LangChain 最新实战指南教程Agent开发全攻略:工具/中间件/记忆/流式一篇通(附避坑手册)
LangChain 从入门到实战
基于2026年 LangChain 官方文档的实战指南。
本文使用全新的 create_agent API,告别老教程里过时的代码。
目录
- LangChain是什么?
- 环境安装与配置
- 你的第一个Agent
- 理解 Agent 运行循环
- 创建自定义工具
- 中间件:控制Agent的每一步
- 进阶:动态模型与动态工具
- 完整项目:构建一个研究助手 Agent
- 调试与追踪:LangSmith
- 短期记忆:让 Agent 记住对话历史
- 长期记忆:跨会话的数据持久化
- 流式输出:实时反馈
- 结构化输出:返回结构化数据
- Deep Agents:开箱即用的高级 Agent
- 总结
1. LangChain 是什么?
大白话:LangChain 就是一个"AI 工具箱"。你想让 AI 帮你查天气、搜网页、算数学、写代码?以前每一项都要自己写一大堆代码,现在 LangChain 把轮子都造好了,你只需要像搭积木一样拼起来。10 行代码搞定以前 200 行的事。
LangChain 是一个开源框架,提供预构建的 Agent 架构和任何模型或工具的集成——让你能构建随 AI 生态演进而快速适应的 Agent。
用大白话说:LangChain 让你用不到 10 行代码就能搭出一个能调用工具、做决策、多轮对话的 AI Agent。
┌──────────────────────────────────────────────────────┐
│ LangChain Agent │
│ │
│ 用户输入 ──→ LLM(思考)──→ 工具调用 ──→ 观察结果 │
│ ↑ │ │
│ └──────────────┘ │
│ 循环直到完成任务 │
└──────────────────────────────────────────────────────┘
2026 年 LangChain 的核心变化
|
旧版 |
新版 |
|
|
|
|
多种 Agent 类型(ReAct, OpenAI Functions, ...) |
统一 |
|
独立的 Chain 和 Agent 体系 |
Agent 是核心,Chain 概念淡化 |
|
自己管理对话状态 |
内置基于 LangGraph 的状态管理 |
|
无中间件 |
完整中间件系统 |
|
多文件编辑困难 |
支持多步骤、条件分支、循环 |
2. 环境安装与配置
安装
pip install -U langchain如果你要使用特定模型提供商,安装对应扩展:
# OpenAI
pip install -U langchain langchain-openai
# Anthropic Claude
pip install -U langchain langchain-anthropic
# Google Gemini
pip install -U langchain langchain-google-genai
# Ollama(本地模型)
pip install -U langchain langchain-ollama设置 API Key
# OpenAI
export OPENAI_API_KEY="sk-xxx"
# Anthropic
export ANTHROPIC_API_KEY="sk-ant-xxx"
# Google
export GOOGLE_API_KEY="xxx"Windows 用户:
$env:OPENAI_API_KEY = "sk-xxx"
3. 你的第一个 Agent
用 create_agent 创建一个能调用工具的 AI Agent,不到 10 行代码:
大白话:create_agent 就是"帮我造个 AI 助手出来"。你指定用什么模型、配什么工具、让它干什么,它就像乐高工厂一样给你吐出一个能干活、会决策的完整 Agent。比泡面还简单,倒水(配参数)→等三秒→开吃。
from langchain.agents import create_agent
# 定义工具:一个普通的 Python 函数
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
return f"{city} 今天天气晴朗,22°C,适合出门!"
# 创建 Agent
agent = create_agent(
model="openai:gpt-5.4", # 格式:provider:model
tools=[get_weather], # 工具列表
system_prompt="你是一个乐于助人的助手",
)
# 运行 Agent
result = agent.invoke({
"messages": [
{"role": "user", "content": "旧金山今天天气怎么样?"}
]
})
# 获取最终回复
print(result["messages"][-1].content_blocks)支持的模型格式
LangChain 使用 provider:model 的统一格式来指定模型:
# OpenAI
agent = create_agent("openai:gpt-5.4", tools=[...])
# Claude
agent = create_agent("claude-sonnet-4-6", tools=[...])
# Gemini
agent = create_agent("google_genai:gemini-2.5-flash-lite", tools=[...])
# Ollama(本地)
agent = create_agent("ollama:qwen3", tools=[...])
# 也可以省略 provider,让 LangChain 自动推断
agent = create_agent("gpt-5.4", tools=[...]) # 自动识别为 openai精细控制模型参数
如果需要设置 temperature、max_tokens 等参数:
from langchain.chat_models import init_chat_model
model = init_chat_model(
"openai:gpt-5.4",
temperature=0.3, # 创造性控制(0=精确, 1=随机)
max_tokens=4096, # 最大输出长度
timeout=60, # 超时设置
)
agent = create_agent(model, tools=[...])4. 理解 Agent 运行循环
大白话:Agent 像办公室里的新员工。老板(你)说"帮我查下北京天气",新员工不会直接回答——他先翻气象系统(工具调用),查到"晴天 22°C",然后才跟你说"老板,北京晴天 22°C"。**Agent Loop 就是:听到指令→想怎么干→找帮手→看结果→再想想→交作业。**环形的,会跑好几圈才停。
Agent 的执行流程是一个循环:模型接收输入 → 决定需要什么工具 → 调用工具 → 观察结果 → 继续思考 → 输出最终答案。
┌──────────┐
用户输入 ──→│ │
│ LLM │←──────────────┐
│ (模型) │ │
└────┬─────┘ │
│ │
┌───────────┼───────────┐ │
│ │ │ │
"finish" "action" "action" │
(完成) (工具A) (工具B) │
│ │ │ │
▼ ▼ ▼ │
┌────────┐ ┌───────┐ ┌───────┐ │
│ 输出 │ │调用A │ │调用B │ │
│ 结果 │ │ │ │ │ │
└────────┘ └───┬───┘ └───┬───┘ │
│ │ │
▼ ▼ │
observation observation │
(观察结果) (观察结果) │
│ │ │
└──────────┴──────────┘
代码演示:有多个工具的 Agent
from langchain.agents import create_agent
def search_web(query: str) -> str:
"""在网络上搜索信息"""
return f"关于 '{query}' 的搜索结果:LangChain 是一个流行的 AI 框架..."
def get_time(city: str) -> str:
"""获取指定城市的当前时间"""
return f"{city} 现在是下午 3:00"
def calculate(expression: str) -> str:
"""执行数学计算"""
return f"{expression} = {eval(expression)}"
agent = create_agent(
model="gpt-5.4",
tools=[search_web, get_time, calculate],
system_prompt="你是一个全能助手,能搜索、查时间和计算",
)
# 测试复杂问题 — Agent 会自动选择合适的工具
result = agent.invoke({
"messages": [{
"role": "user",
"content": "帮我算一下 123 * 456,然后告诉我纽约现在几点"
}]
})
for msg in result["messages"]:
if msg.type == "tool":
print(f" 调用了工具: {msg.name}")
elif msg.type == "ai":
print(f" AI回复: {msg.content_blocks}")输出示例:
调用了工具: calculate
调用了工具: get_time
AI回复: 123 × 456 = 56,088。纽约现在是下午 3:00。可以看到,Agent 自动判断需要同时使用计算工具和时间查询工具来回答这个问题。
深度解析:Agent 到底怎么"跑"的?
