Set类:关联式容器|pair<>|lower_bound|upper_bound
目录
区间查找:lower_bound和upper_bound 接口
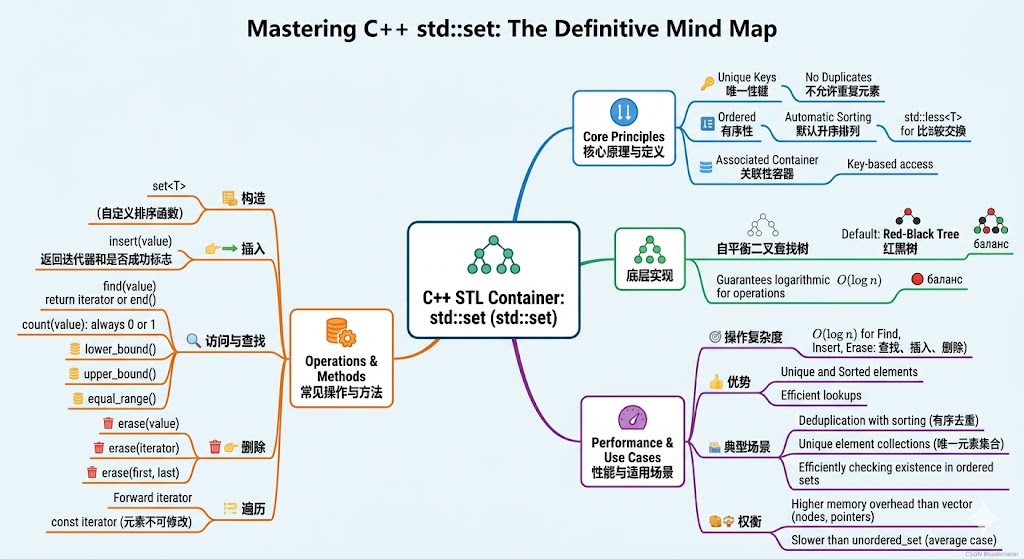
I.Set类
set 是 STL 中的容器之一,不同于普通容器,它的查找速度极快,常用来存储各种经常被检索的数据,因为容器的底层是平衡二叉搜索树中的红黑树。除此之外,还可以借助其特殊的性质,解决部分难题
template < class T, // set::key_type/value_type
class Compare = less<T>, // set::key_compare/value_compare
class Alloc = allocator<T> // set::allocator_type
> class set;关联式容器
之前的STL容器学习中,我们接触到的是 序列式容器,比如string,vector,list,deque等,它们的特点是 底层为线性序列的数据结构,比如list,其中的节点是线性存储的,一个节点存储一个元素,其中存储的元素都可有序,但未必有序
- 【关联式容器】 则比较特殊,其中存储的是
<key, value>的 键值对,这就意味着可以按照 键值大小key以某种特定的规则放置于适当的位置,关联式容器 没有首尾的概念,因此没有头插尾插等相关操作,本文中学习的set就属于 关联式容器
注意: stack、queue 等适配器也属于序列式容器,因为他们的底层是 deque 等容器
键值对
【键值对】是 一种用来表示具有一一对应关系的结构,该结构中一般只包含两个成员变量:key 和 value,前者表示 键值,后者表示 实值 关联式容器的实现离不开【键值对】
pair中的first表示 键值,second则表示 实值,在给 【关联式容器】 中插入数据时,可以构建pair对象
比如下面就构建了一个 键值 key 为 string,实值 value 为 int 的匿名 键值对 pair 对象
pair<string, int>("hehe", 123);
- 可以将此匿名对象传入 关联式容器 中,当然这样写未免过于麻烦了,于是库中设计了一个函数模板
make_pair,可以根据传入的参数,去调用pair构建对象并返回make_pair("hehe", 123); //构建出的匿名对象与上面的一致
元素的插入
 通过插入新的元素来扩展容器,有效地通过插入的元素数量增加容器的大小。
通过插入新的元素来扩展容器,有效地通过插入的元素数量增加容器的大小。
