Harness Engineering 到底是啥?
一、前言
4月初有一个概念”驾驭工程“(Harness Engineering”)逐渐爆火,并开始替代提示词工程(prompt engineering)、上下文工程(context engineering)。本次分享给大家分享下我对这个新词的理解。
二、AI 工程的三代演进
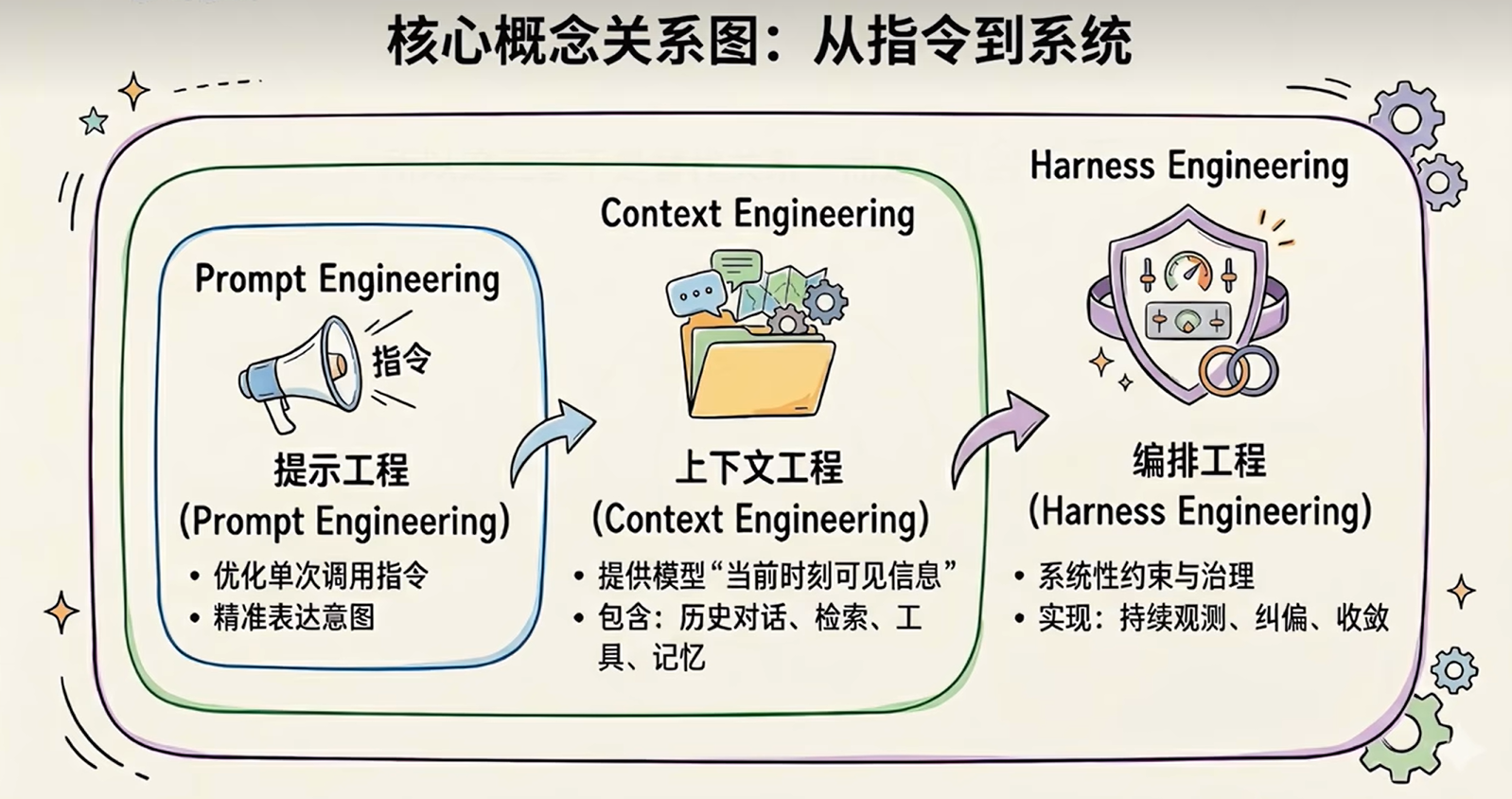
第一代:Prompt Engineering(提示词工程)
最早大家做 AI 应用,核心工作就是把任务讲清楚。怎么写角色、怎么给例子、怎么控制格式……提示词确实很重要。
但它有个根本局限:提示词解决的是表达的问题,不是信息的问题。
它不擅长凭空弥补缺失的知识,也搞不定大量动态信息的处理,更不用说长链路任务里的状态管理了。
当任务短、链路短、状态少的时候(比如聊天机器人),提示词确实够用。但后来 agent 开始火了,模型不只是要回答问题,而是要进入真实的环境去执行任务,提示词就开始捉襟见肘了。
第二代:Context Engineering(上下文工程)
大家意识到,模型能不能稳定发挥,很多时候不只取决于它聪不聪明,而取决于它看到了什么。
于是开始关注怎么给模型喂对信息:RAG 检索增强、动态加载 SOP、按需注入相关文档……
有个很典型的实践:不是一开始就把所有文档塞满,而是等它真正要触发某些能力的时候,再把那部分 SOP 和详细参考信息动态加载进来。这个思路叫「渐进式披露」——上下文的优化不只是给得更多,而是按需给、分层给、在正确的时机给。
但上下文工程也不是终点。因为后来大家又发现了一个更麻烦的问题:就算信息给对了,模型也不一定能稳定执行正确。它可能计划做得很好,但执行跑偏了,工具调用搞乱了,中途卡住了也不知道怎么恢复……
第三代:Harness Engineering(驾驭工程)
这就是 Harness Engineering 要解决的问题。
Harness 这个词本来是「马具、约束装置」的意思。放到 AI 系统里,它提醒我们一件非常朴素的事情:当模型从「回答问题」走向「执行任务」,系统不只要负责传信息,还要能够驾驭整个过程。
如果前两代工程关注的是怎么让模型更会想,那 harness 更关注的就是怎么让模型别跑偏、跑得稳、出了错还能拉回来。
三、用一个例子理解三代工程
用一个通俗的比喻来区分这三个概念——
想象你要雇一个人帮你完成一个复杂任务:
-
Prompt Engineering = 你给他一份详细的任务说明书,告诉他目标是什么、格式是什么、注意事项是什么。这是「把任务讲清楚」。
-
Context Engineering = 你确保他在工作的时候能查到需要的资料、数据库、参考文献。这是「把信息都给对」。
-
Harness Engineering = 你给他搭了一套工作环境:有清晰的工作流程、有工具、有检查机制、有出错了怎么恢复的预案、有监控他工作质量的评估体系。这是「让他在真实执行中持续做对」。
