【光流跟踪】MegaFlow:零样本大位移光流算法

文章目录
标题:《MegaFlow: Zero-Shot Large Displacement Optical Flow》项目:https://kristen-z.github.io/projects/megaflow/.来源:ETH Zurich ;Microsoft ;University of Tübingen, Tübingen AI Center
摘要
对大位移光流进行精确估计仍是当前面临的关键挑战。现有方法通常依赖迭代式局部搜索和/或领域特定的微调,这严重限制了其在大位移场景和零样本泛化场景下的性能表现。
MegaFlow是一个简单强大的零样本大位移光流模型,无需依赖高度复杂的任务特定架构设计,而是通过调用强大的预训练视觉先验知识来生成时间一致性运动场。具体利用预训练的全局视觉Transformer特征将光流估计转化为全局匹配问题,这种设计能自然捕捉大位移特征;随后通过少量轻量级迭代优化进一步提升亚像素级精度。大量实验表明,MegaFlow在多项光流基准测试中均实现了最先进的零样本性能。此外,该模型在长距离点跟踪基准测试中也展现出极具竞争力的零样本性能,充分证明了其强大的迁移能力,并为通用化运动估计提供了统一的范式。
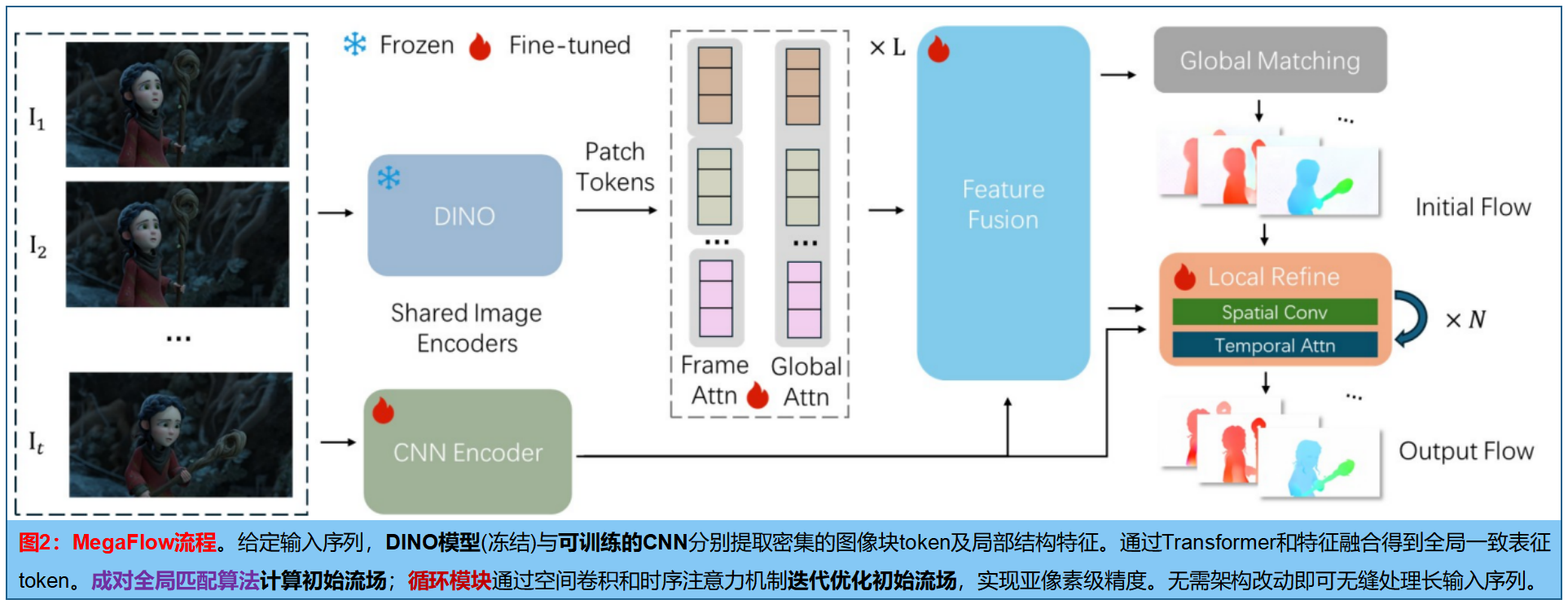
核心目标:给定 T T T 帧的视频序列 { I 1 , I 2 , … , I T } \{I_1, I_2, \dots, I_T\} {I1,I2,…,IT},估计连续帧之间的光流 { f 1 , … , f T − 1 } \{f_1, \dots, f_{T-1}\} {f1,…,fT−1}。整个框架由三部分组成:特征提取与融合 (Feature Extraction and Fusion)、全局匹配 (Global Matching)以及局部循环细化 (Local Recurrent Refinement)
一、特征提取与融合 (Feature Extraction and Fusion)
-
基础特征提取:使用 DINOv2 提取每帧特征,生成Patch Token。后接冻结的Transformer骨干网络(交替的逐帧和全局自注意力层,类似VGGT结构)。
-
多尺度CNN补充:为了弥补Patch Token化带来的细节丢失,引入了一个轻量级的CNN编码器来生成多尺度(1/2 和 1/4 分辨率)的特征图。
-
