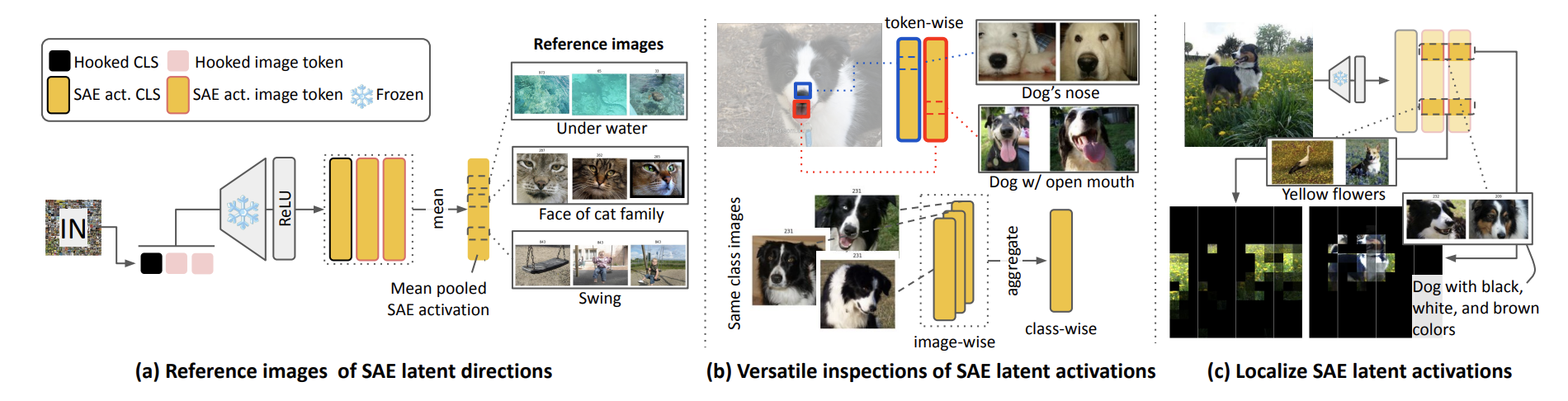
模型训练完成后,本文通过解析输入样本中**激活的 SAE 隐变量**,对 PatchSAE 开展有效性验证。 首先,收集能够最大化激活每个 SAE 隐单元的参考图像,以此筛选候选概念(即 SAE 隐特征方向),并统计其综合分布指标; 随后,分析 SAE 隐激活强度,衡量当前输入与对应隐特征方向的匹配程度。 基于**词元级(图像块级)**分析,可实现对图像的空间局部化解读。
为得到单张图像的全局概念解释,本文统计每个隐单元在整张图内的激活图像块数量,将块级激活聚合为**图像级激活**; 同理,进一步拓展至**类别级、数据集级**的跨尺度分析(公式 5)。
SAE 隐变量的参考图像
挖掘 SAE 可解释概念的第一步:选取**能够最大化激活单个 SAE 隐单元**的一组图像作为参考样本。 给定训练好的 SAE 模型与目标数据集,对每个隐维度,保留激活值最高的前 $k$ 张图像,最终共得到 张参考图。 本文采用**图像级激活值**筛选 Top-$k$ 样本,完整流程如图 2(a) 所示。
### SAE 隐变量的统计指标 为刻画每个 SAE 隐单元的整体激活规律,本文统计其激活分布的多项量化特征(Bricken 等人, 2023),基于部分训练集图像计算**激活频率**与**平均激活强度**; 同时依托 ImageNet 等分类数据集的类别标签,额外计算参考图像的**标签熵**与**标签标准差**,多维度刻画语义属性。 各项指标定义与解释如下:
- **稀疏度(激活频率)**:表征单个隐单元的全局激活频次。 统计产生正向激活的图像数量并除以总样本数。 高频激活的隐单元,要么对应通用视觉概念,要么属于无意义噪声特征。
- **平均激活值**:仅在激活样本上取正向激活的平均值,反映 SAE 对该概念的**置信度**。 平均激活越高,该隐特征越大概率对应有效、可解释的视觉概念。
- **标签熵**:衡量能激活该隐单元的类别丰富度。 先根据各类别对应的总激活值计算类别概率,再求解熵值:
其中 为类别 c 的累计激活值。 熵值为 0 代表所有参考图像属于同一类别;熵值越高,说明越多类别会触发该隐单元激活。
- **标签标准差**:ImageNet 类别基于词网语义层级结构构建(Deng 等人, 2009;Miller, 1995)。 本文利用该层级关系,结合参考图像的标签标准差,与标签熵互补,共同判别隐概念的**语义粒度**,详细讨论见附录 A.1。
