一篇跑通 Spring AI Alibaba RAG:文档上传、向量检索、知识库问答全实战(附源码)
这篇文章只讲一件事:怎么用 `Spring AI Alibaba + Milvus` 跑通一套真正能落地的 RAG 知识库。
看完你会得到两样东西:一是搞清楚 `检索、增强、生成` 这条链路到底怎么接,二是拿到一套可以继续往企业知识库场景演进的实战思路。
RAG 说白了就三步:先检索,再补充上下文,最后让模型生成答案。难点不在概念,而在工程落地。
这篇就用 `Spring AI Alibaba + Milvus` 把这条链路完整跑一遍:
`文件上传 -> 文档解析 -> 文本切分 -> 向量化 -> Milvus 存储 -> 检索增强 -> 大模型回答`
如果你是 `Java / Spring Boot` 开发者,这套方案会很好上手。下面直接进入实战。
一 、 引入 Milvus 向量存储依赖
RAG 的第一步是检索,而语义检索的基础就是向量库。
这里我们选 `Milvus`,原因也很直接:
-
方案成熟
-
社区广泛使用
-
和
Spring AI的集成比较顺
先引入依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-vector-store-milvus</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>这几个依赖可以理解成三层能力:
-
向量存储能力
-
Spring Boot 自动配置能力
-
RAG 检索增强能力
把这三件事补齐,后面整条链路才接得起来。
二 、在 application.yml 里接上 Milvus
依赖加完,下一步就是连接配置。
spring:
ai:
vectorstore:
milvus:
enabled: true
initialize-schema: true
client:
host: "1.111.115.117"
port: 19530
username: "minioadmin"
password: "minioadmin"
databaseName: "default"
collectionName: "vector_store"
embeddingDimension: 1024
metricType: COSINE这里有几个参数要特别注意。`initialize-schema: true`
它的作用是应用启动时自动初始化集合,适合我们这种先快速跑通链路的场景。
`embeddingDimension: 1024`
这个维度必须和你实际使用的嵌入模型输出一致。这个地方一旦不匹配,后面写向量时大概率会直接报错。
`metricType: COSINE`
这是文本语义检索里很常见的一种相似度计算方式,绝大多数场景下都够用。
到这里为止,你的应用已经具备连接 Milvus 的能力了。
但光能连上还不够,向量库里还得先有内容。
三、启动时初始化一批测试向量数据
很多人做 RAG,容易一上来就卡在“为什么查不到数据”。
所以最实用的方式,是先在应用启动时塞一批演示文档,先验证整条链是不是通的。
@Configuration
public class MilvusInitializer {
private static final Logger logger = LoggerFactory.getLogger(MilvusInitializer.class);
@Bean("milvusDataInitializer")
public ApplicationRunner milvusInitializer(
VectorStore vectorStore,
@Value("${spring.ai.vectorstore.milvus.initialize-demo-data:true}") boolean initializeDemoData) {
return args -> {
if (initializeDemoData) {
logger.info("开始初始化Milvus数据...");
List<Document> demoDocs = List.of(
new Document("苹果是一种常见的水果,富含维生素C和纤维素"),
new Document("香蕉是热带水果,含有丰富的钾元素"),
new Document("橙子味道酸甜,富含维生素C"),
new Document("草莓外观鲜红,口感甜美,富含抗氧化物质"),
new Document("葡萄可以制作葡萄酒,含有多种有益成分")
);
try {
int batchSize = 10;
for (int i = 0; i < demoDocs.size(); i += batchSize) {
int endIndex = Math.min(i + batchSize, demoDocs.size());
List<Document> batch = demoDocs.subList(i, endIndex);
vectorStore.add(batch);
