LangChain 聊天模型核心能力 [ 4 ]

聊天模型 -- 流式传输
流式处理对于使基于 LLM 的应用程序能够响应最终用户至关重要。其通过逐步显示输出,甚至在完整的响应准备就绪之前,流式传输可以显著改善用户体验。
我们之前直接 invoke 的调用方式属于非流式传输,看到的现象是聊天模型直接返回全量内容,若模型思考时间较长,则我们等待的时间就越长。如下所示:
# 伪代码
model = ChatOpenAI()
model.invoke("讲一个1000字的笑话")
我们等待了 20s 之后,返回了全量结果:
从前有一个小镇,……,毕竟,生活中总需要一些笑声来调剂。
从结果看来,我们等待的时间太长了,对于用户来说,太长的等待时间严重影响体验。
接下来再来看下流式传输的效果,例如我们使用 deepseek 客户端,它默认流式返回:(聊天界面效果展示:问题 “讲一个 1000 字的笑话”,模型逐步输出)
效果得到了显著提升!那么对于 LangChain 的聊天模型来说,它同样支持流式返回。
stream() 同步传输
在 LangChain 聊天模型中,可以使用其 .stream() 方法,来同步生成流式响应的效果。
聊天模型的 .stream() 方法返回一个迭代器,该迭代器在生成输出时同步产生输出消息块。可以使用 for 循环实时处理每个块。代码如下:
from langchain_openai import ChatOpenAI
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 流式输出
chunks = []
for chunk in model.stream("讲一个50字的笑话"):
chunks.append(chunk)
print(chunk.content, end="|", flush=True)
打印结果:
| 有 | 一天,| 兔 | 子 | 和 | 乌 | 龟 | 比 | 赛 | 跑 | 步 |。| 兔 | 子 | 跑 | 得 | 飞 | 快 |,| 没 | 想 | 到 | 中 | 途 | 睡 | 着 | 了 |。| 等 | 它 | 醒 | 来 |,| 发现 | 乌 | 龟 | 快 | 到 | 终 | 点 | 了 |,| 兔 | 子 | 急 | 了 |:|“| 怎 | 么 | 可 | 能 |!|”| 乌 | 龟 | 笑 | 着 | 说 |:|“| 慢 | 就 | 是 | 快 |,| 我 | 在 | 享 | 受 | 风 | 景 |!|”|
通过调试,让我们来看下 chunk 是什么:调试信息显示,我们得到了一个叫做 AIMessageChunk 的东西,它代表 AIMessage 的一部分,也就是消息块。
消息块还可以直接相加,来看效果:
print("\n")
print(chunks[0] + chunks[1] + chunks[2] + chunks[3] + chunks[4])
结果如下(AIMessageChunk):
content='有一天,兔'
additional_kwargs={}
response_metadata={}
id='run--e619cbc3-9ee9-4ae7-a73e-32edb166d401'
astream() 异步传输
对于流式传输,通常我们可以选择异步调用。先来了解下异步相关知识。
异步相关概念
想象一个场景:你需要煮一壶水,同时还要给朋友发一条短信。我们分别用同步(传统)和异步两种方式来完成,以此对比并引入协程和事件循环的概念。
同步(阻塞)方式:这就像是一个 “死心眼” 的人,做事必须一件一件来:
import time
def boil_water():
print("开始煮水...")
time.sleep(5) # 模拟阻塞等待5秒
print("水开了!")
def send_message():
print("开始发短信...")
time.sleep(2) # 模拟阻塞等待2秒
print("短信发送成功!")
# 主程序
def main():
boil_water() # 先花5秒煮水,期间什么也不能做
send_message() # 水开后再花2秒发短信
main()
总耗时:7 秒问题:在 boil_water 函数等待的 5 秒里,CPU 完全空闲,但却不能去做 send_message 任务,效率低下。
异步方式:我们请出 asyncio、协程和事件循环。
什么是协程?
