【实战篇】非线性回归算法
文章目录
1 任务目标
在实际工程和科学实验中,非线性函数拟合是一个常见且重要的问题。指数函数作为典型的非线性函数,广泛应用于人口增长、放射性衰变、经济学和物理学等领域。本文通过一个完整的案例,展示如何对指数函数进行非线性回归分析,具体包括以下三个目标:
① 仿真生成一组非线性数据(指数函数),并添加噪声;
② 采用指数函数模型进行拟合求解;
③ 评估拟合误差并分析拟合质量。
2 数据生成
2.1 指数函数模型定义
我们采用的指数函数模型为:
y = a * exp(b*x) + c
其中,a 表示振幅系数,b 表示增长率系数,c 表示垂直偏移量。
在 Python 中,我们定义如下函数:
def exponential_func(x, a, b, c):
"""指数函数模型: y = a * exp(b*x) + c"""
return a * np.exp(b * x) + c
2.2 仿真数据生成
为模拟实际测量数据,我们在理想指数函数上添加高斯噪声,生成代码如下:
def generate_simulated_data(seed=42, n_samples=100, noise_level=0.1):
"""生成带有噪声的仿真数据"""
if seed is not None:
np.random.seed(int(seed))
# 真实参数
true_params = {
'a': 2.5, # 振幅
'b': 0.3, # 增长率
'c': 1.0 # 偏移量
}
# 生成x值
x = np.linspace(0, 5, n_samples)
# 计算理论y值
y_true = exponential_func(x, **true_params)
# 添加高斯噪声
noise = np.random.normal(0, noise_level * np.max(y_true), n_samples)
y_noisy = y_true + noise
return x, y_true, y_noisy, true_params
参数说明:
seed:随机种子,确保结果可重复n_samples:数据点数量noise_level:噪声水平,相对于 y 最大值的比例true_params:真实参数值,用于评估拟合效果
2.3 数据可视化
下图展示了理想指数曲线和添加 5% 噪声后的数据分布: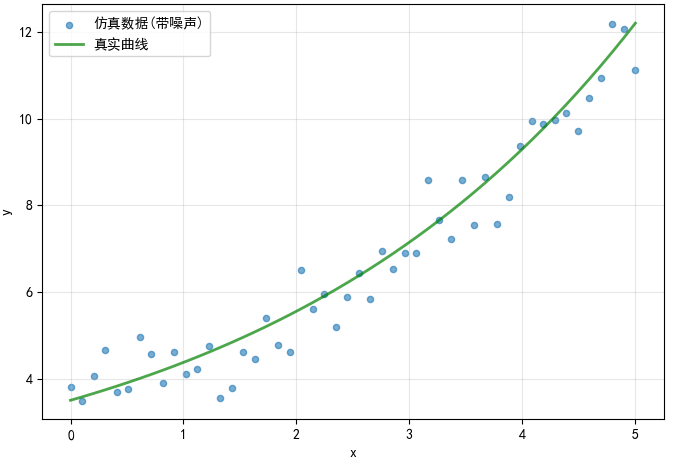
从图中可以看出,噪声数据在理想曲线周围随机分布,模拟了实际测量中的随机误差。
3 拟合求解
3.1 非线性最小二乘原理
对于非线性回归问题,我们采用最小二乘法进行参数估计。最小二乘法的目标是找到一组参数,使得模型预测值与实际观测值之间的残差平方和最小:
min Σ(y_i - ŷ_i)²
其中,y_i 是观测值,ŷ_i 是模型预测值。
3.2 实现代码
我们使用 SciPy 库中的 curve_fit 函数进行非线性回归:
def fit_exponential_model(x, y, initial_guess=None):
"""使用非线性最小二乘法拟合指数函数"""
if initial_guess is None:
initial_guess = [1.0, 0.1, 0.0]
# 使用curve_fit进行非线性回归
params, covariance = curve_fit(
exponential_func,
x,
y,
p0=initial_guess, # 初值
maxfev=10000, # 迭代次数
method='lm' # 方法选择
)
# 计算参数的标准误差
perr = np.sqrt(np.diag(covariance)) if covariance is not None else None
return params, perr, covariance
参数设置说明:
p0:初始猜测值,设置为[1.0, 0.1, 0.0]maxfev:最大迭代次数,设置为 10000method:优化方法,采用 Levenberg-Marquardt 算法(‘lm’)
3.3 拟合结果
下图展示了拟合曲线(红色虚线)与真实曲线的对比: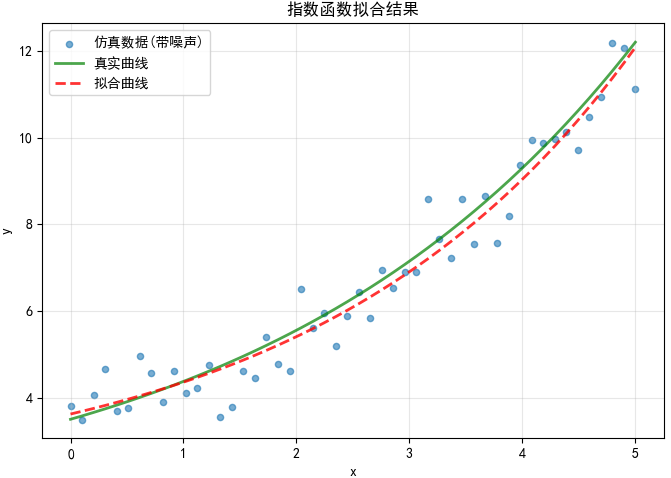
从图中可以看出,拟合曲线与真实曲线非常接近,表明模型能够较好地捕捉数据的指数增长趋势。
4 结果评估
4.1 评估指标
对于回归问题,我们采用以下四个常用指标评估拟合质量:
| 指标 | 公式 | 量纲 | 对异常值 | 用途 |
|---|---|---|---|---|
| R² | 1 - SS_res/SS_tot | 无 | 敏感 | 解释力,0-1,越高越好 |
| MSE | (1/n)Σ(y-ŷ)² | 原始平方 | 非常敏感 | 优化目标,比较模型 |
| RMSE | √MSE | 原始 | 敏感 | 解释误差大小 |
| MAE | (1/n)Σ|y-ŷ| | 原始 | 不敏感 | 稳健评估 |
其中:
- R²(决定系数):衡量模型解释数据变异的能力
