基于 PASCAL VOC 2012 的多标签图像分类实验:ConvNeXt V2 Base 模型优化与鲁棒性分析
摘要

PASCAL VOC 2012 是计算机视觉领域经典数据集,广泛用于图像分类、目标检测和语义分割等任务。与普通单标签分类不同,VOC2012 中一张图像可能同时包含多个目标类别,例如 person、dog、chair 等,因此模型需要同时判断 20 个类别是否存在,而不是只输出一个类别。
本文围绕 PASCAL VOC 2012 多标签图像分类任务,构建并优化了一套基于 ConvNeXt V2 Base 的图像分类模型。相比早期使用的 ConvNeXt V2 Tiny 和 Focal Loss 方案,最终优化后的模型采用 ConvNeXt V2 Base + 448×448 高分辨率输入 + ImageNet-22K / FCMAE 预训练 + Asymmetric Loss + 鲁棒数据增强策略,在验证集上取得了当前最佳结果:
最高 mAP = 0.965实验表明,ConvNeXt V2 Base 在更大输入分辨率和 ASL 多标签损失函数配合下,能够更充分地学习复杂场景中的多目标语义信息,对尺度变化、遮挡、模糊和噪声干扰也具有较好的鲁棒性。
1. 任务说明
在普通图像分类任务中,一张图片通常只对应一个类别。例如:
一张猫的图片 -> cat
一张狗的图片 -> dog
一张汽车的图片 -> car但 PASCAL VOC 2012 的图像分类任务并不是这种单标签分类。VOC 图像往往来自真实场景,一张图中可能同时出现多个目标,例如:
person + bicycle
bus + person
train + pottedplant
cow + sheep
car + person + chair因此,模型的输出不能是一个类别编号,而应该是一个长度为 20 的概率向量:
[p_aeroplane, p_bicycle, p_bird, ..., p_tvmonitor]其中每一个位置表示该类别在图像中是否存在。例如:
[aeroplane, bicycle, bird, ..., person, tvmonitor]
[0.01, 0.82, 0.03, ..., 0.91, 0.76]如果某一类别的概率大于设定阈值,例如 0.5,则认为该图像中包含该类别。
这也决定了本任务不能简单使用 Softmax 分类,而应采用:
Sigmoid + 多标签损失函数例如:
- BCEWithLogitsLoss
- Focal Loss
- Asymmetric Loss
同时,评价指标也不能只看 Accuracy,还需要重点关注:
- mAP
- AUC
- Precision
- Recall
- F1-score
- subset accuracy
其中,mAP 是 VOC 多标签分类任务中最核心的指标之一。
2. 数据集结构
本文使用 PASCAL VOC 2012 官方目录结构:
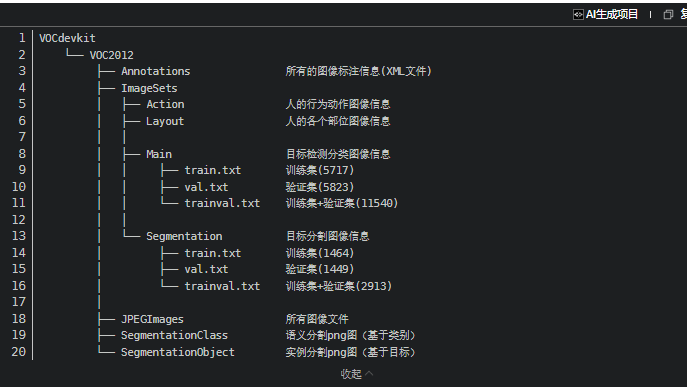
VOC2012 分类标签不是一个单独的 CSV 文件,而是每个类别一个 txt 文件。例如:
ImageSets/Main/person_train.txt ImageSets/Main/dog_train.txt ImageSets/Main/car_train.txt
文件内容格式如下:
2007_000033 1 2007_000042 -1 2007_000061 1
其中:
1 表示该图片包含该类别 -1 表示该图片不包含该类别
