第55节:微调大模型的性能与能力评估【深入剖析评估框架 |评估内容与标准|评估的核心目标】2
文章目录
前言
在尝试大语言模型微调时,许多开发者都有过这样的经历:训练日志中的Loss值一路平滑下降,验证集的困惑度也在持续降低,满怀期待地导出模型进行测试,却发现回答要么答非所问,要么一本正经地“胡说八道”。这种“训练表现良好,实际表现糟糕”的落差,恰恰揭示了微调评估中最核心的命题:Loss下降不等于模型学会了有用的东西。
微调大模型的过程,可以类比为培养一名学生。训练阶段是“课堂教学”,而评估则是决定其能否“毕业上岗”的终极考试。无论是让客服机器人更懂行业术语,让代码助手更符合团队规范,还是让创作模型写出特定风格的文案,评估都是验证“模型是否真的变成了你想要的样子”的唯一标准。
本文的核心目标,是系统性地回答三个问题:
- 评估什么——从能力、性能、鲁棒性、合规性四个维度构建评估体系;
- 用什么评估——深度解析当前主流的评估框架和工具;
- 怎么评估——提供可直接运行的代码示例和操作指南。
在正式展开之前,需要明确一个基本立场:评估不是训练结束后的“验收环节”,而是贯穿整个模型开发周期的“反馈机制”。优秀的评估体系能够帮助开发者及早发现隐藏缺陷、精准定位优化方向、用数据替代主观判断,从而让AI项目从“玩具”走向“工具”。
第一章:大模型评估框架
1.1 评估框架的核心逻辑与构建原则
大模型评估框架是整个评估工作的“骨架”,其核心逻辑在于突破“单一指标片面性”的局限,构建一个覆盖能力、性能、鲁棒性、合规性等多个维度的综合评估体系。一个好的评估框架应遵循四项基本原则:
全面性:覆盖模型能力、性能、鲁棒性、合规性等多维度,不遗漏关键评估点。例如,仅评估准确率而忽略推理速度,可能导致模型在实际部署中因延迟过高而无法使用。
可量化:尽可能采用可量化指标,减少主观判断偏差,确保评估结果可复现。量化指标包括但不限于准确率、F1值、BLEU、ROUGE、推理延迟、显存占用等。
场景化:评估内容与微调目标、实际应用场景强绑定,避免“为评估而评估”。例如,面向医疗问答场景的微调模型,评估重点应当是医学知识准确性和术语规范性,而非通用对话的流畅度。
可落地:评估流程简洁、工具可获取,兼顾研发阶段的快速测试与落地前的全面核验。这意味着评估框架应当能够在不同环境(本地GPU、云端API、边缘设备)中运行,并产出具有可比性的结果。
1.2 评估框架的四层递进结构
一个完整的评估框架通常采用分层递进的结构设计,从基础准备到结果产出,形成闭环反馈机制。
第一层:基础层——评估准备
本层的核心工作是明确评估的目标和边界。具体包括:
- 明确微调目标:确认微调后模型的核心应用场景(如医疗问诊、金融分析)和核心任务(如文本分类、多轮对话、代码生成)。
- 准备测试数据集:构建独立的验证集与测试集,确保其与训练集无交集。数据集应覆盖常规场景、边界场景与异常场景,并保持数据的时效性和多样性。
- 确定评估工具与环境:根据评估维度选择适配工具,配置一致的软硬件环境(如GPU型号、推理框架),确保评估结果具有可比性。
第二层:核心层——多维度评估执行
本层是评估工作的主体,包含四个并行的评估子维度:
- 能力评估:聚焦模型“会不会做事、能不能做好事”,是评估的核心;
- 性能评估:聚焦模型“能不能高效做事”,决定模型工程化落地的可行性;
- 鲁棒性评估:聚焦模型“能不能稳定做事”,检验模型抗干扰能力和泛化性;
- 合规性评估:聚焦模型“能不能安全做事”,是模型落地的生命线。
四个维度缺一不可,且在不同应用场景中的权重各异。例如,自动驾驶场景中合规性和鲁棒性权重最高,而内容创作场景中能力评估的权重则更高。
第三层:结果层——指标汇总与分析
本层负责将各维度的评估结果汇总为可理解的指标和报告。具体工作包括:
- 指标计算(如准确率、F1值、推理速度);
- 可视化展示(如雷达图、对比柱状图);
- 问题归因(如“逻辑推理薄弱”“长文本生成易跑偏”)。
第四层:迭代层——反馈与优化
评估的最终目的是指导模型优化。本层将评估结果转化为具体的优化行动,如增加特定类型的训练数据、调整微调超参数、更换评估工具等,形成“评估—分析—优化—再评估”的闭环。
1.3 主流评估框架概览
在构建自己的评估体系之前,了解当前主流的评估框架有助于借鉴其设计思路。
HELM(Holistic Evaluation of Language Models) 由斯坦福大学CRFM团队开发,是目前最为全面的学术评估框架之一。HELM覆盖叙事问答、数学推理、法律文书、医学翻译等多个场景,使用经过充分验证的数据集和方法,并在不同模型版本间保持一致。HELM的核心理念是“广度与深度并重”,它不仅评估模型的准确性,还同时评估效率、鲁棒性、公平性等多个维度。
OpenCompass(司南) 由上海人工智能实验室开发,是国内最具影响力的开源大模型评测平台。OpenCompass支持超过20个Hugging Face和API模型、70多个数据集、约40万个问题,能够实现大语言模型和多模态模型的一站式评测。2025年,OpenCompass全面升级为“五位一体”的全景评估范式,从大模型评测扩展至AI计算系统、具身智能、安全可信及垂类行业应用等五大领域。
LLMEval-3 由复旦大学提出,是一个动态评估框架。与传统的静态基准不同,LLMEval-3建立在一个包含22万个研究生级问题的私有问题库上,为每次评估动态采样不可见的测试集,通过抗污染数据管理和校准的LLM-as-a-Judge过程确保评估完整性,与人类专家的一致性达到90%。LLMEval-3揭示了一个重要现象:所有模型在长期评估中趋向于约90%的表现上限,尤其在文学和医学等专业领域仍存在显著差距。
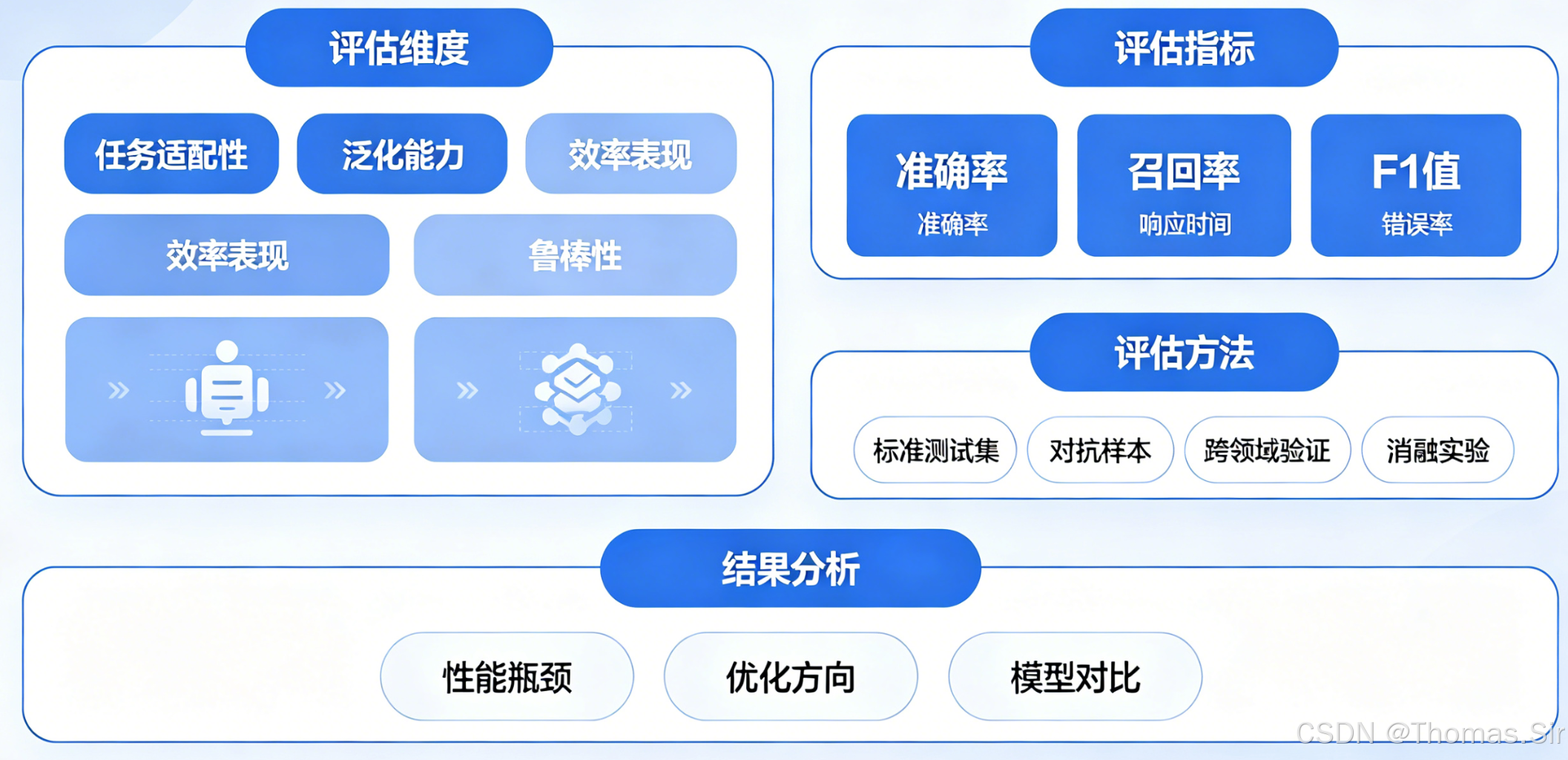
第二章:评估内容与标准
微调大模型的评估内容可以归纳为四个核心维度:能力评估、性能评估、鲁棒性评估和合规性评估。每个维度都有其特定的评估标准和量化指标。
2.1 能力评估——会不会做事
能力评估是评估体系的核心,关注模型在具体任务上的表现。根据任务类型的不同,能力评估又分为分类任务评估和生成任务评估两大类。
2.1.1 分类任务评估指标
分类任务的目标是让模型将输入归入正确的类别。常用的评估指标包括:
准确率(Accuracy) :最直观的指标,计算公式为(正确分类数)/(总样本数)。准确率简单易懂,但在样本不平衡的场景下可能存在“虚高”问题。例如,在90%好评、10%差评的评论数据中,一个全部预测为“好评”的模型也能达到90%的准确率,但这显然没有实际价值。
精确率(Precision)与召回率(Recall) :这两个指标针对特定类别进行深入分析。精确率衡量“模型说是正类的样本中,真正是正类的比例”,召回率衡量“真正的正类样本中,有多少被模型找出”。二者通常需要结合使用,单一指标无法全面反映模型表现。
F1值:精确率和召回率的调和平均值,计算公式为 F1 = 2 × (Precision × Recall) / (Precision + Recall)。F1值能够平衡精确率和召回率,尤其适合处理样本不平衡的任务。
混淆矩阵(Confusion Matrix) :以矩阵形式展示模型在各类别上的预测情况,能够直观地揭示模型在哪些类别上表现良好、哪些类别上容易出错。
