DeepSeek V4:百万上下文时代的架构革命,论文深度解析
导读:
从论文出发,逐层剖析 CSA / HCA 混合注意力、mHC 残差连接与 Muon 优化器——这三项核心创新如何让开源模型第一次真正"用得起"百万 token 上下文
编辑:V号:人工智能研究Suo为什么百万 Token 是个大问题
注意力机制(Attention)是 Transformer 的核心,但它有一个致命的数学诅咒:计算复杂度随序列长度呈二次方增长。当上下文长度从 128K 扩展到 1M 时,原始注意力所需的 KV Cache 和计算量暴增近 60 倍。
这不只是内存问题。在 Agentic AI 场景中,模型需要持续保持数十万 token 的工作记忆——分析整个代码仓库、跨越数百页的文档推理、或者在长达数小时的多轮工具调用中维持连贯的思维链。没有原生高效的长上下文支持,这些能力只是数字游戏。
核心矛盾
测试时计算扩展(Test-Time Scaling)是 2025 年最重要的进展方向,但它本质上要求模型在推理时展开极长的思维链——而传统注意力机制的二次复杂度让这条路越走越贵。DeepSeek V4 的核心命题是:打破这个效率天花板。
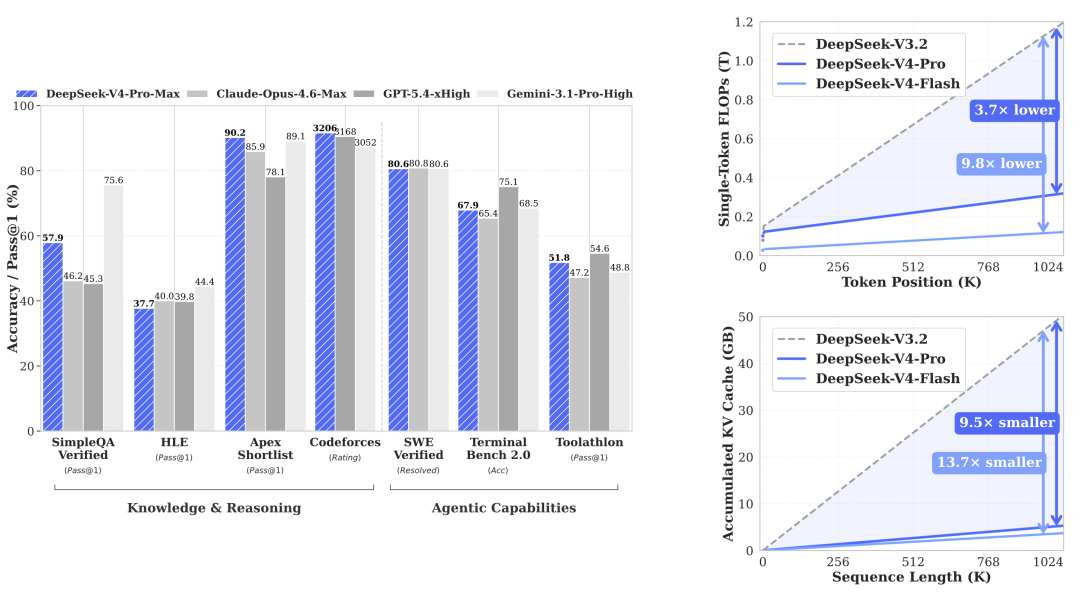