内部机制
Agent 底层是一个状态机驱动的循环。每一次循环被称为一个"Step":
┌─────────────────────────────────────────────┐
│ Step N │
│ │
│ state.messages ──→ LLM ──→ 决定做什么 │
│ │ │
│ ┌───────────────┼───────┐ │
│ │ │ │ │
│ finish tool_A tool_B │
│ (结束) (执行A) (执行B) │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ 返回结果 结果追加到state.messages│
│ ↓ │
│ 进入 Step N+1 │
└─────────────────────────────────────────────┘核心逻辑伪代码:
def agent_loop(state, max_steps=10):
for step in range(max_steps):
# 1. 把所有消息发给 LLM
response = llm.invoke(state["messages"])
# 2. 如果 LLM 说 "完成了",返回
if response.is_final:
return response.content
# 3. LLM 要求调工具 → 执行工具
for tool_call in response.tool_calls:
result = execute_tool(tool_call)
# 4. 把工具结果追加回消息历史
state["messages"].append(tool_result_to_message(result))
# 5. 循环下一轮,LLM 看到工具结果后继续思考常见踩坑
坑 1:Agent "想太多了"——无限循环
# 症状:Agent 不断调工具→看结果→再调工具→再看→...永不停
agent.invoke({"messages": [{"role": "user", "content": "给我写个操作系统"}]})
# 等了 5 分钟还没结束...根因有 3 种:
- 任务太难——Agent 找不到答案就反复尝试
- system_prompt 没写好——没说"如果找不到就承认找不到"
- 工具返回信息不足——Agent 以为多调几次能获得更多信息
解决方案:
# 1. 设置最大步数(推荐:默认 10,复杂任务 25-50)
agent = create_agent(
model="gpt-5.4",
tools=[...],
# 控制循环深度
).with_config({"recursion_limit": 15})
# 2. system_prompt 加入 "灭火器"
agent = create_agent(
model="gpt-5.4",
tools=[...],
system_prompt="""你是助手。重要规则:
- 如果 3 次尝试后仍无法解决,直接告诉用户你做不到
- 不要反复调用同一个工具得到相同结果
- 调工具前先想清楚:这次调用能带来新信息吗?""",
)坑 2:Agent 提前放弃了
# 症状:明明还有工具能用,Agent 直接说 "我不知道"
result = agent.invoke({
"messages": [{"role": "user", "content": "帮我查一下张三和我的订单有没有冲突"}]
})
# Agent: "抱歉,我需要更多信息" ← 但它没调用 search_customer!原因:system_prompt 写得过于保守,或者 tools 的 description 不够清晰,Agent 不知道这个工具能干嘛。
解决:
# 工具描述写得详细到 "什么场景下用"
@tool
defাই customer_search(name: str) -> str:
"""搜索客户信息。
何时使用:
- 用户询问任何人的信息时(哪怕只提了名字)
- 用户说 "查一下谁谁谁"
- 需要对比两个人的数据时
何时不用:
- 用户的问题跟具体的人无关
"""坑 3:messages 结构不对导致 Agent 行为异常
# 症状:手动构造 messages 时用错了格式
agent.invoke({
"messages": [
{"role": "user", "content": "你好"}, # 不兼容
HumanMessage("你好") # 正确
]
})解决:始终使用 LangChain 的 Message 对象:
from langchain.messages import HumanMessage, AIMessage, ToolMessage
messages = [
SystemMessage("你是一个助手"),
HumanMessage("北京天气如何"),
]
# 或者让 create_agent 的 invoke 接收 dict 时自动转换
result = agent.invoke({"messages": messages})排错技巧
如何看到 Agent 每一步在做什么?
# 方法 1:打印所有中间消息
result = agent.invoke(...)
for msg in result["messages"]:
print(f"[{msg.type.upper()}]", msg.content if hasattr(msg, 'content') else msg.name)
# 方法 2:用 callback 实时监控
import logging
logging.basicConfig(level=logging.INFO)
logging.getLogger("langchain.agents").setLevel(logging.DEBUG)如何在 Agent 跑飞时优雅中断?
import signal
class TimeoutError(Exception): pass
def handler(signum, frame):
raise TimeoutError("Agent 超时了!")
signal.signal(signal.SIGALRM, handler)
signal.alarm(30) # 30 秒超时
try:
result = agent.invoke(...)
except TimeoutError:
print("Agent 跑了 30 秒还没停,已被打断")
finally:
signal.alarm(0)💡 一句话总结:Agent 循环最怕两件事——"停不下来"(设 max_iterations)和"提前不干"(工具描述写清楚)。排错第一步永远是 打印每一步的 messages。
5. 创建自定义工具
大白话:工具 = Agent 的手和脚。没有工具的 Agent 是嘴炮——啥都做不了只会说"我查不到"。给了工具它就能真的干活:查数据库、调 API、发邮件。@tool 装饰器就是贴标签:"此函数可供 AI 随时调用"。AI 看到标签就知道什么时候用、怎么用。
工具是 Agent 的"手和脚"。LangChain 提供了 @tool 装饰器来快速定义工具。
5.1 基础工具定义
from langchain.tools import tool
@tool
def search_customer(name: str) -> str:
"""根据姓名搜索客户信息。用于查询客户的联系方式、订单记录等。"""
# 真实场景中这里连接数据库
customers = {
"张三": "电话: 138xxxx, 订单: 3笔, 总消费: ¥1,200",
"李四": "电话: 139xxxx, 订单: 1笔, 总消费: ¥300",
}
return customers.get(name, f"未找到客户 '{name}'")
# 查看工具信息
print(search_customer.name) # search_customer
print(search_customer.description) # 根据姓名搜索客户信息...重要提示:
- 类型注解必须写(
name: str),这是工具输入 schema 的基础
- docstring 决定了工具的 description,模型根据它判断何时使用工具
- 工具名用 snake_case(如
web_search而非Web Search),避免兼容性问题
5.2 自定义工具名和描述
@tool("customer_search") # 自定义名称
def search(name: str) -> str:
"""根据姓名搜索客户信息"""
return f"搜索结果: {name}"
@tool(
"calculator",
description="执行数学计算。当用户问加减乘除等数学问题时使用此工具。"
)
def calc(expression: str) -> str:
"""计算数学表达式"""
return str(eval(expression))5.3 使用 Pydantic 定义复杂参数
当工具参数较复杂时,可以用 Pydantic 模型:
from pydantic import BaseModel, Field
from typing import Literal
class WeatherInput(BaseModel):
"""天气查询参数"""
location: str = Field(description="城市名称,如 '北京'、'上海'")
units: Literal["celsius", "fahrenheit"] = Field(
default="celsius",
description="温度单位"
)
include_forecast: bool = Field(
default=False,
description="是否包含未来5天预报"
)
@tool(args_schema=WeatherInput)
def get_weather(
location: str,
units: str = "celsius",
include_forecast: bool = False
) -> str:
"""获取指定城市的天气信息"""
temp = 22 if units == "celsius" else 72
unit_str = "°C" if units == "celsius" else "°F"
result = f"{location} 当前温度: {temp}{unit_str},晴天"
if include_forecast:
result += "\n未来5天: 均为晴天,温度稳定"
return result
5.4 在工具中访问运行时信息
工具可以通过 ToolRuntime 获取对话状态、上下文、长期记忆:
大白话:ToolRuntime 是工具干活时背的随身背包。工具执行任务时,能从背包里掏出:当前对话记录(短记忆)、用户长期档案(长记忆)、甚至调用者身份。工具不瞎,它知道在帮谁、在什么上下文中干活。
from langchain.tools import tool, ToolRuntime
from langchain.messages import HumanMessage
@tool
def remember_my_preference(
pref_name: str,
runtime: ToolRuntime
) -> str:
"""保存用户的偏好设置"""
# 读取当前状态
state = runtime.state
# 获取用户最后一条消息
last_user_msg = None
for msg in reversed(state["messages"]):
if isinstance(msg, HumanMessage):
last_user_msg = msg.content
break
# 保存偏好
state["user_preferences"] = state.get("user_preferences", {})
state["user_preferences"][pref_name] = last_user_msg
return f"已记住你的偏好: {pref_name}"注意: runtime 参数会被自动注入,模型看不到这个参数 — 它不会出现在工具 schema 中。
深度解析:工具系统的"坑"都在哪?
