Java开发者AI转型第十五课!Spring AI神技:模块化RAG引擎一键闭环实战
大家好,我是直奔標杆!专注Java开发者AI转型干货分享,和大家一起从零基础吃透Spring AI,稳步向AI工程师进阶~ 今天带来《Spring AI 零基础到实战》系列的第十五课,也是RAG全链路实战的关键一课,干货拉满,建议收藏慢慢练!
回顾上一课(Java开发者AI转型第十四课!Spring AI向量数据库实操:检索召回与相似度检索实战详解),我们已经掌握了用VectorStore和SearchRequest从私有知识库中精准召回相关文档的技巧。相信很多小伙伴实操后都会有一个疑问:按照传统开发思路,召回文档后,是不是还要写for循环提取文本、拼接字符串,再手动塞进Prompt里发给大模型?
其实不用这么繁琐!今天我们就一起解锁Spring AI中最惊艳的“黑科技”——QuestionAnswerAdvisor与RetrievalAugmentationAdvisor,只需一行代码挂载,就能彻底打通“拦截提问→检索向量库→组装上下文→大模型生成”的RAG全链路闭环,告别冗余代码,高效落地私有知识库问答功能!
本节学习目标(一起打卡进阶)
-
痛点直击:搞懂传统手工拼接RAG Prompt的弊端,避免代码臃肿、开发低效的坑;
-
极简实战:上手QuestionAnswerAdvisor,一行代码快速挂载知识库,实现基础问答;
-
架构深挖:拆解源码,搞懂Modular RAG(模块化检索增强)的八道核心流水线;
-
高阶进阶:实战RetrievalAugmentationAdvisor,像搭乐高一样定制企业级RAG引擎!
揭秘:模块化RAG的自动拦截机制
Spring AI的Advisor API,为我们封装了常用的RAG流程,开箱即用,无需重复造轮子。大家可以参考下方架构图(建议保存),清晰看懂RetrievalAugmentationAdvisor的底层执行逻辑:
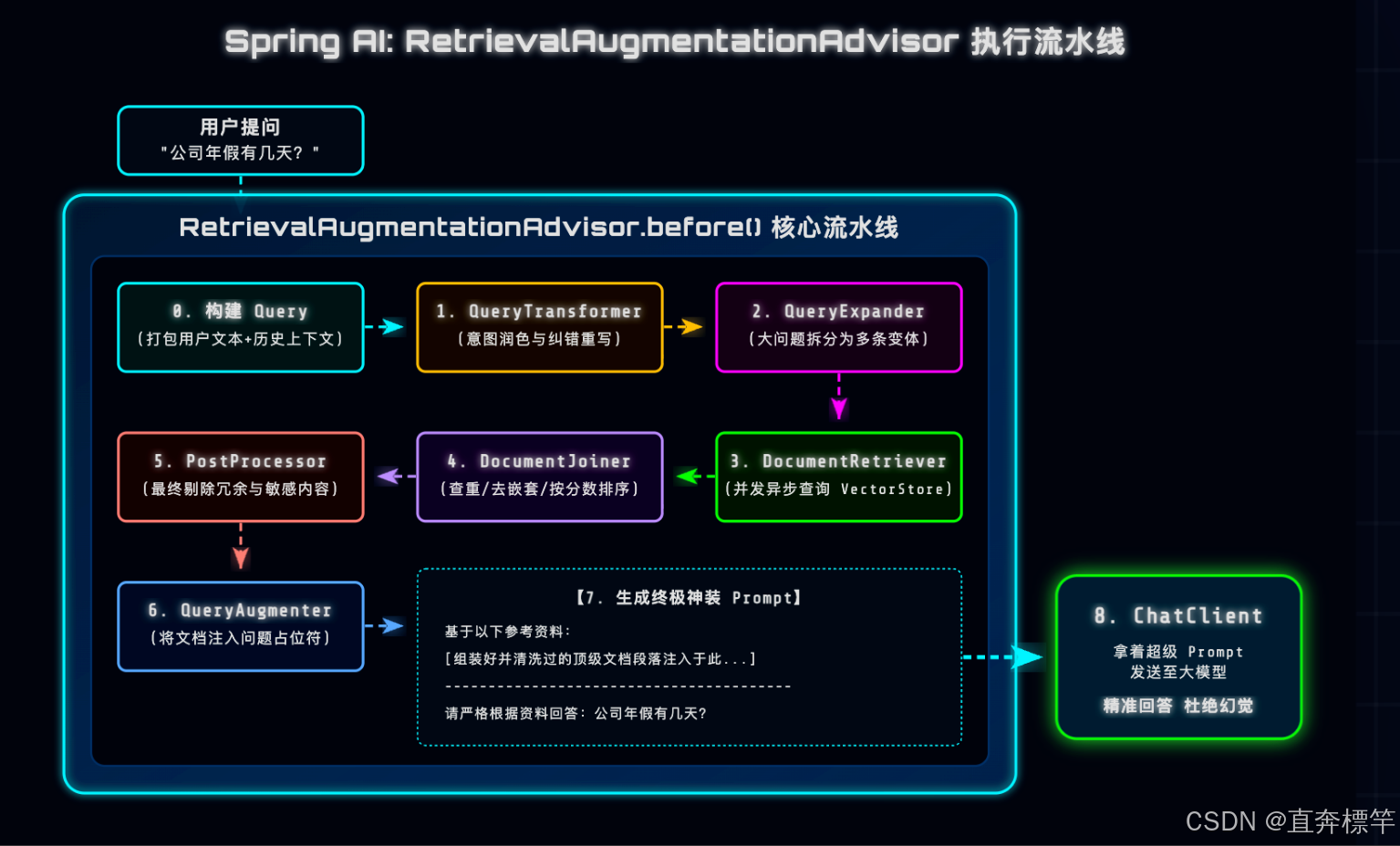
核心亮点:当你调用ChatClient发送请求时,整个RAG流程都会在后台自动执行,无需手动干预——从接收问题到最终生成答案,全链路闭环,这就是Spring AI的便捷之处!
入门实战:QuestionAnswerAdvisor 一键挂载知识库
如果大家只是想快速开发一个基础的私有知识库问答助手,对RAG流程没有过高的定制需求,官方提供的QuestionAnswerAdvisor完全够用,上手零难度,一起实操起来~
第一步:引入依赖
<!-- 引入问答顾问拦截器,用于基础RAG闭环 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>第二步:实战案例(可直接复制运行)
