【26CVPR - MedCLIPSeg】_ 当医学影像学会“阅读理解”:MedCLIPSeg如何用文本指令精准定位病灶?
论文信息
- 论文链接 - MedCLIPSeg: Probabilistic Vision–Language Adaptation for Data-Efficient and Generalizable Medical Image Segmentation
- 代码仓库
零、摘要

1. 背景与痛点 (Background & Challenges)
- 现状: 医学图像分割面临三大难题:标注数据稀缺、解剖结构模糊以及不同设备/医院导致的域偏移。
- 机遇: 虽然 CLIP 等视觉-语言模型很强,但在医学图像这种需要精细像素级预测(密集分割)的任务中,潜力还没被完全挖掘出来。
2. 核心方法 (Proposed Method)
- 提出框架: MedCLIPSeg —— 一个基于 CLIP 改进的框架。
- 关键创新:
- 利用概率性跨模态注意力来处理图像块特征。
- 实现图像和文本特征的双向交互。
- 显式建模不确定性(让模型知道自己哪里“拿不准”)。
3. 优化策略 (Optimization Strategy)
- 损失函数: 引入了软图块级对比损失。
- 目的: 让模型能理解多样化的文本提示,学习更细腻的语义,从而提升数据效率和泛化能力。
4. 实验与结论 (Experiments & Conclusion)
- 验证规模: 在 16个数据集、5种模态、6种器官上进行了广泛测试。
- 结果: 准确率、效率和鲁棒性都超过了现有方法。
- 亮点: 能提供可解释的不确定性图谱,直观告诉医生哪些区域不可靠。
专有名词解释
这里列出了摘要中出现的关键术语,按类别整理:
A. 模型与架构
- Vision-Language Models (VLMs):视觉-语言模型。能同时理解图片和文字的AI(比如CLIP),通过对比学习把图文对应起来。
- CLIP:对比语言-图像预训练模型。OpenAI开发的强力基础模型,本文是把它作为底座进行改造。
- MedCLIPSeg:本文提出的模型名。即 Medical CLIP Segmentation 的缩写,专门用来做医学图像分割。
B. 技术细节
- Patch-level Embeddings:图块级嵌入。Transformer类模型不看整张图,而是把图切成一个个小方块(Patch)来提取特征,这叫图块级嵌入。
- Probabilistic Cross-modal Attention:概率性跨模态注意力。传统的注意力机制输出一个确定的值,而这个机制输出的是一个概率分布(包含均值和方差),能让模型感知到特征的不确定性。
- Bidirectional Interaction:双向交互。指图像特征和文本特征互相“交流”、互相增强,而不是单向的文字指挥图片。
- Soft Patch-level Contrastive Loss:软图块级对比损失。一种训练技巧。“软”指的是使用软标签(比如0.8的相似度)而不是硬标签(0或1),这样能让模型处理更复杂的语义关系。
C. 性能指标
- Data Efficiency:数据效率。指模型很“省数据”,只用少量样本就能训练得很好(这对医学领域很重要,因为标注太贵了)。
- Domain Generalizability:域泛化能力。指模型“见多识广”,换个医院、换个设备拍片子,它依然能认得准,不会因为环境变了就失效。
- Uncertainty Maps:不确定性图谱。模型输出的一张“热力图”,颜色深的地方表示模型觉得这里很难判断,提醒医生重点检查。
一、引言
1. 现状与挑战 (The Challenge)
医学图像分割至关重要,但面临三大核心障碍:
- 数据标注难: 专家标注昂贵且不一致。
- 边界模糊: 病灶和器官的边界不清晰,难以精确划分。
- 域偏移问题: 模型在不同医院或设备的数据上表现不佳。
这些挑战催生了业界对数据高效、不确定性感知、跨域泛化能力强的新型分割系统的需求。
2. 现有方案的局限 (Limitations of Existing Methods)
- 主流方法: 以 U-Net 为代表的 CNN/ViT 模型虽然成功,但它们依赖大量像素级标注,并且是确定性(deterministic)模型。
- 核心缺陷: 这些模型普遍存在“过度自信”的问题,尤其在面对模糊边界或陌生数据时,会给出错误的结果却不提供任何预警。它们无法处理特征中的模糊性和内在矛盾。
3. 新思路与机遇 (A New Paradigm with VLMs)
- 潜力股: 视觉-语言模型(VLMs)如 CLIP,通过图文对齐,为解决上述问题提供了新范式。它能用更易获取的文本描述来辅助训练,实现数据高效和用户交互。
- 待解决问题: 尽管有潜力,但通用 VLMs 在医学领域的精细定位能力较弱,且同样存在确定性模型的“过度自信”缺陷。如何让其具备不确定性感知能力是关键。
4. 本文方案与贡献 (Our Solution: MedCLIPSeg)
- 提出框架: 我们提出了 MedCLIPSeg,一个通过概率性、双向融合来适配 CLIP 的文本驱动分割框架。
- 核心机制:
- PVL 适配器: 在 CLIP 深层网络中引入概率性视觉-语言适配器,学习基于置信度的注意力。
- 不确定性建模: 通过对注意力中的键(Keys)和值(Values)进行概率建模,分别捕捉偶然不确定性和认知不确定性,并生成像素级不确定性图谱。
- 保持效率: 保留 CLIP 预训练参数,并引入软对比损失,确保在少样本下的高效学习。
- 主要贡献:
- 双向融合: 增强数据效率和鲁棒性。
- 概率性注意力: 提升准确性和泛化能力。
- 不确定性图谱: 提供临床可解释的可靠性可视化。
- 全面评估: 在多模态、多器官数据集上验证了优越性。