所以这三者不是替代关系,而是包含关系:
-
Prompt 是对指令的工程化
-
Context 是对输入环境的工程化
-
Harness 是对整个运行系统的工程化,边界一层比一层大
四、Harness 的官方定义
Anthropic 的工程师给 harness 下了一个很典型的定义:
Agent = Model + Harness所以 Harness = Agent − Model
翻译成人话:在一个 AI Agent 系统里,除了模型本身以外,几乎所有能决定它能不能稳定交付的东西,都可以算进 harness。
五、一个成熟的 Harness Engineering 分六层
成熟的 Harness Engineering 拆成六层:
第一层:Context 管理(信息边界)
模型能不能稳定发挥,很多时候不只取决于它聪不聪明,而取决于它看到了什么。所以 harness 的第一职责,就是让模型在正确的信息边界内思考。
这一层通常包括三件事:
-
角色、目标和定义:模型要知道自己是谁、任务是什么、成功的标准是什么
-
信息的裁剪和选择:上下文不是越多越好,而是越相关越好
-
结构化的组织:固定的规则放在哪、当前任务放在哪、任务运行状态放在哪、外部证据放在哪——最好分层清晰,因为信息一旦乱掉,模型就很容易漏重点、忘约束
第二层:工具调用管理
给模型配工具,听起来简单,但这里面有三个具体问题:
-
给他什么工具:工具太少,能力不够;工具太多,模型又会乱用
-
什么时候该调用工具:本来不需要查的时候别乱查,该查的时候也别硬答
-
工具结果怎么重新喂回模型:搜索过来的几十条结果,不应该原封不动地塞回去,而是要提炼筛选,保持和任务的相关性
第三层:执行编排
这一层解决的核心问题是:模型下一步该做什么。
很多 agent 的问题不是某一步不会,而是不会把所有的步骤串起来。它会搜索,也会总结,也会写代码,但整个过程想到哪做到哪,最后交出来一堆半成品。
一个完整的任务需要有清晰的轨道:理解目标 → 判断信息够不够 → 不够继续补 → 基于结果分析 → 生成输出 → 检查输出 → 不满足要求就重新修正或重来。
这个时候你会发现,这已经非常接近人在工作的方式了。区别只在于:人靠经验,Agent 靠 harness 这套环境。
第四层:记忆与状态管理
没有状态的 agent,每一轮都会像失忆一样——它不知道自己刚做了啥,也不知道哪些结论已经确认了,哪些问题还没解决。
所以 harness 必须管理状态,至少要分清三类东西:
-
当前任务的状态:做到哪了,下一步是什么
-
会话中的中间结果:这轮已经得到了什么结论
-
长期的记忆和用户偏好:跨会话的知识沉淀
这三类如果混在一起,系统会越来越乱。分清楚之后,agent 才会像一个稳定的工作者。
第五层:评估与观测