/**
* 账号:直奔標杆
* 说明:QuestionAnswerAdvisor基础实战,一行代码挂载RAG拦截器
*/
@Test
void testQuestionAnswerAdvisor() {
// 初始化ChatClient(上一课已实操,此处省略构建细节)
ChatClient chatClient = chatClientBuild.build();
// 模拟用户提问(实际开发可替换为前端传入的问题)
String message = "公司打车怎么报销";
// 发送请求,挂载RAG拦截器,自动完成检索+上下文组装+生成答案
String content = chatClient.prompt()
.user(message)
.advisors(
// 核心:挂载QuestionAnswerAdvisor,关联向量库
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest.builder()
.topK(3) // 召回前3条最相关文档
.similarityThreshold(0.75) // 相似度阈值,过滤不相关文档
.filterExpression("year == '2026'") // 过滤条件,精准检索
.build()
)
.build()
)
.call() // 发送请求,拦截器自动处理全流程
.content();
// 打印结果
System.out.println(content);
}第三步:运行结果(实测可用)
根据提供的上下文信息,公司打车报销的具体政策如下: 1. 【夜间加班打车】 - 适用条件:工作日晚上22:00(含)后下班的员工。 - 报销方式:直接通过企业滴滴打车叫车回家,费用由公司企业账户代付,无需个人垫资或贴票。 2. 【部门团建费用】 - 额度:每位转正员工每季度200元。 - 报销要求:需由部门负责人统一策划,并在当季度内完成报销,额度不跨季度累计。 如果您的报销需求不在上述范围内(例如非加班时间的打车或其他费用),则无法根据当前提供的信息回答。请进一步咨询公司财务或行政部门确认其他报销政策。
进阶优化:自定义Prompt模板(贴合业务场景)
默认情况下,QuestionAnswerAdvisor使用的是框架自带的英文Prompt,实际开发中我们可以自定义模板,给AI赋予对应业务人设(比如HR专家、技术顾问)。这里提醒大家:自定义模板必须包含{query}和{question_answer_context}两个占位符——{query}是用户原始问题,{question_answer_context}是向量库检索到的私有资料,缺一不可!
