基于轻量级神经网络的人群计数:一个文献综述
摘要
人群计数是指估计特定区域内的人数的任务,它提供了对人群动态和分布的见解。该任务在公共安全、城市规划、交通管理等领域有着广泛的应用。深度学习的最新进展,特别是卷积神经网络和Transformer架构,以及多模态预训练模型,如CLIP和SAM,大幅提高了计数精度。然而,现有的模型主要是基于高复杂度的架构进行设计的,这会带来巨大的计算和数据需求,并阻碍实时部署和增加成本。 因此,轻量级的人群计数方法已经成为一个关键的研究方向,其目的是在保持高性能的同时减少参数和推理时间。在本次调查中,我们总结了公开可用的数据集、评价指标、最新的轻量级架构,并在基准数据集上对代表性模型进行了评估,以启发未来的人群计数研究。
1、数据集
1.1 数据集
Shanghai Tech是最大和最广泛使用的人群之一-统计了近几年的数据集,包含1198幅图像,共330个165个标注,数据集分为A部分和B部分,分别代表不同的人群密度和场景复杂度。A部分包含来自互联网的300张训练图像和182张测试图像,以密集人群场景为特征。B部分包含来自上海街道的400张训练图像和316张测试图像,反映稀疏人群分布。数据集显示图像密度不平衡,在训练集和测试集中,低密度图像的流行率较高。此外,规模和视角的变化为设计基于CNN的网络架构带来了挑战和机遇。
UCF_CC_50 代表了第一个从公开访问的网络图像创建的具有挑战性的数据集。它由50张不同分辨率的图像组成,涵盖了一系列场景,包括音乐会,抗议活动,体育场和马拉松,展示了不同的密度水平和透视扭曲。
UCF-QNRF 是一个具有挑战性的集合,包含1535张高分辨率人群图像,其中1201张用于训练,334张用于测试。它包含大约125万个注释,涵盖具有不同视角、密度和照明条件的不同场景。这些图像的平均分辨率为2013 x 2902像素。此外,该数据集包括来自地球仪的真实户外场景,捕捉各种元素,如建筑物、植被、天空和道路。2这种多样性对于研究人口密度的区域差异至关重要。
NWPU-Crowd数据集包含5109张图像,共有2133238个注释个体,平均分辨率为2191 × 3209像素。该数据集包含负样本,这增强了模型在训练过程中的鲁棒性。与其他数据集相比,它在规模,密度和背景方面提供了更大的多样性。此外,它包含没有任何个体的负样本,进一步丰富了数据集的整体多样性。
WorldExpo'10 dataset [65]是2010年上海世博会的一个综合跨场景人群计数数据集。它包括108个监控摄像机记录的1132个带注释的视频序列,包括3920帧分辨率为576 × 720的视频和199 923个个体的注释。训练数据覆盖来自103个场景的3980帧,而测试数据由来自另外5个场景的600帧组成。
JHU-CROWD++ 包含来自不同在线场景的4372张图像,平均每张图像有346个注释,峰值注释数为25791。它捕捉一系列天气条件,如雨,雪和雾霾。它还提供图像和头部级别的全面注释,每个注释包括头部位置,大小,遮挡程度,这些丰富的细节增强了数据质量,从而实现更高效的模型训练。
