从机器学习到AI大模型:深度解析Transformer、多模态与未来趋势!
本文深入探讨了机器学习的发展脉络,重点解析了深度学习、AI大模型及其核心技术Transformer。内容涵盖了AI大模型在大规模数据处理、自然语言处理、计算机视觉等领域的应用,并详细介绍了Transformer的自注意力机制及其在多模态模型中的关键作用。此外,文章还分析了多模态大模型的发展趋势,以及ChatGPT、Sora等前沿模型的训练原理和世界模型在通用人工智能中的潜在应用。
1 机器学习:以设定规则+数据喂养驱动算法自成长
机器学习>神经网络>深度学习≈深度神经网络。机器学习用于解决由人工基于 if-else 等规则开发算法而导致成本过高的问题,想要通过帮助机器 “发现” 它们 “自己”解决问题的算法来解决;机器学习可以分为有监督学习、无监督学习和强化学习等三类。
◼ 深度学习是基于深度神经网络的,而神经网络算法是机器学习模型的一个分支 , 包 括 卷 积 神 经 网 络CNN/循环神经网络RNN等等,自注意力机制(Transformer)则是基于全连接神经网络和循环神经网络的衍生。
◼ 深度学习使用多层神经网络,从原始输入中逐步提取更高层次更抽象的特征用于后续算法识别,处理大规模数据是其核心优势。当前,深度学习已经应用到包括图像识别、自然语言处理、语音识别等各领域。
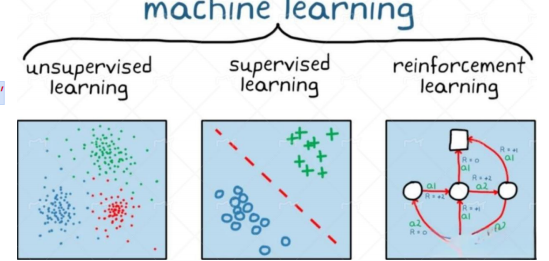
机器学习
2 大模型:大规模参数赋能神经网络,持续优化
AI大模型是指具有超大规模参数(通常在十亿个以上)、超强计算资源的机器学习模型,其目标是通过增加模型的参数数量来提高模型的表现能力,它们能够处理海量数据,完成各种复杂任务。
AI大模型的原理是基于神经网络和大量数据的训练,模型通过模拟人脑的神经元结构,对输入数据进行多层抽象和处理,从而实现对复杂任务的学习和预测。AI大模型的训练主要分为:数据预处理、模型构建、横型训练、模型评估等几大步骤,如下:
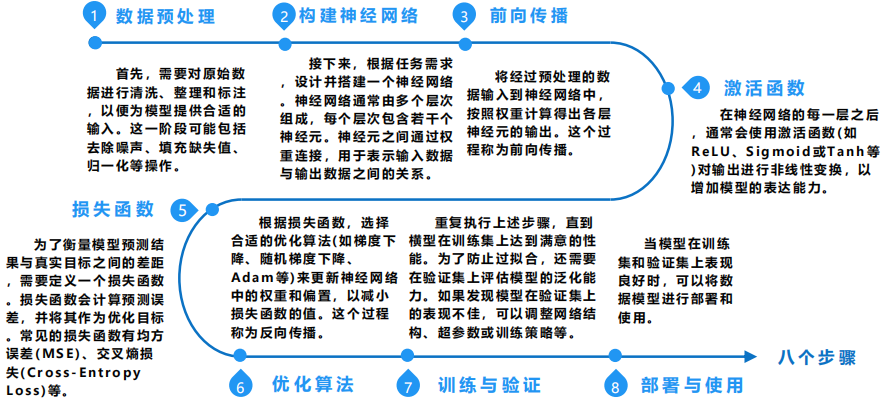
