深度学习(7)感知机
1. 单层感知机
1.1 感知机

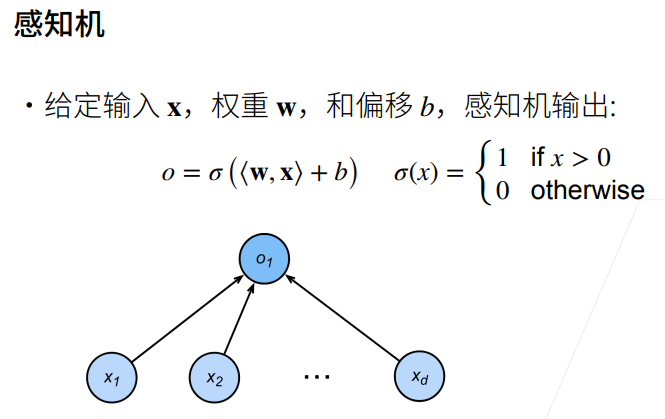
① 线性回归输出的是一个实数,感知机输出的是一个离散的类。

1.2 训练感知机
① 如果分类正确的话y<w,x>为正数,负号后变为一个负数,max后输出为0,则梯度不进行更新。
② 如果分类错了,y<w,x>为负数,下图中的if判断就成立了,就有梯度进行更新。

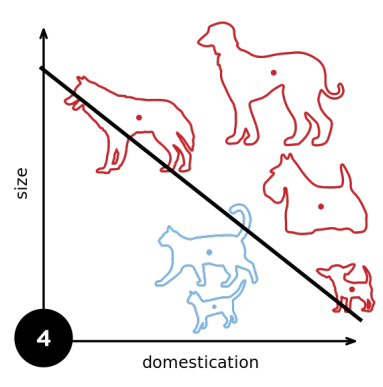
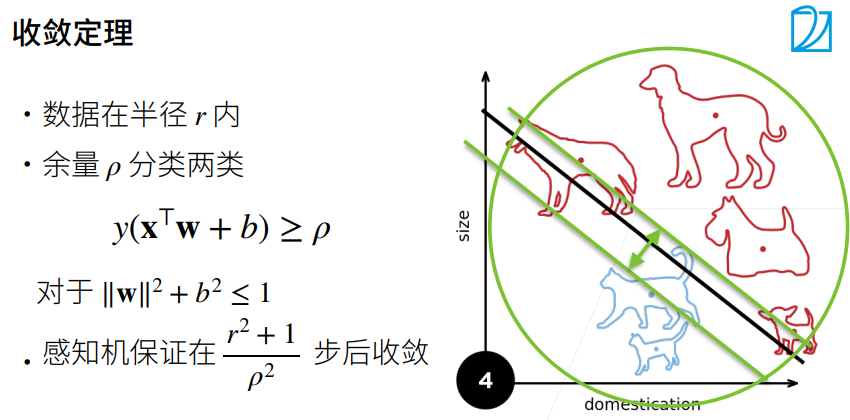
1.3 收敛半径
r是数据的大小
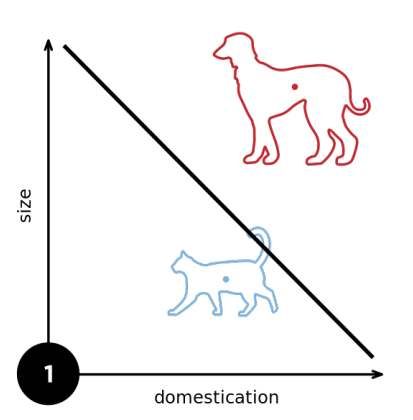
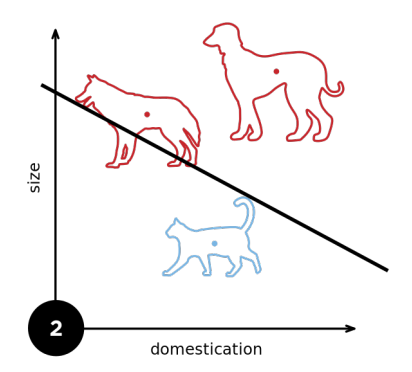
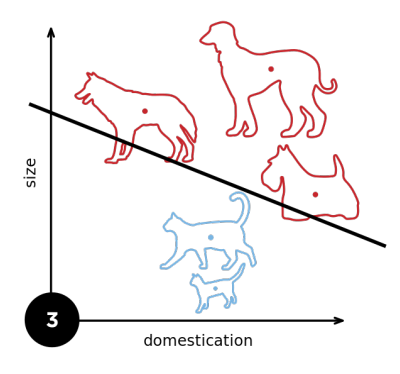
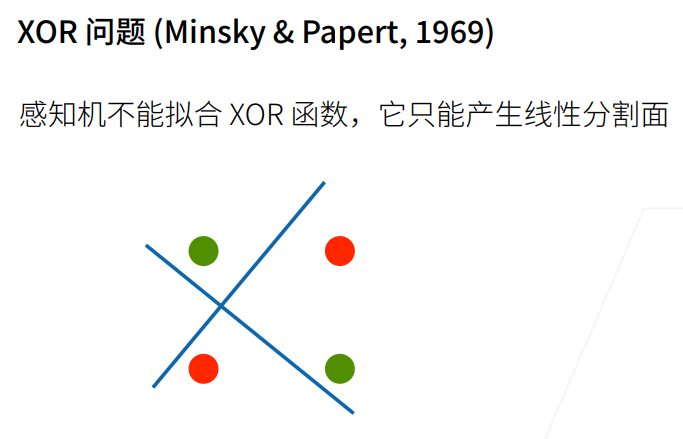
1.4 XOR问题
感知机不能分割异或问题;异或问题:同为1则为-1;同为0也为-1;不同则为1;
1.5 总结

2. 多层感知机
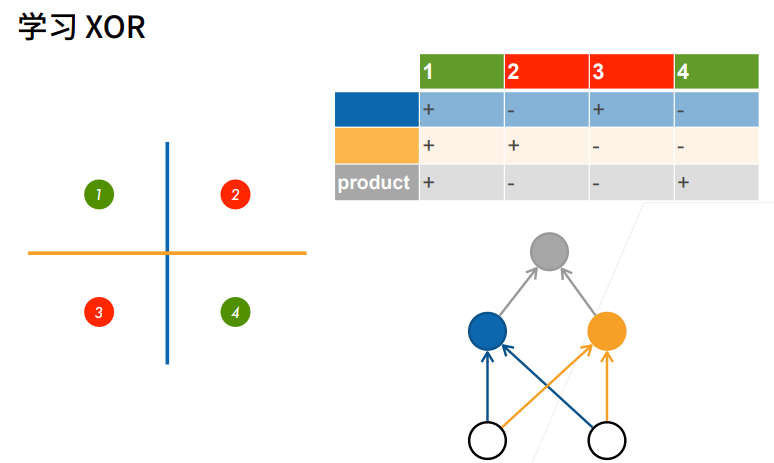
2.1 学习XOR
① 先用蓝色的线分,再用黄色的线分。
② 再对蓝色的线和黄色的线分出来的结果做乘法。【同正异负】
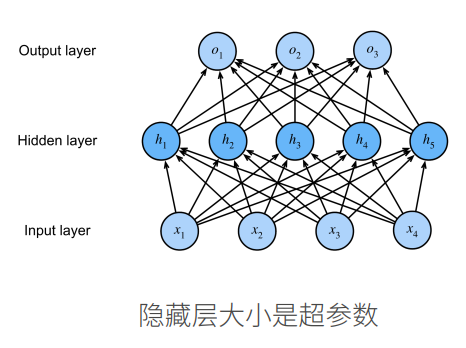
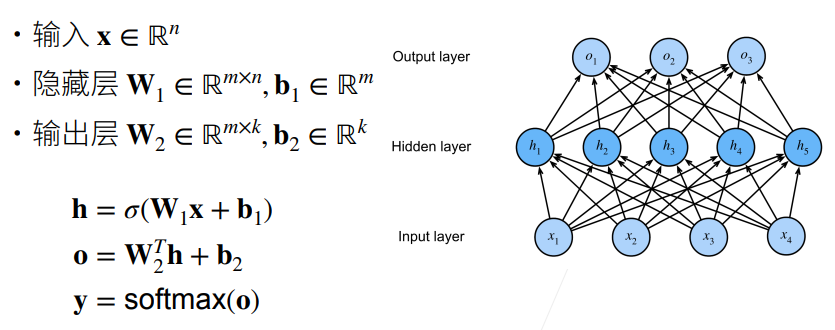
2.2 单隐藏层
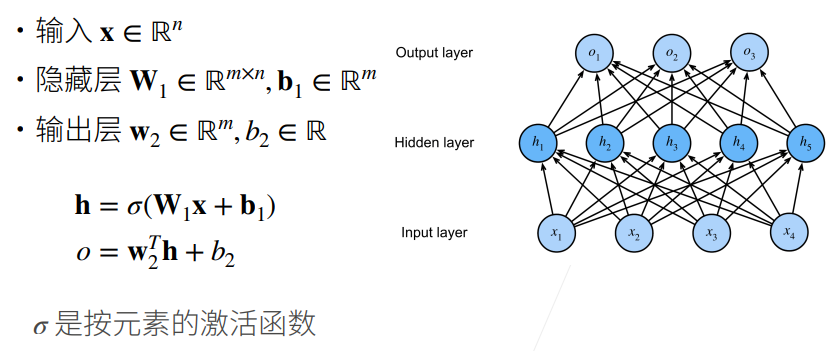
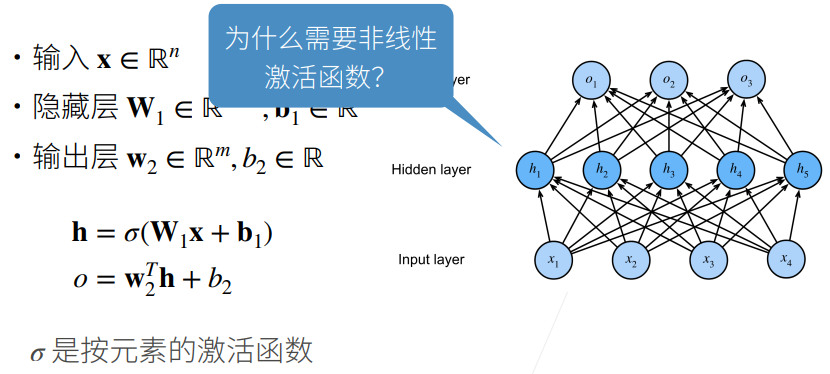
① 不用激活函数的话,所以全连接层连接在一起依旧可以用一个最简单的线性函数来表示。
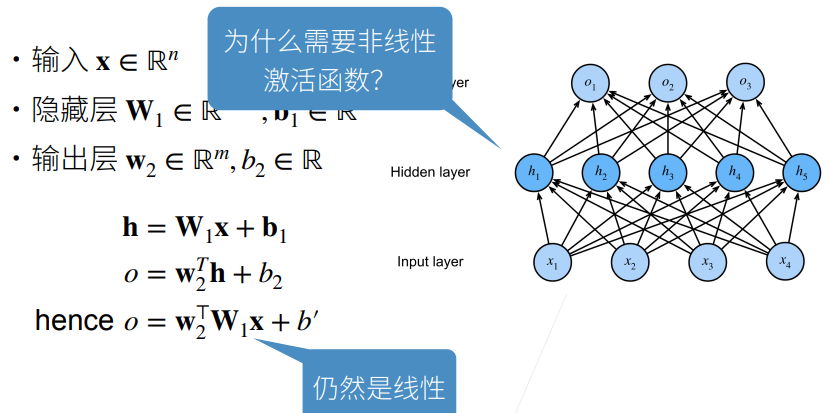