1.2 评价指标
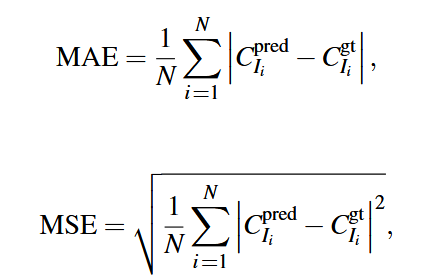
其中N是测试图像的数量,Cred Ii和Cgt Ii分别表示预测结果和地面真值。特别地,MAE决定了估计的准确性,而RMSE表示估计的鲁棒性。

其中L表示模型中的层数,Wi表示权重参数,Bi表示第i层的偏置参数。Cin指定输入通道的数量,而Hout和Wout分别指输出特征图的高度和宽度。卷积核维数由Kh(高度)和Kw(宽度)给出。Cout表示输出通道的数量。此外,Elapsed_Time(i)以毫秒为单位度量每次迭代i的推理时间,M表示迭代的总数。
2、引言
总体而言,基于检测和基于回归的方法通常在高密度复杂场景中难以获得准确性。
虽然像CNN这样的深度网络在性能上有了显着的进步,但它们通常需要大量的层和参数,导致高计算成本。高复杂度模型实现了高精度,但施加了显著的计算和内存开销,这限制了它们在现实世界环境中的应用,特别是在资源有限的环境中。因此,在保持模型准确性的同时减少计算需求已经成为人群计数研究的关键挑战。
为了解决这个挑战,研究人员越来越关注于设计轻量级网络。这些网络旨在减少参数和计算需求的数量,以实现更高的效率和资源利用率,同时保持模型性能。分为三种主要类型:
(1)基于轻量级架构的网络。这些网络旨在构建有效的神经架构,降低参数计数和计算开销。通过细化网络结构,包括层减少和使用轻量级卷积,这些网络实现了性能和计算效率之间的平衡。
(2)基于轻量级模块的网络。这些网络通过合并特定模块(如轻量级注意力机制或多尺度特征融合)来建立在现有模型的基础上,以改善特征提取和适应性。
(3)基于知识提炼的网络。这些网络将见解从大型教师模型转移到紧凑的学生模型。这种方法使学生模型能够实现高精度,同时显著减少参数和计算需求。在提取过程中,教师模型的软标签和特征表示作为学习样本,引导学生模型更好地理解复杂的数据分布。知识提取对于复杂环境中的人群计数特别有用,它使轻量级模型能够获得高的计数精度,并适合在资源有限的环境中部署。
这三种轻量级方法具有很强的适应性和在资源有限环境中的应用潜力,本文系统地回顾了这些方法,并详细分析了它们的特点和适用性,以支持轻量级网络在人群计数中的研究,本文的主要贡献如下:
(1)回顾了主流的轻量级人群计数方法,将其分为三种主要类型,为研究人员提供详细的技术框架。
(2)本文通过比较各种轻量级模型在准确性、效率、和资源利用,为应用提供实际见解。
(3)本文基于当前的局限性,指出轻量级人群计数方法的发展潜力,并为未来的研究提供了明确的方向。
3、轻量级网络
3.1.基于轻量级架构的网络