专有名词解释
A. 核心问题类
| 专有名词 | 缩写 | 解释 |
|---|---|---|
| Domain Shift | - | 域偏移。指模型训练数据和实际应用数据的分布不一致。例如,用A医院的CT数据训练的模型,在B医院的CT数据上效果变差。 |
| Over-confident | - | 过度自信。指AI模型即使在预测错误或不确定的情况下,也给出很高的置信度分数。这是医疗AI中的一个严重安全隐患。 |
| Partial-volume Effects | - | 部分容积效应。医学成像中的一个现象,当一个体素(3D像素)内包含多种不同组织时,其信号强度是这些组织的混合平均值,导致边界模糊。 |
B. 技术方法类
| 专有名词 | 缩写 | 解释 |
|---|---|---|
| Deterministic Models | - | 确定性模型。给定一个输入,模型总是输出唯一、固定的结果。传统的U-Net就是这类,它无法表达“我不确定”。 |
| Probabilistic Modeling | - | 概率性建模。将模型的某些部分(如此处的注意力键和值)看作概率分布而非固定值。这使得模型能够量化和表达自身的不确定性。 |
| Variational Modeling | - | 变分建模。一种用于近似复杂概率分布的数学方法。文中用它来估计注意力中“键”的分布。 |
| Aleatoric Uncertainty | - | 偶然不确定性。源于数据本身的噪声或固有模糊性(如模糊的病灶边界),这种不确定性无法通过增加数据来消除。 |
| Epistemic Uncertainty | - | 认知不确定性。源于模型自身的知识局限,比如遇到了训练时没见过的数据类型(域外数据)。这种不确定性可以通过收集更多样化的数据来降低。 |
| Inductive Biases | - | 归纳偏置。模型为了解决问题而预先做出的假设。例如,CNN的归纳偏置是“局部相关性”,即相邻的像素更可能相关。 |
C. 模型与组件类
| 专有名词 | 缩写 | 解释 |
|---|---|---|
| Vision-Language Models | VLMs | 视觉-语言模型。能同时理解和关联图像与文本信息的AI模型,CLIP是其杰出代表。 |
| PVL Adapter | PVL | 概率性视觉-语言适配器。本文提出的核心模块,像一个“插件”一样插入CLIP中,使其具备概率性处理和双向交互的能力。 |
| Monte Carlo Sampling | - | 蒙特卡洛采样。一种通过多次随机抽样来估算结果的计算方法。文中通过对概率分布进行多次采样,来生成最终的平均分割结果和不确定性图谱。 |
Figure 1 _ 直观的对比和实验数据
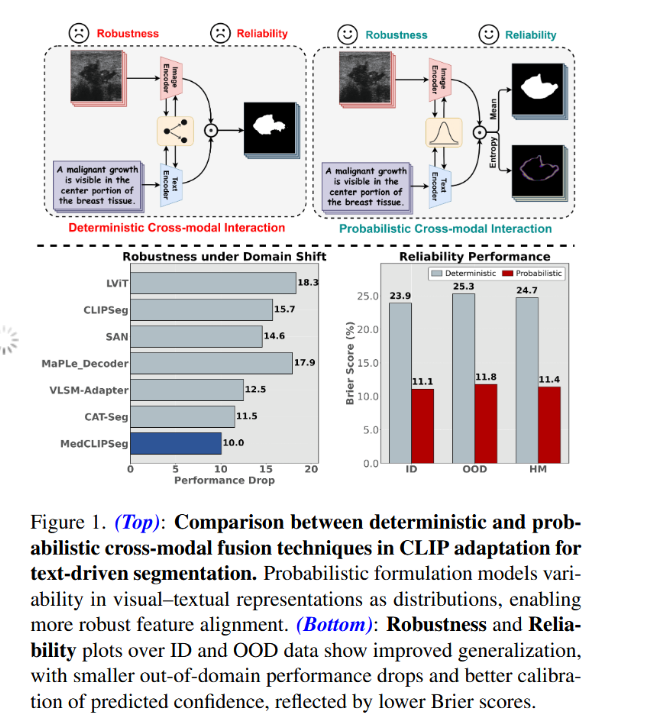
第一部分:核心机制对比(顶部示意图)
这部分通过左右两个流程图的对比,直观地展示了“确定性方法”(传统做法)与“概率性方法”(本文提出的 MedCLIPSeg)的本质区别。
左侧:确定性跨模态交互
- 流程:图像和文本分别进入编码器,提取出特征后直接进行交互(那个黑色的连接点),最后输出一个分割结果(白色的掩码)。
- 问题:
- 缺乏反馈:你看那个图像编码器出来的箭头是单向的,文本也是单向的,它们之间没有深层的互相修正。
- 过度自信:虽然输出了分割结果,但模型并不知道自己对哪里“拿不准”。如果遇到模糊的边界,它可能会瞎猜一个结果,而且信誓旦旦地告诉你“我很确定”。
- 标签:上方标注了“Robustness(鲁棒性)”和“Reliability(可靠性)”都是哭脸,暗示这种传统方法在这两方面表现不佳。
右侧:概率性跨模态交互(MedCLIPSeg)
- 流程:
- 双向交互:注意看中间的双向箭头,图像和文本特征在深层是互相融合的,文本在指导图像,图像也在修正文本理解。
- 概率建模:最关键的区别在于那个钟形曲线(高斯分布图标)。这意味着模型不再把特征看作一个死板的点,而是看作一个分布。它计算特征的“均值”来生成分割结果,同时计算“熵(Entropy)”来生成不确定性图。
- 输出:除了分割结果,它还多输出了一个彩色的图,这就是不确定性图谱。颜色越深(或越亮)的地方,代表模型越犹豫。
- 优势:上方标注了“Robustness”和“Reliability”都是笑脸。这意味着这种方法更稳健,且结果更值得信赖,因为它能告诉你:“这里我分得不太清,请医生重点看一下。”
第二部分:定量实验验证(底部柱状图)
这部分用真实数据证明了上面的理论优势。
左图:域偏移下的鲁棒性
- 指标:Performance Drop(性能下降幅度)。这个柱子越短越好,意味着换了不同的数据环境(比如换了医院或设备),模型性能掉得越少,说明它越稳健。
- 对比:
- 灰色的柱子是其他 SOTA(最先进)的方法,如 LViT, CLIPSeg, SAN 等。它们的性能下降幅度都在 11.5 到 18.3 之间。
- 深蓝色的柱子是本文的 MedCLIPSeg,它的数值是 10.0,明显最短。
- 结论:在面对陌生数据环境时,MedCLIPSeg 的性能下降最少,证明了它极强的泛化能力和鲁棒性。
右图:可靠性表现
- 指标:Brier Score(布里尔分数)。这是一个衡量概率预测准确性的指标,简单来说,分数越低,代表模型的预测越准,且置信度越靠谱(即:懂就是懂,不懂就是不懂,不会瞎自信)。
- 对比:
- 图表展示了三种情况:ID(训练过的数据)、OOD(没见过的陌生数据)、HM(调和平均)。
- 在每一组中,红色柱子(Probabilistic,即本文方法)都远远低于灰色柱子(Deterministic,即确定性方法)。
- 例如在 OOD(陌生数据)场景下,传统方法分数高达 25.3,而本文方法仅为 11.8。