2.3 Sigmoid 函数
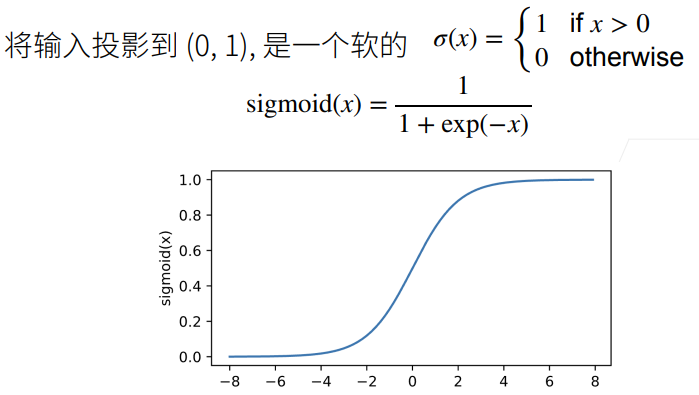
2.4 Tanh函数
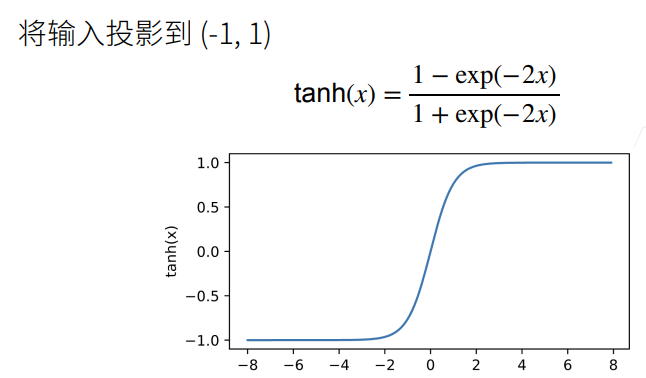
2.5 ReLU
① ReLU的好处在于不需要执行指数运算。
② 在CPU上一次指数运算相当于上百次乘法运算。
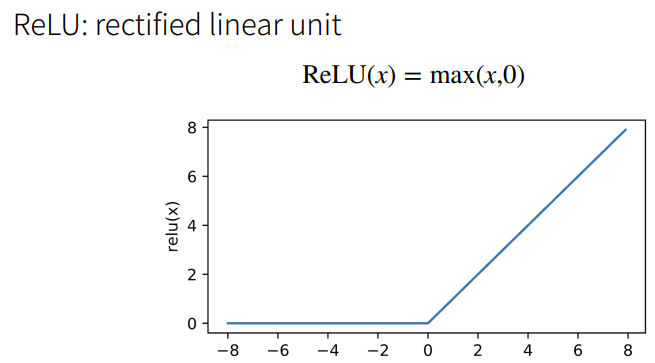
2.6 多类分类
softmax就是将所有输入拉到0-1之间,所有输出的和为1
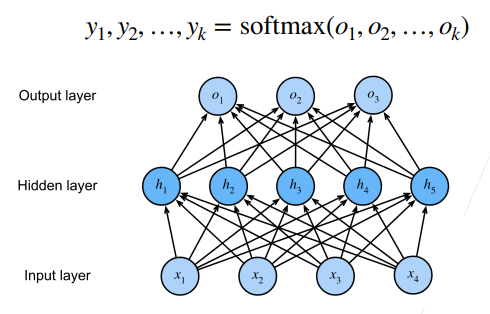
第一个隐藏层的输出会作为第二个隐藏层的输入;PS:不要忘记使用激活函数
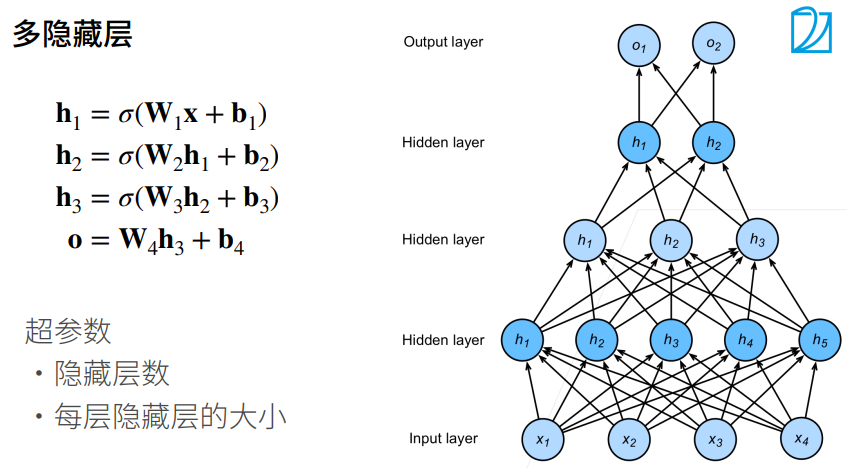
2.7 总结

1. 多层感知机(使用自定义)
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 实现一个具有单隐藏层的多层感知机,它包含256个隐藏单元
num_inputs, num_outputs, num_hiddens = 784, 10, 256 # 输入、输出是数据决定的,256是调参自己决定的
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True))
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True))
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1,b1,W2,b2]
# 实现 ReLu 激活函数
def relu(X):
a = torch.zeros_like(X) # 数据类型、形状都一样,但是值全为 0
return torch.max(X,a)
# 实现模型
def net(X):