基于轻量级架构的网络减少了参数计数和计算需求,以创建适用于资源有限环境的高效神经模型。这些网络通过最小化网络深度和使用依赖可分离和分组卷积等策略实现结构优化。我们基于面向问题的方法将这些网络分为两类。第一类包括以下方法:解决规模变化问题的方法,例如MCNN 、PCCNet 和一些类似的方法。这些方法重点关注各种规模的人群分布,特别是在高密度场景中,并使用诸如多-尺度特征提取来管理远近目标之间的差异。第二类关注背景噪声,如MCNet ,TinyCount [81],等等[51,82,83]。这些方法旨在减少背景噪声对人群计数的影响,特别是在具有遮挡和复杂背景的环境中。
为了解决图像的尺度变化问题,多列卷积神经网络(MCNN)采用三个具有不同感受野的并行分支来提取各种尺度的特征。它去除了全连接层,只保留卷积层和池化层,最后一个1×1卷积层用于生成密度图。这种多列结构降低了计算成本,实现了模型轻量化,并提高了实时性能,这使得它适用于不同的人群密度和多视角场景。然而,MCNN 主要依赖于局部特征,缺乏全局特征捕获,这限制了其在高密度场景中的准确性。基于MCNN ,Ma等人提出了一种级联小滤波器方法,以实现更精细的多尺度特征提取,同时进一步降低计算需求。该方法设计了一个轻量级的三级网络,包括多尺度特征提取,密度图估计和细化,以平衡精度和效率。然而,该网络继续努力在高密度和复杂场景中捕获全局特征,这限制了其精度和泛化能力。
Shi等人开发了紧凑卷积神经网络(CCNN)以进一步优化计算效率。如图1所示,CCNN 包括前面的三个并行卷积层,每一个都有不同的内核大小来捕获多尺度的局部特征。它将生成的特征图合并成一个统一的特征图。这种方法提供了有效的实时性能,同时保持了较低的计算成本。
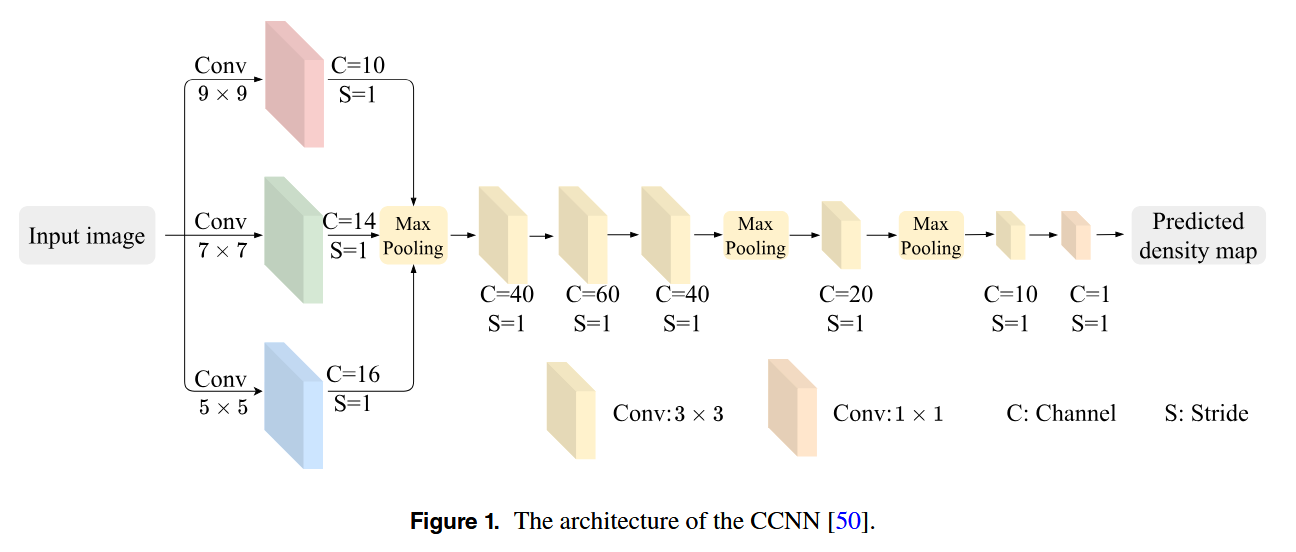
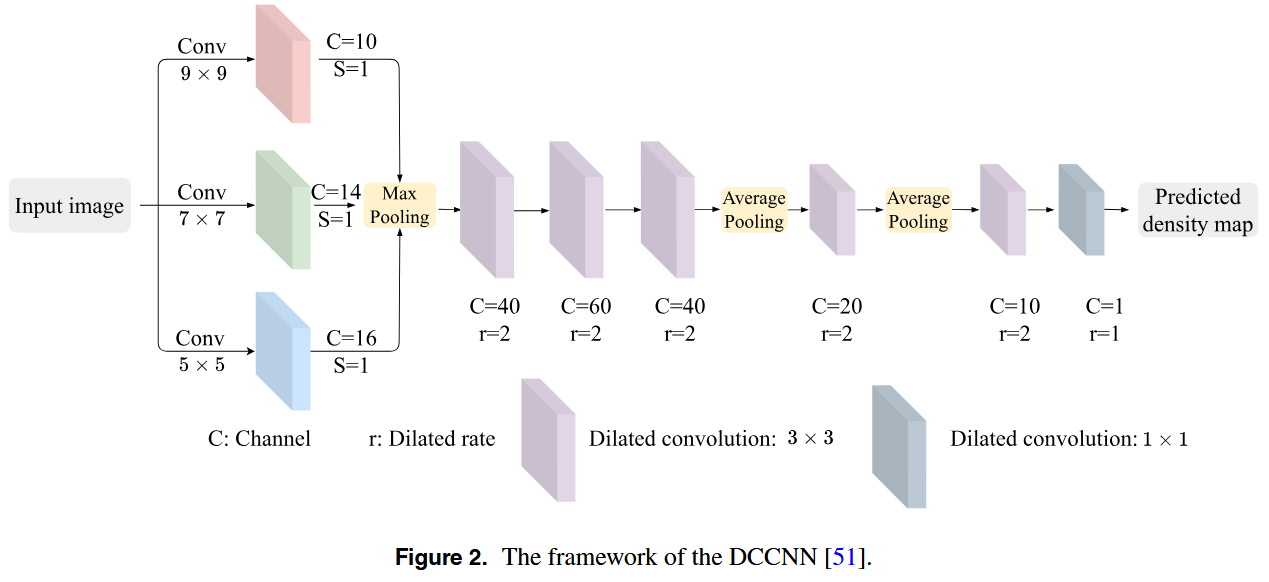
然而,由于缺乏背景噪声抑制机制,CCNN 也存在局限性,这影响了其在复杂场景中的准确性。基于CCNN ,Thai等人提出了扩张紧凑卷积神经网络(DCCNN),以增强人群计数中的背景噪声抑制。如图2所示,DCCNN 在第二层引入了扩张卷积,膨胀率为2。这种调整扩大了感受野,而不增加计算成本,并加强了噪声抑制。此外,DCCNN 在第二层和第三层用平均池化代替最大池化。这种修改有助于减少关键计数细节的丢失。批量归一化也应用于所有卷积层,以提高模型稳定性并加速收敛。尽管如此,尽管取得了进步,DCCNN 在捕获全局特征方面仍然存在局限性。它在稀疏场景中的自适应性也较差,这影响了其准确性。
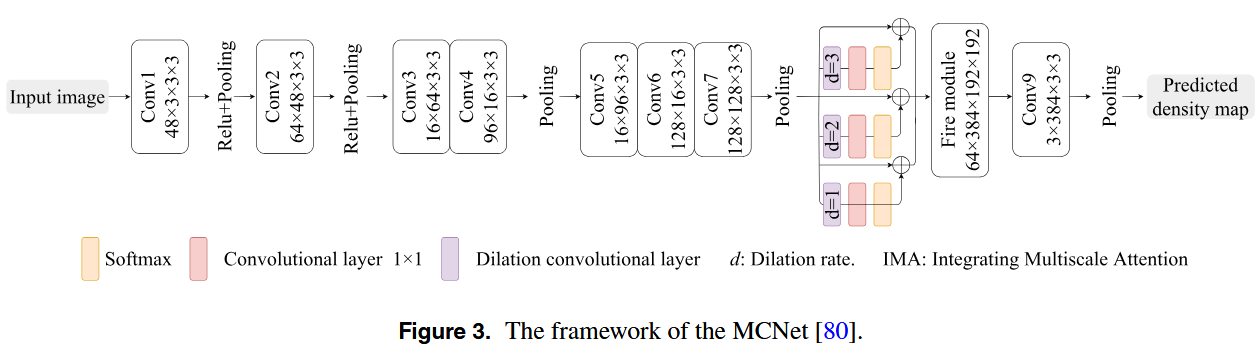
为了解决背景问题噪音问题,一些研究将联合收割机多尺度特征与注意力机制相结合。Guo等人提出了MCNet,如图3所示。MCNet 通过将多尺度特征提取与空间注意力机制相结合来提高复杂环境中的模型鲁棒性。首先,它通过一系列卷积层,ReLU激活,和池化操作。然后,这些特征被送入多尺度注意力层。它利用多尺度扩张卷积和空间注意力动态调整各个区域的重要性。这使得网络能够聚焦于关键区域,提高高密度区域的准确性,并有效地减轻背景噪声干扰。
3.2.基于轻量级模块的网络