logger.info("已添加批次文档到Milvus,批次范围: {}-{}", i, endIndex - 1);
}
logger.info("成功添加 {} 个文档到Milvus", demoDocs.size());
} catch (Exception e) {
logger.warn("添加数据到Milvus时出现错误,由于集合尚未完全准备好,错误信息: {}", e.getMessage());
}
}
};
}
}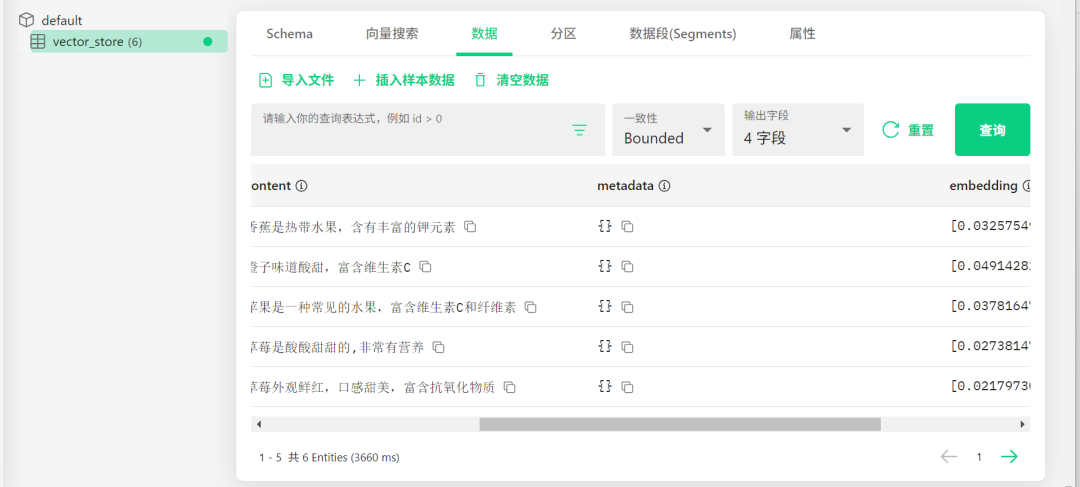
这段代码的价值,不只是“放几条水果数据做演示”。
它背后其实是在做一件更重要的事:
先把向量存储、向量写入、集合初始化这几个环节验证通。
另外,这里保留“分批写入”也很有必要。
因为你后面如果接的是在线 Embedding 服务,批量大小往往会受到限制。提前按批次写,工程上会更稳。
四、把 QuestionAnswerAdvisor 接进 ChatClient
前面只是把数据放进了向量库。
真正让 RAG 发挥作用的关键,是让模型在回答前先去检索。
在 `Spring AI` 里,这一步的核心组件之一就是 `QuestionAnswerAdvisor`。
先看配置:
@Configuration
public class ChatConfig {
@Bean
public ChatClient milvusRagChatClient(
@Qualifier("dashscopeChatModel") ChatModel dashscopeChatModel,
RedisChatMemoryRepository redisChatMemoryRepository,
VectorStore vectorStore) {
return ChatClient.builder(dashscopeChatModel)
.defaultSystem("""
你是一位专业的知识库问答助手,名字叫小王同学。
你只能基于 Milvus 向量数据库中检索到的信息回答用户问题。
请遵循以下原则:
1. 只能使用知识库中检索到的信息作答,不要凭空编造内容。
2. 如果检索结果不足以回答问题,要明确告诉用户当前知识库无法支持作答。
3. 回答要简洁、准确、重点清晰,结构尽量明了。
4. 当检索结果与问题相关时,结合这些信息给出可靠答案。
5. 保持专业、客观的语气,不添加无依据的主观判断。
""")
.defaultOptions(DashScopeChatOptions.builder()
.withModel("qwen-plus")
.withTemperature(0.7)
.build())
.defaultAdvisors(
new SimpleLoggerAdvisor(),
MessageChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.chatMemoryRepository(redisChatMemoryRepository)
.maxMessages(Integer.MAX_VALUE)
.build()
).build(),
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.topK(5)
.similarityThreshold(0.7)
.build())
.build()
)
.build();
}
}
这段配置建议重点看三个点。
4.1 System Prompt 负责给模型“划边界”
这里不是为了把 Prompt 写得多华丽,而是为了限制模型别乱答。
尤其在知识库场景里,比“答不上来”更危险的,是“胡说八道但语气很坚定”。
所以你会看到这里明确强调:
-
只能基于检索结果回答
-
检索不到就直接说不知道
-
不要凭空补全
这一步,本质上是在压幻觉。
4.2 MessageChatMemoryAdvisor 负责让对话不断片
如果用户上一轮问“这个接口怎么配”,下一轮又问“那端口号是多少”,系统必须知道“那”指的是前文哪个上下文。
这就是聊天记忆的意义。
它不直接负责检索,但会极大改善多轮问答体验。
4.2.1 QuestionAnswerAdvisor 负责把检索结果真正塞进问答流程
这才是 RAG 最核心的一步。
用户提问后,它会先去 `VectorStore` 检索相关片段,再把这些片段补充进模型上下文里,然后模型才开始生成答案。
这里两个参数尤其关键:
- `topK(5)`:拿回最相关的 5 个片段
- `similarityThreshold(0.7)`:只保留相似度达到阈值的内容
RAG 后面很多调优,调的其实就是这两个东西。
五、先做一个最小版的文本入库和问答接口
现在,检索增强能力已经挂进 `ChatClient` 了。
下一步要做的,是把它真正暴露成接口,先跑通最小闭环。
下面这个 Controller 里,包含了两个非常关键的接口:
-
向 Milvus 添加文档
-
基于 Milvus 进行 RAG 问答
@RestController
@RequestMapping("/milvus")