- 结论:无论是在熟悉还是陌生的环境中,MedCLIPSeg 的预测都更加“靠谱”,它极好地解决了模型“盲目自信”的问题。
总结
这张图的核心逻辑是:
- 原理上:我们将“死板”的特征变成了“灵活”的概率分布,并增加了双向交流。
- 结果上:这让模型在面对陌生环境时更抗造(鲁棒性高),在面对模糊情况时更诚实(可靠性高,有不确定性提示)。
二、相关工作
1. 医学图像分割的演变
- 起步(CNN时代): 以 U-Net 为核心,通过跳跃连接(skip connections)和变体(如 UNet++、nnUNet)建立了基础。
- 进阶(ViT时代): 引入 视觉Transformer 捕捉长距离依赖,出现了 TransUNet、Swin-UNet 等混合架构,性能更强。
- 痛点: 纯视觉模型过于依赖图像的“长相”(低级特征),一旦换了医院或设备(域偏移),性能就容易崩盘。因此,需要引入“语义先验”(即语言信息)来增强泛化能力。
2. 视觉-语言模型的崛起与适配
- 通用与专用模型: CLIP 证明了图文对齐的强大能力,随后 BiomedCLIP 等模型将其迁移到医学领域。
- 微调技术: 为了让大模型适应医学任务,出现了 提示微调(如 CoOp)和 低秩适配(如 LoRA)等高效方法。
- 进阶方向: 最近开始尝试 概率性微调(如 ProbVLM)来处理图文之间的一对多映射问题,提升可靠性。
- 痛点: 大多数医学 VLM 还在做分类或检索,真正做像素级分割的还很少,且对解剖细节的捕捉还不够。
3. 基于提示的分割与本文定位
- 自然图像领域: CLIPSeg 和 Segment Anything Model 是代表。前者用文本驱动分割,后者用点/框驱动分割(SAM 虽然强,但不懂自然语言)。
- 医学领域的尝试:
- LViT / MedSAM:尝试结合文本或几何提示,但往往需要复杂的中间层干预。
- 少样本分割:如 UniverSeg,利用少量样本进行分割。
- 现有缺陷:直接套用 CLIPSeg 效果不好(Poudel et al. 指出),现有的适配方法(如 VLSM-Adapter)在跨域泛化上依然有短板。
- 本文定位: 不同于上述方法,本文在保留 CLIP 预训练参数的前提下,引入概率性、双向的图文融合,专门解决医学分割的鲁棒性和临床可靠性问题。
专有名词解释
A. 核心架构与模型
- U-Net / CNN: 医学图像分割的“祖师爷”。利用卷积神经网络提取特征,U-Net 特有的跳跃连接能很好地保留图像细节。
- ViT / TransUNet: 引入 Transformer 机制的分割模型。相比 CNN,它们更擅长理解图像的全局结构(比如器官的整体形状)。
- CLIP / BiomedCLIP: 视觉-语言预训练模型。CLIP 是通用版,BiomedCLIP 是专门在医学文献和图片上训练过的“医学特供版”,更懂医学术语。
- SAM: 一个强大的通用分割模型,但它主要通过点、框来交互,不像 CLIP 那样能直接听懂“肝脏肿瘤”这样的文字指令。
B. 关键技术术语
- 域偏移: 模型在 A 医院的数据上训练,拿到 B 医院的数据上效果变差。这是医学 AI 最大的痛点之一。
- 参数高效微调: 大模型太大,全量微调太贵。这种方法只训练模型的一小部分参数(比如提示词或低秩矩阵),就能让它适应新任务。
- 提示微调: 不改动模型主体,而是通过优化输入的“提示词”向量来引导模型输出正确结果。
- 概率性微调: 传统模型输出一个确定的数值,概率性模型输出一个分布(包含均值和方差),这样模型就能表达“我不确定”的态度。
C. 本文提到的具体方法
- CLIPSeg: 一个经典的利用 CLIP 进行文本驱动分割的方法,本文将其作为对比基准。
- UniverSeg / MultiverSeg: 少样本分割框架,旨在用极少的数据适应新任务。
三、方法
第一部分:地基——CLIP 架构的重用
这部分主要讲“我们站在巨人的肩膀上”。
- 核心逻辑:作者并没有重新发明轮子,而是直接使用了 CLIP 的两个编码器(视觉编码器 Ev 和文本编码器 Et )。
- 图像处理:把一张图切成很多小块(Patches),加上一个特殊的 [CLS] 标记,扔进视觉 Transformer。
- 文本处理:把一句话(提示词)变成向量,扔进文本 Transformer,提取出 [EOS] 标记作为整句话的代表。
- 关键点:作者特别指出,虽然 CLIP 原本只关注全局匹配([CLS] 对齐),但研究表明其内部的图像块(Patches)其实已经隐含了空间信息。这意味着 CLIP 天生就具备做分割(像素级任务)的潜力,只需要稍微“点拨”一下。
第二部分:核心创新——概率性视觉-语言适配器
这是论文最硬核的部分,为了解决传统模型“过度自信”的问题,作者设计了一个叫 PVL Adapter 的插件。
- 双向交互:传统的适配器通常是单向的,而这个插件让图像特征和文本特征在深层网络中互相“对话”(双向 Transformer),让图像更懂文本,文本更懂图像。
- 概率性建模(QKV 参数化):
- 在标准的注意力机制中,特征是一个确定的数值。
- 在这里,作者把特征(Key 和 Value)变成了概率分布(高斯分布)。也就是说,模型不仅输出一个特征值(均值 μ ),还输出一个“不确定度”(方差 σ2 )。
- 置信度加权注意力:
- 模型在计算注意力时,不仅看“相似度”,还要看“不确定度”。
- 如果模型觉得某个区域很模糊(方差大),它就会自动降低这个区域的权重(置信度惩罚)。这就像医生在看片子时,看不清的地方就不会轻易下结论。
- 残差门控:为了训练稳定,加了一个“开关”(Gate),控制原始特征和新特征的融合比例。
第三部分:任务适配与优化
这部分讲如何把处理好的特征变成最终的分割图,并教模型怎么学习。