论文给出了一组震撼的数据:在 1M token 上下文场景下,DeepSeek-V4-Pro 所需的单 token 推理 FLOPs 仅为 DeepSeek-V3.2 的 27%,KV Cache 仅为 10%;而更小的 Flash 版本更是降至 FLOPs 的 10%、KV Cache 的 7%。
27% V4-Pro 推理 FLOPs(vs V3.2,1M 上下文)
10% V4-Pro KV Cache(vs V3.2,1M 上下文)
10% V4-Flash 推理 FLOPsvs V3.2,1M 上下文)
7% V4-Flash KV Cache vs V3.2,1M 上下文)
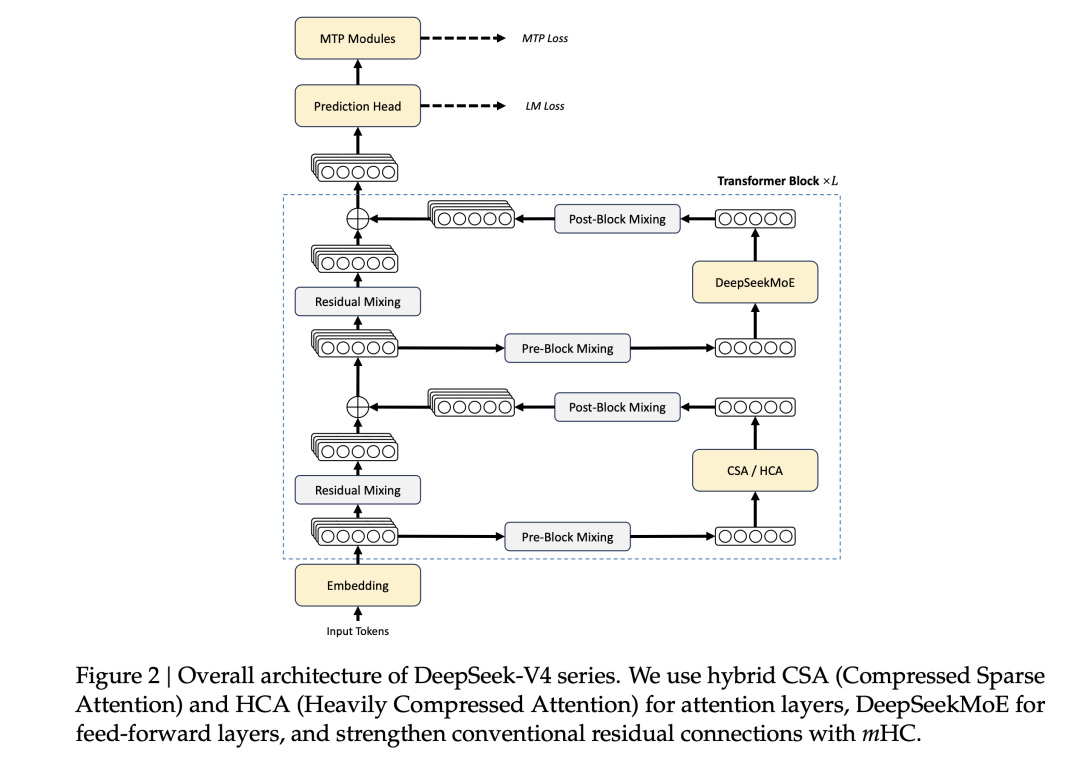
核心创新一:CSA + HCA 混合注意力
这是 V4 最重要、最底层的架构创新。论文提出了两种全新的注意力机制,并将它们交织使用,形成一套多尺度感知系统。
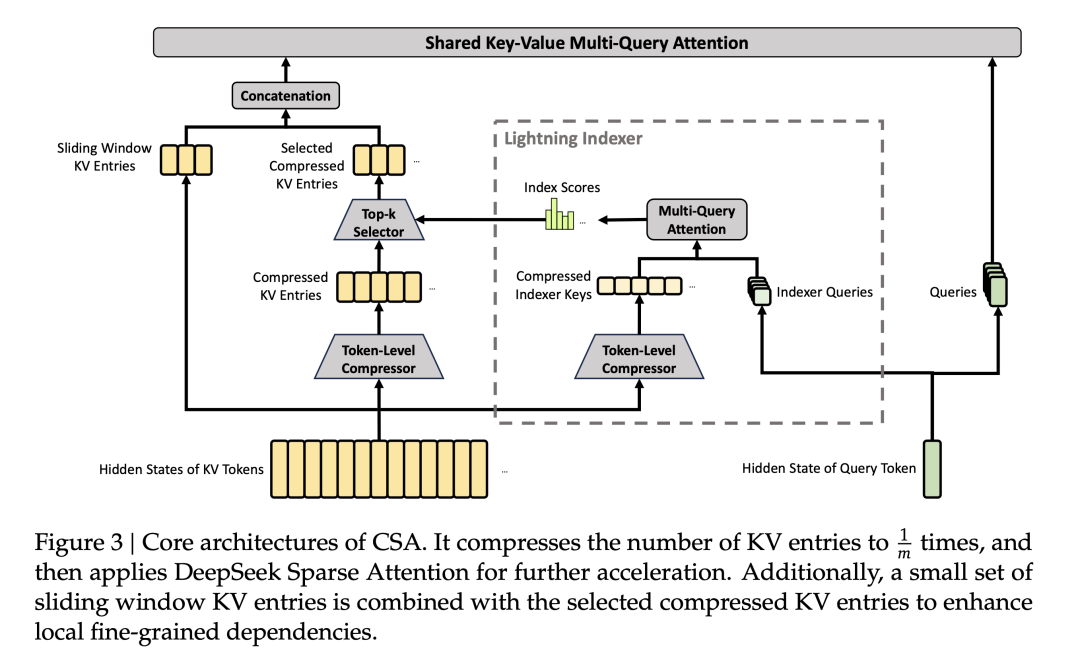
1.1 压缩稀疏注意力(CSA):精准模式
CSA 的设计哲学是"压缩后再选择"——先把 KV 序列压缩短,再只看最重要的部分。它分三步走:

关键参数:在 V4-Pro 中,m=4(4:1 压缩),top-k=1024。这意味着对于一个 1M token 序列,实际压缩后约有 250K 个条目,然后每个 Query 只与最相关的 1024 个发生注意力计算。两步压缩叠加,效果极为显著。
工程细节
CSA 采用了一种重叠压缩(overlapped compression)策略。计算第 i 个压缩条目时,同时使用当前窗口的 m 个 token(称为 C^a)以及前一窗口的最后 m 个 token(称为 C^b)。这个设计让每个条目能看到 2m 个 token 的信息,有效缓解了边界信息丢失的问题。
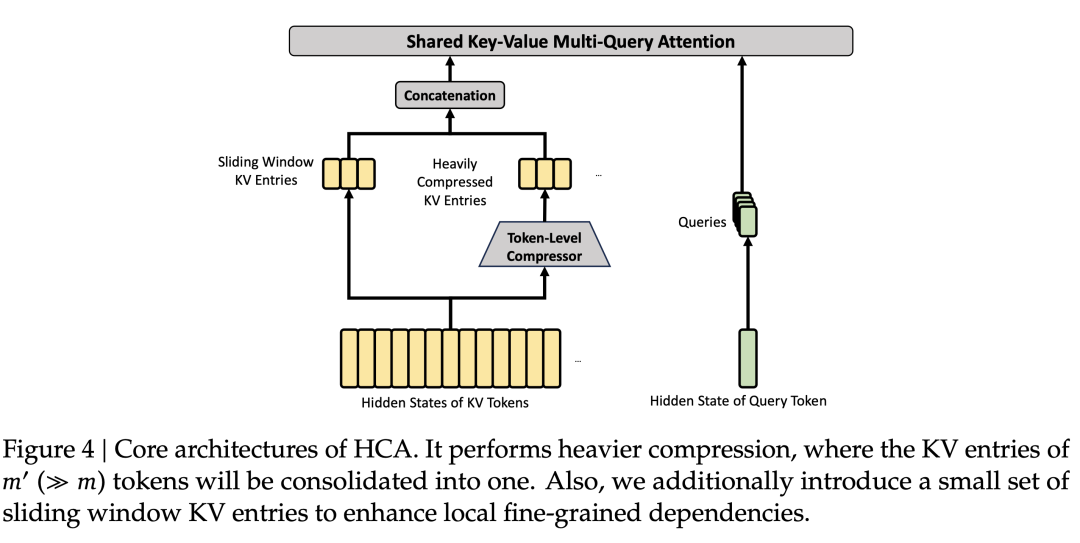
1.2 重度压缩注意力(HCA):全局视野模式
HCA 走向另一个极端:不做稀疏选择,改做极度压缩。每 m'=128 个 token 才压缩为 1 个条目,序列长度缩短 128 倍,然后对这极短的序列做全密集注意力。
HCA 的计算量极低,但它给了模型一张整个上下文的"低分辨率全景图"——在需要从超长文档中定位关键段落、维持宏观叙事一致性时,这种全局感知至关重要。
1.3 为什么要混合交织,而不能二选一?