多进程通常利用的是多核 CPU 的优势,同时执行多个计算任务。每个进程有自己独立的内存管理,所以不同进程之间要进行数据通信比较麻烦。【进程之间的独立性 [ 程序地址空间 ]】
多线程是在一个 CPU 上创建多个子任务,当某一个子任务休息的时候其他任务接着执行。多线程的控制是由 Python 自己控制的。线程存在数据同步问题,所以要有锁机制。
协程的实现是在一个线程内实现的,相当于流水线作业。由于线程切换的消耗比较大,所以对于并发编程,可以优先使用协程。
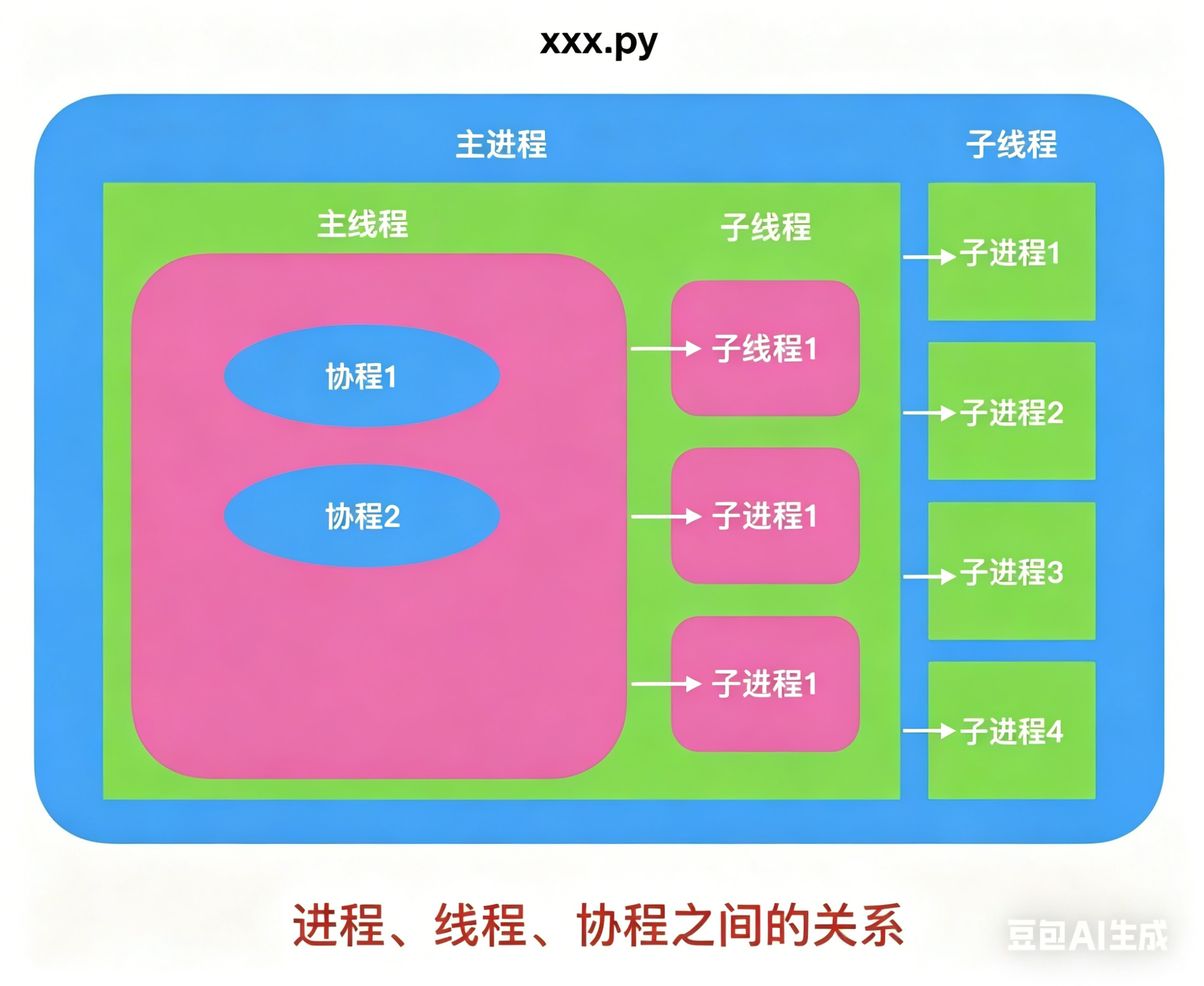
- 线程 = 多个工人同时干活(会抢、会冲突)
- 协程 = 一个工人快速切换做多个任务(绝对不冲突)
协程,作为一种轻量级的并发编程模型,可以被视为用户态的 “轻量级线程”。与传统线程相比,协程的核心优势在于其调度完全由用户空间掌控,避免了操作系统内核的频繁介入,从而显著降低了上下文切换的开销。在诸如网络数据刷新、资源加载、用户界面更新、以及 I/O 读写等场景下,如果并发任务的计算量相对较小、对系统资源占用较低,则不必动用操作系统级别的线程。
协程的切换由程序员和编程语言控制,程序员决定在何时暂停或恢复协程。协程是一个特殊的函数 [ 任务 ],它可以在执行过程中暂停,并在稍后恢复执行。它用 async def 定义,并在需要暂停的地方使用 await。
在我们的例子里,boil_water_async 和 send_message_async 就是两个协程。
import asyncio
# 定义协程
async def boil_water_async():
print("开始煮水...")