因此需要把 20 个类别文件合并成一个 20 维 one-hot / multi-hot 标签:
[0, 1, 0, 0, ..., 1]
3. 类别定义
VOC2012 图像分类共 20 类:
VOC_CLASSES = (
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor",
)这些类别可以大致分为几组:
交通工具类:aeroplane, bicycle, boat, bus, car, motorbike, train
动物类:bird, cat, cow, dog, horse, sheep
室内物体类:bottle, chair, diningtable, pottedplant, sofa, tvmonitor
人物类:person
这种类别设计也使 VOC2012 更贴近真实场景,因为真实图片中通常存在多个物体,而不是只有单一目标。
PASCAL VOC 2012 的一个重要特点是:一张图像中可能同时包含多个目标类别。
例如,一张图片中可能同时出现:
- person + bicycle
- bus + person
- train + pottedplant
- cow + sheep
因此,该任务并不是简单的单分类问题,而是典型的多标签图像分类任务。
在多标签分类中,模型需要对每一个类别分别输出一个概率值,例如:
[aeroplane, bicycle, bird, ..., tvmonitor]
[0.01, 0.82, 0.03, ..., 0.76]然后根据阈值判断每个类别是否存在。
这也意味着,模型的评价指标不能只看 Accuracy,还需要综合考虑:
- mAP
- F1-score
- Precision
- Recall
- subset accuracy
- AUC
4. 数据读取思路
核心代码在 datasets.py 中,主要做三件事:
-
自动定位 VOC 根目录。
-
读取
ImageSets/Main/train.txt或val.txt获取图片 ID。 -
遍历 20 个类别的
{class}_{split}.txt,把1/-1转成1/0。
关键代码如下:
labels = {
image_id: torch.zeros(len(VOC_CLASSES), dtype=torch.float32)
for image_id in image_ids
}
for class_idx, class_name in enumerate(VOC_CLASSES):
class_file = self.main_dir / f"{class_name}_{image_set}.txt"
with class_file.open("r", encoding="utf-8") as f:
for line in f:
image_id, target = line.strip().split()[0], int(line.strip().split()[-1])
if image_id in labels:
labels[image_id][class_idx] = 1.0 if target == 1 else 0.0图片读取:
def __getitem__(self, index):
image_path, target = self.samples[index]
image = Image.open(image_path).convert("RGB")
if self.transform is not None:
image = self.transform(image)