2.1.2 生成任务评估指标
生成任务(如文本摘要、机器翻译、对话生成)的评估比分类任务更加复杂,因为答案并非唯一的。
BLEU(Bilingual Evaluation Understudy) :通过比较模型生成的文本与参考文本之间的n-gram重叠度来衡量生成质量。BLEU-4(即使用4-gram)是机器翻译和文本生成任务中最常用的变体。BLEU值的范围是0到1,值越高表示生成文本与参考文本越相似。需要注意的是,BLEU主要衡量词汇层面的相似性,无法评估语义正确性和逻辑连贯性。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation) :专注于召回率的评估指标,特别适用于文本摘要任务。ROUGE-N计算n-gram的重叠,ROUGE-L计算最长公共子序列(LCS)的重叠。ROUGE-L能够捕捉句子级的结构相似性,对词序变化具有一定的容忍度。
困惑度(Perplexity,PPL) :衡量模型对数据“确定性”的指标。数值越低表示模型对预测的确定性越高。直观理解,困惑度表示模型在预测下一个词时的平均“困惑程度”。在英文任务中,PPL值低于50通常认为可接受,低于20则为优秀水平。需要特别注意的是,不同语言、不同分词方式下的PPL值不能直接比较——中文因分词复杂,PPL值通常会比英文高。
2.1.3 代码示例:分类任务评估
以下代码展示了如何使用Hugging Face Transformers加载微调后的模型,并在测试集上计算准确率、精确率、召回率和F1值。
# -*- coding: utf-8 -*-
"""
分类任务评估示例:计算准确率、精确率、召回率和F1值
适用于情感分析、意图识别等分类任务的微调模型评估
"""
import torch
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch.utils.data import DataLoader, Dataset
from tqdm import tqdm
import logging
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# ==================== 1. 配置参数 ====================
MODEL_PATH = "./fine_tuned_model" # 微调后模型路径
TEST_DATA_PATH = "./test_data.json" # 测试数据路径(需替换为实际路径)
MAX_LENGTH = 512 # 最大序列长度
BATCH_SIZE = 16 # 批次大小
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
NUM_LABELS = 2 # 类别数(二分类)
logger.info(f"使用设备: {DEVICE}")
# ==================== 2. 加载模型和分词器 ====================
def load_model_and_tokenizer(model_path, num_labels):
"""
加载微调后的模型和对应的分词器
"""
logger.info(f"从 {model_path} 加载模型...")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForSequenceClassification.from_pretrained(
model_path,
num_labels=num_labels,
trust_remote_code=True
)
model.to(DEVICE)
model.eval() # 设置为评估模式
logger.info("模型加载完成")
return tokenizer, model
# ==================== 3. 加载测试数据 ====================
class TextClassificationDataset(Dataset):
"""自定义文本分类数据集类"""
def __init__(self, texts, labels, tokenizer, max_length):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = str(self.texts[idx])
label = self.labels[idx]
encoding = self.tokenizer(
text,
truncation=True,
padding='max_length',
max_length=self.max_length,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].squeeze(0),
'attention_mask': encoding['attention_mask'].squeeze(0),
'label': torch.tensor(label, dtype=torch.long)
}
def load_test_data(file_path):
"""
加载测试数据
假设数据格式为 JSON: [{"text": "...", "label": 0}, ...]
请根据实际数据格式调整此函数
"""
import json
logger.info(f"从 {file_path} 加载测试数据...")
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
texts = [item['text'] for item in data]
labels = [item['label'] for item in data]
logger.info(f"加载完成,共 {len(texts)} 条测试样本")
return texts, labels
# ==================== 4. 模型推理 ====================
def predict(model, dataloader, device):
"""
对测试集进行批量推理,返回预测标签和概率
"""
model.eval()
all_predictions = []
all_probs = []
with torch.no_grad():
for batch in tqdm(dataloader, desc="推理进度"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
logits = outputs.logits
# 获取预测类别和概率
probs = torch.softmax(logits, dim=-1)
predictions = torch.argmax(logits, dim=-1)
all_predictions.extend(predictions.cpu().numpy())
all_probs.extend(probs.cpu().numpy())
return np.array(all_predictions), np.array(all_probs)