- MSE(均方误差):预测误差平方的平均值
- RMSE(均方根误差):MSE 的平方根,与原始数据同量纲
- MAE(平均绝对误差):绝对误差的平均值
4.2 评估函数实现
def evaluate_fit(y_true, y_pred):
"""评估拟合质量"""
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
r2 = r2_score(y_true, y_pred)
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_true, y_pred)
metrics = {
'R²': r2,
'MSE': mse,
'RMSE': rmse,
'MAE': mae
}
return metrics
4.3 残差分析
下图展示了残差分布情况: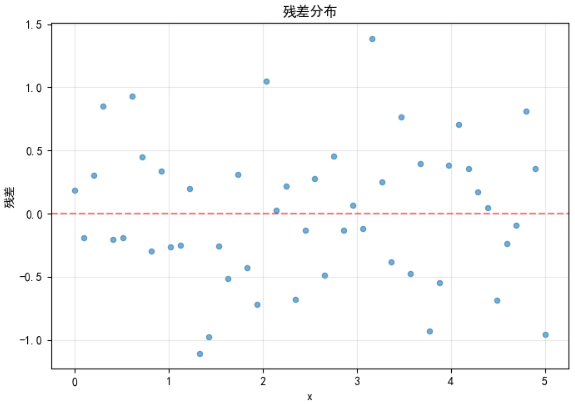
残差分析要点:
- 残差随机分布在零线周围,无明显模式
- 残差方差大致恒定,满足同方差性假设
- 无明显的离群点,表明模型对数据拟合较好
5 噪声水平对拟合效果的影响
5.1 实验设计
为研究噪声对拟合质量的影响,我们设置了四个不同的噪声水平:[0.01, 0.05, 0.1, 0.2],分别对应 1%、5%、10% 和 20% 的噪声水平。对于每个噪声水平,我们生成仿真数据并进行拟合,记录 R² 分数。
5.2 实现代码
# 子图4: 不同噪声水平下的拟合效果
noise_levels = [0.01, 0.05, 0.1, 0.2]
r2_scores = []
for i, noise in enumerate(noise_levels):
# 使用不同的整数种子
_, y_true_tmp, y_noisy_tmp, _ = generate_simulated_data(
seed=1000 + i, # 使用整数种子
n_samples=50,
noise_level=noise
)
params_tmp, _, _ = fit_exponential_model(x, y_noisy_tmp, initial_guess)
if params_tmp is not None:
y_pred_tmp = exponential_func(x, *params_tmp)
r2 = evaluate_fit(y_true_tmp, y_pred_tmp)['R²']
r2_scores.append(r2)
else:
r2_scores.append(0)
5.3 结果分析
下图展示了不同噪声水平下的 R² 分数变化:
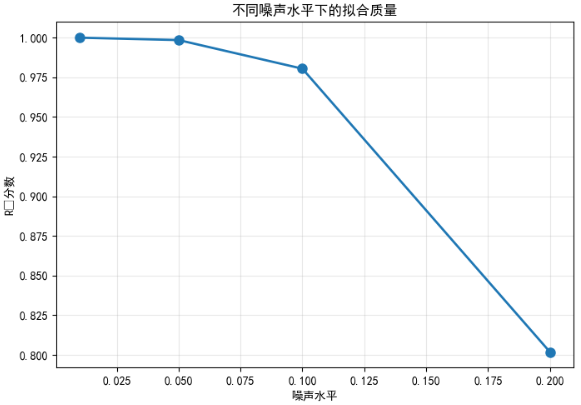
结果分析:
- 噪声水平为 1% 时,R² 接近 1.0,表明拟合效果极佳
- 噪声水平增加到 5% 时,R² 略有下降,但仍保持较高水平
- 噪声水平达到 20% 时,R² 明显下降,但仍能保持一定的解释力
- 整体趋势表明,噪声越小,拟合质量越高,这与理论预期一致
6 结论
本文通过完整的仿真实验,展示了指数函数非线性回归的全过程:
- 数据生成:成功生成了带噪声的指数函数仿真数据,模拟了实际测量场景
- 模型拟合:采用 Levenberg-Marquardt 算法实现了非线性最小二乘拟合,得到了准确的参数估计
- 结果评估:通过 R²、MSE、RMSE 和 MAE 等多个指标全面评估了拟合质量
- 噪声分析:验证了噪声水平对拟合质量的负面影响,为实际应用提供了参考
附录:完整代码
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 定义指数函数模型
def exponential_func(x, a, b, c):
"""指数函数模型: y = a * exp(b*x) + c"""
return a * np.exp(b * x) + c
# 2. 生成仿真数据
def generate_simulated_data(seed=42, n_samples=100, noise_level=0.1):
"""生成带有噪声的仿真数据"""
if seed is not None:
# 确保seed是整数
np.random.seed(int(seed))
# 真实参数
true_params = {
'a': 2.5, # 振幅
'b': 0.3, # 增长率
'c': 1.0 # 偏移量
}
# 生成x值
x = np.linspace(0, 5, n_samples)
# 计算理论y值
y_true = exponential_func(x, **true_params)
# 添加高斯噪声
noise = np.random.normal(0, noise_level * np.max(y_true), n_samples)
y_noisy = y_true + noise
return x, y_true, y_noisy, true_params