public class MilvusRagController {
@Autowired
private VectorStore vectorStore;
@Autowired
@Qualifier("milvusRagChatClient")
private ChatClient chatClient;
@Autowired
private RedisChatMemoryRepository redisChatMemoryRepository;
@Autowired
private RedisTemplate redisTemplate;
private static final Logger logger = LoggerFactory.getLogger(MilvusRagController.class);
@PostMapping(value = "/add-documents", produces = "text/html;charset=utf-8")
public String addDocuments(String[] text) {
try {
List<Document> documents = Arrays.stream(text)
.map(Document::new)
.toList();
int batchSize = 10;
for (int i = 0; i < documents.size(); i += batchSize) {
int endIndex = Math.min(i + batchSize, documents.size());
List<Document> batch = documents.subList(i, endIndex);
vectorStore.add(batch);
logger.info("已添加批次文档到Milvus,批次范围: {}-{}", i, endIndex - 1);
}
return String.format("成功添加 %d 个文档到Milvus向量数据库", documents.size());
} catch (Exception e) {
logger.error("添加文档到Milvus时发生错误: ", e);
return "添加文档失败: " + e.getMessage();
}
}
@GetMapping(value = "/rag-query", produces = "text/html;charset=utf-8")
public Flux<String> ragQuery(
@RequestParam String query,
@RequestParam(value = "sessionId", defaultValue = "student_session") String sessionId,
@RequestParam(value = "userId", defaultValue = "default_userId") String userId) {
String redisKey = userId + ":" + sessionId;
MessageWindowChatMemory messageWindowChatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(redisChatMemoryRepository)
.maxMessages(Integer.MAX_VALUE)
.build();
if (messageWindowChatMemory.get(redisKey).size() < 1) {
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setValueSerializer(RedisSerializer.json());
BoundListOperations boundListOperations = redisTemplate.boundListOps("history:" + userId);
boundListOperations.leftPush(sessionId);
}
try {
return chatClient.prompt()
.advisors(a -> a.param(CONVERSATION_ID, redisKey))
.user(query)
.advisors(
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder().query(query).build())
.build()
)
.stream()
.content();
} catch (Exception e) {
logger.error("RAG查询时发生错误: ", e);
return Flux.error(e);
}
}
}这一步做完后,你已经有了一个最基础的知识库问答雏形。
也就是说,只要把文本写进 Milvus,用户提问时系统就能先检索,再作答。
但问题也很明显。
现实业务里,谁会手工一条一条传字符串进知识库?
