拿到数据集不会选模型?机器学习十大算法从公式到代码一次讲透
目录
2. 逻辑回归:什么时候使用 Logistic Regression?
Python 代码示例:乳腺癌分类、混淆矩阵和 ROC 曲线
Python 代码示例:CountVectorizer + MultinomialNB 文本分类
7. 线性回归:什么时候使用 Linear Regression?
Python 代码示例:真实值 vs 预测值,并输出 MAE、MSE、R²
很多同学参加数学建模比赛、做毕业设计、写数据分析项目时,最头疼的往往不是“代码怎么写”,而是:
我手里有一个数据集,到底该用哪个算法?
比如,题目给了一堆城市指标,让你预测空气质量;或者给了用户评论,让你判断情感倾向;又或者给了一批没有标签的客户数据,让你找出不同消费群体。这个时候,直接上模型很容易陷入两个误区:要么把所有算法都试一遍,结果不知道怎么解释;要么看到别人用 XGBoost,自己也无脑套,最后模型效果和论文逻辑都很弱。
机器学习算法选择,本质上不是背概念,而是看清楚四件事:
任务类型是什么、数据有什么特征、是否需要解释、最终更看重精度还是可理解性。
这篇文章围绕 10 个最常见的机器学习算法展开:KNN、逻辑回归、决策树、K-Means、随机森林、朴素贝叶斯、线性回归、SVM、Boosting 和 LDA。每个算法都从“什么时候用”出发,配公式、代码和图表,适合大学生、数学建模参赛者和数据分析初学者作为入门速查。
一、机器学习十大算法总览表
| 算法名称 | 主要任务类型 | 适合使用的场景 | 不适合使用的场景 | 优点 | 缺点 | 常用 Python 实现类 |
|---|---|---|---|---|---|---|
| KNN | 分类、回归 | 小规模数据,边界不规则,数据分布复杂 | 大规模数据,高维稀疏数据,实时预测要求高 | 思想简单,非参数模型,能处理复杂边界 | 预测慢,对尺度敏感,k 值影响大 | sklearn.neighbors.KNeighborsClassifier |
| 逻辑回归 | 分类 | 二分类,要求可解释,特征与分类概率近似线性 | 非线性关系强,复杂边界明显 | 速度快,可解释性强,输出概率 | 表达能力有限,对非线性问题较弱 | sklearn.linear_model.LogisticRegression |
| 决策树 | 分类、回归 | 规则清晰,需要解释决策过程 | 数据噪声大,追求高稳定性 | 可解释性强,不强依赖标准化 | 容易过拟合,单棵树不稳定 | sklearn.tree.DecisionTreeClassifier |
| K-Means | 聚类 | 没有标签,想发现样本内部群体 | 簇形状复杂,类别数量未知,异常值多 | 简单快速,适合初步分群 | 需要指定 K,对初始中心和异常值敏感 | sklearn.cluster.KMeans |
| 随机森林 | 分类、回归、集成学习 | 特征较多,关系复杂,追求稳定效果 | 极端追求解释性,数据量极大且实时要求高 | 稳定、抗过拟合、能看特征重要性 | 模型较重,可解释性低于单棵树 | sklearn.ensemble.RandomForestClassifier |
| 朴素贝叶斯 | 分类 | 文本分类、垃圾邮件识别、高维稀疏特征 | 特征强相关、需要复杂非线性边界 | 训练快,小数据也能用,适合文本 | 独立性假设较强 | sklearn.naive_bayes.MultinomialNB |
| 线性回归 | 回归 | 连续值预测,自变量与因变量近似线性 | 非线性强,异常值多,多重共线性严重 | 简单、可解释、适合基线模型 | 表达能力有限,对异常值敏感 | sklearn.linear_model.LinearRegression |
| SVM | 分类、回归 | 中小规模数据,高维特征,边界清晰 | 样本量特别大,参数调节成本高 | 泛化能力强,核函数能处理非线性 | 训练慢,参数敏感,不易解释 | sklearn.svm.SVC |
| Boosting | 分类、回归、集成学习 | 追求高精度,比赛建模,复杂非线性关系 | 数据噪声很大,参数调优时间不足 | 精度强,表达能力强 | 容易过拟合,调参复杂 | sklearn.ensemble.GradientBoostingClassifier |
| LDA | 分类、降维 | 类别近似线性可分,各类协方差相近 | 类别边界强非线性,分布差异很大 | 可分类也可降维,可解释性较好 | 假设较强,复杂边界效果有限 | sklearn.discriminant_analysis.LinearDiscriminantAnalysis |
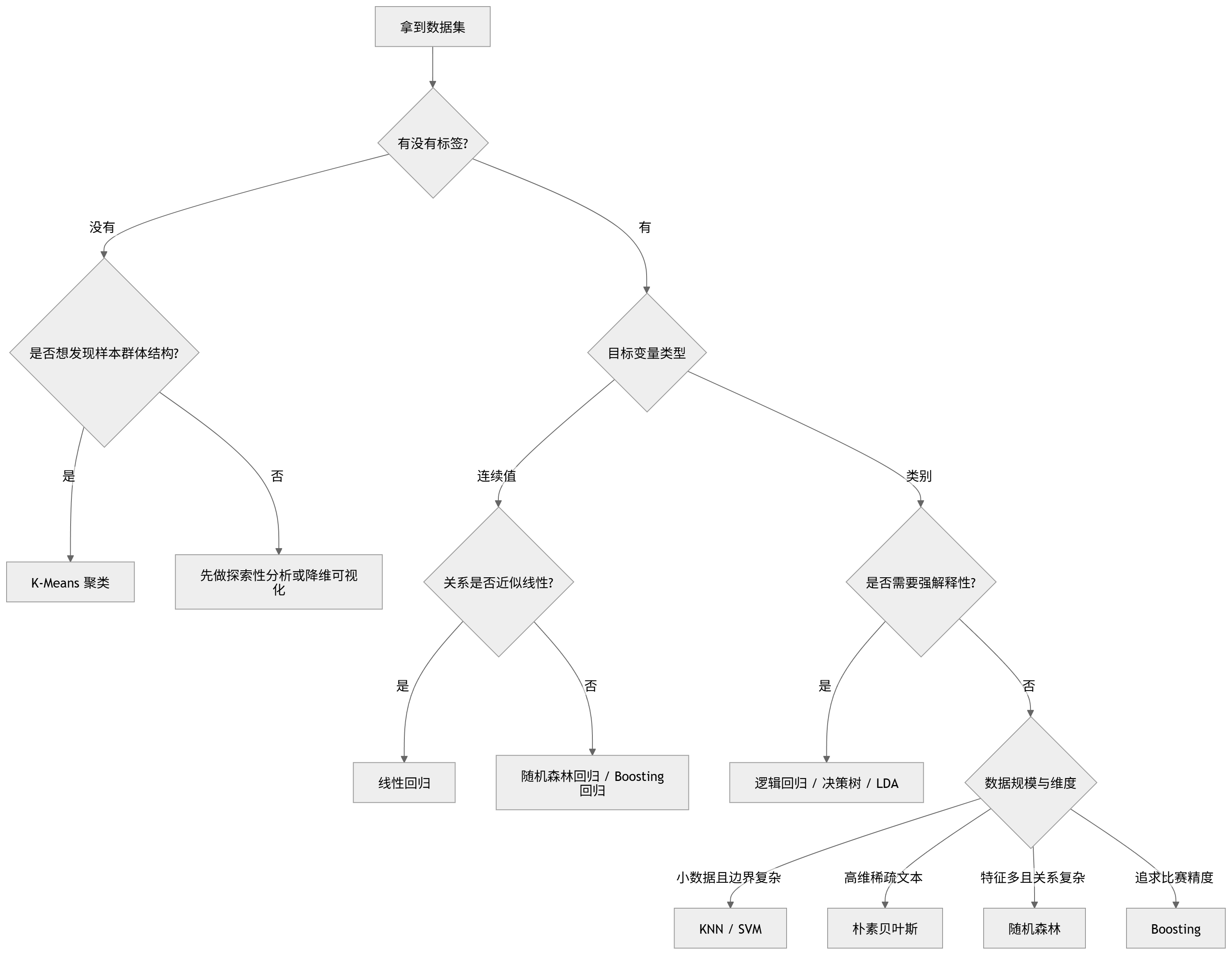
二、拿到数据集后,应该怎么选算法?
不要一上来就问“哪个算法最好”,更合理的问题是:
这个数据集到底是什么任务?
可以从下面几个角度判断。
1. 目标变量有没有标签
如果数据里有明确的目标变量,比如“是否违约”“房价”“空气质量指数”,这就是监督学习。
如果没有标签,只是一批样本和特征,比如客户消费记录、城市发展指标、用户行为数据,就更像无监督学习,常见选择是 K-Means 聚类。
2. 目标变量是连续值还是类别
如果目标变量是连续数值,比如房价、销售额、温度、AQI,可以考虑线性回归、随机森林回归、Boosting 回归。
如果目标变量是类别,比如是否患病、是否流失、评论正负面,可以考虑逻辑回归、决策树、随机森林、SVM、朴素贝叶斯、KNN、LDA。
3. 是否需要模型可解释性
如果你要写论文、答辩或者解释变量影响方向,逻辑回归、线性回归、决策树会更友好。
如果你更看重预测精度,随机森林和 Boosting 往往更强,但解释起来需要借助特征重要性、SHAP 等方法。
4. 数据量是大还是小
KNN 和 SVM 更适合中小规模数据。
随机森林和 Boosting 可以处理更复杂的数据,但数据量特别大时也需要考虑训练时间。
逻辑回归、朴素贝叶斯通常训练很快,适合作为基线模型。
5. 特征维度高不高
文本分类这种高维稀疏数据,朴素贝叶斯很常用。
高维小样本分类,SVM 也经常表现不错。
如果维度较高且需要可视化或分类前降维,可以考虑 LDA。
6. 数据是否线性可分
如果类别边界接近线性,逻辑回归、LDA、线性 SVM 都可以。
如果边界明显弯曲或不规则,KNN、决策树、随机森林、RBF 核 SVM、Boosting 更合适。
7. 是否更看重预测精度
在数学建模比赛、Kaggle 类比赛、企业预测任务中,如果目标是尽量提高准确率、AUC 或 R²,Boosting 和随机森林通常是很强的选择。
8. 是否需要发现隐藏结构
如果没有标签,只想知道样本能不能自然分成几类,比如客户分群、城市类型划分、企业风险分层,可以先用 K-Means 做探索性聚类。
三、算法选择流程图
四、公共代码:导入库与数据准备
下面的代码作为后面所有示例的公共准备部分。你可以在 Jupyter Notebook、PyCharm 或 VS Code 里先运行这一段,再运行每个算法对应的代码。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification, make_blobs, make_regression, load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_curve, auc
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.cluster import KMeans
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import SVC
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.feature_extraction.text import CountVectorizer
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
np.random.seed(42)
# 分类数据
X_cls, y_cls = make_classification(
n_samples=500,
n_features=2,
n_redundant=0,
n_informative=2,
n_clusters_per_class=1,
class_sep=1.2,
random_state=42
)
X_train_cls, X_test_cls, y_train_cls, y_test_cls = train_test_split(
X_cls, y_cls, test_size=0.3, random_state=42, stratify=y_cls
)
scaler_cls = StandardScaler()
X_train_cls_scaled = scaler_cls.fit_transform(X_train_cls)
X_test_cls_scaled = scaler_cls.transform(X_test_cls)
# 回归数据
X_reg, y_reg = make_regression(
n_samples=400,
n_features=3,
noise=15,
random_state=42
)
X_train_reg, X_test_reg, y_train_reg, y_test_reg = train_test_split(
X_reg, y_reg, test_size=0.3, random_state=42
)
# 聚类数据
X_cluster, y_cluster_true = make_blobs(
n_samples=400,
centers=4,
cluster_std=1.0,
random_state=42
)
# 分类边界绘图函数
def plot_decision_boundary(model, X, y, title):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(
np.linspace(x_min, x_max, 300),
np.linspace(y_min, y_max, 300)
)
grid = np.c_[xx.ravel(), yy.ravel()]
Z = model.predict(grid).reshape(xx.shape)
plt.figure(figsize=(6, 5))
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor="k", s=35)
plt.title(title)
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.show()1. KNN:什么时候使用 k-近邻算法?
算法直觉
KNN 的想法很朴素:一个样本属于哪一类,可以看看它周围最近的 k 个邻居大多数属于哪一类。
如果你搬到一个新小区,想判断这个小区更像“学生区”还是“办公区”,你可能会看周围的人群、店铺、作息。如果附近大多数都是学生、公寓、打印店,那它大概率是学生区。KNN 做的就是类似判断。
KNN 不主动学习一个显式公式,它把训练数据“记住”,预测新样本时再计算距离。
核心公式
KNN 最常用的是欧氏距离:
其中, 和
表示两个样本,
表示特征数量,
表示第
个样本在第
个特征上的取值。距离越小,说明两个样本越相似。
分类时,KNN 通常使用多数投票:
其中,$N_k(x)$ 表示离样本 $x$ 最近的 $k$ 个邻居,$I(y_i=c)$ 表示第 $i$ 个邻居是否属于类别 $c$。
适合什么时候用
KNN 适合小规模数据、边界不规则、没有明显线性关系的分类或回归问题。比如二维特征下的非线性分类、小样本模式识别、简单推荐系统中的相似用户查找。
如果数据量不大,并且你怀疑类别边界不是一条直线,而是弯弯曲曲的,KNN 值得尝试。
不适合什么时候用
KNN 不适合大规模数据,因为预测时需要计算新样本和大量训练样本之间的距离。它也不适合高维稀疏数据,因为维度升高后,距离度量会变得不稳定。
另外,KNN 对特征尺度非常敏感。身高用厘米、收入用万元,如果不标准化,数值范围大的特征会主导距离计算。
典型应用场景
KNN 常见于小样本分类、相似用户推荐、异常点初步识别、简单图像分类、局部模式识别等任务。
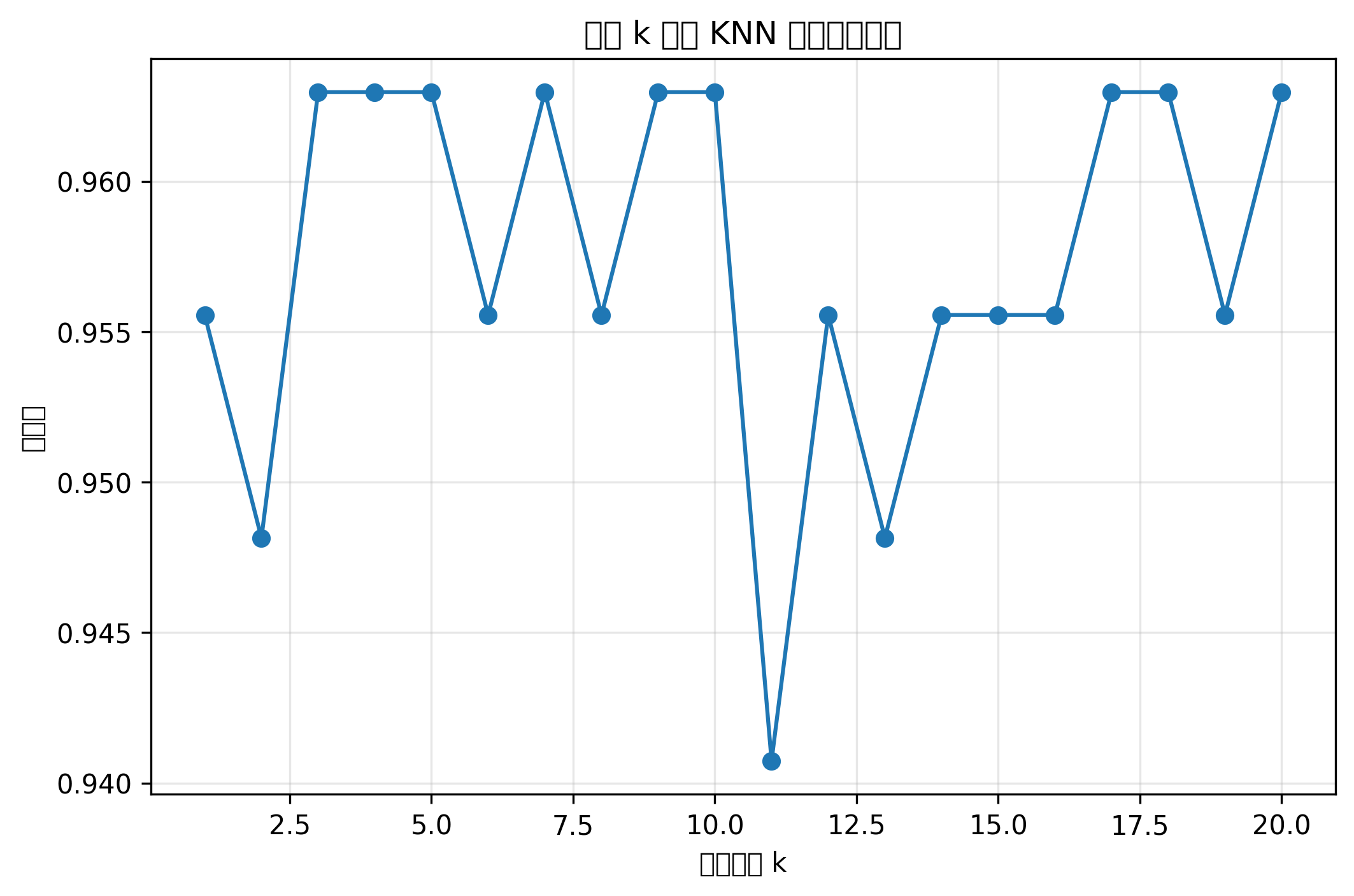
k_values = [1, 5, 15]
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train_cls_scaled, y_train_cls)
y_pred = knn.predict(X_test_cls_scaled)
acc = accuracy_score(y_test_cls, y_pred)
print(f"KNN, k={k}, 测试集准确率: {acc:.3f}")
plot_decision_boundary(
knn,
X_train_cls_scaled,
y_train_cls,
title=f"KNN 分类边界,k={k}"
)图表怎么看
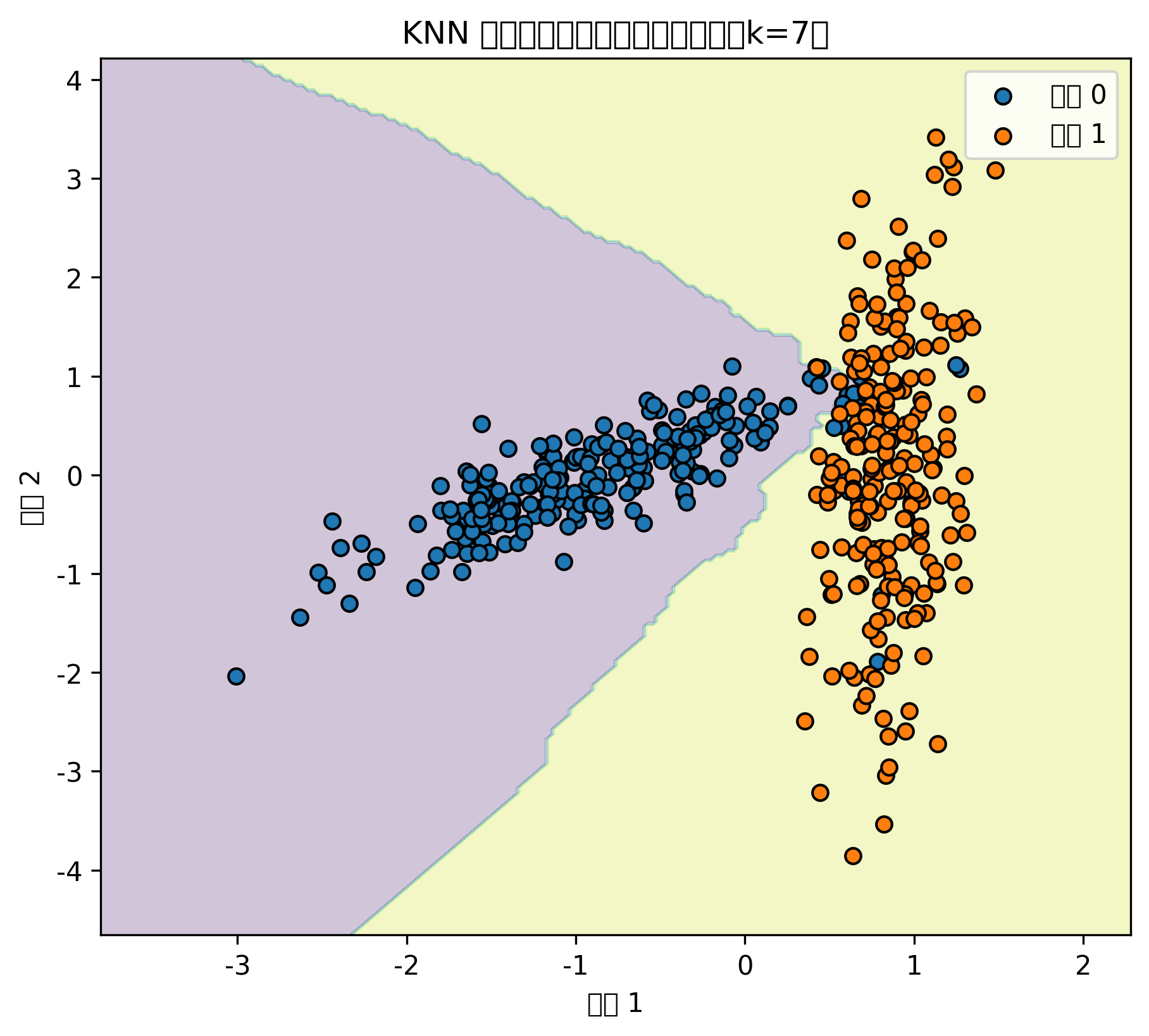
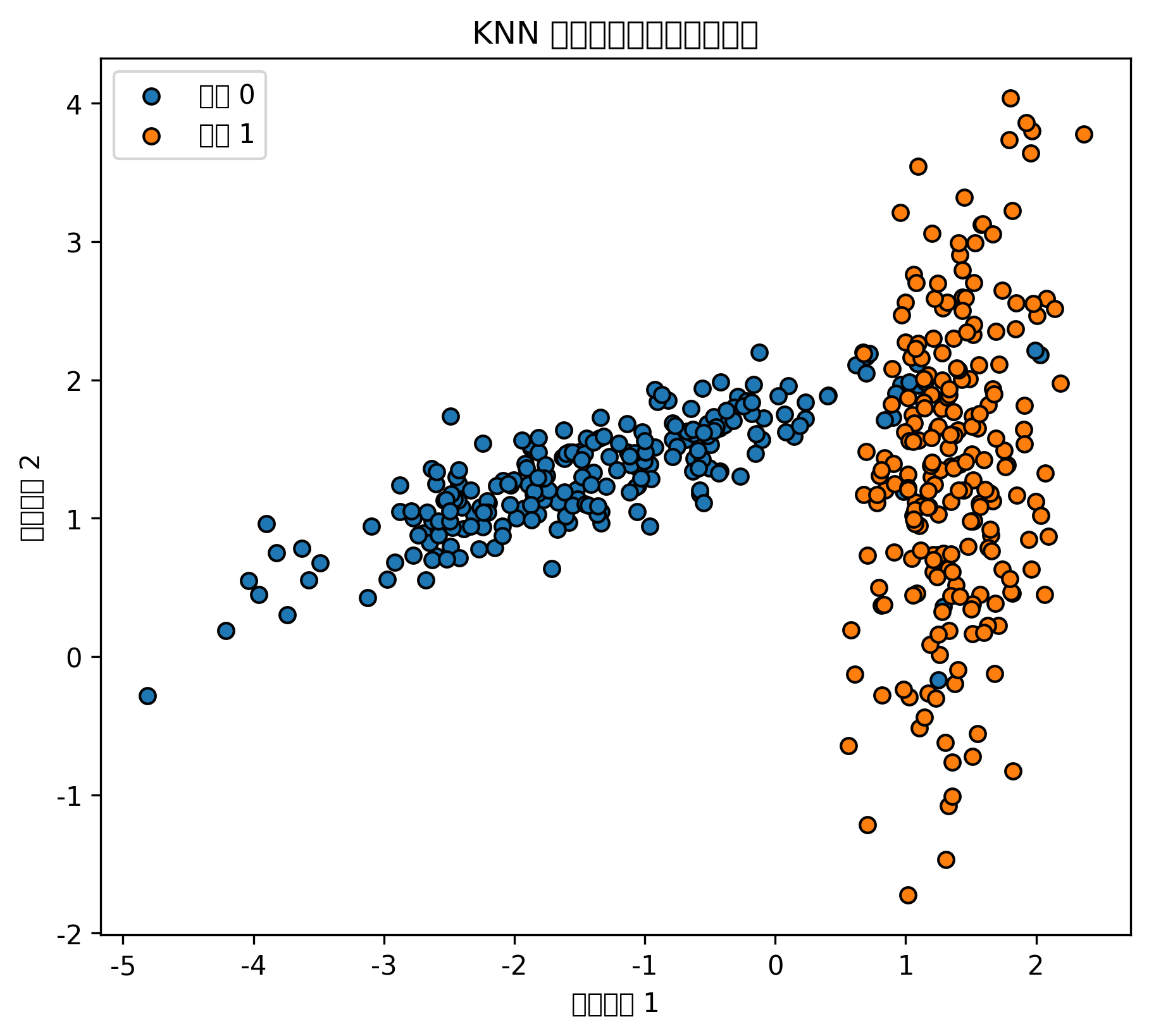
当 k=1 时,模型会非常贴近训练数据,分类边界容易变得破碎,这通常意味着过拟合。
当 k 很大时,分类边界会变得过于平滑,模型可能忽略局部结构,出现欠拟合。
所以 KNN 不是 k 越小越好,也不是 k 越大越好。实际建模中,通常通过交叉验证选择合适的 k。
和其他算法的区别
KNN 和逻辑回归最大的区别是:逻辑回归会学习一个明确的参数模型,而 KNN 更像“查邻居”。
KNN 比线性模型更能处理不规则边界,但预测速度更慢,对标准化更敏感。
2. 逻辑回归:什么时候使用 Logistic Regression?