# 3. 非线性回归求解系数
def fit_exponential_model(x, y, initial_guess=None):
"""使用非线性最小二乘法拟合指数函数"""
if initial_guess is None:
# 如果没有提供初始猜测,使用简单启发式方法
initial_guess = [1.0, 0.1, 1.0]
# 使用curve_fit进行非线性回归
params, covariance = curve_fit(
exponential_func,
x,
y,
p0=initial_guess,#初值
maxfev=10000,#迭代次数
method = 'lm' # 方法选择
)
# 计算参数的标准误差
perr = np.sqrt(np.diag(covariance)) if covariance is not None else None
return params, perr, covariance
# 4. 评估拟合结果
def evaluate_fit(y_true, y_pred):
"""评估拟合质量"""
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
r2 = r2_score(y_true, y_pred)
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_true, y_pred)
metrics = {
'R²': r2,
'MSE': mse,
'RMSE': rmse,
'MAE': mae
}
return metrics
# 6. 主程序
def main():
print("=" * 60)
print("非线性回归求解指数函数系数")
print("模型: y = a * exp(b*x) + c")
print("=" * 60)
# 生成仿真数据
x, y_true, y_noisy, true_params = generate_simulated_data(
n_samples=50,
noise_level=0.05
)
print(f"真实参数: a={true_params['a']:.4f}, b={true_params['b']:.4f}, c={true_params['c']:.4f}")
print(f"数据点数: {len(x)}")
print(f"噪声水平: 5%")
# 非线性回归,最小二乘求解
print("\n" + "-" * 60)
print("非线性最小二乘法")
print("-" * 60)
# 初始猜测值
initial_guess = [1.0, 0.2, 0] #初始值
print(f"初始猜测: a={initial_guess[0]:.2f}, b={initial_guess[1]:.2f}, c={initial_guess[2]:.2f}")
# 拟合模型
params, perr, covariance = fit_exponential_model(x, y_noisy, initial_guess)
# 计算预测值
y_pred = exponential_func(x, *params)
# 评估拟合
metrics = evaluate_fit(y_true, y_pred)
# 计算残差
residuals = y_noisy - y_pred
# 可视化结果
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 子图1: 原始数据和拟合曲线
ax1 = axes[0, 0]
ax1.scatter(x, y_noisy, alpha=0.6, label='仿真数据(带噪声)', s=20)
ax1.plot(x, y_true, 'g-', linewidth=2, label='真实曲线', alpha=0.7)
if params is not None:
ax1.plot(x, y_pred, 'r--', linewidth=2, label='拟合曲线', alpha=0.8)
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax1.set_title('指数函数拟合结果')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 子图2: 残差图
ax2 = axes[0, 1]
if params is not None:
ax2.scatter(x, residuals, alpha=0.6, s=20)
ax2.axhline(y=0, color='r', linestyle='--', alpha=0.5)
ax2.set_xlabel('x')
ax2.set_ylabel('残差')
ax2.set_title('残差分布')
ax2.grid(True, alpha=0.3)
# 子图3: 参数搜索空间可视化
ax3 = axes[1, 0]
if params is not None and covariance is not None and perr is not None:
# 生成参数a的搜索范围
a_range = np.linspace(params[0] - 3 * perr[0], params[0] + 3 * perr[0], 50)
b_range = np.linspace(params[1] - 3 * perr[1], params[1] + 3 * perr[1], 50)
# 计算误差曲面
error_surface = np.zeros((len(a_range), len(b_range)))
for i, a_val in enumerate(a_range):
for j, b_val in enumerate(b_range):
y_tmp = exponential_func(x, a_val, b_val, params[2])
error_surface[i, j] = np.sum((y_noisy - y_tmp) ** 2)
# 绘制误差曲面
A, B = np.meshgrid(a_range, b_range)
contour = ax3.contourf(A, B, error_surface.T, levels=20, cmap='viridis')
ax3.scatter(params[0], params[1], color='red', s=100, marker='x', label='最优解')
ax3.scatter(true_params['a'], true_params['b'], color='yellow', s=100, marker='o', label='真实值')
ax3.set_xlabel('参数 a')
ax3.set_ylabel('参数 b')
ax3.set_title('参数搜索空间 (固定c)')
ax3.legend()
plt.colorbar(contour, ax=ax3)
# 子图4: 不同噪声水平下的拟合效果
ax4 = axes[1, 1]
noise_levels = [0.01, 0.05, 0.1, 0.2]
r2_scores = []
for i, noise in enumerate(noise_levels):
# 使用不同的整数种子
_, y_true_tmp, y_noisy_tmp, _ = generate_simulated_data(
seed=1000 + i, # 使用整数种子
n_samples=50,
noise_level=noise
)
params_tmp, _, _ = fit_exponential_model(x, y_noisy_tmp, initial_guess)
if params_tmp is not None:
y_pred_tmp = exponential_func(x, *params_tmp)
r2 = evaluate_fit(y_true_tmp, y_pred_tmp)['R²']
r2_scores.append(r2)
else:
r2_scores.append(0)
ax4.plot(noise_levels, r2_scores, 'o-', linewidth=2, markersize=8)
ax4.set_xlabel('噪声水平')
ax4.set_ylabel('R^2分数')
ax4.set_title('不同噪声水平下的拟合质量')
ax4.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 输出参数对比
print("\n" + "=" * 60)
print("参数对比总结")
print("=" * 60)
if params is not None:
print(f"{'参数':<10} {'真实值':<10} {'拟合值':<10} {'误差':<10} {'相对误差(%)':<15}")
print("-" * 60)
for i, (param_name, true_val) in enumerate(zip(['a', 'b', 'c'], true_params.values())):
fitted_val = params[i]
error = abs(true_val - fitted_val)
rel_error = 100 * error / abs(true_val) if true_val != 0 else float('inf')
print(f"{param_name:<10} {true_val:<10.4f} {fitted_val:<10.4f} {error:<10.4f} {rel_error:<15.2f}")
# 运行主程序
if __name__ == "__main__":
main()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 39
39 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)