把2万个基因压成10个数字,这个AI让大模型真正“读懂”了细胞
论文信息
标题:RVQ-Alpha: Bridging Single-Cell Transcriptomics and Large Language Models via Discrete Tokenization and Verifiable Reinforcement Learning
把2万个基因压成10个数字,这个AI让大模型真正“读懂”了细胞
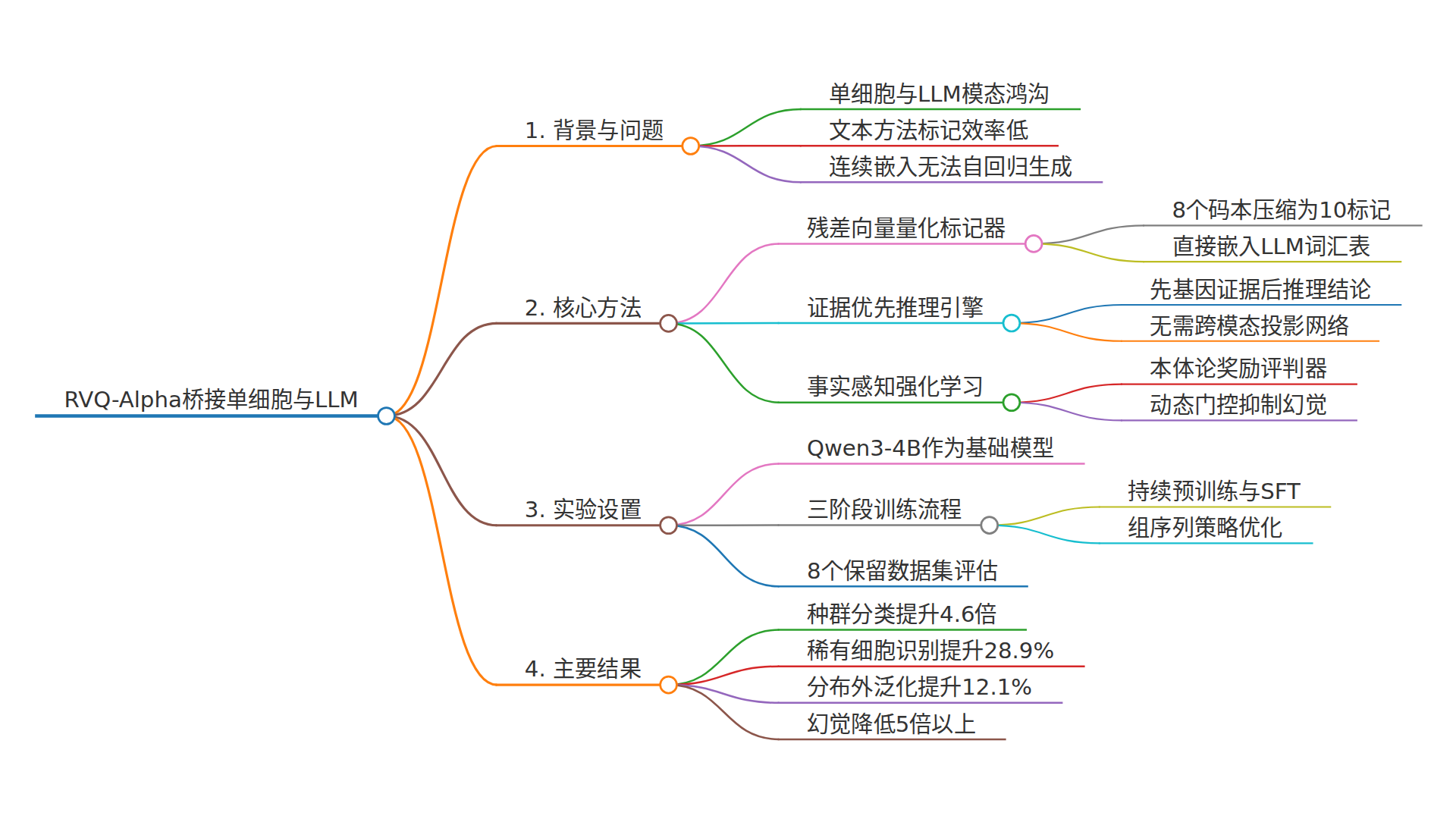
一句话速览
单细胞转录组数据与大语言模型之间存在“语言鸿沟”——连续表达值无法被LLM原生理解,而文本描述既低效又丢失精度。RVQ-Alpha用残差向量量化(RVQ)将每个细胞的基因表达压缩为10个离散token,通过“先摆证据、再下结论”的推理训练和可验证强化学习,在8个留出数据集上实现83.6%的单细胞注释准确率,罕见细胞识别提升28.9个百分点,群体级细胞分类任务提升4.6倍。
背景与痛点:当生命科学遇上大模型,卡在了“翻译”上
如果给ChatGPT看一个细胞的基因表达数据,它根本读不懂。这不是GPT不够聪明,而是数据格式不兼容。
单细胞RNA测序(scRNA-seq)能测量单个细胞中数万个基因的表达水平,每个细胞本质上是一个包含几千个数值的向量。大语言模型擅长处理的是离散的单词序列,不是连续的数字排列。这就像让一个精通拉丁文的学者去读心电图——知识结构完全不同。
过去几年,科学家们尝试了两种思路来打通这个壁垒。