#print("X.shape:",X.shape)
X = X.reshape((-1, num_inputs)) # -1为自适应的批量大小
#print("X.shape:",X.shape)
H = relu(X @ W1 + b1)
#print("H.shape:",H.shape)
#print("W2.shape:",W2.shape)
return (H @ W2 + b2)
# 损失
loss = nn.CrossEntropyLoss() # 交叉熵损失
# 多层感知机的训练过程与softmax回归的训练过程完全一样
#num_epochs ,lr = 30, 0.1
#updater = torch.optim.SGD(params, lr=lr)
#d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
#手动实现训练过程
num_epochs, lr = 30, 0.1
updater = torch.optim.SGD(params, lr=lr)
for epoch in range(num_epochs):
total_loss, total_acc, n = 0.0, 0.0, 0
for X, y in train_iter:
l = loss(net(X), y)
updater.zero_grad()
l.backward()
updater.step()
total_loss += l.item() * y.numel()
total_acc += (net(X).argmax(axis=1) == y).sum().item()
n += y.numel()
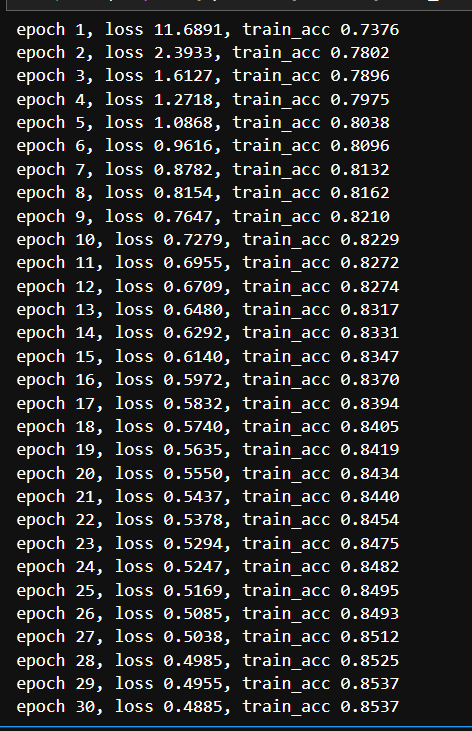
print(f'epoch {epoch + 1}, loss {total_loss / n:.4f}, train_acc {total_acc / n:.4f}')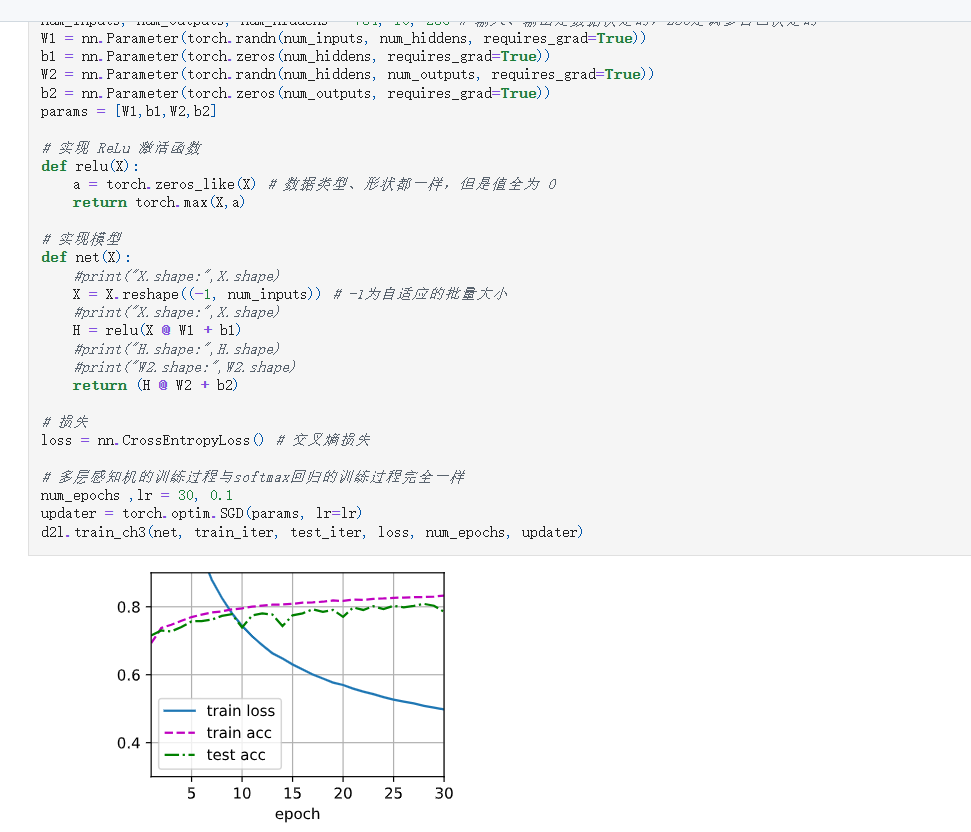