特征融合:使用DPT融合头将CNN特征与Transformer特征对齐合并,输出多帧特征图 { F i } i = 1 T \{F_i\}_{i=1}^T {Fi}i=1T。既保留了强烈的局部细节,又编码了跨帧的上下文信息。
二、全局匹配 (Global Matching):估计相邻帧间的初始光流。
- 全对全相关性计算:将匹配问题建模为全局匹配。对于第一帧 F i F_i Fi 中的每个空间位置 u \mathbf{u} u,计算它与下一帧 F i + 1 F_{i+1} Fi+1 中所有位置 v \mathbf{v} v 的点积相关性:
C i ( u , v ) = ⟨ F i ( u ) , F i + 1 ( v ) ⟩ C_i(\mathbf{u}, \mathbf{v}) = \langle F_i(\mathbf{u}), F_{i+1}(\mathbf{v}) \rangle Ci(u,v)=⟨Fi(u),Fi+1(v)⟩
-
概率分布与期望:对相关性矩阵应用 Softmax 归一化,得到每个位置的匹配概率分布 M i ( u , v ) M_i(\mathbf{u}, \mathbf{v}) Mi(u,v)。
-
初始光流计算:初始光流 f i init f_i^{\text{init}} fiinit 被计算为源坐标和基于概率分布的匹配坐标期望值之间的位移(其中 G ( v ) G(v) G(v) 代表v点的坐标):
f i init ( u ) = ∑ v M i ( u , v ) ⋅ G ( v ) − G ( u ) f_i^{\text{init}}(\mathbf{u}) = \sum_{\mathbf{v}} M_i(\mathbf{u}, \mathbf{v}) \cdot G(\mathbf{v}) - G(\mathbf{u}) fiinit(u)=v∑Mi(u,v)⋅G(v)−G(u)
三、局部循环优化
1. 构建局部搜索区域
在第二帧里找到第一帧的某个像素 u \mathbf{u} u,在初始光流 f ~ i init ( u ) \tilde{f}_i^{\text{init}}(\mathbf{u}) f~iinit(u)(大致位置)周围寻找: C i local ( u ) = ⟨ F i cnn ( u ) , F i + 1 cnn ( u + f ~ i init ( u ) + Δ u ) ⟩ C_i^{\text{local}}(\mathbf{u}) = \left\langle F_i^{\text{cnn}}(\mathbf{u}), F_{i+1}^{\text{cnn}}\left(\mathbf{u} + \tilde{f}_i^{\text{init}}(\mathbf{u}) + \Delta\mathbf{u}\right) \right\rangle Cilocal(u)=⟨Ficnn(u),Fi+1cnn(u+f~iinit(u)+Δu)⟩