AI 算法训练
3 大模型:强泛化为核心优势,聚焦自然语言处理
AI大模型能够处理以下几类核心问题:1)自然语言处理:以GPT-3和BERT为例, AI大模型通过学习海量的语料库和上下文,让计算机更加准确地理解和处理自然语言,如翻译、问答、分词、文本生成等领域。2)计算机视觉:以ResNet和EficientNet为例,AI大模型通过学习大量的图像数据和构建更深更复杂的神经网络,使计算机能够对图像进行更加准确的识别和分析,包括目标检测、图像分类、语义分割等领域。3)语音识别和生成。通过以上几类问题的解决,AI大模型可以进一步通过自动化和智能化的方式提高生产效率,在部分工业领域可以实现人机合作或自动化,减少人力成本。
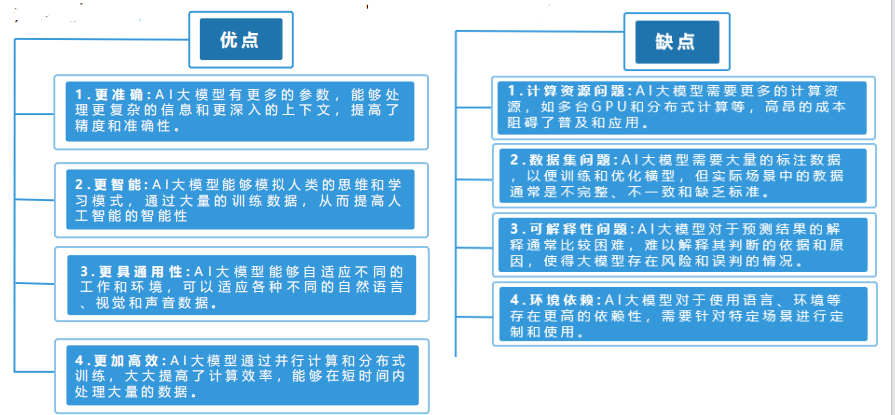
AI大模型的优劣势分析
4 Transformer:架构变化的核心,多模态理解的关键
◼ Transformer是本轮大模型颠覆全行业算法架构的核心,也是多模态模型相比之前单一文本理解模型提升的关键,Transformer赋予算法更精准的特征提取能力,强化理解和识别功能,其独特的自注意力机制是灵魂,即Attention is all you need。
◼ Transformer的优势在于:1)自注意力机制赋予的长依赖语义问题(捕捉间隔较远的词之间的语义联系问题);2)支持并行计算,可极大的提升大模型数据处理效率。
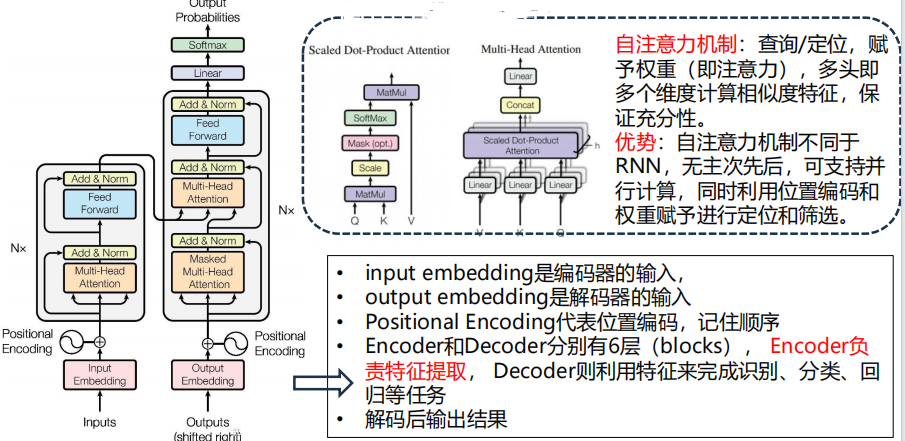
Transformer的原理机制
5 多模态大模型:多类别数据输入,算法不断进化
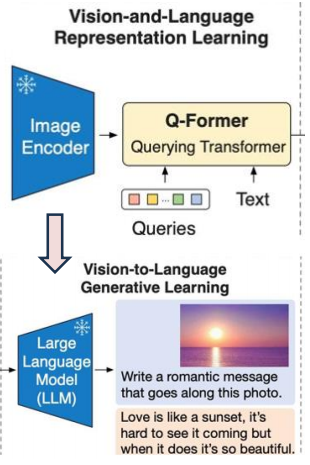
由理解内容至生成内容,多模态大语言模型持续进化。多模态模型是一种能够处理多种类型数据(如文本、图像、音频和视频)的人工智能模型。这种模型的目标是通过结合不同类型的数据来提供更全面、更准确的信息。在自然语言处理(NLP)领域,多模态模型可以用于机器翻译、情感分析、文本摘要等任务。在计算机视觉领域,多模态模型可以用于图像分类、目标检测、人脸识别等任务。多模态大语言(MM-LLMs)即是将多模态模型与具备强大推理和生成能力的大语言模型结合的产物,其难点在于如何对齐本不兼容的图像/视频/文本等的编码器。