工具是怎么被 AI "选中"的?
LLM 不"理解"你的代码,它只看3 样东西:
- 工具名(name)→ 告诉 LLM "我能干嘛"
- 工具描述(description/docstring)→ 告诉 LLM "什么时候用我"
- 参数 schema(类型注解+Pydantic)→ 告诉 LLM "用我需要传什么"
@tool
def get_stock_price(symbol: str, exchange: str = "NASDAQ") -> str:
"""获取实时股票价格。如果用户问 "XX股票多少钱" 或 "帮我查XX股价" 时使用。"""
# ↑ 这段 docstring 决定了 AI 什么时候选它
# ↑ symbol: str 决定了 AI 必须传股票代码
# ↑ exchange: str = "NASDAQ" 是可选参数,AI 可以不传常见踩坑
坑 1:docstring 写得太模糊——AI 选错工具
docstring: "搜索信息" ← AI 不知道什么场景用
docstring: "搜索客户在CRM系统中的订单和联系方式。当用户提到具体客户名字或要查某人信息时使用。"坑 2:两个工具 description 撞车——AI 犹豫不决
@tool
def search_customer(name: str):
"""搜索客户信息""" # ← 太像了
pass
@tool
def lookup_customer(name: str):
"""查找客户资料""" # ← AI 分不清该选哪个
pass解决:把区别写进 docstring。
坑 3:类型注解忘了写——参数变成 any
@tool
def save(name, email): # 没写类型 → AI 传什么都行
pass
@tool
def save(name: str, email: str): # AI 知道必须传字符串
pass坑 4:工具调用失败后 Agent 不知道怎么办
# 症状:工具抛异常 → Agent 对话直接炸了
@tool
def search(city: str) -> str:
"""查天气"""
import requests
resp = requests.get(f"https://api.com?city={city}")
return resp.json()["weather"]
# 如果 API 挂了,整个 Agent 都报错解决:
@tool
def search(city: str) -> str:
"""查天气"""
try:
resp = requests.get(f"https://api.com?city={city}", timeout=5)
resp.raise_for_status()
return resp.json()["weather"]
except requests.Timeout:
return f" 天气API超时,建议稍后重试。{city}通常是晴天。"
except Exception as e:
return f" 天气查询失败: {str(e)}。建议用户稍后重试或换一个城市。"
# 优雅降级——工具挂了也不影响 Agent 继续对话进阶技巧
技巧 1:工具返回结构化信息
@tool
defsearch products(query: str) -> str:
"""搜索产品。返回格式化的产品列表。"""
products = [
{"name": "笔记本", "price": 5999, "stock": 150},
{"name": "键鼠套装", "price": 299, "stock": 200},
]
# 用清晰格式返回,方便 LLM 理解和总结
lines = [f"🔍 '{query}' 搜索结果 ({len(products)}个):"]
for i, p in enumerate(products, 1):
lines.append(f"{i}. {p['name']} — ¥{p['price']} — 库存:{p['stock']}")
return "
".join(lines)技巧 2:async 工具——别让一个慢工具拖慢整个 Agent
import asyncio
async def fetch_price_async(symbol: str):
await asyncio.sleep(2) # 模拟慢速 API
return f"{symbol}: $123.45"
@tool
async defstock price(symbol: str) -> str:
"""获取实时股票价格(async)"""
return await fetch_price_async(symbol)
agent = create_agent(model="gpt-5.4", tools=[stock_price])
result = await agent.ainvoke({...}) # 注意用 ainvoke技巧 3:给工具分组——管理大量工具
项目中可能有几十个工具,全塞给 Agent 会选错。
# 用 Cantian middleware ——根据场景动态过滤
from langchain.agents.middleware import ToolFilterMiddleware
# 只给客服 Agent 暴露客服相关工具
agent = create_agent(
model="gpt-5.4",
tools=[search_order, create_return, check_inventory, ..., release],
middleware=[
ToolFilterMiddleware(
allowed=["search_order", "create_return", "check_inventory"]
)
]
)💡 一句话总结:工具不是代码写对了就行——docstring 写得好不好,直接决定 AI 会不会用它、用对没有。花 30% 时间写代码,花 70% 时间打磨 docstring。
6. 中间件:控制 Agent 的每一步
大白话:中间件 = Agent 流水线上的保安+质检员。Agent 每次要调模型或执行工具,都先被中间件检查一遍:调模型前记日志(监控),删数据前查权限(安全),对话太长就帮你摘要(性能)。就像机场安检——不是不让过,是确保按规矩过,顺便帮你省点钱。
中间件(Middleware)是 LangChain v1.0 的核心创新之一,它在 Agent 运行循环的每个步骤前后插入自定义逻辑。
│ Middleware Hooks │
┌──────────┐ ┌┴──────────────────┐┴┐ ┌──────────┐
│ 用户输入 │ ────→ │ before_model 等 │ ────→ │ LLM │
└──────────┘ └┬──────────────────┬┘ └──────────┘
│ │ │
│ before_tool │ │
│ after_tool │ ┌───────┴───────┐
│ │ │ 工具调用 │
└──────────────────┘ └───────────────┘
6.1 使用内置中间件
from langchain.agents import create_agent
from langchain.agents.middleware import (
SummarizationMiddleware,
HumanInTheLoopMiddleware,
)
agent = create_agent(
model="gpt-5.4",
tools=[...],
middleware=[
# 对话太长时自动摘要,防止上下文溢出
SummarizationMiddleware(
model="gpt-5.4-mini", # 用便宜模型做摘要
max_tokens_before_summarize=4000,
),
# 在关键操作前暂停,等待人工批准
HumanInTheLoopMiddleware(
interrupt_on_tool_names=["delete_database", "send_email"]
),
],
)6.2 编写自定义中间件
大白话:@wrap_model_call 就是在 LLM 调用外面包了一层保鲜膜。每次模型要生成回复时先穿过你这层膜——你可以在里面打日志、换模型、改提示词、甚至直接拦掉。相当于在 Agent 大脑外面装了监控 + 遥控器。
用 @wrap_model_call 装饰器在模型调用前后插入逻辑:
from langchain.agents.middleware import (
wrap_model_call,
ModelRequest,
ModelResponse,
)
from typing import Callable
@wrap_model_call
def log_and_limit_retries(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""记录每次模型调用,并限制重试次数"""
retry_count = request.state.get("retry_count", 0)
if retry_count >= 3:
# 超过 3 次重试,强制返回失败
return ModelResponse(
result="抱歉,我尝试多次后无法完成这个任务,请简化你的需求。"
)
print(f" [LOG] 第 {retry_count + 1} 次调用模型")
print(f" [LOG] 可用工具: {[t.name for t in request.tools]}")
print(f" [LOG] 消息数: {len(request.state['messages'])}")
# 更新重试计数
request.state["retry_count"] = retry_count + 1
# 调用模型(handler 是 LangChain 内部的模型调用函数)
response = handler(request)
print(f" [LOG] 模型返回,使用了 {len(response.tool_calls)} 个工具调用")
return response
agent = create_agent(
model="gpt-5.4",
tools=[...],
middleware=[log_and_limit_retries],
