python学习-xx12-1 numpy【⭐】
numpy可以简单的认为是和列表类似的容器的对象(可以简单理解为多维列表,但实际要比列表复杂),里面也可以存储任意对象,它的底层是C实现的,所以比python效率要高,并且提供多种方法
1 简介(pandas会比numpy更好)
numpy:开源的python科学计算模块,用于数据快速处理;
numpy支持矩阵与数组操作,计算速度快,是Python中科学计算的基础库;
numpy优点:
1:底层使用C语言实现,计算速度快
2:numpy支持均值,累积和,方差等运算,可以直接使用;
3:numpy处理数据方式灵活,支持excel, csv等多种方式数据导入;
2 安装
方式1:pip install numpy
方式2:anaconda环境:自带numpy,不用安装
numpy官方文档: https://numpy.org/doc/ (https://numpy.org/doc/) numpy
源码: https://github.com/numpy/numpy
3 使用
3.1 导入
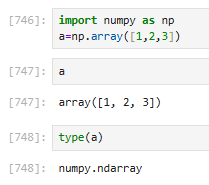
使用np.array()创建对象
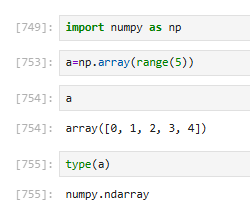
3.2 创建ndarray
3.2.1 ndarray基本概念
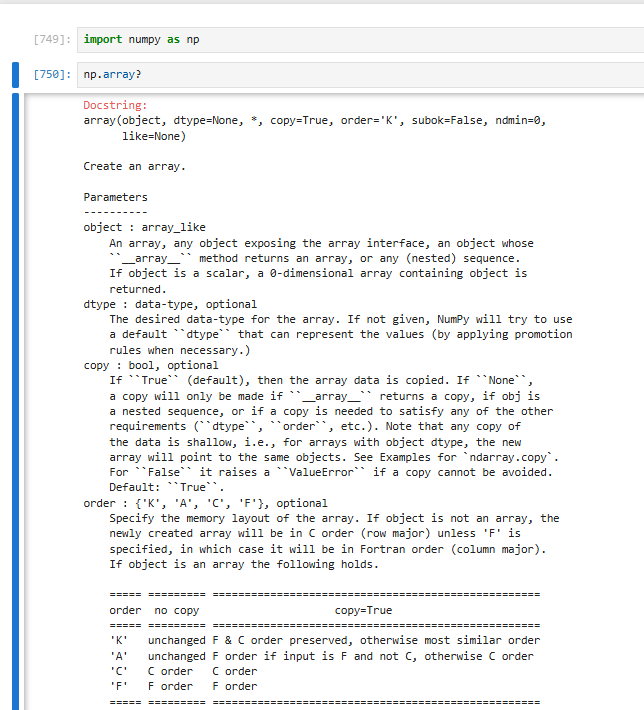
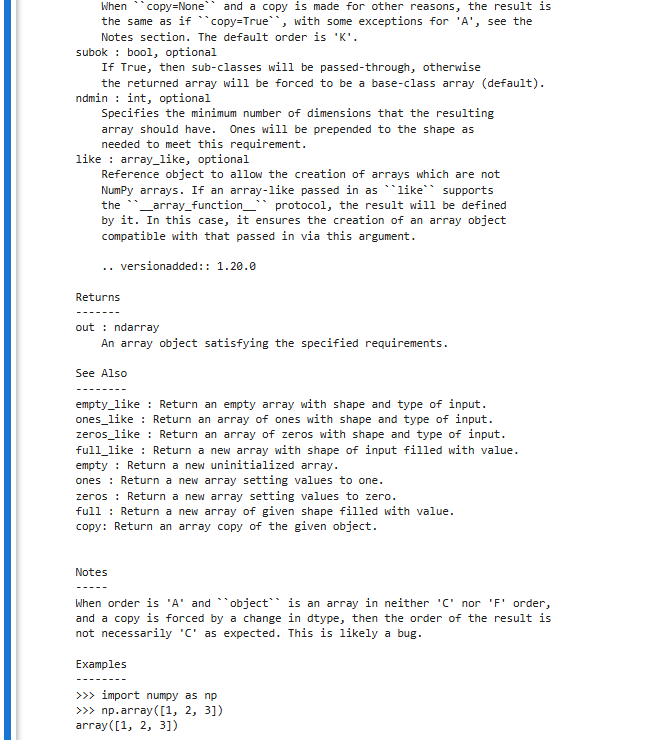

np.array() = 把 Python 列表 / 元组 / 数据 → 变成 NumPy 数组(ndarray)
关键参数(只记这 4 个就够)
① object(必须传):将各种类型的数据转换为数组
你要转成数组的数据:列表、元组、数字、其他数组都行。
② dtype(指定数据类型)
③ ndmin(强制最小维度)
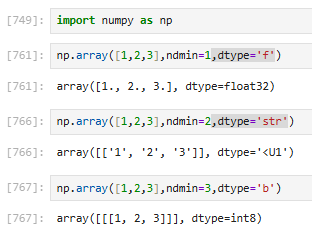
④ copy(是否复制数据)
默认 True = 复制一份False = 不复制,直接用原数据(尽量别乱改)
3.2.2 ndarray的轴和秩
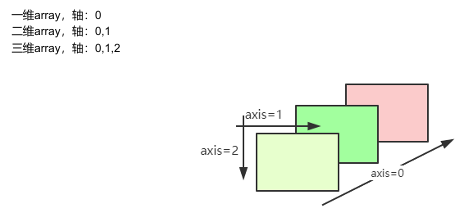
轴(axis)::每一个线性的数组称为是一个轴
第一个轴(axis=0):第一层数组,
第二个轴(axis=1):数组里的数组
依次类推;
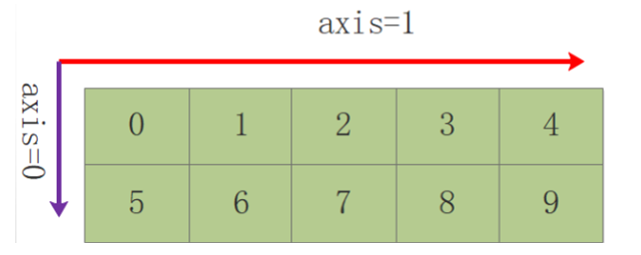
数组中轴的拆解:最外面一层是0轴,依次往里增加
按照轴进行相应计算,需要清楚按的是哪个轴计算
3.2.3 ndarray相关属性

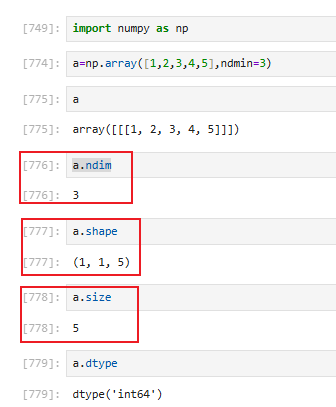
3.2.4 【⭐】创建ndarray对象(基本方式)