return image, target.clone()该设计的好处是:每张图片最终都能对应一个固定长度的 20 维标签向量,方便模型使用 BCEWithLogitsLoss 或 Focal Loss 进行多标签训练。
5. 模型选择
ConvNeXt 系列可以理解为一种“现代化卷积神经网络”。它保留了 CNN 的局部感受野、层级特征提取和高效推理优势,同时吸收了 Transformer 时代的一些设计思想,例如:
- 更大的卷积核;
- 更简洁的模块结构;
- 更合理的归一化设计;
- 更强的特征表达能力;
- 更适合大规模预训练。
ConvNeXt V2 在 ConvNeXt 的基础上进一步引入了:
FCMAE: Fully Convolutional Masked Autoencoder
GRN: Global Response Normalization其中,FCMAE 可以让卷积网络也具备类似 Masked Autoencoder 的自监督预训练能力;GRN 则用于增强通道之间的特征竞争,缓解特征塌缩问题,从而提升视觉表征质量。
对于 VOC2012 这类多标签任务,ConvNeXt V2 Base 的优势主要体现在三方面。
第一,更强的多尺度目标表达能力。
VOC 图像中目标尺度差异明显。例如:
bottle、bird、pottedplant 通常较小;
bus、train、aeroplane 通常较大;
person、dog、cat 可能以不同尺度出现。448×448 的输入尺寸可以保留更多细节信息,尤其对小目标类别更友好。
第二,更强的复杂背景建模能力。
VOC 图像不是干净背景下的单目标图片,而是真实环境下的复杂图像。例如:
街景、室内、草地、车站、道路、家庭场景ConvNeXt V2 Base 相比 Tiny 具有更大的模型容量,可以更好地区分目标主体和背景纹理。
第三,更适合多标签语义共现学习。
VOC 中某些类别之间存在明显共现关系。例如:
person + bicycle
person + horse
person + motorbike
bus + car
chair + diningtable模型不仅要识别单个目标,还要理解多个类别之间的上下文关系。更强的 Backbone 能够提升这种复杂语义关系的建模能力。
本文使用 timm 创建 ConvNeXtV2 模型:
self.backbone = timm.create_model(
backbone,
pretrained=pretrained and not local_pretrained_file,
num_classes=0,
global_pool="avg",
)Convnext模型架构图:
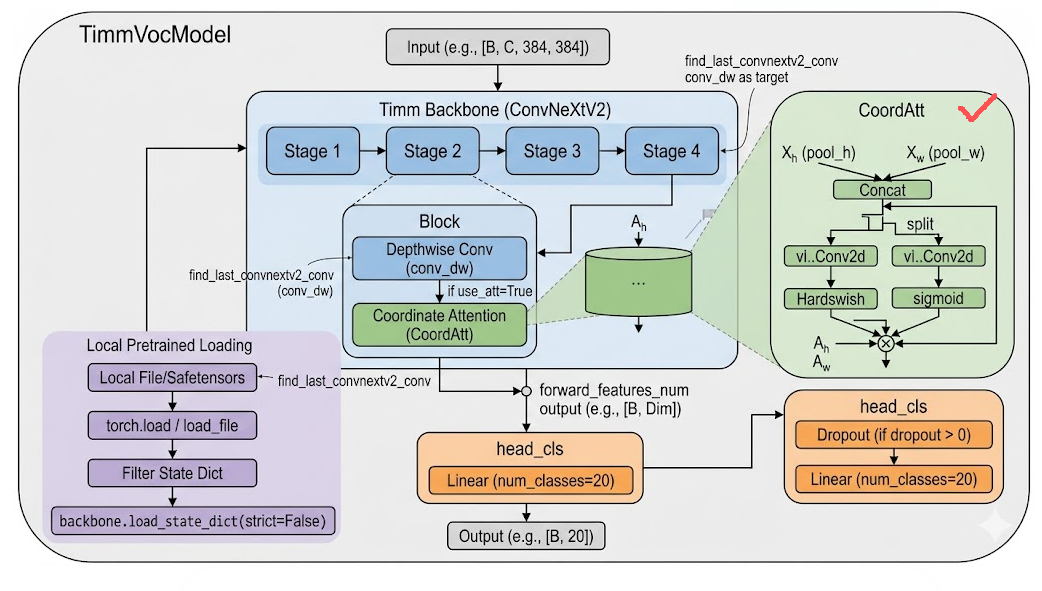
由于 VOC 2012 是 20 类多标签分类任务,因此模型最后的分类层输出维度设置为:
num_classes = 206.损失函数对比
在多标签分类任务中,损失函数对模型效果影响很大。本实验主要尝试了三类损失函数:
Focal Loss
BCEWithLogitsLoss(pos_weight)
Asymmetric Loss6.1 Focal Loss
Focal Loss 的核心思想是降低简单样本的损失权重,提高困难样本的关注度。
它适合处理类别不均衡问题,尤其是在负样本远多于正样本的情况下。
在 VOC2012 中,不同类别数量差异明显。例如:
person 类样本较多;
sofa、sheep、pottedplant 等类别样本较少。因此,Focal Loss 在早期实验中能够提升模型对困难类别的关注。