第一种是“同声传译”路线:让大模型直接用数字打交道,如scGPT、Geneformer等模型都是在自定义的Transformer架构上学习细胞的连续嵌入表达。这类方法能精准地“理解”细胞,但有个致命缺陷——它们的输出是嵌入向量,不是语言。模型没法说人话,也无法用人类的推理链条来解释自己的判断。
第二种是“全文翻译”路线:把基因表达数据写成文本,比如“细胞X中CD8A高表达、CD4低表达”,然后喂给GPT。这种方法的好处是模型能理解自然语言,但代价巨大——光描述20个基因就需要40-80个token,而一个细胞表达数千个基因。更糟的是,文本描述丢弃了表达量的精确数值,而且模型读完文本后无法反向生成细胞状态。
这就是领域内的核心困境:要精度就不能生成,要生成就丢了精度。有没有可能鱼与熊掌兼得?
核心方法:残差量化 + 证据优先推理 + 可验证强化学习
RVQ-Alpha的研究者们给出的答案是一种三层递进的创新架构。
第一步:把细胞“翻译”成大模型的语言
核心创新是残差向量量化(Residual Vector Quantization, RVQ)。这个技术最早用于音频压缩(比如把高质量音乐压成小文件),但被巧妙地移植到了基因表达领域。
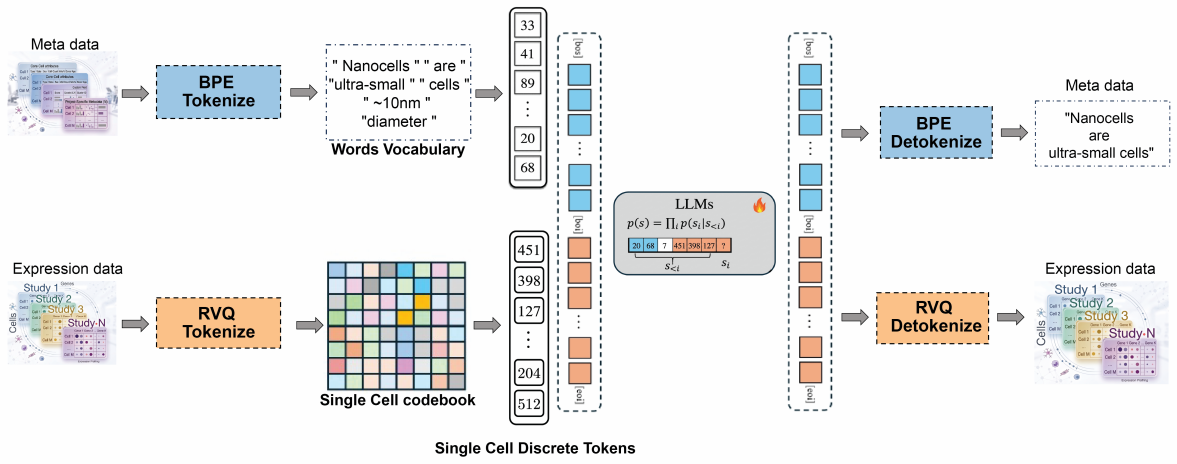
具体来说,一个编码器先把细胞中约2万种基因的表达值压缩成一个128维的向量。然后,8个依次排列的“码本”对这个向量进行逐级量化:
-
第一个码本捕获最主要的变异方向——这通常对应着细胞大类(是免疫细胞还是神经细胞?)