# ==================== 5. 计算评估指标 ====================
def compute_metrics(y_true, y_pred):
"""
计算分类任务的核心评估指标
返回: 准确率、精确率、召回率、F1值
"""
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred, average='weighted', zero_division=0)
recall = recall_score(y_true, y_pred, average='weighted', zero_division=0)
f1 = f1_score(y_true, y_pred, average='weighted', zero_division=0)
return {
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1_score': f1
}
def print_confusion_matrix(y_true, y_pred):
"""打印混淆矩阵"""
cm = confusion_matrix(y_true, y_pred)
logger.info("\n混淆矩阵:")
logger.info(f" 预测为0 预测为1")
logger.info(f"实际为0: {cm[0,0]:<10} {cm[0,1]:<10}")
logger.info(f"实际为1: {cm[1,0]:<10} {cm[1,1]:<10}")
return cm
# ==================== 6. 主流程 ====================
def main():
# 加载模型和数据
tokenizer, model = load_model_and_tokenizer(MODEL_PATH, NUM_LABELS)
texts, labels = load_test_data(TEST_DATA_PATH)
# 创建数据集和数据加载器
dataset = TextClassificationDataset(texts, labels, tokenizer, MAX_LENGTH)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=False)
# 执行推理
predictions, probabilities = predict(model, dataloader, DEVICE)
# 计算并打印指标
metrics = compute_metrics(labels, predictions)
logger.info("\n" + "=" * 50)
logger.info("评估结果汇总")
logger.info("=" * 50)
logger.info(f"准确率 (Accuracy): {metrics['accuracy']:.4f}")
logger.info(f"精确率 (Precision): {metrics['precision']:.4f}")
logger.info(f"召回率 (Recall): {metrics['recall']:.4f}")
logger.info(f"F1值 (F1 Score): {metrics['f1_score']:.4f}")
# 打印混淆矩阵
print_confusion_matrix(labels, predictions)
# 可选:按类别输出详细指标
from sklearn.metrics import classification_report
report = classification_report(labels, predictions, target_names=['类别0', '类别1'])
logger.info("\n详细分类报告:\n" + report)
if __name__ == "__main__":
main()
2.1.4 代码示例:生成任务评估
以下代码展示了如何使用Hugging Face加载微调模型进行文本生成,并计算BLEU和ROUGE指标。
# -*- coding: utf-8 -*-
"""
生成任务评估示例:计算BLEU和ROUGE指标
适用于文本摘要、对话生成等任务的微调模型评估
"""
import json
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModelForCausalLM
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
from rouge_score import rouge_scorer
from tqdm import tqdm
import logging
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# ==================== 1. 配置参数 ====================
MODEL_PATH = "./fine_tuned_generation_model" # 微调后的生成模型路径
TEST_DATA_PATH = "./test_generation_data.json" # 测试数据路径
MAX_NEW_TOKENS = 256 # 生成的最大token数
TEMPERATURE = 0.7 # 生成温度参数
TOP_P = 0.9 # top-p采样参数
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
logger.info(f"使用设备: {DEVICE}")
# ==================== 2. 加载模型和分词器 ====================
def load_model_and_tokenizer(model_path):
"""
加载微调后的生成模型和分词器
"""
logger.info(f"从 {model_path} 加载模型...")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 如果模型没有pad_token,使用eos_token作为pad_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto" if torch.cuda.is_available() else None,
trust_remote_code=True
)
model.eval()
logger.info("模型加载完成")
return tokenizer, model
# ==================== 3. 加载测试数据 ====================
def load_test_data(file_path):
"""
加载测试数据
假设数据格式为 JSON: [
{"prompt": "请总结以下内容: ...", "reference": "参考摘要内容..."},
...