算法直觉
逻辑回归名字里有“回归”,但它不是用来预测连续值的,而是一个分类模型,最常见的是二分类。
它做的事情是:先把特征线性组合成一个得分,再用 Sigmoid 函数把这个得分压缩到 0 到 1 之间,表示样本属于正类的概率。
比如在乳腺癌分类中,模型可以输出“某个样本为恶性的概率是 0.87”。如果概率大于 0.5,就判为正类。
核心公式
Sigmoid 函数为:
其中, 是特征,
是截距项,
是模型参数。线性组合越大,
越接近 1;线性组合越小,概率越接近 0。
也可以写成对数几率形式:
这说明逻辑回归假设的是:特征与类别的对数几率之间近似线性关系。
适合什么时候用
逻辑回归适合二分类问题,尤其适合需要解释变量影响方向的场景。例如疾病风险预测、用户是否流失、贷款是否违约、学生是否通过考试等。
如果你要在论文里解释“某个指标升高会让事件发生概率增加还是降低”,逻辑回归比很多复杂模型更容易讲清楚。
不适合什么时候用
如果数据中的类别边界非常复杂,逻辑回归可能表现一般。它默认线性决策边界,除非手工构造多项式特征或交互项,否则难以表达复杂非线性关系。
典型应用场景
医学二分类、信用评分、用户转化预测、风险预警、二分类基线模型。
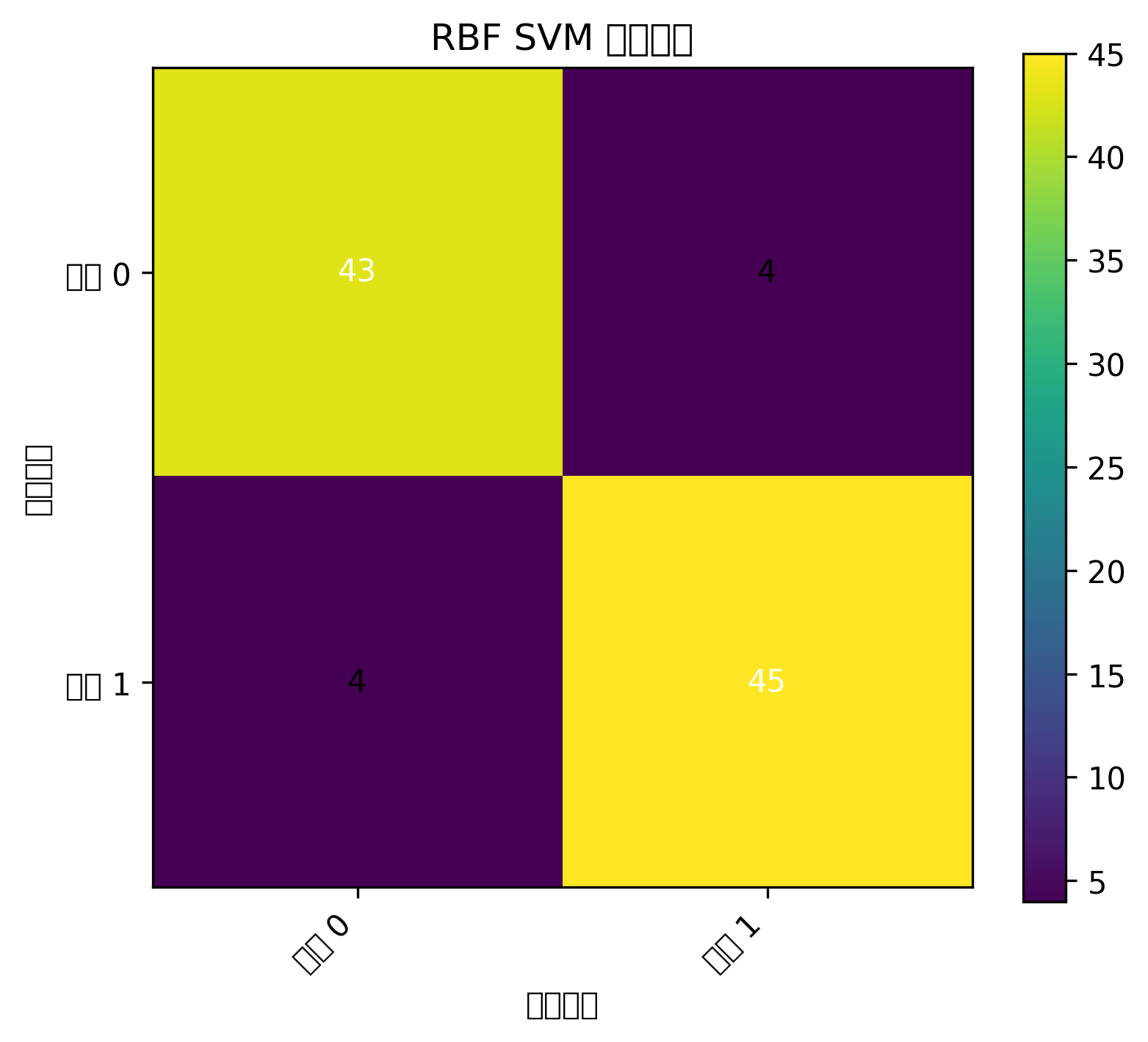
Python 代码示例:乳腺癌分类、混淆矩阵和 ROC 曲线
# 加载乳腺癌数据集
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
log_reg = LogisticRegression(max_iter=1000)
log_reg.fit(X_train_scaled, y_train)
y_pred = log_reg.predict(X_test_scaled)
y_prob = log_reg.predict_proba(X_test_scaled)[:, 1]
acc = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
print("逻辑回归准确率:", round(acc, 3))
print("混淆矩阵:\n", cm)
print("分类报告:\n", classification_report(y_test, y_pred))
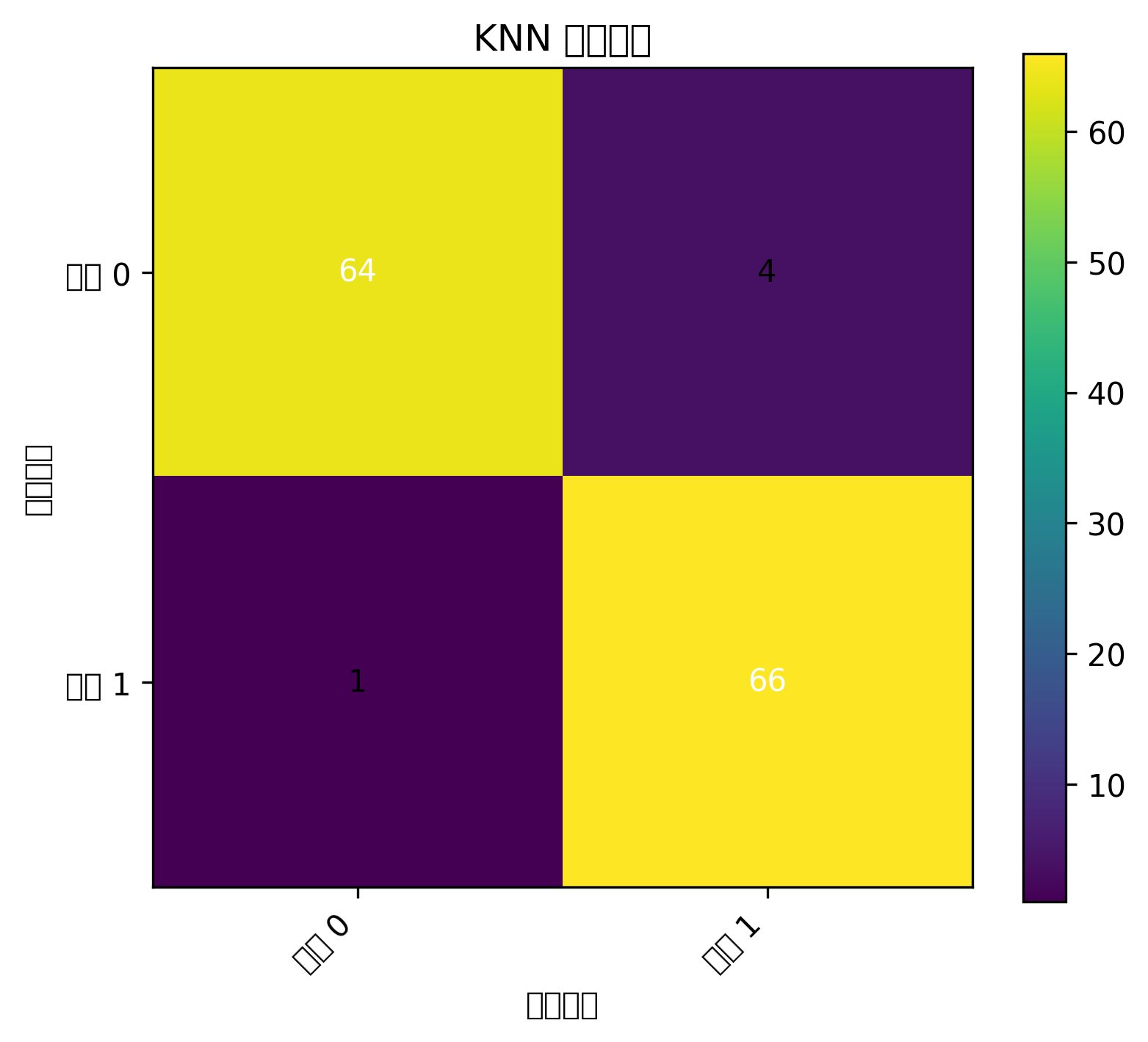
# 混淆矩阵图
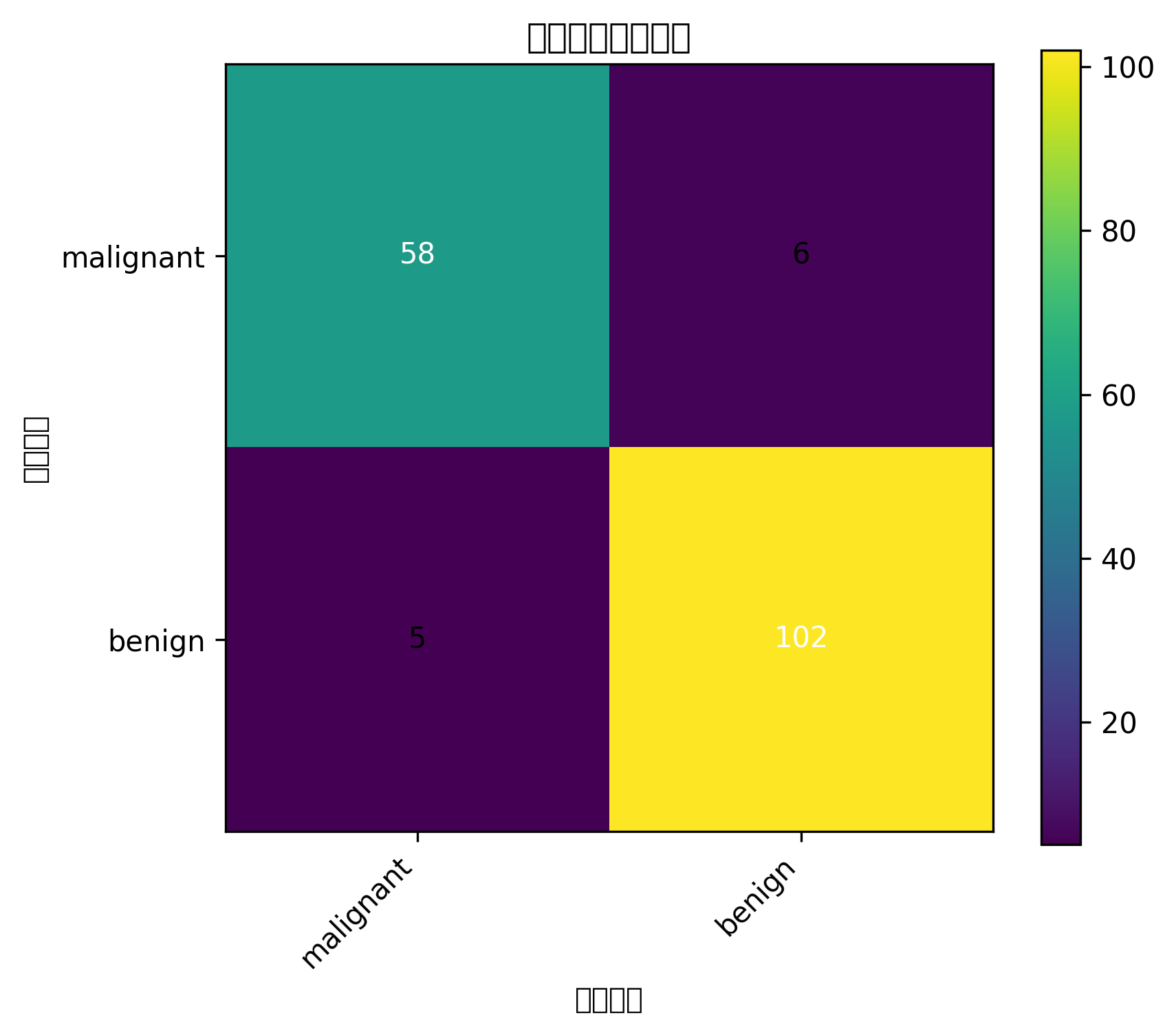
plt.figure(figsize=(5, 4))
plt.imshow(cm)
plt.title("逻辑回归混淆矩阵")
plt.xlabel("预测类别")
plt.ylabel("真实类别")
plt.xticks([0, 1])
plt.yticks([0, 1])
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
plt.text(j, i, cm[i, j], ha="center", va="center")
plt.colorbar()
plt.show()
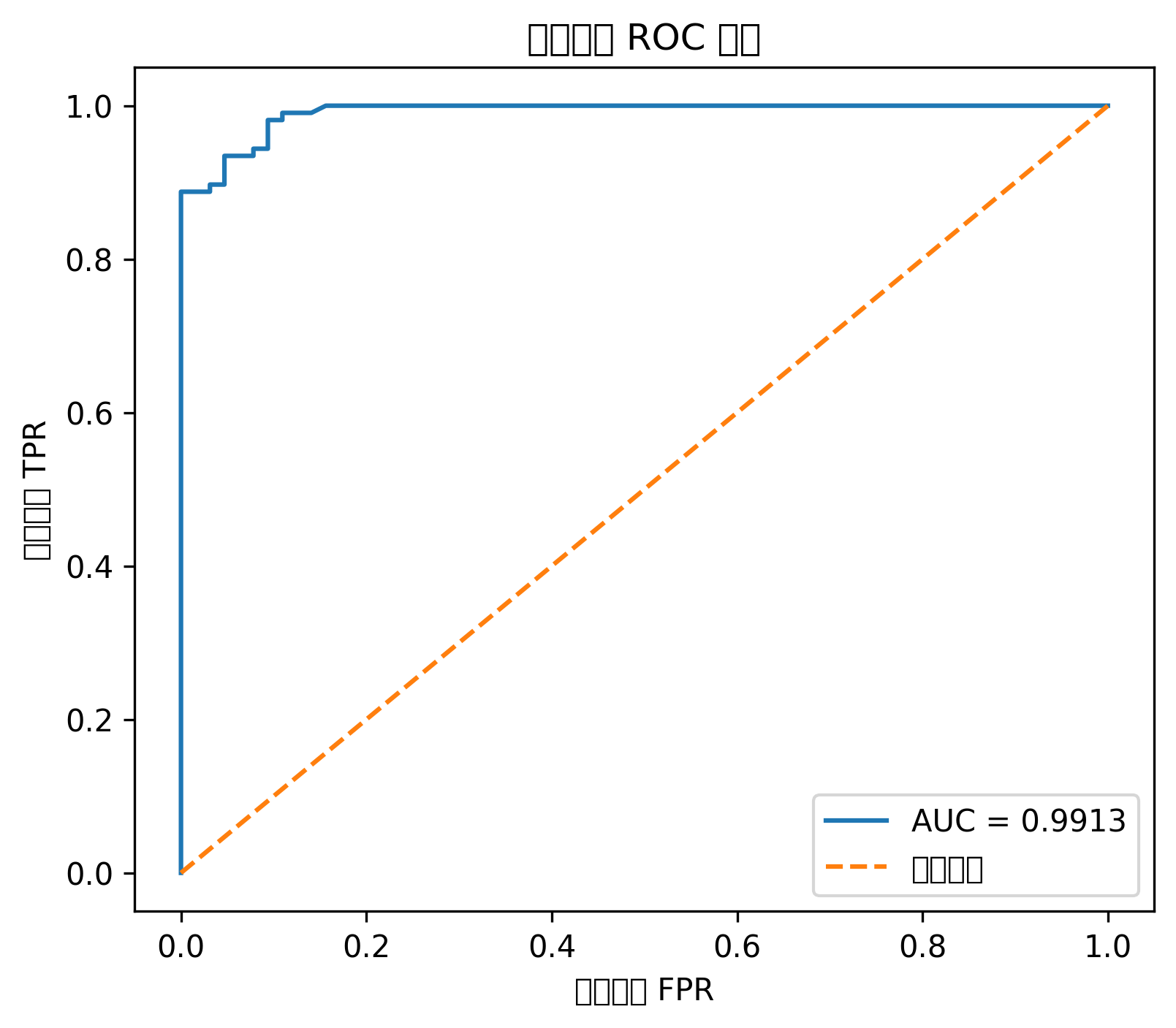
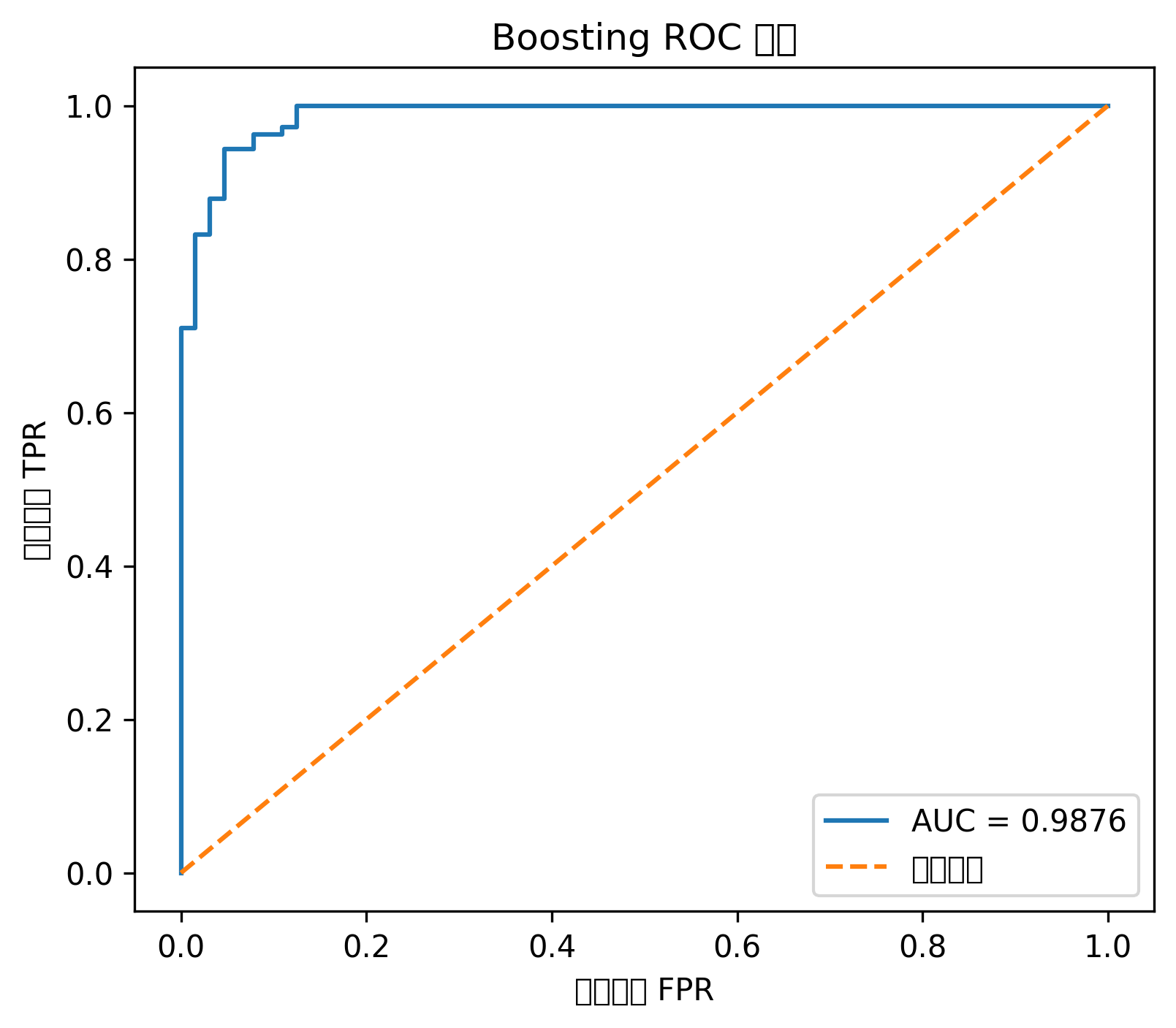
# ROC 曲线
plt.figure(figsize=(6, 5))
plt.plot(fpr, tpr, label=f"AUC = {roc_auc:.3f}")
plt.plot([0, 1], [0, 1], linestyle="--")
plt.title("逻辑回归 ROC 曲线")
plt.xlabel("假阳性率 FPR")
plt.ylabel("真正率 TPR")
plt.legend()
plt.show()图表怎么看
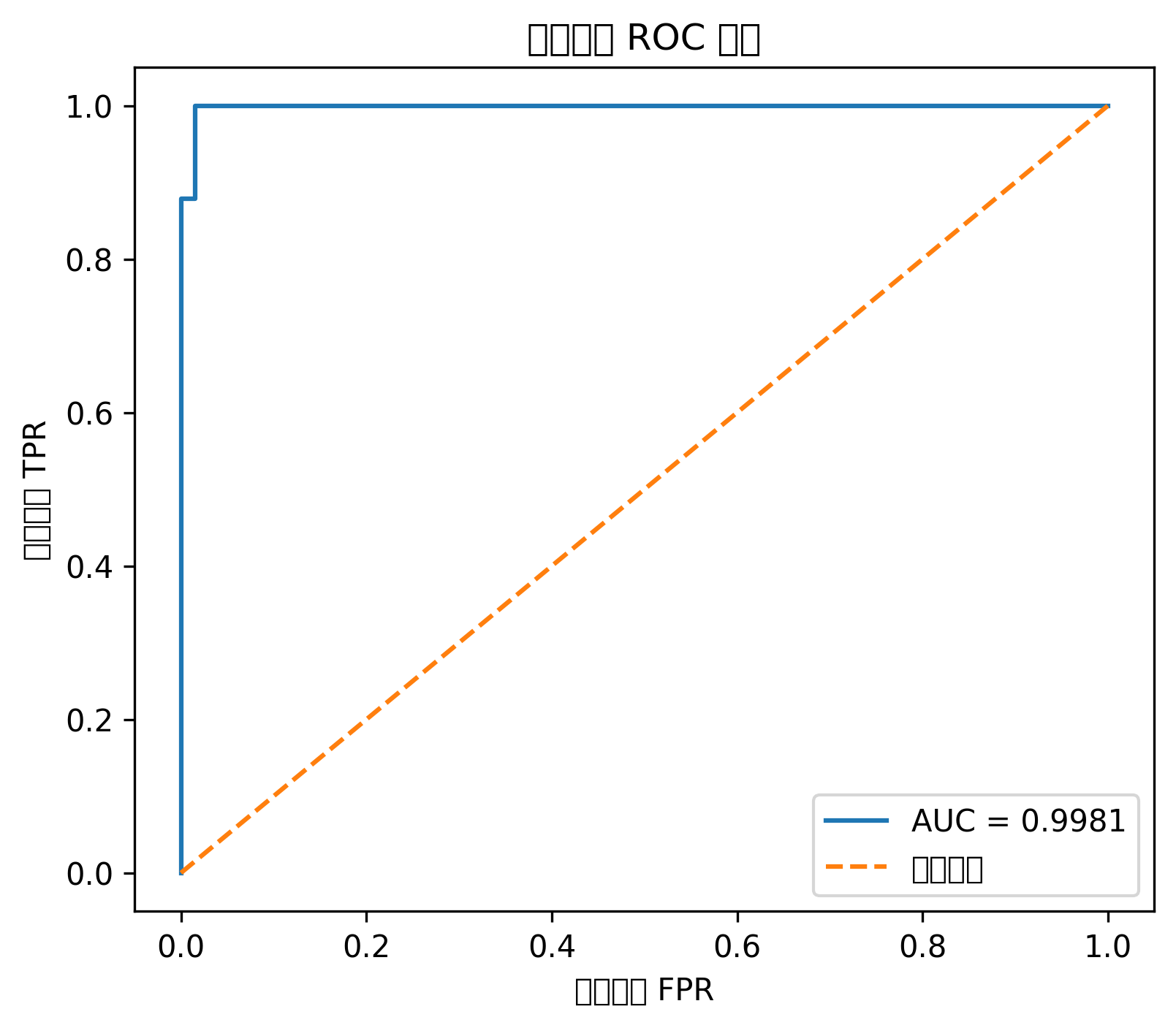
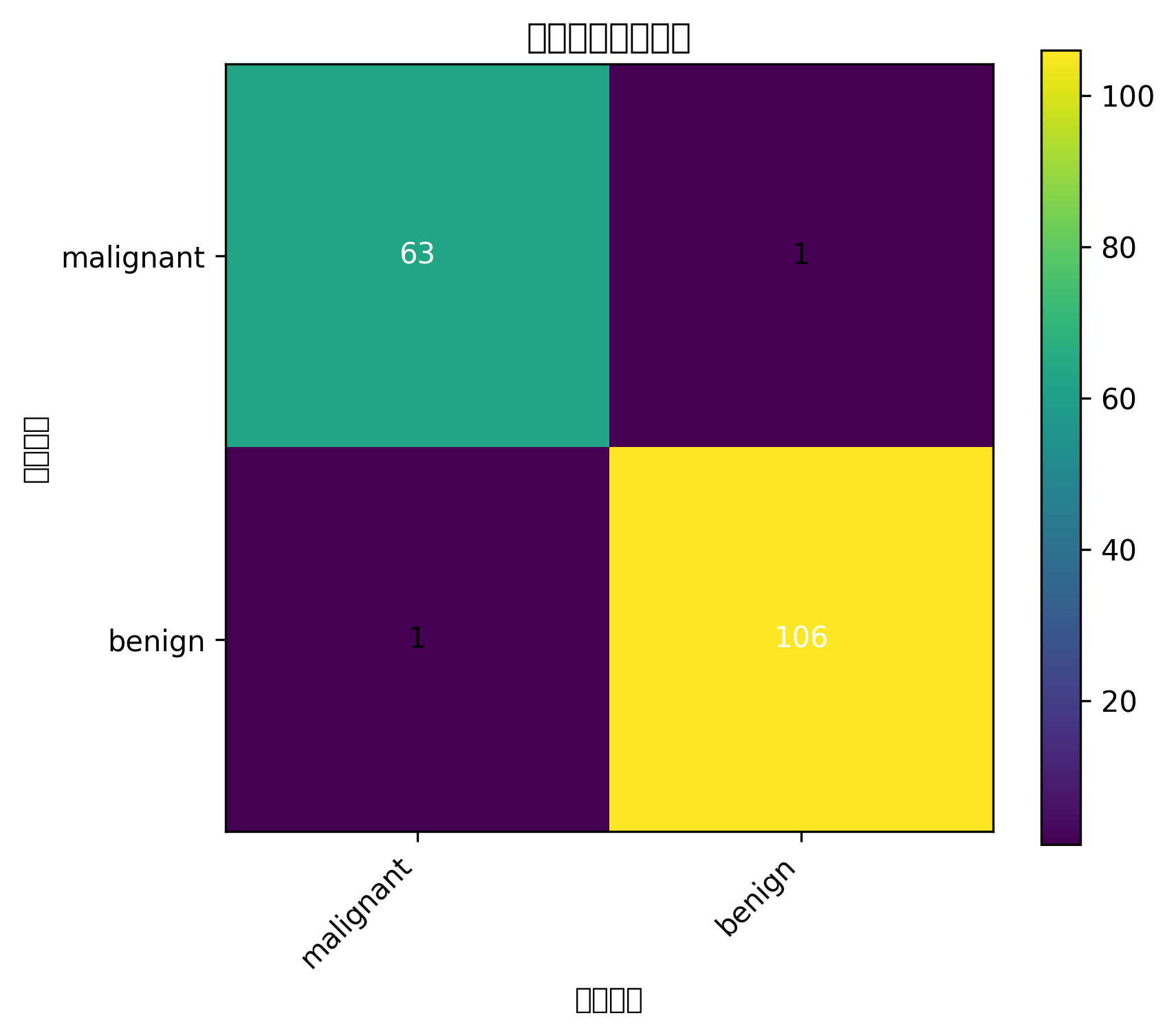
混淆矩阵能告诉你模型把多少正类、负类分对了。
ROC 曲线越靠近左上角,说明模型区分正负样本的能力越强。AUC 越接近 1,整体分类性能越好。
和其他算法的区别
逻辑回归比决策树更像统计模型,解释的是变量对概率的影响。
它比随机森林、Boosting 简单,精度可能不如复杂模型,但在论文、报告、医学和金融场景中非常常用。
3. 决策树:什么时候使用 Decision Tree?
算法直觉
决策树像一套“层层追问”的规则。
比如判断一个学生是否适合参加数学建模比赛,可能先问:会不会 Python?再问:有没有建模基础?再问:是否能坚持三天写论文?每一次判断都把样本分到不同分支,最后得到一个类别。
决策树最大的优点是直观。它不像黑箱模型,而是能画成树结构,告诉你模型为什么这么判断。
核心公式
分类树常用基尼指数衡量节点纯度:
其中, 表示当前节点中的样本集合,
表示类别数量,
表示第
类样本在当前节点中的比例。
如果一个节点里几乎全是同一类样本,$Gini(D)$ 接近 0,说明节点很纯。
如果不同类别混在一起,基尼指数更大,说明还需要继续划分。
决策树在每一步会寻找一个特征和切分点,让划分后的节点更加纯。
适合什么时候用
决策树适合规则清晰、需要可解释性的分类或回归任务。比如客户分层、风险判断、指标阈值分析、论文中的规则提取等。
当你希望模型结果能写成“如果某指标大于多少,就更可能属于某类”时,决策树非常合适。
不适合什么时候用
单棵决策树非常容易过拟合。树长得太深时,它可能把训练集里的噪声也学进去,训练集效果很好,测试集效果下降。
所以实际使用时,常常需要限制最大深度、最小叶子节点样本数,或者进行剪枝。
典型应用场景
信用风险规则、用户分层、医学辅助判断、政策分类规则、可解释分类模型。
Python 代码示例:训练决策树并画树结构
tree = DecisionTreeClassifier(max_depth=3, random_state=42)
tree.fit(X_train_cls, y_train_cls)
y_pred_tree = tree.predict(X_test_cls)
acc_tree = accuracy_score(y_test_cls, y_pred_tree)
print("决策树准确率:", round(acc_tree, 3))
plt.figure(figsize=(14, 8))
plot_tree(
tree,
filled=True,
feature_names=["特征1", "特征2"],
class_names=["类别0", "类别1"]
)
plt.title("决策树结构图")
plt.show()
plot_decision_boundary(
tree,
X_train_cls,
y_train_cls,
title="决策树分类边界"
