LazyLLM 黑科技 | 一个模型名搞定一切:LazyLLM 如何自动识别模型类型?
本文将深入探讨在多模型工程落地中,一个看似不起眼却极度影响开发体验的问题——模型入口的统一与类型识别,并详细解析 LazyLLM 是如何通过优雅的机制解决它的。
1. 背景与问题:模型入口为何"四分五裂"?
在多模型工程里,最先让人头疼的,往往不是模型效果,而是入口不统一。
明明业务逻辑都是“用一个模型处理数据”,但在写代码前,开发者却被迫要先做一堆“选择题”:
- 这是在线 API,还是本地部署部署的模型?
- 这是文本对话(Chat),还是向量化(Embedding),抑或是语音生成(TTS)、多模态(VLM)?
- 不同的能力,对应着不同的类名、不同的参数列表。
更现实的痛点在于工程演进:同一个模型,研发初期为了快,往往在线调用(API);到了生产期为了成本和安全,可能得切成本地私有化部署。 模型没变,业务逻辑没变,但因为底层入口不同,却不得不大改业务代码:改引用的类名、调参数配置、甚至重构调用链。
当模型入口不统一时,这些推断逻辑就会被迫“前置”到业务代码里。这就导致:
- 代码冗长且脆弱:业务代码里充斥着
if isinstance(model, XX)或根据模型名字硬编码的分支。 - 切换成本极高:牵一发而动全身,换个模型供应商,业务层跟着抖动。
- 系统心智负担重:随着模型种类(图、文、音)和数量激增,入口层越复杂,系统越难维护。
2. 业界难点:为何统一入口这么难?
为什么大家不早点把入口统一呢?因为要做好这一层抽象,面临着天然的阻力:
- 形态的割裂:在线模型本质是网络请求(HTTP/RPC),本地模型本质是权重加载+推理框架(vLLM/TensorRT-LLM)。两者的生命周期、资源管理、并发模型完全不同,强行揉在一起容易出现“抽象泄漏”。
- 模态的碎片化:大语言模型(LLM)输入输出是文本;VLM 包含图像;TTS 输入文本输出音频流。不同模态的输入校验、后处理格式千差万别,用一个基类去 cover 所有,很容易变成一个臃肿的“上帝类”。
- 命名规则的无序:开源社区(如 HuggingFace、ModelScope)的模型命名天马行空,没有强约束的标准。如何仅凭一段字符串,就精准猜出它是个什么模态的模型?