]
"""
logger.info(f"从 {file_path} 加载测试数据...")
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
prompts = [item['prompt'] for item in data]
references = [item['reference'] for item in data]
logger.info(f"加载完成,共 {len(prompts)} 条测试样本")
return prompts, references
# ==================== 4. 模型生成 ====================
def generate_responses(model, tokenizer, prompts, max_new_tokens=256, temperature=0.7, top_p=0.9):
"""
使用模型批量生成回复
"""
model.eval()
responses = []
for prompt in tqdm(prompts, desc="生成进度"):
# 编码输入
inputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=2048)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
# 生成
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=top_p,
do_sample=True, # 启用采样以获得多样性
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
# 解码输出(只保留新生成的部分,不包括输入prompt)
response = tokenizer.decode(outputs[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
responses.append(response.strip())
return responses
# ==================== 5. 计算BLEU指标 ====================
def compute_bleu(references, hypotheses):
"""
计算BLEU-1到BLEU-4指标
"""
smoothie = SmoothingFunction().method4
bleu_scores = {1: [], 2: [], 3: [], 4: []}
for ref, hyp in zip(references, hypotheses):
# 分词(简单按空格切分,可根据实际需求使用更复杂的分词器)
ref_tokens = ref.split()
hyp_tokens = hyp.split()
# 计算不同n-gram的BLEU
for n in [1, 2, 3, 4]:
weight = tuple([1.0/n] * n) + tuple([0.0] * (4 - n))
bleu = sentence_bleu([ref_tokens], hyp_tokens, weights=weight, smoothing_function=smoothie)
bleu_scores[n].append(bleu)
results = {}
for n in [1, 2, 3, 4]:
results[f'BLEU-{n}'] = np.mean(bleu_scores[n])
return results
# ==================== 6. 计算ROUGE指标 ====================
def compute_rouge(references, hypotheses):
"""
计算ROUGE-1、ROUGE-2和ROUGE-L指标
"""
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
rouge_scores = {
'rouge1': {'precision': [], 'recall': [], 'fmeasure': []},
'rouge2': {'precision': [], 'recall': [], 'fmeasure': []},
'rougeL': {'precision': [], 'recall': [], 'fmeasure': []}
}
for ref, hyp in zip(references, hypotheses):
scores = scorer.score(ref, hyp)
for metric in ['rouge1', 'rouge2', 'rougeL']:
rouge_scores[metric]['precision'].append(scores[metric].precision)
rouge_scores[metric]['recall'].append(scores[metric].recall)
rouge_scores[metric]['fmeasure'].append(scores[metric].fmeasure)
results = {}
for metric in ['rouge1', 'rouge2', 'rougeL']:
results[f'{metric}_precision'] = np.mean(rouge_scores[metric]['precision'])
results[f'{metric}_recall'] = np.mean(rouge_scores[metric]['recall'])
results[f'{metric}_fmeasure'] = np.mean(rouge_scores[metric]['fmeasure'])
return results
# ==================== 7. 计算困惑度(Perplexity) ====================
def compute_perplexity(model, tokenizer, texts, max_length=512):
"""
计算模型在给定文本上的困惑度
困惑度越低,表示模型对文本的"确定性"越高
"""
model.eval()
total_loss = 0.0
total_tokens = 0
with torch.no_grad():
for text in tqdm(texts, desc="计算困惑度"):
# 编码输入
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=max_length)
input_ids = inputs['input_ids'].to(model.device)
attention_mask = inputs['attention_mask'].to(model.device)
# 前向传播
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=input_ids)
loss = outputs.loss
# 累积损失和token数
total_loss += loss.item() * input_ids.shape[1]
total_tokens += input_ids.shape[1]
# 计算平均负对数似然和困惑度
avg_nll = total_loss / total_tokens
perplexity = np.exp(avg_nll)
return perplexity
# ==================== 8. 主流程 ====================
def main():
# 加载模型和数据
tokenizer, model = load_model_and_tokenizer(MODEL_PATH)
prompts, references = load_test_data(TEST_DATA_PATH)
# 生成回复
logger.info("开始生成回复...")
responses = generate_responses(
model, tokenizer, prompts,
max_new_tokens=MAX_NEW_TOKENS,
temperature=TEMPERATURE,
top_p=TOP_P
)
# 保存生成的回复供后续分析
output_file = "./generated_responses.json"
with open(output_file, 'w', encoding='utf-8') as f:
json.dump([
{"prompt": p, "reference": r, "generated": g}
for p, r, g in zip(prompts, references, responses)
], f, ensure_ascii=False, indent=2)
logger.info(f"生成的回复已保存至 {output_file}")
# 计算评估指标
logger.info("\n" + "=" * 50)
logger.info("BLEU指标")
logger.info("=" * 50)
bleu_results = compute_bleu(references, responses)
for metric, score in bleu_results.items():
logger.info(f"{metric}: {score:.4f}")
logger.info("\n" + "=" * 50)
logger.info("ROUGE指标")
logger.info("=" * 50)
rouge_results = compute_rouge(references, responses)
for metric, score in rouge_results.items():
logger.info(f"{metric}: {score:.4f}")
# 可选:计算困惑度
# 注意:计算整个测试集的困惑度可能耗时较长,且需要模型支持CLM任务
logger.info("\n" + "=" * 50)
logger.info("困惑度指标")
logger.info("=" * 50)
# 提取所有参考文本用于计算困惑度
all_texts_for_ppl = references # 或者使用生成的回复
# ppl = compute_perplexity(model, tokenizer, all_texts_for_ppl)
# logger.info(f"Perplexity (困惑度): {ppl:.4f}")
# 演示:输出前3个样本用于人工检查
logger.info("\n" + "=" * 50)
logger.info("样本输出(前3条)")
logger.info("=" * 50)
for i in range(min(3, len(prompts))):
logger.info(f"\n样本 {i+1}:")
logger.info(f"输入: {prompts[i][:100]}...")