解释:
1. 导入工具
import torch from torch import nn from d2l import torch as d2l
torch:PyTorch 深度学习框架
nn:PyTorch 里专门用来搭神经网络的工具箱
d2l:李沐老师《动手学深度学习》配套的教程工具包,里面有很多方便的函数(比如加载数据、训练可视化)
2. 加载 Fashion-MNIST 数据集
batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
这是一个衣服/鞋子/包包等 10 类小图片的数据集
每张图是 28×28 像素(灰度图)
batch_size = 256:一次取 256 张图来训练,不会一次把所有数据塞进去(内存不够)
train_iter:训练数据迭代器
test_iter:测试(验证)数据迭代器相当于:准备好一批图片,每次拿 256 张给模型看。
3. 定义输入输出维度
num_inputs, num_outputs, num_hiddens = 784, 10, 256
num_inputs = 784:一张 28×28 图片展平后就是 784 个像素点(特征)
num_outputs = 10:最后要分成 10 个类别(上衣、裤子、鞋等)
num_hiddens = 256:隐藏层大小(中间层的神经元个数),可以当作“可以调节的超参数”就像:模型中间加一个“思考层”,有 256 个神经元。
4. 定义两层神经网络的参数(权重 W、偏置 b)
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True)) b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True)) W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True)) b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True)) params = [W1,b1,W2,b2]