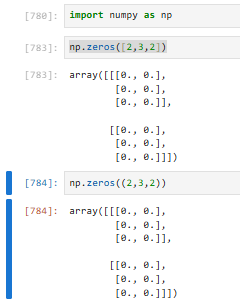
3.2.4.1 np.zeros【0数组】

传入参数用列表和元组是等价的
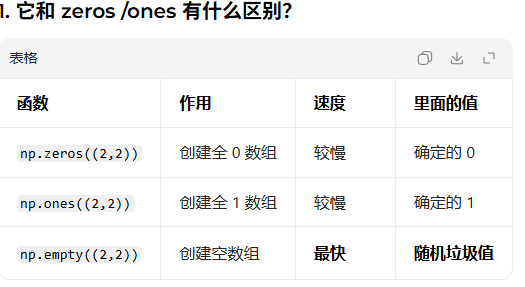
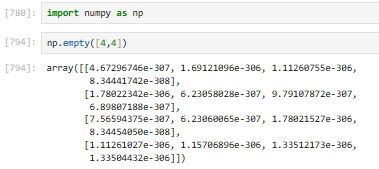
3.2.4.2 np.empty【空数组】
快速创建一个指定形状的数组,但不初始化值(里面是随机垃圾数)

3.2.4.3 np.ones【1数组】

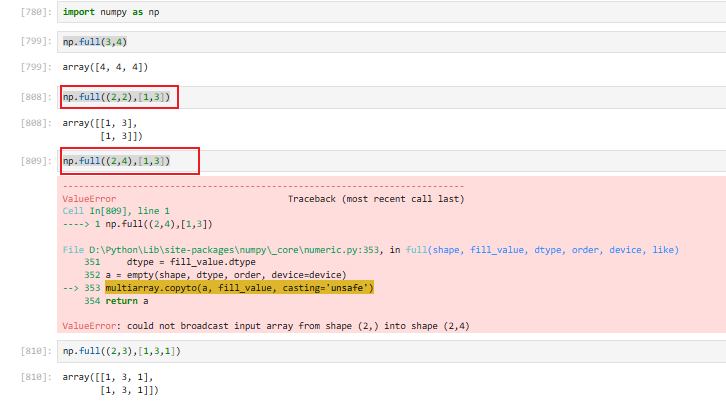
3.2.4.4 np.full【任意填充数组】
创建一个指定形状,所有元素都等于你指定值的数组

如果以数组为填充值,那么填充的形状一定要适配填充值的形状,不然会报错的
zeros 和 ones 就是 full 的特例!
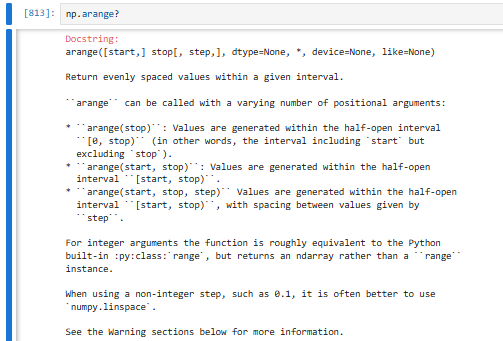
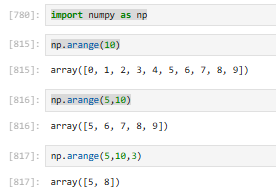
3.2.4.5 np.arange【NumPy 版的 range,生成一段连续数字的数组】
左闭右开:包含起点,不包含终点
np.arange(stop)→ 0 ~ stop-1np.arange(start, stop)→ start ~ stop-1np.arange(start, stop, step)→ 按步长走- 左闭右开,不含终点
- 整数用它,小数用 linspace(arange精度不太好)


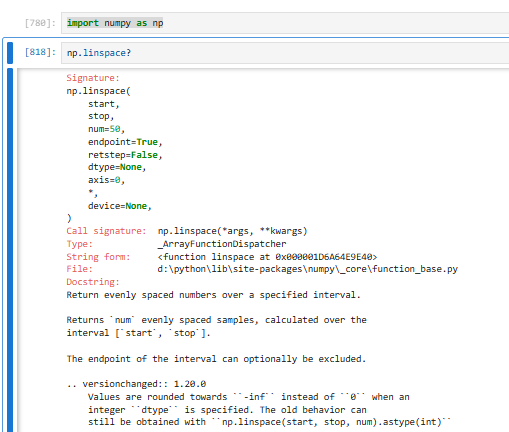
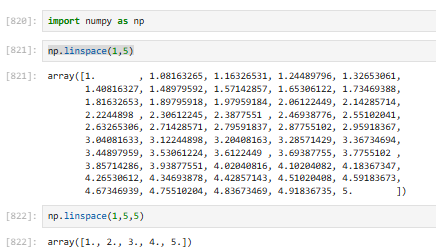
3.2.4.6 np.linspace【线性数组⭐】
生成一段均匀间隔的数字数组,你直接指定要多少个数 **,它自动算步长 **
np.arange:你定步长,自动算个数(不包含结尾)np.linspace:你定个数,自动算步长(默认个数是50)(包含结尾)
✅ linspace 默认包含起点和终点
✅ 小数、整数都非常稳定,不会出错

 \
\
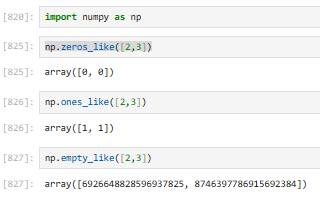
3.2.4.7 np.zeros_like/empty_like/ones_like/full_like【仿写数组⭐】
创建和指定数组形状一样的0/1/空数组
✅ zeros_like = 克隆数组形状 → 填 0
✅ 不用手动写 shape,更安全
以np.zeros_like为例:


3.2.5 创建ndarray对象(使用随机数:np.random相关方法)


3.2.5.1 np.random:
专门给数组生成随机数的工具它生成的直接是 NumPy 数组,适合科学计算、矩阵、批量数据。
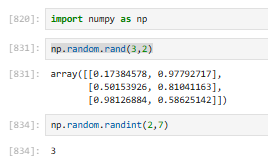
3.2.5.2 np.random.rand(shape):生成 0~1 之间均匀随机数组,给出指定维度的随机数
np.random.rand(2, 3) # 2行3列
3.2.5.3 np.random.randint(low, high, size):生成整数随机数组
np.random.randint(0, 10, size=(2,3)) # 0~9 的整数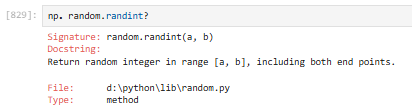
3.2.5.4 np.random.random(size):和 rand 类似,0~1 随机数
np.random.random((2, 3))
注意与.rand()的区别,一个给的是形状,一个给的是更直接的尺寸
3.2.5.5 np.random.randn(shape):生成标准正态分布(均值0,方差1)

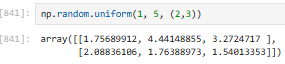
3.2.5.6 np.random.uniform(low, high, size)
指定范围均匀随机小数
3.2.5.7 np.random.normal(均值, 标准差, size):正态分布