logger.info(f"参考: {references[i]}")
logger.info(f"生成: {responses[i]}")
if __name__ == "__main__":
main()
2.2 性能评估——能不能高效做事
性能评估关注模型的工程化可行性,核心指标包括推理速度、显存占用、吞吐量等。
推理延迟(Inference Latency) :模型处理单个请求所需的时间,通常以毫秒或秒为单位。对于实时应用(如聊天机器人),延迟需要控制在可接受范围内(通常为几百毫秒到几秒)。
吞吐量(Throughput) :单位时间内模型能够处理的请求数量或token数量,通常以tokens/秒或请求/秒为单位。吞吐量决定了模型的并发处理能力。
显存占用(Memory Footprint) :模型在推理或训练时所占用的GPU显存量。对于资源受限的环境(如边缘设备),显存占用是关键的制约因素。
首token延迟(Time to First Token,TTFT) :从发送请求到收到第一个输出token的时间。对于流式输出场景,首token延迟直接影响用户体验。
每token延迟(Time Per Output Token,TPOT) :生成每个额外token所需的平均时间。该指标反映了模型生成长文本时的效率。
2.3 鲁棒性评估——能不能稳定做事
鲁棒性评估检验模型在各种干扰下的稳定性。鲁棒性不足的模型在实际应用中可能表现不稳定,导致用户体验差。
输入扰动鲁棒性:测试模型在面对拼写错误、同义词替换、句式变换等输入扰动时的表现。好的模型应当对这些扰动具有一定的容忍度。
对抗性鲁棒性:测试模型在面对恶意设计的对抗样本时的表现。例如,在分类任务中,对输入进行微小修改可能导致模型完全改变预测结果。
分布外泛化(Out-of-Distribution Generalization) :测试模型在面对与训练数据分布不同的新数据时的表现。例如,在金融领域微调的模型,能否泛化到不同类型的金融文档。
灾难性遗忘(Catastrophic Forgetting) :测试模型在微调后是否遗忘预训练阶段获得的基础知识。例如,在一个任务上微调后,模型在通用问答任务上的表现是否下降。
2.4 合规性评估——能不能安全做事
合规性评估是模型落地的生命线,检验模型是否满足安全、伦理与法规要求。
内容安全评估:检验模型是否会生成暴力、色情、仇恨言论等有害内容。评估方法包括使用标准化的安全测试集(如SafetyPrompts、CValues)和红队测试。
隐私保护评估:检验模型是否会泄露训练数据中的敏感信息,包括个人身份信息、商业机密等。特别关注模型是否存在“记忆泄露”(memorization leakage)问题。
偏见与公平性评估:检验模型在不同群体(如不同性别、种族、地域)之间是否存在系统性偏见。例如,在招聘场景中,模型不应基于候选人的性别做出不公正的判断。
指令安全评估:检验模型在面对越狱提示(jailbreak prompts)和提示注入(prompt injection)攻击时是否仍能保持安全行为。例如,模型不应在执行指令时被诱导输出本应禁止的内容。
2025年发布的《通用大模型评测体系2.0》特别强化了安全评测,设计了16项风险指标,涵盖内容安全和指令安全两个类别,为大模型安全部署提供了重要保障。
第三章:评估的核心目标
微调大模型的评估并非单纯“打分”,而是为模型优化和落地决策提供明确依据。核心目标可归纳为四个方面。
3.1 能力验证
能力验证的目标是确认微调后模型是否具备预设的核心能力,是否达到研发阶段的能力阈值。
在实际操作中,能力验证需要回答以下问题:
- 模型能否准确理解并执行目标任务相关的指令?
- 模型在特定领域任务(如医疗问答、代码生成)上的表现是否达到预期水平?
- 微调是否解决了预训练模型在目标场景中的适配不足问题?
能力验证通常通过构建标准化的测试集来进行。测试集应当独立于训练集和验证集,涵盖常规场景、边界场景和异常场景,确保评估结果的可靠性。
3.2 优劣对比
优劣对比的目标是横向对比不同微调方案(如全量微调、LoRA微调、QLoRA微调)或纵向对比微调前后模型的表现。
通过优劣对比,可以:
- 明确不同微调方案在特定任务上的能力边界;
- 为特定场景的模型选型提供数据支持;
- 验证微调是否真正带来了性能提升。
例如,一个典型的对比实验可以设置以下对照组:原始预训练模型(基线)、全量微调模型、LoRA微调(r=8)、LoRA微调(r=32)、QLoRA微调(4-bit量化)。通过对比这些模型在测试集上的表现,可以得出每种微调方法在效果-效率平衡方面的最佳实践。
3.3 迭代指导
迭代指导的目标是精准定位模型短板,为后续优化提供明确方向。
评估结果应当能够回答以下问题:
- 模型在哪些类型的输入上表现最差?——识别弱点
- 哪些特定错误模式最为常见?——归因分析
- 模型是否存在系统性偏差?——公平性问题
基于评估结果,可以采取以下优化措施:增加特定类型的训练数据、调整微调超参数、更换评估工具、或调整模型架构。
3.4 合规保障
合规保障的目标是检验模型是否满足安全、伦理与合规要求,确保模型能够安全合规落地应用。
合规保障的评估内容包括:
- 模型是否会生成有害内容?
- 模型是否会泄露敏感信息?
- 模型在不同群体间是否存在偏见?
- 模型是否能够抵御越狱攻击和提示注入攻击?