- u + f ~ i init ( u ) \mathbf{u} + \tilde{f}_i^{\text{init}}(\mathbf{u}) u+f~iinit(u) :这是像素 u \mathbf{u} u 加上粗略位移后,在下一帧的预期落点。
- Δ u ∈ [ − r , r ] 2 \Delta\mathbf{u} \in [-r,r]^2 Δu∈[−r,r]2 :围绕预期落点画的一个小方块搜索范围(比如 9 × 9 9 \times 9 9×9 的像素邻域)。
- ⟨ … , … ⟩ \langle \dots , \dots \rangle ⟨…,…⟩ (内积/相关性) :第一帧 u \mathbf{u} u 的特征 vs 下一帧方块范围内的所有像素特征对比相似度。
2. 循环迭代更新
找到局部范围内的相似度后,网络进行多次修正: f i ( k + 1 ) = f i ( k ) + R ( f i ( k ) , C i local , F i cnn , F i ) f_i^{(k+1)} = f_i^{(k)} + \mathcal{R}\left(f_i^{(k)}, C_i^{\text{local}}, F_i^{\text{cnn}}, F_i\right) fi(k+1)=fi(k)+R(fi(k),Cilocal,Ficnn,Fi) R \mathcal{R} R (细化网络):根据初始光流 f i ( k ) f_i^{(k)} fi(k),以及上步的局部相似度 C i local C_i^{\text{local}} Cilocal,输出修正值 (Residual)。过程重复 K K K 次。每一次更新,搜索的小方块都会跟据新的预测位置移动。网络 R \mathcal{R} R 包含两个互补分支:
- 基于 ConvNeXt 的卷积分支:聚合来自相关性和CNN特征的局部运动证据。
- 时间注意力分支 (Temporal Attention Branch):在整个序列中关联特征,以捕获长期的时间一致性,从而在遮挡和外观变化下保持稳健。
四、训练损失 (Training Loss)