论文做了消融实验,结论很清楚:单用 CSA 或单用 HCA 都无法达到论文报告的效率数字。关键在于两种注意力的互补性:

V4-Flash 的前两层使用纯滑动窗口注意力(初始化稳定),后续层交替使用 CSA 和 HCA。V4-Pro 的前两层使用 HCA,后续层同样交替。
1.4 精度优化叠加——效率的最后一公里
论文在注意力机制上还叠加了多项精度优化,进一步降低显存和计算:
存储格式混合
KV Cache 的 RoPE 维度用 BF16 存储(位置编码需要精度),其余维度用 FP8 存储,综合下来 KV Cache 大小接近纯 BF16 方案的一半。
LIGHTNING INDEXER 的 FP4 计算
索引器(负责评分并选出 top-k KV 条目)的 QK 矩阵乘法完全在 FP4 精度下完成,并将 index score 从 FP32 量化到 BF16,实现 top-k 选择 2× 加速,且召回率保持在 99.7%。
数量级对比
以 BF16 GQA(head_dim=128)为基线,在 1M token 场景下,DeepSeek-V4 系列的 KV Cache 大小可压缩至基线的约2%。
核心创新二:流形约束超连接(mHC)
如果说 CSA/HCA 解决的是推理效率问题,mHC 解决的是训练稳定性问题——尤其是当模型堆叠到极深(61 层 Transformer Block)时。
2.1 传统残差连接的局限
标准残差连接(x_{l+1} = x_l + F_l(x_l))已经是深度网络的标配,但它有一个隐患:信号沿层传播时,梯度可能爆炸或消失,且各层之间存在强耦合。Hyper-Connections(HC)曾尝试通过扩展残差流宽度(引入 n_hc × d 的扩展维度)来解耦,但论文指出在多层堆叠时会出现严重的数值不稳定。
2.2 mHC 的核心思路:把残差映射约束到双随机矩阵流形
mHC 的关键创新在于将残差变换矩阵 B_l 约束到双随机矩阵(Doubly Stochastic Matrix)集合,即 Birkhoff 多胞形 M:每行每列之和均为 1,且所有元素非负。
为什么双随机矩阵有效
双随机矩阵的谱范数 ‖B_l‖₂ 被保证 ≤ 1,这意味着残差变换是非扩张的(non-expansive)——信号经过任意多层变换后不会爆炸。更重要的是,双随机矩阵集合在乘法下是封闭的,从数学上保证了深层堆叠后的稳定性。
2.3 Sinkhorn-Knopp 算法实现约束
要将任意矩阵投影到双随机矩阵流形,mHC 使用了经典的 Sinkhorn-Knopp 算法:先对原始参数取指数保证正性,再交替做行归一化和列归一化,迭代 t_max=20 次即可收敛。这个过程可以高效实现为一个 fused kernel。
mHC 约束应用(概念伪代码)
# 生成原始未约束参数
B_raw = alpha_res * (X_flat @ W_res) + S_res