- 像素-文本相似度:最后,模型拿着文本特征(比如“肿瘤”的描述)去和每一个图像块特征做点积(计算相似度)。相似度高的地方,就是分割出来的目标。
- 软补丁对比损失:
- 为了解决医学图像中“一个图里可能有多个器官”或者“描述不唯一”的问题,作者设计了一种新的损失函数。
- 它不是简单地让模型死记硬背(硬标签),而是通过计算图像块和文本之间的软相似度(Soft Targets),让模型学习更鲁棒的特征。
专有名词解释
为了帮你更好地理解,这里列出文中的关键术语:
基础架构类
- CLIP (Contrastive Language-Image Pre-training):一种预训练模型,通过学习大量的“图-文”对,让计算机理解图像和文字的对应关系。本文将其作为基础底座。
- Transformer / Encoder:目前主流的深度学习架构,擅长处理序列数据(如文本或切分的图像块),能够捕捉长距离的依赖关系。
- [CLS] Token:在输入图像序列前加的一个特殊标记,通常用来代表整张图的全局特征。
- [EOS] Token:在文本序列末尾加的标记,代表“句子结束”,本文用它来代表整句话的特征。
核心算法类
- PVL Adapter (Probabilistic Vision-Language Adapter):本文提出的核心模块,用于在 CLIP 内部进行概率性的图文融合。
- QKV (Query, Key, Value):注意力机制中的三个核心概念。你可以理解为:Query 是“提问者”,Key 是“被检索的内容”,Value 是“真正要提取的信息”。
- 概率分布 (Probability Distribution):不再用一个固定的数表示特征,而是用一个分布(均值和方差)来表示。这能让模型表达“我不确定”的状态。
- 方差 (Variance, σ2 ):统计学概念,衡量数据的离散程度。在本文中,方差大意味着模型对这个特征感到“模糊”或“不确定”。
- 重参数化技巧 (Reparameterization Trick):一种数学技巧,使得包含随机采样的神经网络也能通过反向传播进行训练。
训练策略类
- 残差门控 (Residual Gating):一种控制信息流动的方法,决定保留多少原始信息,加入多少新信息,防止训练初期模型不稳定。
- 对比损失 (Contrastive Loss):一种训练目标,目的是拉近相似图文的距离,推远不相似图文的距离。
- 软标签 (Soft Targets):相比于非黑即白的“硬标签”(是或不是),软标签提供的是概率分布(比如有 80% 可能是 A,20% 可能是 B),能让模型学习得更细腻。
- Dice + BCE:医学图像分割中常用的两种损失函数的组合,用于衡量预测区域和真实区域的重叠程度及误差。
Figure 2 _ 系统架构图
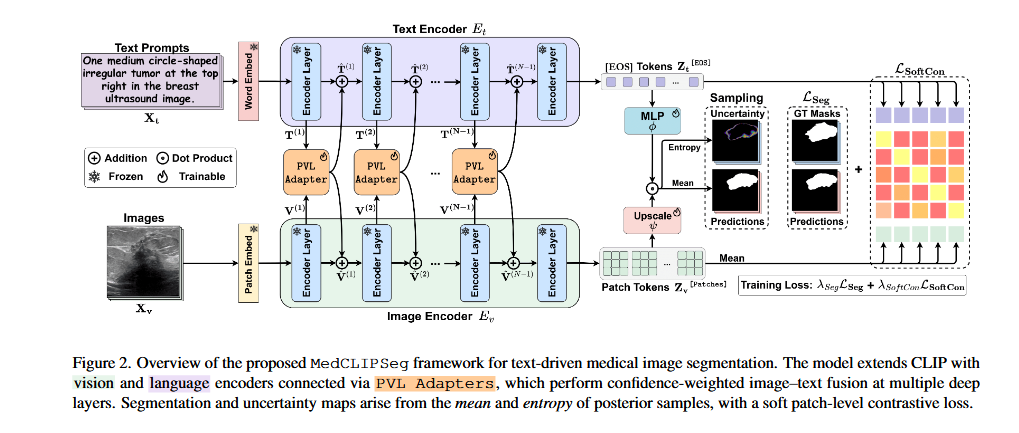
第一步:原料输入(最左侧)
这里有两个入口,分别对应“看图”和“读字”:
- 文本入口(上方):
- 输入:一段描述性的文字,比如图里的例子:“One medium circle-shaped irregular tumor at the top right...”(右上方有一个中等大小、形状不规则的圆形肿瘤……)。
- 处理:这段文字先经过 Word Embed(词嵌入),把字变成计算机能懂的数字向量。
- 关键符号:注意那个带星号
(*)的红色方块,图例说明这是冻结的。这意味着文本编码器的底层参数是锁死的,直接用的预训练模型(CLIP),不重新训练,为了省钱也为了保持强大的语言理解力。
- 图像入口(下方):
- 输入:一张医学影像(比如这里的乳腺超声图)。
- 处理:图片被切成一个个小块,这叫 Patch Embed(图像分块嵌入)。
- 关键符号:这里也有一个带星号
(*)的绿色方块,说明图像编码器的底层也是冻结的。
第二步:核心加工车间(中间部分)
这是模型最“聪明”的地方,也是本文创新点 PVL Adapter 发挥作用的地方。
- 双塔结构:
- 上面一排紫色的方块是 Text Encoder(文本编码器)的层。
- 下面一排绿色的方块是 Image Encoder(图像编码器)的层。
- PVL Adapter(橙色方块):
- 你看那些橙色的方块插在每一层编码器的中间。这就是我们刚才说的“插件”。
- 双向箭头:注意看橙色方块之间的连线,是双向的!
- 从上往下:文本特征告诉图像,“你要找的是肿瘤,不是血管”。
- 从下往上:图像特征告诉文本,“这里确实有个东西,长得挺像你说的肿瘤”。
- 具体操作:在每一层,图像特征 V 和文本特征 T 都会进入 Adapter,进行我们在方法论里看到的“概率性交互”。它们互相修正,互相融合。
第三步:特征提取与融合(右侧中部)
经过层层加工,特征终于到了出口处:
- 文本侧:提取出 [EOS] Tokens(那个蓝色的长条)。这是整句话的精华总结,代表了“我们要找什么目标”。
- 图像侧:提取出 Patch Tokens(那一排绿色的小格子)。这是图片里每个小块的特征。
- 关键计算(点积):
- 注意那个圆圈里有个叉
⊗的符号,代表 Dot Product(点积)。 - 原理:拿文本的精华(蓝色长条)去和图像的每个小块(绿色格子)做匹配。
- 结果:匹配度高的地方,数值就大;匹配度低的地方,数值就小。这就初步形成了一张“热力图”。
- 注意那个圆圈里有个叉
第四步:成品出厂(最右侧)
最后一步是把计算结果变成我们看得懂的东西:
- 上采样:
- 那个 Upscale 的箭头,意思是把粗糙的热力图放大,还原成原图的大小。
- 这里用到了 Mean(均值):因为我们在中间用了概率采样,这里取平均值作为最靠谱的预测。
- 双重输出:
- 分割结果:模型画出白色的区域,告诉你“肿瘤在这里”。
- 不确定性图:那个彩色的图(Entropy/熵)。