与基于轻量级架构的网络相比,基于轻量级模块的网络注重通过模块化设计优化模型特征,通过引入模块化组件,该模型可以根据任务需求灵活地选择或调整合适的模块,提高了模型在复杂环境下的性能。
我们将基于模块的轻量级网络分为两类。第一类侧重于通过使用多尺度特征融合和自适应模块来解决尺度变化。第二类针对背景噪声,它使用特定的模块来抑制背景干扰。例如,轻量级注意机制使模型能够关注重要区域,同时最小化不相关的背景噪声。同时,即使在复杂的环境中也能保持很高的精度。
为了应对规模变化的挑战,Yi等人提出了LEDCrowdNet,这是一种用于人群计数的轻量级网络,可以优化计算效率和准确性。如图4所示,LEDCrowdNet 使用MobileViT 作为编码器来提取多尺度人群特征。解码器集成了增强的AMLKA和LCASPP模块,以生成高-质量密度图。AMLKA模块通过具有三种膨胀率的卷积来捕获多尺度特征,以解决与传统大内核相关的信息丢失问题。LC-ASPP模块使用自适应平均池化和稀疏卷积来提高特征定位精度并降低计算成本。LEDCrowdNet 在稀疏场景中实现了效率和精度之间的平衡,但其特征提取在密集环境中不太稳定。
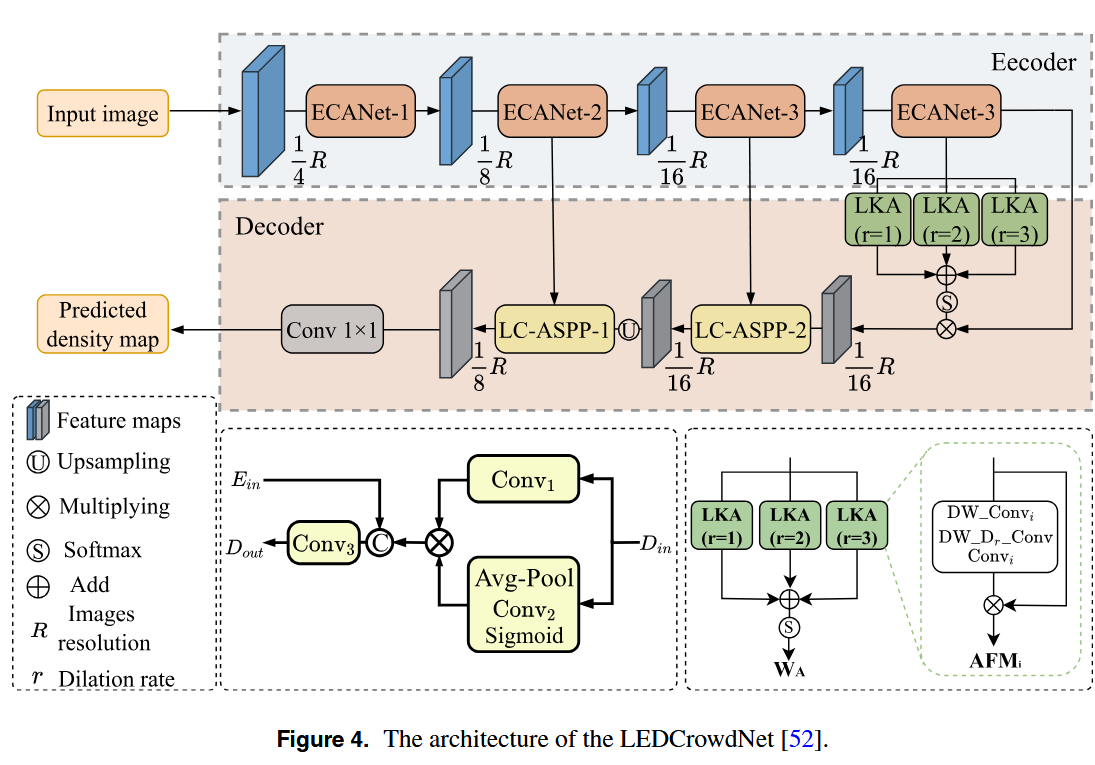
Zhai等人开发了FPANet,这是一种轻量级网络,旨在解决密集人群场景中规模变化的挑战。基于ResNet50 的浅层特征,FPANet 包括特征金字塔模块,注意力模块和多尺度聚合模块(图5)。特征金字塔模块采用多尺度卷积核来提取金字塔结构中的特征,捕获跨不同尺度的人群特征。如图6所示,注意力模块包括金字塔空间注意力(PSA)单元和轻量通道注意力(LCA)单元。PSA突出头部区域中的空间特征,减少背景干扰,而LCA增强了关键通道之间的连接,以改善特征聚焦。多尺度聚合模块集成了空间和通道注意力信息,以丰富特征表示并提高对复杂人群场景的适应性。尽管FPANet [46]中的两个模块尽管它们显著增强了模型性能,但它们也引入了额外计算开销,这限制了它们在具有有限资源的设备上的适用性。
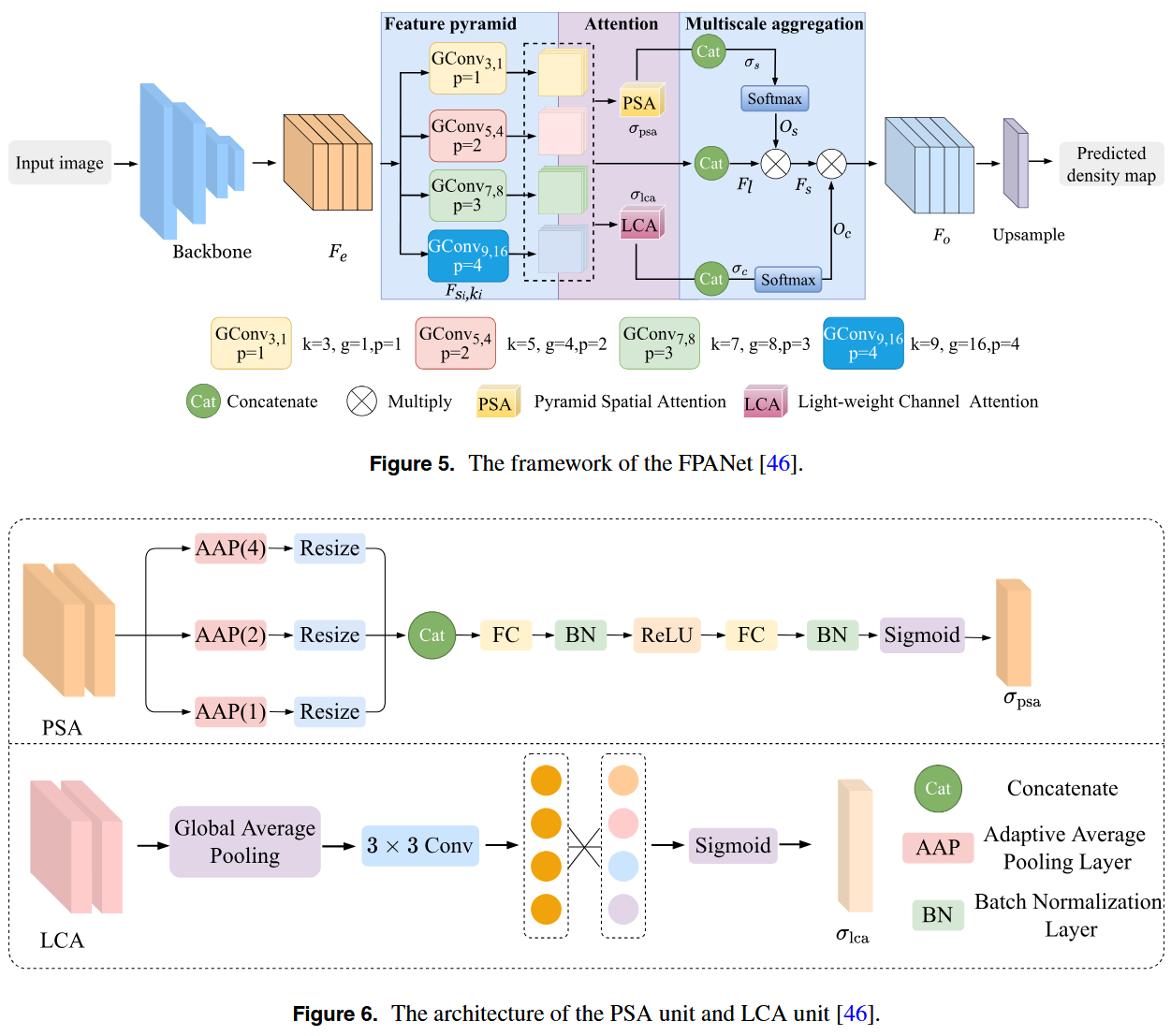
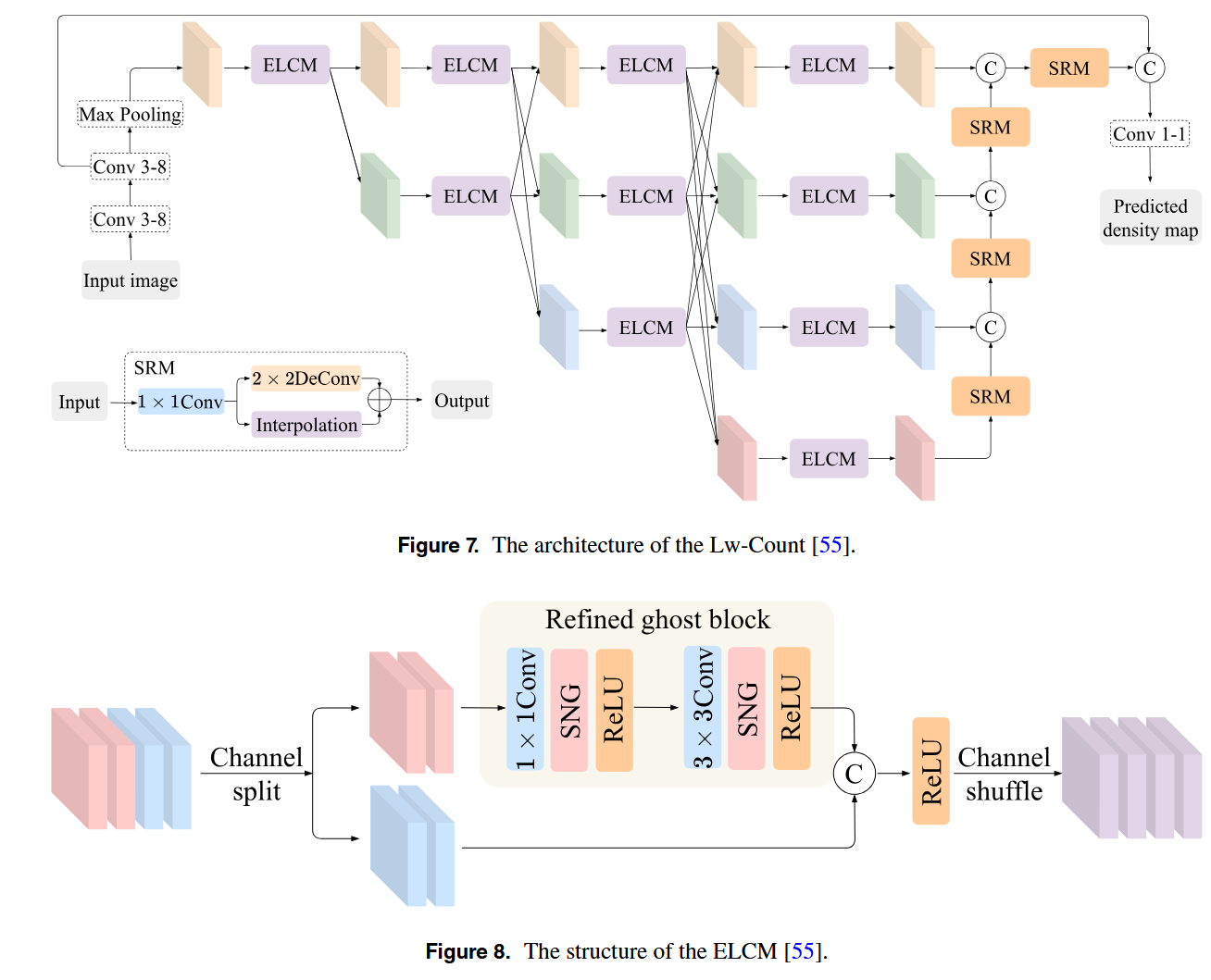
Liu等人提出了Lw-Count,这是一个旨在解决尺度变化挑战的轻量级人群计数网络,其设计兼顾了高精度与运行效率。如图7和图8所示,该网络以精简版的HRNet为基线,并引入了两个关键模块以增强性能:高效轻量级卷积模块和尺度回归模块。ELCM采用改进的Ghost模块结构,能以极少的参数量提取特征,并结合空间组归一化来应对因人群分布不均带来的计数挑战。解码阶段的SRM模块则负责融合来自不同层级的多尺度特征。这种方法能最小化插值误差,并避免由转置卷积产生的伪影,从而提升密度图的质量。此外,Lw-Count采用区域归一化互相关损失来增强空间一致性,进一步提高了计数精度。然而,该网络也存在局限:其一,其所用的简化版HRNet限制了网络在高密度复杂场景中捕获多尺度细粒度细节的能力;其二,Ghost模块生成的冗余特征在捕捉边界信息方面效率较低,这影响了高密度人群区域的计数准确性。
