Prompt Engineering、Context Engineering、Harness Engineering三者之间的区别
·
文章目录
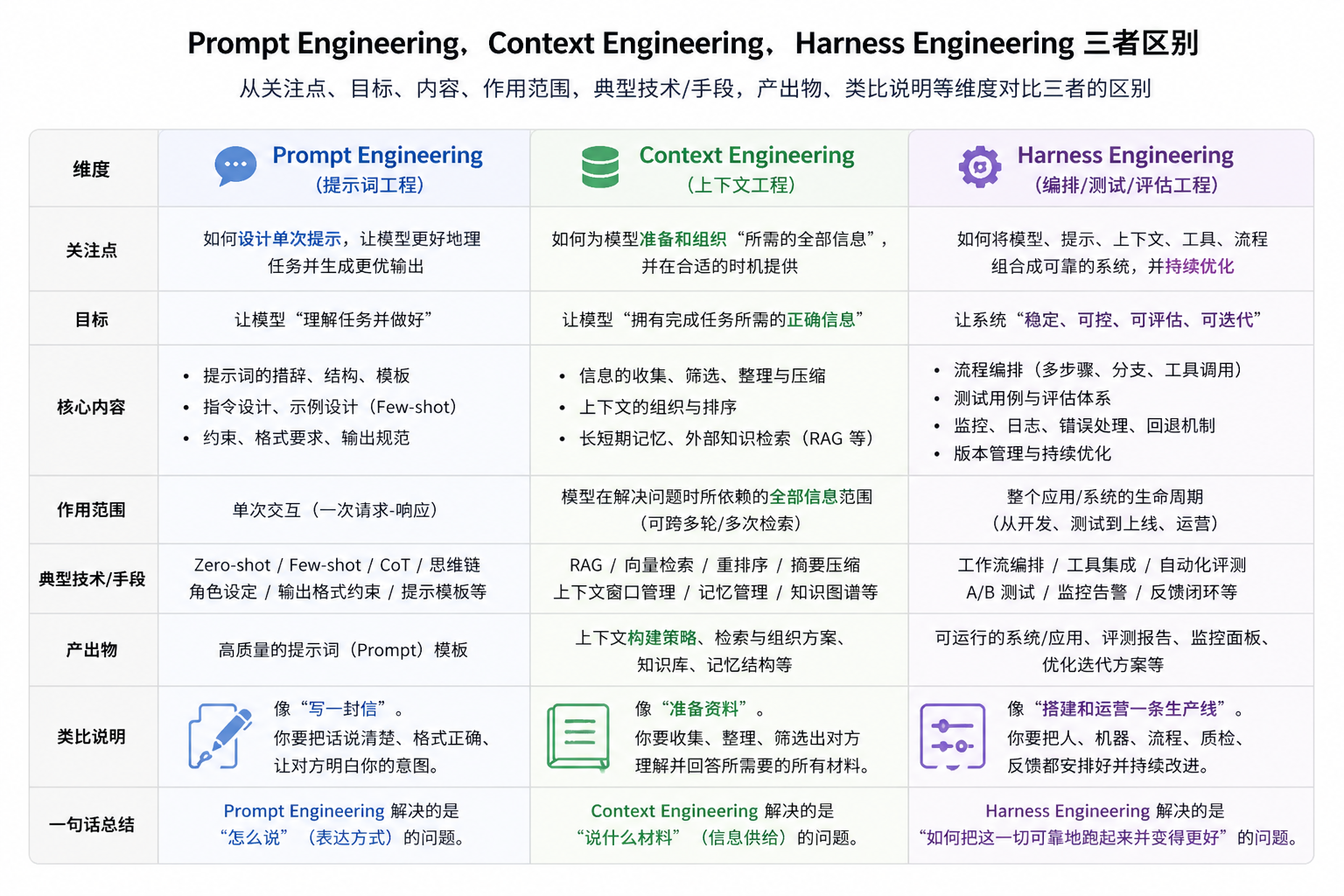
- Prompt Engineering 👉 你怎么下指令
- Context Engineering 👉 你给他什么资料
- Harness Engineering 👉 你怎么安排他工作流程(甚至配工具)
🧠 三者对比
| 层级 | 关注点 | 类比 |
|---|---|---|
| Prompt Engineering | 怎么说 | 写问题 |
| Context Engineering | 给什么信息 | 提供资料 |
| Harness Engineering | 怎么用模型做事 | 搭整个系统 |
1️⃣ Prompt Engineering(提示工程)
👉 核心:怎么把一句话说好,让模型给出更好的回答
它关注的是“输入文本本身”的设计,比如:
- 如何写清晰的指令
- 是否需要 few-shot 示例
- 用什么语气、结构、格式
例如:
- ❌ “总结一下这篇文章”
- ✅ “用3点总结这篇文章,每点不超过20字,并给出一个标题”
📌 本质:微观层面优化单次调用
👉 重点:你写了什么 prompt
from openai import OpenAI
client = OpenAI()
question = "什么是量子计算?"