多尺度层级的有效隐概念挖掘
以参考图像作为 SAE 隐方向的可解释依据,以输入图像的隐激活强度表征与该概念的相似度,从而判断输入中各类视觉概念的激活强弱。 如图 2(b)(c) 所示,**图像块级 SAE 激活**可以定位每一块区域对应的识别概念。 例如,包含“狗鼻子”的图像块,会特异性激活以“狗鼻子”为参考特征的 SAE 隐单元。 为从局部块特征得到整张图像的全局表征,本文将块级激活聚合为图像级激活: 设置小正数阈值 ,对第
张图、第
个图像块、第 s 个 SAE 隐单元的激活
做二值化, 超过阈值记为**有效激活隐单元**,反之视为未激活。 统计单张图内激活隐单元 s 的图像块总数,作为该图的图像级激活。
同理,聚合同类别、同数据集下所有图像的激活,得到**类别级激活**与**数据集级激活**。 形式化定义:
通过类别级与数据集级激活,可挖掘群组内的**共享视觉概念**。 后文 4.1 节将基于这类群组级有效隐单元,分析可解释概念与模型行为之间的关联。
图像块级 SAE 激活的空间定位
PatchSAE 支持在图像空间中对激活隐单元做精准定位,将块级隐激活视作**软分割掩码**实现可视化。 给定图像 与指定隐单元序号 s,将每个图像块
与其对应的隐激活值
加权相乘,实现特征高亮。 如图 2(c) 示例,该方法可以精准凸显输入图像中的“黄色花朵”“黑白棕相间的犬类”等局部概念。 从输入图与参考图中分离出目标隐单元对应的关键图像块,能够更直观、清晰地展示模型学到的视觉概念。
3.3 PatchSAE 挖掘 CLIP 中具备空间特异性的视觉概念
更多示例可见交互式演示demo(图12)及后续章节内容。 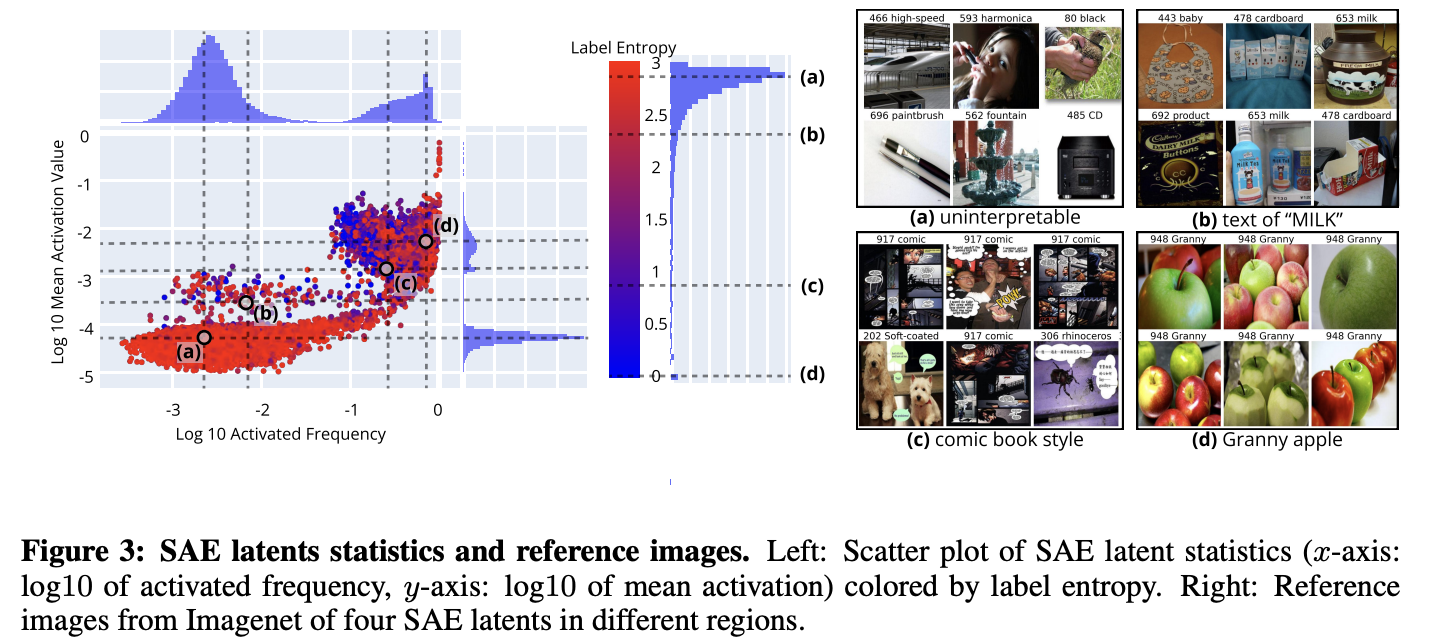 **PatchSAE 可识别丰富多样的可解释概念**。 如图3所示,本文结合统计指标筛选并分析SAE隐变量。实验观察到三类分布集群: 第一类为**激活频率低、激活强度弱**的大规模集群(左下区域); 第二类为**高频激活、高激活强度**的大规模集群(右上区域); 以及位于中心附近的小型集群。 尽管统计特征无法完全保证隐变量可解释,但本文发现了多条规律: 左下区域中大量标签熵较高的隐变量普遍**无法被人类解读**(图3(a)); 而第二大集群(右上区域)中存在大量高可解释性隐单元。 