大家真正需要的,是“直接上传文档”。
所以接下来这一步,才是让这套方案真正从 Demo 走向可用的关键。
六、接入文件读取能力,让知识库开始像个产品
企业知识库里的数据,通常不会老老实实躺成字符串数组。
它更常见的样子是:
-
PDF 产品手册
-
Word 制度文档
-
Markdown 技术文档
-
PPT、Excel、HTML 等各类业务资料
所以如果 RAG 想变成一个真正能用的东西,就必须把“文件读取”接进来。
先加依赖:
<!-- PDF文档读取器 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<!-- Markdown文档读取器 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>
<!-- Tika文档读取器 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- Spring AI Alibaba文档读取器 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-document-reader-poi</artifactId>
</dependency>这里的思路很清楚:
-
PDF 单独处理
-
其他常见文档交给 Tika
-
Spring AI Alibaba 再补一层文档读取支持
这样后面上传各种业务文件时,整个系统才接得住。
七、上传文件、切分文本、向量化入库
到了这里,整篇文章真正最有“实战味”的部分来了。
因为从这一步开始,你处理的就不再是 demo 数据,而是真实文档。
代码如下:
@RestController
@RequestMapping("/api/rag")
public class RagController {
@Autowired
private VectorStore vectorStore;
@Autowired
@Qualifier("milvusRagChatClient")
private ChatClient chatClient;
@Autowired
private RedisChatMemoryRepository redisChatMemoryRepository;
@Autowired
private RedisTemplate redisTemplate;
@PostMapping(value = "/upload", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public ResponseEntity<String> uploadFile(@RequestParam("file") MultipartFile file) {
try {
if (file.isEmpty()) {
return ResponseEntity.badRequest().body("文件不能为空");
}
String filename = file.getOriginalFilename();
String extension = getFileExtension(filename);
List<Document> documentList;
if ("pdf".equalsIgnoreCase(extension)) {
byte[] fileBytes = file.getBytes();
ByteArrayInputStream pdfInputStream = new ByteArrayInputStream(fileBytes);
InputStreamResource pdfResource = new InputStreamResource(pdfInputStream);
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(pdfResource);
documentList = pdfReader.get();
} else {
TikaDocumentReader reader = new TikaDocumentReader(file.getResource());
documentList = reader.get();
}
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> documents = splitter.apply(documentList);