nn.Parameter:告诉 PyTorch 这些变量是“需要被训练的参数”
torch.randn:随机初始化(从正态分布中取一些数)
requires_grad=True:PyTorch 会自动计算梯度,帮我们更新参数两个全连接层(也叫线性层):
第一层:784 → 256
第二层:256 → 10
你可以理解成:
第一层从 784 维压缩到 256 维(提取特征)
第二层从 256 维映射到 10 维(分类结果)
5. 实现 ReLU 激活函数
def relu(X): a = torch.zeros_like(X) return torch.max(X, a)
对每个元素:如果是负数就变成 0,正数保持不变
给神经网络引入“非线性能力”(不然多层线性层等于一层)
就像:负值直接“掐掉”,只让正信息往后传。
6. 前向传播(模型如何计算)
python
def net(X): X = X.reshape((-1, num_inputs)) # 把图片拉平 H = relu(X @ W1 + b1) # 第一层 return H @ W2 + b2 # 第二层(得到 10 个分数)
X @ W1:矩阵乘法(等价于torch.matmul)
-1:自动推导 batch size(256)你给模型一张图
→ 展平成 784 长度
→ 第一层算出 256 个值
→ ReLU 把负数变 0
→ 第二层算出 10 个分数(哪个类别的分数高,就预测是哪一类)
7. 损失函数
loss = nn.CrossEntropyLoss()
交叉熵损失:专门用于分类问题
它会同时做
softmax + 求损失,不需要我们自己写 softmax相当于告诉模型:“你预测错的越离谱,我给你的分数越差”。
8. 训练模型