对于可解释隐变量: 标签熵越低(图3(d)),对应语义越专一、特征越明确(例如单一特定类别物体); 标签熵越高(图3(c)),则大多表征参考图像之间的**共有风格、通用纹理**。 同时,本文发现部分**多模态隐变量**,可对图像内的文字内容产生特异性激活。 例如,图3(b)中的隐单元能够专门检测图像中的 “MILK” 文字;更多文字类概念示例见图13。
**PatchSAE 可识别丰富多样的可解释概念**。 如图3所示,本文结合统计指标筛选并分析SAE隐变量。实验观察到三类分布集群: 第一类为**激活频率低、激活强度弱**的大规模集群(左下区域); 第二类为**高频激活、高激活强度**的大规模集群(右上区域); 以及位于中心附近的小型集群。 尽管统计特征无法完全保证隐变量可解释,但本文发现了多条规律: 左下区域中大量标签熵较高的隐变量普遍**无法被人类解读**(图3(a)); 而第二大集群(右上区域)中存在大量高可解释性隐单元。 对于可解释隐变量: 标签熵越低(图3(d)),对应语义越专一、特征越明确(例如单一特定类别物体); 标签熵越高(图3(c)),则大多表征参考图像之间的**共有风格、通用纹理**。 同时,本文发现部分**多模态隐变量**,可对图像内的文字内容产生特异性激活。 例如,图3(b)中的隐单元能够专门检测图像中的 “MILK” 文字;更多文字类概念示例见图13。
**PatchSAE 实现概念的空间归因定位**。 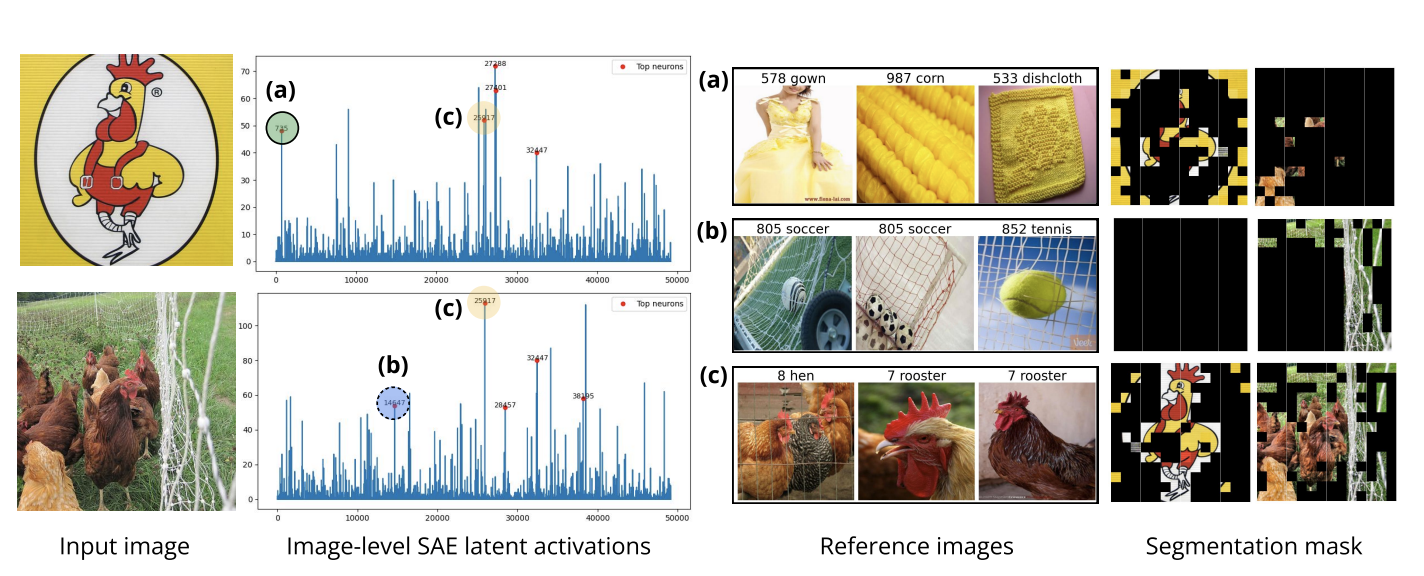 以跨域对比实验为例:图4选取两张**类别相同、域分布不同(协变量偏移)**的图像进行对照。 两张图像共同激活的SAE隐变量,对应共享核心概念「母鸡」(图4(c)),且该概念仅在两张图像的目标主体区域产生局部激活。 二者各自独有的特异性激活隐变量(图4(c)(d)),则分别表征独立差异化概念,如「黄色色调」「网状纹理」等。 模型输出的分割热力图,可精准高亮每个视觉概念对应的关键图像块区域。 **PatchSAE 具备跨数据集泛化能力**。 本文仅使用 ImageNet 训练集训练 PatchSAE,但实验证明: SAE 隐变量学到的可解释概念具备良好迁移性,可泛化至其他陌生数据集。 