但实验也发现,如果 Focal Loss 与过强数据增强、较高阈值组合使用,模型后期可能会变得过于保守,出现:
预测正类数量减少;
Recall 下降;
部分真实类别被漏检。这说明 Focal Loss 虽然能处理困难样本,但在多标签任务中仍需要谨慎设置参数。
6.2 BCEWithLogitsLoss(pos_weight)
之后实验尝试使用:
BCEWithLogitsLoss(pos_weight)它是多标签分类中非常常见的损失函数。
其中 pos_weight 可以提高正样本权重,缓解正负样本不均衡问题。
该版本的实验配置为:
Loss: FocalLoss -> BCEWithLogitsLoss(pos_weight)
threshold: 0.5
RandomResizedCrop scale: (0.50, 1.0) -> (0.75, 1.0)
RandAugment: 关闭
ColorJitter: 0.05
RandomErasing: 0.0实验结果为:
mAP: 93.071
acc: 98.192
subset_acc: 71.922
F1: 88.102
precision: 83.399
recall: 93.366
loss: 0.051这个版本的特点是 Recall 较高,说明模型更倾向于预测正类,但 Precision 相对较低,说明误报也有所增加。
6.3 Asymmetric Loss
最终较优版本采用了 Asymmetric Loss,即 ASL。
ASL 是多标签分类任务中非常适合长尾分布和正负样本不均衡问题的损失函数。它的核心思想是:
对正样本和负样本采用非对称处理。在多标签分类中,一张图像通常只包含少数几个正类别,而剩下的大部分类别都是负类别。也就是说,负样本数量远大于正样本数量。
如果所有负样本都同等参与训练,模型很容易被大量简单负样本主导,导致正样本学习不足。
ASL 的典型参数如下:
gamma_neg = 4
gamma_pos = 0
clip = 0.05含义如下:
| 参数 | 作用 |
|---|---|
| gamma_neg | 抑制大量简单负样本 |
| gamma_pos | 保持正样本学习强度 |
| clip | 对负样本概率进行裁剪,提高训练稳定性 |
ASL 相比 BCE 和 Focal Loss 的优势在于,它更加符合 VOC 多标签分类的样本分布特点:既要关注正样本,又不能让大量简单负样本主导训练。
这也是最终模型 mAP 能够提升到 0.965 的重要原因之一。
7. 数据增强策略
数据增强是本实验中影响模型性能的关键因素之一。早期实验表明,增强并不是越强越好。过强的数据增强可能会破坏目标主体,导致模型学习到背景伪特征。
当前最优版本采用了更加稳定的鲁棒数据增强策略。
7.1 几何鲁棒性控制
1. 随机裁剪与缩放 RandomResizedCrop
RandomResizedCrop 用于模拟目标远近变化,缓解 VOC 数据集中目标尺度不一致的问题。
VOC2012 中同一类别可能出现在不同尺度下。例如:
远处的小 person;
近景的大 dog;
占据大部分画面的 bus;
图像边缘的小 bottle。通过随机裁剪和缩放,模型能够学习不同尺度下的目标特征。
但需要注意的是,RandomResizedCrop 不能过强。早期使用过:
RandomResizedCrop scale=(0.08, 1.0)这会导致图像可能只保留极小区域,目标主体被裁掉,模型容易学习背景或局部纹理。后续将其调整为更合理的范围,使模型在保留主体结构的同时获得尺度鲁棒性。
2. 仿射变换 Affine
仿射变换主要包含旋转、平移和缩放。本实验使用:
旋转:±25°
平移与缩放:±15%该策略用于增强模型对物体姿态变化的适应能力。
真实图像中,目标通常不会以标准角度出现。例如:
bicycle 可能倾斜;
aeroplane 可能存在拍摄角度变化;
cat、dog、horse 的姿态差异较大;
person 的动作和方向变化明显。适度的 Affine 变换可以提升模型对这些变化的鲁棒性。
3. 水平翻转 Horizontal Flip
水平翻转是图像分类中非常常用且稳定的数据增强方式。
对于 VOC 中的大多数类别,例如:
car, bus, train, bicycle, person, dog, cat左右翻转不会改变类别语义,因此可以有效扩展样本分布,提高泛化能力。
7.2 环境适应力增强
色彩抖动组合 OneOf
VOC2012 图像来源复杂,光照条件差异明显。图像可能来自:
室内场景;
户外街景;
晴天;
阴天;
夜晚;
不同相机设备。因此,本实验使用 OneOf 色彩扰动组合,随机调整:
- 亮度;
- 对比度;
- 饱和度;
- 色相。
该策略可以减少模型对固定颜色分布的依赖,使模型更加关注目标的结构和语义信息,而不是简单依赖颜色。
7.3 遮挡处理与正则化
1. 随机区域擦除 CoarseDropout
CoarseDropout 会随机遮挡图像中的一部分区域,迫使模型学习更加完整、分散和鲁棒的目标特征。
例如,如果模型只依赖:
dog 的头部;
car 的车灯;
bus 的车窗;
train 的局部边缘;
person 的脸部区域。那么一旦这些区域被遮挡,模型就可能预测失败。
加入 CoarseDropout 后,模型不能只依赖单一局部区域,而需要结合更多上下文和整体结构进行判断。
2. 标准化 Normalize
训练集图像使用 ImageNet 均值和方差进行标准化:
Normalize标准化的作用包括:
统一输入分布;
加快模型收敛;
适配 ImageNet-22K / FCMAE 预训练权重;
减少亮度和颜色差异带来的影响。8.Convnext-tiny实验版本对比分析
8.1 ConvNeXtV2 V3 版本
数据增强
RandomResizedCrop scale=(0.08, 1.0) RandAugment rand-m9-mstd0.5-inc1 ColorJitter 0.4 RandomErasing p=0.25
inputsize(448)实验配置:
dropout = 0.5
batch_size = 8
epochs = 20
lr = 3e-5
warmup_epochs = 3
weight_decay = 0.1
head_dropout = 0.5
early_stop_patience = 5
loss = focal测试结果:
test_mAP: 94.2824
test_acc: 98.2998
test_subset_acc: 73.5875
test_f1: 88.7551
test_precision: 84.4118
test_recall: 93.5696该版本的 Recall 较高,说明模型能够较好地识别正类目标,但仍存在部分误判问题。
8.2 ConvNeXtV2 V4 版本
V4 版本主要改动是更换数据增强策略。
原增强:
RandomResizedCrop scale=(0.08, 1.0) RandAugment rand-m9-mstd0.5-inc1 ColorJitter 0.4 RandomErasing p=0.25新增强 failure_aware:
RandomResizedCrop scale=(0.50, 1.0) RandAugment rand-m5-mstd0.5-inc1 ColorJitter 0.2 RandomErasing p=0.05测试结果:
test_mAP: 93.4317
test_acc: 98.6510
test_subset_acc: 78.3960
test_f1: 90.4527
test_precision: 91.8312
test_recall: 89.1151与 V3 相比:
| 指标 | V3 | V4 |
|---|---|---|
| mAP | 94.28 | 93.43 |
| Accuracy | 98.30 | 98.65 |
| Subset Accuracy | 73.59 | 78.40 |
| F1 | 88.76 | 90.45 |
| Precision | 84.41 | 91.83 |
| Recall | 93.57 | 89.12 |
可以看出,V4 版本的 Precision 和 F1 明显提升,说明模型误判正类的情况减少,但 Recall 略有下降。
8.3 ConvNeXtV2 V5 版本
V5 版本将损失函数从 Focal Loss 改为 BCEWithLogitsLoss(pos_weight),并固定阈值为 0.5。
实验结果:
mAP: 93.071
acc: 98.192
subset_acc: 71.922
F1: 88.102
precision: 83.399
recall: 93.366
loss: 0.051该版本 Recall 较高,但 Precision 相对较低,说明模型倾向于预测更多正类。
8.4 ConvNeXtV2 V6 多头分类实验
V6 版本尝试了 20 个类别分别使用分类头,即:
20 个分类头 交叉熵损失函数并比较了两种损失聚合方式:
- loss mean
- loss sum
实验中发现,loss sum 的表现更优。
其中较优结果为:
mAP: 93.6089
test_auc: 99.3401
test_acc: 98.5686从实验曲线来看,loss sum 与 loss mean 在 Recall、F1、Precision 上整体差异不大,但 loss sum 在部分类别上表现更稳定。
9. 最高性能版本:mAP 达到 0.965
最终,经过对tiny的调优只能达到mAP最高94%.于是我们提升了模型参数并且通过优化模型结构、损失函数和增强策略,实验取得了当前最佳结果:
最高 mAP: 0.965最终版本的核心优化包括:
- 使用更强的 ConvNeXtV2 -Base主干;
- 使用 ImageNet-22K / FCMAE 预训练权重;
- 输入尺寸提升到 448 × 448;
- 使用 ASL 损失函数;
- 使用 AdamW 优化器;
- 引入 Cosine Annealing 学习率策略;
- 开启 AMP 混合精度训练;
- 数据增强从强增强调整为更稳定的鲁棒增强。
10 鲁棒性测试
为了验证模型在复杂测试环境下的稳定性,实验进一步设计了测试集扰动实验。
主要测试了以下四种场景:
| 测试场景 | 含义 |
|---|---|
| clean | 原始图像 |
| noise | 添加噪声 |
| blur | 图像模糊 |
| occlusion | 随机遮挡 |
从鲁棒性测试曲线可以看出,模型在加噪声、模糊和遮挡条件下的 AUC 下降幅度较小。
对应结果大致如下:
clean: 99.19
noise: 接近 clean
blur: 略低于 clean
occlusion: 98.78 左右这说明当前模型不仅在原始测试集上表现较好,在轻度图像退化条件下也具有较强的稳定性。