await asyncio.sleep(5) # 关键! await 表示“等待这个操作完成,期间让事件循环去做别的事”
print("水开了!")
async def send_message_async():
print("开始发短信...")
await asyncio.sleep(2) # 同样,等待2秒,但让出控制权
print("短信发送成功!")
什么是事件循环?事件循环是 asyncio(Python 标准库中的模块,用于编写异步 I/O 操作的代码)的核心,你可以把它想象成一个总调度员或一个高效的待办事项(To-Do List)管理员。
它的工作流程非常简单:
它维护着一个任务列表(比如:煮水、发短信)。
它不断地循环检查每个任务:
-
如果任务处于 “等待
I/O” 状态(比如等水开、等网络响应),就暂停它,立即去执行下一个已经 “就绪” 的任务。 -
如果任务的等待时间到了或者
I/O操作完成了,事件循环就恢复执行这个任务。
如何运行?
# 主程序(也是一个协程)
async def main():
# 创建两个任务,并交给事件循环去调度
task1 = asyncio.create_task(boil_water_async())
task2 = asyncio.create_task(send_message_async())
# 等待两个任务都完成
await task1
await task2
# 它负责创建事件循环,并将第一个协程(主程序)放入其中运行。
asyncio.run(main())
输出结果:
开始煮水... # 任务1开始
开始发短信... # 任务1遇到await,立即让出控制权,事件循环马上启动任务2
(此时两个任务都在后台“等待”)
短信发送成功! # 任务2的等待时间先到,任务2完成
(继续等待约3秒后...)
水开了! # 任务1的等待时间也到了,任务1完成
总耗时:5 秒(因为两个任务的等待时间是并发的)
通过使用 asyncio,我们可以在单线程中同时处理多个任务。一个在单线程内调度和管理所有协程的核心机制,就是事件循环。它不停地检查哪些协程可以执行,哪些在等待。
总结一下:
协程:是 asyncio 的核心概念之一。它是一个特殊的函数,可以在执行过程中暂停,并在稍后恢复执行。协程通过 async def 关键字定义,并通过 await 关键字暂停执行,等待异步操作完成。要运行一个协程,可以使用 asyncio.run() 函数。它会创建一个事件循环,并运行指定的协程。
事件循环:是 asyncio 的核心组件,负责调度和执行协程。它不断地检查是否有任务需要执行,并在任务完成后调用相应的回调函数。
使用 astream() 异步流式传输
可以使用 .astream() 方法,来异步生成流式响应的效果,这专为非阻塞工作流而设计。可以在异步代码中使用它来实现相同的实时流式处理行为。
代码如下:
from langchain_openai import ChatOpenAI
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 异步调用
async def async_stream():
print("=== 异步调用 ===")
async for chunk in model.astream("讲一个50字的笑话"):
print(chunk.content, end="|", flush=True)
asyncio.run(async_stream())
打印结果:
=== 异步调用 ===
|有|一|天|,|一|只|鸭|子|走|进|药|店|,|问|:|“|你|们|有|口|红|吗|?|”|药|剂|师|说|:|“|没|有|!|”|鸭|子|失|望|地|摇|摇|头|转|身|离|开|。|第|二|天|,|鸭|子|又|来|:|“|你|们|有|口|红|吗|?|”|药|剂|师|说|:|“|没|有|!|”|鸭|子|说|:|“|那|你|们|为|什|么|不|进|货|!|”|
使用 StrOutputParser 解析模型的输出
还记得最早我们说过 Runnable 接口:
聊天模型、输出解析器等组件,都实现了 LangChain 的 Runnable 接口,他们都是 Runnable 接口的实例。Runnable 定义了一个标准接口,允许 Runnable 组件:允许 LangChain 协同工作创建复杂的管道。
Invoked(调用):单个输入转换为输出。Batched(批处理):多个输入被有效地转换为输出。Streamed(流式传输):输出在生成时进行流式传输。Composed(组合):可以组合多个Runnable,以便使用LCEL协同工作创建复杂的管道。- ...