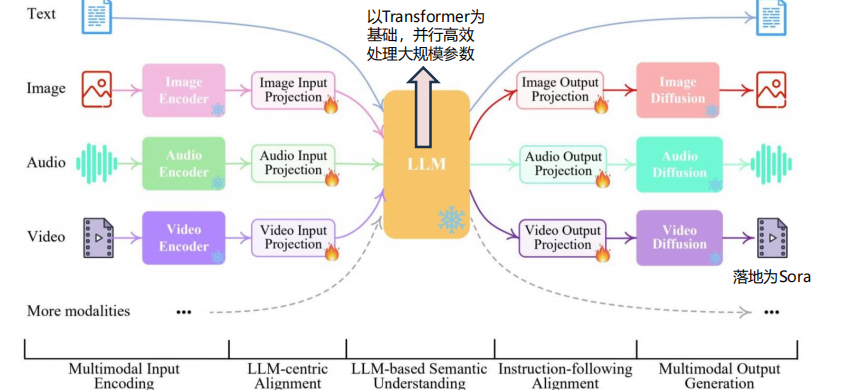
多模态大模型
6 算法框架:ViT为核心,多模态融合生成任务
视觉表征主框架由CNN切换Transformer,即ViT,其多头自注意力机制赋予模型并行高效计算以及把握前后长时间依赖关系的能力,能够同时接收来自文本/图像/音频/视频的特征Token,并接入全链接层服务于下游的分类任务。ViT成功的秘诀在于大量的数据做预训练,如果没有这个过程,在开源任务上直接训练,其效果仍会逊色于具有更强归纳偏置的CNN网络。
◼ ViT步骤分为三大步:
➢ 图 形 切 块 Patch Embedding ; 位 置 编 码 PositionEmbedding;
➢ 特征提取Class Token;注意力权重赋予TransformerEncoder;
➢ 多头输出MLP Head。
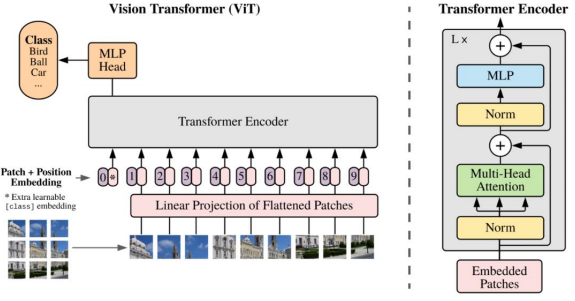
VIT
7 CHAT GPT横空出世,持续进化引领AIGC浪潮
GPT1:用Transformer的解码器和大量的无标签样本去预训练一个语言模型,然后在子任务上提供少量的标注样本做微调,就可以很大的提高模型的性能。
◼ GPT2: Zero-shot,在子任务上不去提供任何相关的训练样本,而是直接用足够大的预训练模型去理解自然语言表达的要求,并基于此做预测。但GPT2性能差,有效性低。
◼ GPT3:few-shot learning,兼顾少样本和有效性。用有限的样本,模型可以迅速学会任务。