11. 结果图展示
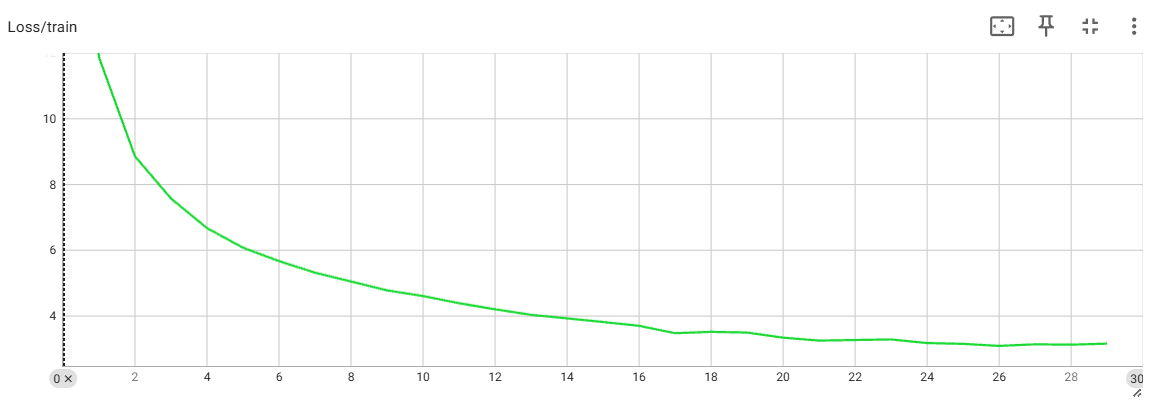
11.1 Loss 曲线
Loss 曲线用于观察训练损失和验证损失变化。如果训练 loss 下降而验证 loss 上升,说明模型可能开始过拟合。
11.2 学习率曲线
本文使用 Cosine LR scheduler。曲线一般表现为 warmup 阶段学习率上升,之后按余弦逐步下降。
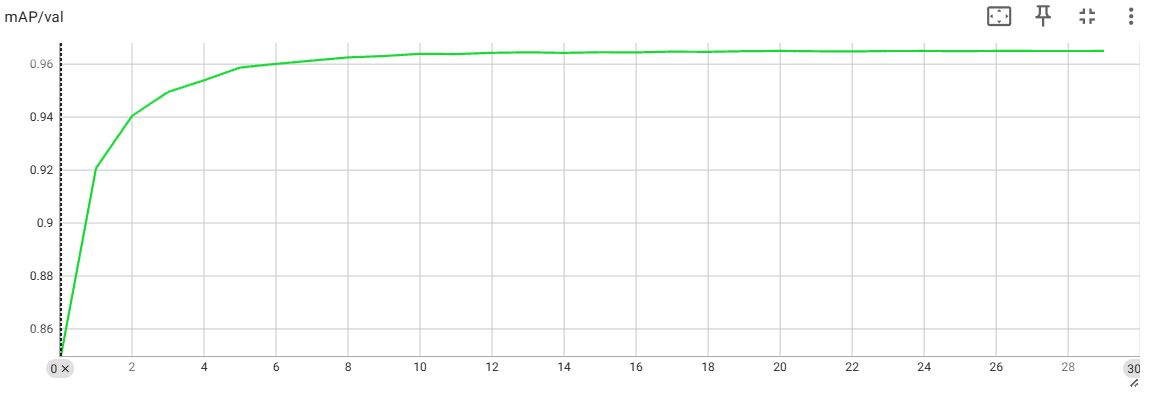
11.3 mAP 指标曲线
11.4 最新 epoch 鲁棒性 AUC 柱状图
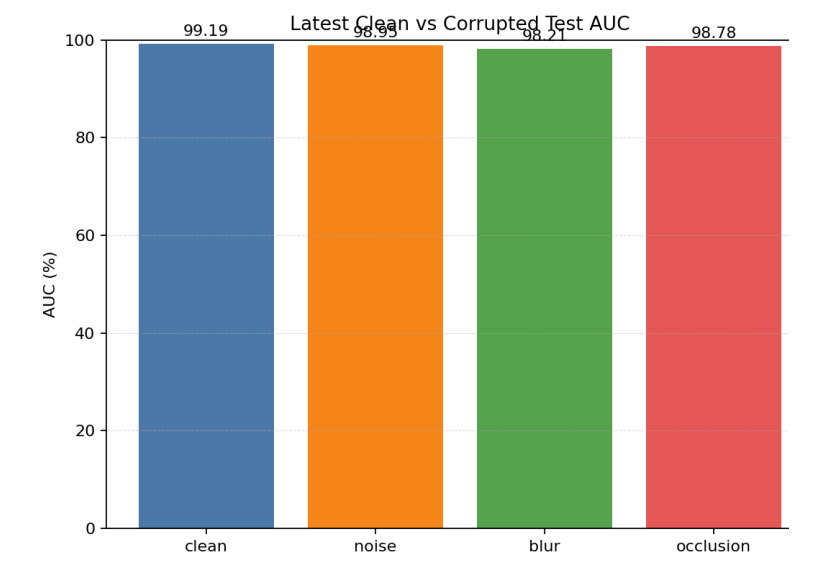
该图对比最后一轮在原图、噪声图、模糊图和遮挡图上的 AUC。
通常:
-
clean AUC 高,说明原始验证集效果好。
-
noise AUC 降低,说明模型对噪声敏感。
-
blur AUC 降低,说明模型依赖纹理或边缘细节。
-
occlusion AUC 降低,说明模型对目标局部缺失较敏感。
12. 鲁棒性测试实现
本文在验证集基础上构造三个扰动版本:
def corrupt_image(image, corruption, args):
if corruption == "noise":
array = np.asarray(image).astype(np.float32) / 255.0
noise = np.random.normal(0.0, args.noise_std, size=array.shape)
array = np.clip(array + noise, 0.0, 1.0)
return Image.fromarray((array * 255).astype(np.uint8))
if corruption == "blur":
return image.filter(ImageFilter.GaussianBlur(radius=args.blur_radius))
if corruption == "occlusion":
occluded = image.copy()
draw = ImageDraw.Draw(occluded)
width, height = occluded.size
box_w = int(width * args.occlusion_ratio)
box_h = int(height * args.occlusion_ratio)
x0 = (width - box_w) // 2
y0 = (height - box_h) // 2
draw.rectangle((x0, y0, x0 + box_w, y0 + box_h), fill=(0, 0, 0))
return occluded训练时每轮验证后,会额外评估:
for corruption, robust_loader in robust_loaders.items():
stats = evaluate_multilabel(
robust_loader, model, device, args.use_amp, args.threshold
)
robust_stats[f"robust_{corruption}_auc"] = stats.get("auc", 0.0)
robust_stats[f"robust_{corruption}_mAP"] = stats.get("mAP", 0.0)13. Grad-CAM 可视化