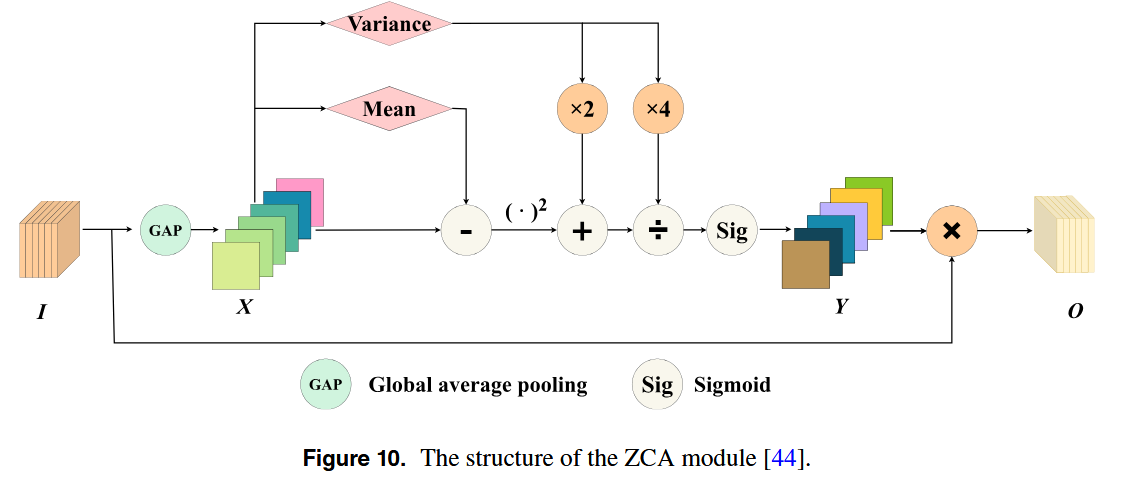
尽管多尺度模块增强了模型处理尺度变化的能力,但背景噪声仍然是复杂场景下的瓶颈。为了解决这个问题,Guo等人提出了Ghost Attention Pyramid Network(GAPNet)来抑制背景干扰。GAPNet 使用GhostNet 作为主干来提取低级别特征。如图9所示,该模型以人群图像作为输入,并生成相应的预测密度图作为输出。为了有效地识别有区别的人群区域,GAPNet 引入了零参数信道注意(ZCA)(图10)ZCA模块通过线性变换和激活函数调整信道权重。ZCA模块首先应用全局平均池化,获取每个通道的统计特征。然后引入基于能量的加权方案来强调与目标有显著差异的通道。这增强了模型对信息特征的关注。该模块不包含可学习的参数。所有关注分数都是通过预定义的线性运算和归一化导出的,这保持了计算的轻量化。此外,GAPNet 采用四分支设计的高效金字塔融合(EPF)模块来增强背景抑制。通过将群卷积与扩张卷积相结合,EPF模块有效地过滤掉不相关的背景特征,同时保持低参数。在解码器阶段,虽然GAPNet 降低了计算成本并提高了效率,但其流线型设计限制了特征提取深度,影响了高密度设置中的准确性。

其他基于轻量级模块的网络,如Chen等人[88],Yi等人[89],LMSNet [90],LigMSANet [91],MDCount [92],PDDNet [93],MLRNet [94],MobileCount [45],JMFEEL-Net [95],LSANet [96]和Yu等人[97]解决规模变化,而NeXtCrowd [98],ConNet [99],PSCC + DCL [53],LDNet [100]和LigMANet [101]专注于抑制背景干扰。
3.3.基于知识提炼的网络
知识蒸馏通过将专业知识从大型教师模型转移到更小但更有效的学生模型来实现轻量级网络。这种策略减少了参数和计算负载,同时保持了模型的准确性。在蒸馏期间,学生模型从地面实况和教师的指导中学习。这些额外的线索帮助模型捕获更详细的模式,并增强其通过将轻量化设计与高精度相结合,知识提取被广泛用于资源有限环境中的人群计数应用。
Liu等人提出了一个轻量级的人群计数网络,称为结构化知识转移(SKT)框架,如图11所示。它旨在有效地将知识从经过训练的大型教师模型转移到较小的学生模型。SKT框架采用CSRNet 作为教师网络,并采用简化的CSRNet作为学生网络。为了支持有效的知识转移,SKT 包括两个主要模块:层内图案转移(PT内)和层间关系转移(Inter-RT),Intra-PT允许来自教师的层内模式的逐步转移以指导学生的局部特征学习,而Inter-RT捕捉教师模型中各层之间的关系,学生理解特征演化。这些模块使学生模型能够在轻量级设计原则下进行有效学习。然而,由于其依赖于固定的特征模式,SKT [58]在密集和复杂场景中捕获全局特征的能力有限。此外,学生模型的泛化能力取决于教师模型的性能。
