从 0 到 1 构建第一个 AI Agent
目录
一、Agent 的核心组成
一个完整的 Agent 可以用下面的公式概括:
Agent = LLM + Planning + Memory + Tool Use
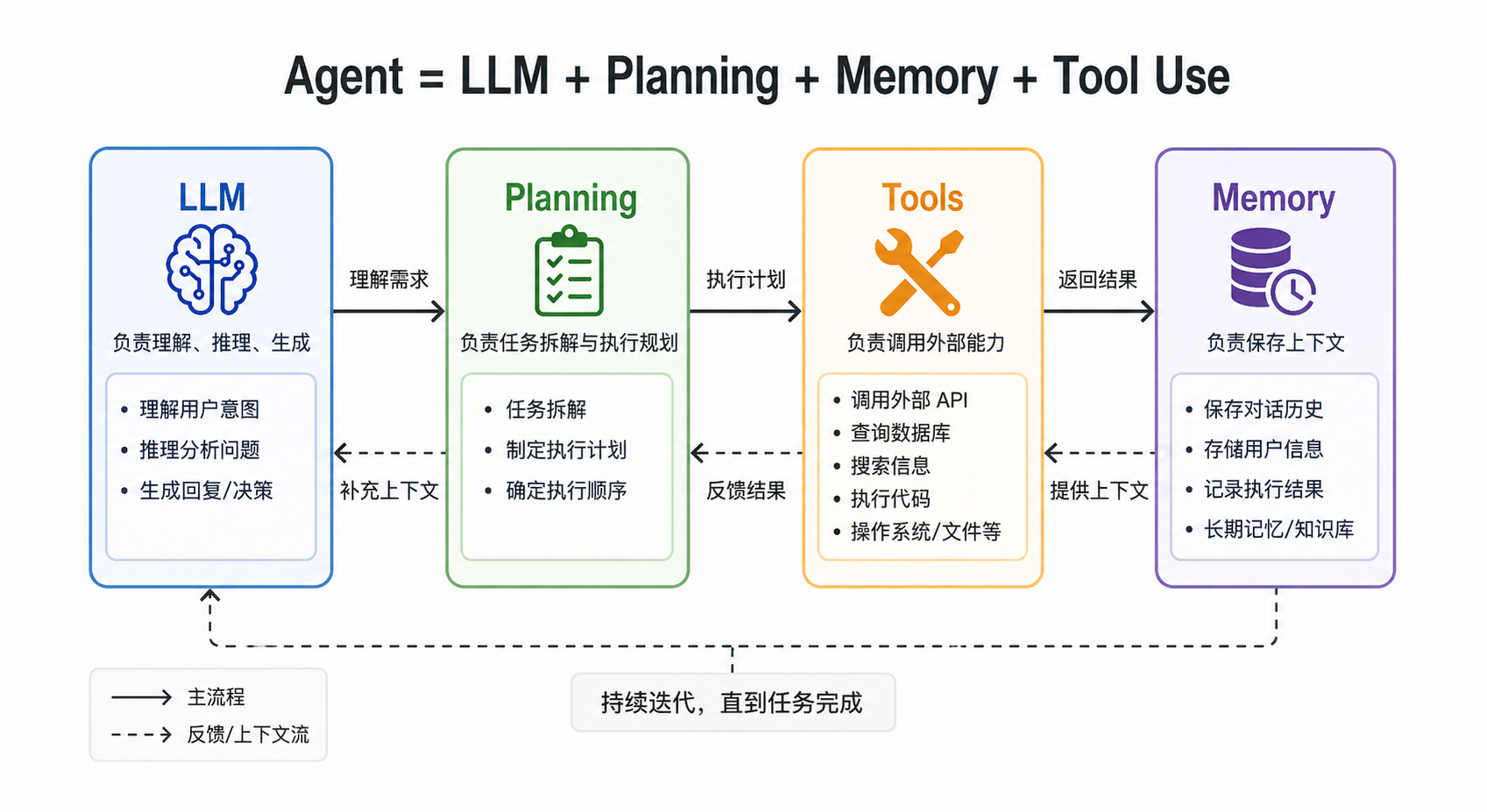
其中:
- LLM 是 Agent 的大脑,负责理解用户意图和生成响应。
- Planning 负责将复杂任务拆解为可执行步骤。
- Memory 让 Agent 具备上下文连续性。
- Tool Use 让 Agent 能调用外部工具完成真实操作。
普通大模型调用只能完成文本生成,而 Agent 的关键能力在于:它可以根据用户意图,自主判断是否需要调用工具,并将工具结果整合为最终答案。
二、Agent 应用的三层架构
在开发 Agent 之前,首先要明确代码结构。一个可维护的 Agent 应用通常可以拆分为三层。
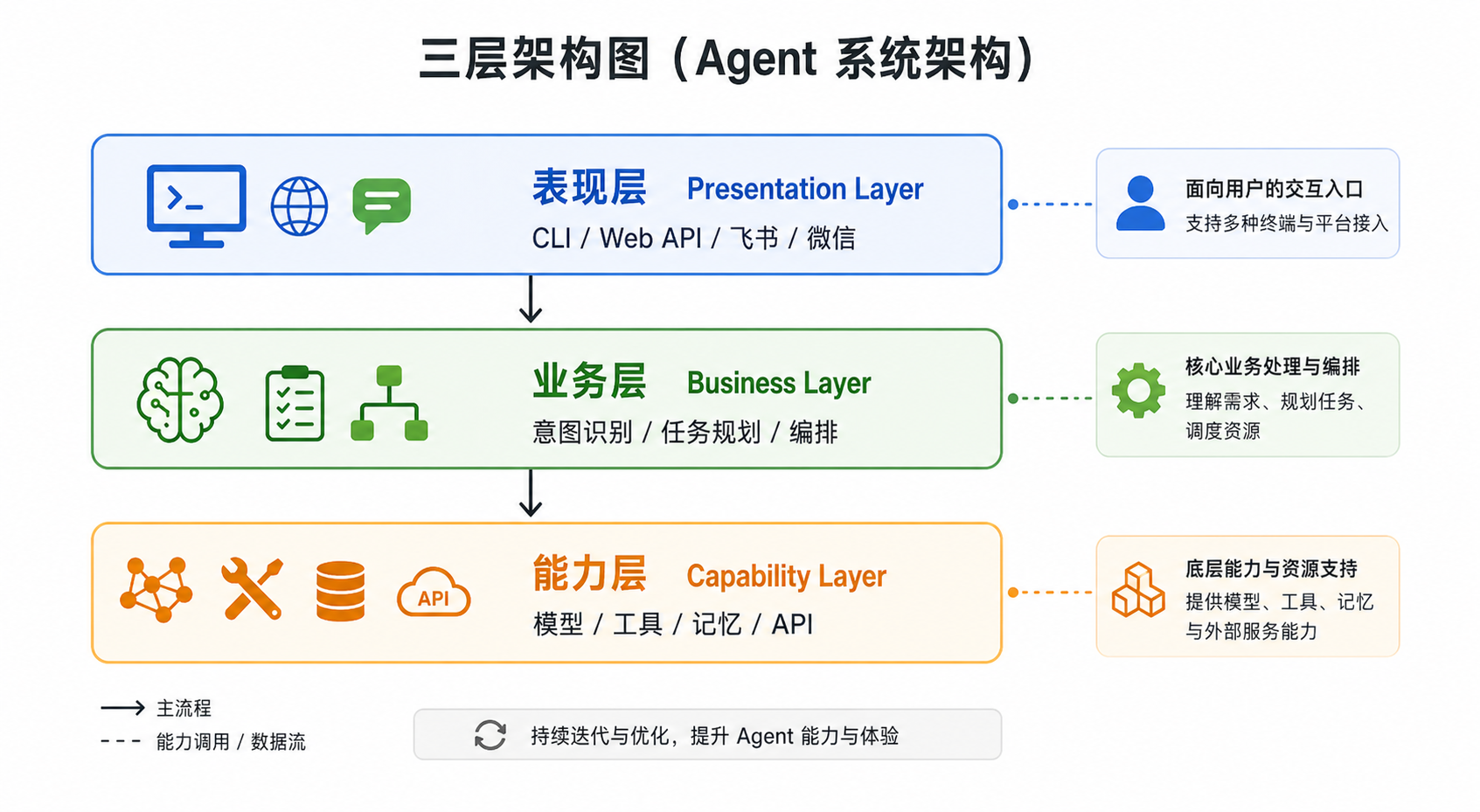
1. 能力层
能力层负责提供基础能力,包括:
- 模型适配器
- 工具函数
- 记忆模块
- 外部 API 调用
- 数据库或向量库访问
这一层只关心“能做什么”,不关心“什么时候做”。
2. 业务层
业务层是 Agent 的决策中心,负责:
- 用户意图识别
- 任务规划
- 工具选择
- 多步骤执行
- 结果整合
它决定 Agent 如何完成任务,是整个系统的核心。
3. 表现层
表现层负责用户交互,例如:
- 命令行 CLI
- Web API
- 飞书、微信、Slack 等聊天入口
- 前端页面
表现层应尽量保持轻量,只负责输入输出,不应承载复杂业务逻辑。
三、使用 LangChain 构建基础 Agent
LangChain 提供了模型适配、工具封装和 Agent 编排能力。一个基础 Agent 可以通过 create_agent 创建。
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
model = ChatOpenAI(
model="qwen-plus",
temperature=0.7,
api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
agent = create_agent(
model=model,
tools=[],
system_prompt="你是一个友好的AI助手,用简洁易懂的语言回答用户问题。",
)此时 Agent 还没有工具,只能完成基础对话。但它已经具备了后续扩展工具调用和记忆能力的统一入口。
四、为 Agent 添加工具调用能力
Agent 与普通聊天机器人的重要区别,是它可以调用外部工具。
例如,定义一个获取当前时间的工具:
from datetime import datetime
from langchain_core.tools import tool