)深度解析:中间件的"黑暗面"
内部机制
中间件的 5 个生命周期 hook:
Agent 一次循环中中间件的触发点:
│
before_model (发给LLM前) ←→ 改 system prompt / messages
│ │
▼ │
LLM │
│ │
after_model (LLM返回后) ←→ 检查/修改 LLM 输出
│ │
▼ │
before_tool (执行工具前) ←→ AO: 命令前检查
│ │
▼ │
Tool │
│ │
after_tool (工具执行后) ←→ 记录结果 / 改写输出
│ │
▼ │
wrap_model_call (包整个调用)关键规则:多个中间件按定义顺序执行,每个 hook 是一个洋葱层:
请求进去:M1.before → M2.before → M3.before → LLM
结果出来:M3.after → M2.after → M1.after常见踩坑
坑 1:中间件修改 state 造成其他中间件行为异常
# 中间件 A 改了 messages,中间件 B 依赖原来的 messages,行为就乱了
@before_model
def add_context(state, runtime):
state["messages"].append(SystemMessage("追加上下文"))
# 这个修改会影响后续所有中间件 + LLM 输入!解决:中间件不要直接改传入的对象,返回新对象:
@before_model
def add_context(state, runtime):
new_messages = [SystemMessage("追加上下文")] + list(state["messages"])
return {"messages": new_messages} # 返回新的,不改旧的坑 2:中间件抛异常 → 整个 Agent 挂了
# 这个中间件在某些 state 下直接炸了
@after_model
def validate_output(state, runtime):
last_msg = state["messages"][-1]
if "删除" in last_msg.content:
raise RuntimeError("检测到危险操作!")
# 异常直接中断 Agent,用户看到的是 traceback解决:捕获异常并优雅处理:
@after_model
def validate_output(state, runtime):
try:
last_msg = state["messages"][-1]
if "删除" in str(last_msg.content):
# 不抛异常,而是修改消息内容
return {"messages": [
AIMessage(" 检测到潜在危险操作,已阻止。请尝试其他方式。")
]}
except Exception as e:
runtime.logger.warning(f"validate_output 跳过: {e}")
return None # 返回 None = 不干预,让 Agent 正常继续坑 3:中间件可能成为性能杀手
# 每次 LLM 调用前都做一次全量 state 拷贝
@before_model
def expensive_logging(state, runtime):
log_data = json.dumps(state, default=str) # 可能几 MB!
send_to_logging_service(log_data) # 网络 IO
# 每个 Step 都卡一秒 → Agent 跑 10 步就慢 10 秒解决:
@before_model
def smart_logging(state, runtime):
# 只记摘要,不记全量
msg_count = len(state["messages"])
runtime.logger.info(f"[Agent Step] messages={msg_count}")
return None # 不修改 state,直接放行排错技巧
怎么知道是哪个中间件搞出了问题?
# 给每个中间件加标识
def traced(name):
def decorator(fn):
def wrapper(state, runtime):
print(f"[MW:{name}] 进入 → state.messages={len(state['messages'])}条")
result = fn(state, runtime)
print(f"[MW:{name}] 退出 → 返回 {type(result).__name__}")
return result
return wrapper
return decorator
@traced("权限检查")
@before_model
def auth_middleware(state, runtime):
# 你的逻辑
pass进阶技巧
模式:条件中间件——有的场景跳过
@before_model
def conditional_security(state, runtime):
context = getattr(runtime, 'context', {})
user_role = getattr(context, 'role', 'user')
if user_role == 'admin':
return None # 管理员不用检查,加快速度
# 非管理做安全扫描
for msg in state["messages"]:
if "DROP TABLE" in str(msg.content):
return {"messages": [AIMessage(" SQL注入嫌疑已阻止")]}
return None模式:中间件链——日志链 + 安全链 + 摘要链
agent = create_agent(
model="gpt-5.4",
tools=[...],
middleware=[
LoggingMiddleware(), # 最外层:记录
RateLimitMiddleware(), # 第2层:限频
SummarizationMiddleware(model="gpt-mini"), # 第3层:摘要
SecurityMiddleware(), # 最内层:审查 LLM 输出
# 洋葱顺序:Log → Rate → Summarize → Secure → LLM
]
)💡 一句话总结:中间件最怕两件事——直接改 state(返回新对象!)和抛异常中断 Agent(捕获+优雅降级!)。排错时给每个中间件加 trace 日志,一眼就知道谁在捣乱。
7. 进阶:动态模型与动态工具
7.1 动态模型选择
大白话:看菜下饭,看任务选模型。用户说"今天星期几"→ mini 模型就够了;用户说"帮我分析这份财报"→ 自动切旗舰模型。既省钱又不出错——吃多少拿多少,不浪费。
根据对话复杂度自动切换模型——简单问题用便宜模型,复杂问题用旗舰模型:
from langchain.agents.middleware import wrap_model_call
from langchain.chat_models import init_chat_model
# 准备两个模型
cheap_model = init_chat_model("gpt-5.4-mini", temperature=0.3)
powerful_model = init_chat_model("gpt-5.4", temperature=0.3)
@wrap_model_call
def smart_model_router(request, handler):
"""根据对话复杂度智能选择模型"""
message_count = len(request.state["messages"])
has_tool_calls = any(
msg.type == "tool" for msg in request.state["messages"]
)
# 判断规则
if message_count > 15 or has_tool_calls:
print("检测到复杂任务,切换到 gpt-5.4")
model = powerful_model
else:
print("简单任务,使用 gpt-5.4-mini")
model = cheap_model
return handler(request.override(model=model))
agent = create_agent(
model=cheap_model, # 默认用便宜的
tools=[...],
middleware=[smart_model_router],
)7.2 动态工具过滤
大白话:不同级别不同待遇,跟公司门禁卡一样。管理员进来→所有工具随便用;普通编辑→删除按钮灰掉不能用;游客→只让看不让改。同一个问题"帮我把数据库清了",管理员能执行,编辑会被拦下——你的权限决定了你手里的钥匙能开哪些门。
根据用户权限或对话阶段决定暴露哪些工具:
from dataclasses import dataclass
@dataclass
class UserContext:
"""运行时上下文"""
user_role: str # "admin" | "editor" | "viewer"
user_id: str
@wrap_model_call
def permission_based_tools(request, handler):
"""根据用户权限过滤可用工具"""
ctx = request.runtime.context
user_role = ctx.user_role if ctx else "viewer"
if user_role == "admin":
pass # 管理员拥有全部工具
elif user_role == "editor":
# 编辑者不能删除
request = request.override(
tools=[t for t in request.tools if t.name != "delete_data"]
)
else:
# 普通用户只能用只读工具
request = request.override(
tools=[t for t in request.tools if t.name.startswith("read_")]
)
return handler(request)
agent = create_agent(