vectorStore.add(documents);
return ResponseEntity.ok("成功上传文件并添加到向量数据库中,一共处理了 " + documents.size() + " 个文档片段");
} catch (Exception e) {
return ResponseEntity.status(500).body("处理文件时发生错误: " + e.getMessage());
}
}
@GetMapping(value = "/query", produces = "text/html;charset=utf-8")
public Flux<String> ragQuery(@RequestParam("question") String question,
@RequestParam("sessionId") String sessionId,
@RequestParam("userId") String userId) {
String redisKey = userId + ":" + sessionId;
MessageWindowChatMemory messageWindowChatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(redisChatMemoryRepository)
.maxMessages(Integer.MAX_VALUE)
.build();
if (messageWindowChatMemory.get(redisKey).size() < 1) {
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setValueSerializer(RedisSerializer.json());
BoundListOperations boundListOperations = redisTemplate.boundListOps("history:" + userId);
boundListOperations.leftPush(sessionId);
}
try {
return chatClient.prompt()
.advisors(a -> a.param(CONVERSATION_ID, redisKey))
.user(question)
.advisors(
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.query(question)
.topK(5)
.similarityThreshold(0.3)
.build())
.build()
)
.stream()
.content();
} catch (Exception e) {
return Flux.error(e);
}
}
private String getFileExtension(String fileName) {
if (fileName == null || !fileName.contains(".")) {
return "";
}
return fileName.substring(fileName.lastIndexOf(".") + 1);
}
}这段代码其实把“企业知识库入库链路”完整串起来了。
7.1 先识别文件类型
PDF 走 `PagePdfDocumentReader`。
其他常见文档走 `TikaDocumentReader`。
这一步解决的是“不同格式,不同读取器”的问题。
7.2 再把整篇文档切成适合检索的小块
这里用的是 `TokenTextSplitter`。
这是 RAG 里一个特别容易被低估,但实际上特别关键的环节。
因为你不能把一整份几十页的 PDF 当成一个大文本块直接去做向量化。
那样会有两个后果:
-
检索粒度太粗
-
上下文噪音太大
只有切成合理的文档片段,向量检索才真正有意义。
7.3 最后向量化并写入 Milvus
`vectorStore.add(documents)` 这一行看起来很轻,但背后其实完成了几件事:
-
文本向量化
-
向量数据写入 Milvus
-
为后续语义检索建立基础
也就是说,从这一刻起,这份文件才真正进入了你的 RAG 知识库。
八、加一个简单页面,先把上传链路跑通