// 自定义Prompt模板,适配HR问答场景
String customPrompt = """
你现在是公司资深的HR专家,专注解答员工各类规章制度相关问题。请严格基于以下【参考资料】的内容回答,不得捏造任何信息。
要求:
1. 语气专业、耐心,符合HR沟通规范;
2. 若参考资料中无相关信息,直接回复:“很抱歉,当前的规章制度中暂未找到说明。”
【参考资料】:
---------------------
{question_answer_context}
---------------------
【用户问题】:
---------------------
{query}
---------------------
""";
// 挂载拦截器时,传入自定义Prompt模板
QuestionAnswerAdvisor.builder(vectorStore)
.promptTemplate(
PromptTemplate.builder().template(customPrompt).build()
)
.build()修改后运行结果(更贴合HR专业口吻): 根据公司现行规定,工作日晚上超过22:00(含)下班的员工,可直接使用企业滴滴打车服务叫车回家。费用由公司企业账户统一代付,无需个人垫资和贴票报销。
小贴士:大家可以根据自己的业务场景(比如技术问答、客服咨询)修改Prompt模板,灵活适配需求~
高阶实战:RetrievalAugmentationAdvisor 定制企业级RAG引擎
如果大家开发的是复杂的企业级AI应用,QuestionAnswerAdvisor的灵活性就不够用了。比如:想在检索前优化用户提问、想改变文档拼接逻辑、想增加多轮检索策略……这时就需要用到RetrievalAugmentationAdvisor(检索增强顾问)。
它的核心优势的是:将RAG全流程拆解为模块化组件,我们可以像搭乐高一样,随意替换、组合流水线上的任意组件,完全适配企业级复杂场景,这也是Spring AI架构设计的精妙之处!
第一步:引入依赖
<!-- 引入高级模块化RAG引擎,适配企业级定制需求 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>第二步:实战案例(企业级常用配置)
/**
* 账号:直奔標杆
* 说明:RetrievalAugmentationAdvisor实战,定制模块化RAG引擎
*/
@Test
void testRetrievalAugmentationAdvisor() {
// 1. 定义文档检索器,配置向量库、相似度阈值、召回数量
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.75)
.topK(3)
.build();
// 2. 核心组装:模块化配置RAG流水线
RetrievalAugmentationAdvisor ragAdvisor = RetrievalAugmentationAdvisor.builder()
// 优化1:查询润色(将用户模糊提问转化为更精准的检索语句)
.queryTransformers(RewriteQueryTransformer.builder().chatClientBuilder(chatClientBuilder).build())
// 优化2:查询扩展(将单个提问拆解为多个语义变体,提升检索覆盖率)
.queryExpander(MultiQueryExpander.builder().chatClientBuilder(chatClientBuilder).build())
// 关联检索器
.documentRetriever(retriever)
.build();
// 3. 发送请求,挂载定制化RAG引擎
ChatClient chatClient = chatClientBuilder.build();
String message = "公司打车怎么报销";
String content = chatClient.prompt()
.user(message)
.advisors(ragAdvisor) // 挂载企业级模块化RAG引擎
.call()
.content();
System.out.println(content);
}第三步:运行结果与核心优势
运行结果: 工作日晚上超过22:00(含)下班的员工可直接用企业滴滴打车回家,费用由公司企业账户代付,无需个人垫资和贴票。
核心优势:即使用户提问比较随意(比如“加班打车能报销不”),后台也会自动完成“提问润色→多维度扩展→并行检索→内容整合”一系列操作,确保最终答案精准、全面,完全适配企业级场景的复杂需求。
源码深挖:模块化RAG的八道核心流水线
很多小伙伴可能会好奇,RetrievalAugmentationAdvisor的底层是如何实现模块化闭环的?下面我们结合源码,一步步拆解这八道流水线(建议结合代码注释理解,新手也能看懂),一起吃透底层逻辑,避免只会用不会懂的尴尬~
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, @Nullable AdvisorChain advisorChain) {
Map<String, Object> context = new HashMap<>(chatClientRequest.context());
// 1、【接收问题】:封装用户原始提问、历史聊天记录,生成原始查询参数
Query originalQuery = Query.builder()
.text(chatClientRequest.prompt().getUserMessage().getText())
.history(chatClientRequest.prompt().getInstructions())
.context(context)
.build();
// 2、【润色问题(QueryTransformer)】:优化用户提问,解决提问模糊、格式不规范的问题,提升检索效率
Query transformedQuery = originalQuery;
for (var queryTransformer : this.queryTransformers) {
transformedQuery = queryTransformer.apply(transformedQuery);
}
// 3、【拆解/展开问题(QueryExpander)】:将单个提问拆解为多个语义变体,覆盖更多检索角度,避免遗漏相关文档