model="gpt-5.4",
tools=[read_data, write_data, delete_data, search_public],
middleware=[permission_based_tools],
context_schema=UserContext,
)
# 调用时指定用户身份
result = agent.invoke(
{
"messages": [{"role": "user", "content": "帮我删除所有用户数据"}]
},
context=UserContext(user_role="editor", user_id="editor_001")
)
# editor 角色下,delete_data 工具不可用,Agent 无法执行删除操作
8. 完整项目:构建一个研究助手 Agent
现在我们把上面学的全部用上,写一个真正的研究助手 Agent,如下。
8.1 功能需求
- 用户给出一个 URL 或关键词
- Agent 自动获取文章内容
- Agent 分析文章,给出摘要、关键信息、观点
- 支持追问和深入探讨
8.2 完整代码
# research_agent.py
import urllib.request
import urllib.error
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import (
wrap_model_call,
SummarizationMiddleware,
ModelRequest,
ModelResponse,
)
from langchain.chat_models import init_chat_model
from langchain.tools import tool, ToolRuntime
from typing import Callable
# ─── 工具定义 ───
@tool
def fetch_webpage_content(url: str) -> str:
"""从 URL 获取网页内容。用于阅读在线文章、博客、文档等。
Args:
url: 要获取的网页 URL
"""
try:
req = urllib.request.Request(
url,
headers={
"User-Agent": (
"Mozilla/5.0 (compatible; ResearchAgent/1.0)"
)
},
)
with urllib.request.urlopen(req, timeout=30) as resp:
raw = resp.read()
text = raw.decode("utf-8", errors="replace")
# 截断过长内容(大模型有上下文限制)
return text[:8000] if len(text) > 8000 else text
except urllib.error.URLError as e:
return f"获取页面失败: {e}"
except Exception as e:
return f"发生未知错误: {e}"
@tool
defalen analyse_statistics(
numbers: str,
runtime: ToolRuntime
) -> str:
"""分析文本中提到的数字数据,给出统计摘要。
Args:
numbers: 需要分析的逗号分隔的数字列表,如 "100,200,300"
"""
try:
vals = [float(n.strip()) for n in numbers.split(",")]
except ValueError:
return "输入格式错误,请使用逗号分隔的数字"
if not vals:
return "没有可分析的数据"
avg = sum(vals) / len(vals)
maximum = max(vals)
minimum = min(vals)
return (
f" 数据分析结果:\n"
f" - 数据量: {len(vals)} 条\n"
f" - 平均值: {avg:.2f}\n"
f" - 最大值: {maximum:.2f}\n"
f" - 最小值: {minimum:.2f}\n"
)
# ─── 中间件 ───
@wrap_model_call
defimal analysis_logger(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""记录每次分析步骤,用于调试和追踪"""
step = request.state.get("analysis_step", 0)
request.state["analysis_step"] = step + 1
print(f"\n{'='*50}")
print(f"分析步骤 #{step + 1}")
print(f"上下文消息数: {len(request.state['messages'])}")
print(f"可用工具: {[t.name for t in request.tools]}")
print(f"{'='*50}")
response = handler(request)
return response
# ─── 系统提示词 ───
SYSTEM_PROMPT = """你是一个专业的研究助手。你的能力包括:
1. 获取和分析网页内容
2. 提取关键信息和主要观点
3. 回答关于文档内容的具体问题
4. 分析文本中提到的数字数据
工作流程:
- 当用户提供 URL 时,先获取内容,再分析
- 分析时标注信息来源
- 如果用户提供数字数据,使用统计工具进行分析
- 回答要准确、简洁、结构化
格式规范:
- 使用标题分层
- 重要信息用要点列表
- 有数据结论时给出置信度说明
"""
# ─── 组装 Agent ───
model = init_chat_model(
"openai:gpt-5.4",
temperature=0.2, # 低温度,确保分析严谨
max_tokens=4096,
)
agent = create_agent(
model=model,
tools=[fetch_webpage_content, analyse_statistics],
system_prompt=SYSTEM_PROMPT,
middleware=[
SummarizationMiddleware(
model=init_chat_model("gpt-5.4-mini"),
max_tokens_before_summarize=6000,
),
analysis_logger,
],
)
# ─── 运行入口 ───
if __name__ == "__main__":
print("LangChain 研究助手已就绪\n")
# 示例 1:分析一篇博客文章
result = agent.invoke({
"messages": [{
"role": "user",
"content": (
"帮我分析这篇文章:"
"https://example.com/ai-trends-2026\n"
"请给出摘要、关键发现和你的评价。"
)
}]
})
print("\n 分析结果:")
print(result["messages"][-1].content_blocks)
# 示例 2:追问
result = agent.invoke({
"messages": [
*result["messages"], # 带上之前的对话历史
{"role": "user", "content": "文章里提到的技术中,哪一个最值得关注?为什么?"}
]
})
print("\n 追问结果:")
print(result["messages"][-1].content_blocks)8.3 项目结构
research_agent/
├── research_agent.py ← 主程序
├── tools.py ← (可选) 工具独立文件
├── middleware.py ← (可选) 中间件独立文件
└── README.md
9. 调试与追踪:LangSmith
在生产环境中,Agent 的行为常常难以追踪。LangChain 官方提供了 LangSmith 平台来可视化 Agent 的执行过程。
# 安装
pip install -U langsmith
# 启用追踪
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY="ls_xxx"
export LANGSMITH_PROJECT="my-research-agent"设置后,每次 agent.invoke() 都会自动发送到 LangSmith 仪表盘:
┌──────────────────────────────────────────────────┐
│ LangSmith Trace View │
│ │
│ [用户输入] ──→ [LLM Call #1] ──→ [Tool: fetch] │
│ │ │
│ ▼ │
│ [LLM Call #2] │
│ │ │
│ ▼ │
│ [最终输出] │
│ │
│ 每个节点可展开查看: │
│ - 输入/输出内容 │
│ - 耗时统计 │
│ - Token 用量 │
│ - 错误信息 │
└──────────────────────────────────────────────────┘# 常见调试命令
# 查看追踪
langsmith trace list --project my-research-agent
# 导出追踪
langsmith trace export --run-id xxx > trace.json
10. 短期记忆:让 Agent 记住对话历史
大白话:短期记忆 = Agent 的便签纸。你跟它聊天,它把内容记在便签纸上贴在面前。换了新页(新 thread),之前的就翻篇了。checkpointer 就是那个图钉——把便签钉在桌上,你暂时走开回来便签还在。普通 Agent 是金鱼(7秒记忆),加了 checkpointer 才有真正的聊天能力。
短期记忆(Short-term Memory)让 Agent 记住当前会话中的上下文,包括之前的对话、工具调用结果等。
10.1 为什么需要记忆?
没有记忆的 Agent 就像一个金鱼:
用户: 我叫张三
Agent: 你好张三!
用户: 我叫什么?