)图表怎么看
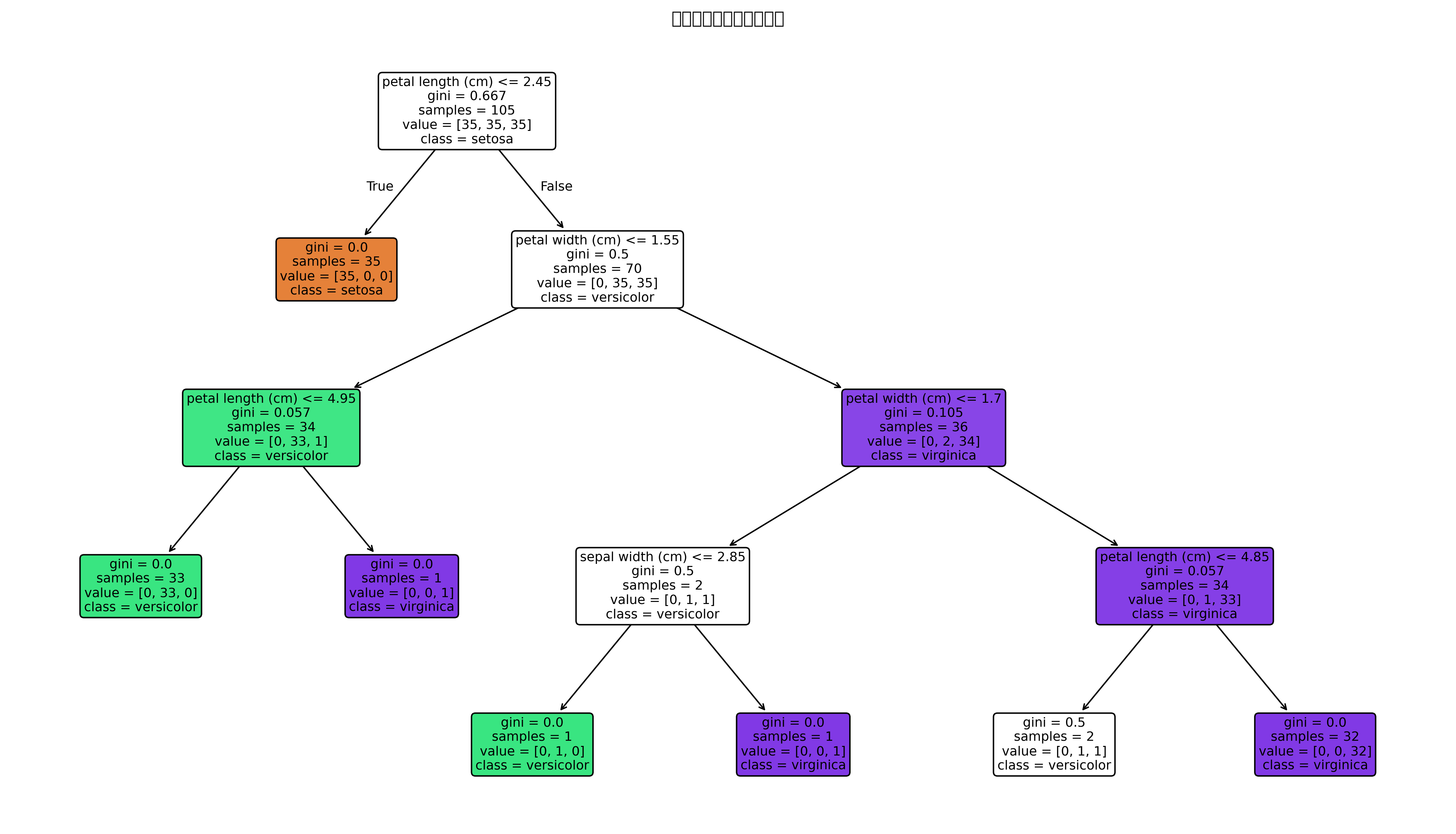
树结构图可以直接看到模型使用了哪些特征、在哪些阈值处分裂。
分类边界图通常呈现“横平竖直”的块状边界,这是决策树按特征阈值不断切分空间的结果。
和其他算法的区别
决策树比逻辑回归更能处理非线性关系,也不强制要求特征标准化。
但单棵树不如随机森林稳定。随机森林本质上就是很多棵决策树的组合。
4. K-Means:什么时候使用聚类算法?
算法直觉
K-Means 是无监督学习算法。它适合在没有标签的情况下,寻找数据内部的群体结构。
比如你有一批城市数据,包括 GDP、人口、产业结构、污染物排放、绿地面积,但没有“城市类型”标签。你可以用 K-Means 把城市分成几类,再分析每一类城市有什么特点。
K-Means 的直觉是:把样本分到离自己最近的聚类中心,然后不断更新中心位置,直到结果稳定。
核心公式
K-Means 的目标函数为:
其中,是样本数量,
是簇的数量,
是第
个样本,
是第
个簇的中心,
表示样本
是否属于第
个簇。若属于,则
,否则为 0。
这个公式的意思是:让每个样本尽量靠近自己所属簇的中心。
适合什么时候用
K-Means 适合没有标签、想发现样本内部群体结构的任务。比如客户分群、城市类型划分、消费行为分层、企业画像分析等。
它尤其适合簇形状接近圆形、各簇大小差别不太大的数据。
不适合什么时候用
K-Means 需要人为指定 $K$ 值。
如果真实簇形状非常复杂,比如月牙形、环形,K-Means 效果可能不好。它也容易受到异常值影响,因为均值中心会被极端点拉偏。
典型应用场景
用户分群、城市综合发展水平分类、企业类型划分、图像颜色压缩、无标签样本初步探索。
Python 代码示例:聚类散点图和肘部法则
# K-Means 聚类
kmeans = KMeans(n_clusters=4, random_state=42, n_init=10)
cluster_labels = kmeans.fit_predict(X_cluster)
plt.figure(figsize=(6, 5))
plt.scatter(X_cluster[:, 0], X_cluster[:, 1], c=cluster_labels, s=35, edgecolor="k")
plt.scatter(
kmeans.cluster_centers_[:, 0],
kmeans.cluster_centers_[:, 1],
marker="X",
s=200,
label="聚类中心"
)
plt.title("K-Means 聚类结果")
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.legend()
plt.show()
# 肘部法则
inertias = []
K_range = range(1, 10)
for k in K_range:
model = KMeans(n_clusters=k, random_state=42, n_init=10)
model.fit(X_cluster)
inertias.append(model.inertia_)
plt.figure(figsize=(6, 5))
plt.plot(list(K_range), inertias, marker="o")
plt.title("K-Means 肘部法则")
plt.xlabel("聚类数量 K")
plt.ylabel("簇内平方和 Inertia")
plt.show()图表怎么看
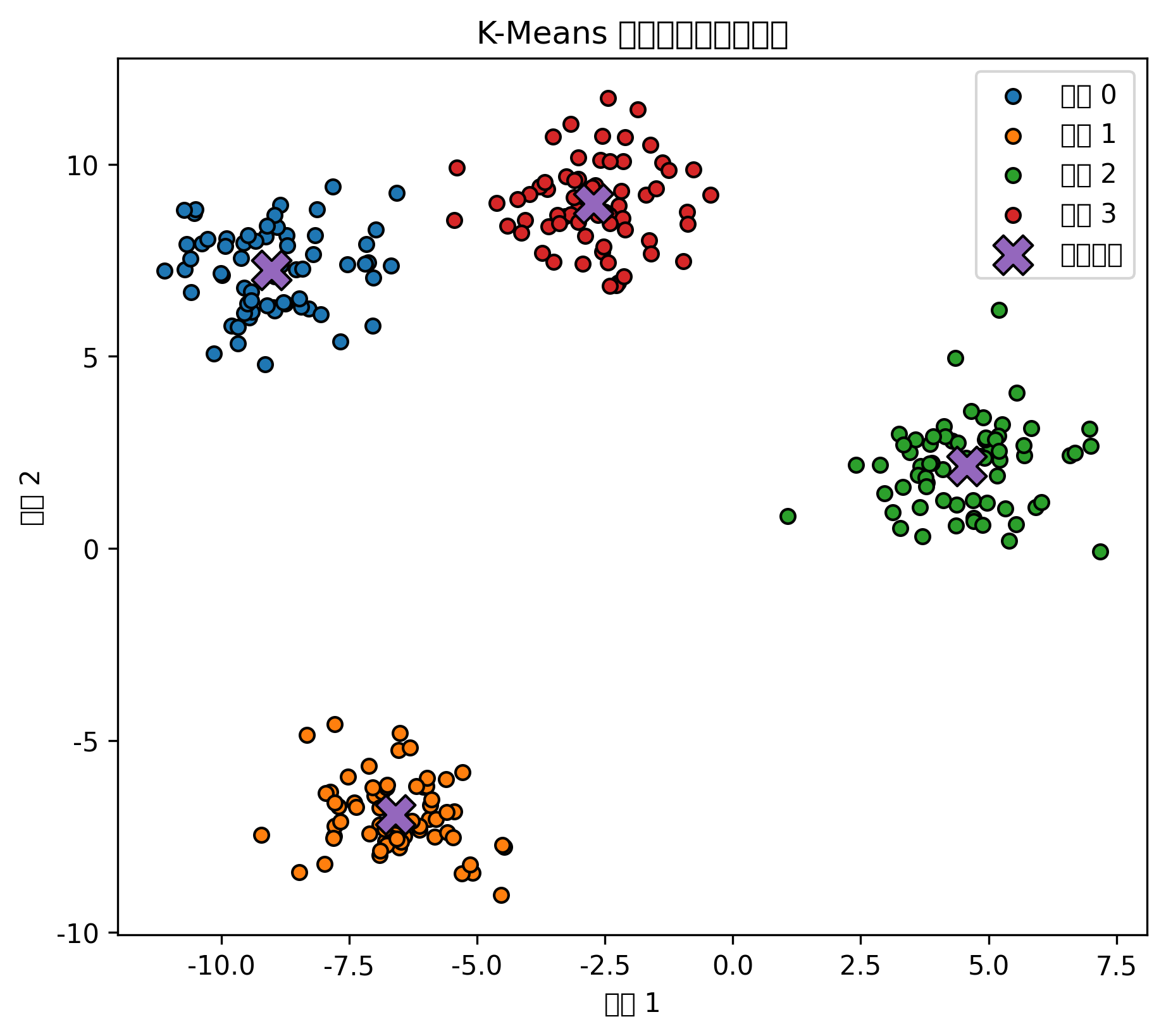
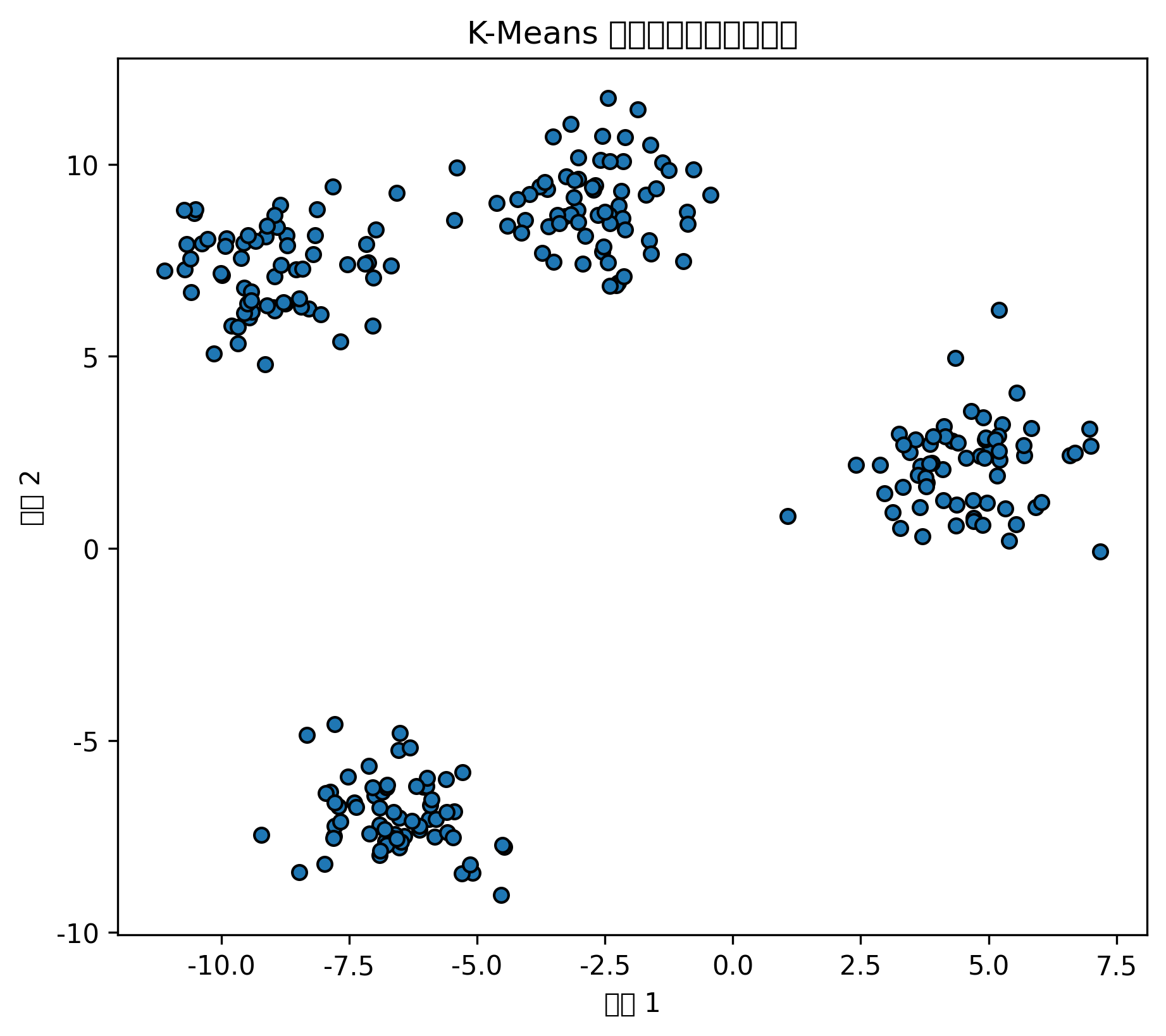
聚类散点图展示了不同样本被分到了哪个簇。
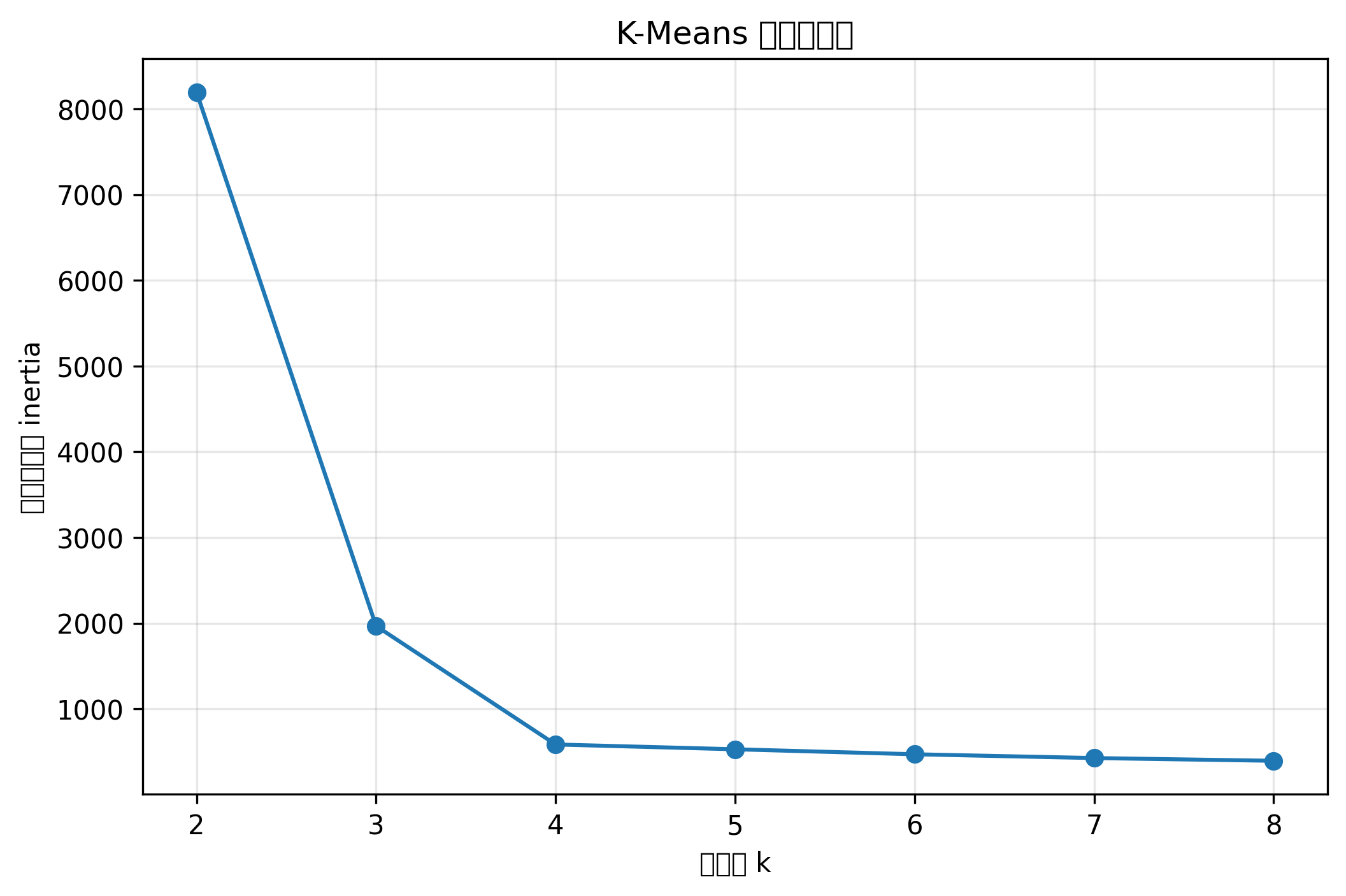
肘部法则图中,如果某个 K 之后簇内平方和下降速度明显变慢,这个位置就可能是合适的聚类数量。
和其他算法的区别
K-Means 和前面的 KNN 完全不是一类算法。
KNN 是监督学习,需要标签;K-Means 是无监督学习,不需要标签。
KNN 用“邻居”做预测,K-Means 用“中心”做分组。
5. 随机森林:什么时候使用 Random Forest?
算法直觉
随机森林可以理解为“很多棵决策树一起投票”。
单棵决策树容易受数据扰动影响。今天训练出来一棵树,明天换一批样本,树结构可能就变了。随机森林通过构造多棵树,让每棵树看不同的样本、不同的特征,最后综合判断。
分类任务中,多棵树投票;回归任务中,多棵树取平均。
核心思想:Bagging
随机森林基于 Bagging 思想。对于分类任务,可以写成:
其中,表示第
棵树对样本
的预测结果,
是树的数量,
表示投票最多的类别。
回归任务则通常取平均:
随机森林的稳定性来自“多模型平均”。单棵树可能偏,但很多棵树综合起来,方差会下降。
适合什么时候用
随机森林适合分类和回归,也适合特征较多、关系复杂、追求稳定预测效果的任务。如果你不知道先用什么强模型,随机森林通常是一个很稳的选择。
它还可以输出特征重要性,因此在建模报告中也比较好解释。
不适合什么时候用
随机森林比单棵决策树更难解释。虽然可以看特征重要性,但很难像决策树那样完整画出所有规则。
如果业务场景极度强调透明规则,单棵决策树或逻辑回归可能更适合。
典型应用场景
信用风险预测、疾病分类、用户流失预测、特征重要性分析、复杂表格数据建模。
Python 代码示例:随机森林分类与特征重要性图
rf = RandomForestClassifier(
n_estimators=200,
max_depth=5,
random_state=42
)
rf.fit(X_train_cls, y_train_cls)
y_pred_rf = rf.predict(X_test_cls)
acc_rf = accuracy_score(y_test_cls, y_pred_rf)
print("随机森林准确率:", round(acc_rf, 3))
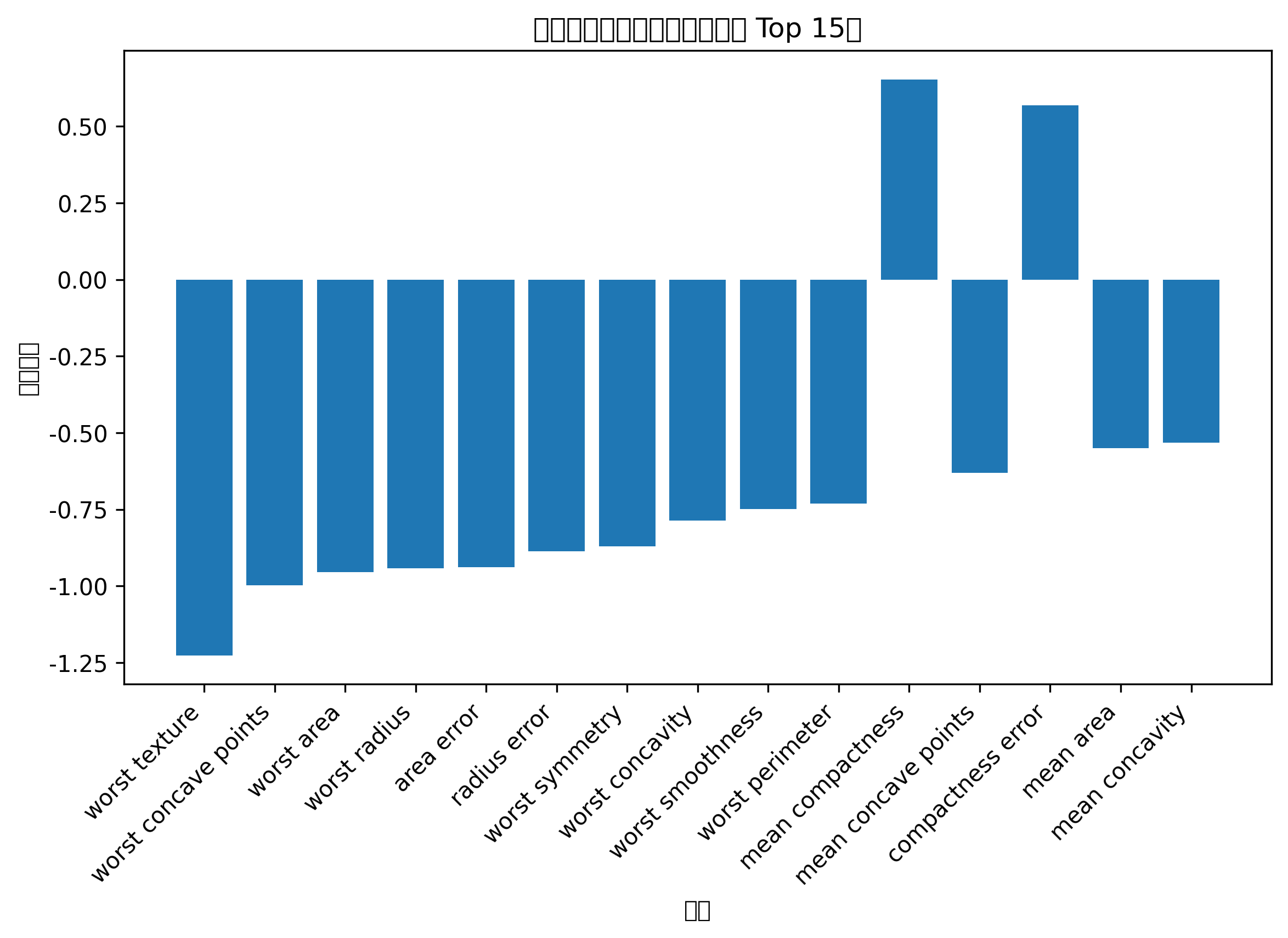
# 特征重要性
feature_names = ["特征1", "特征2"]
importances = rf.feature_importances_
plt.figure(figsize=(6, 4))
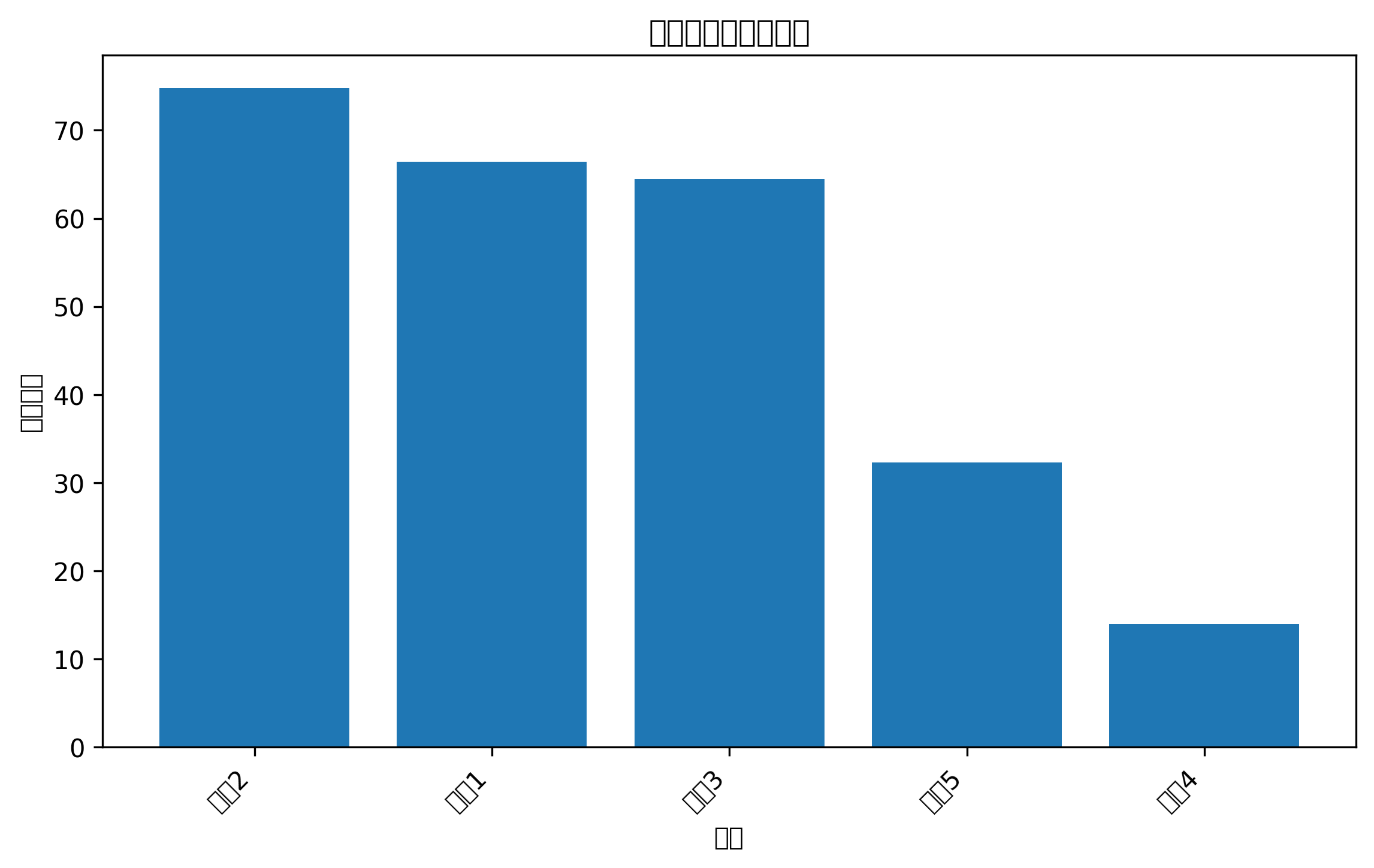
plt.bar(feature_names, importances)
plt.title("随机森林特征重要性")
plt.xlabel("特征")
plt.ylabel("重要性")
plt.show()