可以看到,流式传输并不是聊天模型独有的能力,而是所有实现了 Runnable 接口的组件,都天然具备的通用能力!
不过要注意:
- 并不是所有
Runnable组件都需要支持流式处理 - 有些场景下,流式处理可能不必要、实现困难,甚至完全没有意义
- 举个例子:我们后面会学的
Retriever(检索器),就不支持流式处理
对于支持流式传输的组件,返回的 “数据块 [ chunk ]” 类型,会根据组件的不同而变化:
- 目前我们用聊天模型做流式传输,返回的每个数据块都是
AIMessageChunk类型 - 但如果换成其他组件,流式返回的块类型可能就不一样了
接下来,我们用 LCEL(LangChain 表达式语言) 构建一个简单的链,把模型和输出解析器结合起来,看看流式处理的效果。别忘了:用 LCEL 创建的链,同样实现了 Runnable 接口,所以它也天然支持流式传输!
这个链的工作流程是:
- 聊天模型产生流式返回(返回
AIMessageChunk) - 输出解析器从
AIMessageChunk中提取出文本内容字段 - 这样就为上层提供了统一的 “纯文本令牌” 流式接口
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出解析器 - 把模型返回的复杂消息,只把文字内容抽出来
parser = StrOutputParser()
chain = model | parser
for chunk in chain.stream("写一段关于爱情的歌词,需要5句话"):
print(chunk, end="|", flush=True)
打印结果:
|在|星|空|下|许|下|心|愿|,|
|你|的|笑|容|如|晨|曦|般|温|暖|,|
|手|牵|手|走|过|每|段|时|光|,|
|无|论|风|雨|,|依|然|相|伴|,|
|爱|是|永|恒|,|心|与|心|相|连|。|
自定义流式输出解析器
在我们刚才的输出里,模型是一个字、两个字这样小块流式输出的。但我们希望:仍然保持流式功能,但是让输出变成 “一句话一句话” 吐出来。
要做到这一点,我们不能直接用默认的解析器,而是需要自己写一个自定义的流式解析器,用来控制输出格式。
你可以这样理解:
- 模型还是一边生成一边吐字(流式)
- 我们在中间加一个 “过滤器 / 整理器”
- 它把零散的字攒成一句话,遇到句号就输出一句
- 这样最终效果就是:流式 + 一句一句输出
这就叫自定义流式输出。
之前我们讲过:聊天模型的 .stream() 返回的是一个迭代器(iterator)它会一边生成,一边不断返回内容块。
我们自己写的自定义解析器,也要符合这种迭代器格式:
-
同步格式:
Iterator[Input] -> Iterator[Output]意思:输入是迭代器,输出也是迭代器 -
异步格式:
AsyncIterator[Input] -> AsyncIterator[Output]
简单说:你给我流式小块,我给你转成你想要的流式格式。
我们要写一个按句号分割句子的自定义解析器。它的功能就是:
- 接收模型流式输出的一个个字
- 攒起来
- 遇到句号就输出完整一句话
- 继续攒下一句
这就是最经典、最常用的自定义流式输出示例。
# 导入大模型对象
from langchain_openai import ChatOpenAI
# 导入字符串解析器:专门把模型复杂消息对象,提取为纯文本字符串
from langchain_core.output_parsers import StrOutputParser
# 导入类型注解:迭代器、列表,规范流式输入输出类型
from typing import Iterator, List
# 1. 初始化大语言模型,指定使用 gpt-4o-mini
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 初始化基础字符串解析器
# 作用:模型流式返回的是 AIMessageChunk 复杂对象
# StrOutputParser 自动帮我们提取里面的文本 content,吐出纯字符串小块
parser = StrOutputParser()
# 3. 自定义流式分割处理器
# 入参:接收上游传过来的 字符串迭代器(源源不断的文字小块)
# 出参:产出 包裹句子的列表迭代器,实现【按句号一句一句流式输出】
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:
# 定义缓冲区:用来临时积攒模型零散吐出的字、词语片段
buffer = ""
# 遍历上游流式传递过来的每一段文本碎片
for chunk in input:
# 将当前碎片追加到缓冲区,持续攒内容
buffer += chunk
# 循环判断:只要缓冲区里出现了句号,说明凑齐了一句话
while "." in buffer:
# 找到第一个句号的下标位置
stop_index = buffer.index(".")