通过监督学习,使用预测光流 f f f 与真实光流 f ^ \hat{f} f^ 之间的误差(赋予指数递增的权重 γ \gamma γ): L flow = ∑ i T − 1 ∥ f i init − f ^ i ∥ smooth + ∑ k = 1 K γ K − k ∑ i T − 1 ∥ f i k − f ^ i ∥ 1 \mathcal{L}_{\text{flow}} = \sum_{i}^{T-1} \left\| f_i^{\text{init}} - \hat{f}_i \right\|_{\text{smooth}} + \sum_{k=1}^K \gamma^{K-k} \sum_{i}^{T-1} \left\| f_i^k - \hat{f}_i \right\|_1 Lflow=i∑T−1 fiinit−f^i smooth+k=1∑KγK−ki∑T−1 fik−f^i 1
五、扩展到点追踪 (Extension to Point Tracking)
目标是在不修改架构的情况下,无缝切换到密集点追踪任务。
- 任务定义:给定一个查询帧 I 0 I_0 I0 和目标点集 x ∈ P \mathbf{x} \in \mathcal{P} x∈P,目标是估计 I 0 I_0 I0 与后续每一帧 I t I_t It 之间的对应关系 f 0 → t f_{0 \to t} f0→t。点的追踪位置计算为: p t ( x ) = x + f 0 → t ( x ) p_t(\mathbf{x}) = \mathbf{x} + f_{0 \to t}(\mathbf{x}) pt(x)=x+f0→t(x)
- 与光流的区别:光流是严格计算相邻帧( i i i 与 i + 1 i+1 i+1)的运动,而点追踪则是通过全局匹配和局部细化,直接计算第一帧 I 0 I_0 I0 与目标帧 I t I_t It 之间的对应关系。追踪损失函数:调整了训练目标,不再直接惩罚密集光流场,而是直接惩罚点轨迹的误差: L point = ∑ t = 1 T ∥ p t init − p ^ t ∥ smooth + ∑ k = 1 K γ K − k ∑ t = 1 T ∥ p t k − p ^ t ∥ 1 \mathcal{L}_{\text{point}} = \sum_{t=1}^T \left\| p_t^{\text{init}} - \hat{p}_t \right\|_{\text{smooth}} + \sum_{k=1}^K \gamma^{K-k} \sum_{t=1}^T \left\| p_t^k - \hat{p}_t \right\|_1 Lpoint=t=1∑T ptinit−p^t smooth+k=1∑KγK−kt=1∑T ptk−p^t 1