plot_decision_boundary(
rf,
X_train_cls,
y_train_cls,
title="随机森林分类边界"
)图表怎么看
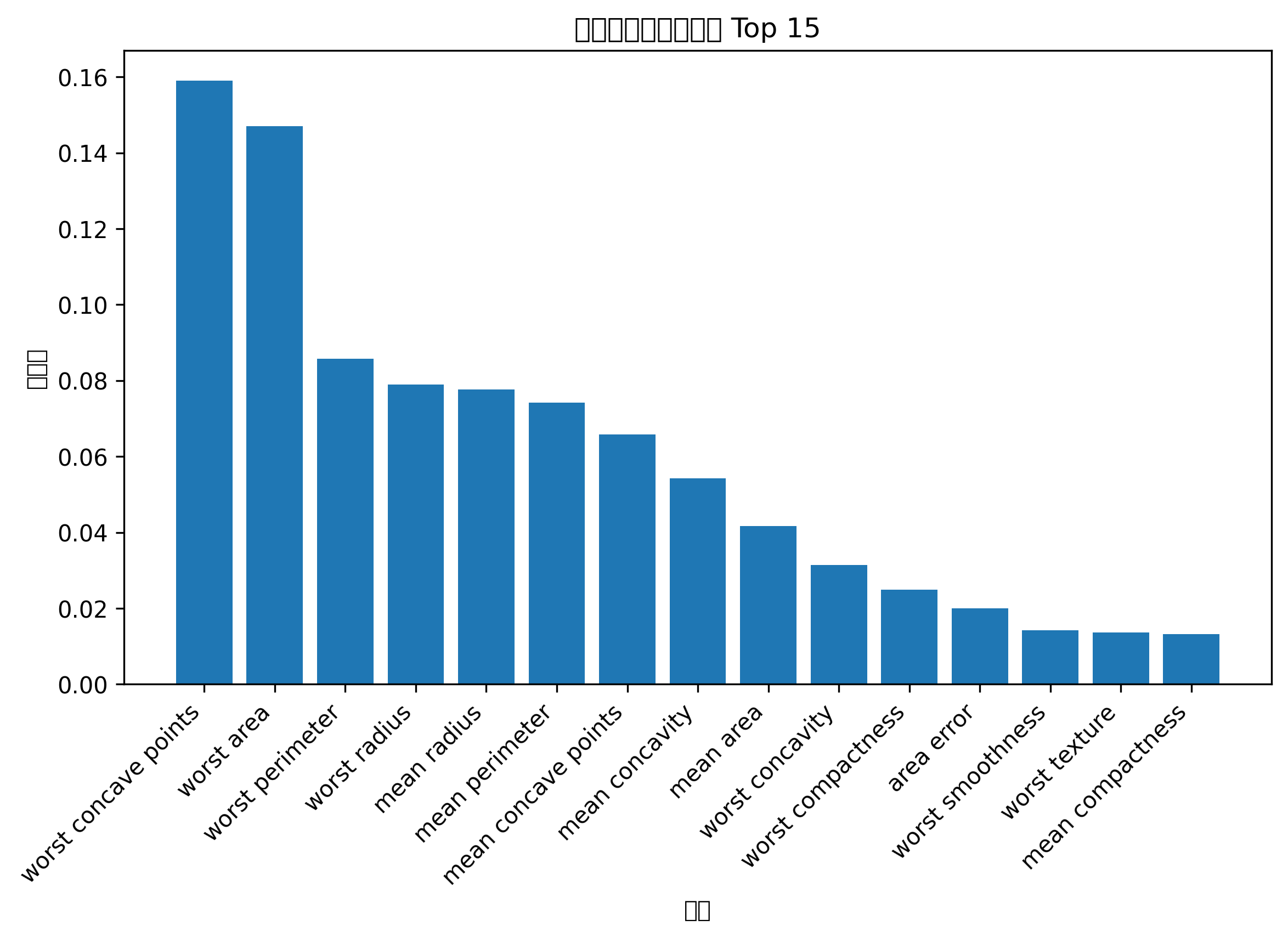
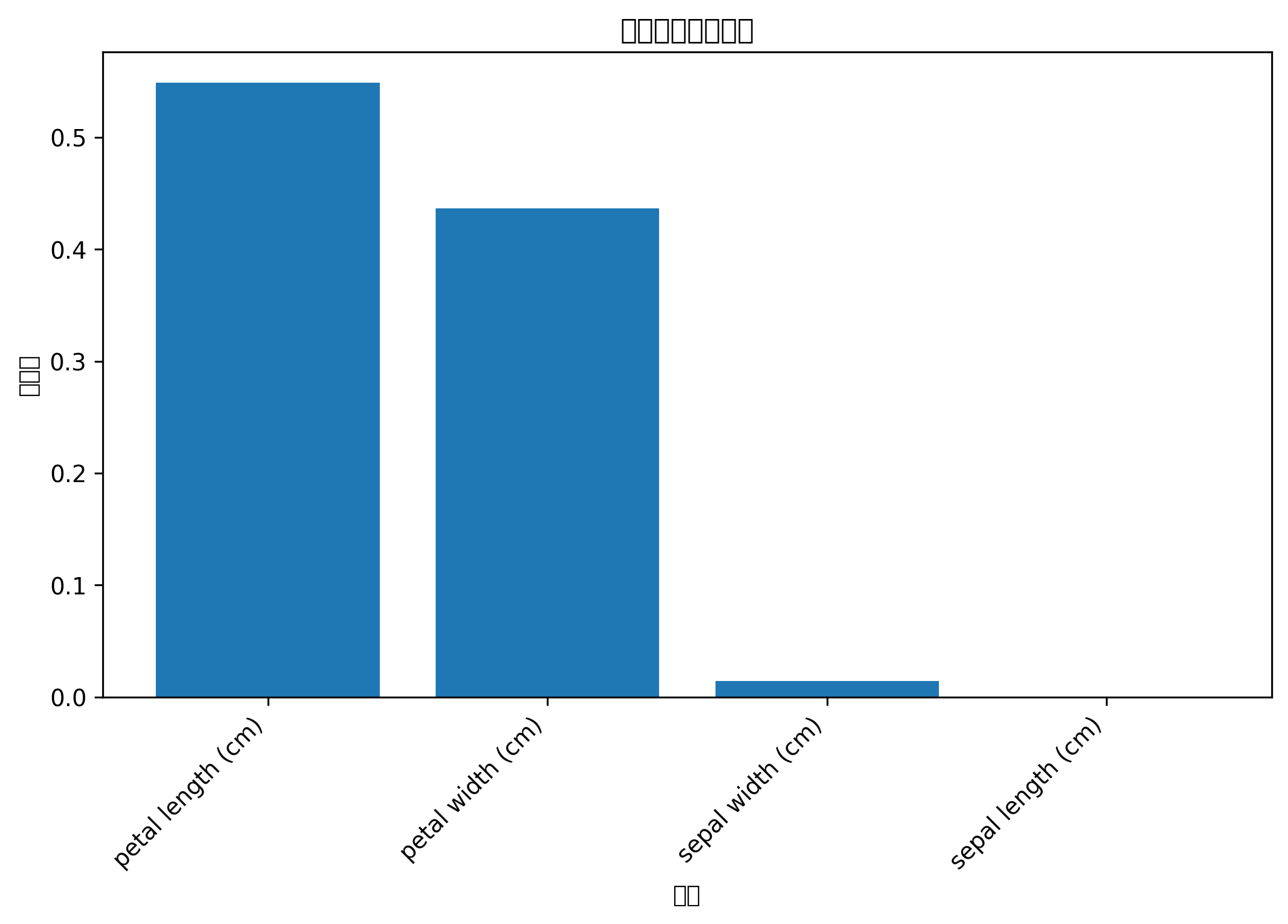
特征重要性条形图可以告诉你,模型主要依赖哪些变量做判断。
如果某个特征重要性很高,说明它对分类结果影响较大,可以在论文或报告中重点分析。
和其他算法的区别
随机森林比单棵决策树更稳定,不容易过拟合。
它不像 Boosting 那样一轮一轮纠错,而是多棵树并行训练,再进行投票或平均。
如果你想要稳健结果,随机森林很适合;如果你想冲击更高精度,Boosting 往往更强。
6. 朴素贝叶斯:什么时候使用 Naive Bayes?
算法直觉
朴素贝叶斯是一个非常适合文本分类的算法。它的基本思想是:根据词语出现情况,计算某段文本属于某一类的概率。
比如一句评论是“这个产品很好用,物流也快”,模型会根据“好用”“快”等词更常出现在正面评论中,判断它更可能是正面情感。
它叫“朴素”,不是因为算法低级,而是因为它做了一个强假设:在给定类别的条件下,各个特征之间相互独立。
核心公式
贝叶斯公式为:
其中,表示在看到特征
后,样本属于类别
的概率;
表示类别为
时出现特征
的概率;
表示类别先验概率;
表示特征出现的总体概率。
文本分类中,可以看作一组词语特征:
这个乘积形式就来自条件独立假设。
适合什么时候用
朴素贝叶斯特别适合文本分类、垃圾邮件识别、评论情感分析、新闻分类等高维稀疏数据。
文本数据中,词表可能有几千甚至几万个词,但每篇文章只包含其中一小部分词。朴素贝叶斯在这种场景下训练快、效果稳,是很好的基线模型。
不适合什么时候用
如果特征之间存在很强的相关关系,且这种相关性对判断非常重要,朴素贝叶斯的独立性假设就会限制模型效果。
典型应用场景
垃圾邮件识别、新闻分类、评论情感分析、舆情文本分类、商品评价分类。
Python 代码示例:CountVectorizer + MultinomialNB 文本分类
texts = [
"这个产品很好用 物流很快",
"质量不错 用起来很舒服",
"体验很好 下次还会购买",
"非常满意 推荐购买",
"产品太差了 物流也慢",
"质量不好 使用体验很差",
"非常失望 不会再买",
"包装破损 客服态度差"
]
labels = np.array([1, 1, 1, 1, 0, 0, 0, 0]) # 1 表示正面,0 表示负面
vectorizer = CountVectorizer()
X_text = vectorizer.fit_transform(texts)
nb = MultinomialNB()
nb.fit(X_text, labels)
test_texts = [
"物流很快 产品不错",
"质量太差 非常失望"
]
X_test_text = vectorizer.transform(test_texts)
pred_text = nb.predict(X_test_text)
prob_text = nb.predict_proba(X_test_text)
for text, pred, prob in zip(test_texts, pred_text, prob_text):
print("文本:", text)
print("预测类别:", "正面" if pred == 1 else "负面")
print("预测概率:", prob)
print("-" * 30)图表建议
文本分类中可以画词频柱状图、混淆矩阵、不同模型准确率对比图。对于初学项目,推荐先画“正面评论和负面评论的高频词对比”。
和其他算法的区别
朴素贝叶斯比 SVM、Boosting 更简单,训练速度很快。
在小规模文本数据上,它经常能给出不错的基线结果。
但如果数据量充足、特征工程更完善,SVM、逻辑回归或深度学习模型可能进一步提升效果。
7. 线性回归:什么时候使用 Linear Regression?
算法直觉
线性回归用于预测连续值。它假设目标变量可以由多个特征线性组合得到。
比如用面积、房龄、楼层预测房价;用温度、节假日、促销活动预测销量;用工业排放、人口密度、气象因素预测空气质量指数。如果变量之间存在近似线性关系,线性回归就是非常好的起点。
核心公式
线性回归模型为:
其中, 是连续型目标变量,
是特征,
是截距项,
表示各特征的回归系数,
是误差项。
模型训练的目标通常是最小化残差平方和:
其中,$y_i$ 是真实值,$\hat{y}_i$ 是预测值。残差越小,模型拟合越好。
适合什么时候用
线性回归适合预测连续值,并且自变量和因变量之间存在近似线性关系的任务。它非常适合作为回归问题的基线模型,也适合需要解释变量影响方向和影响大小的论文场景。
不适合什么时候用
线性回归对异常值敏感。少数极端值可能明显改变回归线。
如果特征之间存在严重多重共线性,回归系数会不稳定。
如果真实关系明显非线性,线性回归预测效果可能有限。
典型应用场景
房价预测、销量预测、能耗预测、空气质量指数预测、经济指标预测、实验数据拟合。
Python 代码示例:真实值 vs 预测值,并输出 MAE、MSE、R²
lin_reg = LinearRegression()
lin_reg.fit(X_train_reg, y_train_reg)
y_pred_reg = lin_reg.predict(X_test_reg)
mae = mean_absolute_error(y_test_reg, y_pred_reg)
mse = mean_squared_error(y_test_reg, y_pred_reg)
r2 = r2_score(y_test_reg, y_pred_reg)
print("线性回归 MAE:", round(mae, 3))
print("线性回归 MSE:", round(mse, 3))
print("线性回归 R²:", round(r2, 3))
print("回归系数:", lin_reg.coef_)
print("截距:", lin_reg.intercept_)
plt.figure(figsize=(6, 5))
plt.scatter(y_test_reg, y_pred_reg, edgecolor="k")
plt.plot(
[y_test_reg.min(), y_test_reg.max()],
[y_test_reg.min(), y_test_reg.max()],
linestyle="--"
)
plt.title("线性回归:真实值 vs 预测值")
plt.xlabel("真实值")
plt.ylabel("预测值")