# 截取句号前面的内容,去除首尾空格,包装为列表并产出
# yield 代表流式吐出,不阻塞、符合Runnable流式规范
yield [buffer[:stop_index].strip()]
# 截断缓冲区:保留句号后面剩余内容,继续拼接下一句话
buffer = buffer[stop_index + 1 : ]
# 循环结束后,如果缓冲区还有剩余未收尾文本,统一最后产出
if buffer.strip():
yield [buffer.strip()]
# 4. 使用 LCEL 管道拼接整条链路
# 执行顺序:
# model(大模型生成)
# | parser(转为纯文本)
# | split_into_list(自定义按句号断句)
chain = model | parser | split_into_list
# 5. 调用 chain.stream 开启完整流式链路
# 特点:全程流式、不等待全部生成完毕再输出
for chunk in chain.stream("写一份关于爱情的歌词,需要5句话,每句话用句号分割"):
# 逐句打印,end="|" 做分割标记,flush=True 强制即时刷新输出,避免缓存滞留
print(chunk, end="|", flush=True)代码中注意:因为 LangChain 有一个超级黑魔法:只要你的函数符合迭代器格式(输入迭代器,输出迭代器),LangChain 会自动把它包装成 Runnable!
你不用继承、不用实现任何接口,写个普通函数就能放进 | 链里!
打印结果:
["在星空下许下承诺的誓言"]|["你的笑容如晨曦,温暖了我的心"]|["无论时光如何流转,我愿与你携手共行"]|["爱情是我们心中永恒的旋律"]|["每一次相拥,都是一场甜蜜的重逢"]|
深度探索流式传输
SSE 协议介绍
HTTP 协议本身设计为无状态的请求 - 响应模式,严格来说,是无法做到服务器主动推送消息到客户端,但通过 Server-Sent Events(服务器发送事件,简称 SSE)技术可实现流式传输,允许服务器主动向浏览器推送数据流。
也就是说,服务器向客户端声明,接下来要发送的是流消息(streaming),这时客户端不会关闭连接,会一直等待服务器发送过来新的数据流。
SSE(Server-Sent Events)是一种基于 HTTP 的轻量级实时通信协议,浏览器可以通过内置的 EventSource API 接收并处理这些实时事件。
核心特点
- 基于
HTTP协议:复用标准HTTP/HTTPS协议,无需额外端口或协议,兼容性好且易于部署。 - 单向通信机制:
SSE仅支持服务器向客户端的单向数据推送,客户端通过普通HTTP请求建立连接后,服务器可持续发送数据,客户端无法通过同一连接向服务器发送数据。 - 自动重连机制:支持断线重连,连接中断时,浏览器会自动尝试重新连接(支持
retry字段指定重连间隔)。 - 自定义消息类型:客户端发起请求后,服务器保持连接开放,响应头设置
Content-Type: text/event-stream,标识为事件流格式,持续推送事件流。
数据格式
服务端向浏览器发送 SSE 数据,需要设置必要的 HTTP 头信息:
Content-Type: text/event-stream;charset=utf-8
Connection: keep-alive
Cache-Control: no-cache
每一次发送的消息,由若干个 message 组成,每个 message 之间由 \n\n 分隔,每个 message 内部由若干行组成,每一行都是如下格式:
[field]: value\n
Field 可以取值为:
data[必需]: 数据内容event[非必需]: 表示自定义的事件类型,默认是message事件id[非必需]: 数据标识符,相当于每一条数据的编号retry[非必需]: 指定浏览器重新发起连接的时间间隔
除此之外,还可以有冒号 : 开头的行,表示注释。
数据示例
event: foo
data: a foo event\n\n
data: an unnamed event\n\n
event: bar
data: a bar event\n\n
LangChain 流式传输流程分析
LangChain 本身并不 “创造” 或 “规定” 一个底层的网络传输协议,而是依赖于其底层的大模型供应商(如 OpenAI)和我们自身服务应用所使用的 Web 框架(如 FastAPI)的协议。
因此对于 LangChain 的流式传输能力,本身是因为大模型供应商提供了流式传输能力,由 LangChain 进行调用后接收并处理成一个传的 AIMessageChunk。
通过源码分析流程
接下来我们将会通过分析相关源码探索整个传输流程。整个过程我们以 OpenAI 举例,其他大模型方式类似,可自行探索。当我们向 OpenAI 发起流式请求,LangChain 实际上会通过 BaseChatOpenAI 类中的 _stream 方法发起调用。
下面来看下 _stream 方法的关键流程性源码,完整源码见:class langchain_openai.chat_models.base.BaseChatOpenAI
def _stream(
self,
messages: list[BaseMessage], # 输入:用户的消息列表(HumanMessage等)
