LangChain核心技巧:优雅解决大模型上下文限制
智能体开发必学的关键技术,让你的应用告别token超限烦恼
今天我们带大家深入探讨LangChain中一个至关重要的技术——Summarization Middleware(总结中间件)。
一、问题的本质:上下文窗口的局限

所有大模型都有一个固有的限制:上下文窗口。
• GPT-4:128K token
• DeepSeek:64K token
• 国内多数模型:通常更少
在现实应用中,这个限制很快就会成为瓶颈:
• UI自动化测试:整个HTML页面+截图base64编码,轻松超限
• 长文档处理:几万字的文章生成需要多次交互
• 智能客服:上百轮对话需要保持连贯记忆
粗暴的截断方案行不通,因为会破坏上下文的连贯性。我们需要更智能的解决方案。
二、Summarization Middleware:智能的上下文管理者
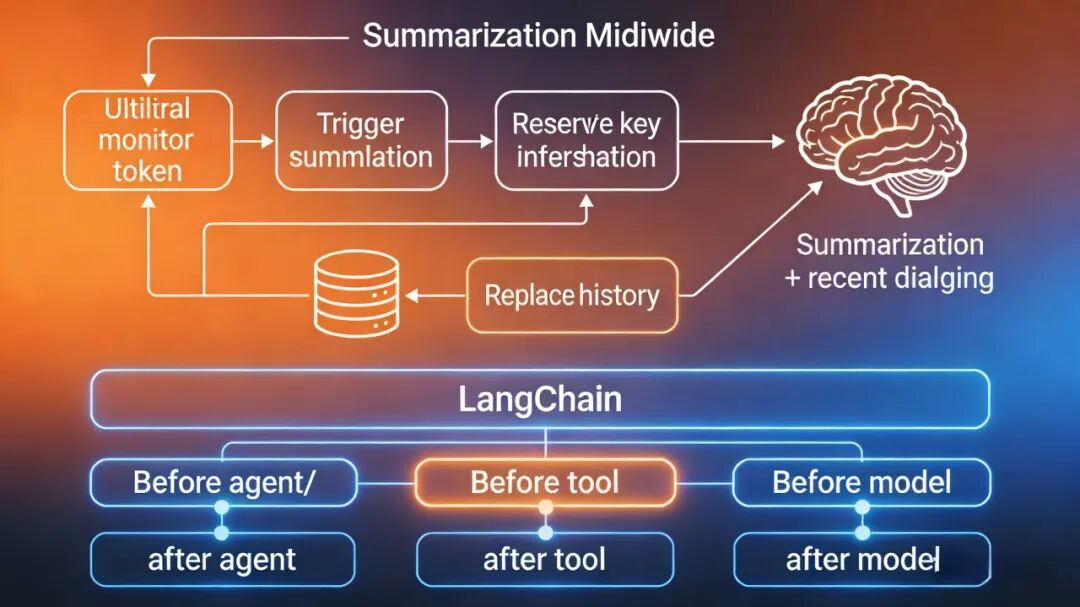
核心思想:智能压缩,而非简单截断
总结中间件的工作原理类似于人脑的记忆机制:记住要点,忘掉细节。
它会在发送给大模型之前,对历史对话进行智能分析:
1. 实时监控token数量
2. 触发总结当达到预设阈值
3. 生成摘要保留关键信息
4. 替换历史用摘要+最近对话继续
技术架构:像Spring AOP一样的切面编程
在LangChain中,中间件可以在多个位置介入:
• before_agent / after_agent:智能体执行前后
• before_tool / after_tool:工具调用前后
• before_model / after_model:模型调用前后
总结中间件主要在before_model阶段工作,确保输入不超过限制。
三、实战配置:三步搭建智能上下文管理

步骤1:基础配置
python
from langchain.middleware import SummarizationMiddleware
# 创建中间件
summarization_middleware = SummarizationMiddleware(
llm=ChatOpenAI(model="gpt-4o-mini"), # 总结专用模型
trigger="tokens", # 触发条件类型
trigger_value=3000, # 3000token时触发
keep_messages=5, # 保留最近5条消息
)步骤2:高级配置选项
触发条件灵活选择:
• trigger="tokens":精确控制成本(如5000token)
• trigger="messages":简单场景(如20条消息)
• trigger="fraction":自适应(如容量的60%)
保留策略按需调整:
python
# 保留最近5条消息
keep_messages=5
# 或保留1500个token
keep_tokens=1500
# 或保留20%的容量
keep_fraction=0.2步骤3:优化总结提示词(最关键!)