◼ GPT4:GPT1~3本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型能够收敛,因此不具备文本生成能力。 ChatGPT则在此基础上,依赖指令学习(Instruction Learning)和人工反馈强化学习(RLHF)进行训练,对原有模型进行有监督的微调(人工优化数据集)+强化学习对模型生成结果进行打分,提高泛化能力,在此基础上loss持续迭代,生成正确结果。相比GPT3规模大幅提升,从1750亿提升至1.8万亿,算力需求大幅提升。
GPT4o:完全统一多模态。o即omni,意为 “全体”、“所有” 或 “全面的”,打通多模态间输入交互,延迟降低并完全开放免费,并进一步增强推理能力。但其依然是基于Transformer架构去实现对于模态信息的理解和生成,因此并未有底层架构的创新。
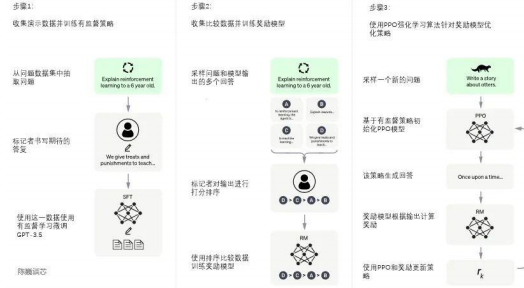
ChatGPT模型的训练过
8 Sora发挥DiT模型优势,利用大数据实现文生视频
Sora模型充分利用扩散模型(Diffusion Model)精细化生成能力以及Transformer的前后文全局关系捕捉能力,实现视频每一帧的图像精确生成以及前后的时空一致性。
◼ Sora可以理解为是Open AI大模型技术的完全集成,其原理可以分为三步:1)首先,模型将视频压缩到低维潜在空间中,然后将其分解为patch(类似于GPT中的Token),从而将视频完全压缩。2)其次,视频patch在低维空间中训练,扩散模型通过在训练数据上逐步添加高斯噪声并学习如何逆向去除噪声的过程来生成新数据,并整合了Transformer的多头注意力机制和自适应层归一化,提升扩散模型在处理连续大规模视频数据时的稳定性和一致性。3)最后,模型通过对应解码器,将生成的元素映射回像素空间,完成视频生成任务。
◼ Sora的核心DiT模型:Transformer架构取代原有UNet架构(本质为CNN卷积神经网络),提升长时间性能的同时具备可扩展性+灵活性,并支持跨领域扩展,或可应用至自动驾驶领域。
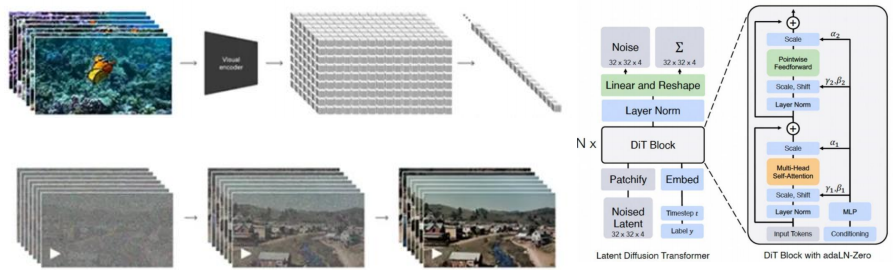
Sora文生视频,DiT模型为基础原理
9 世界模型:通用人工智能AGI,预测未来