- 长序列处理:对于较长的视频序列,模型 采用窗口大小为8的滑动窗口策略 (Sliding Window Strategy)。它将当前窗口预测的轨迹作为下一个窗口的初始化,从而连续传播轨迹 。这种方法不依赖显式的可见性启发式算法或置信度分数。
实验
数据集。训练在FlyingChairs [11]、TartanAirV1 [58]和FlyingThings [32]数据集上,在Sintel [5]和 KITTI [12]数据集上进行零样本评估,以检验跨域泛化能力。此外,我们在包含FlyingThings [32]、HD1K [23]、Sintel [5]和 KITTI [12]的混合数据集上进行训练,并在Sintel、 KITTI 和Spring [33]的在线基准测试中报告结果。
评估指标采用终点误差(EPE),即预测流与真实流之间的平均 ℓ2 距离(标准光流评估指标);对于 KITTI 数据集还报告了F1-all指标(表示异常值占比);对于Spring数据集,则包含1像素异常率(1px)、流异常率(Fl)及加权曲线下面积(WAUC)[12,33,42]。
为深入分析不同运动尺度下的性能,我们按流强度分层报告 EPE 值:s0−10、s10−40和s40+分别对应流强度为0–10、10–40及超过40像素的区间。
实现细节。Transformer主干网络基于 VGGT [57]架构,包含L=24层交替的全局注意力和帧级注意力机制;局部特征通过在ImageNet [7]上预训练的ResNet [15]前两个模块提取,生成1/4分辨率的特征图。该优化模块包含两个ConvNeXt模块[27,61]和两个时间注意力模块。完整模型共包含9.36亿个参数。
使用PyTorch,AdamW 优化,DINOv2图像编码器(冻结)、Transformer模块及部分特征融合模块均采用预训练的 VGGT [57]权重进行初始化。训练分为三个阶段:
- (1)在FlyingChairs数据集上进行20,000次迭代;
- (2)在TartanAirV1数据集上进行30,000次迭代;
- (3)在FlyingThings数据集上进行30,000次迭代(包括15,000次双帧预训练及15,000次多帧训练);
- (4)在混合数据集上进行30,000次迭代。