# Sinkhorn-Knopp 投影到双随机矩阵流形
M = exp(B_raw) # 保证正性
for t in range(20):
M = M / M.sum(axis=1, keepdim=True) # 行归一化
M = M / M.sum(axis=0, keepdim=True) # 列归一化
B_l = M # 此时满足 ||B_l||₂ ≤ 1
# 残差流更新(扩展宽度 n_hc=4)
X_{l+1} = B_l @ X_l + C_l * F_l(A_l @ X_l)工程层面,mHC 引入的额外 wall-time 开销仅为 overlapped 1F1B pipeline stage 的 6.7%——代价极小,收益是全局训练稳定性的显著提升。
核心创新三:Muon 优化器
DeepSeek V4 放弃了几乎所有 LLM 都在用的 AdamW,转而采用 Muon(Momentum + Orthogonalization) 优化器作为大多数模块的主优化器。这是一个相当大胆的工程选择。
3.1 Newton-Schulz 正交化更新
Muon 的核心思路:在做权重更新之前,先用 Newton-Schulz 迭代将梯度矩阵正交化(约近到 UV^T,即 SVD 的旋转部分),再以此作为更新方向。
正交化更新的物理意义在于:每个参数方向上的更新幅度接近均匀,避免了 AdamW 中因为梯度方差差异极大导致的部分参数更新过度/不足的问题。这带来更快的收敛速度和更好的训练稳定性。
HYBRID NEWTON-SCHULZ 迭代
V4 使用了两阶段混合策略:前 8 次迭代用系数
(a,b,c)=(3.4445,−4.7750,2.0315)
快速驱动奇异值趋近 1;后 2 次切换为(2,−1.5,0.5)
精确稳定到 1。总共 10 次迭代,在精度和计算开销之间取得最优平衡。
3.2 与 ZeRO 的兼容性工程
Muon 的最大挑战在于:它需要完整的梯度矩阵才能正交化,但 ZeRO 优化会将参数切分到不同 rank 上。两者本质上冲突。
DeepSeek 的解决方案是为 Muon 设计了一套混合 ZeRO bucket 分配策略:用背包算法(Knapsack)将完整参数矩阵分配到不同 rank,保证每个 rank 管理整矩阵而非切片;当数据并行度超过限制时,部分 rank 冗余计算 Muon 更新(以计算换内存),并在 MoE 参数上特别优化,对所有 Expert 做批量 Newton-Schulz 迭代提升硬件利用率。
另一个工程细节:将 MoE 梯度在数据并行 rank 间同步时,以随机舍入方式量化到 BF16,将通信量减半,并用 two-phase all-to-all(而非 tree/ring reduce-scatter)保证数值鲁棒性。
训练稳定性:两个关键 Trick
训练 1.6 万亿参数模型时,论文团队遭遇了严重的训练不稳定问题,最终找到了两个有效解法,并在论文中坦诚承认其背后机理尚未完全理解。