plt.show()图表怎么看
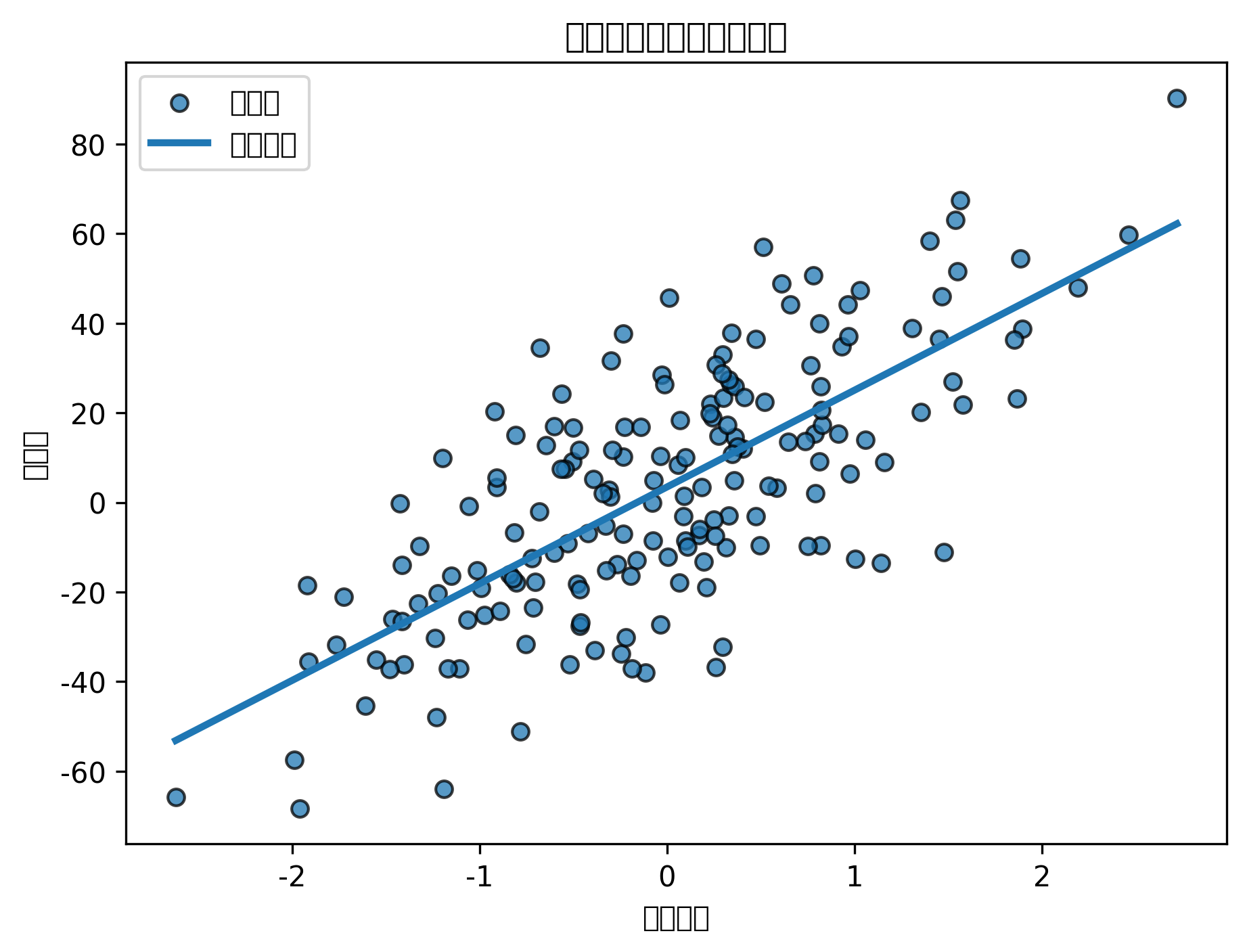
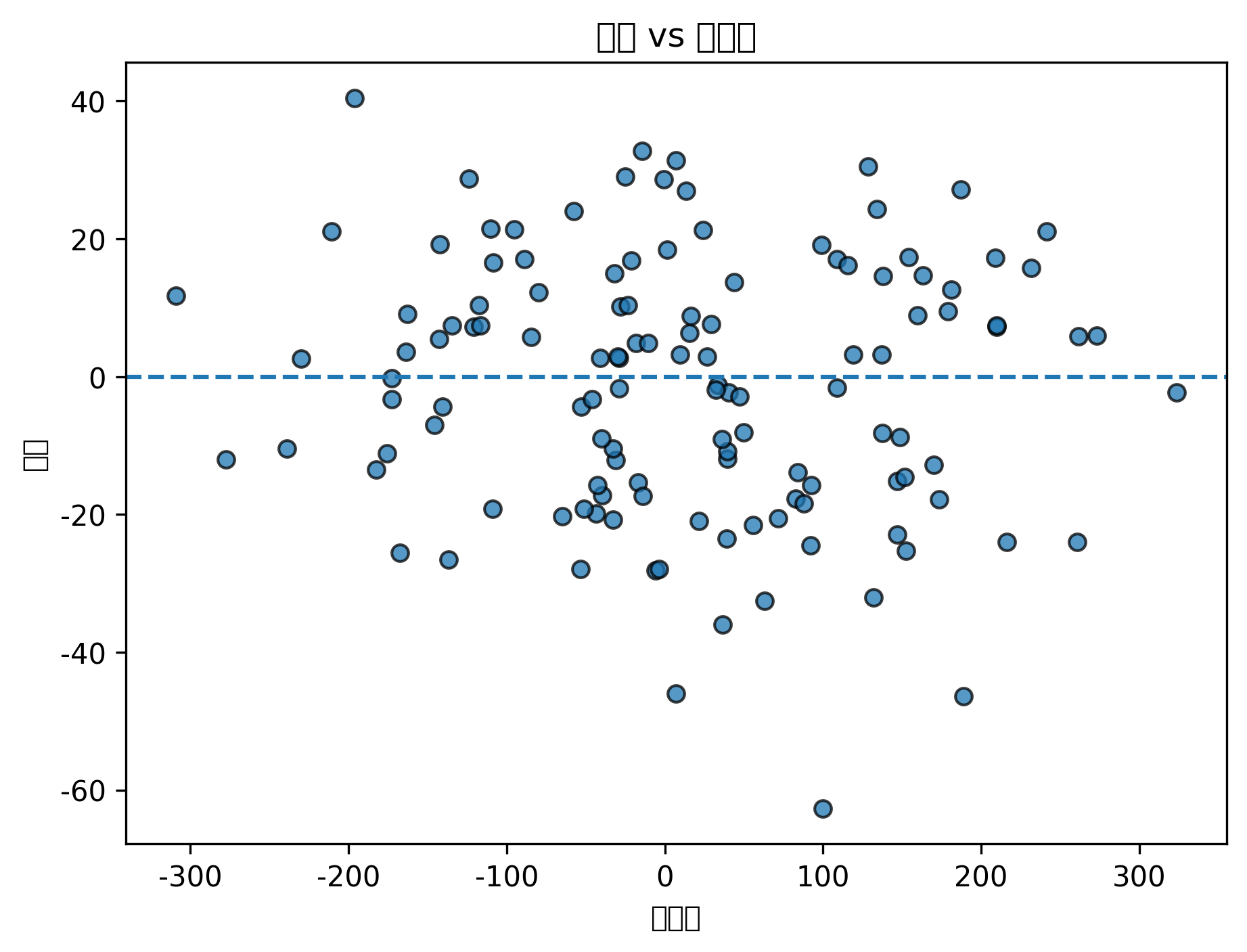
真实值 vs 预测值散点图中,点越接近对角线,说明预测越准确。
如果点系统性偏离对角线,说明模型可能漏掉了非线性关系或重要变量。
和其他算法的区别
线性回归比随机森林回归、Boosting 回归更简单,也更容易解释。
但它不擅长复杂非线性关系。如果只是想得到高预测精度,树模型集成方法通常更强。
8. SVM:什么时候使用支持向量机?
算法直觉
SVM 的核心思想是:找到一条尽可能宽的分界线,把不同类别分开。
在二维空间中,这条分界线是一条直线;在高维空间中,它是一个超平面。SVM 不只是随便找一条能分开的线,而是希望这条线离两边最近样本都尽可能远。这个“距离”就是间隔。
离分界线最近的那些关键样本,叫支持向量。
核心公式
线性 SVM 的约束可以写成:
其中,是样本特征,
是类别标签,
是超平面法向量,
是偏置项。
SVM 希望最大化分类间隔,等价于最小化:
如果数据不是线性可分,可以使用核函数。常见的 RBF 核为:
其中,控制单个样本影响范围。
越大,模型边界可能越复杂。
适合什么时候用
SVM 适合中小规模数据、高维数据、类别边界清晰但可能非线性的分类任务。
在样本量不大、特征维度较高的场景中,SVM 经常有不错表现。
不适合什么时候用
SVM 在大规模数据上训练可能较慢。
它对参数 $C$、$\gamma$ 和核函数选择比较敏感。
此外,SVM 的可解释性不如逻辑回归和决策树。
典型应用场景
小样本分类、高维文本分类、图像特征分类、生物医学分类、复杂边界二分类。
Python 代码示例:RBF 核 SVM 分类边界
svm = SVC(kernel="rbf", C=1.0, gamma="scale", probability=True, random_state=42)
svm.fit(X_train_cls_scaled, y_train_cls)
y_pred_svm = svm.predict(X_test_cls_scaled)
acc_svm = accuracy_score(y_test_cls, y_pred_svm)
print("SVM 准确率:", round(acc_svm, 3))
plot_decision_boundary(
svm,
X_train_cls_scaled,
y_train_cls,
title="RBF 核 SVM 分类边界"