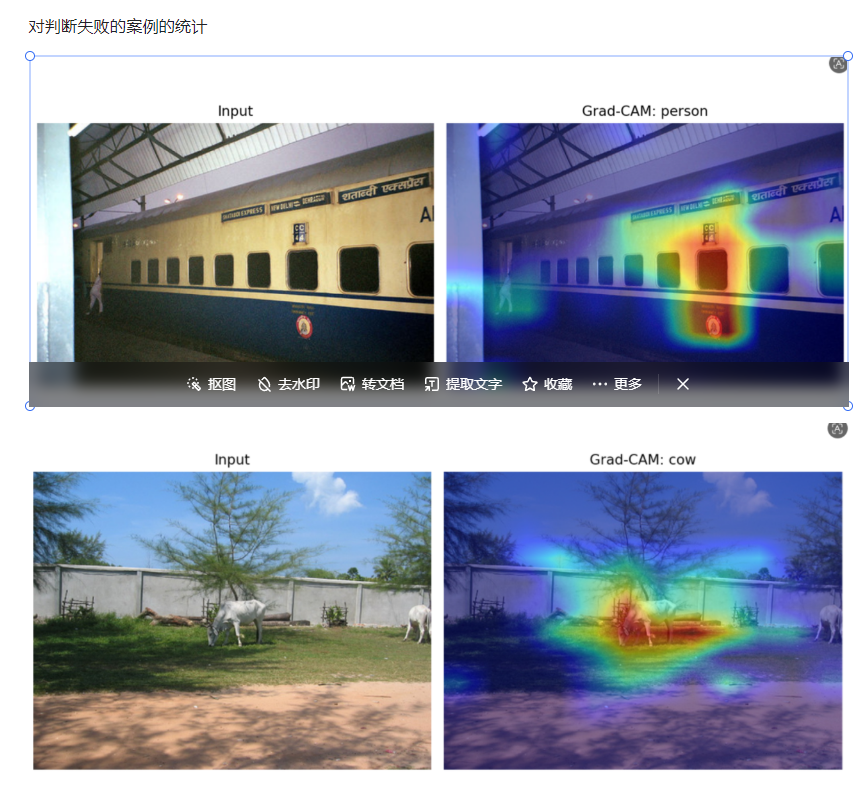
Grad-CAM 用于观察模型关注的图像区域。对于分类任务,它可以帮助判断模型是否真正关注到了目标本体,而不是背景或上下文。
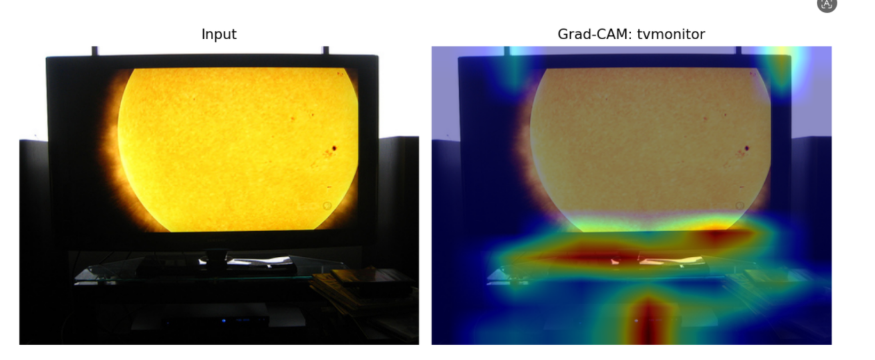
失败样本会额外保存原图摘要和 Grad-CAM 图,方便分析模型为什么出错。
14. 单张图片预测
训练结束后可以使用单图预测脚本:
python convnextv2_voc_aug/predict.py \ --image VOCdevkit/VOC2012/JPEGImages/2007_000033.jpg \ --checkpoint outputs/convnextv2_tiny_voc_focal_baseline_robust/checkpoint-best.pth \ --backbone convnextv2_tiny.fcmae_ft_in22k_in1k_384 \ --threshold 0.5
预测逻辑:
scores = model(tensor).sigmoid()[0].cpu()
positives = [
(VOC_CLASSES[i], scores[i].item())
for i in range(len(VOC_CLASSES))
if scores[i].item() >= args.threshold
]如果某个类别的 sigmoid 概率大于阈值,就认为图片中包含该类别。
15. 实验总结
本实验从 ConvNeXt V2 Tiny 逐步优化到 ConvNeXt V2 Base,最终取得 mAP 0.965。整个过程可以总结为以下几点。
15.1 VOC 标签读取必须按多标签处理
VOC2012 最容易出错的地方是标签读取。不能把每张图片简单看成单标签样本,而必须将每个类别的 txt 文件合并成 20 维 multi-hot 标签。
只有标签构建正确,后面的 mAP、AUC、F1、Precision、Recall 才有意义。
15.2 数据增强不是越强越好
早期过强增强会破坏目标主体,使模型学习到背景伪特征。
更合理的增强策略应该是:
保留目标主体;
模拟真实尺度变化;
模拟合理姿态变化;
模拟光照变化;
适度遮挡。也就是说,增强的目标不是“把图像变得越复杂越好”,而是让训练分布更接近真实测试分布。
15.3 多标签任务更适合 ASL
BCEWithLogitsLoss 是多标签分类的基础方案,Focal Loss 可以缓解困难样本问题,但 ASL 更适合 VOC 这种正负样本极不均衡的多标签任务。
ASL 能够有效抑制大量简单负样本,使模型更加关注正类别和困难类别。
15.4 高分辨率输入对小目标有帮助
448×448 输入相比 384×384 能保留更多细节,对 VOC 中的小目标类别更友好。
特别是:
bottle
bird
chair
pottedplant
person这些类别容易受到尺度和背景影响,高分辨率输入能够改善识别效果。
16 代码链接
ConvNeXt V2 Base所有文件已成功上传到 GitHub 仓库,您可以在此库内容(README.md、config.py、dataset(1).py、loss.py、model.py、predect.py、tensorbard.sh、train.py 和 utils.py):
GitHub 仓库链接: https://github.com/nickyang708/voc-convnextv2

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)