3.2.5.8 np.random.choice(arr, size):从数组里随机选择
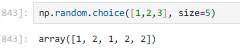
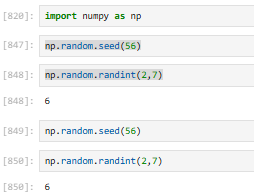
3.2.5.9 np.random.seed():固定随机种子,让结果可复现
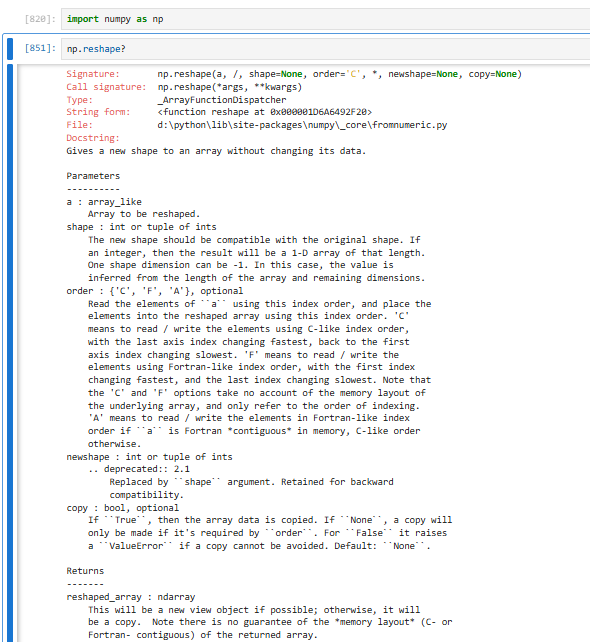
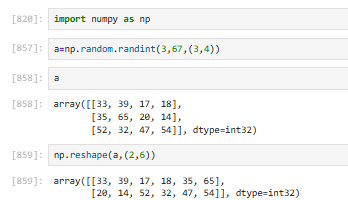
3.2.6 【⭐】创建ndarray对象(reshape(指定的形状)方法【将数组格式重新定义】)
重置形状的数组元素的个数要与原数组一致




3.2.7 创建ndarray对象(ndarray对象转其他数据结构)
将arange格式转换为其他数据结构:列表、字符、文件等等
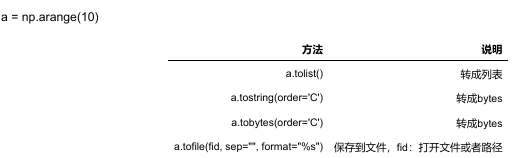
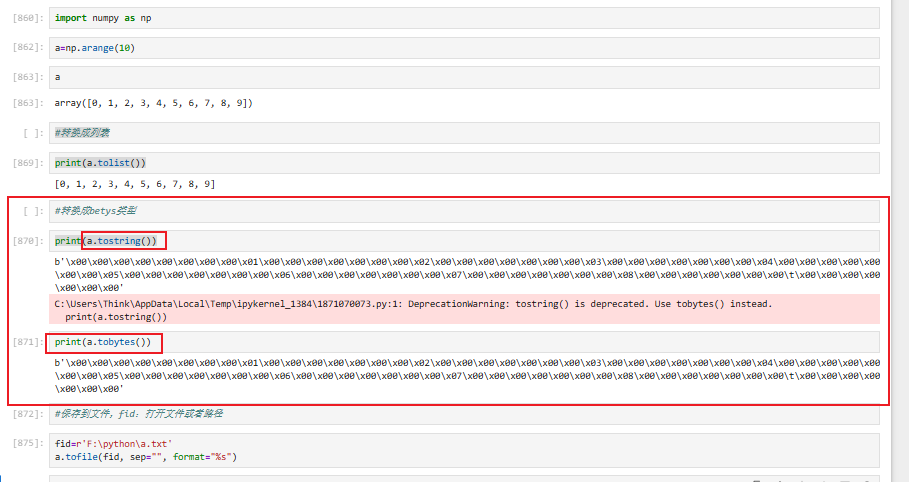
3.3 ndarray的数据类型
常用的有整数、浮点和字符串
例如整数:int8:8位有符号的整数,uint16:16位无符号的整数

3.3.1 查看数据类型
3.3.1.1 np.sctypeDict(将简写的数据类型转换为标准的numpy格式,查询字典)
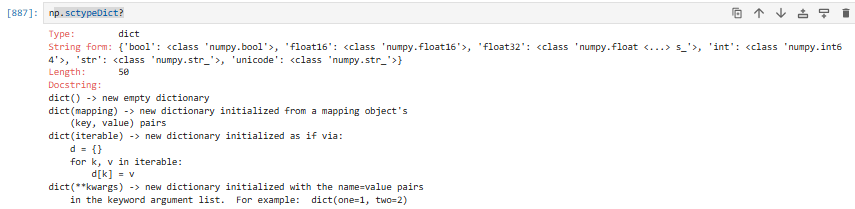
这是一个 Python 字典(dict),长度 50,是 NumPy 内部用来管理数据类型对应关系的核心字典。
键(key):类型名字符串(如 'bool', 'int', 'float32')
值(value):真正的 NumPy 类型对象(如 numpy.bool_, numpy.int64)
包含:整数、浮点数、复数、布尔、字符串、时间、对象、简写符号


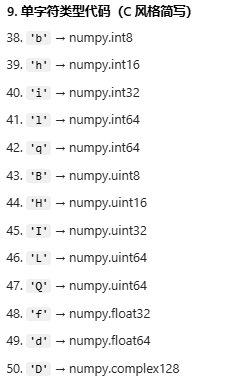
使用方式:当做字典使用即可
比如:直接在创建数组时,用dtype指定即可,将指定类型标准化为numpy类型
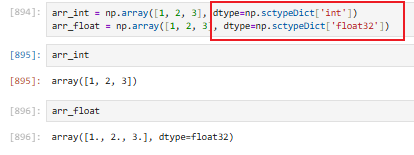
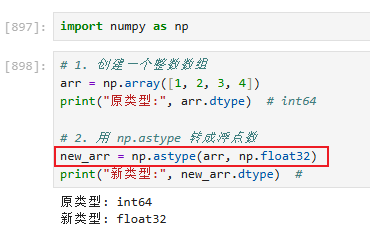
3.3.1.2 类型转换:obj.astype(数组,转换的类型)【将当前类型转换为指定的类型】


使用:

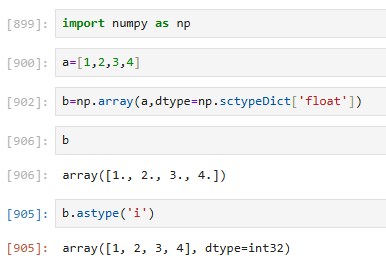
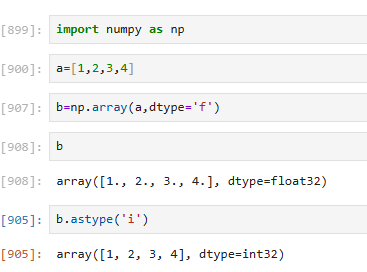
指定时也可直接等于类型,只是可能没有那么标准