因为集合中的元素是唯一的,插入操作检查每个插入的元素是否等同于已经在容器中的元素。
如果是,则不插入该元素,返回一个到这个现有元素的迭代器(如果该函数返回一个值)。
pair<iterator,bool> insert (const value_type& val);
iterator insert (iterator position, const value_type& val);
template <class InputIterator>
void insert (InputIterator first, InputIterator last);- 我们通过 insert 接口将数据插入到 𝑆𝑒𝑡 中,然后使用迭代器将数据打印出来。
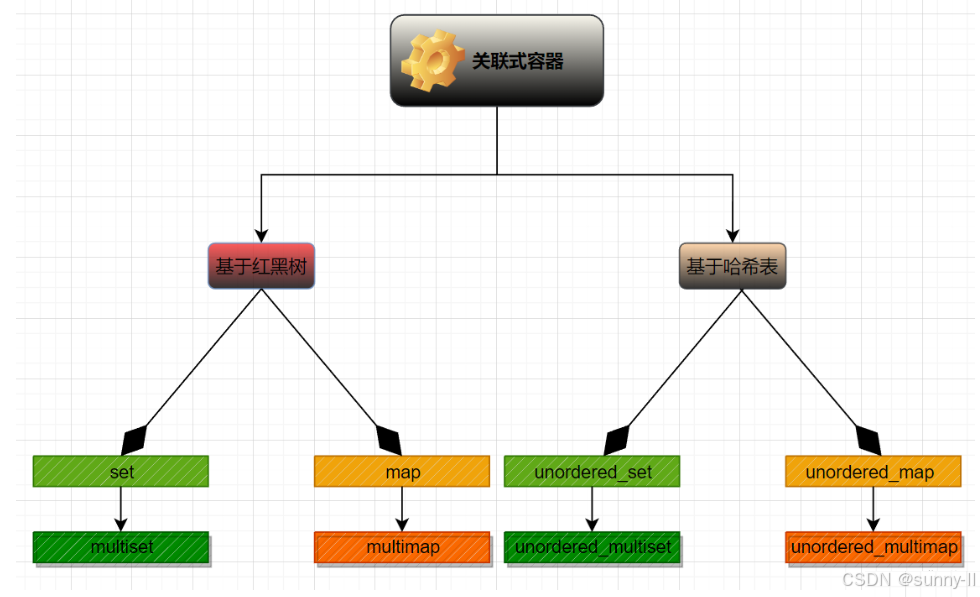
void test_set1() { set<int> s; s.insert(4); s.insert(5); s.insert(2); s.insert(1); s.insert(3); s.insert(3); // 排序 + 去重 set<int>::iterator it = s.begin(); while (it != s.end()) { cout << *it << " "; ++it; } cout << endl; } int main(void) { test_set1(); return 0; }结果如下:
我们发现 𝑆𝑒𝑡
确实有去重的效果,这和数学中的 集合 (set) 是一样的,集合元素具有 "惟一性" 。
所以,如果插入的元素已经存在于 𝑆𝑒𝑡里了,就不插入了。
不仅如此,我们是按照 4,5,2,1,3,3 的顺序依次插入的,它还会自动帮你排好序:
[4,5,2,1,3,3]→𝑠𝑒𝑡{1,2,3,4,5}
𝑆𝑒𝑡 是 "排序 + 去重" 的!
注意:set同样支持范围for
元素的查找
find 接口,如果这个元素被找到就会返回 val 的迭代器,否则返回 end。
iterator find (const value_type& val) const;void test_set2() {
set<int> s;
s.insert(4);
s.insert(5);
s.insert(2);
s.insert(1);
s.insert(3);
s.insert(3);
set<int>::iterator pos = s.find(2);
if (pos != s.end()) {
cout << "找到了" << endl;
}
}我们知道algorithm中也有一个find,那么这两个有什么区别呢???