List<Query> expandedQueries = this.queryExpander != null ? this.queryExpander.expand(transformedQuery)
: List.of(transformedQuery);
// 4、【批量查询资料】:并行检索多个扩展后的提问,提升检索速度,获取更全面的文档
Map<Query, List<List<Document>>> documentsForQuery = expandedQueries.stream()
.map(query -> CompletableFuture.supplyAsync(() -> getDocumentsForQuery(query), this.taskExecutor))
.toList()
.stream()
.map(CompletableFuture::join)
.collect(Collectors.toMap(Map.Entry::getKey, entry -> List.of(entry.getValue())));
// 5、【整合资料】:合并多个检索结果,去重、排序,筛选出最相关的文档
List<Document> documents = this.documentJoiner.join(documentsForQuery);
// 6、【后置审核】:对筛选后的文档进行二次处理,删除冗余、不相关内容,压缩文档体积,减少噪声
for (var documentPostProcessor : this.documentPostProcessors) {
documents = documentPostProcessor.process(originalQuery, documents);
}
// 将最终文档存入上下文,供后续使用
context.put(DOCUMENT_CONTEXT, documents);
// 7、【合并内容】:将用户原始提问与筛选后的文档,组装成符合大模型要求的Prompt
Query augmentedQuery = this.queryAugmenter.augment(originalQuery, documents);
// 8、【最终查询】:将组装好的Prompt发送给大模型,生成最终答案
return chatClientRequest.mutate()
.prompt(chatClientRequest.prompt().augmentUserMessage(augmentedQuery.text()))
.context(context)
.build();
}小结:这八道流水线环环相扣,每一步都可以单独定制替换,这就是模块化RAG的核心价值——灵活、可扩展,既能满足基础需求,也能适配企业级复杂场景。
进阶技巧:私有知识 + 长期记忆,打造更智能的对话机器人
给大家分享一个实用技巧:Spring AI中的Advisor(顾问拦截器)支持无限叠加!结合我们第七课学的MessageChatMemoryAdvisor(实现AI对话记忆),就能打造一个“既能记住历史对话,又精通公司私有规章制度”的智能业务机器人,实战价值拉满~
下面是伪代码演示(可直接整合到实际项目中),大家可以参考实操:
// 伪代码演示:多重AOP增强,组合RAG与对话记忆
chatClient.prompt()
.user(message)
.advisors(
// 增强1:赋予AI长期记忆(记住历史对话,解决多轮上下文问答)
MessageChatMemoryAdvisor.builder(chatMemory).build(),
// 增强2:赋予AI私有知识(挂载模块化RAG引擎,检索私有知识库)
RetrievalAugmentationAdvisor.builder()
.documentRetriever(retriever)
.build()
)
.call()
.content();这里不得不夸一下Spring AI的架构设计——所有功能模块完全解耦,随插随用,无需修改核心代码,极大提升了开发效率,这也是我们Java开发者转型AI时,优先选择Spring AI的核心原因之一!
本节课总结(一起复盘,巩固知识点)
到本节课为止,我们已经彻底打通了RAG(检索增强生成)全链路,从文档抽取、切片、向量化入库,到今天的全链路闭环,每一步都是实战必备技能。我们一起复盘一下RAG全链路的核心要点(建议收藏):
-
E(抽取):用DocumentReader抽取PDF、Markdown等格式的私有文档;
-
T(转换):用自定义SemanticTokenTextSplitter对文档进行精准切片,避免语义被暴力切断;
-
L(加载):用Embedding技术将文本向量化,存入向量库,完成知识库搭建;
-
G(生成):用本节课学的RetrievalAugmentationAdvisor,一行代码组装模块化流水线,实现RAG全链路闭环!
恭喜大家!现在的你们,已经完全具备了独立开发一个私有知识库AI问答助手的核心技术能力,赶紧把今天的案例实操一遍,把知识转化为实战能力~ 坚持打卡,我们一起向AI工程师标杆迈进!
下节预告(精彩不容错过)
目前我们实现的AI,不管检索能力多强,本质上都只能被动“读取”知识,无法主动操作外部工具。比如用户说“帮我查一下今天杭州到北京的机票”“把这份周报发给老板并创建日历会议”,AI就无从下手——因为它没有“双手”去操作外部系统。
下一课(Java开发者AI转型第十六课!赋予AI真实的双手!一行代码打通Tool Calling自动闭环状态机),我们将打破这层物理枷锁,带大家吃透AI走向终极智能体(Agent)的灵魂技术——Tool Calling(工具调用),让AI能主动调用外部工具,完成各类实际任务!
精彩继续,咱们下节课不见不散~
往期回顾(循序渐进,拒绝跳跃)
-
Java开发者AI转型第十二课!吃透Embeddings向量化:让Java代码读懂文本语义
-
Java开发者AI转型第十三课!知识库终局方案:Spring AI Vector Store架构演进与ETL全链路入库实战
-
Java开发者AI转型第十四课!Spring AI向量数据库实操:检索召回与相似度检索实战详解
我是直奔標杆,专注Java开发者AI转型干货分享,每一节课都结合实战案例,让大家能快速上手、学以致用。如果大家在实操中遇到问题,欢迎在评论区留言交流,我们一起探讨、一起进步,共同向AI工程师标杆冲刺 💪

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)