Agent: 抱歉,我不知道你是谁... # 因为没有记住10.2 添加 Checkpointer
通过 checkpointer 参数启用记忆:
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver # 内存存储
agent = create_agent(
model="gpt-5.4",
tools=[...],
checkpointer=InMemorySaver(), # 启用短期记忆
)
# 运行时需要指定 thread_id
result = agent.invoke(
{"messages": [{"role": "user", "content": "我叫张三"}]},
{"configurable": {"thread_id": "conversation_001"}} # 会话 ID
)
# 继续同一会话
result = agent.invoke(
{"messages": [{"role": "user", "content": "我叫什么?"}]},
{"configurable": {"thread_id": "conversation_001"}} # 同一个 ID
)
# Agent 会回答: "你叫张三"10.3 生产环境使用数据库
内存存储重启后数据丢失,生产环境用 PostgreSQL:
pip install langgraph-checkpoint-postgresfrom langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://user:pass@localhost:5432/db"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 自动创建表
agent = create_agent(
"gpt-5.4",
tools=[...],
checkpointer=checkpointer,
)10.4 自定义 State 扩展记忆
添加自定义字段存储额外信息:
from langchain.agents import create_agent, AgentState
class MyState(AgentState):
user_id: str
preferences: dict
visit_count: int
agent = create_agent(
"gpt-5.4",
tools=[...],
state_schema=MyState,
checkpointer=InMemorySaver(),
)
result = agent.invoke(
{
"messages": [{"role": "user", "content": "你好"}],
"user_id": "user_123",
"preferences": {"theme": "dark"},
"visit_count": 5
},
{"configurable": {"thread_id": "1"}}
)10.5 管理长对话:修剪消息
对话太长会超过上下文窗口,需要修剪:
from langchain.agents.middleware import before_model
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
@before_model
def trim_messages(state, runtime):
"""只保留最近 3 轮对话"""
messages = state["messages"]
if len(messages) <= 3:
return None # 不需要修剪
# 保留系统消息 + 最近消息
first_msg = messages[0] # 通常是 system prompt
recent = messages[-3:]
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES), # 删除所有
first_msg,
*recent
]
}
agent = create_agent(
"gpt-5.4",
tools=[...],
middleware=[trim_messages],
checkpointer=InMemorySaver(),
)
深度解析:Agent 的记忆到底怎么工作
内部机制
Checkpointer 内部做三件事:
- 序列化 state:把 Python 对象(messages、tool results)转成字节
- 写入存储:以
(thread_id, checkpoint_id)为 key 存起来 - 版本链:每次新 checkpoint 链接到上一个,形成"历史版本链"
Thread "conv_001":
Step 0: checkpoint_0 (用户: "我叫张三")
│
Step 1: checkpoint_1 (Agent: "你好张三!" + 工具调用结果)
│
Step 2: checkpoint_2 (用户: "帮我查天气" → Agent思考...)
任何时候可以从任意 checkpoint_恢复!常见踩坑
坑 1:换了个 thread_id,之前的记忆全丢了
# 同一用户每次生成新 ID
result1 = agent.invoke(
{"messages": [{"role": "user", "content": "我叫张三"}]},
{"configurable": {"thread_id": str(uuid.uuid4())}} # 每次随机
)
result2 = agent.invoke(
{"messages": [{"role": "user", "content": "我叫什么?"}]},
{"configurable": {"thread_id": str(uuid.uuid4())}} # 又生成新 ID
)
# Agent: "我不知道你是谁" ← 因为 thread_id 变了正确做法:用户会话用固定 thread_id:
# 用户会话 → 固定 thread_id
USER_THREAD = "user_lyp_session_1"
result1 = agent.invoke(
{"messages": [{"role": "user", "content": "我叫张三"}]},
{"configurable": {"thread_id": USER_THREAD}}
)
result2 = agent.invoke(
{"messages": [{"role": "user", "content": "我叫什么?"}]},
{"configurable": {"thread_id": USER_THREAD}} # 同一个 ID
)
# Agent: "你叫张三" 坑 2:消息膨胀——上下文悄悄爆了
# 症状:聊了 50 轮后 Agent 突然报错 "context length exceeded"
# 原因:每轮对话都把 messages 追加到 state,messages 列表越来越长
# 50 轮后可能有 100+ 条消息,几十万 token!
# 解决:定期修剪
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="gpt-5.4",
tools=[...],
checkpointer=InMemorySaver(),
middleware=[
SummarizationMiddleware(
model="openai:gpt-5.4-mini",
trigger=("tokens", 4000), # 超过 4000 token 触发
keep=("messages", 6), # 保留最近 6 条消息
)
]
)坑 3:InMemorySaver 重启就全丢
# 开发时好用,但部署后发现每次重启用户记忆全没了
agent = create_agent(
model="gpt-5.4",
checkpointer=InMemorySaver(), # 重启即丢!
)→ 生产环境用 PostgresSaver,数据持久化。
排错技巧
"我的 Agent 记忆丢了"——逐层排查
1. 检查 thread_id 是不是变了 → thread_id 用程序打印出来确认
2. 检查 checkpointer 是否还在 → 重启了 → InMemorySaver 丢了
3. 检查 state 是否被中间件清空 → 中间件可能 RemoveMessage 把所有历史删了
4. 检查是否用了不同的 agent 实例 → 不同实例 = 不同 checkpointer诊断代码:
# 检查某个 thread 的记忆还在不在
test_result = agent.invoke(
{"messages": [{"role": "user", "content": "ping"}]},
{"configurable": {"thread_id": "USER_123"}}
)
msg_count = len(test_result.get("messages", []))
print(f"Thread USER_123 有 {msg_count} 条消息")
# 如果只有 2-3 条(system + user + AI),说明之前记忆丢了💡 一句话总结:记忆丢了的排查顺序:thread_id 变了?→ InMemorySaver 重启了?→ 中间件把消息删了?→ agent 实例不对? 90% 的情况是前两个原因。
11. 长期记忆:跨会话的数据持久化
大白话:长期记忆 = Agent 的档案柜。第一次说"我喜欢咖啡"→ 写入档案塞进柜子。一个月后回来 → 翻柜子找到这条记录。便签纸(短期)可能丢,档案柜(长期/Store)永久保存。一个会话里用的 vs 跨会话记住的。
长期记忆(Long-term Memory)让 Agent 记住跨会话的信息,比如用户偏好、历史记录等。
11.1 Store 系统
长期记忆基于 LangGraph Store,以 JSON 文档形式存储:
Store 结构:
├── Namespace(命名空间,类似文件夹)
│ └── Key(键,类似文件名)
│ └── Value(JSON 数据)11.2 配置 Store
from langchain.agents import create_agent
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
agent = create_agent(
model="gpt-5.4",
tools=[...],