num_epochs ,lr = 30, 0.1 updater = torch.optim.SGD(params, lr=lr) d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
epochs = 30:把全部数据学习 30 遍
lr = 0.1:学习率(每次迈多大步子去优化)
SGD:随机梯度下降优化器,帮我们一步一步减小损失
train_ch3:d2l 提供的训练函数,会打印训练损失和准确率这就是让模型一遍遍看数据,不断调整参数,直到效果还不错。
一句话总结
这段代码实现了一个两层全连接神经网络(MLP),手写数字/衣服分类任务,通过 30 轮迭代训练,让模型学会把 28×28 像素的图片分为 10 类。
2. 多层感知机(使用框架)
① 调用高级API更简洁地实现多层感知机。
import torch
from torch import nn
from d2l import torch as d2l
# 隐藏层包含256个隐藏单元,并使用了ReLU激活函数
net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std=0,)
net.apply(init_weights)
# 训练过程
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)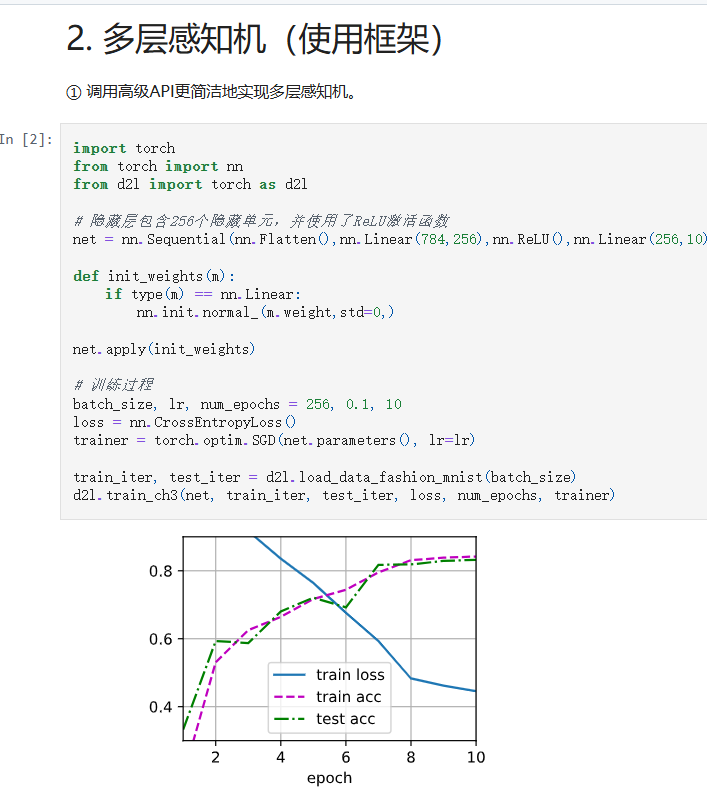
1️⃣ 准备数据
batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
去网上下载一个叫 Fashion-MNIST 的数据集
里面全是衣服、鞋子、包、裙子等 10 类图片
分成两部分:
train_iter:训练集(用来学习)
test_iter:测试集(用来考试)每次看 256 张,不一次看完
就像:你有一本 1000 页的习题册,每次翻 256 页来学。