后端链路接完之后,建议先别急着追求页面多漂亮。
先做一个最简单的上传页,把“文件上传 -> 文档解析 -> 向量入库”这段链路验证通,反而更重要。
<!DOCTYPE html>
<html>
<head>
<title>RAG文件上传测试</title>
<meta charset="utf-8">
</head>
<body>
<h1>RAG文件上传测试</h1>
<form id="uploadForm" action="/api/rag/upload" method="post" enctype="multipart/form-data">
<div>
<label for="file">选择文件:</label>
<input type="file" id="file" name="file"
accept=".pdf,.txt,.md,.doc,.docx,.xls,.xlsx,.ppt,.pptx,.html,.xml" required>
</div>
<br>
<button type="submit">上传文件</button>
</form>
</body>
</html>这个页面虽然简单,但它对排障非常有价值。
因为做 RAG 时,最怕的不是“回答有点偏”,而是你根本不知道问题到底出在:
-
文件没传成功
-
文档没解析出来
-
文本没切好
-
向量根本没入库
先把上传这段验证通:
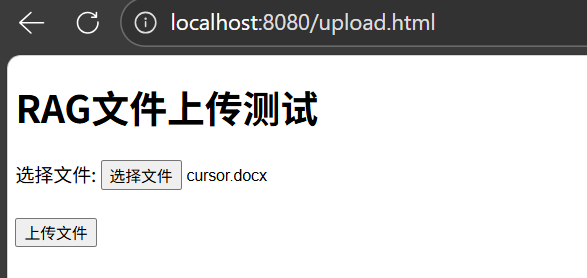
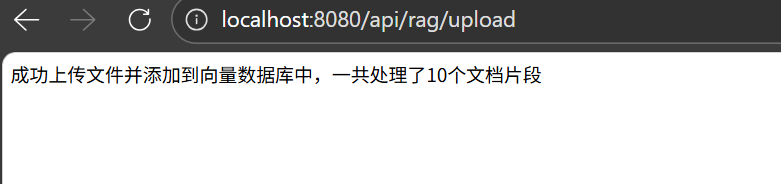
上传了一个cursor的文档:
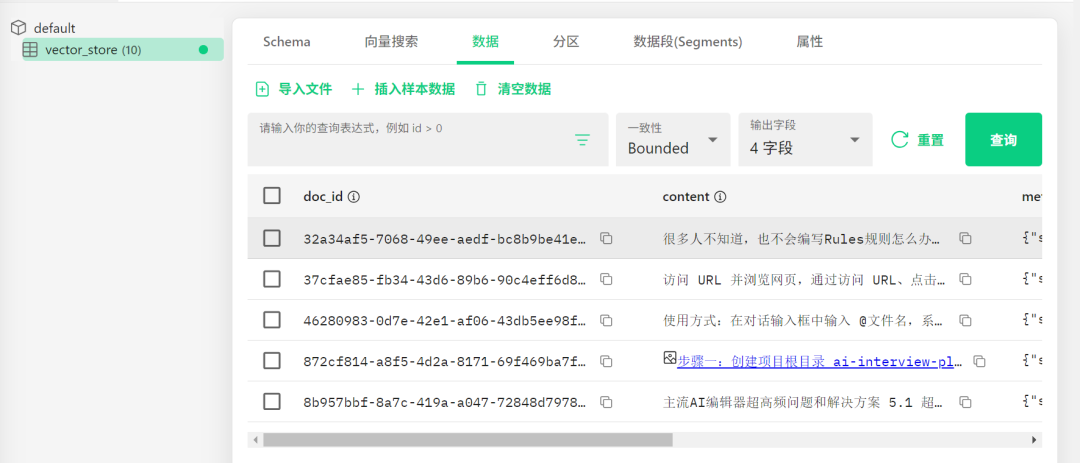
检索内容:
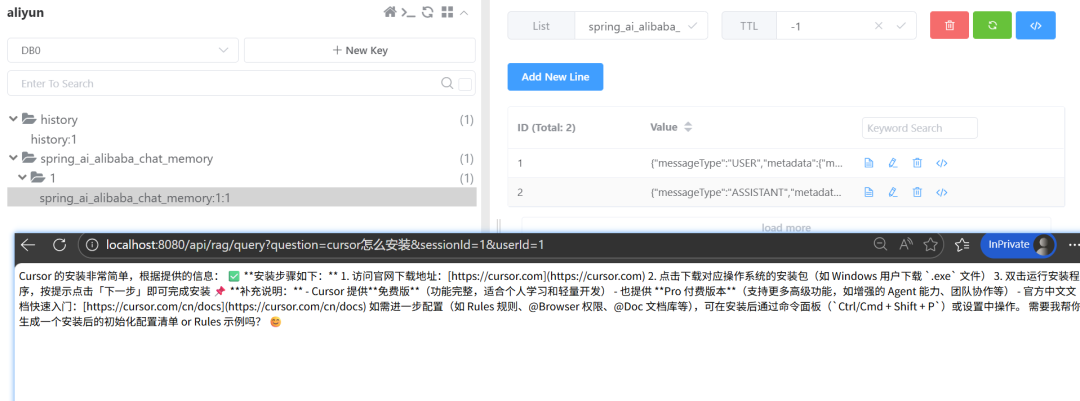
提问一个库中没有的:

记忆功能:
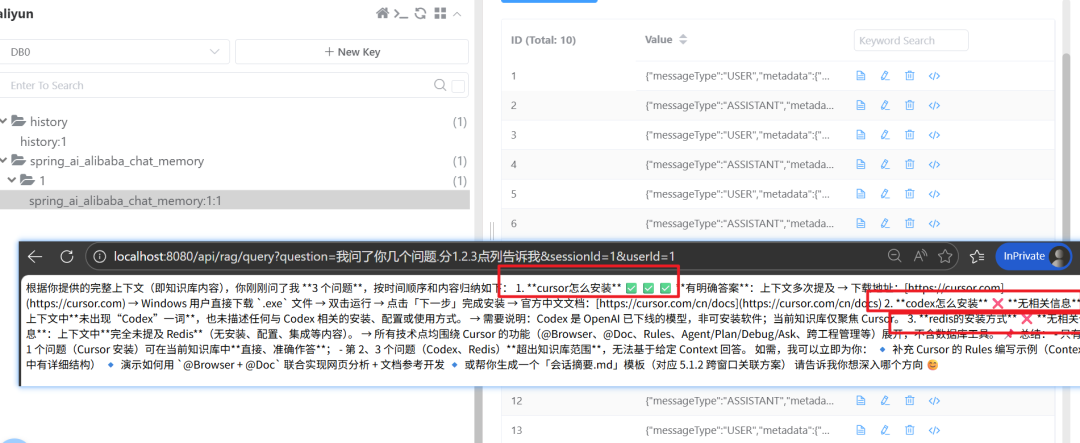
九、到这里,你其实已经有了一套能继续扩展的 RAG 雏形
我们回头看一下这套链路到底做成了什么。
你现在已经完成了:
-
用 `Spring AI Alibaba` 接上模型与文档处理能力
-
用 `Milvus` 存储向量数据
-
用 `TokenTextSplitter` 做文档切片
-
用 `QuestionAnswerAdvisor` 接入检索增强
-
用 `RedisChatMemoryRepository` 保留会话记忆
-
用上传接口实现知识文档动态入库
这意味着你手上的已经不只是一个“会调用大模型 API”的小 Demo,而是一套可以继续往业务知识库方向推进的最小可用版本。
十、最后补几句实战里特别容易踩坑的点
到这里,代码链路算是跑通了。
但如果你准备继续往真实项目推进,这几个点一定要留意。
10.1 Embedding 维度一定要对齐
你在 `application.yml` 里配置了 `embeddingDimension: 1024`,那你的嵌入模型输出维度就必须一致。
这个地方不对齐,后面向量写入基本很难正常。
10.2 文档切分策略会直接影响召回质量
切得太大,检索不准。
切得太碎,语义断裂。
所以 `TokenTextSplitter` 虽然默认能用,但真上线时通常还要结合你的业务文档继续调。
10.3 相似度阈值没有标准答案
文里示例里出现了 `0.7` 和 `0.3` 两种阈值,不是谁错谁对,而是说明:
这个参数必须根据你的数据实测。
不同文档类型、不同 Embedding 模型、不同业务问题,对阈值的敏感度都不一样。
10.4 很多 RAG 问题,本质是数据问题
别一看到回答效果差,就马上怀疑模型。
真实项目里更常见的情况是:
-
知识库内容本身不干净
-
文档切分不合理
-
召回片段质量不高
-
阈值设置太松或太严
-
上下文噪音太大
所以做 RAG,千万别只盯着模型参数。
数据链路和检索链路,往往更决定最终效果。
本文所有调用逻辑、配置、代码我都整理完整可运行项目,不用自己拼凑,直接导入就能测。
如果你对 Java + AI 实战、Spring AI 落地、RAG、MCP、Agent、AI 支付这些内容感兴趣,关注我的技术号,想领取 本节源码的话,关注后后台回复:SpringAI-RAG-Milvus 即可。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)