store=store, # 启用长期记忆
)11.3 在工具中读写记忆
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
@tool
def remember_user_preference(
key: str,
value: str,
runtime: ToolRuntime[Context]
) -> str:
"""记住用户的偏好设置"""
user_id = runtime.context.user_id
# 写入 Store
runtime.store.put(
("users",), # namespace
user_id, # key
{"preferences": {key: value}} # value
)
return f"已记住:{key} = {value}"
@tool
def get_user_preference(
key: str,
runtime: ToolRuntime[Context]
) -> str:
"""获取用户的偏好设置"""
user_id = runtime.context.user_id
# 从 Store 读取
item = runtime.store.get(("users",), user_id)
if item:
prefs = item.value.get("preferences", {})
return prefs.get(key, "未设置")
return "未找到用户信息"
agent = create_agent(
model="gpt-5.4",
tools=[remember_user_preference, get_user_preference],
store=InMemoryStore(),
context_schema=Context,
)
# 第一次会话:记住偏好
agent.invoke(
{"messages": [{"role": "user", "content": "我喜欢深色主题"}]},
context=Context(user_id="user_123")
)
# 第二次会话(重启后):读取偏好
agent.invoke(
{"messages": [{"role": "user", "content": "我上次选的什么主题?"}]},
context=Context(user_id="user_123")
)
# Agent 会回答: "你喜欢深色主题"11.4 语义搜索记忆
Store 支持向量搜索,可以语义检索相关记忆:
from langgraph.store.base import IndexConfig
from langchain.embeddings import OpenAIEmbeddings
# 配置向量索引
store = InMemoryStore(
index=IndexConfig(
embed=OpenAIEmbeddings(),
dims=1536
)
)
# 搜索相关记忆
results = store.search(
("users",),
query="用户的颜色偏好",
filter={"user_id": "user_123"}
)深度解析:长期记忆让你"跨天找回用户信息"
内部机制
Store 的增删改查+搜索全貌:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
# ── CRUD 四件套 ──
# Create / Update
store.put(("users", "preferences"), "user_123", {
"theme": "dark",
"language": "zh-CN",
"last_active": "2026-04-26"
})
# Read
item = store.get(("users", "preferences"), "user_123")
print(item.value["theme"]) # "dark"
# List all keys in a namespace
items = store.list(("users", "preferences"))
for i in items:
print(i.key, i.value)
# Delete
store.delete(("users", "preferences"), "user_123")
# ── Semantic Search ──
# 配置向量索引后可以语义搜索
from langgraph.store.base import IndexConfig
from langchain.embeddings import init_embeddings
embeddings = init_embeddings("openai:text-embedding-3-small")
store = InMemoryStore(
index=IndexConfig(embed=embeddings, dims=1536)
)
# 搜索与"主题偏好"语义相关的记忆
results = store.search(
("users", "preferences"),
query="用户的UI偏好设置",
limit=5 # 返回 top 5 最相关
)常见踩坑
坑 1:namespace 没设计好 → 数据找不到
# 一开始随意写 namespace,后面想查查不到
store.put(("random_stuff",), "prefs", {...}) # 只有一个层级
store.put(("random_stuff_123",), "prefs", {...}) # 命名乱
# 用 (域, 类型) 两级命名
store.put(("users", "preferences"), "user_123", {...}) # 用户偏好
store.put(("users", "history"), "user_123", {...}) # 用户历史
store.put(("global", "configs"), "rate_limit", {...}) # 全局配置坑 2:Store 没配 index → 只能精确查,不能模糊搜索
# 没 index → 只能 get(key) 精确查找
# 用户说 "我之前的设置还在吗" → Agent 没法语义搜索找到相关记忆
# 配 index
store = InMemoryStore(
index=IndexConfig(
embed=init_embeddings("openai:text-embedding-3-small"),
dims=1536
)
)💡 一句话总结:长期记忆的关键是两个设计——namespace 层级清晰(方便 CRUD)和配 index(支持语义搜索)。别在 namespace 上省事,将来要找数据时你会后悔。
12. 流式输出:实时反馈
大白话:流式输出 = 边炒边上菜,不是等满汉全席做好了才一起端。非流式:等 10 秒一口气看到一大段。流式:一个字一个字蹦出来,像跟朋友聊天。打字机效果——让人觉得 AI "正在思考中",体验好太多。
流式输出(Streaming)让 Agent 的响应像打字机一样实时显示,而不是等全部生成完再显示。
12.1 为什么需要流式输出?
非流式:用户提问 → 等待 10 秒 → 一次性显示完整回答
流式: 用户提问 → 立即看到 "我" → "我认" → "我认为" → ...流式输出显著提升用户体验,特别是在 LLM 响应较慢时。
12.2 三种流式模式
|
模式 |
说明 |
用途 |
|
|
每个步骤完成后发送更新 |
显示 Agent 思考过程 |
|
|
流式发送 LLM Token |
打字机效果 |
|
|
自定义数据流 |
显示进度信息 |
12.3 流式 Agent 进度
from langchain.agents import create_agent
def get_weather(city: str) -> str:
return f"{city} 天气晴朗"
agent = create_agent(
model="gpt-5.4",
tools=[get_weather],
)
# 流式获取每个步骤的更新
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "北京天气怎么样?"}]},
stream_mode="updates",
version="v2"
):
if chunk["type"] == "updates":
for step, data in chunk["data"].items():
print(f"步骤: {step}")
print(f"内容: {data['messages'][-1].content_blocks}")
print("---")输出示例:
12.4 示例
步骤: model
内容: [{'type': 'tool_call', 'name': 'get_weather', 'args': {'city': '北京'}}]
步骤: tools
内容: [{'type': 'text', 'text': '北京 天气晴朗'}]
步骤: model
内容: [{'type': 'text', 'text': '北京今天天气晴朗!'}]
### 12.4 流式 LLM Token
```python
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "讲个笑话"}]},
stream_mode="messages",
version="v2"
):
if chunk["type"] == "messages":
token, metadata = chunk["data"]
# 实时打印每个 token
print(token.content_blocks[0]["text"], end="", flush=True)12.5 自定义流式数据
在工具中发送自定义进度信息:
from langgraph.config import get_stream_writer
@tool
def fetch_large_data(query: str) -> str:
"""获取大量数据,发送进度更新"""
writer = get_stream_writer()
writer(f"开始搜索: {query}")
# 模拟长时间操作
writer("已获取 10/100 条记录...")
writer("已获取 50/100 条记录...")
writer("已获取 100/100 条记录,完成!")