- 原理:通过 Sampling(多次采样)计算出来的。如果模型每次猜的结果都不一样,熵就高(颜色深),说明模型“心里没底”;如果每次猜得都很一致,熵就低。这对医生非常有价值,提示医生“这块我也拿不准,你重点看看”。
- 损失函数监督:
- 最右边的方格阵列代表 Training Loss。
- 模型会把预测结果跟 GT Masks(Ground Truth,也就是医生画的金标准)去对比,计算误差,然后反向传播去训练那些橙色的 Adapter。
需要注意的细节
细节一:冻结与微调的博弈(图例中的星号 *)
- 观察:注意看图例,带星号的方块(Text Encoder 和 Image Encoder 的主体)是灰色的,代表冻结。只有红色的 Text Prompt Embedding 和橙色的 PVL Adapters 是实心的,代表可训练。
- 解读:这是一个非常典型的参数高效微调策略。
- 为什么要冻结? CLIP 的预训练模型非常庞大,如果全部重新训练,需要海量医学数据和算力,且容易“灾难性遗忘”(忘了它在自然图像上学到的通用知识)。
- 只训什么? 作者只训练中间插入的轻量级 PVL Adapters 和输入的提示词嵌入。这意味着模型保留了 CLIP 强大的通用特征提取能力,只通过少量参数来“微调”它适应医学领域。
细节二:双向交互的层级性(橙色方块的连接)
- 观察:PVL Adapters 并不是只在最后一层才让图文见面,而是在每一层(从第1层到第N-1层)都插入了适配器,并且箭头是双向的(
↔)。 - 解读:
- 深层交互:这意味着文本语义不仅仅是在最后去“查询”图像特征,而是在特征提取的每一个阶段都在互相修正。
- 从粗到细:浅层可能对齐的是边缘、纹理等低级特征,深层对齐的是器官、病灶等高级语义。这种层层递进的融合比单纯的最后融合要精细得多。
细节三:不确定性图与均值图的并行输出(右侧输出端)
- 观察:在右上角,经过采样后,模型分出了两条路:
- Mean:生成了最终的分割预测图。
- Entropy:生成了一个黑白的热力图,标注为“Uncertainty”。
- 解读:这是本文的一大亮点——临床可靠性。
- 传统的分割网络只给一张图,医生不知道哪里是模型“猜”的。
- 这个模型通过概率建模,额外输出了熵图。颜色越深(熵越大),代表模型越“心里没底”。这在医学上至关重要,可以提醒医生:“这块区域我看不准,请你重点检查。”
细节四:损失函数的双重约束(最右侧 Loss 部分)
- 观察:总损失函数由两部分组成:
- 分割损失:连接着“预测图”和“GT Masks”。
- SoftCon 损失:连接着“Patch Tokens”和“Text Tokens”。
- 解读:
- 分割损失负责让结果画得准(像素级对齐)。
- SoftCon 损失负责让特征对得齐(语义级对齐)。
- 这就好比教学生做题:分割损失是“批改答案”,SoftCon 损失是“讲解思路”。两者结合,模型不仅答案对,而且是真的“理解”了图文关系,而不是死记硬背。
细节五:上采样模块的位置
- 观察:注意看 Upscale ψ 这个模块的位置。它是在图像编码器的最后一层输出(Patch Tokens)之后,而不是在融合了文本信息之后直接做。
- 解读:这暗示了特征融合的方式。图像的高维特征( Zv )提取出来后,通过 ψ 还原回图像分辨率,然后才与文本特征( t~ )进行点积运算得到最终的分割掩码。这是一种解耦的设计,保证了视觉特征的完整性,同时也让文本引导更加直接。
总结来说,这张图的精髓在于:用最小的代价(冻结主干+轻量适配器),换取了最大的收益(细粒度跨模态对齐+不确定性量化)。
总结
这张图展示了一个“借鸡生蛋”的过程:
- 借鸡:借用了强大的 CLIP 模型(冻结的编码器等)。
- 生蛋:在中间插入了轻量级的 PVL Adapter(橙色部分)进行微调。
- 结果:不仅输出了分割图,还额外输出了不确定性图,实现了既准又稳的医学图像分割。
Figure 3 _ PVL Adapter
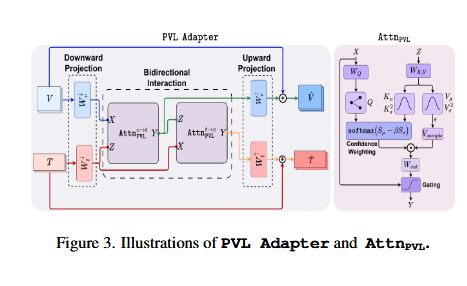
如果说上一张图是“工厂全景”,这张图就是“核心机器内部构造图”。它详细展示了图像特征(V)和文本特征(T)到底是怎么在微观层面进行“深度融合”和“概率计算”的。
我们按照数据流动的顺序,分三个步骤来拆解这个黑盒子:
第一步:降维压缩(Downward Projection)
- 看图左侧:
- 输入是大写的 V(视觉特征)和 T (文本特征)。
- 它们分别经过了 Wv 和 Wt 这两个矩阵。
- 技术含义:
- 这是一个降维操作。CLIP 原始的特征维度很高(比如 512 或 768 维),直接计算非常费资源。
- 作者先把它们投影到一个低维空间( Ds ),就像把高清视频压缩成流畅版再处理,既保留了核心信息,又大大减少了计算量。
- 输出变成了小写的 v 和 t,这就是压缩后的特征。
第二步:双向概率交互(Bidirectional Interaction)
- 看图中间:
- 这里有两个紫色的方块,代表两个 AttnPVL(概率注意力模块)。
- 注意箭头的方向:
- 左边的紫色块:Query 是 t (文本),Context 是 v (图像)。意思是:文本去查询图像(“肿瘤在哪里?”)。
- 右边的紫色块:Query 是 v (图像),Context 是 t (文本)。意思是:图像去查询文本(“我是肿瘤吗?”)。
- 技术含义:
- 这就是所谓的双向交互。文本特征指导图像关注特定区域,图像特征帮助文本确认描述是否准确。
- 这一步是核心创新点,它不是简单的特征相加,而是通过复杂的概率注意力机制(右边粉色大图详解的部分)来计算的。
第三步:升维与残差融合(Upward Projection & Gating)
- 看图右侧:
- 经过交互后的特征(小写 v′和 t′)并没有直接输出,而是先经过了 Wv↑ 和 Wt↑ 。
- 这是一个升维操作,把特征恢复到原来的维度(大写 V^ 和 T^ )。
- 关键细节(残差连接):你看最外圈的线条,输入 V 直接连到了输出端,和计算后的结果相加。
- 关键细节(门控机制):在输出前还有一个 Gating(门控)开关。
- 技术含义:
- 残差连接是为了防止训练过程中信息丢失,保证模型至少能保留原始 CLIP 的特征。
- 门控机制就像是一个“水龙头”,控制着“新融合的特征”和“原始特征”的混合比例。训练初期可能主要靠原始特征,随着训练进行,逐渐打开水龙头,引入更多跨模态信息。
核心组件详解:AttnPVL(右侧粉色大图)
图 3 右边那个独立的粉色大图,是对中间紫色方块的极致放大。它展示了“概率性”到底是怎么算的。
传统的注意力机制公式是: Attention=Softmax(QKT)V。
而这里的 AttnPVL 把它改得极其复杂且高级:
-
QKV 的概率化(左上角):
- 普通的 Attention: K 和 V 是一个确定的数值向量。
- 这里的 Attention: K 和 V变成了高斯分布。
- 看图中的波浪线符号( ∼ ),模型不仅预测均值( μ ),还预测方差(σ2 )。
- 解释:模型在说:“我觉得这个特征大概是这个值(均值),但我有多大的把握(方差)”。
-
置信度加权(Confidence Weighting - 中间部分):
- 公式里出现了 Sμ和 Sσ 。
- 这是在计算注意力分数时,减去了一个“惩罚项”。
- 解释:如果模型对某个图像块的判断很模糊(方差大),它在计算注意力时就会自动降低这个块的权重。这是为了抗噪,防止模型被图像中不相关的背景干扰。
-
重参数化采样(Reparameterization - 下方):
- 图中有个 ϵ∼N(0,I)。
- 这是为了让模型能“可导”地训练。模型通过采样得到一个具体的 VsampleVsample ,然后才进行最后的加权求和。
总结这张图的核心逻辑
PVL Adapter 的工作流就是:
先把图文特征压缩 →→ 然后在低维空间里互相询问(但这次询问带着“不确定性”的考量,不仅问“是什么”,还问“有多确定”) →→ 最后把结果放大回去,并通过门控小心翼翼地融合进原始模型中。
四、实验
第一部分:实验设置
这部分定义了比赛的“场地”和“规则”。
核心逻辑
- 数据效率测试:作者故意只用 10%、25%、50% 的数据来训练,看模型在“吃不饱”的情况下能不能学好。这是为了模拟现实中医学数据标注昂贵的痛点。
- 多域测试:用了 6 个器官(乳腺、脑、皮肤等)、5 种模态(超声、MRI、内镜等)的数据集。
- 内部测试:用常见的数据集(如 BUSI, ISIC)。
- 域泛化测试:用那些模型从未见过的、拍摄设备或环境不同的数据集(如 BUSUC, CVC-ColonDB),测试模型的“见多识广”程度。
- 提示词策略:对于没有文字描述的数据集,作者用 GPT-5(原文如此,可能是笔误指代最新GPT模型)自动生成描述,并配合图像处理技术提取属性。
- 硬件与参数:基于 UniMedCLIP 骨干网络,训练 100 轮,使用 Dice + BCE 混合损失函数。
第二部分:核心实验结果
数据效率
- 结论:数据越少,MedCLIPSeg 的优势越明显。
- 细节:在只用 10% 数据时,它比最强的基线模型(CAT-Seg)高出 2-3%;比没有 PVL 适配器的版本(EoMT-CLIP)高出 7%。这证明概率性适配器(PVL Adapter)在数据稀缺时能极大防止模型“学偏”。
域泛化能力
- 结论:换了“考场”依然能拿高分。
- 细节:在面对光照变化(内镜)、增益变化(超声)等巨大的域偏移时,模型依然保持了很好的轮廓分割能力。比如在 ISIC 皮肤病变数据集上达到了 92.5% 的 DSC。
组件有效性
- 结论:每个零件都有用,缺一不可。
- 关键发现:
- 去掉 PVL 适配器,性能下降最严重(域外数据 DSC 暴跌 23.8%),说明它是跨域能力的核心。
- 把概率注意力换成普通的确定性注意力,性能也大幅下降,证明“知道哪里不确定”对分割很重要。
- 双向交互和软对比损失也能带来小幅但稳定的提升。
第三部分:深度消融研究
这部分是对模型进行“微调”和“压力测试”。
层级干预
- 在 Transformer 的深层(第 10 层左右)加入适配器效果最好。浅层主要学纹理,深层才学语义,所以深层交互更有效。
置信度权重
- 参数 β设置为 2.35 时效果最佳。这个参数控制着模型对“不确定区域”的惩罚力度。
提示词风格
- 结论:提示词要“短而精”。
- 细节:包含空间位置信息(如“右上角”)的简洁提示词效果最好。太长(啰嗦)或太短(信息不足)都会降低效果。如果是自相矛盾的提示词,模型性能会崩盘。
骨干网络
- 使用在医学数据上预训练过的 UniMedCLIP 比通用的 CLIP 效果更好,说明“专业对口”很重要。
第四部分:不确定性与可靠性
这是本文的“杀手锏”功能。
- 可视化:模型生成的不确定性热力图(Uncertainty Map)非常准。哪里边缘模糊、哪里医生都很难判断,模型的不确定性数值就高。
- 相关性:预测的不确定性与实际的分割误差高度相关(斯皮尔曼相关系数高达 0.87)。
- 校准:通过概率建模,模型的Brier Score(一种衡量预测准确度的指标,越低越好)几乎减半。这意味着模型不再“盲目自信”,这对临床诊断至关重要。
专有名词解释
为了帮你彻底读懂这部分,以下是文中出现的关键术语解释:
数据集与模态
- BUSI/BTMRI/ISIC:常见的医学图像公开数据集,分别对应乳腺超声、脑肿瘤 MRI、皮肤病变。
- 模态:成像的方式。比如超声、CT、MRI、内镜照片,它们的成像原理和图像风格完全不同。