-
第二个码本捕获残差中最重要的部分——对应亚型(T细胞还是B细胞?)
-
第三个、第四个……层层细化,直到第八个码本捕获最精细的功能状态
每个码本只有32个“词”,8个码本加起来就是256个词。将这些词直接嵌入到LLM的词表中,每个细胞最终被表示为8 + 2(分隔符)= 10个token。
这比Cell2Sentence的100-500个token少了10-50倍,比同期工作CellTok的34个token也压缩了3.4倍。10个token意味着什么?意味着可以在一个上下文窗口里同时塞进几十个细胞和指令文本,实现真正的群体级推理。
更关键的是,越早的码本编码越宽泛的生物学类别,越晚的码本编码越细的功能状态(论文图8验证了这一假设)。这意味着RVQ天然地保留了细胞身份的层级结构——从“这是免疫细胞”到“这是激活的CD8+杀伤T细胞”。
第二步:教大模型“先摆证据,再下结论”
光有离散token还不够——新加入的256个token对大模型来说完全是陌生字符,没有任何语义。
RVQ-Alpha的解决方案叫做scCoT-Synth,本质上是一个“脚手架教学法”:
在生成训练数据时,研究者给教师模型提供基因特征(如排名靠前的基因名、已知标记基因),并要求它严格遵守“证据→推理→结论”的链式推理格式。例如:“该细胞CD8A、CD8B、GZMB高表达,CD4不表达(证据)→提示为细胞毒性T细胞(推理)→因此细胞类型为CD8+ T细胞(结论)”。
当学生模型(真正的Qwen3-4B)用这些数据训练时,基因特征信息被完全剥离。模型只能看到RVQ token和指令,必须学会从这10个数字中解码出基因表达信息,才能准确预测那些证据环节中的基因名称。
这个设计精妙之处在于:语言建模损失函数本身就成了跨模态对齐的信号——模型要想预测出正确的基因名,它的注意力机制就必须学会把RVQ token映射到预训练权重中已经存在的基因名表征上。实验表明,去掉这个“证据优先”结构,准确率下降8.3个百分点,幻觉率从4.2%飙升到23.7%。
第三步:用可验证的强化学习根治幻觉
SFT训练完的模型已经不错了,但研究者更进一步,引入了专为生物学推理设计的强化学习奖励系统。
这个奖励系统的核心是一个分门别类的裁判组:
-