当目标数据集包含某类视觉概念时,对应SAE隐变量能在不同数据集中稳定提取一致概念; 若数据集不存在该概念,则隐变量平均激活值显著降低,或检索出无明确语义的不可解释图像(附录A.3)。 图10展示了两组SAE隐变量在 ImageNet 与四个细粒度数据集上的参考样例; 图14 展示了各类任务下排名第一的关键隐变量对应的参考图像。
以跨域对比实验为例:图4选取两张**类别相同、域分布不同(协变量偏移)**的图像进行对照。 两张图像共同激活的SAE隐变量,对应共享核心概念「母鸡」(图4(c)),且该概念仅在两张图像的目标主体区域产生局部激活。 二者各自独有的特异性激活隐变量(图4(c)(d)),则分别表征独立差异化概念,如「黄色色调」「网状纹理」等。 模型输出的分割热力图,可精准高亮每个视觉概念对应的关键图像块区域。 **PatchSAE 具备跨数据集泛化能力**。 本文仅使用 ImageNet 训练集训练 PatchSAE,但实验证明: SAE 隐变量学到的可解释概念具备良好迁移性,可泛化至其他陌生数据集。 当目标数据集包含某类视觉概念时,对应SAE隐变量能在不同数据集中稳定提取一致概念; 若数据集不存在该概念,则隐变量平均激活值显著降低,或检索出无明确语义的不可解释图像(附录A.3)。 图10展示了两组SAE隐变量在 ImageNet 与四个细粒度数据集上的参考样例; 图14 展示了各类任务下排名第一的关键隐变量对应的参考图像。
4 基于 PatchSAE 分析 CLIP 模型行为
本章探究**SAE 隐变量**与模型在分类任务中行为表现之间的关联。 通过将模型中间层输出替换为 SAE 重构特征、以及对 SAE 解码器所用隐变量进行消融实验,本文证实:SAE 隐变量中包含**类别判别特征信息**(4.1 节)。 对比下游任务中**适配前后**的 CLIP 模型行为差异,本文阐明:模型性能提升的核心原因,是**建立了 SAE 隐特征与下游任务类别之间的全新映射关系**,而非激活了额外的判别性视觉概念(4.2 节)。
4.1 SAE 隐变量对分类任务的影响
本节探究 SAE 隐变量如何影响分类任务的模型最终预测结果。 本文选择性调用部分 SAE 概念,将 CLIP 图像编码器的中间层表征替换为 SAE 重构输出,以此调控模型预测输出。 随后计算图文编码器输出之间的余弦相似度,完成分类任务。完整流程如图 5(a) 所示。