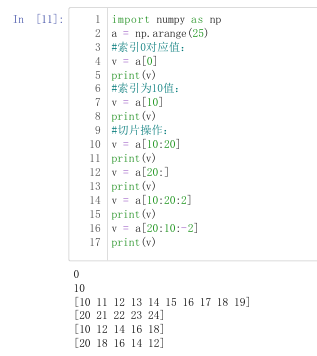
3.4 ndarray访问与修改(切片访问)
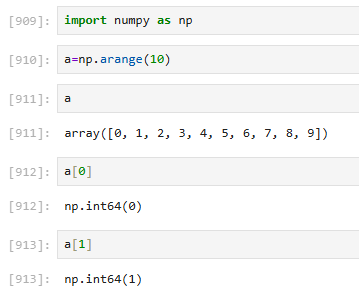
3.4.1 一维array(和列表一样 [索引] )
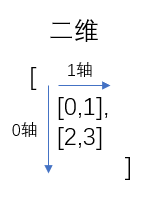
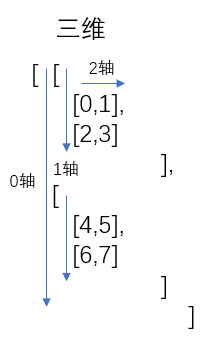
3.4.2 理解numpy中的轴
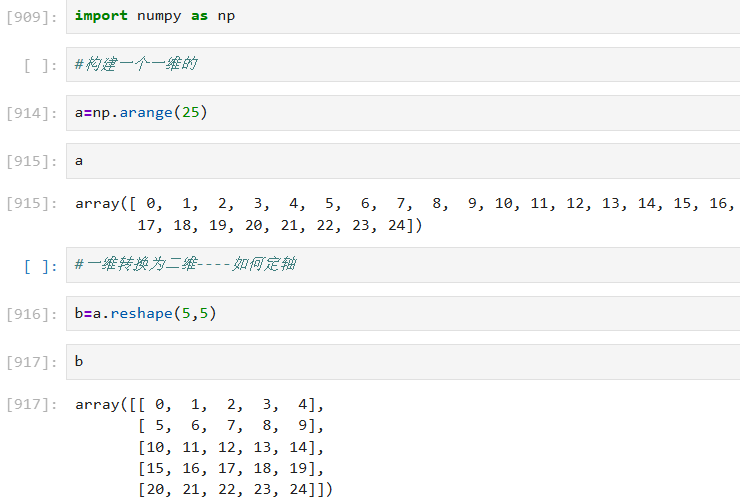
实例:
二维拆解
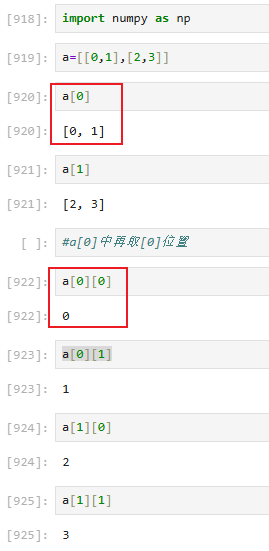
三维拆解
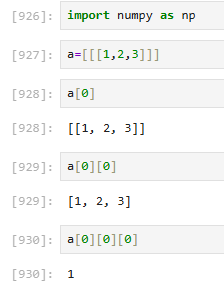
3.4.3 二维array
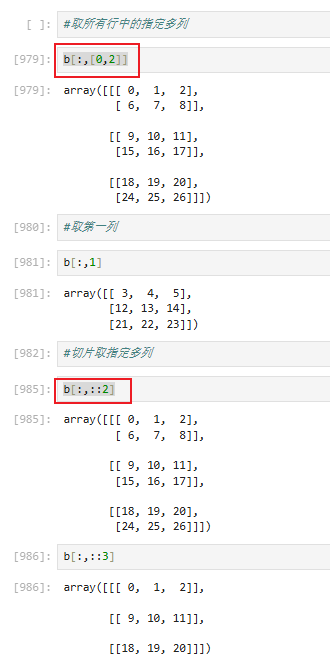
切片:[起始索引 : 结束索引 : 步长]
3.4.4 三维array
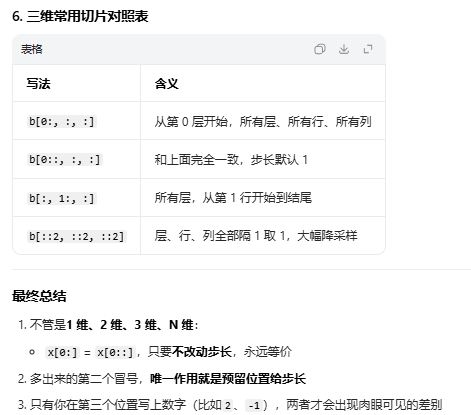
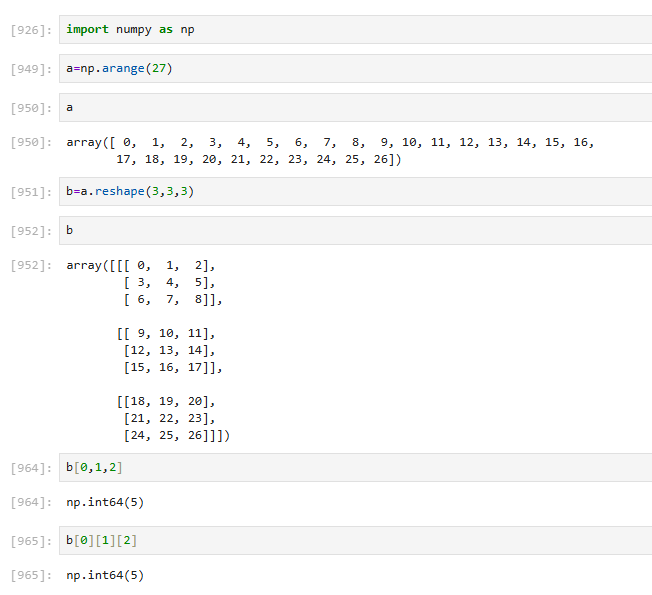
3.4.5 多维数据取值【⭐】
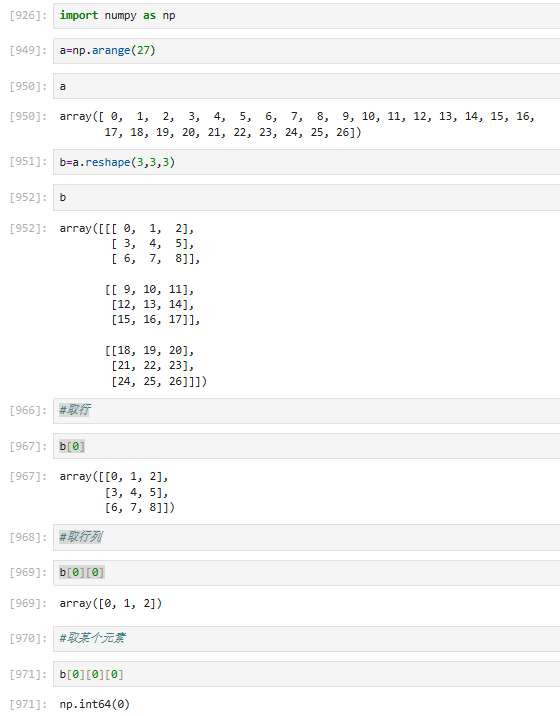
注意多括号和单括号的不同
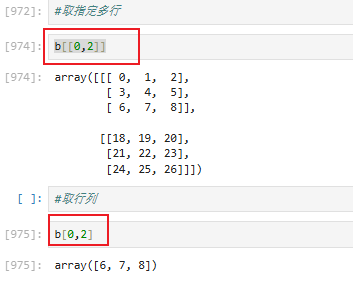
第二个实际取的是11和22
第三个实际取的是111和222
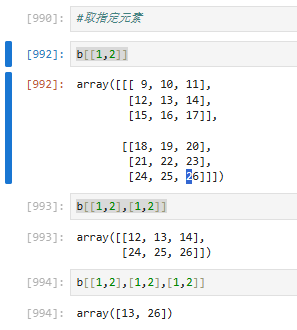