答案裁判:基于细胞本体论(Cell Ontology)评估预测的语义正确性。如果模型说“B细胞”而答案是“naive B细胞”,后者是前者的子类型,这不等于错误。裁判有7个等级的打分标准,从“完全匹配”到“错误分支”,范围从-1到1。
-
推理裁判:只在答案基本正确时才激活,评估推理过程的质量——独立性(是否从基因证据推导而非复述问题)、稳健性(不同组织/疾病语境下推理是否依然成立)、因果充分性、粒度一致性和逻辑一致性。
-
事实验证模块:将推理链拆解成可独立验证的原子声明,与实际的基因表达数据一一核对。比如模型声称“CD8A高表达”,验证器就去原始数据中检查这一条。
最巧妙的设计是动态门控机制:在训练初期,模型能力弱,任务奖励占主导;当模型开始掌握任务后,事实约束逐渐介入;只有当模型达到一定水平后,完全的幻觉抑制才会激活。这就像一个导师先让学生自由发挥建立信心,再逐步引入严格的标准。
训练分三个阶段:持续预训练(让RVQ token在模型表征空间中扎根)→ 多任务SFT(教会结构化指令遵循和链式推理)→ RLVR(通过可验证的奖励信号优化推理质量和事实可靠性)。
实验结果:数据会说话
在8个留出数据集、11914个测试样本上的结果相当亮眼。
单细胞级别任务:RLVR训练后,免疫细胞识别准确率从70.7%提升到82.8%(+12.1个百分点),罕见神经母细胞瘤细胞从36.1%跃升至65.0%(+28.9个百分点),8个组织平均准确率达到83.6%。
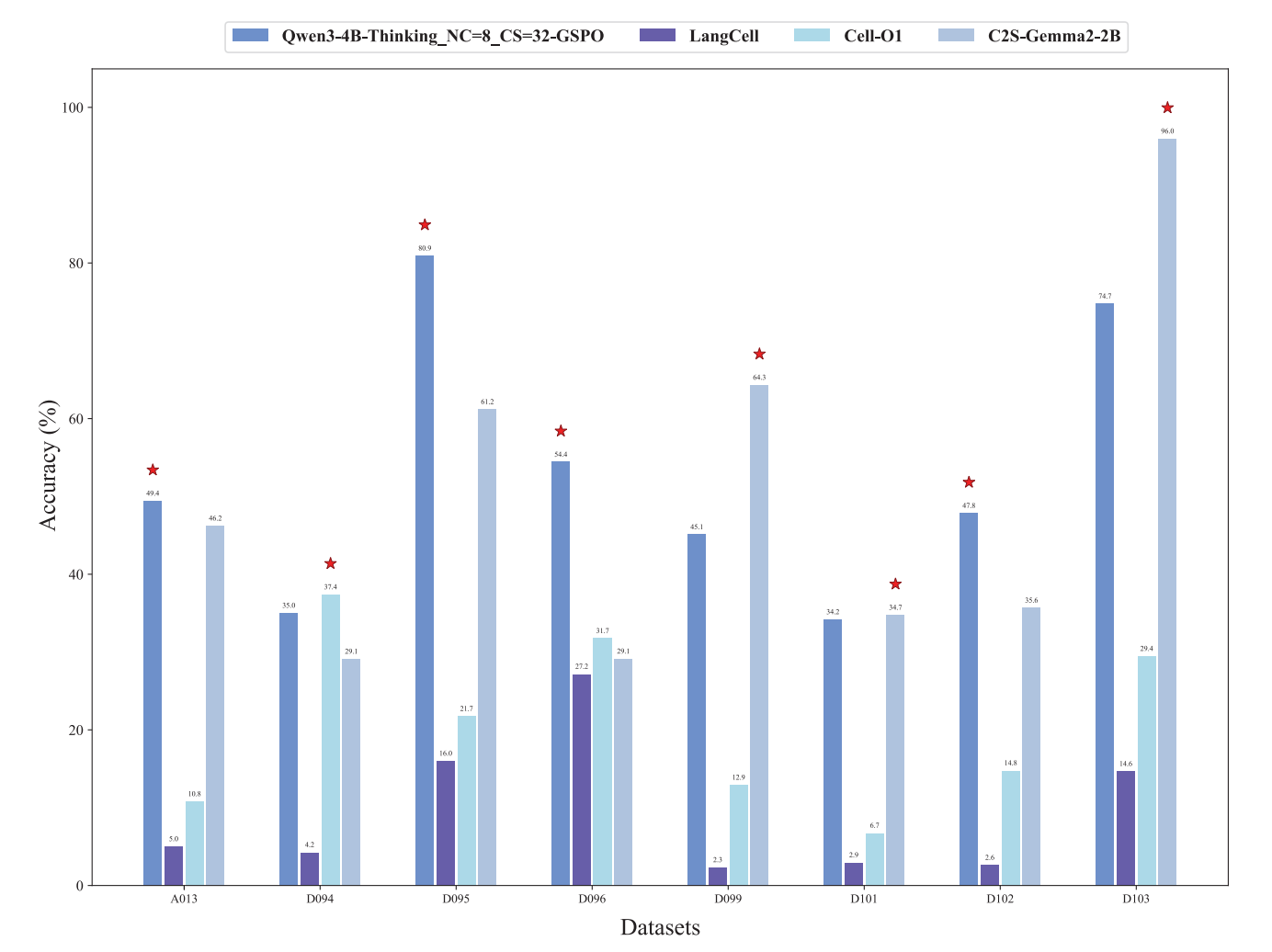
群体级别任务:这是真正的亮点。传统的单细胞方法几乎无法处理“一群细胞是什么”这样的群体级推理任务。RVQ-Alpha在细胞类型分类上从16.8%提升到78.0%(4.6倍),新冠肺炎疾病状态预测从33.1%翻倍到66.2%,组织类型识别从42.5%提升到71.3%。
消融实验:去掉证据优先约束,幻觉率从4.2%涨到23.7%;去掉事实验证模块,OOD准确率下降6.5个百分点,生物学上不合理的预测增加41%。
与竞品对比:在8个数据集中,RVQ-Alpha在4个上取得最佳成绩。值得注意的是,同期工作CellTok(也采用离散token化)虽然相关但无法直接比较——其模型权重尚未公开,且RVQ-Alpha在token效率(10 vs 34 tokens)、推理能力和训练策略上有明确优势。
意义与展望:AI虚拟细胞的基石