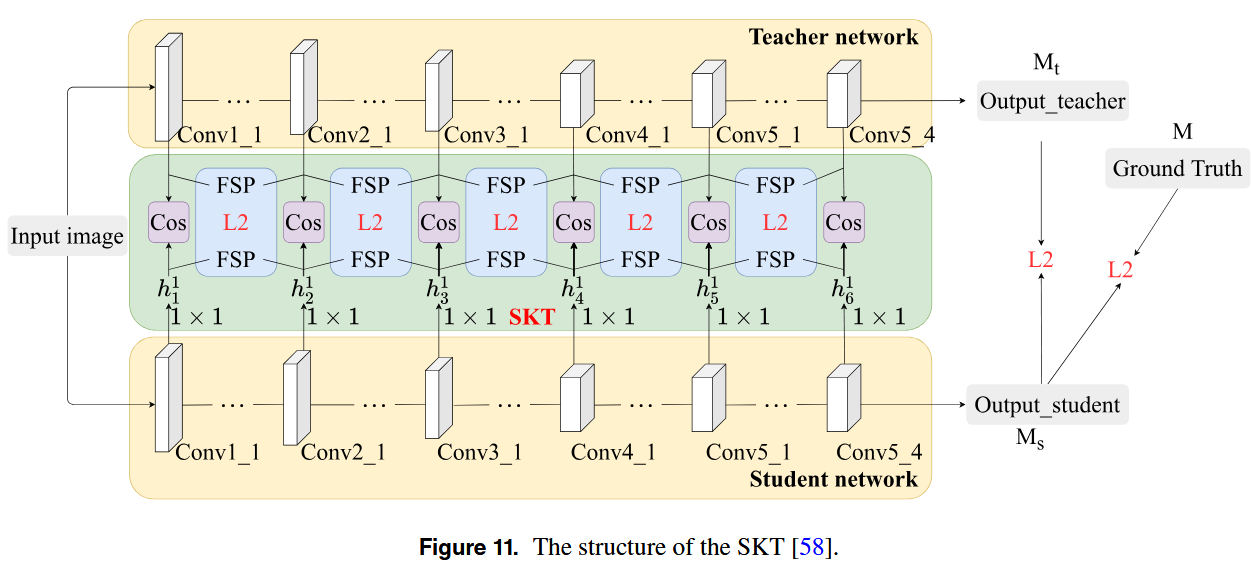
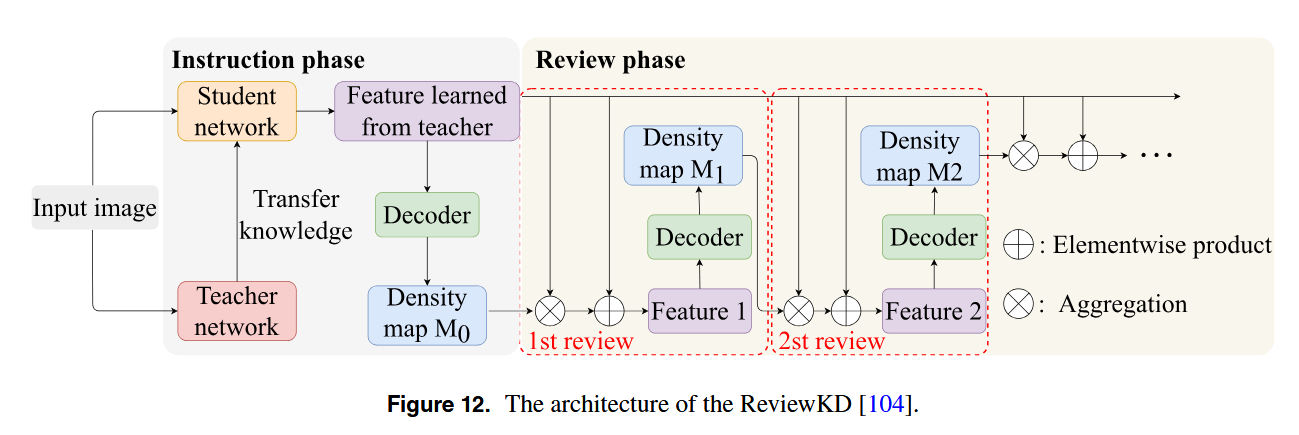
在此基础上,Liu等人引入了ReviewKD方法,这是SKT框架的增强。这种方法通过两个蒸馏阶段加强了学生模型中的特征学习:教学和复习,如图12所示。在教学阶段,教师网络逐渐将其特征模式传递给学生,指导其学习过程。在复习阶段,密度图作为注意力权重,帮助学生专注于关键区域并逐步提高特征提取能力。这种双阶段方法有效缩小了教师和学生网络之间的性能差距。虽然ReviewKD 显着提高了学生网络的计数精度,它严重依赖于教师模型的高级特征。这种依赖限制了在复杂环境中的鲁棒性。此外,审查机制专注于优化局部特征,忽略了动态场景适应的需要。
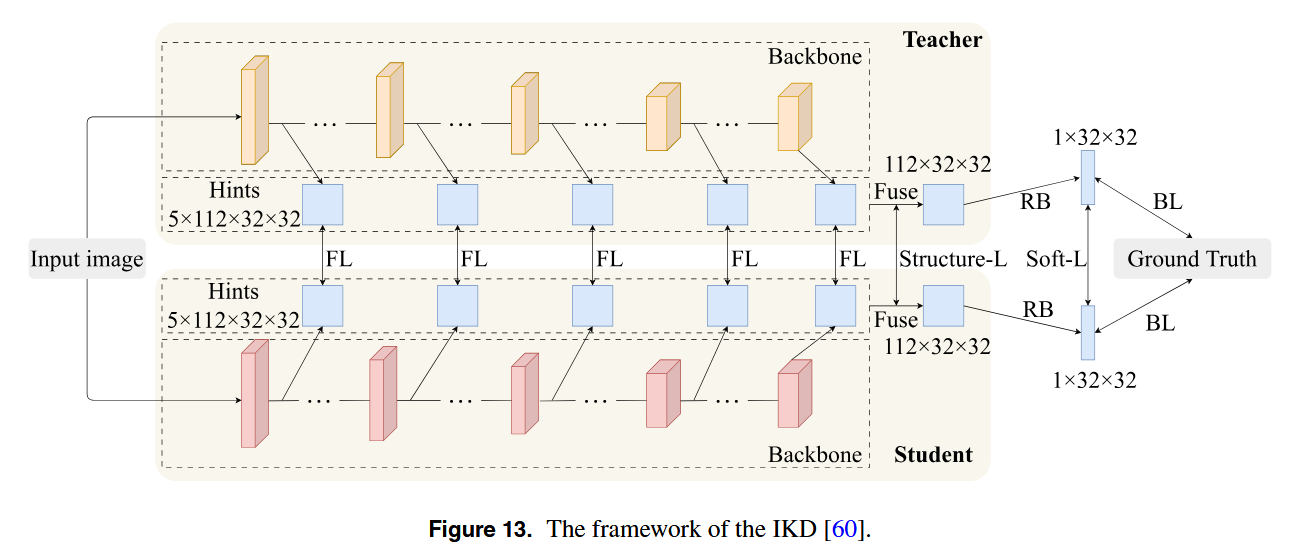
为了解决这些限制,Huang等人提出了一种基于知识蒸馏的轻量级人群计数网络,称为改进的知识蒸馏(IKD),旨在增强紧凑模型中的计数性能。IKD 的框架如图13所示。EffCC-lite 2 用作教师网络,为学生网络提供知识。学生网络,作为EffCC-lite的一个变体,具有更小的参数,适合部署在资源有限的设备上。IKD包含两个主要模块:自我转换提示和离群值容忍损失,解决了与信息损失和离群值相关的挑战。在IKD框架中,自我转换提示模块确保教师和学生网络之间的特征维度保持一致。这种一致性消除了Transformer依赖关系通常在传统的知识蒸馏中发现,从而减少信息损失。outlierolerant loss模块通过限制蒸馏期间异常数据的影响进一步改进了模型。这种增强提高了模型在高密度场景中的鲁棒性和计数精度。虽然IKD 显着提高了学生网络的计数精度,但其在动态场景中的适应性和泛化能力仍然有限。
其他基于知识蒸馏的网络包括ShuffleCount [56],DKD [57],Repmobilenet [59],D2 PT [106],Gu [107],MJPNet-S [108],EdgeCount [109],Duan等人[110]和其他几个。
4、挑战和研究方向
4.1 挑战
准确性和轻量级设计之间的平衡。轻量级网络在减少计算开销方面具有显著优势,但它们通常以准确性为代价,特别是在高密度,细节敏感的人群计数任务中。SRRNet 导致了高计算成本。相比之下,像TinyCount 这样的方法具有小得多的参数大小,仅为0.06 M。虽然这导致精度略有下降(78.2的A部分MAE),它提高了推理速度。这种权衡突出了轻量级方法在实时和资源受限环境中的优势,因此,轻量级人群计数网络的核心挑战之一仍然是实现高效和鲁棒的性能,同时最大限度地减少实际应用中的准确性损失。
