学习AI 工程师第 2 天:搞懂大模型的核心参数
学习任务
1.为什么需要指定大模型的输出规范?
2.大模型的输出规范,有哪些核心参数?
3.为什么不直接在前端代码中调用模型,而是通过后端调用后封装成接口,前端在间接调用?
一、梳理大模型的由来
1.0 AI(人工智能): AI 是技术总称,模型是 AI 的具体实现体
1.1 模型(AI 的大脑): 训练好的一堆数据 + 算法,用来做判断、生成、识别
1.1.1 普通模型( 2022 年 ChatGPT 爆火之前,绝大多数模型,都是一个模型做只能做一件事)
特点:只干一件事、体量小、功能专一
举例:语音转文字模型
1.1.2 大模型(模型体积大、处理事件多)
概念:属于模型的一种,超级大,海量参数和海量文本训练,具备语言理解能力
- 1.1.2.1 豆包模型(
专业叫法:豆包大模型) - 1.1.2.2 DeepSeek 模型(
专业叫法:DeepSeek 大模型) - 1.1.2.3 千问(…)
- 1.1.2.4 文心一言(…)
- 所以,你可以听到日常简称:大模型===豆包、deep seek、千问模型
二、大模型的3个核心参数(真正分类:只有2个核心参数)
在上一篇文章中,学习了如何在项目中手动(node.js方式)调用大模型功能,这里发3个核心参数就是在调用大模型后,制定大模型的输出内容(遵循的规范、约定),
-
表格理解:temperature 温度值(控制ai模型返回的内容的准确度,温度值越低,回答的准确度越高)、top_p核采样(针对温度值的微调)、max_tokens(限制模型单次返回的内容长度,有点类似数据库限制某个字段的最大值效果)

-
通俗理解:
temperature=0.1(最小值,最适合代码和问题的标准回复):模型会 “保守输出”,优先用最常规的写法,代码几乎不会出错,适合生产场景。
temperature=1.5(值越大,涉及逻辑代码的准确率越低):说好听点就是,模型会 “放飞自我”,说坏点用来生成功能代码功能的正确率不高,需要来回请求模型进行校准,当然开放问题的时候,适合找多种思路(我就没真正体验到过实际的好处,个人觉得问题的描述精确点,使用最小值的请求模型进行输出,避免浪费时间…)。
top_p(针对温度调节后的微调) :是temperature温度的子集,当温度值调节完毕后,部分微调可以使用top_p,取值范围:
0.1-0.9max_tokens(控制:输出的内容的长度):相当于给输出 “设上限”,既控制成本,也避免模型生成超长无效文本(我记得之前配置过开源龙虾成功后,在对话的时候让他帮忙生成一个功能代码,当时报了一个错误,就是输出控件太小限制了,最后就是修改配置文件中max_tokens的文本输出大小)。
-
以豆包实践,咨询

-
实践结论:参考豆包的大致温度值,我们可以代码中尝试去看看效果…(当然也可以用一些
边界值,看看ai的输出到底有多离谱)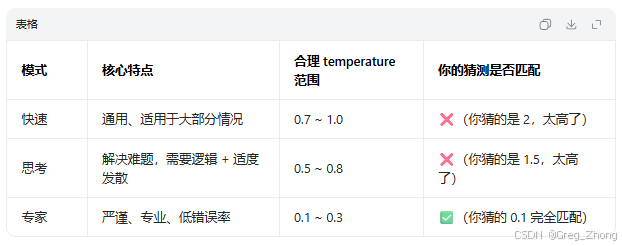
- 当你不配置这三个参数时,模型会直接使用平台 / 模型预设的内置默认值来生成内容,,,
三、node代码中,定义大模型的返回规范
-
指定模型的返回规范js
// ai-client.js require('dotenv').config(); const OpenAI = require('openai'); // 初始化客户端(兼容所有OpenAI接口的模型) const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, baseURL: process.env.OPENAI_BASE_URL, }); /** * 通用AI调用函数,支持配置核心参数 * @param {Object} options 调用参数 * @param {string} options.prompt 给AI的提示词 * @param {string} [options.model] 模型名称(默认取环境变量) * @param {number} [options.temperature=0.7] 温度参数 * @param {number} [options.top_p=1] top_p参数 * @param {number} [options.max_tokens=1024] 最大生成token数 * @returns {Promise<string>} AI生成的文本 */ async function callAI({ prompt, model = process.env.OPENAI_MODEL, temperature = 0.7, top_p = 1, max_tokens = 1024, }) { try { const response = await openai.chat.completions.create({ model, messages: [{ role: 'user', content: prompt }], temperature, top_p, max_tokens, }); return response.choices[0].message.content.trim(); } catch (error) { console.error('AI调用失败:', error.response?.data || error.message); throw error; } } module.exports = { callAI }; -
测试3个核心参数不同组合配置的效果
// test-params.js const { callAI } = require('./ai-client'); // 测试用prompt:生成Vue3计数器组件 const TEST_PROMPT = `请帮我写一个Vue3的计数器组件,包含: 1. 显示当前计数 2. 增加按钮 3. 减少按钮 4. 重置按钮 请直接给代码,不需要额外解释`; // 不同参数组合的测试用例 const testCases = [ { name: '低temperature+低top_p(稳定模式)', params: { temperature: 0.1, top_p: 0.1, max_tokens: 1024 }, }, { name: '中temperature+中top_p(平衡模式)', params: { temperature: 0.5, top_p: 0.5, max_tokens: 1024 }, }, { name: '高temperature+高top_p(创意模式)', params: { temperature: 1.5, top_p: 0.9, max_tokens: 1024 }, }, { name: '低temperature+高top_p(稳定+细节变化)', params: { temperature: 0.2, top_p: 0.9, max_tokens: 1024 }, }, ]; // 批量执行测试 async function runTests() { for (const test of testCases) { console.log(`\n===== 测试: ${test.name} =====`); console.log(`参数: ${JSON.stringify(test.params)}`); console.log('正在生成代码...\n'); try { const code = await callAI({ prompt: TEST_PROMPT, ...test.params, }); console.log('生成的代码:'); console.log(code); console.log('\n----------------------------------------'); } catch (error) { console.error(`测试失败: ${error.message}`); } } } // 运行测试 runTests();
四、大模型的其他参数
除了 stream:流式输出(打字机效果),其余似乎没怎么用过…

五、调用模型,为什么都放在后端?为什么不直接在前端直接调用?
其实,只要能发送 HTTP 请求的框架,都能直接调用模型。但从安全角度「前端直接调用为什么不合适」
原因:避免模型的Key泄露
前端代码是对用户透明的(可通过 “查看网页源代码” 或抓包获取)。如果把Key 写在前端代码里,容易被盗用从而产生巨额费用的安全问题,当然还有前端直接使用也会出现跨域问题,
六、总结
学习制定模型返回的核心参数,旨在后续在项目中封装自己的 AI 工具,
可以任意切换国产大模型(DeepSeek、千问、豆包),的自由使用;
- 在模型返回代码的场景,温度值不能太高,过高会乱编语法、制造 bug;追求稳定一定要用低温度。
安全问题 - API 密钥绝对不能明文写代码里、不能上传 github,必须用环境变量储存,防止被盗扣费。
模型匹配 - max_tokens 不要设置太大,按需设置使用,避免多余消耗、增加费用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)