合规保障不仅是技术问题,也是法律问题。随着《欧盟AI法案》等法规的实施,大模型的可信评估正在从“可选”变为“强制”。
第四章:评估框架工具解析
当前,大模型评估领域涌现出多种成熟的框架和工具。本章将深度解析四个最具代表性的评估框架,并提供完整的使用指南和代码示例。
4.1 OpenCompass:一站式大模型评测平台
OpenCompass(司南)由上海人工智能实验室开发,是国内最具影响力的开源大模型评测平台。截至2025年,OpenCompass已全面升级为“五位一体”的全景评估范式,覆盖大模型评测、AI计算系统、具身智能、安全可信及垂类行业应用五大领域。
4.1.1 核心特性
- 广泛模型支持:支持超过20个Hugging Face和API模型的评估方案。
- 丰富数据集:集成70多个数据集,约40万个问题,涵盖中英文及多模态任务。
- 灵活评估模式:支持API模式评测(针对以API服务形式部署的模型)和本地直接评测(针对可获取模型权重文件的模型)。
- 自动化工具链:提供标准化的测试集与自动化评估流程,确保评估结果客观、可复现。
4.1.2 安装与环境配置
# 创建conda环境
conda create --name opencompass python=3.10 -y
conda activate opencompass
# 克隆OpenCompass仓库
git clone https://github.com/open-compass/opencompass
cd opencompass
# 安装OpenCompass
pip install -e .
# 下载数据集(可选,评估时会自动下载)
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
4.1.3 查看支持的模型和数据集
# 列出所有配置
python tools/list_configs.py
# 查找与MMLU相关的配置
python tools/list_configs.py mmlu
# 查找与Llama相关的配置
python tools/list_configs.py llama
4.1.4 配置评估任务
OpenCompass使用Python格式的配置文件来定义评估实验。以下是一个完整的配置文件示例:
# -*- coding: utf-8 -*-
# 文件名: configs/eval_my_model.py
from mmengine.config import read_base
# 继承预定义的配置
with read_base():
# 引入需要评估的数据集配置
from opencompass.configs.datasets.mmlu.mmlu_gen import mmlu_datasets
from opencompass.configs.datasets.gsm8k.gsm8k_gen import gsm8k_datasets
from opencompass.configs.datasets.hellaswag.hellaswag_ppl import hellaswag_datasets
from opencompass.configs.models.hf_model.hf_model import hf_model
# 定义待评估的模型
models = [
dict(
type='HuggingFaceCausalLM',
abbr='my-fine-tuned-model', # 模型缩写
path='./path/to/your/fine_tuned_model', # 模型路径
tokenizer_path='./path/to/your/fine_tuned_model',
tokenizer_kwargs=dict(
padding_side='left',
truncation_side='left',
trust_remote_code=True,
),
max_out_len=512, # 最大输出长度
max_seq_len=2048, # 最大序列长度
batch_size=8, # 批次大小
run_cfg=dict(num_gpus=1, num_procs=1), # 运行配置
)
]
# 定义评估数据集
datasets = []
datasets += mmlu_datasets # 多任务语言理解
datasets += gsm8k_datasets # 数学推理
datasets += hellaswag_datasets # 常识推理
# 可选:修改数据集的评估配置
for dataset in datasets:
# 对于生成式数据集,可能需要调整max_out_len
if 'infer_cfg' in dataset and 'inferencer' in dataset['infer_cfg']:
dataset['infer_cfg']['inferencer'].pop('max_out_len', None)
# 可选:限制评估样本数量(用于快速测试)
# for dataset in datasets:
# dataset['eval_cfg']['num_shot'] = 5
# dataset['eval_cfg']['subset_size'] = 100
# 输出配置
work_dir = './outputs/evaluation_results'
4.1.5 运行评估
# 使用配置文件的绝对路径运行评估
python run.py configs/eval_my_model.py
# 使用torchrun进行多GPU并行评估
torchrun --nproc_per_node=4 run.py configs/eval_my_model.py
# 评估后生成报告
python tools/visualize_report.py --output_dir ./outputs/evaluation_results
4.1.6 结果解读
OpenCompass的评估输出通常包含以下信息:
- 每个数据集上的具体得分(如MMLU的准确率、GSM8K的通过率);
- 各模型的综合对比报告;
- 可选的样本级输出日志,用于深入分析模型的错误模式。
4.2 lm-evaluation-harness:学术基准评估的“金标准”
lm-evaluation-harness是EleutherAI开源的评估框架,已被广泛应用于Hugging Face Open LLM Leaderboard,并被NVIDIA、Cohere、BigScience等数十个组织使用。框架支持超过60个标准学术基准测试,包含数百个子任务和变体。
4.2.1 核心特性
- 丰富的内置任务:支持MMLU、GSM8K、HellaSwag、TruthfulQA、HumanEval等主流基准。
- 多模型后端:支持HuggingFace Transformers、vLLM、SGLang、OpenAI API等多种模型加载方式。
- 灵活的任务配置:通过YAML文件定义评估任务,支持少样本学习、思维链等高级提示策略。
- 权威评估结果:生成符合学术标准的评估报告,可直接用于论文发表或产品白皮书。
4.2.2 安装与环境配置
# 克隆仓库
git clone --depth 1 https://github.com/EleutherAI/lm-evaluation-harness
cd lm-evaluation-harness
# 基础安装
pip install -e .