场景复杂性和模型鲁棒性。在实际人群计数应用中,环境因素(例如场景变化、遮挡、背景噪音和不同的人群密度)会降低模型性能。虽然轻量级网络在计算效率方面表现出优势,但在复杂环境中的鲁棒性往往表现不佳,尤其是在高密度人群和动态背景。QNRF数据集展示了场景多样性和人群密度对模型性能的影响。该数据集涵盖了不同的人群安排和环境。它需要如表2所示,尽管RAQNet 在MAE中表现良好(106.5)和RMSE(186.1)在QNRF数据集上,推理时间(36.83 ms)由于大参数而长得多。轻量级网络GAPNet提供更快的推理时间(4.27 ms),但在复杂环境中(如遮挡和高密度人群)的鲁棒性很差。因此,未来的研究应该集中在提高轻量级网络在不同场景下的鲁棒性,特别是在处理复杂背景和照明变化等环境变化时。
泛化能力不足。泛化仍然是轻量级人群计数模型研究中的一个重大挑战。现有的轻量级模型通常依赖于大型标记数据集进行训练,并且在标准基准测试中表现良好。但在实际应用中,由于数据分布和环境变化的差异,其泛化能力有限(如位置,天气和密度)。这些因素导致在复杂和动态环境中性能不稳定。此外,基于大规模预训练模型的无监督方法,如对比图像预训练(CLIP)[120],可以执行类不可知计数,但它们的大参数和缺乏空间感知使它们在现实世界的应用中效率较低。例如,Chen等人[6]证明,虽然CLIP模型可以基于文本指令对对象进行计数,它对对象位置缺乏敏感性,更关注全局内容而不是精确定位。此外,CLIP 通常会冻结其预训练的编码器并忽略模态之间的未对准,未来的工作应该集中在提高轻量级人群计数模型的泛化能力,以确保在各种环境下的高准确性和稳定性。
4.2 研究方向
优化的轻量级网络压缩技术。目前,轻量级模型通常通过剪枝和量化来降低计算成本和内存占用。然而,这些技术通常会导致精度损失。未来的研究可以关注结构感知的剪枝方法,例如通道和块剪枝,以及混合精度量化策略。例如,HAWQ-V3 [121]应用二阶信息来实现混合精度量化。这种方法在保持精度的同时显著降低了模型复杂度。Lw-Count [55]重点是人群计数,并使用轻量级组件重新设计网络。它在参数和FLOP方面实现了高压缩率,而精度损失很小。进一步的改进可能来自考虑空间密度模式和区域差异,权重。这可以实现定制的压缩策略,以在密集人群环境中获得更好的性能。
动态适应不同环境。数据分布的变化,如城市和农村、白天和夜间的差异,或遮挡和清晰视图的差异,通常会对人群计数模型的泛化提出挑战。为了提高这些具有挑战性的环境下的性能,未来的研究应该探索轻量级模型的领域自适应和迁移学习方法。对抗训练和特征对齐等方法可以帮助弥合源域和目标域之间的差距。Nguyen等人[122]提出了一种自训练方法,该方法将源域标签与目标域未标记样本相结合。它应用对抗训练和熵图最小化来提高跨域设置中的泛化能力。此外,元学习方法(如动态β-MAML [123])允许快速模型适应新领域。此外,生成对抗网络(GAN)可以生成域不变特征或合成数据,并进一步提高模型适应性。例如,ASNet [124]采用具有双鉴别器的对抗学习来最小化域间隙并提高复杂环境中的计数准确性。在未来的工作中,建议探索这些方法的实用性,并解决轻量级人群计数模型所面临的领域适应挑战。