默认提示词可能不够精准,自定义提示词能大幅提升效果:
python
summary_prompt = """
请总结对话历史,特别注意:
1. 核心问题与用户的核心需求
2. 已提供的解决方案和达成的结论
3. 待处理的后续任务和未解决的问题
4. 所有重要的事实、数据、ID、日期等信息
要求:
- 保留所有关键决策点
- 用简洁的语言表达
- 结构化输出关键信息
"""四、实际应用案例
案例1:智能客服系统
例如在电商智能客服项目中,我们实现了:
python
# 电商客服中间件配置
customer_service_middleware = SummarizationMiddleware(
llm=ChatOpenAI(model="gpt-4o-mini"),
trigger="tokens",
trigger_value=6000,
keep_messages=6,
summary_prompt="总结客户问题、已提供的帮助、待处理事项..."
)
# 集成用户确认中间件(重要操作前需要用户确认)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
middlewares=[customer_service_middleware, user_confirmation_middleware]
)实际效果:
• 用户查询订单 → 显示11个历史订单
• 修改收货地址 → 调用修改接口,用户确认后生效
• 长时间对话 → 自动总结历史,保持连贯性
案例2:代码审查助手
python
code_review_middleware = SummarizationMiddleware(
llm=ChatOpenAI(model="gpt-4o-mini"),
trigger="fraction",
trigger_value=0.6, # 达到容量60%时触发
keep_tokens=3000,
summary_prompt="请总结代码审查的关键信息:代码模块、主要问题、建议、待处理事项..."
)五、避免的坑与优化技巧
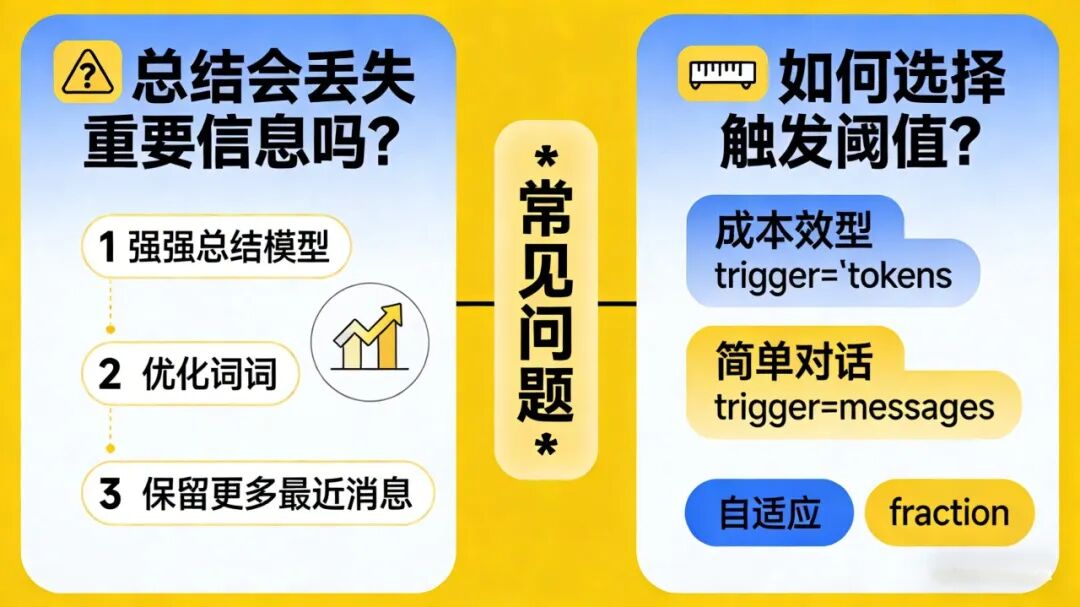
常见问题1:总结会丢失重要信息吗?
会的,但可以通过以下方式最小化影响:
1. 使用更强的总结模型:如果预算允许,用更好的模型做总结
2. 优化提示词:明确要求保留哪些信息
3. 保留更多最近消息:适当增加keep_messages的值
常见问题2:如何选择触发阈值?