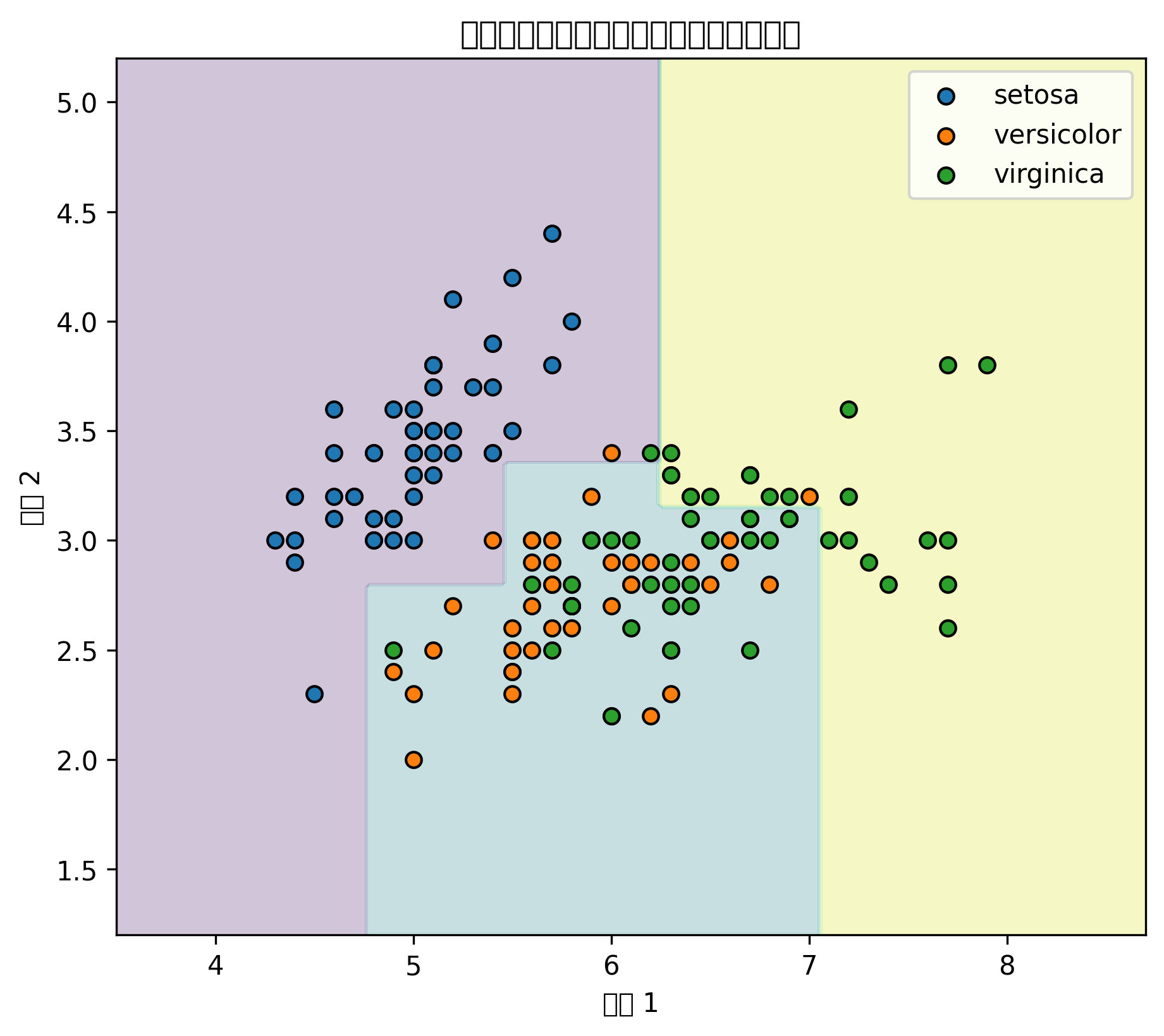
)图表怎么看
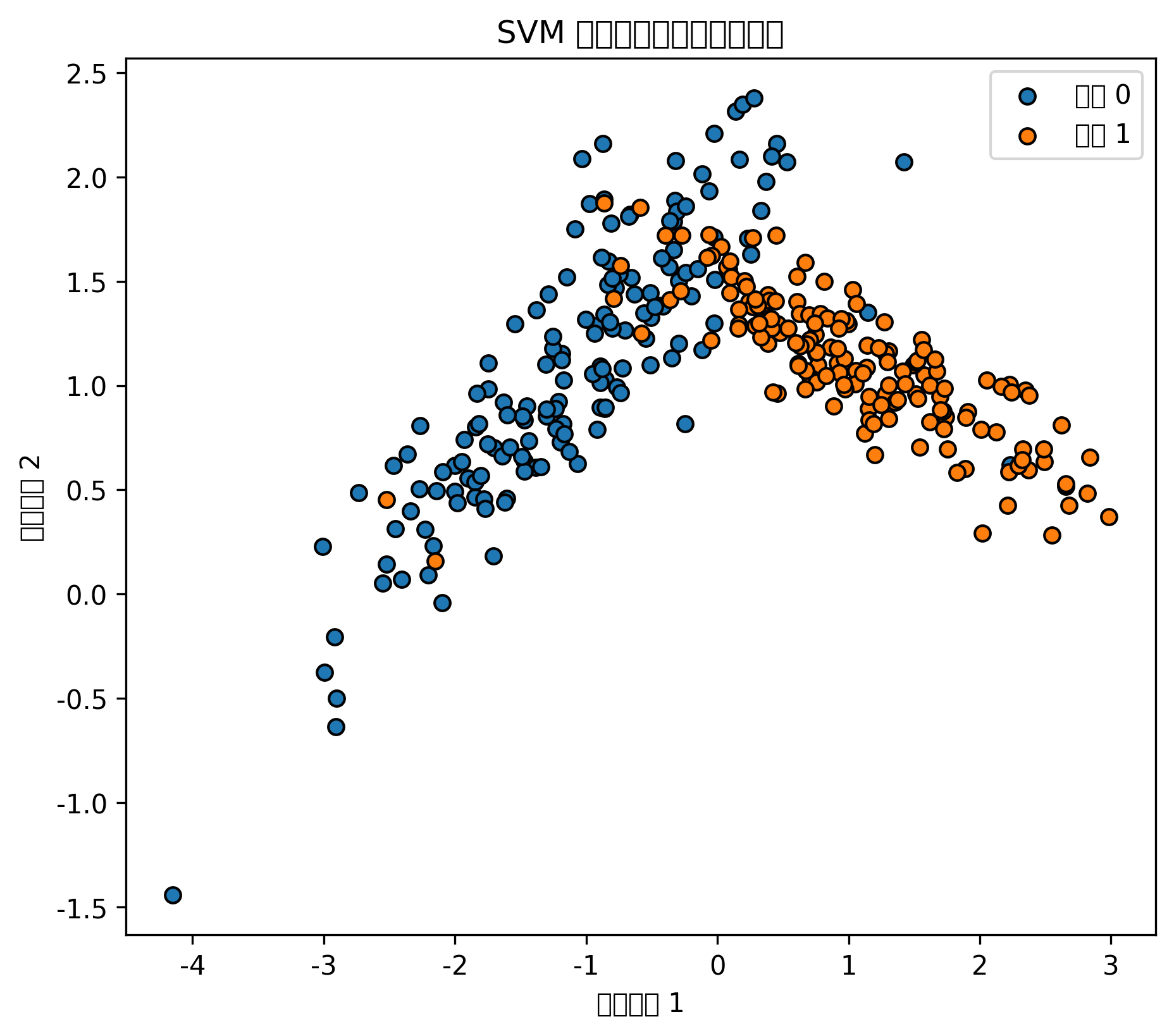
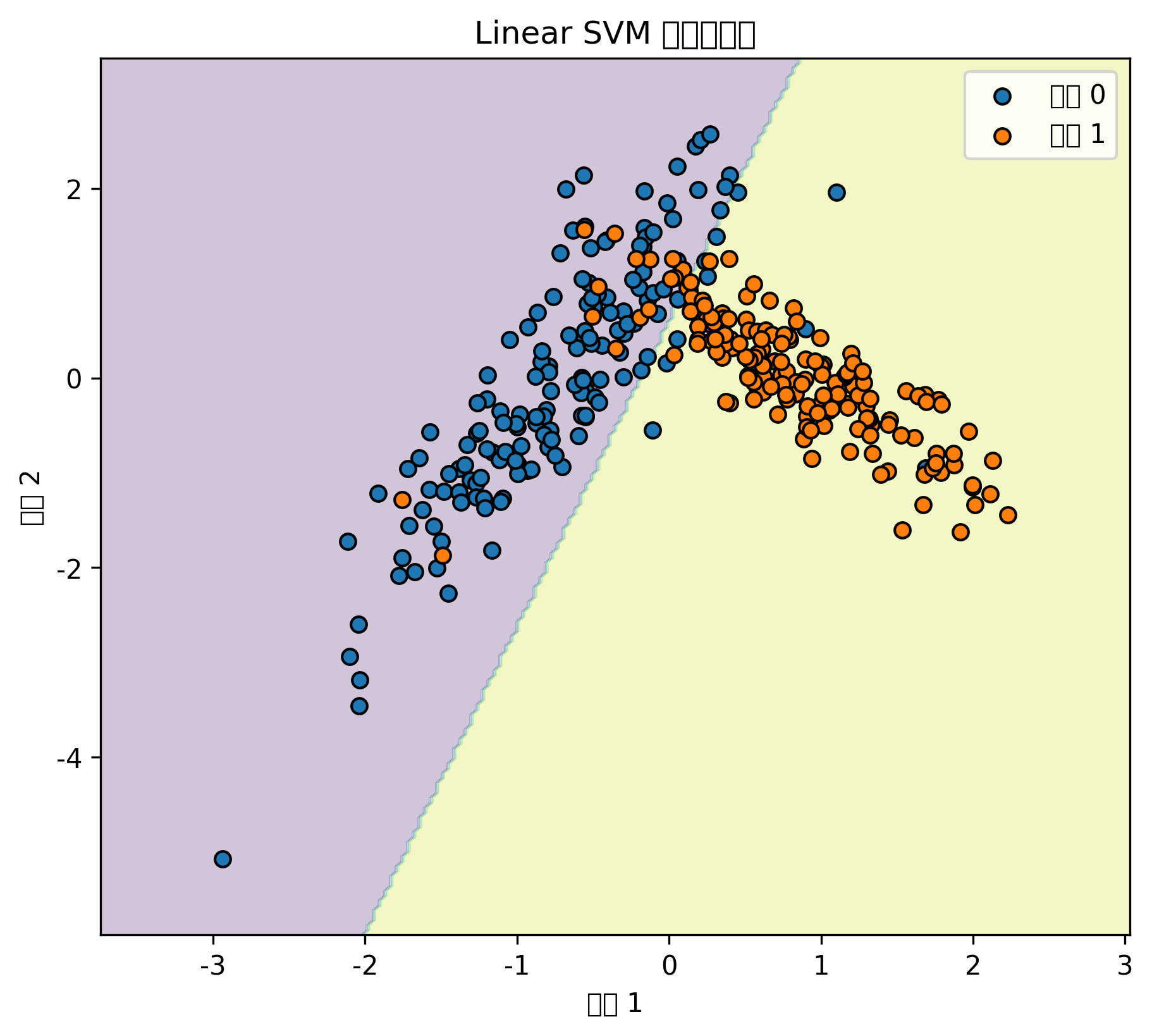
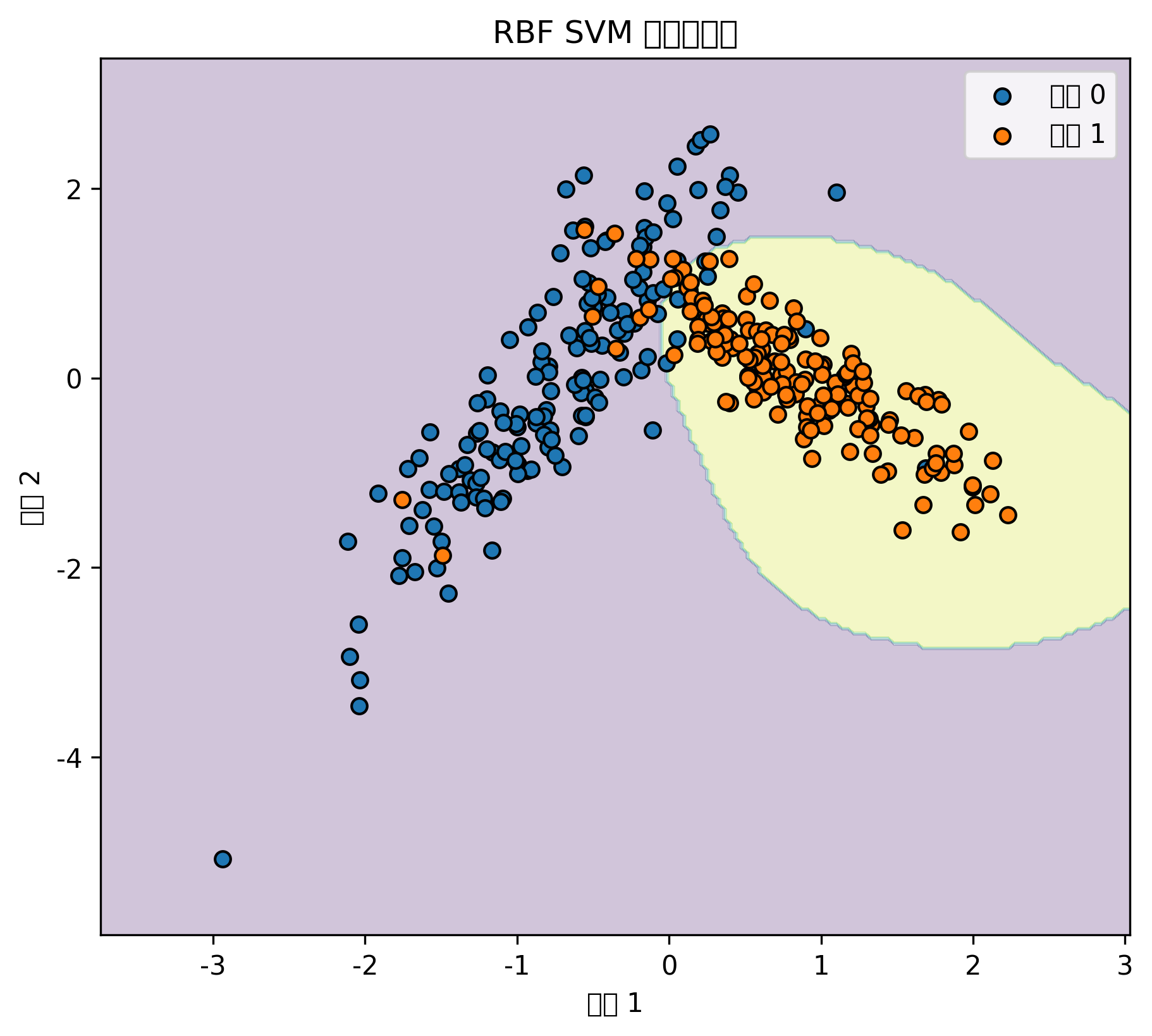
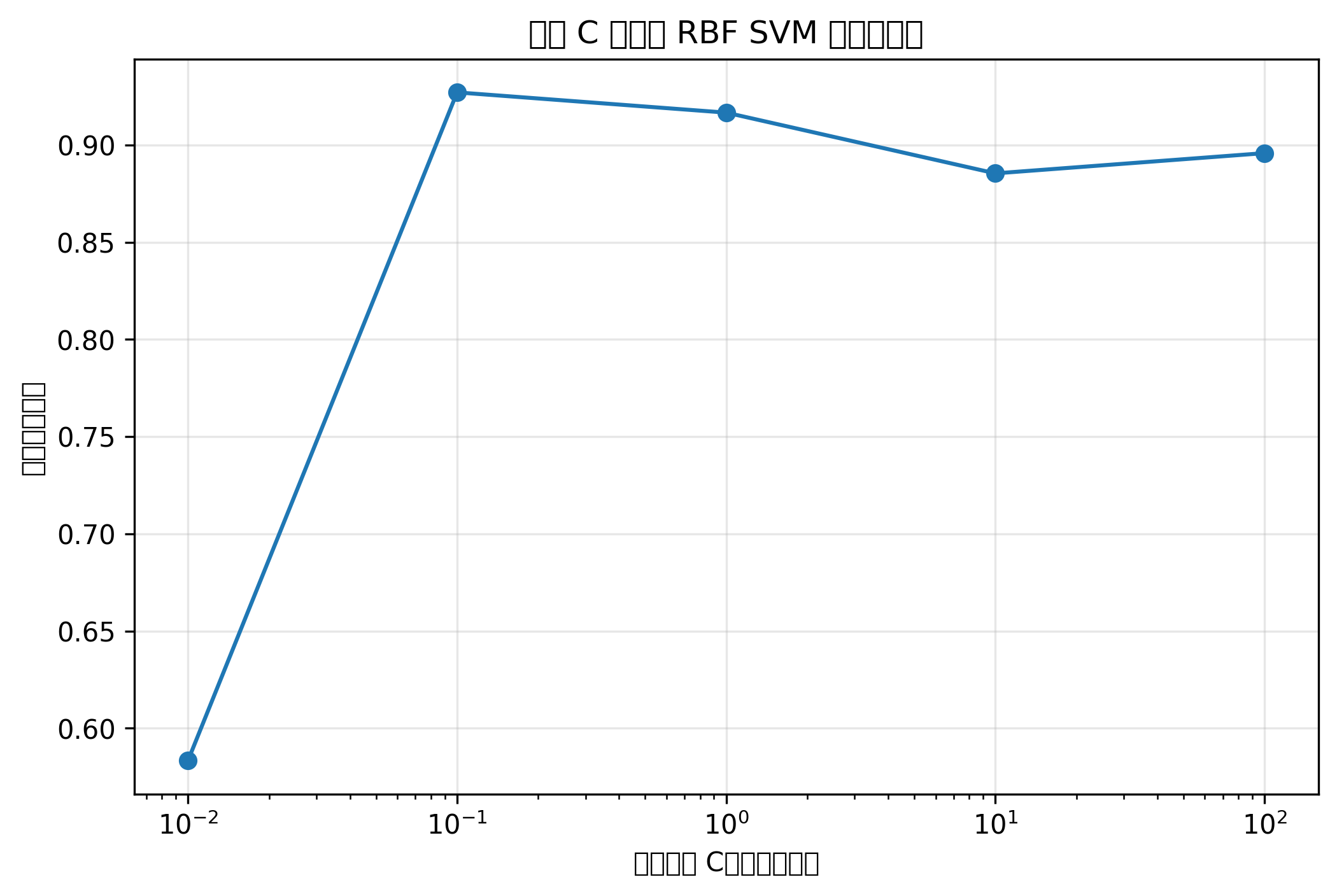
SVM 的分类边界通常比逻辑回归更灵活。
使用 RBF 核后,它可以处理弯曲边界,但参数过强时也可能过拟合。
和其他算法的区别
SVM 比逻辑回归更适合非线性边界。
相比 KNN,SVM 训练后预测更依赖支持向量,不需要每次都和所有训练样本比较。
相比随机森林和 Boosting,SVM 在表格大数据上的使用频率略低,但在中小样本高维分类中仍然很有价值。
9. Boosting:什么时候使用提升算法?
算法直觉
Boosting 的思想是:多个弱学习器逐步纠错。
它不像随机森林那样让很多树相对独立地投票,而是一轮接一轮地训练模型。后面的模型会重点关注前面模型预测不好的样本。这样不断迭代后,多个弱模型组合成一个强模型。
常见 Boosting 算法包括 AdaBoost、Gradient Boosting、XGBoost、LightGBM、CatBoost 等。为了不依赖外部库,这里使用 sklearn 的 GradientBoostingClassifier。
核心公式
Boosting 可以理解为加法模型:
其中,是第
个弱学习器,
是它的权重,
是弱学习器数量。
梯度提升的思想是,每一步都拟合当前损失函数的负梯度方向:
其中,是学习率,控制每一步更新的幅度。学习率越小,通常需要更多树,但模型可能更稳。
适合什么时候用
Boosting 适合追求高精度的分类或回归任务,尤其适合数学建模比赛、数据挖掘竞赛和复杂表格数据预测。
如果你的目标是把准确率、AUC、F1 或 R² 尽量提高,Boosting 往往是重要候选模型。
不适合什么时候用
Boosting 参数较多,调参成本更高。
如果学习器太多、树太深、学习率不合理,模型可能过拟合。
数据噪声很大时,Boosting 也可能反复学习噪声样本。
典型应用场景
比赛建模、信用评分、销量预测、用户流失预测、广告点击率预测、风险预警。
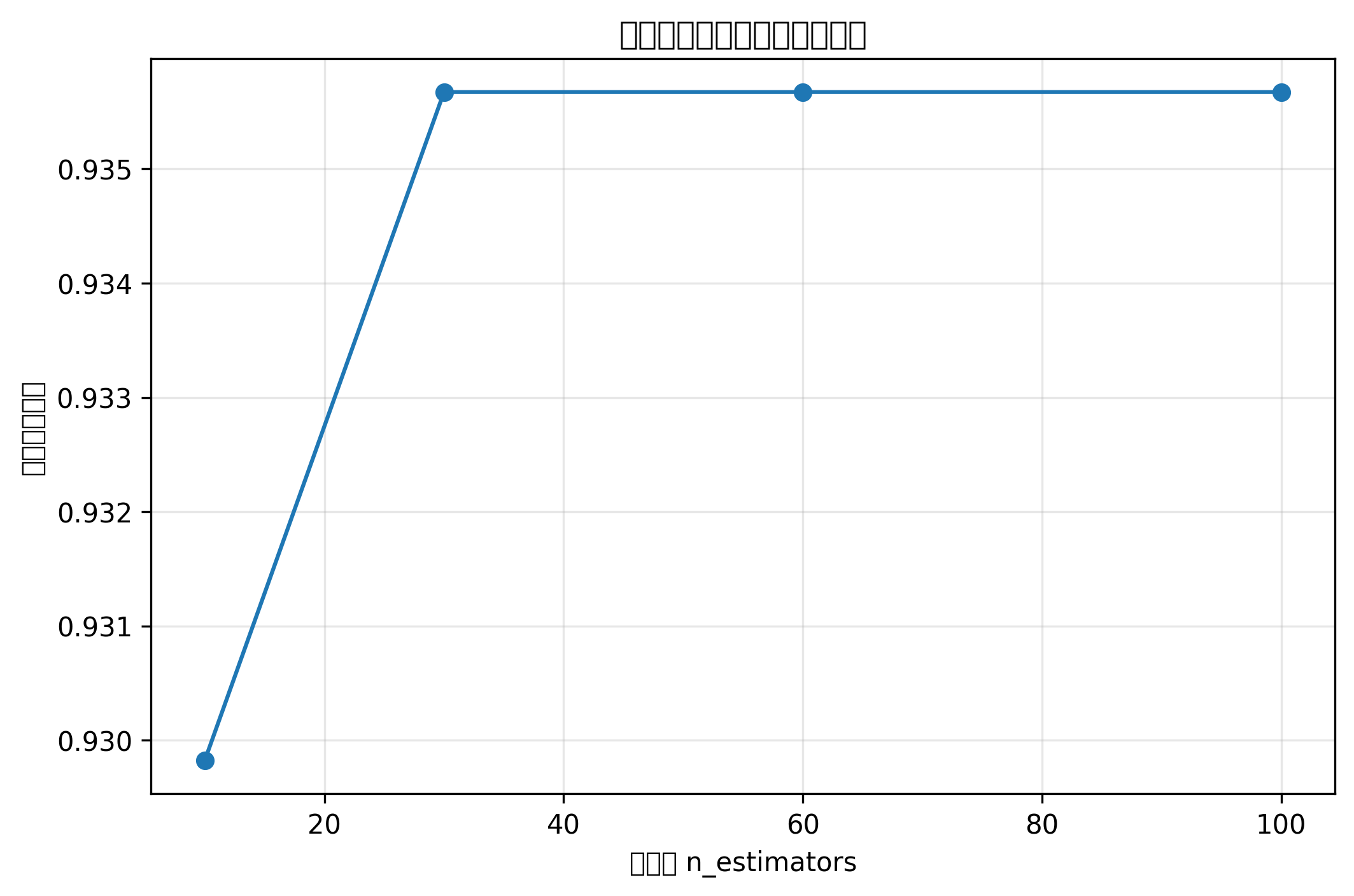
Python 代码示例:多模型准确率对比柱状图
models = {
"逻辑回归": LogisticRegression(max_iter=1000),
"KNN": KNeighborsClassifier(n_neighbors=5),
"决策树": DecisionTreeClassifier(max_depth=4, random_state=42),
"随机森林": RandomForestClassifier(n_estimators=200, max_depth=5, random_state=42),
"SVM": SVC(kernel="rbf", C=1.0, gamma="scale"),
"Boosting": GradientBoostingClassifier(random_state=42)
}
accuracies = {}
for name, model in models.items():
# KNN、逻辑回归、SVM 对标准化更敏感;树模型不强制要求标准化
if name in ["逻辑回归", "KNN", "SVM"]:
model.fit(X_train_cls_scaled, y_train_cls)
pred = model.predict(X_test_cls_scaled)
else:
model.fit(X_train_cls, y_train_cls)
pred = model.predict(X_test_cls)
acc = accuracy_score(y_test_cls, pred)
accuracies[name] = acc
print(f"{name} 准确率: {acc:.3f}")
plt.figure(figsize=(8, 5))
plt.bar(accuracies.keys(), accuracies.values())
plt.title("不同分类模型准确率对比")
plt.xlabel("模型")
plt.ylabel("准确率")
plt.ylim(0, 1)
plt.xticks(rotation=30)