@tool
def get_current_time():
"""返回当前的日期和时间。当用户询问现在几点、今天日期、当前时间时调用此工具。"""
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
再定义一个计算器工具:
@tool
def calculator(expression: str):
"""计算数学表达式。输入应该是字符串形式的数学表达式,如 '2+3*4'。"""
try:
result = eval(expression, {"__builtins__": {}}, {})
return f"计算结果:{expression} = {result}"
except Exception as e:
return f"计算失败:{str(e)}"然后将工具注册到 Agent:
agent = create_agent(
model=model,
tools=[get_current_time, calculator],
system_prompt="当需要实时时间时调用 get_current_time,当需要数学计算时调用 calculator。",
)需要注意的是,工具的描述非常关键。模型会根据函数名、参数和 docstring 判断何时调用工具,因此描述必须清晰、准确。
五、使用 LangGraph 实现短期记忆
没有记忆的 Agent 每次对话都是独立的。用户上一轮说“我叫张三”,下一轮问“我叫什么名字”,如果没有上下文,Agent 无法正确回答。
LangGraph 可以通过状态图和检查点机制实现短期记忆。
核心代码如下:
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
from typing import TypedDict, Annotated
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
def run_agent(state: AgentState):
result = agent.invoke({"messages": state["messages"]})
return {"messages": [result["messages"][-1]]}
graph = StateGraph(AgentState)
graph.add_node("agent", run_agent)
graph.set_entry_point("agent")
graph.add_edge("agent", END)
checkpointer = InMemorySaver()
graph = graph.compile(checkpointer=checkpointer)
调用时需要传入固定的 thread_id:
config = {"configurable": {"thread_id": "user_123"}}只要同一用户会话使用同一个 thread_id,LangGraph 就能自动保存和恢复上下文。
六、OpenClaw 的技能化开发方式
与 LangChain 相比,OpenClaw 更强调“技能化”开发。开发者可以通过 SKILL.md 描述技能,再通过 Python 文件实现具体逻辑。
一个 OpenClaw 技能通常包含:
my_tools/ ├── SKILL.md └── __init__.py
SKILL.md 负责描述技能能力,__init__.py 负责实现工具逻辑。这种方式将“工具描述”和“代码实现”分离,更适合快速构建可插拔的 Agent 能力。
七、LangChain 与 OpenClaw 对比
| 维度 | LangChain + LangGraph | OpenClaw |
|---|---|---|
| 架构风格 | 组件化、可深度定制 | 技能化、开箱即用 |
| 工具定义 | @tool + 函数签名 |
SKILL.md + Python 实现 |
| 记忆机制 | 需要显式配置状态图和检查点 | 默认封装更多能力 |
| 灵活性 | 更高 | 更偏框架约定 |
| 学习成本 | 较高 | 较低 |
| 适用场景 | 复杂业务流程、企业系统 | 快速原型、个人助理、MVP |
简单来说,LangChain 更适合理解 Agent 的底层机制和复杂编排,OpenClaw 更适合快速搭建可用系统。
八、开发 Agent 时的关键注意事项
-
不要硬编码 API Key,应使用
.env和环境变量管理密钥。 -
工具描述必须清晰,否则模型可能错误调用或不调用。
-
每个工具都应做好异常处理,避免单点失败导致 Agent 崩溃。
-
生产环境不建议直接使用
eval,应使用安全的表达式解析方案。 -
Agent 可能产生多轮模型调用,需要关注 token 成本。
-
记忆功能必须正确配置
checkpointer和thread_id。 -
表现层应保持轻量,业务逻辑不要写在接口或机器人回调中。
九、总结
构建 Agent 的重点不只是“让模型回答问题”,而是让系统具备可扩展的工程结构。
一个完整的 Agent 应用应当具备:
-
清晰的三层架构
-
可插拔的工具系统
-
稳定的模型适配能力
-
可持续的记忆机制
-
良好的日志、异常处理和成本控制
LangChain 适合帮助开发者理解 Agent 的底层机制,OpenClaw 则更适合快速搭建技能化 Agent。对于初学者而言,推荐先使用 LangChain 掌握工具调用和记忆原理,再使用 OpenClaw 提升开发效率。
Agent 开发的本质,是将大模型从“会回答”升级为“能执行”。这也是 AI 应用从聊天机器人走向生产力工具的关键一步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)