这是很多团队最容易忽视的一层。
很多系统其实不是生成不出来,而是生成完了之后根本不知道自己做得好不好。如果没有独立的评估和观测能力,agent 就会长期停留在「自我感觉良好」的状态。
这一层通常包括:输出和验收环境的验证、自动化测试、日志和指标监控。
第六层:约束与恢复
如果没有约束和恢复机制,agent 每次出错就只能从头再来。
一个成熟的 harness 一定要包括三件事:
-
约束:哪些能做,哪些不能做
-
校验:输出之前、输出之后要怎么检查
-
恢复:失败之后怎么切入,回滚到稳定的状态
六、一线公司的真实实践
Harness 之所以最近突然火起来,不是因为大家在空谈方法论,而是很多公司已经把它做进了产品和工程体系里,并且拿到了实实在在的结果。
Anthropic(Claude)
采用了一个非常关键的思路:把干活的人和验收的人分开。
-
Planner:负责把模糊的需求扩展成完整的规格
-
Generator:负责逐步实现
-
Evaluator:负责像 QA 一样去真实测试
更关键的是,这个 evaluator 不只是会看代码,而是会真实地操作页面、看具体的交互、检查实际的结果。这不是一个抽象的审查,是一个带具体环境的验证。
OpenAI(Codex)
案例一:渐进式披露
OpenAI 早期犯过一个很多团队都会犯的错误:写了一个巨大的 agent 说明文档(AGENT.MD),一股脑全塞给模型。结果发现效果很差。
后来改成:按需暴露,不是一次性全给。等它真正要触发某些能力的时候,再动态加载对应的 SOP 和参考信息进来。
案例二:让 Agent 自己验
当代码生产速度一旦上来,瓶颈就不再是「写」,而是「验」。人类根本验不过来。
所以 OpenAI 让 agent 自己去验:
-
接浏览器,能截图
-
点页面,能模拟用户真实操作
-
接日志系统和指标系统,能查 log、查监控
-
每个任务都在独立隔离的环境里跑,互不影响
结果就是:agent 不再是「写完代码就说写完了」,而是真正可以跑起来看结果,发现 bug → 修 bug → 再验证。
这是 harness 里非常完整的一套体系:执行编排 + 评估和观测 + 约束和恢复。
LangChain
在底层模型完全不变的情况下,只通过改造和迭代 Harness,就把自家的智能体验从榜单上 30 名开外,直接杀进了前五。
七、核心观点总结
当 agent 出了问题的时候,修复方案几乎从来不是「让它更努力一点」,而是:
-
确定它缺了什么样的结构性能力
-
问环境里面缺了什么能力
-
建立反馈链路,让 agent 真正能够看到自己的工作结果
这就是典型的 harness 思维。
Harness 不是在取代 Prompt,也不是在取代 Context。它是在更大的系统边界上,把前两者都包含进来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)