3. LazyLLM 的解决方案:两层自动推断,化繁为简
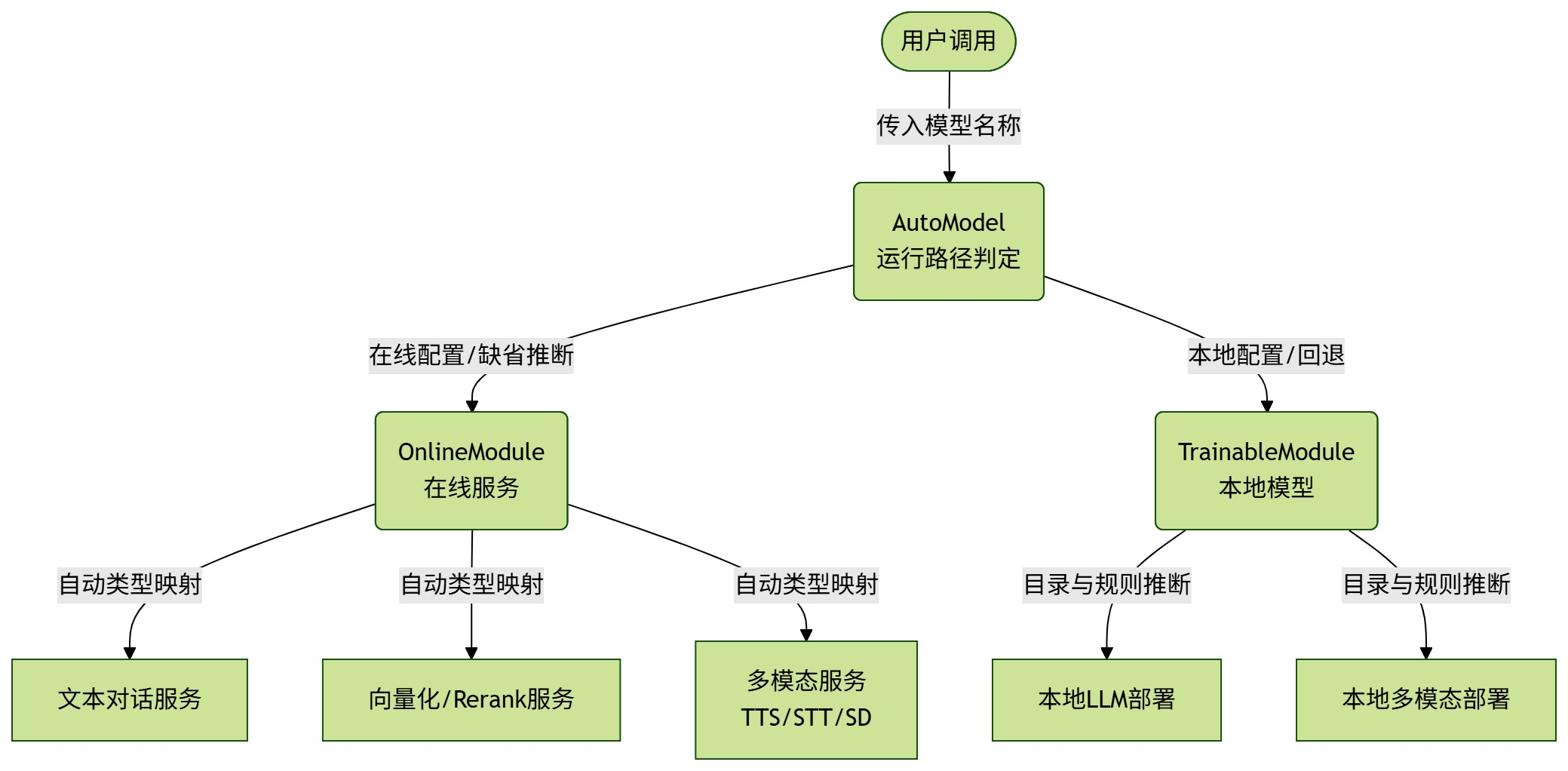
面对上述难题,LazyLLM 的解法是:在模型入口层引入“两层自动推断机制”,将运行方式、能力类型和模型类别的判断全部收敛截留在框架内部。
对用户来说,核心理念只有一句话:你只管给模型名字,其余(本地还是在线?什么模态?怎么跑)全交给框架。
架构设计上,我们将核心入口收敛为 AutoModel,并派生出两条路径:
4. 极致的用户体验:自动推断下的代码示例
在这个设计下,开发者的使用变得极其简单,几乎是真正的“零切换成本”。
示例 1:纯无感调用 你只需传入模型名,它是 API 还是本地,是 LLM 还是 TTS,框架自己懂。
import lazyllm
# 框架推断:这是一个在线大语言模型
model = lazyllm.AutoModel(model="gpt-4o")
print(model("Summarize this paper."))
# 框架推断:这是一个在线文本转语音多模态模型
tts = lazyllm.AutoModel(model="qwen3-tts-flash")
audio_output = tts("你好,世界")
# 框架推断:这是一个向量化模型
embed = lazyllm.AutoModel(model="nova-embedding-stable")
vector = embed("这是一段文本")
示例 2:在线与本地的无缝切换 如果有一天,你想把 GPT-4o 换成自己本地部署的开源模型。
# 昨天:调用在线的 Qwen
chat = lazyllm.AutoModel(model="qwen-plus")
# 今天:老板说要私有化,换成本地部署的 Qwen 权重
# 只要改名字(如果本地配置了映射),或者显式声明来源
chat = lazyllm.AutoModel(model="qwen2.5-7b-instruct", source="local")
# 业务调用代码完全不变!
chat("hello")
5. 技术剖析:我们是如何做到的?