response = client.chat.completions.create(
model="gpt-5.3",
messages=[
{"role": "user", "content": f"请用通俗语言解释:{question},并给一个生活中的例子"}
]
)
print(response.choices[0].message.content)
2️⃣ Context Engineering(上下文工程)
👉 核心:给模型“喂什么信息”
不仅仅是写 prompt,而是决定:
- 要不要加入历史对话(memory)
- 要不要做 RAG(检索增强生成)
- 是否注入知识库内容
- 如何组织上下文顺序(system / user / tool)
例如:
- 在客服系统中,把用户历史订单、FAQ 一起放进上下文
- 在 coding assistant 中注入当前文件内容
📌 本质:控制模型“看到的世界”
👉 重点:你给模型加了额外上下文(RAG / memory / docs)
from openai import OpenAI
client = OpenAI()
question = "什么是量子计算?"
# 模拟从知识库检索到的内容(RAG)
retrieved_docs = """
量子计算利用量子比特(qubit),可以同时表示0和1,
在某些问题上比传统计算更高效。
"""
response = client.chat.completions.create(
model="gpt-5.3",
messages=[
{"role": "system", "content": "你是一个专业但通俗的讲解助手"},
{"role": "user", "content": f"""参考以下资料回答问题:{retrieved_docs} 问题:{question}"""}
]
)
print(response.choices[0].message.content)
3️⃣ Harness Engineering(工程/编排工程)
👉 核心:如何把模型变成一个“可用系统”
这个层面已经不只是 prompt 或上下文,而是:
- 多步骤调用(agent / tool use)
- 模型 + 工具(搜索、数据库、API)
- 错误处理、重试、评估
- pipeline / workflow 设计
比如:
- 一个 AI 能: 1. 先搜索资料; 2. 再总结; 3. 再生成报告
- 或者自动调用函数、写代码、执行结果
📌 本质:构建完整 AI 应用系统
👉 重点:不只是一次调用,而是一个流程(带搜索 + 校验 + 兜底)
from openai import OpenAI
client = OpenAI()
def decide_need_search(question):
"""Step 1: 判断是否需要搜索"""
resp = client.chat.completions.create(
model="gpt-5.3",
messages=[
{"role": "system", "content": "判断问题是否需要最新或外部信息,只回答 yes 或 no"},
{"role": "user", "content": question}
]
)
return "yes" in resp.choices[0].message.content.lower()
def search(query):
"""Step 2: 外部工具(可以换成真实搜索API)"""
return f"(模拟搜索结果)关于 {query} 的最新资料..."
def generate_answer(question, context):
"""Step 3: 生成答案"""
resp = client.chat.completions.create(
model="gpt-5.3",
messages=[
{"role": "system", "content": "你是一个严谨的专家,基于上下文回答"},
{"role": "user", "content": f"""上下文:{context} 问题:{question}"""}
]
)
return resp.choices[0].message.content
def evaluate_answer(answer):
"""Step 4: 自检"""
resp = client.chat.completions.create(
model="gpt-5.3",
messages=[
{"role": "system", "content": "判断答案是否可靠,只回答 yes 或 no"},
{"role": "user", "content": answer}
]
)
return "yes" in resp.choices[0].message.content.lower()
def pipeline(question):
"""总流程(Harness)"""
# 决策
need_search = decide_need_search(question)
# 上下文
context = ""
if need_search:
context = search(question)
# 生成
answer = generate_answer(question, context)
# 自检
if not evaluate_answer(answer):
return "这个问题我不太确定,需要更多可靠信息。"
return answer
# 使用
print(pipeline("什么是量子计算?"))

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)