stop: Optional[list[str]] = None, # 停止词,可选
run_manager: Optional[CallbackManagerForLLMRun] = None, # 回调管理器(打日志、监控)
*,
stream_usage: Optional[bool] = None, # 是否流式返回用量信息
**kwargs: Any, # 其他扩展参数
) -> Iterator[ChatGenerationChunk]: # 返回值:迭代器,不断吐出 ChatGenerationChunk
# ====================== 1. 配置流式模式 ======================
# 强制开启流式输出,告诉大模型:我要一边生成一边返回
kwargs["stream"] = True
# 判断是否需要在流式中携带 token 使用量信息
stream_usage = self._should_stream_usage(stream_usage, **kwargs)
# ====================== 2. 构建发给 OpenAI 的请求体 ======================
# 把 messages、stop、model、temperature 等参数打包成 OpenAI API 需要的格式
payload = self._get_request_payload(messages, stop=stop,** kwargs)
# ====================== 3. 定义流式消息块类型 ======================
# 重点!
# 所有流式返回的消息块,默认都是 AIMessageChunk 类型
# 这就是我们之前说的:聊天模型流式返回 AIMessageChunk
default_chunk_class: type[BaseMessageChunk] = AIMessageChunk
# 基础生成信息(存放模型信息、使用量、元数据等)
base_generation_info = {}
# ====================== 4. 发起流式请求 ======================
# 判断是否指定了 response_format(如JSON格式)
if "response_format" in payload:
# 指定格式的流式调用
self.root_client.chat.completions.stream(**payload)
context_manager = response_stream
else:
# 普通流式调用:调用 OpenAI API,开始实时返回数据块
response = self.client.create(**payload)
context_manager = response
# ====================== 5. 处理 OpenAI 返回的流式块 ======================
try:
# 打开流式响应上下文,开始逐包接收数据
with context_manager as response:
# 遍历 OpenAI 实时推送的每一个小数据块
for chunk in response:
# ====================== 核心转换 ======================
# 将 OpenAI 原生返回的 chunk
# 转换成 LangChain 统一的 ChatGenerationChunk
# 内部包装的就是 AIMessageChunk
generation_chunk = self._convert_chunk_to_generation_chunk(
chunk,
default_chunk_class, # 这里就是 AIMessageChunk
base_generation_info if is_first_chunk else {},
)
# 如果是空块,跳过
if generation_chunk is None:
continue
# ====================== 回调通知 ======================
# 如果有回调管理器,通知:新的 token 生成了
if run_manager:
run_manager.on_llm_new_token(
chunk.generation_chunk,
logprobs=logprobs,
)
# ====================== 流式吐出 ======================
# yield:把数据块抛给上层(LangChain的stream迭代器)
# 上层 for chunk in model.stream() 就能收到
yield generation_chunk
# ====================== 6. 异常处理 ======================
# 捕获 OpenAI 错误请求(如参数错误、内容安全过滤)
except OpenAI.BadRequestError as e:
_handle_openai_bad_request(e)从上述流程看来,这就是流式逐块产生 AIMessageChunk 聊天消息的核心方法。那么接下来看三个问题:
- 发起调用时,底层使用什么协议?