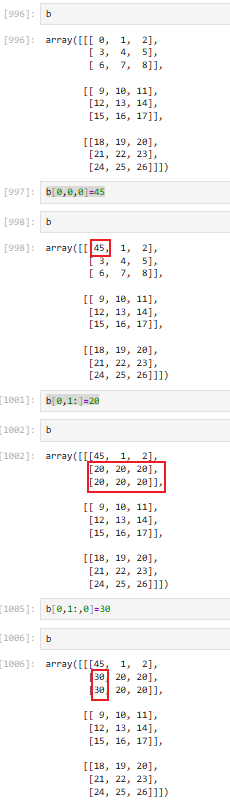
3.4.6 array修改
直接在array上修改即可
3.5 numpy计算
3.5.1 numpy广播:boardcasting
定义一个列表,想让其元素每一个都加一
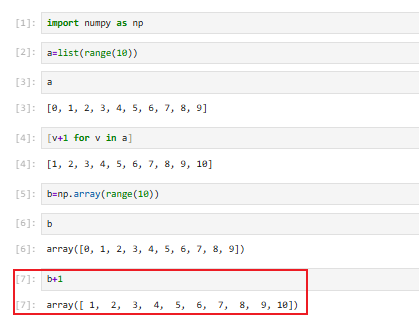
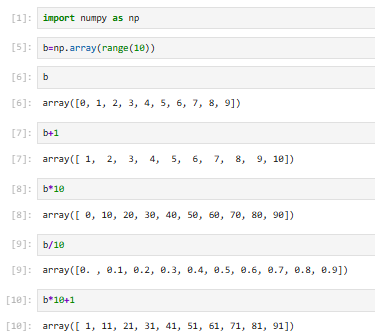
这是numpy的一种广播操作:基本运算都会被应用到array的所有元素中【前提是np.array才行】
【加减乘除均可】比list要简单
3.5.2 array之间的计算
两个array之间进行运算维度一定要相同
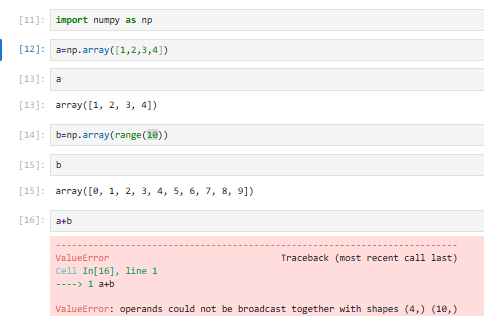
两个array之间的运算发生在对应的元素上,这也是为什么需要维度一样(一维中是做真正的运算操作)
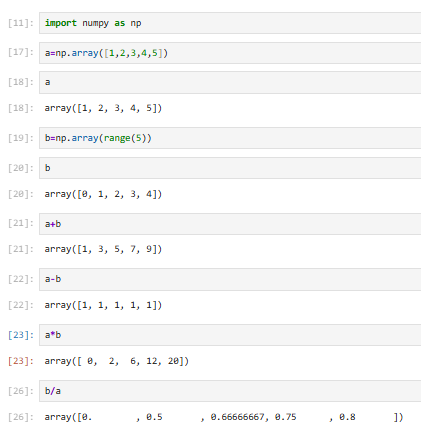
3.5.3 多维array计算
基本运算也是对应元素进行的
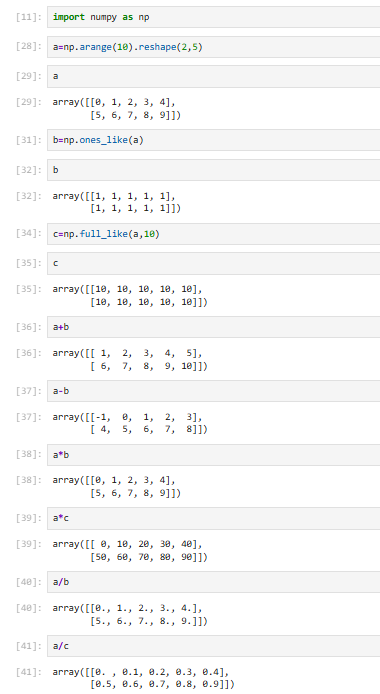
3.5.4 array之间计算注意点
①shape不同不能计算
②一维array与多维array的行相同,可以计算
③一维array与多维array的列相同,可以计算
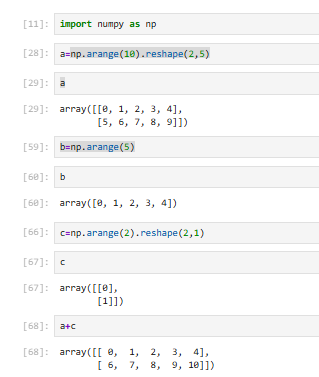
【会将一维array按行/列广播到相同shape再对应相加,只有一维的可以扩展】
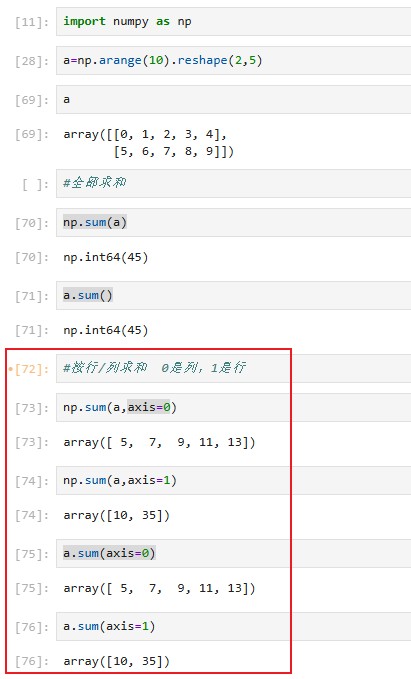
3.5.5 numpy统计相关算法
主要包括:求和,均值,方差,累积和等