底层看似神奇的“魔法”,源于我们精心设计的匹配规则与责任链模式。让我们结合 LazyLLM 的源码来看看。
5.1 第一层:AutoModel 运行路径判定 (环境与配置感知)
AutoModel 的首要任务是决定走 TrainableModule(本地)还是 OnlineModule(在线)。 在 lazyllm/module/llms/automodel.py 中,我们的判断并不是粗暴的 if-else,而是一套基于配置和环境感知的优先级推断:
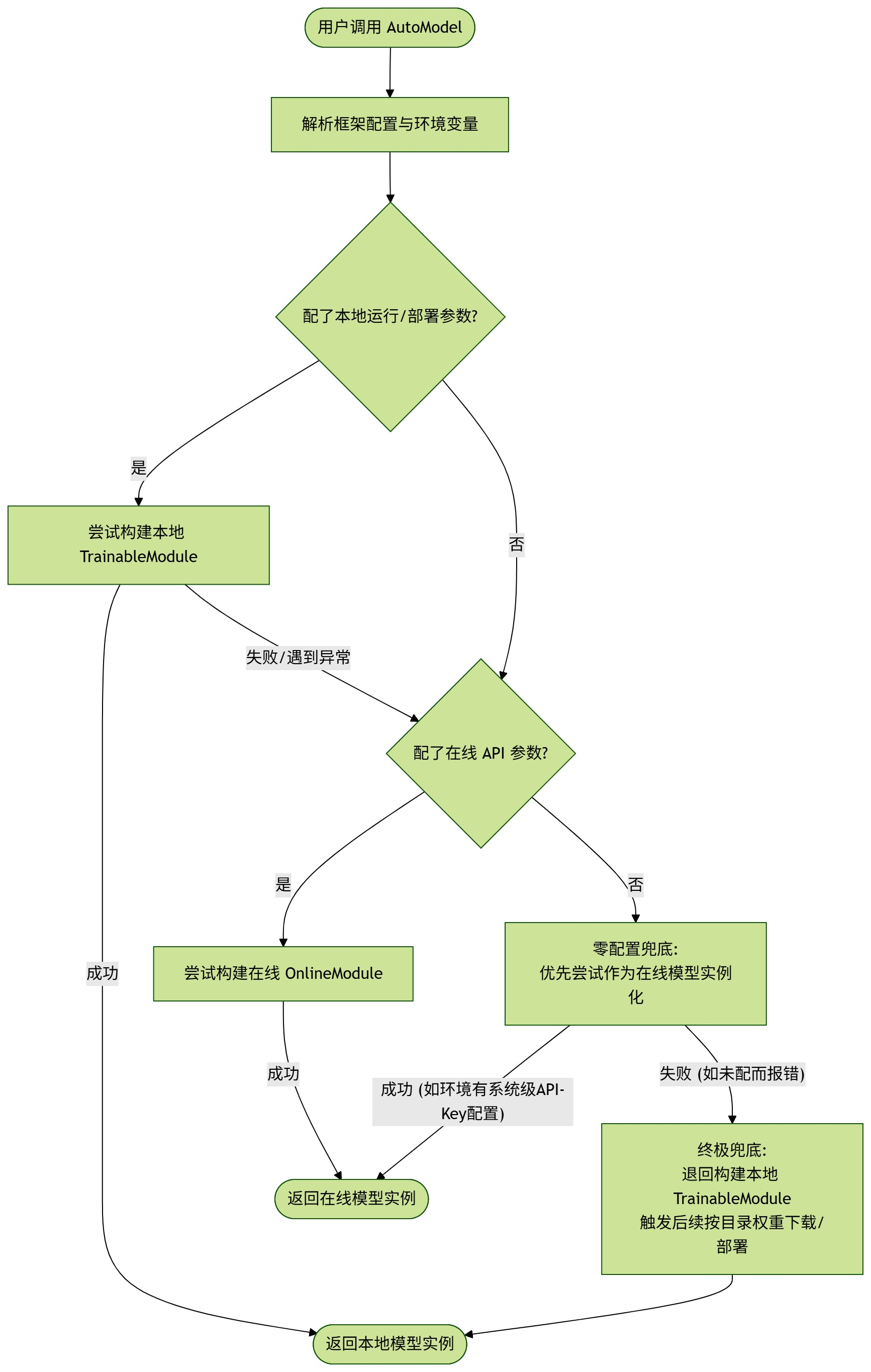
- 配置优先尝试本地:去检查环境里有没有该模型的本地运行部署配置(
framework、deploy_config等),如果有,尝试构建TrainableModule。 - 在线配置兜底:如果在本地配置没找到或者失败了,尝试去匹配在线的 API 配置,构建
OnlineModule。 - 无配置回退:如果用户啥都没配,我们优先尝试作为在线模型去实例化(因为成本最低),如果报错(比如没配 Token),则最终回退到本地模型进行自动下载和部署。
这种设计确保了开发者配置的明确意图最高,同时在零配置下具备较强的容错生存能力。
5.2 第二层左路:OnlineModule 的在线能力映射