所有阶段batchsize =128。精炼模块在训练阶段使用4次迭代,在评估阶段使用8次迭代。多帧训练时,我们从随机场景中随机抽取2至6帧图像,以提升模型对不同时间跨度的处理能力;默认推理时使用T=4的输入帧。完整训练过程在64块 NVIDIA GH200 GPU上持续四天完成。为确保稳定性,我们采用梯度范数裁剪阈值为1.0,并利用bfloat16精度和梯度检查点技术优化内存使用与计算效率。所有注意力层均采用FlashAttention-3 [45]进行加速。
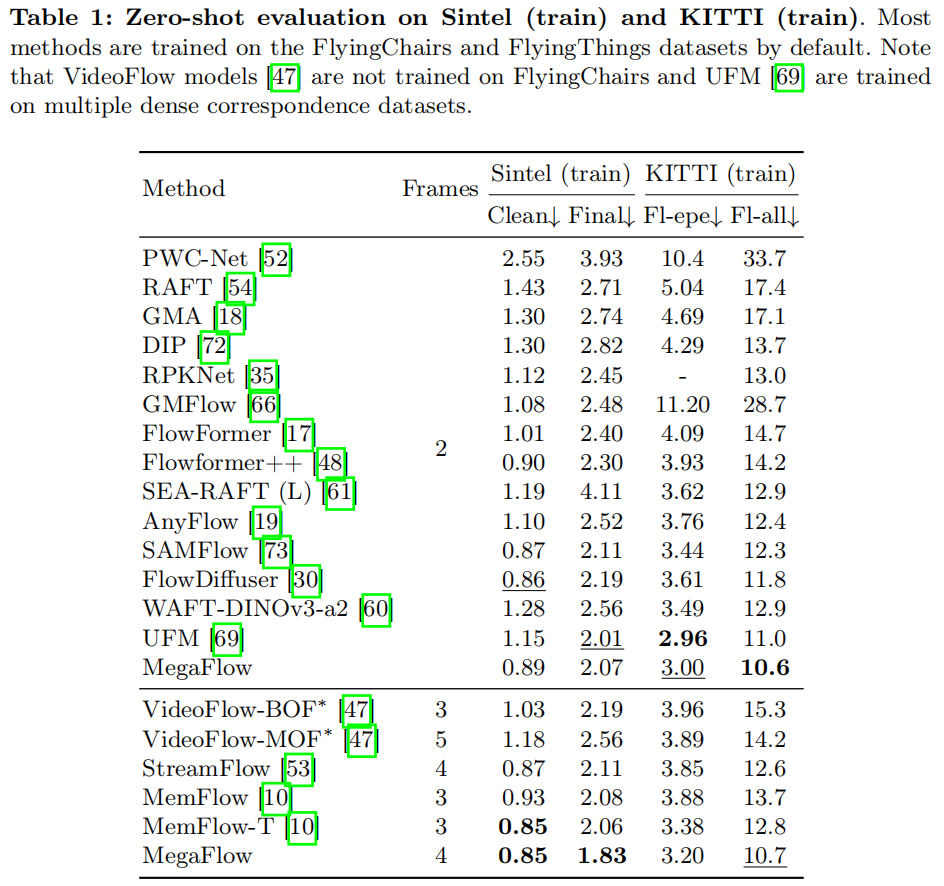
1.零样本泛化
在第三阶段训练后,评估了MegaFlow在Sintel和KITTI训练集上的零样本性能。如表1所示,MegaFlow取得了新的最先进水平,其性能优于双帧和多帧架构:
2.大幅度运动
在Sintel数据集上针对不同运动幅度区间进行了零样本场景下的性能评估(表2)。
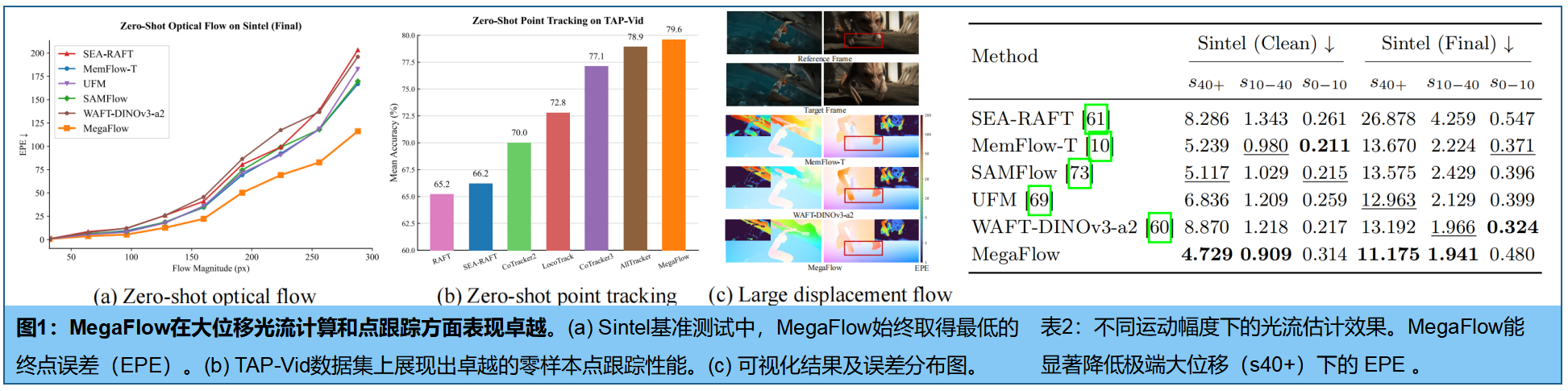
图1(a)的误差曲线所示,基线方法的终点误差(EPE)随运动幅度增大而急剧上升。表2的定量分析进一步证实了这一缺陷:虽然像MemFlow-T这样的多帧模型试图通过累积序列记忆来缓解此问题,但其仍受局部搜索范式的固有限制所制约。相比之下,MegaFlow有效平缓了误差曲线,并在极端位移场景下实现了显著提升——在Sintel(Clean)数据集上的误差降至4.729,在Sintel(Final)数据集上更是降至11.175。
3.长距离点跟踪
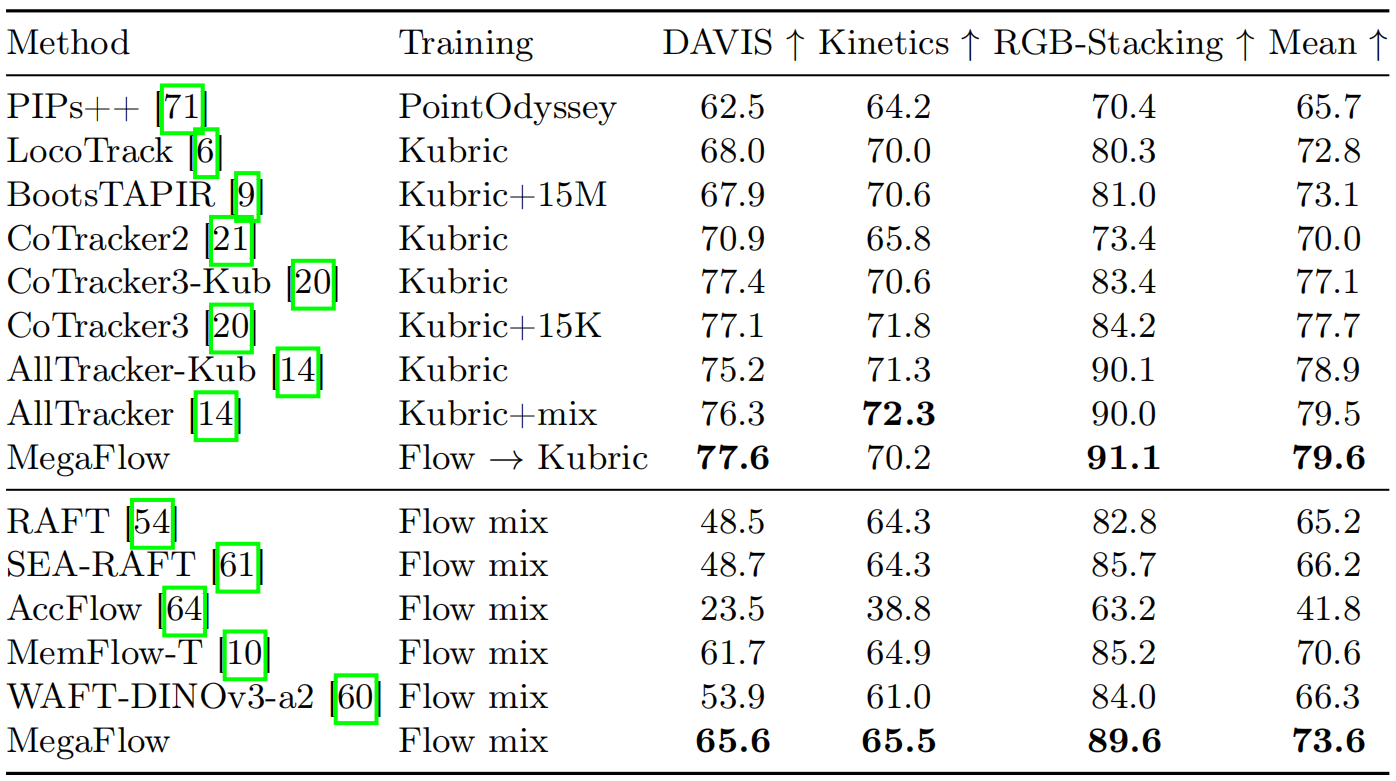
上述表3和图1(b)是在TAP-Vid[8]基准集(包含Kinetics、Davis、RGB-Stacking数据集)上对MegaFlow进行了测试,未对架构进行任何修改。滑动窗口方法可在单块GH200 GPU上处理长达600帧的序列。使用 δavg 指标[14,20,21]在384×512分辨率下评估所有模型,该指标取 δk =100·1[||p− pˆ ||²<k]的平均值(其中k∈{1,2,4,8,16})。定性分析来看(图3),MegaFlow始终能生成准确且连贯的密集跟踪轨迹。与本地搜索方法(例如SEA-RAFT)在长距离运动中生成不稳定轨迹,或MemFlow在关节部位存在边界伪影不同,我们的全局匹配架构具有更强的鲁棒性。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)