• 成本敏感型:使用trigger="tokens",精确控制(如5000)
• 简单对话:使用trigger="messages",易于理解(如20条)
• 自适应场景:使用trigger="fraction",按比例触发(如0.7)
高级技巧:自定义中间件
如果默认中间件不满足需求,可以继承并自定义:
python
class CustomSummarizationMiddleware(SummarizationMiddleware):
async def before_model(self, run_manager, **kwargs):
# 获取消息
messages = kwargs.get("messages", [])
# 执行总结逻辑
if self._should_summarize(messages):
summary = await self._create_summary(messages)
# 自定义验证逻辑
if self._validate_key_info(summary, messages):
kwargs["messages"] = self._format_output(summary, messages)
return kwargs六、性能与成本优化
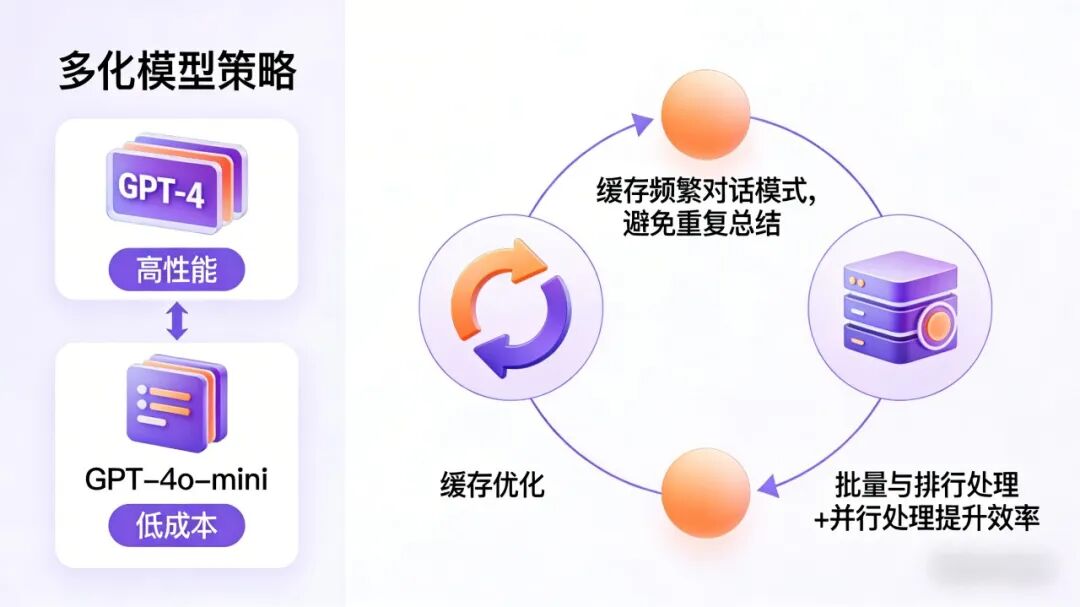
1. 多模型策略
• 主对话模型:高性能模型(如GPT-4)
• 总结模型:便宜模型(如GPT-4o-mini)
2. 缓存优化
对频繁出现的对话模式进行缓存,避免重复总结。
3. 批量与并行处理
对于大量历史消息,可以使用批量总结和并行处理提升效率。
七、完整实战项目结构
客服项目的核心架构:
python
# 1. 工具定义(MCP服务对接电商系统)
tools = [
search_products_tool,
query_order_status_tool,
update_address_tool,
create_ticket_tool
]
# 2. 中间件配置
middlewares = [
SummarizationMiddleware(...), # 总结中间件
LongTermMemoryMiddleware(...), # 长期记忆
DynamicPromptMiddleware(...) # 动态提示词
]
# 3. 智能体执行器
agent_executor = AgentExecutor(
agent=create_react_agent(llm, tools),
tools=tools,
middlewares=middlewares,
verbose=True
)八、总结

Summarization Middleware是LangChain中解决长上下文问题的核心工具,它通过:
✅ 智能压缩历史对话,而非简单截断
✅ 保持连贯性,让大模型"长期记忆"关键信息
✅ 大幅降低成本,减少不必要的token消耗
✅ 灵活配置,适应各种应用场景
关键收获:
1. 总结中间件是智能体开发中的必备组件
2. 自定义提示词是优化效果的关键
3. 结合长期记忆存储可以构建更强大的智能体
4. 多中间件组合能实现复杂的控制逻辑
在AI应用开发中,管理好上下文不仅是一个技术问题,更是成本控制和用户体验的核心。掌握了Summarization Middleware,你就掌握了构建高效、经济、智能的AI应用的关键技术。
📞 支持与反馈
维护团队: 北京慧测·杭州但问智能技术团队

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)