- 域偏移:训练数据和测试数据分布不一致。比如用 A 医院的机器拍的片子训练,去测 B 医院机器拍的片子,因为机器参数不同,图像亮度、噪点都不一样,这就叫域偏移。
评价指标
- DSC:Dice 相似系数,医学分割最常用的指标。范围 0-100%,越高越好,代表预测区域和真实区域的重叠程度。
- NSD:归一化表面距离,衡量预测轮廓和真实轮廓之间的距离误差,越低越好。
- HM:调和平均数。在这里用来平衡“域内表现”和“域外表现”,防止模型偏科。
- Brier Score:布里尔分数。衡量概率预测准确性的指标。它惩罚那些“预测错误且非常自信”的情况。分数越低,说明模型越靠谱(校准得越好)。
- 斯皮尔曼相关系数:衡量两个变量排名的相关性。这里用来证明“模型觉得难的地方”和“实际真的难的地方”是一致的。
模型组件
- UniMedCLIP:一个专门在大量医学图像和文本上预训练过的 CLIP 模型,比通用的 CLIP 更懂医学术语。
- PubMedBERT:专门在生物医学文献上预训练的 BERT 语言模型,用来处理文本提示词。
- GPT-5:文中提到的用于生成提示词的大语言模型(注:截至当前时间 GPT-5 尚未正式发布,文中可能指代最新的 GPT-4o 或作者笔误)。
- PVL Adapters:本文提出的核心插件,用于连接图像和文本特征。
- LSoftCon:软对比损失,一种辅助训练的损失函数,帮助模型更好地区分相似但不同的特征。
训练策略
- 余弦退火:一种调整学习率的方法,让学习率像余弦曲线一样平滑下降,有助于模型收敛到更好的结果。
- 消融研究:像做化学实验一样,每次拿走模型的一个部件(比如去掉 PVL,或者去掉概率机制),看性能下降多少,以此证明该部件的必要性。
Table 1 _ 少样本结果展示
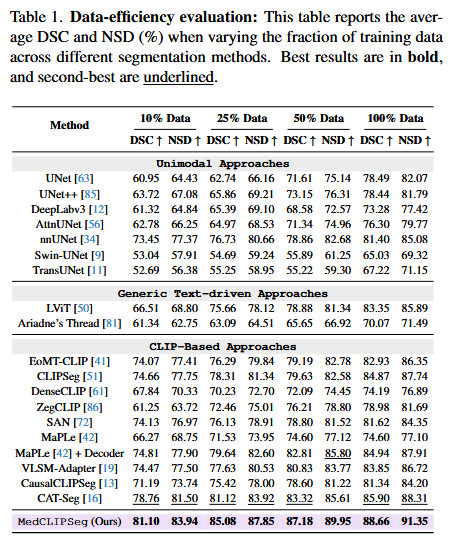
这张表强有力地证明了 MedCLIPSeg 是一个极度省数据且性能天花板极高的模型,完美解决了医学领域标注难、数据少的痛点。
如何解读这张表
-
看列(实验条件):
- 表格被分为四个主要板块,分别代表使用了 10%、25%、50%、100% 的训练数据。
- 这模拟了从“极度缺乏数据”到“数据充足”的四种场景。
-
看行(对比选手):
- Unimodal Approaches:纯图像模型(如 UNet),不看文字。
- Generic Text-driven Approaches:通用的图文模型。
- CLIP-Based Approaches:基于 CLIP 的医学模型(这是最强的竞争对手圈)。
- MedCLIPSeg (Ours):作者提出的模型(表格最底行紫色)。
-
看指标(成绩):
- DSC ↑:Dice 相似系数,越高越好(主要看这个)。
- NSD ↑:归一化表面距离,衡量边缘贴合度,越高越好。
- 粗体:全场最高分。
- 下划线:全场第二高分。
Table 2 _ 域泛化性结果
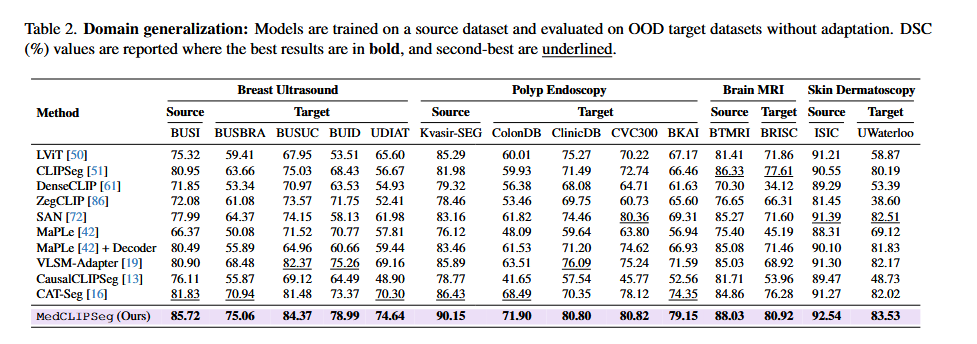
这张表(Table 2)专门用来测试模型的“举一反三”能力,也就是域泛化。它的核心逻辑是:让模型在一家医院的数据(Source)上学习,然后直接去另一家设备、环境完全不同的医院(Target)考试,中间不给任何复习机会,以此检验模型是否真的“学懂了”而不是“死记硬背”。
如何解读这张表
1. 看实验逻辑(Source vs. Target)
表格被分成了四个主要的医学领域板块:
- 乳腺超声
- 息肉内镜
- 脑部 MRI
- 皮肤镜
在每个板块中:
- Source:这是训练集。例如在乳腺超声中,模型只在 BUSI 数据上训练。
- Target:这是测试集(OOD,即分布外数据)。例如 BUSUC、BUID 等。这些数据的拍摄机器、图像质量、甚至病人群体都和 Source 不同。
2. 看对比对象
- 上半部分:是一些通用的视觉模型(如 LViT, CLIPSeg)。
- 中间部分:是一些医学专用的分割模型(如 SAN, MaPLe)。
- 下半部分:是基于 CLIP 的最强竞争对手(如 CAT-Seg)。
- 最底行:是作者的 MedCLIPSeg。
3. 看成绩
同样是 粗体 代表第一,下划线 代表第二。注意这里的分数通常比 Table 1 低,因为这是“跨域考试”,难度更大。
Table 3 _ 消融实验
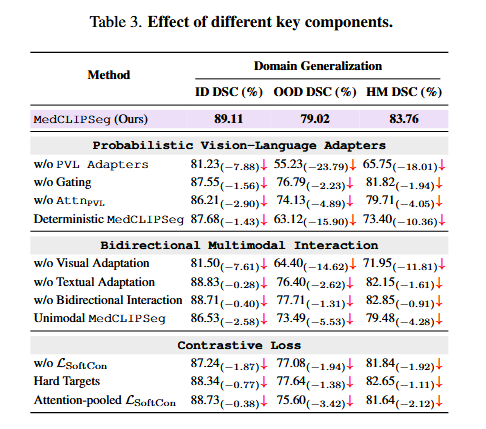
这张表(Table 3)通常被称为“消融实验”,它的作用是给模型做“减法”。如果把之前的实验看作是“与其他选手的比赛”,那么这个实验就是作者的“内部复盘”。
作者通过逐个移除模型的关键组件(比如拿掉PVL适配器、拿掉门控机制等),观察性能下降了多少,从而证明每个组件都是不可或缺的,并非凑数。
如何解读这张表
1. 看指标
- ID DSC (%):在训练过的数据上的表现(例如在 BUSI 上训练,在 BUSI 上测)。
- OOD DSC (%):在没见过的数据上的表现(例如在 BUSI 上训练,去 BUSUC 上测)。这是检验泛化能力的核心指标。
- HM DSC (%):ID 和 OOD 的调和平均数。这个分数越高,说明模型既没有死记硬背,也没有过度泛化导致精度下降,达到了最佳平衡。
2. 看括号里的数字
- 表格中的红色箭头和括号数字(如
-7.88)代表了“移除该组件后,分数下降了多少”。数字越大,说明这个组件越重要。
3. 看分组
表格分成了三个板块,分别测试了三类核心技术:
- Probabilistic Vision-Language Adapters:测试概率性视觉-语言适配器及其内部机制。
- Bidirectional Multimodal Interaction:测试双向多模态交互机制。
- Contrastive Loss:测试损失函数的设计。