解答:差异主要表现在时间复杂度上,algorithm中find的时间复杂度为O(n),而Set中的find的时间复杂都为O(logN)
count接口
count 接口,有时我们需要判断元素在不在集合中,使用 count 往往比使用 find 方便。
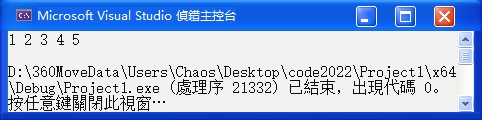
size_type count (const value_type& val) const;void test_set3() {
set<int> s;
s.insert(4);
s.insert(5);
s.insert(2);
s.insert(1);
s.insert(3);
s.insert(3);
if (s.count(3)) {
cout << "3在" << endl;
}
}结果如下:
元素的删除
erase 支持三种,分别是在某个位置删除,删除一个值和删除一个区间:
void erase (iterator position);
size_type erase (const value_type& val);
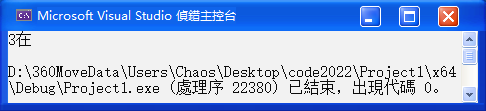
void erase (iterator first, iterator last);void test_set2() {
set<int> s;
s.insert(4);
s.insert(5);
s.insert(2);
s.insert(1);
s.insert(3);
s.insert(3);
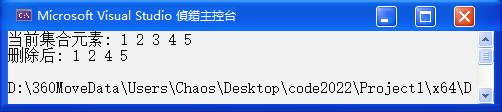
cout << "当前集合元素: ";
for (auto e : s) {
cout << e << " ";
}
cout << endl;
int x = 0;
while (1) {
cout << "请输入要删除的元素:";
cin >> x;
// 查看要删除的元素在不在集合中
set<int>::iterator pos = s.find(x);
if (pos != s.end()) {
// 在集合中,删除
s.erase(pos);
cout << "成功删除: " << x << endl;
// 打印删除后的结果
cout << "删除后: ";
for (auto e : s) {
cout << e << " ";
}
cout << endl;
}
else {
// 不在集合中,提示删除失败
cout << "删除失败!" << x << "不在集合中。" << endl;
}
}
}结果如下:
当然了,还可以直接给 erase 一个值进行删除,这个用法相较于迭代器就简单许多!
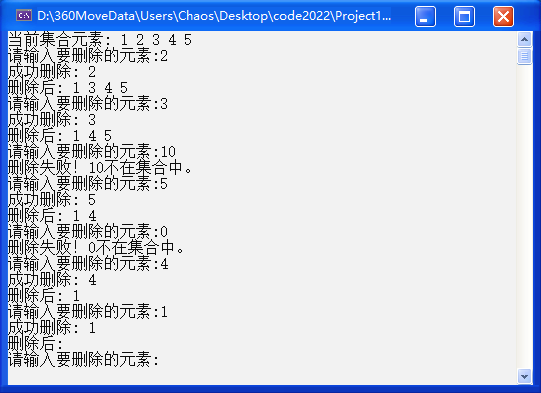
void test_set3() {
set<int> s;
s.insert(4);
s.insert(5);
s.insert(2);
s.insert(1);
s.insert(3);
s.insert(3);
cout << "当前集合元素: ";
for (auto e : s) {
cout << e << " ";
}
cout << endl;
s.erase(3); // 直接删除3
cout << "删除后: ";
for (auto e : s) {
cout << e << " ";
}
cout << endl;
}结果如下:
❓ 思考:那迭代器的方式删除和直接删除有什么区别呢?