# 如需vLLM支持
pip install -e .[vllm]
# 如需SGLang支持
pip install -e .[sglang]
# 验证安装
lm_eval --help
4.2.3 命令行快速评估
# 评估HuggingFace模型在HellaSwag任务上的表现
lm_eval --model hf \
--model_args pretrained=./path/to/fine_tuned_model \
--tasks hellaswag \
--device cuda:0 \
--batch_size 8
# 评估多个任务
lm_eval --model hf \
--model_args pretrained=./path/to/fine_tuned_model \
--tasks mmlu,gsm8k,hellaswag,truthfulqa \
--device cuda:0 \
--batch_size auto
# 少样本学习设置
lm_eval --model hf \
--model_args pretrained=./path/to/fine_tuned_model \
--tasks mmlu \
--num_fewshot 5 \
--device cuda:0
# 保存详细日志和样本输出
lm_eval --model hf \
--model_args pretrained=./path/to/fine_tuned_model \
--tasks mmlu \
--output_path ./results/ \
--log_samples
4.2.4 使用Python API进行评估
对于需要深度集成到微调流程的场景,可以使用Python API:
# -*- coding: utf-8 -*-
"""
使用lm-evaluation-harness的Python API评估微调后的模型
"""
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from lm_eval import evaluator
from lm_eval.models.huggingface import HFLM
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def evaluate_fine_tuned_model(model_path, tasks=None, num_fewshot=0):
"""
评估微调后的模型
Args:
model_path: 微调后的模型路径
tasks: 评估任务列表,如['mmlu', 'gsm8k']
num_fewshot: 少样本学习示例数量
"""
if tasks is None:
tasks = ['hellaswag', 'arc_easy', 'lambada_openai']
logger.info(f"加载模型: {model_path}")
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto",
trust_remote_code=True
)
# 封装为lm_eval兼容的模型接口
lm = HFLM(
pretrained=model,
tokenizer=tokenizer,
batch_size=8,
max_length=2048,
)
# 执行评估
logger.info(f"开始评估任务: {tasks}")
results = evaluator.simple_evaluate(
model=lm,
tasks=tasks,
num_fewshot=num_fewshot,
limit=None, # 限制样本数量,用于快速测试
bootstrap_iters=100, # 置信区间计算迭代次数
)
# 输出结果
logger.info("\n" + "=" * 50)
logger.info("评估结果")
logger.info("=" * 50)
for task_name, task_results in results['results'].items():
logger.info(f"\n任务: {task_name}")
for metric_name, metric_value in task_results.items():
if isinstance(metric_value, (int, float)):
logger.info(f" {metric_name}: {metric_value:.4f}")
return results
# 使用示例
if __name__ == "__main__":
# 替换为实际模型路径
MODEL_PATH = "./fine_tuned_model"
# 评估基础任务
results = evaluate_fine_tuned_model(
model_path=MODEL_PATH,
tasks=['hellaswag', 'arc_easy', 'mmlu'],
num_fewshot=5
)
4.2.5 自定义评估任务
从0.4.0版本开始,lm-evaluation-harness引入了基于YAML的配置化任务定义系统,使得添加自定义任务不再需要修改源代码。
以下是创建自定义评估任务的YAML配置示例:
# custom_task.yaml
task: custom_sentiment_analysis
dataset_path: ./custom_data/sentiment.jsonl
output_type: generate_until
training_split: null
validation_split: null
test_split: null
doc_to_text: "判断以下评论的情感是正面还是负面。\n评论: {{text}}\n情感:"
doc_to_target: "{{label}}"
target_delimiter: " "
metric_list:
- metric: accuracy
aggregation: mean
higher_is_better: true
- metric: f1
aggregation: mean
higher_is_better: true
num_fewshot: 0
运行自定义任务:
lm_eval --model hf \
--model_args pretrained=./fine_tuned_model \
--tasks custom_sentiment_analysis \
--task_config_path ./custom_task.yaml
4.3 AlpacaEval:指令遵循能力的自动化评估
AlpacaEval是一个专门用于评估指令微调语言模型的自动化评估框架。它使用基于LLM的自动标注器(通常是GPT-4)对模型输出进行成对比较,生成胜率排行榜。
4.3.1 核心特性
- 自动化评估:用自动评估器替代昂贵、耗时的人工评估,与人类判断保持高度一致性。
- 长度控制:通过广义线性模型(GLM)计算长度控制胜率(LC Win Rate),有效缓解评估器对长输出的偏好。
- 高效低成本:完整评估可在5分钟内完成,成本低于10美元。
- 灵活部署:支持各种模型类型(本地模型、API模型、自定义模型)。
4.3.2 长度控制胜率的技术原理
AlpacaEval 2.0引入的长度控制胜率是其核心创新之一。研究发现,LLM评估器存在明显的长度偏好——倾向于给更长的输出更高的评分,无论其内容质量如何。
长度控制胜率通过以下步骤解决该问题:
- 收集标注数据,提取特征(包括输出长度差异);
- 拟合逻辑回归模型,基于这些特征预测偏好;
- 使用该模型估计“如果输出长度相等,偏好会是怎样”;
- 同时报告标准胜率和长度控制胜率。
这种方法将评估结果与人类判断的相关性从0.93提升至0.98。
4.3.3 安装与使用
# 安装AlpacaEval
pip install alpaca-eval
# 使用命令行评估模型
alpaca_eval evaluate \
--model_outputs ./model_outputs.json \
--annotators_config "alpaca_eval_gpt4" \
--output_path ./results/
4.3.4 Python API使用示例
# -*- coding: utf-8 -*-
"""
使用AlpacaEval评估指令微调模型
"""
import json
from alpaca_eval import evaluate
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def evaluate_with_alpacaeval(model_outputs_path, baseline_name="text-davinci-003"):
"""
使用AlpacaEval评估模型输出
Args:
model_outputs_path: 模型输出的JSON文件路径
baseline_name: 基线模型名称(用于计算胜率)
"""
logger.info(f"加载模型输出: {model_outputs_path}")
# 加载模型输出
with open(model_outputs_path, 'r', encoding='utf-8') as f:
model_outputs = json.load(f)
# 执行评估
results = evaluate(
model_outputs=model_outputs,
annotators_config="alpaca_eval_gpt4_turbo", # 使用GPT-4 Turbo作为评判器
baseline_name=baseline_name,
output_path="./alpaca_eval_results/",
is_return_instead_of_print=True,
)
# 输出结果
logger.info("\n" + "=" * 50)
logger.info("AlpacaEval评估结果")
logger.info("=" * 50)
logger.info(f"胜率 (Win Rate): {results['win_rate']:.4f}")