2️⃣ 搭建模型
net = nn.Sequential( nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10) )这段就是在“造大脑”:
Flatten:把 28×28 的图片拉成一长条(784 个数字)
Linear(784, 256):第一层“思考层”,把 784 个数字压缩成 256 个核心特征
ReLU:只把“正的想法”传下去,负的丢掉
Linear(256, 10):第二层,最终输出 10 个分数(每个类别一个分数)分数最高的那一类,就是模型的“猜测”。
3️⃣ 初始化参数
def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights)
给模型的“脑细胞”设一个初始值
一开始什么都不会,但也不能全是 0(否则学不动)
就像:小朋友刚开始学认东西,脑子里啥也没有,但脑子结构是正常的。
4️⃣ 准备“裁判”和“教练”
loss = nn.CrossEntropyLoss() trainer = torch.optim.SGD(net.parameters(), lr=0.1)
loss:判断模型猜得对不对、差多远(交叉熵损失)
trainer:根据“差多远”去调整模型的内部参数(SGD 优化器)裁判打分,教练调动作。
5️⃣ 开始训练
d2l.train_ch3(net, train_iter, test_iter, loss, 10, trainer)
模型把训练数据看 10 遍(epochs = 10)
每看一遍,就调整一次内部的“脑细胞连接”
训练过程中,会在测试集上看看效果怎么样了
就像:拿着习题册反复刷题,每刷一遍就进步一点。
一句话总结“整体思路”
准备一批图片 → 搭一个“脑残”模型 → 让模型一遍一遍看图片和正确答案 → 每次猜错就纠正内部参数 → 最后考试

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)