4.1.1 分析方法与实验设置
零样本分类 基于 OpenAI 官方 CLIP ViT-B/16 模型,在 ImageNet-1K 数据集上开展零样本分类实验(复现细节见附录)。 采用 80 组官方 ImageNet 文本提示模板集成策略,为每个类别生成文本特征; 通过计算图像特征与文本特征的余弦相似度,实现图像分类(见图 5(a))。 #### Top-k SAE 隐变量掩码 为筛选出参与 SAE 解码器线性组合的关键隐变量子集,本文挖掘各类别专属的代表性视觉概念,并采用**类别级激活值**(公式 5)进行筛选。 具体方式:利用各下游任务训练集数据,聚合同一类别下所有图像的 SAE 隐激活,筛选出每一类中**激活频率最高的前 k 个隐变量**。 在隐变量输入解码器前,通过掩码操作控制隐变量的激活状态; 将原始模型表征替换为掩码 SAE 重构后的特征,通过更换不同掩码方案对比分类精度变化: - **启用 Top-k**:独热掩码,仅前 k 个高激活隐变量置为有效(1),其余全部屏蔽(0); - **关闭 Top-k**:全局全量激活掩码,仅屏蔽当前类别前 k 个核心隐变量,其余全部保留。 同时设置对照消融实验:随机选取同等数量隐变量、以及数据集级通用高频隐变量(在数据集所有类别中普遍激活),对比各类掩码策略的性能差异。
4.1.2 核心实验结论 **SAE 隐变量蕴含充足的类别判别信息**。 Top-k 隐变量掩码实验结果如图 5(b)(c) 所示: 1. 启用全部 SAE 隐变量(全量掩码)时,模型分类性能与原模型基本持平,重构误差较小(全量掩码准确率 64.82%,原始模型 68.25%); 2. 全屏蔽所有隐变量(全零掩码)后,关键判别信息完全丢失,准确率仅剩余 0.1%; 3. 随机消融、数据集通用隐变量消融,在屏蔽数量较少时,对分类精度几乎无显著影响; 4. 但**逐类别屏蔽 Top 高激活隐变量**,会严重破坏模型分类能力。 实验同时呈现明显规律:有效 SAE 隐变量数量增加,分类性能上升;有效隐变量减少,性能同步下降。 综上可证:部分 SAE 隐变量承载着**决定类别区分的关键语义信息**; 且这类核心概念,可精准锁定在**同一真值类别样本中高频激活的头部 SAE 隐单元**。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)