判定为在线模型后,进入 OnlineModule (lazyllm/module/llms/online_module.py)。它需要知道怎么组装 HTTP 请求,这就需要知道模型到底是什么类型(Type)。
如果用户没指明 type,引擎会调用 get_model_type(model)。在 map_model_type.py 中,我们维护了一个精密的映射与降级机制:
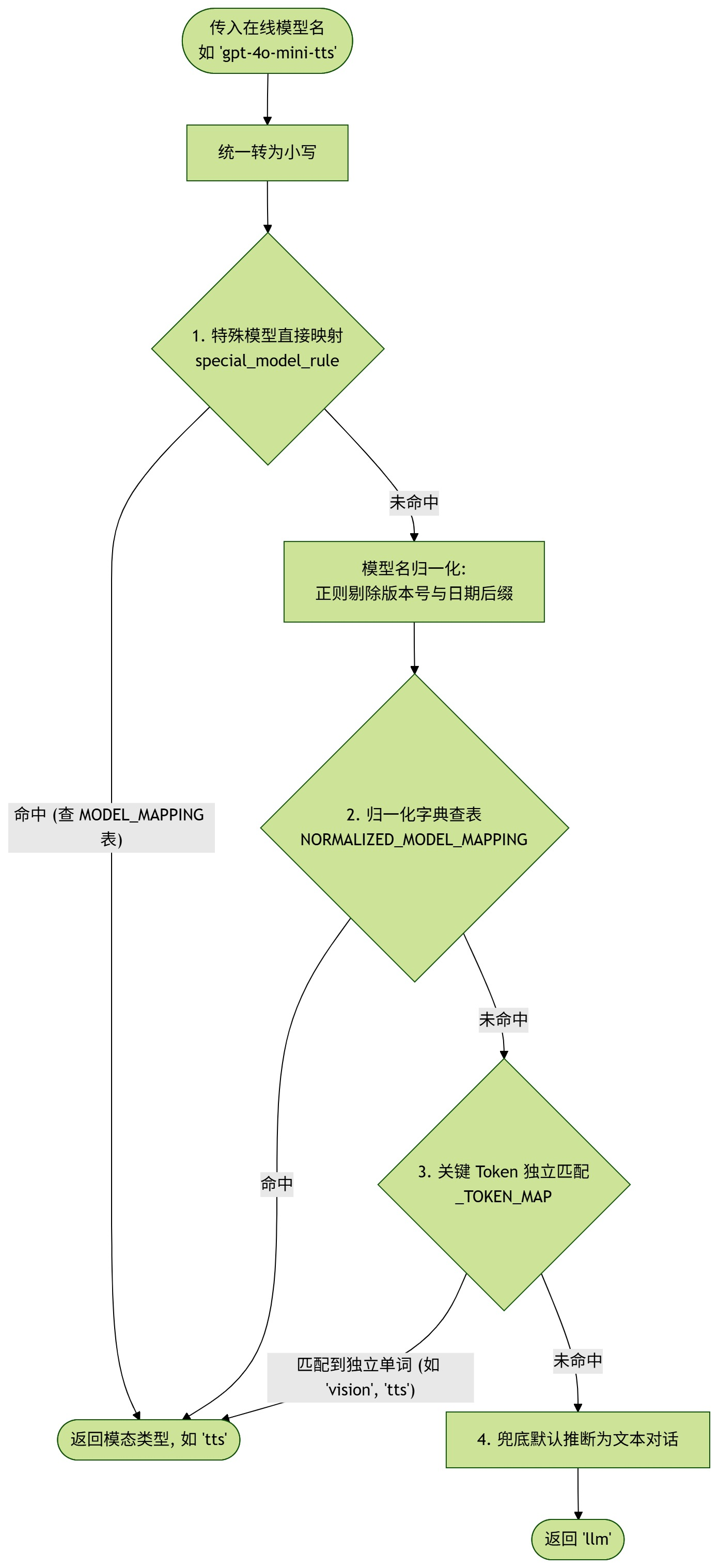
源码亮点:
为了应对厂商频繁发版(比如加时间戳),我们做了归一化处理 (_normalize_key),利用正则 (?:|[-_.]\d{4}(?:-\d{2}-\d{2})?|[-_.]v?\d+[a-z0-9\-]*)+$ 自动剥离模型名后缀的版本号和日期,大幅提高了基于关键词(如 vision, asr, tts)的命中率。
5.3 第二层右路:TrainableModule 的本地模型类型推测
如果是本地模型(需要下载、加载权重),它的推断在 lazyllm/components/utils/downloader/model_directory.py 中的 infer_model_type 函数完成。
由于开源社区模型浩如烟海,我们设计了严格的三级分层嗅探规则:
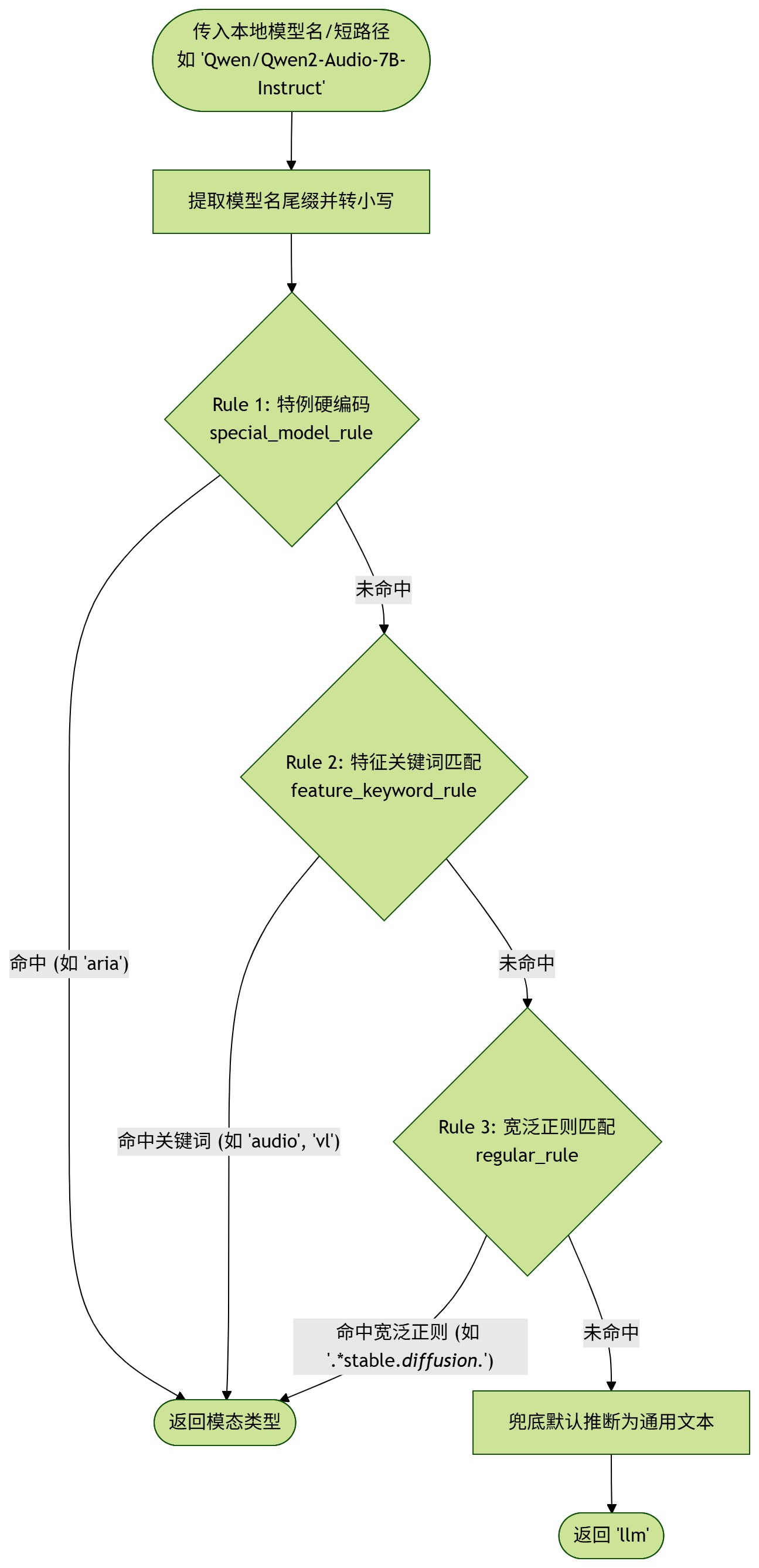
- Rule 1 - special_model_rule (特例硬编码):有一些模型名字非常个性,不包含任何模态特征(如