Anticipatory Routing(预期路由)
核心思路:将骨干网络的参数更新与路由网络的参数更新在时间上解耦。在步骤 t 计算特征时,路由 index 使用历史参数 θ_{t-Δt} 预先计算好。这打破了路由决策和特征计算之间的恶性循环,显著减少了 loss spike 的发生频率。
工程实现上,额外的 wall-time 开销约为 20%,且系统会自动检测 loss spike 后才激活 Anticipatory Routing,正常训练时不开启——几乎零成本。
SwiGLU Clamping(激活函数值域截断)
对 SwiGLU 的线性分量截断到 [-10, 10],门控分量上界截断到 10。这是一个极其简单但据论文反映极为有效的方法——直接消除了 MoE 层中的异常大值,从源头抑制训练不稳定。
类似方法在 Gemma 2 等论文中也有出现,V4 将其应用到了 SwiGLU 这个具体激活函数上。
后训练范式转移:On-Policy Distillation 替代混合 RL
V4 的后训练管道相比 V3.2 有一个根本性变化:完全放弃了混合 RL 阶段,转而使用 On-Policy Distillation(OPD)进行能力融合。

OPD 的技术创新在于使用全词汇表(full-vocabulary)logit 蒸馏而非 token 级别的 KL 估计。Token 级别的方法虽然节省显存,但梯度估计方差极大、训练不稳定。全词汇表蒸馏提供了更准确的梯度信号,代价是存储所有教师模型最后一层的 hidden states 并 on-the-fly 通过 prediction head 重建 logits。
工程挑战
10+ 个万亿参数的教师模型同时训练,显存压力极大。解决方案:所有教师权重 offload 到分布式存储,按需加载并 ZeRO-like 分片;按教师 index 排序 mini-batch,确保任意时刻最多 1 个教师的 prediction head 在 GPU 显存中。
性能评估:真实对比,不粉饰
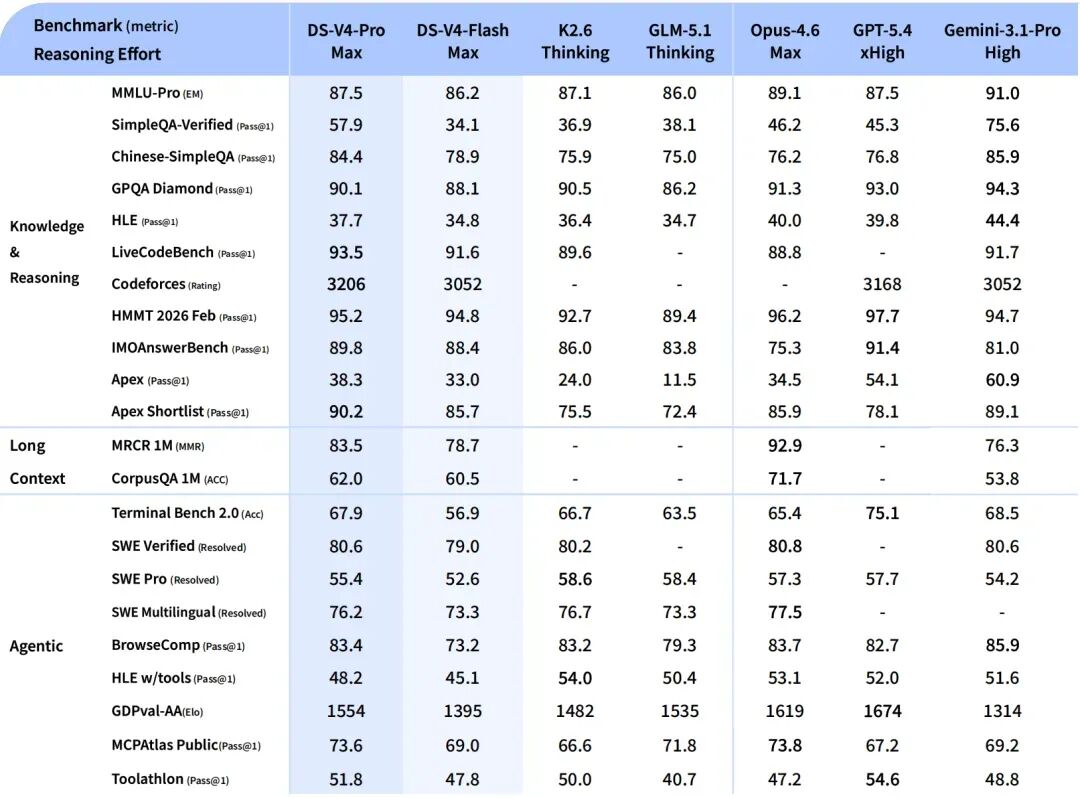
论文的评估部分难得地给出了非常坦诚的定位。以下是对主要基准的解读:
编程竞赛(Codeforces Rating)
在编程竞赛上,这是历史上第一次开源模型匹敌闭源顶级模型。V4-Pro-Max 当前在 Codeforces 人类参与者中排名第 23 位。

SWE-Verified(代码工程 Agent

SimpleQA-Verified(事实知识)
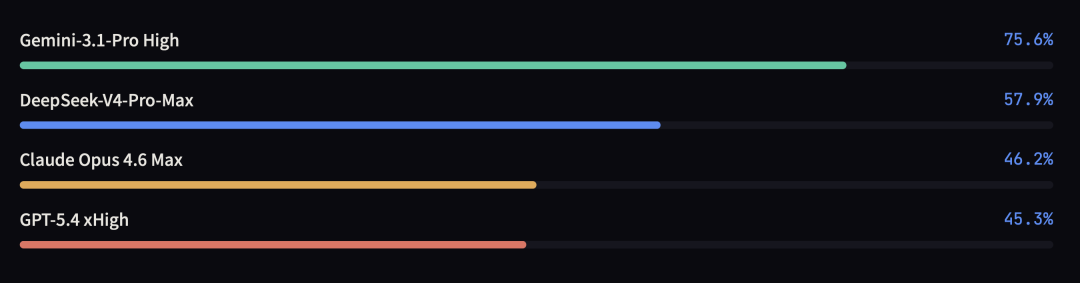
在事实知识方面,V4 领先所有其他开源模型,但与 Gemini-3.1-Pro 仍有明显差距。论文对此直言不讳。
百万 Token 上下文(MRCR 检索)