plt.show()图表怎么看
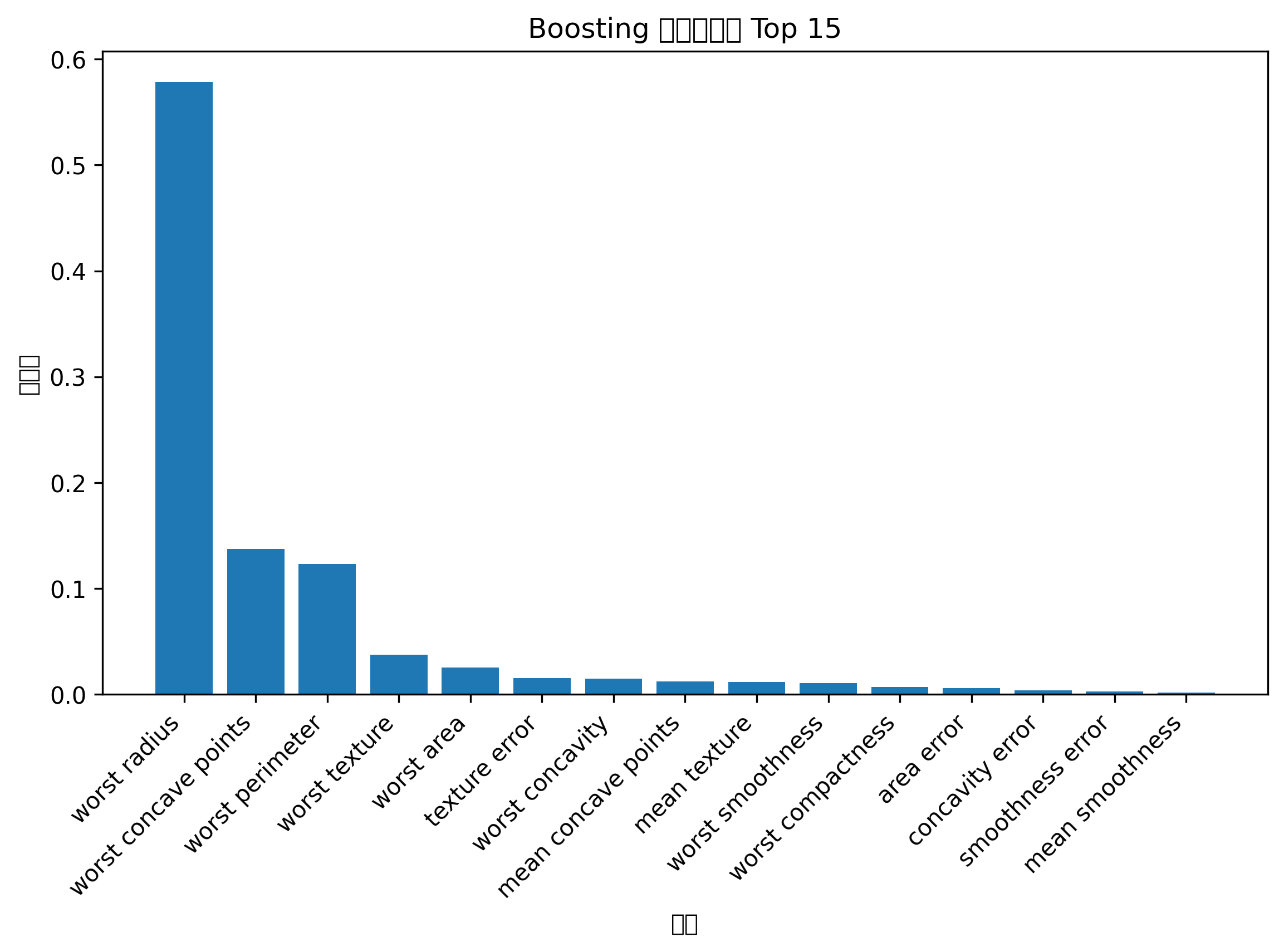
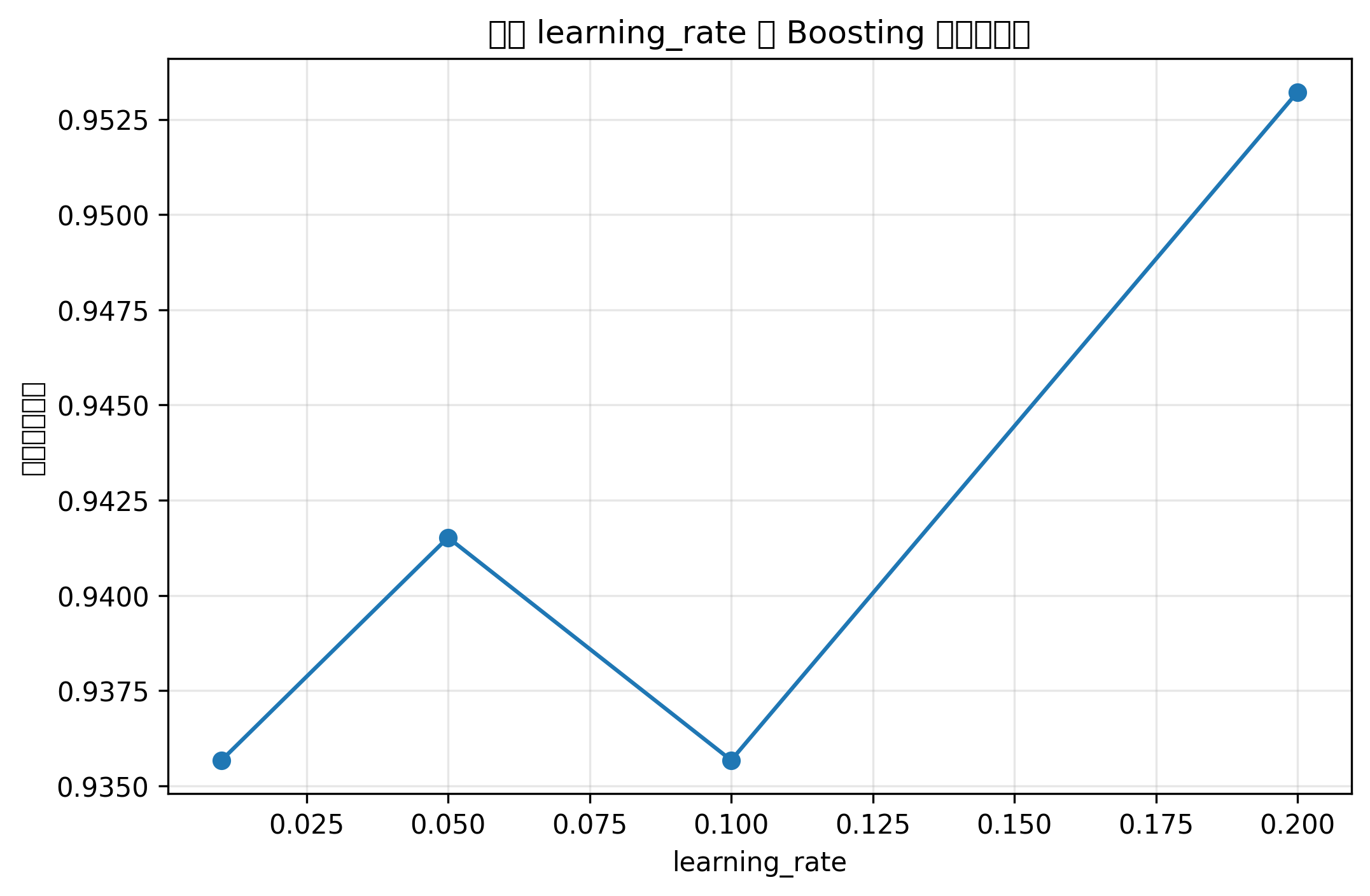
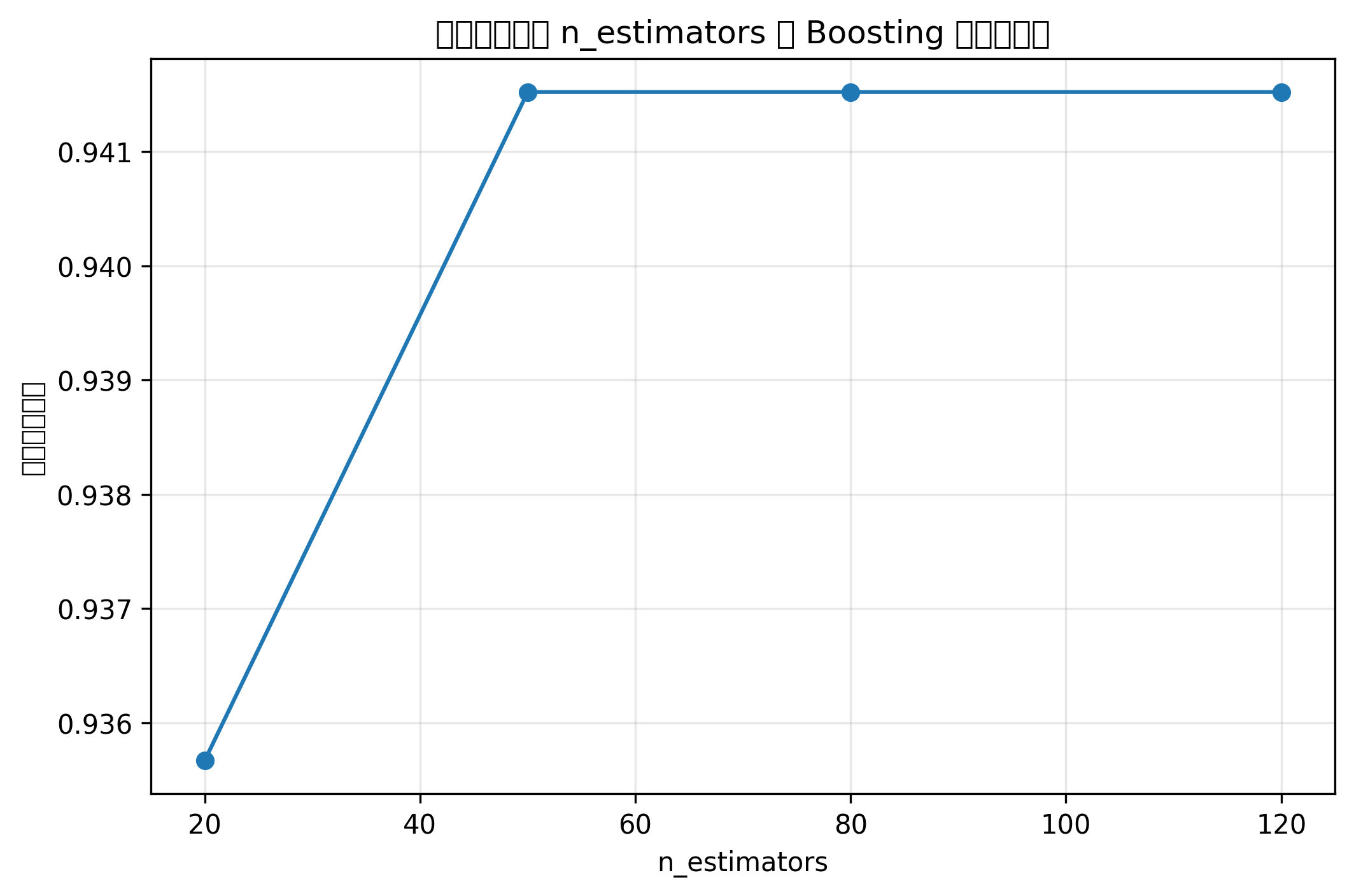
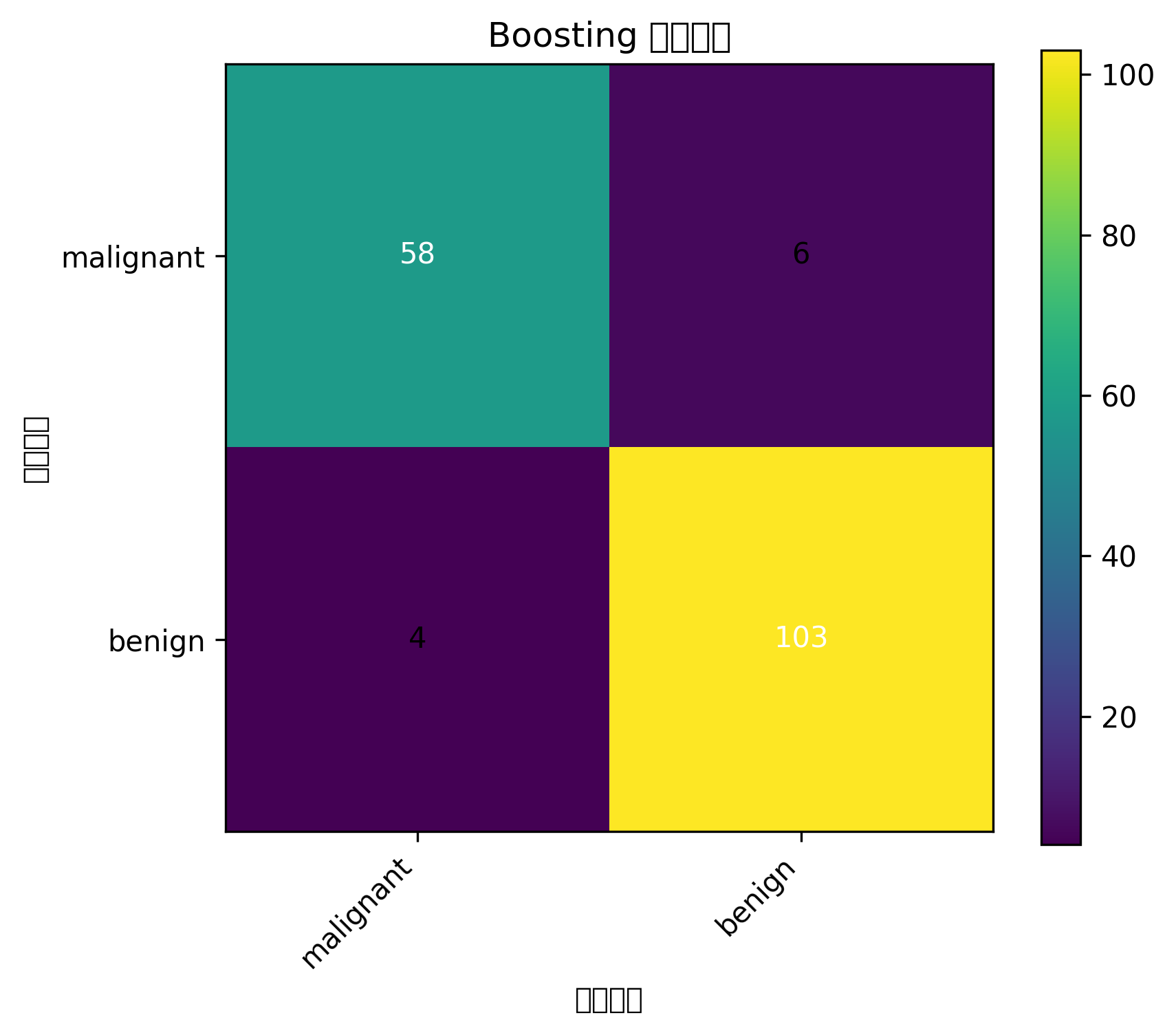
准确率对比柱状图能快速判断不同模型在当前数据集上的表现。
但注意,不能只看一次随机划分结果。正式建模中建议使用交叉验证,并结合 AUC、F1、召回率等指标综合判断。
和其他算法的区别
Boosting 和随机森林都属于集成学习,但思想不同。
随机森林是多棵树并行投票,偏向降低方差;Boosting 是模型逐步纠错,偏向降低偏差。
在很多结构化数据任务中,Boosting 的上限更高,但也更依赖调参。
10. LDA:什么时候使用线性判别分析?
算法直觉
LDA 有两个常见用途:分类和降维。
它的核心思想是:把数据投影到一个方向上,让同一类样本尽量靠近,不同类样本尽量分开。
也就是说,LDA 不是单纯保留数据方差,而是利用标签信息寻找最有利于分类的投影方向。
核心公式
LDA 的目标可以写为:
其中, 是类间散度矩阵,表示不同类别中心之间分得有多开;
是类内散度矩阵,表示同一类别内部有多分散;
是投影方向。
LDA 希望最大化,也就是让类间差异尽量大、类内差异尽量小。
适合什么时候用
LDA 适合类别之间近似线性可分、各类别协方差相近的场景。
当你既想做分类,又想把高维数据降到二维进行可视化时,LDA 很有用。
不适合什么时候用
如果类别边界强非线性,LDA 的效果可能不如 SVM、随机森林和 Boosting。
如果不同类别的协方差结构差异很大,LDA 的假设也可能不太合适。
典型应用场景
小样本分类、医学分类、降维可视化、模式识别、分类前特征压缩。
Python 代码示例:LDA 二维降维后的分类散点图
# 构造一个 3 类、较高维的数据,便于 LDA 降到二维
X_lda_data, y_lda_data = make_classification(
n_samples=500,
n_features=6,
n_informative=4,
n_redundant=0,
n_classes=3,
n_clusters_per_class=1,
class_sep=1.5,
random_state=42
)
X_train_lda, X_test_lda, y_train_lda, y_test_lda = train_test_split(
X_lda_data, y_lda_data, test_size=0.3, random_state=42, stratify=y_lda_data
)
scaler_lda = StandardScaler()
X_train_lda_scaled = scaler_lda.fit_transform(X_train_lda)
X_test_lda_scaled = scaler_lda.transform(X_test_lda)
lda = LinearDiscriminantAnalysis(n_components=2)
X_train_lda_2d = lda.fit_transform(X_train_lda_scaled, y_train_lda)
X_test_lda_2d = lda.transform(X_test_lda_scaled)
y_pred_lda = lda.predict(X_test_lda_scaled)
acc_lda = accuracy_score(y_test_lda, y_pred_lda)
print("LDA 分类准确率:", round(acc_lda, 3))