- 如何支持流式传输?
- 返回的块是什么格式,如何转换成
AIMessageChunk?
这三个问题都掌握后,整个流式传输的流程就都能理解了。
LangChain 请求 OpenAI 使用什么协议?
回答这个问题,需要看 LangChain 关于 OpenAI 的客户端是怎么定义的。让我们找到 class langchain_openai.chat_models._client_utils_.SyncHttpxClientWrapper,如下所示:
import openai
import os
from typing import Optional, Any
# 自定义同步 HTTPX 客户端包装类,继承自 openai 默认的 HttpxClient
class SyncHttpxClientWrapper(openai.DefaultHttpxClient):
# 实现上下文管理器的进入方法,使用 with 语句时触发
def __enter__(self) -> None:
# 预留扩展:可在这里添加客户端初始化逻辑
...
# 析构函数:对象被销毁、垃圾回收时自动执行
def __del__(self):
# 如果客户端未关闭
if not self._closed:
try:
# 主动关闭客户端,释放网络连接资源
self.close()
except Exception: # noqa: S110 忽略异常,避免程序崩溃
# 捕获所有关闭异常,不做处理,保证程序稳定性
pass
# 构建同步 HTTPX 客户端的工厂函数
def build_sync_httpx_client(
base_url: Optional[str], timeout: Any
) -> SyncHttpxClientWrapper:
# 优先级:传入的 base_url > 环境变量 OPENAI_BASE_URL > 默认官方地址
base_url = (
base_url
or os.environ.get("OPENAI_BASE_URL")
or "https://api.openai.com/v1"
)
# 预留:实际会在这里完成客户端完整构建、超时配置等
...从上面的代码看来,LangChain 使用了 OpenAI 的官方 OpenAI SDK for Python 接入方式,继承了 openai._base_client 定义了一个 HTTP 客户端。因此在调用时,发起的是 HTTP 调用。
具体流程就是:LangChain 向 OpenAI 发起请求全程基于标准 HTTP/HTTPS 应用层协议,底层依托 httpx 同步 / 异步 HTTP 客户端发送 REST 风格接口请求,通过 HTTPS 加密传输数据,以 JSON 格式承载请求参数与响应内容,流式对话则依靠 HTTP 长连接结合 SSE 服务端推送机制,持续接收模型分段返回的内容块。
LangChain 如何支持流式传输?
模型厂商(如 OpenAI)本身并不会自定义全新的网络传输协议,LangChain 也不会。它们都基于通用的 HTTP/HTTPS 协议通信。LangChain 的角色只是适配层,负责把请求按模型要求组装好,再交给模型服务端处理。
当我们要做流式输出时,只需要在请求里加上 stream=True(这正是 _stream() 源码第一步做的事)。一旦开启 stream=True,OpenAI 就会使用 SSE(Server-Sent Events) 技术:保持 HTTP 连接不关闭,一边生成内容,一边分段把数据推送给客户端。
比如你问:“你好,我是张三。”
OpenAI 不会等全部回答完再返回,而是一段一段实时推回来,像这样(简化版):
data: {"content": "你好"}
data: {"content": ","}
data: {"content": "我"}
data: {"content": "是"}
data: {"content": "AI"}
...
每一段都是一个小数据块,LangChain 底层的 _stream() 方法负责接收这些块,再包装成 AIMessageChunk 抛给上层使用。
所以结论非常明确:设置 stream=True → 让 OpenAI 以 SSE 流式分段返回数据 → LangChain 接收并处理这些块。这就是流式输出的完整底层原理。
OpenAI 返回的块是什么格式,如何转换成 AIMessageChunk?