其他方法:

numpy模块与array对象都支持这些方法,使用方式也类似,我们来看一种即可;
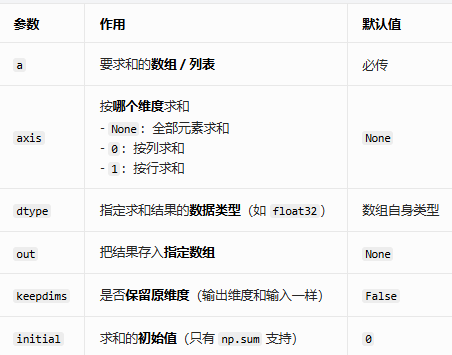
这些方法参数类似,我们以sum为例: np.sum(a,axis=None,dtype=None,out=None,keepdims=,initial=)
a.sum(axis=None, dtype=None, out=None, keepdims=False)
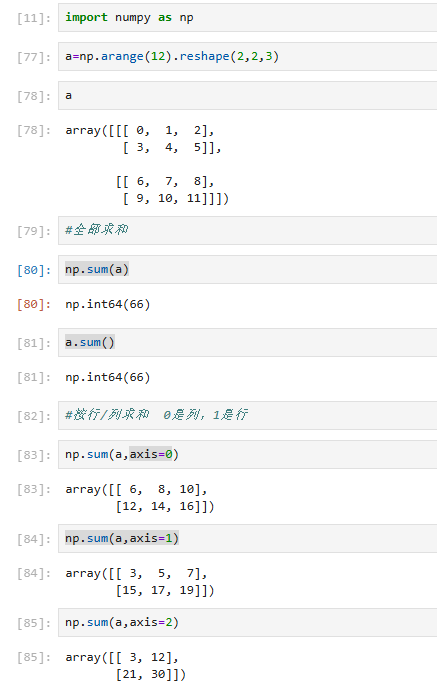
三维的,注意按哪个轴处理的形式是什么样的
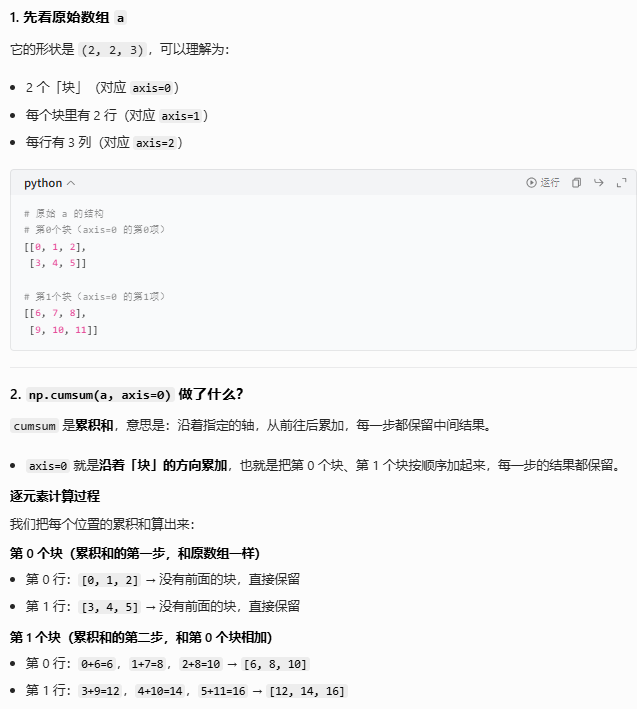
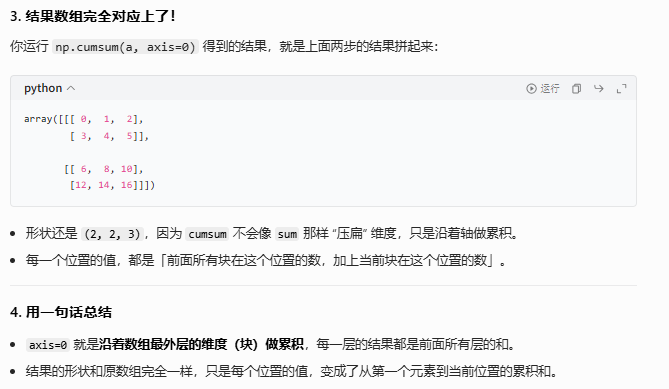
#累加和:[a[0], a[0]+a[1], a[0]+a[1]+a[2], ...]

3.6 numpy数据拼接分割
应用场景:多个数据的拼接或者拆分

3.6.1 多个array拼接
注意:在列表中可以用+进行拼接,但在array中+是一种计算
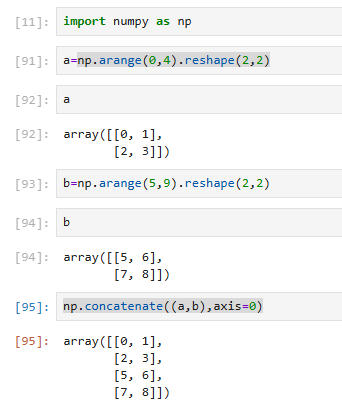
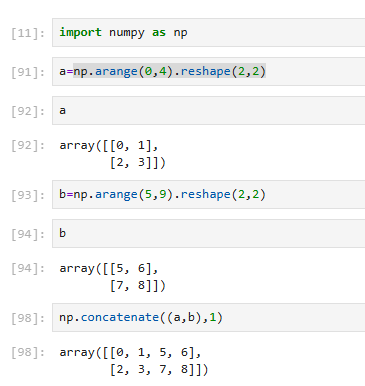
拼接方法:concatenate((a1, a2, ...), axis=0, out=None)
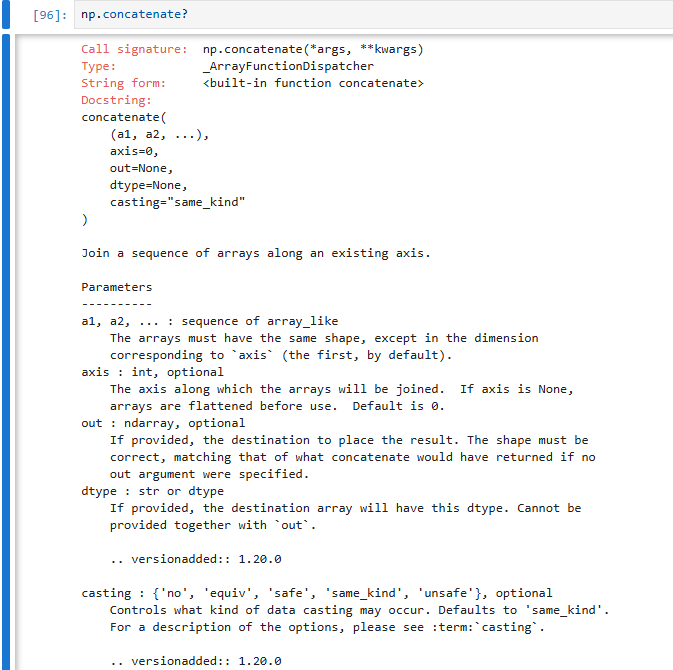


np.concatenate 拼接 = 沿着指定 axis 把数组 “粘起来”
-
把多个数组 沿着 axis 方向拼接
-
不会新增维度,只是在现有维度上延长
-
除了拼接方向的维度,其他维度必须完全一样
二维数组(最常用)shape=(行,列)
-
axis=0 → 上下拼接(竖着粘)【按行】
-
axis=1 → 左右拼接(横着粘)【按列】
三维数组 shape=(块,行,列)
-
axis=0 → 块与块拼接(前后叠)
-
axis=1 → 行拼接(每页内上下加行)
-
axis=2 → 列拼接(每行内左右加列)
3.6.2 多个array(数组)的堆叠【使用概率较小】
注意拼接和堆叠的不同:新建一个轴,把数组叠在新轴上 → 维度 +1
np.stack(arrays, axis=0, out=None)