plt.figure(figsize=(6, 5))
plt.scatter(
X_train_lda_2d[:, 0],
X_train_lda_2d[:, 1],
c=y_train_lda,
edgecolor="k",
s=35
)
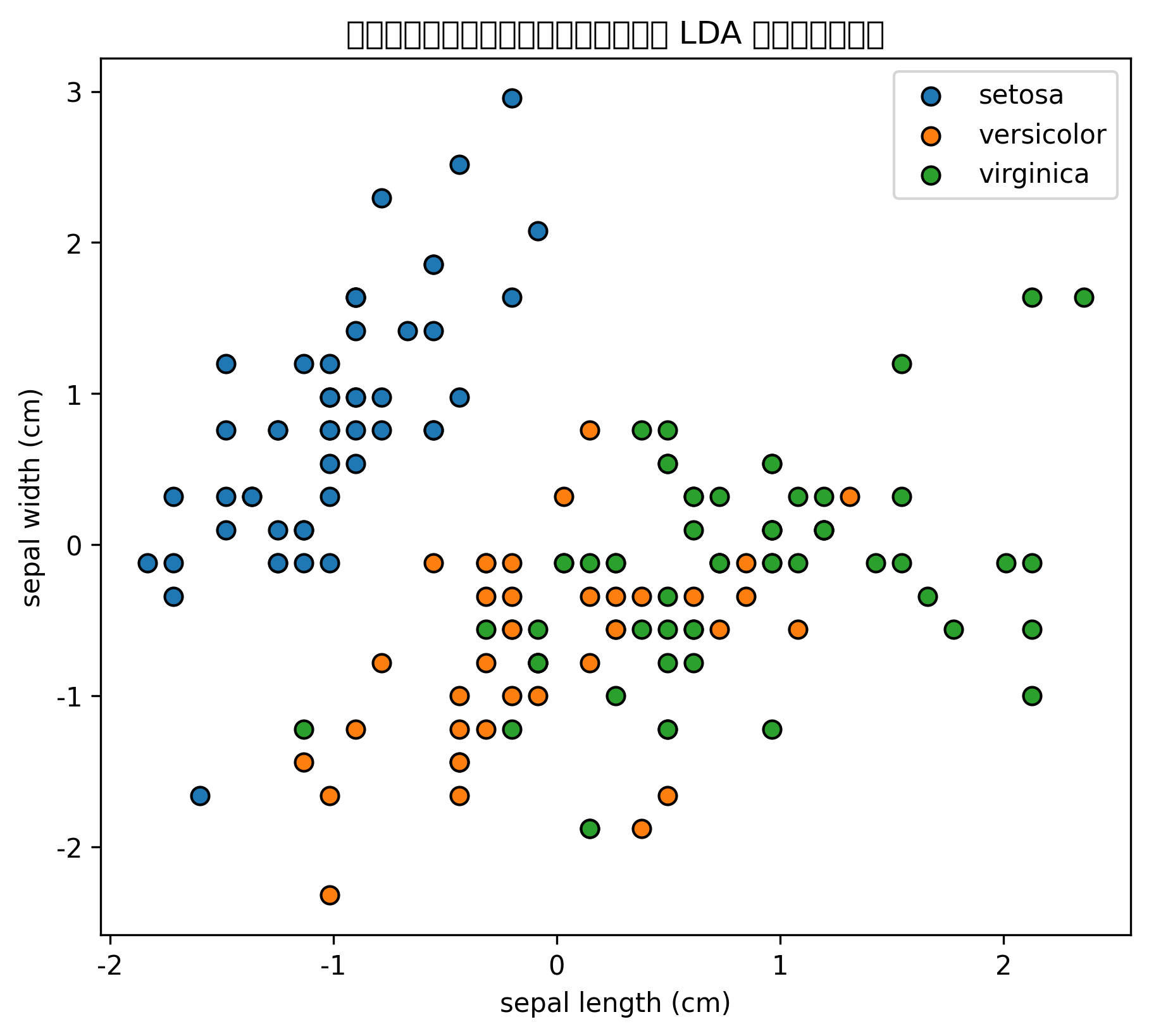
plt.title("LDA 二维降维可视化")
plt.xlabel("LDA 方向 1")
plt.ylabel("LDA 方向 2")
plt.show()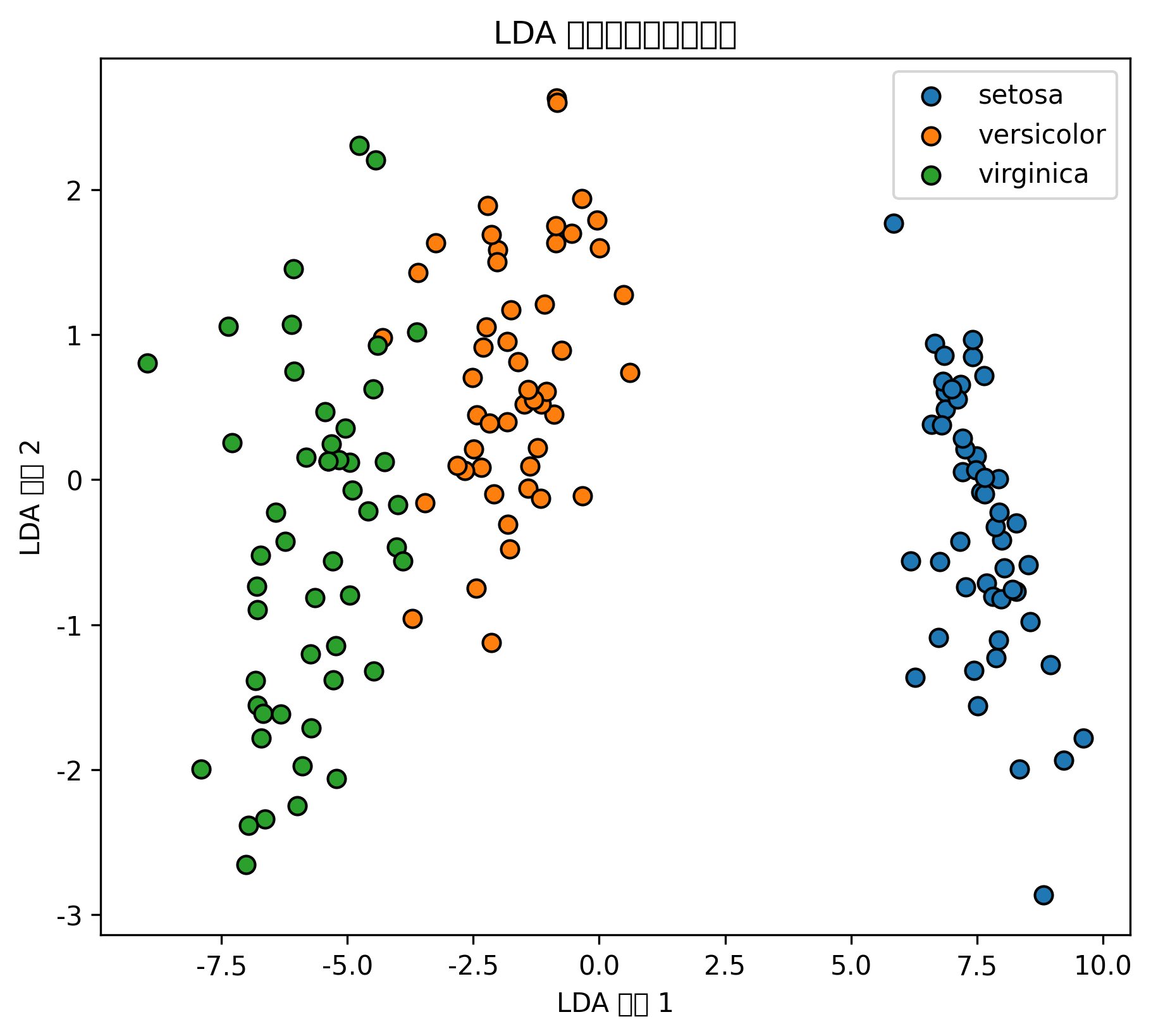
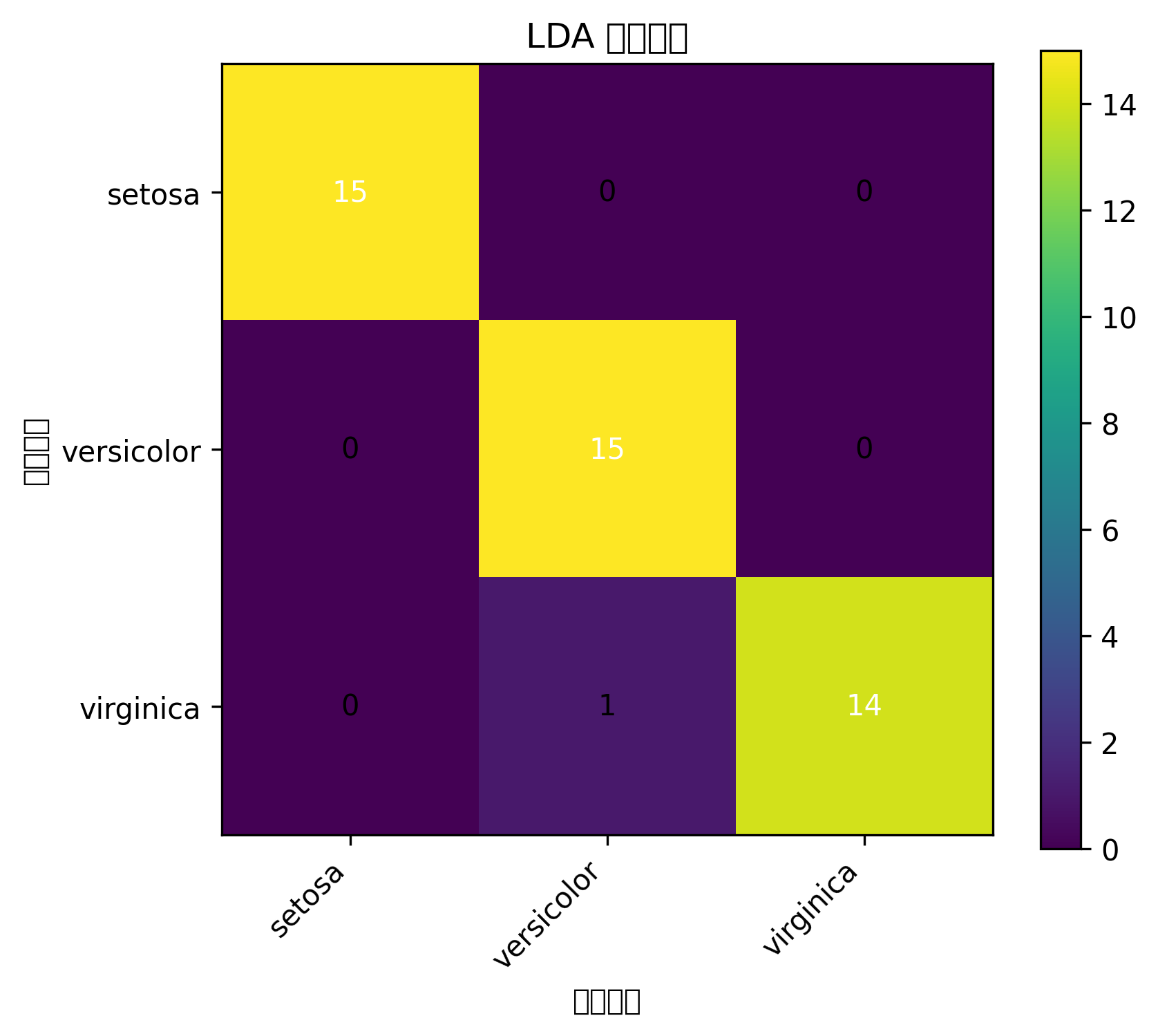
DA 和 PCA 的区别
PCA 是无监督降维,不看标签,只关心数据整体方差最大。
LDA 是有监督降维,会使用类别标签,目标是让类别更容易分开。
简单说:
| 方法 | 是否使用标签 | 目标 |
|---|---|---|
| PCA | 不使用 | 保留最大方差 |
| LDA | 使用 | 最大化类别区分度 |
和其他算法的区别
LDA 比逻辑回归更强调类别分布结构,也可以作为降维方法。
它比随机森林、Boosting 更简单,但对数据分布假设更强。
如果数据近似线性可分,LDA 很干净;如果边界复杂,它通常不是最强选择。
五、把这些图表放进一篇建模博客里,应该怎么安排?
如果你要把本文内容整理成数学建模博客或项目复盘,可以这样安排图表:
| 图表 | 作用 |
|---|---|
| 算法选择总览表 | 快速说明不同算法适合什么任务 |
| 算法选择流程图 | 展示从数据特征到模型选择的判断逻辑 |
| KNN 不同 k 值分类边界 | 解释过拟合与欠拟合 |
| 逻辑回归混淆矩阵 | 展示分类结果具体错在哪里 |
| ROC 曲线 | 展示二分类模型区分能力 |
| 决策树结构图 | 展示模型规则和可解释性 |
| K-Means 聚类图 | 展示无标签数据的分群结果 |
| 肘部法则图 | 解释如何选择聚类数量 K |
| 随机森林特征重要性图 | 解释哪些变量更重要 |
| 线性回归真实值 vs 预测值 | 判断回归预测是否贴近真实值 |
| 多模型准确率柱状图 | 对比不同算法在同一任务上的表现 |
| LDA 二维降维散点图 | 展示类别在低维空间中的可分性 |
六、算法选择速查表
| 建模情况 | 优先考虑的算法 |
|---|---|
| 没有标签,想分群 | K-Means |
| 连续值预测 | 线性回归、随机森林回归、Boosting 回归 |
| 二分类且要解释 | 逻辑回归 |
| 规则清晰且要解释 | 决策树 |
| 文本分类 | 朴素贝叶斯 |
| 高维小样本分类 | SVM |
| 追求稳定效果 | 随机森林 |
| 追求比赛精度 | Boosting |
| 分类加降维 | LDA |
| 小数据、边界复杂 | KNN |
七、最后怎么记?
机器学习算法没有绝对最优,只有在具体数据、具体任务和具体评价指标下更合适的选择。
拿到数据集后,不要急着套模型。先判断有没有标签,再判断目标变量是类别还是连续值,再看数据规模、特征维度、线性关系、可解释性要求和精度要求。逻辑回归、线性回归和决策树适合解释;随机森林和 Boosting 适合复杂预测;K-Means 适合无标签分群;朴素贝叶斯适合文本;SVM 适合中小规模高维分类;LDA 适合分类与降维结合;KNN 适合小数据、边界复杂的直觉型建模。
真正成熟的建模思路,不是“我会多少算法”,而是:
我知道这个问题为什么该用这个算法,也知道它什么时候不该用。
需要代码的,请在评论区留言,制作不易,请给我看官老爷点个赞和收藏!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)