在长上下文检索方面,V4 超越了 Gemini-3.1-Pro,但仍落后于 Claude Opus 4.6。考虑到 V4 是第一个原生高效支持 1M 上下文的开源模型,这个成绩非常值得肯定。
论文明确指出:在推理能力上,V4-Pro-Max 超过 GPT-5.2 和 Gemini-3.0-Pro,但落后于 GPT-5.4 和 Gemini-3.1-Pro,开发轨迹上大约落后前沿闭源模型 3~6 个月。这种坦诚度在技术报告中颇为罕见。
不可忽视的基础设施创新
V4 的论文有将近三分之一篇幅在讲基础设施,这在 LLM 论文中非常罕见,但也最能体现工程深度。
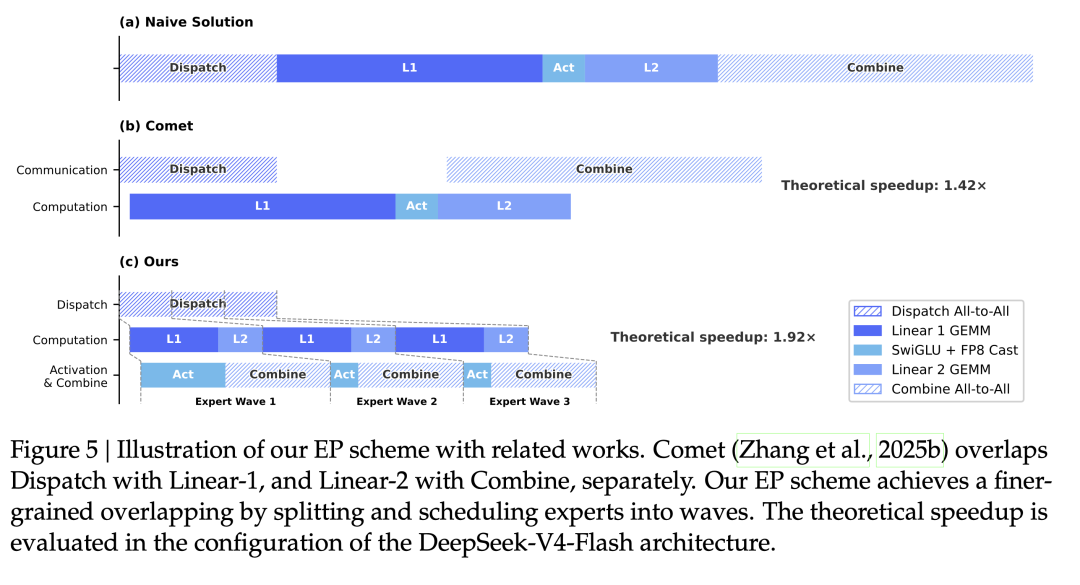
1.92× 理论加速比的通信计算重叠
将 MoE 层的 Expert 分批(wave)处理,当前 wave 的 Expert 在计算时,下一 wave 的 token 传输和上一 wave 的结果发送同时进行。相比 Comet 方案(1.42× 加速),V4 的细粒度 wave 调度实现了 1.92× 的理论加速,已开源为 DeepGEMM 的一部分(MegaMoE)。
形式化整数分析驱动的 kernel 开发
TileLang 是 DeepSeek 基于 TVM 自研的领域特定语言,用于开发 fused kernel。V4 在其中集成了 Z3 SMT solver,对 tensor index 算术进行形式化分析,将每次 kernel 调用的 CPU 端验证开销从数百微秒降至亚微秒级别,并解锁了更激进的向量化、内存优化。
共享前缀场景的推理复用
对于 CSA/HCA 的压缩 KV 条目,直接持久化存盘并在命中前缀时复用(跳过重新 prefill)。对于 SWA 的未压缩 KV(体积约是压缩 KV 的 8 倍),提供三种策略:Full Caching(零计算冗余但存储密集)、Periodic Checkpointing(可调节存储/计算权衡)、Zero SWA Caching(纯计算复现、零存储)。
这意味着什么
DeepSeek V4 不是一次参数规模的暴力扩展,而是一次系统性的架构重设计。CSA/HCA 混合注意力解决了百万上下文的效率瓶颈;mHC 解决了极深网络的训练稳定性;Muon 优化器提升了收敛速度;OPD 替代混合 RL 实现了更平滑的多专家能力融合。
更重要的是,这些创新是开源的。模型权重在 HuggingFace 以 MIT 协议开放,技术细节在论文中详细披露,CSA 的参考实现也已开源。整个社区都可以在这个基础上继续迭代。
真正值得关注的信号不是某个 benchmark 的分数,而是:百万 token 上下文正在从"技术噱头"变成可以日常部署的工程现实。这将深刻改变 Agentic AI、长文档分析、代码库理解等场景的产品边界。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)