return "搜索完成,共找到 100 条结果"
agent = create_agent("gpt-5.4", tools=[fetch_large_data])
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "搜索 AI 新闻"}]},
stream_mode="custom",
version="v2"
):
if chunk["type"] == "custom":
print(f"进度: {chunk['data']}")12.6 组合多种流式模式
for chunk in agent.stream(
{"messages": [...]},
stream_mode=["updates", "custom"], # 同时获取两种流
version="v2"
):
print(f"类型: {chunk['type']}, 数据: {chunk['data']}")
13. 结构化输出:返回结构化数据
大白话:不加结构化 → AI 说"张三,电话是 138xxxx,邮箱 zhang@xx.com"→ 你得自己再爬一遍文字。加结构化 → AI 直接返回 {name:"张三", phone:"138xxxx", email:"zhang@xx.com"}。你的代码拿到就能直接用,不用再做"阅读理解题"。JSON 永远比长文本好处理。
结构化输出(Structured Output)让 Agent 返回 JSON、Pydantic 模型等结构化数据,而不是纯文本。
13.1 使用场景
- 提取联系人信息(姓名、电话、邮箱)
- 生成结构化报告(标题、摘要、要点)
- 解析用户意图(意图类型、参数)
13.2 Pydantic 模型方式
from pydantic import BaseModel, Field
from langchain.agents import create_agent
class ContactInfo(BaseModel):
"""联系人信息"""
name: str = Field(description="姓名")
email: str = Field(description="邮箱地址")
phone: str = Field(description="电话号码")
agent = create_agent(
model="gpt-5.4",
response_format=ContactInfo # 指定输出格式
)
result = agent.invoke({
"messages": [{
"role": "user",
"content": "从以下文本提取联系人信息:张三,电话 138-0000-0000,邮箱 zhangsan@example.com"
}]
})
# 获取结构化输出
contact = result["structured_response"]
print(contact.name) # "张三"
print(contact.email) # "zhangsan@example.com"
print(contact.phone) # "138-0000-0000"13.3 TypedDict 方式
from typing_extensions import TypedDict
class ProductReview(TypedDict):
"""产品评论分析"""
sentiment: str # 情感:positive/negative/neutral
rating: int # 评分 1-5
keywords: list[str] # 关键词
agent = create_agent(
model="gpt-5.4",
response_format=ProductReview
)
result = agent.invoke({
"messages": [{
"role": "user",
"content": "分析这条评论:'这个手机电池续航很棒,但价格有点贵'"
}]
})
review = result["structured_response"]
print(review)
# {'sentiment': 'positive', 'rating': 4, 'keywords': ['电池续航', '价格']}13.4 工具调用策略 vs 原生策略
LangChain 自动选择最佳策略:
from langchain.agents import ProviderStrategy, ToolStrategy
# 原生策略(OpenAI、Claude 等支持)
agent = create_agent(
model="gpt-5.4",
response_format=ProviderStrategy(ContactInfo, strict=True)
)
# 工具调用策略(通用,所有模型支持)
agent = create_agent(
model="ollama:qwen3",
response_format=ToolStrategy(ContactInfo)
)13.5 结合工具使用
@tool
def search_products(query: str) -> str:
"""搜索产品"""
return f"找到 5 个 {query} 相关产品"
class ProductList(BaseModel):
products: list[dict]
total_count: int
agent = create_agent(
model="gpt-5.4",
tools=[search_products],
response_format=ProductList
)
result = agent.invoke({
"messages": [{"role": "user", "content": "搜索笔记本电脑"}]
})
# Agent 会先调用 search_products,然后返回结构化数据
products = result["structured_response"]
14. Deep Agents:开箱即用的高级 Agent
大白话:普通 Agent = 毛坯房(墙自己刷、地自己铺)。Deep Agents = 精装房(拎包入住)。空调(自动规划)、地暖(文件系统)、智能锁(权限)、管家(子 Agent)、档案室(长期记忆)全给你装好了。你要做的就一件事:把需求告诉它,它自己会分步执行。
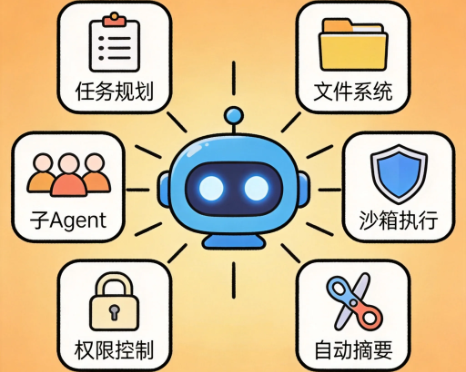
Deep Agents 是 LangChain 官方提供的高级 Agent SDK,内置了任务规划、文件系统、子 Agent、长期记忆等能力。
14.1 Deep Agents vs 普通 LangChain Agent
|
特性 |
普通 Agent |
Deep Agents |
|
代码量 |
需要配置各种组件 |
一行代码创建 |
|
任务规划 |
手动实现 |
内置 |
|
文件系统 |
无 |
虚拟文件系统 |
|
子 Agent |
手动创建 |
内置 |
|
上下文管理 |
手动处理 |
自动摘要 |
|
沙箱执行 |
无 |
支持 Modal/Daytona |
14.2 创建 Deep Agent
pip install deepagentsfrom deepagents import create_deep_agent
def get_weather(city: str) -> str:
return f"{city} 天气晴朗"
agent = create_deep_agent(
model="openai:gpt-5.4",
tools=[get_weather],
system_prompt="你是一个全能助手",
)
result = agent.invoke({
"messages": [{"role": "user", "content": "帮我规划一次北京三日游"}]
})14.3 内置能力详解
任务规划:
用户: 帮我做一个网站
Agent 自动创建 TODO 列表:
1. [ ] 确定网站类型和功能需求
2. [ ] 设计页面结构和布局
3. [ ] 编写 HTML/CSS 代码
4. [ ] 添加交互功能
5. [ ] 测试和部署虚拟文件系统:
# Agent 可以读写文件,管理上下文
agent.invoke({
"messages": [{"role": "user", "content":
"读取 /docs/requirements.txt,然后分析需求"
}]
})
# Deep Agent 会自动调用 read_file 工具子 Agent:
# Agent 可以创建子 Agent 处理子任务
agent.invoke({
"messages": [{"role": "user", "content":
"研究 AI 趋势(使用子 Agent 搜索最新信息)"
}]
})14.4 沙箱执行
Deep Agents 支持在隔离环境中执行代码:
from deepagents import create_deep_agent
from deepagents.backends import SandboxBackend
agent = create_deep_agent(
model="gpt-5.4",
backend=SandboxBackend.Modal, # 使用 Modal 沙箱
)
# Agent 可以安全地执行 shell 命令
result = agent.invoke({
"messages": [{"role": "user", "content":
"运行测试:pytest tests/"
}]
})14.5 权限控制
from deepagents import create_deep_agent
from deepagents.permissions import PermissionRule
agent = create_deep_agent(
model="gpt-5.4",
permissions=[
PermissionRule.allow("/data/*"), # 允许读写数据目录
PermissionRule.deny("/etc/*"), # 禁止访问系统目录
PermissionRule.allow("/tmp/*", read_only=True), # 只读临时目录
]
)
15. 总结
完整学习路径
LangChain 入门 (本文)
│
├──→ 核心概念
│ ├── Agent 架构(create_agent)
│ ├── 工具系统(@tool)
│ ├── 中间件(Middleware)
│ ├── 记忆系统(Short-term / Long-term)
│ └── 流式输出(Streaming)
│
├──→ Deep Agents(开箱即用)
│ 内置规划、文件系统、子 Agent、沙箱
│
├──→ LangGraph(底层编排)
│ 自定义工作流、多 Agent 协作、Human-in-the-loop
│
├──→ LangSmith(可观测性)
│ 追踪、调试、评估、部署
│
└──→ 生产部署
LangGraph Platform、API 服务化✅ 本文覆盖的所有知识点
|
章节 |
核心内容 |
|
1-2 |
LangChain 概述、安装配置 |
|
3-4 |
create_agent、Agent 运行循环 |
|
5 |
@tool 装饰器、Pydantic schema、ToolRuntime |
|
6 |
中间件系统、@wrap_model_call |
|
7 |
动态模型选择、动态工具过滤 |
|
8 |
完整项目:研究助手 Agent |
|
9 |
LangSmith 调试追踪 |
|
10 |
短期记忆(Checkpointer) |
|
11 |
长期记忆(Store) |
|
12 |
流式输出(Streaming) |
|
13 |
结构化输出(response_format) |
|
14 |
Deep Agents 高级功能 |
如有疑问欢迎留言讨论!


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 41
41 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)