logger.info(f"长度控制胜率 (LC Win Rate): {results['length_controlled_win_rate']:.4f}")
return results
def generate_model_outputs(model, tokenizer, prompts, output_path):
"""
为AlpacaEval生成模型输出
"""
outputs = []
for prompt in prompts:
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
generated_ids = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
)
response = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:],
skip_special_tokens=True)
outputs.append({
"instruction": prompt,
"output": response,
})
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(outputs, f, ensure_ascii=False, indent=2)
logger.info(f"模型输出已保存至 {output_path}")
return outputs
# 使用示例
if __name__ == "__main__":
# 假设已有模型输出文件
MODEL_OUTPUTS_PATH = "./model_outputs.json"
evaluate_with_alpacaeval(MODEL_OUTPUTS_PATH)
4.4 LLM-as-a-Judge:以大模型评大模型
LLM-as-a-Judge是一种新兴的评估范式,利用大语言模型作为自动评估器来评判其他模型的输出质量。该范式已在MT-Bench、AlpacaEval等多个基准测试中得到广泛应用。
4.4.1 核心原理
LLM-as-a-Judge的核心思想是:一个足够强大的LLM可以模拟人类评估者的判断,对模型输出进行评分或排序。典型的评估流程包括:
- 向评判模型提供评估指令(如“请评价以下回答的质量,从1到10打分”);
- 评判模型接收待评估的模型输出;
- 评判模型根据预设标准生成评分或判断;
- 汇总多个样本的评分,得出最终评估结果。
4.4.2 优势与挑战
优势:
- 可扩展性:可以大规模自动化评估,不受人力限制;
- 一致性:同一位LLM评判器在相同条件下产生一致的判断;
- 成本效益:相比人工评估,成本大幅降低。
挑战与局限:
- 长度偏好:LLM评判器倾向于给更长的输出更高分;
- 自我偏好:评判器可能偏向与自己同源的模型;
- 推理能力局限:在需要复杂推理的评估任务上,LLM评判器可能出错;
- 情境偏好:即使是顶尖模型(如Gemini-2.5-Pro和GPT-5),在近四分之一的困难案例中也难以保持一致的偏好。
4.4.3 微调评判模型的实践
研究表明,微调LLM-as-a-Judge是提升评判性能的可行方法。JudgeLM项目展示了如何通过微调开源LLM(如Vicuna-13B)来构建可扩展的评判器,实现与教师评判器(如GPT-4)的满意一致性。
以下是一个使用微调后的JudgeLM进行模型评估的示例:
# -*- coding: utf-8 -*-
"""
使用LLM-as-a-Judge评估模型输出质量
"""
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import json
from tqdm import tqdm
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class LLMJudgeEvaluator:
"""使用LLM作为评判器的评估类"""
def __init__(self, judge_model_path, device=None):
self.device = device or torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.tokenizer = AutoTokenizer.from_pretrained(judge_model_path, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(
judge_model_path,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto",
trust_remote_code=True
)
self.model.eval()
logger.info(f"评判模型加载完成,设备: {self.device}")
def get_judgment_prompt(self, instruction, response):
"""构建评判提示词"""
prompt = f"""请评价以下回答的质量,从以下几个方面评估:准确性、完整性、连贯性、有用性。
用户问题:{instruction}
模型回答:{response}
请给出1到10分的综合评分,并简要说明理由。
评分:"""
return prompt
def evaluate_response(self, instruction, response, max_new_tokens=256):
"""评估单个回答"""
prompt = self.get_judgment_prompt(instruction, response)
inputs = self.tokenizer(prompt, return_tensors="pt", truncation=True, max_length=2048)
inputs = {k: v.to(self.model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=0.3,
do_sample=False,
)
judgment = self.tokenizer.decode(outputs[0][inputs['input_ids'].shape[1]:],
skip_special_tokens=True)
return judgment
def batch_evaluate(self, test_data):
"""批量评估"""
results = []
for item in tqdm(test_data, desc="评估进度"):
judgment = self.evaluate_response(item['instruction'], item['response'])
results.append({
'instruction': item['instruction'],
'response': item['response'],
'judgment': judgment,
'reference': item.get('reference', None)
})
return results
# 使用示例
if __name__ == "__main__":
# 初始化评判器(可使用微调后的JudgeLM或其他模型)
judge = LLMJudgeEvaluator(judge_model_path="./fine_tuned_judge_model")
# 加载测试数据
with open('./test_data.json', 'r', encoding='utf-8') as f:
test_data = json.load(f)
# 执行评估
results = judge.batch_evaluate(test_data)
# 保存评估结果
with open('./llm_judge_results.json', 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
logger.info("评估完成,结果已保存")
结语:构建科学、可持续的评估体系
本文系统阐述了微调大模型性能与能力评估的完整体系,从评估框架的构建、评估内容与标准的界定、评估目标的明确,到四大主流评估框架工具(OpenCompass、lm-evaluation-harness、AlpacaEval、LLM-as-a-Judge)的深度解析和实战代码示例。
回顾全文,有几点核心认识值得强调:
第一,评估不是训练的“收尾工作”,而是贯穿整个开发周期的“反馈机制” 。好的评估体系能够及早发现隐藏缺陷、精准定位优化方向,形成“评估—分析—优化—再评估”的高效闭环。正如“训练-评估-迭代”闭环所强调的,评估是微调大模型的核心环节。
第二,评估体系应当是多维度的。能力评估、性能评估、鲁棒性评估和合规性评估四个维度缺一不可,且在不同应用场景中的权重各异。切勿以单一指标(如准确率或BLEU)替代全面评估。
第三,评估工具的选择应当场景化。OpenCompass适合需要覆盖多数据集、多模型的一站式评估;lm-evaluation-harness适合学术基准的标准化评估;AlpacaEval适合指令遵循能力的快速基准测试;LLM-as-a-Judge适合需要灵活评判标准的场景。在实际工作中,建议组合使用多种工具,形成互补评估体系。
第四,评估方法正在从“静态”走向“动态” 。以LLMEval-3为代表的动态评估框架,通过私有问题库和动态采样机制,有效解决了数据污染和排行榜过拟合问题。这一趋势值得每一位大模型开发者关注和跟进。
微调大模型的评估是一个仍在快速演进的前沿领域。随着模型能力的持续提升和应用场景的不断扩展,评估体系也将随之迭代完善。希望本文能够为读者构建自己的评估体系提供有价值的参考和可操作的实践指导。
🌟 感谢您耐心阅读到这里!
💡 如果本文对您有所启发欢迎:
👍 点赞📌 收藏 📤 分享给更多需要的伙伴。
🗣️ 期待在评论区看到您的想法, 共同进步。
🔔 关注我,持续获取更多干货内容~
🤗 我们下篇文章见~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)