- 💡 解答:迭代器 find + erase(pos) 的是找到了再删,我们一般和 find 搭配使用,因为如果这个元素不存在我们还强硬调用 erase 删除就会引发报错。而 erase(x) 就比较好了,直接删,就算这个值不存在也不会报错。
区间查找:lower_bound和upper_bound 接口
iterator lower_bound(const key_type& key);lower_bound() 用于在指定区域内查找 不小于 (大于等于) 目标值的第一个元素。
返回一个指向集合中第一个大于等于给定值的元素的迭代器,如果找不到,则返回 end。

即获取集合中任意元素的下界:
[𝑥,+∞)
#include <iostream>
#include <set>
using namespace std;
int main(void)
{
set<int> s = { 10, 20, 30, 40, 50 };
// 使用 lower_bound 查找第一个不小于 25 的元素
auto it = s.lower_bound(25);
// 输出结果
if (it != s.end()) {
cout << "第一个不小于 25 的元素是: " << *it << endl;
}
else {
cout << "未找到不小于 25 的元素" << endl;
}
return 0;
}结果如下:
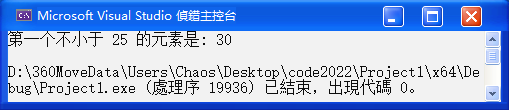
🔑 解读:lower_bound(25) 会返回一个指向集合中第一个不小于 25 的元素的迭代器。在集合{10, 20, 30, 40, 50} 中,第一个不小于 25 的元素是 30,所以输出结果是30。
void test_set4() {
set<int> s = { 10, 20, 30, 40, 50 };
cout << "删除前: ";
for (auto e : s) {
cout << e << " ";
} cout << endl;
int x = 0;
cout << "请输入x: ";
cin >> x;
auto it = s.lower_bound(x); // 找到第一个不小于x的元素
s.erase(it, s.end()); // 迭代器区间删除
cout << "删除后: ";
for (auto e : s) {
cout << e << " ";
} cout << endl;
}结果如下:
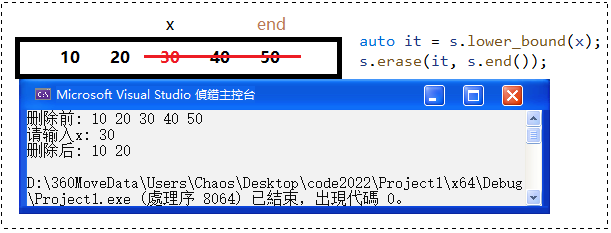
- 🔑 解读:接收 x 的值为 30 之后,就从 lower_bound 的位置开始作为迭代器的起始位置,end 作为结束位置,调用迭代器版本的 erase 就可以做到 30, 40, 50 都删除的效果,最后保留 10, 20。
还有一个 upper_bound 接口,在指定范围内查找大于目标值的第一个元素,不包含等于。
(𝑥,+∞)
这两个接口就是为了迎合迭代器的 "左闭右开" 而配备的,可以结合使用。
void test_set5() {
set<int> s = { 10, 20, 30, 40, 50 };
cout << "删除前: ";
for (auto e : s) {
cout << e << " ";
} cout << endl;
int x = 0, y = 0;
cin >> x >> y;
auto left_it = s.lower_bound(x);
auto right_it = s.upper_bound(y);
s.erase(left_it, right_it);
cout << "删除后: ";
for (auto e : s) {
cout << e << " ";
} cout << endl;
}结果如下:

II.Set的特点
set 和 vector 的对比
vector 是一个动态数组,它允许存储重复的元素,且元素存储的顺序是按插入顺序排列的
- 插入操作:在
vector的末尾插入元素的时间复杂度为O(1),但如果你想在vector的中间插入元素,则需要O(n)的时间来移动元素。 - 查找操作:在
vector中查找元素通常需要O(n)的时间(除非你自己进行排序并使用二分查找)。
set 是一个集合,它自动去重并保持元素的有序性
- 插入操作:在
set中插入元素的时间复杂度为O(log n),并且插入后元素自动排序。 - 查找操作:在
set中查找元素的时间复杂度为O(log n),比vector中的线性查找要高效得多。
使用场景
vector 适用于需要频繁访问元素并且不关心元素顺序的场景,比如用来存储一组数据,然后你可以遍历、访问这些数据。
set 适用于需要存储唯一元素且需要快速查找或顺序访问的场景,比如你需要维护一个不重复的、有序的数据集合


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)