基本理解:arrays,沿着axis进行堆叠,类似穿起来,而不是拼接
拼接不会增加数组的维度,但是堆叠会增加一维
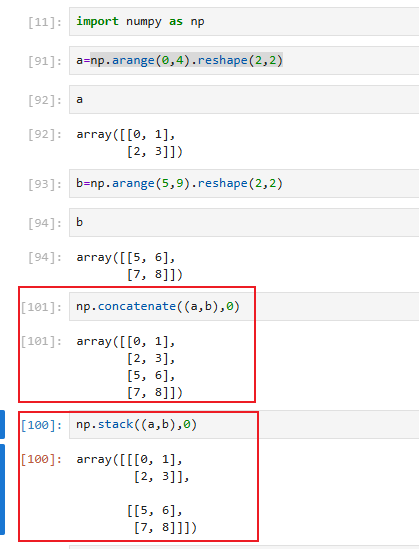
注意不同轴的结果


3.6.3 np.hstack和np.vstack(拼接)
它们不会新增维度,只是横着 / 竖着拼起来,等价于 concatenate 的简化版



示例:
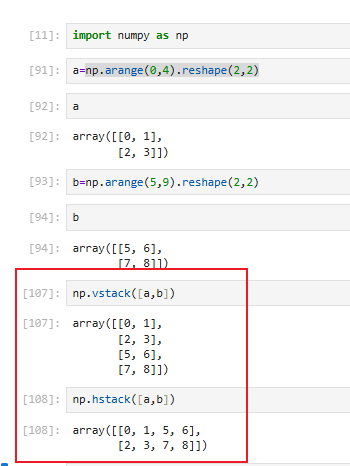
3.6.4 numpy的分割
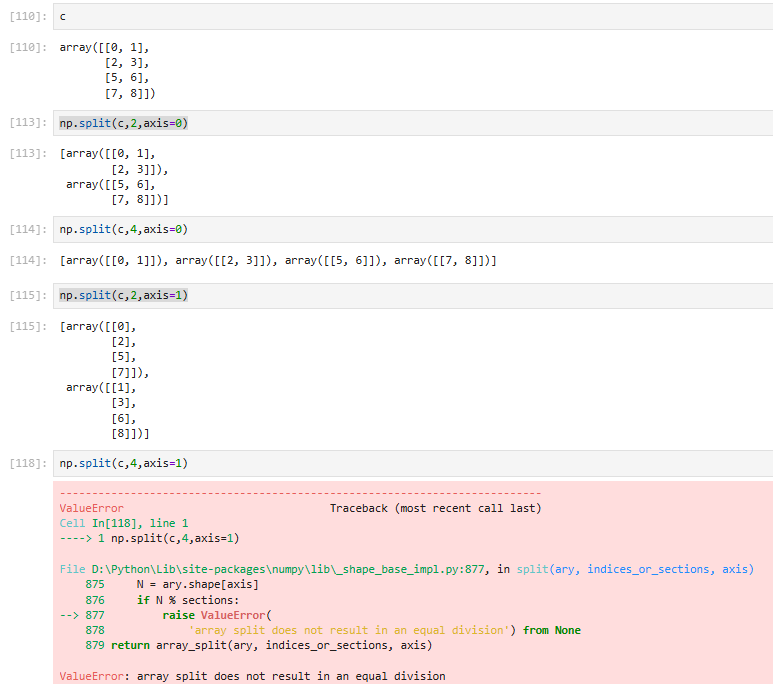
split方法:将制定的array按照aixs分割成制定值
np.split(ary, indices_or_sections, axis=0)
把一个数组,沿着指定的轴,切成多份。
- 是 concatenate 的反向操作
- 切完维度不变
- 不会增加维度,不会减少维度,只是拆分开
- ary:要切的数组
- indices_or_sections:
- 填一个数字 → 平均切成几份
- 填一个列表 → 在第几号位置切(如
[2,5])
- axis:沿着哪个轴切
axis=0→ 上下切(切行)axis=1→ 左右切(切列)


示例:
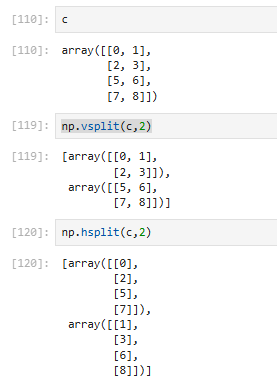
3.6.5 np.vsplit和np.hsplit(np.vstack和np.hstack的反操作)
vsplit沿着垂直轴切分
hsplit沿着水平轴切分
3.7 numpy其他操作
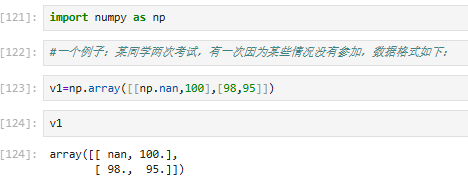
3.7.1 缺省值(nan以及其他缺省值的处理)
①概念
缺省值就是一些缺失数据,一般用nan进行表示
Nan是nunpy和pandas中用于标识缺失数据
None是Python 中对象,不能与Nan混淆一起
示例:
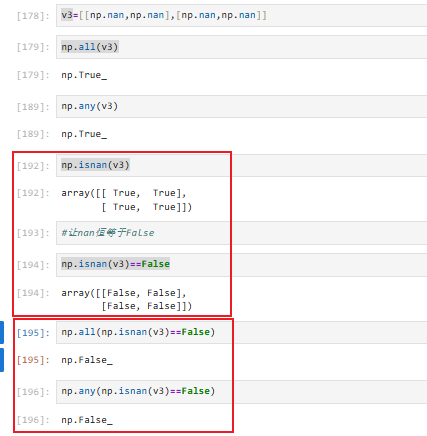
②nan的判断(np.isnan(对象))
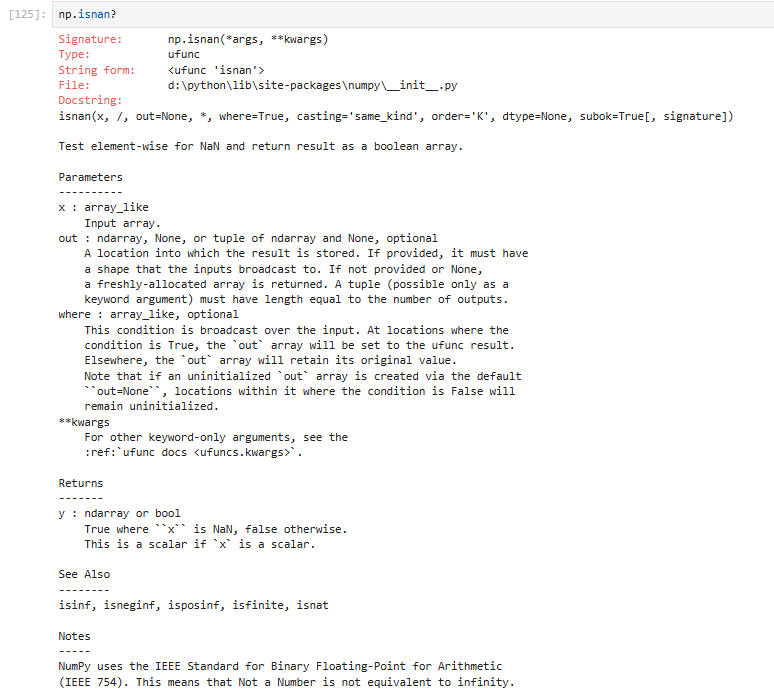