OpenAI 返回的数据块格式我们已经看到了,将其转换为 LangChain 自定义的 AIMessageChunk 则是通过 _convert_chunk_to_generation_chunk() 方法完成的。关键代码及注释如下:
def _convert_chunk_to_generation_chunk(
self,
chunk: dict, # OpenAI API 返回的原始流式数据块(字典格式)
default_chunk_class: type, # 要转换成的消息块类型,这里是 AIMessageChunk
base_generation_info: Optional[dict], # 基础生成信息(模型、ID等元数据)
) -> Optional[ChatGenerationChunk]:
# 1. 从 OpenAI 返回块中提取 choices 字段(模型的回复内容都在这里)
choices = chunk.get("choices", []) or chunk.get("stream_choices", [])
# 遍历每一个回复选项
for choice in choices:
# 2. 如果当前选项没有索引,说明是无效块,直接跳过
if choice.get("index") is None:
return None
# 3. 核心:把 OpenAI 的 delta 增量数据 → 转为 LangChain 的消息块
# delta 就是模型一点点返回的文字片段(如:你、好、呀)
message_chunk = self._convert_delta_to_message_chunk(
choice["delta"], default_chunk_class
)
# 4. 构建生成信息(如 finish_reason、模型信息等)
# ...(省略其他逻辑)
# 5. 包装成 ChatGenerationChunk 并返回给上层流式处理
generation_chunk = ChatGenerationChunk(
message=message_chunk, generation_info=generation_info or None
)
return generation_chunk
下面这个方法负责把 OpenAI 的 delta 片段 → 转为 AIMessageChunk:
def _convert_delta_to_message_chunk(
self,
delta: Mapping[str, Any], # OpenAI 返回的增量内容:{"role": "assistant", "content": "你好"}
default_class: type[BaseMessageChunk] # 默认消息类型,这里是 AIMessageChunk
) -> BaseMessageChunk:
# 从 delta 中提取角色、内容、ID
id_ = delta.get("id")
role = cast(str, delta.get("role"))
content = cast(str, delta.get("content") or "") # 提取真正的文字片段
# 处理工具调用、函数调用等扩展内容(省略)
tool_calls = []
if function_call := delta.get("function_call"):
...
elif tool_calls_raw := delta.get("tool_calls"):
for raw_tool_call in tool_calls_raw:
...
# 根据角色判断应该创建哪种消息块
# user → 用户消息块
if role == "user":
return HumanMessageChunk(content=content, id=id_)
# assistant → AI 消息块(我们最关心的 AIMessageChunk)
elif role == "assistant" or default_class == AIMessageChunk:
return AIMessageChunk(
content=content,
additional_kwargs=additional_kwargs,
tool_call_chunks=tool_call_chunks,
id=id_,
)
# system → 系统消息块
elif role in ("system", "developer") or default_class == SystemMessageChunk:
return SystemMessageChunk(
content=content, id=id_, additional_kwargs=additional_kwargs
)
# 其他消息类型(省略)
elif role == "function" or default_class == FunctionMessageChunk:
return FunctionMessageChunk(content=content, name=name, id=id_)
elif role == "tool" or default_class == ToolMessageChunk:
return ToolMessageChunk(content=content, tool_call_id=tool_call_id, id=id_)
else:
return default_class(content=content, role=role, id=id_)
到此我们就知道了 LangChain 流式传输的完整流程与底层协议。总结一下:
LangChain 中 OpenAI 包通过集成 OpenAI Python SDK,提供了一个 HTTP 客户端,支撑 LangChain 向 OpenAI 的 API 发起网络调用。
如果需要开启流式传输,只需在请求参数中配置 stream=True,告知服务端采用 SSE 服务端推送模式分段返回数据。
LangChain 持续接收 OpenAI 推送的 SSE 原始数据,再通过内部转换方法,将厂商自定义的流式 JSON 碎片,统一转为 LangChain 标准的 AIMessageChunk 消息块。这套统一的封装逻辑,让上层代码无需区分 OpenAI、Anthropic 等不同模型厂商的响应格式,实现多模型流式逻辑的通用复用。
LangChain 发起请求(携带 stream=True)
↓
HTTPS + SSE 长连接
↓
OpenAI 服务端 → 持续推送 原始SSE数据块(data: {} JSON碎片)
↓
_langchain 底层:_convert_chunk_to_generation_chunk()
↓
解析 choices.delta 增量字段
↓
_convert_delta_to_message_chunk() 角色匹配
↓
生成标准化 AIMessageChunk
↓
上层:stream迭代器 / LCEL链路 直接消费
三、核心一句话背诵
OpenAI 依靠 SSE+HTTP 返回碎片化 JSON 数据,LangChain 通过两层转换函数,把厂商原生增量数据,统一收敛为 AIMessageChunk,实现全模型流式接口标准化。
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)