结合自我监督和无监督学习。在人群计数任务中,轻量级模型往往面临标注成本高、标注数据稀缺导致泛化能力受限等挑战,未来的研究应探索自监督和无监督学习相结合的方法,以提高模型性能,并在标注数据有限的情况下实现跨领域泛化。监督学习方法联合收割机将少量的标记数据与大的未标记数据集相结合以增强模型学习。例如,Lin等人[125]提出了一种使用像素级密度回归和交替一致性自适应的方法,监督以提高准确性和泛化能力。无监督方法,例如Liu等人[126]的方法,生成伪标签以进一步增强模型功能。他们的迁移学习方法还使用未标记的数据提高了适应性和跨域性能。此外,结合自监督和无监督策略,例如使用GANs生成伪标签,可以进一步改善未标记数据的特征学习。然而,在复杂环境中平衡更高的跨域适应性与模型效率和稳定性仍然是未来研究的关键挑战。
硬件优化和能效提升。随着边缘设备和嵌入式系统对轻量级人群计数网络需求的增加,高效推理和低功耗变得至关重要。这在智能监控,自动驾驶,未来的研究应该集中在通过硬件/软件协同优化轻量级网络在特定硬件平台上的性能,设计。例如,量化反卷积生成对抗网络(QDCGAN)模型可以部署在FPGA等硬件平台上,以实现高效推理,同时平衡吞吐量和资源使用。Alhussain等人[127]提出了一种硬件/软件协同提出了一种在FPGA上实现QDCGAN的设计方法,该方法利用可扩展的FPGA结构,在降低资源消耗的同时提高了推理速度。该技术具有并行性,适用于GAN等计算密集型应用,特别是边缘计算场景。未来的研究应进一步探索这些技术在增强轻量级人群计数模型方面的应用,具体而言,未来的工作预计将在各种硬件平台上优化低功耗和高性能之间的平衡。
5、 结论
随着深度学习的快速发展,人群计数技术在各个领域都取得了长足的进步,尤其是在准确性和鲁棒性方面。然而,随着模型复杂度的增加,对计算资源和训练数据的需求成为实际应用的瓶颈。因此,在保持高准确度的同时优化计算效率已经成为人群计数领域中的关键挑战。轻量级人群计数方法是近年来研究的热点之一。本文综述了轻量级人群计数方法的最新进展。我们将这些方法分为三大类:基于轻量级架构的网络、基于轻量级模块的网络和基于知识蒸馏的网络。对于每一个类别,本文详细介绍了SOTA轻量级人群计数网络的设计原理,并介绍了主要的代表性方法。2本文的另一个主要贡献是对当前SOTA轻量级人群计数网络的分析,它澄清了贸易-精确度和计算效率之间的差距。重量级模型提供更高的精确度,但带来了显著的计算负担。轻量级模型在推理速度和参数方面具有显着优势这些优点使其非常适合资源有限的实时应用。然而,准确性仍然是这些模型面临的挑战。虽然目前的优化技术在一定程度上提高了轻量级模型的精度,但进一步的研究预计将在不影响效率的情况下提高精度。最后,我们总结了当前的挑战,并提出了未来研究的潜在方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)