Table 4 _ 提示词影响的实验结果
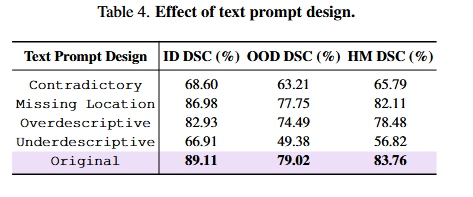
如何解读这张表
1. 实验逻辑
作者对比了五种不同风格的文本提示词:
- Contradictory:矛盾的提示(故意给错误信息,比如“这是一个健康的组织”)。
- Missing Location:缺失位置信息的提示(只说“这是肿瘤”,没说“在左上角”)。
- Overdescriptive:过度啰嗦的提示(描述太长,包含很多无关细节)。
- Underscriptive:描述不足的提示(太简短,信息量不够)。
- Original:原始提示(作者设计的最佳提示,简洁且包含关键信息)。
2. 看指标
- 依然是 ID(已知域)、OOD(未知域)和 HM(调和平均)。
- 核心看点:哪种说话方式能让模型在陌生数据(OOD)上也表现最好。
Figure 4 _ 模型在实际图像上的分割效果和置信度分析
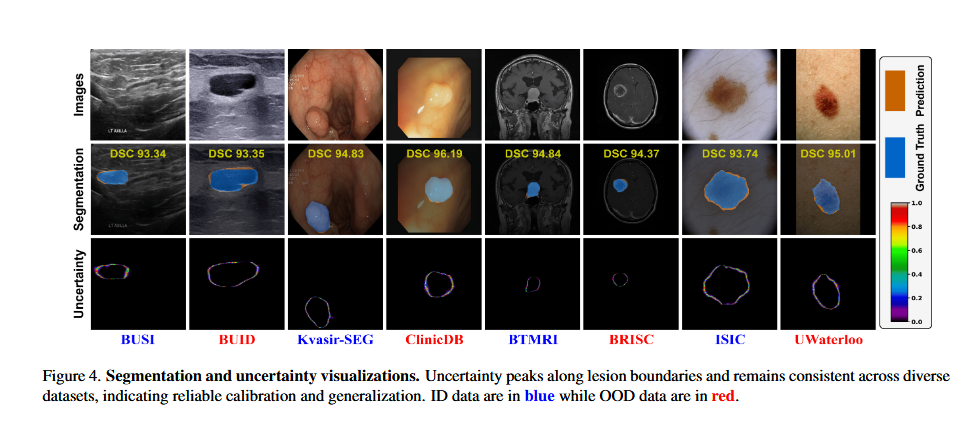
如何解读这张图
1. 看列(不同数据集)
每一列代表一个不同的医学数据集,涵盖了多种模态:
- BUSI, BUID:乳腺超声。
- Kvasir-SEG, ClinicDB:肠道内镜(息肉)。
- BTMRI, BRISC:脑部核磁。
- ISIC, UWaterloo:皮肤病变。
这些数据集展示了模型在不同器官、不同成像设备下的广泛适用性。
2. 看行(不同展示内容)
- 第一行 (Images):原始输入图像。
- 第二行 (Segmentation):分割结果。
- 蓝色区域:模型预测的病变区域。
- 橙色轮廓线:医生标注的真实病变边界。
- DSC 分数:每一列上方的黄色数字,显示分割的重合度,都在 93% - 96% 之间,说明重合度极高。
- 第三行 (Uncertainty):不确定性可视化(热力图)。
- 这是模型在“自我反思”,颜色越亮(偏红/黄),代表模型越“犹豫”;颜色越暗(偏蓝/黑),代表模型越“自信”。
3. 看颜色条
- 右侧的色条显示,红色代表高不确定性(1.0),蓝色代表低不确定性(0.0)。
Figure 5 _ 模型超参数的调优实验
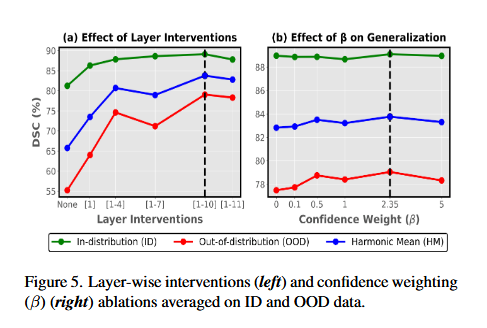
这张图(Figure 5)展示了两个关于模型超参数的调优实验,可以理解为给模型“微调旋钮”,以找到最佳性能点。这类分析通常用来解释为什么模型效果好,以及如何通过调整参数进一步提升性能。
如何解读这张图
1. 左图 (a):层级干预的效果
- 横轴:表示在模型的不同层级(从浅层到深层)进行干预。
[1-4]代表前4层,[1-7]代表前7层,以此类推。None代表不进行干预。
- 纵轴:DSC 分数(分割精度)。
- 三条线:
- 绿色:ID 数据(训练过的数据)。
- 红色:OOD 数据(没见过的数据,最关键的指标)。
- 蓝色:HM(综合指标)。
2. 右图 (b):置信度权重 β 的效果
- 横轴:置信度权重 β 的数值,从 0 到 5。这个参数通常用于控制模型在计算损失函数时,对高置信度样本的重视程度。
- 纵轴:DSC 分数。
- 三条线:同上(绿=ID,红=OOD,蓝=HM)。
Table 5 _ “底座”对模型性能的影响
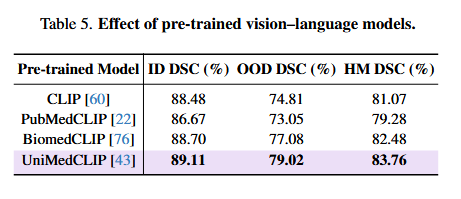
这张表(Table 5)的核心是探究“底座”对模型性能的影响。如果把整个模型比作一辆高性能跑车,那么预训练模型就是它的引擎。作者在这里对比了四种不同的“引擎”(预训练模型),来看看哪个最能带动他们的 MedCLIPSeg 系统跑得更快、更稳。
如何解读这张表
1. 实验对象:四种“引擎”
- CLIP:这是最基础的通用版预训练模型,在海量自然图像(如互联网图片)上训练,不懂医学知识。
- PubMedCLIP:在生物医学文献摘要(PubMed)上训练过的版本,懂一点医学文本,但图像理解可能还是通用的。
- BiomedCLIP:专门针对生物医学领域训练的模型,兼顾了图文。
- UniMedCLIP:这是一个更统一、更强大的医学多模态模型,作者最终选用的底座。
2. 看指标
依然是 ID(训练域)、OOD(测试域)和 HM(综合分)。这里的目的是看换了不同的底座,模型的“举一反三”能力(OOD)会不会受影响。
五、结论
这篇论文提出了 MedCLIPSeg,这是一个专为文本驱动的医学图像分割设计的概率框架。其核心在于引入了 PVL 适配器,实现了置信度加权注意力机制与显式不确定性估计。通过双向融合与软补丁级对比损失,该框架充分利用了 CLIP 的预训练特征,在六个器官、五种模态的数据上实现了 SOTA 分割性能,同时具备高数据效率、强分布外泛化能力与校准良好的不确定性,为医疗 AI 中可靠视觉语言模型的应用提供了重要进展。
具体而言,MedCLIPSeg 的技术优势体现在以下三方面:
- 概率化设计:不同于传统确定性分割模型,MedCLIPSeg 通过 PVL 适配器输出“不确定性热力图”,在病灶边缘等模糊区域主动提示高风险,提升临床可信度。
- 高效泛化能力:依托 CLIP 预训练特征与软补丁对比损失,模型在仅用少量标注数据的情况下,仍能跨医院、跨设备保持稳定表现,显著降低部署成本。
- 医学专用底座优势:实验表明,采用 UniMedCLIP 作为视觉语言底座时,模型在分布外数据上的分割精度(OOD DSC 79.02%)显著优于通用 CLIP(74.81%),验证了医学领域预训练对跨模态理解的关键作用。
该工作不仅推动了文本引导分割的精度边界,更通过不确定性建模与跨域鲁棒性,为临床落地提供了可解释、可信赖的技术路径。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)