逐元素进行判断
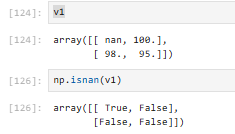
isnan不支持包含有None的操作
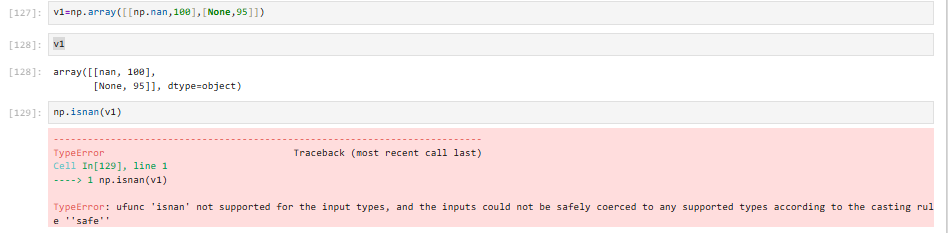
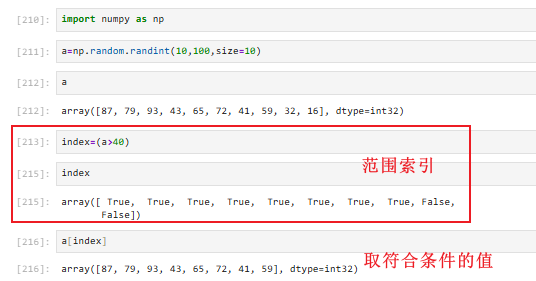
3.7.2 判断和bool索引(可以获取nan的索引)
array的值都为True或者False
例如:array([[False, False],[ True, False]]) 获取所有nan值:
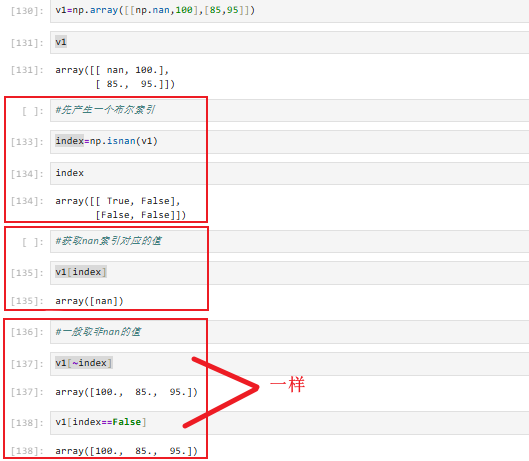
3.7.3 all和any的使用(真假的判断,判断有没有假数据)
①np.all(a, axis=None, out=None, )
沿着给定的axis判断是否有元素为0,为0返回False,不设置axis,判断所有元素
(沿着给定的axis判断元素,都为真返回True,否则返回False,不设置axis,判断所有元素 )
②np.any(a, axis=None, out=None, )
沿着给定的axis判断是否有元素不为0,为0返回False,不设置axis,判断所有元素
(沿着给定的axis判断元素,都为假返回False,否则返回True,不设置axis,判断所有元素 )
注意:np.nan在all和any的眼中也是真的,也是数,只有0和False才会被判识为假
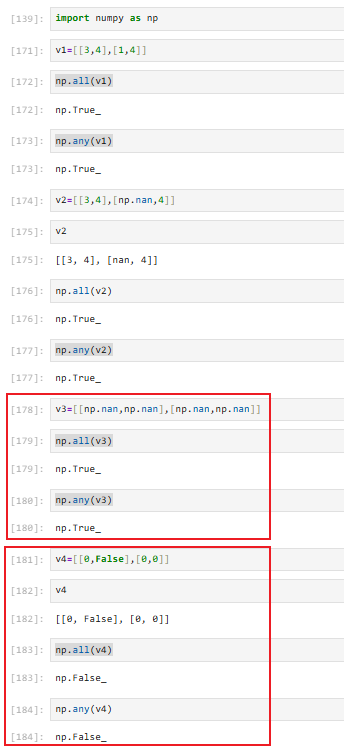
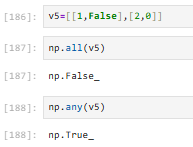
所以如果要判断缺失值,需要先判别缺失值为假才可以
利用条件构建布尔索引,再去符合条件的值

3.7.4 where的基本操作(⭐常用)
where(condition, [x, y]):
如果给定x,y,满足条件condition,输出x,不满足输出y;
如果没有x,y,返回满足条件对应的值的索引;
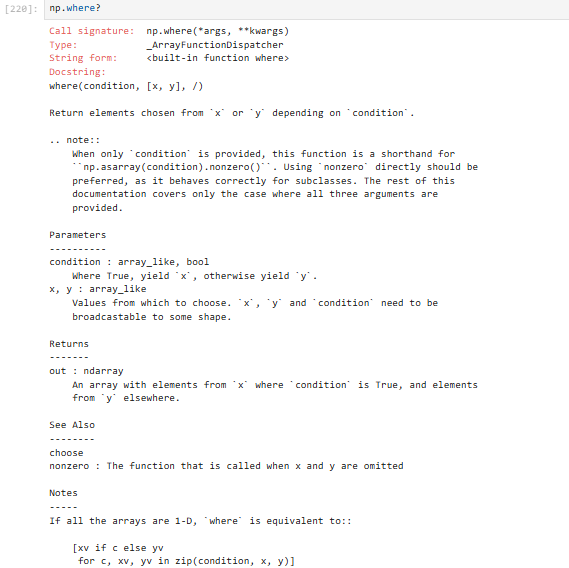

示例:条件赋值
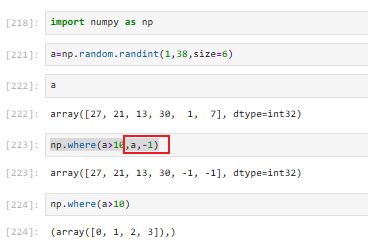
示例:随机生成成绩单,判断是否及格
直接给条件值赋值有可能不正确,因为数据类型不用,但是用where可以,判别后更改值

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)