这项工作的深远意义在于,它首次真正实现了单细胞数据的理解与生成在统一的架构内完成。
一个细胞既是“可读的”(模型能分析它的状态)也是“可写的”(模型能生成它的表达谱)。这意味着什么?想象一下:
-
药物研发人员输入“某种药物处理后的基因表达变化”,模型直接输出对应的细胞状态token,再解码回完整的表达谱
-
罕见病研究:模型从大样本中学习正常细胞的状态分布,然后生成病理状态下的细胞,对比找出关键差异通路
-
个性化医疗:输入患者的单细胞数据,模型推理出疾病亚型和潜在药物靶点,同时用可解释的推理链给出依据
研究者明确将这项工作定位为“AI虚拟细胞”的基础设施。如果把细胞比作一个国家的经济体系,之前的方法要么只能做“经济普查”(记录数据),要么只能写“经济报告”(文本分析),而RVQ-Alpha第一次同时做到了“读懂经济运行规律”和“预测政策影响”——它既理解细胞现在是什么状态,也能想象细胞未来可能变成什么样子。
局限性:坦诚面对的挑战
论文的“局限性”部分写得相当诚实,避免了学术论文常见的“故作谦虚”。
首先,信息损失不可避免。将约2万个基因的连续表达值压缩成8个离散token,必然会丢失精细表达信息。对于需要精确量化表达变化的任务(比如计算差异表达倍数),这个方案可能不够。
其次,评估范围有限。目前的8个留出数据集仅限于人类样本,并非严格的“留一组织”或供体级别的分布外评估。泛化到其他物种、罕见病理状态仍需验证。
第三,计算成本不低。RLVR训练需要LLM裁判多次打分,每次查询增加约1秒延迟。在规模化训练中,裁判成本占据了大部分墙钟时间。
第四,单细胞VS群体推理的瓶颈:受限于上下文长度,目前群体级任务最多只能处理48个细胞。扩展到数千细胞的大规模图谱需要更高效的注意力机制。
在论文的收尾处,研究者抛出了一个值得深思的问题。如果说一个细胞可以被压缩成10个数字,而大模型能够学会“阅读”和“书写”这些数字,那么我们离构建真正的人工虚拟细胞还有多远?更根本地,当细胞的语言和人类的语言在同一个模型中交融,我们是否正在见证生物学范式的转变——从“描述”走向“创造”?当模型不仅能告诉你一个细胞是什么,还能生成它未来可能变成的样子,我们该如何定义“理解”在生物学中的真正含义?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)