minicpm-2b-dpo-bf16,aria)。我们用硬编码集合优先拦截。 - Rule 2 -feature_keyword_rule (特征关键词匹配):通过检索模型名切片后的关键字。比如包含
vl,pixtral,cogagent归类为 VLM(视觉语言),包含music归类为 TTS。 (细节:我们会按关键词长度降序排序再匹配,防止大词被小词截胡) - Rule 3 - regular_rule (宽泛正则匹配):使用正则表达式兜底。例如
r'.*stable.*diffusion.*'识别 SD 模型,r'.*clip.*'识别跨模态嵌入模型。
# 摘自 lazyllm/components/utils/downloader/model_directory.py
def infer_model_type(model_name: str) -> str:
# 责任链模式,依次尝试三种规则
for rule in [special_model_rule, feature_keyword_rule, regular_rule]:
try:
result = rule(model_name)
if result is not None:
LOG.info(f'Model: {model_name} classified as type: {result} by rule: {rule.__name__}')
return result
except Exception as e:
continue
# 终极兜底
LOG.warning(f'Cannot classify model type for: {model_name}. Defaulting to "llm" instead.')
return 'llm'
拿到准确的 Type 后,后续的权重下载分发、TrainableModule 对本地推理引擎(如 vLLM 对 LLM,或特定 Pipeline 对多模态)的选择,也就水到渠成了。
结语
简单的一句 lazyllm.AutoModel("model_name") 背后,包含了 LazyLLM 对多模型生态乱象的深入思考与抽象。 通过环境感知、精确映射、正则嗅探与责任链机制,我们替开发者扛下了所有恶心的脏活累活。这就让 LazyLLM 的应用具有了极强的重构能力与生命力。
把复杂留给框架,把简单还给业务,这就是 LazyLLM 构建 AI 应用的哲学。
欢迎升级体验 LazyLLM 最新版本,请大家去 github 上点一个免费的 star,支持一下~
LazyLLM 项目仓库链接🔗:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)