视频生成Video Generation是世界模型World Model的基础,Sora的成功使得DiT扩散模型收敛为视频生成的主导方式。基于对历史信息的理解生成对于未来的预测进而合理表征,并结合可能的行为action进一步辅助预测可能的结果,可应用于包括直接的视频生成以及自动驾驶和机器人等通用人工智能多个领域。
◼ 基于数据,超越数据。传统大模型要适应新的精细任务时,必须基于数据对模型参数进行全面微调,依赖【预训练】环节,不同任务与不同数据一一对应,模型专业化。相比过往大模型强调的模态信息理解的能力,世界模型更加注重【因果和反事实推理、模拟客观物理定律】等规划和预测的能力,并具备强泛化和高效率等性能表现。
世界模型
10 围绕Transformer/LSTM构建的世界模型运行
传统的多子函数模块化算法演变为世界模型数据闭环训练,持续优化提升算法认知。世界模型在进行端到端训练的过程为:
◼ 观测值经过V(基于Transformer的Vision Model,图中为早先采用的VAE架构)提取feature,然后经过M(基于LSTM的Memory)得到h(预测值), 最后预测值和历史信息合并至C(Controller)得到动作, 基于动作和环境交互的结果产生新的观测值,保障车辆做出合理行为。
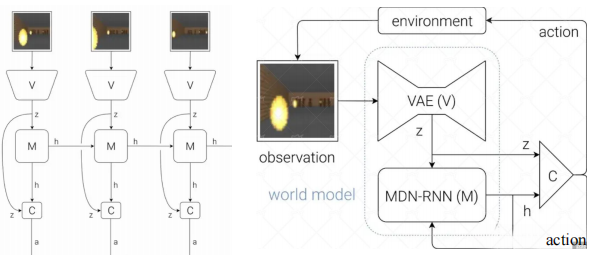
传统模块化算法架构【V+M+C】转变为端到端【VM输出C】
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
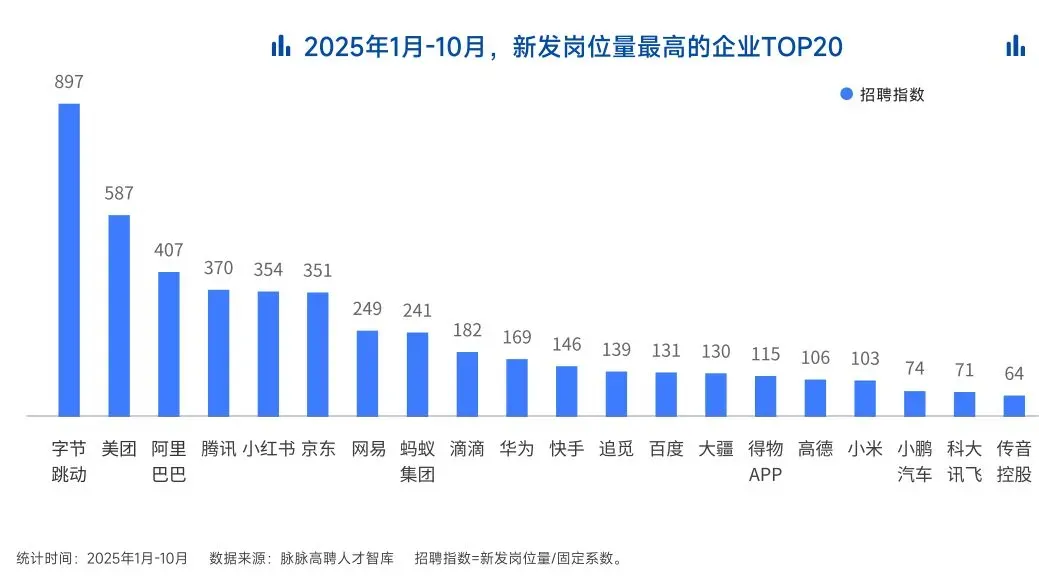
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

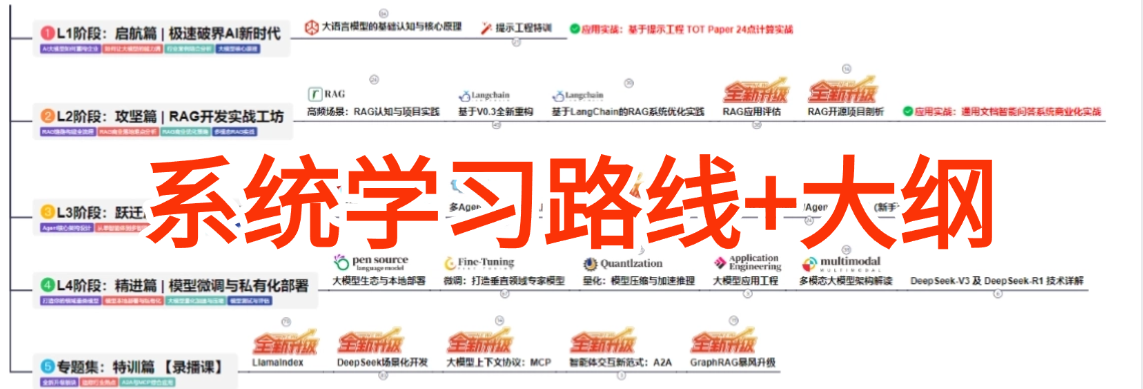
② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献121条内容
已为社区贡献121条内容

所有评论(0)