基于MindSpore的ResNet50模型中药炮制饮片质量判断实战教程
前言
本文同步发布于MindSpore社区,欢迎加入MindSpore社区,一同探索更多可能!
欢迎大家来到这期的实操播客!今天我们将手把手带大家使用MindSpore框架和ResNet50模型,完成一个非常有意思且实用的AI任务——中药炮制饮片质量判断。
过去判断中药炮制得好不好,全靠老药工的经验,但这种经验面临失传的风险。今天,我们就用AI技术把这种宝贵的经验“智能化”!
下面,让我们开始实操!
第一步:打开实验平台
首先,我们需要登录实验平台,找到对应的实训项目。
点击“打开 Jupyter 在线编程”后,选择合适的运行环境。本案例推荐使用 Ascend-snt9b 环境,镜像选择包含 mindspore 的版本(如 python3.9-ms2.7.1-cann8.3.RC1)。
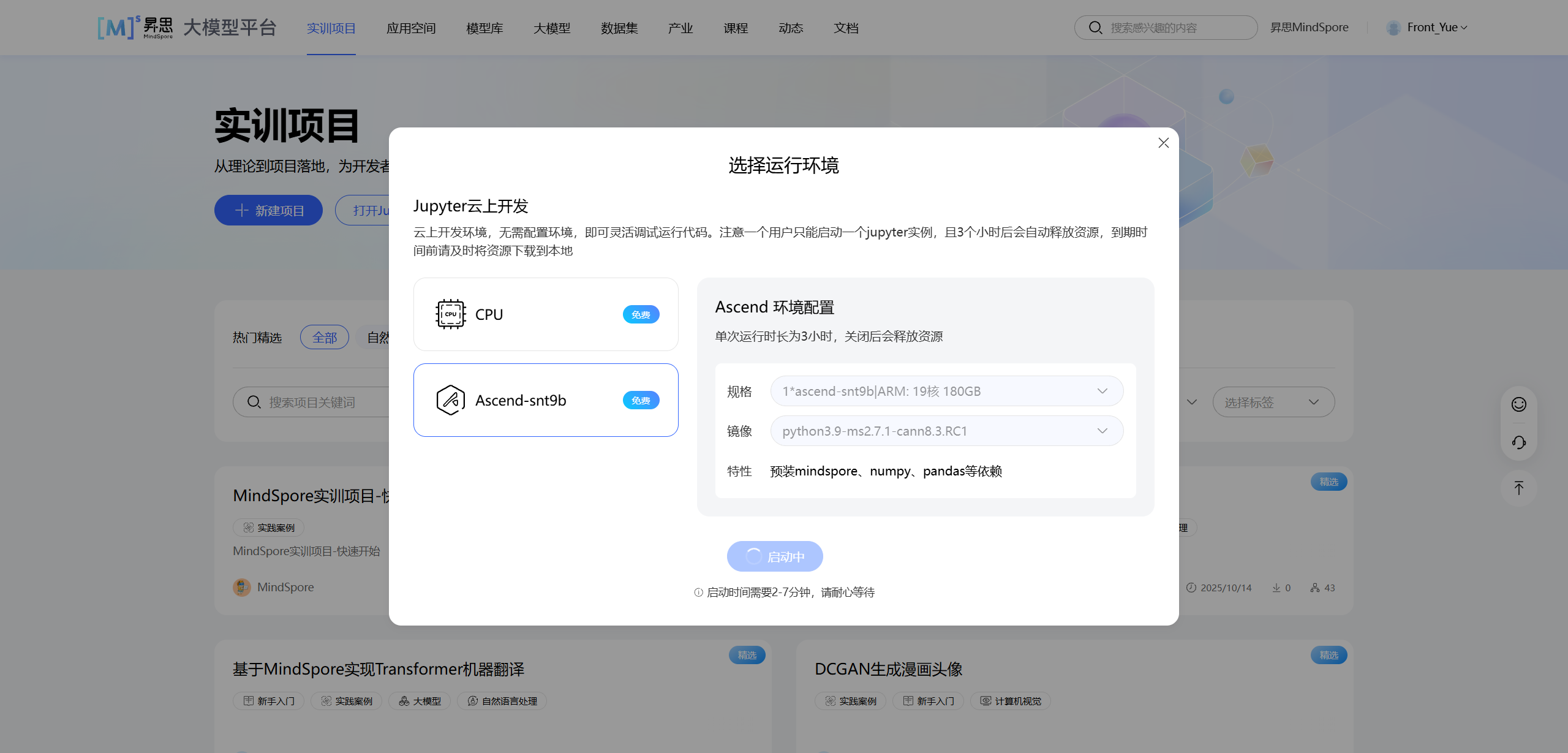
等待环境启动完成后,我们就可以开始编写/运行代码了。
第二步:环境准备
进入Jupyter Notebook后,我们需要确保环境中的MindSpore版本是正确的。本案例基于 Python 3.9 和 MindSpore 2.7.1。
你可以运行以下命令来检查版本,如果版本不符,可以取消注释直接安装。
# 检查mindspore版本是否为2.7.1
!pip show mindspore
# 若需安装对应版本,可运行以下命令:
# !pip uninstall mindspore -y
# %env MINDSPORE_VERSION=2.7.1
# !pip install mindspore==2.7.1 -i https://repo.mindspore.cn/pypi/simple --trusted-host repo.mindspore.cn --extra-index-url https://repo.huaweicloud.com/repository/pypi/simple

接着,我们导入后续需要用到的各种Python库和MindSpore模块:
import os
import random
import shutil
import numpy as np
import mindspore as ms
import matplotlib.pyplot as plt
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from PIL import Image
from download import download
from typing import Type, Union, List, Optional
from mindspore.common.initializer import Normal
from mindspore.dataset import ImageFolderDataset
from mindspore import (Tensor, nn, train, mint, context, load_checkpoint, load_param_into_net, ops,)
[这里插入:导入依赖库的代码执行截图]
第三步:数据加载与预处理
这次我们使用的是成都中医药大学提供的“中药炮制饮片”数据集,包含了蒲黄、山楂、王不留行3个品种,每个品种有4种状态(生品、不及、适中、太过)。
1. 下载数据
首先运行以下代码将数据集下载到本地环境:
# 数据集下载链接
url = "https://obs-xihe-beijing4.obs.cn-north-4.myhuaweicloud.com/jupyter/dataset/zhongyiyao/dataset.zip"
if not os.path.exists("dataset"):
download(url, "dataset", kind="zip")
2. 数据裁剪与划分
原始图片是4K高清大图,为了加快训练速度,代码中先将图片缩放到 1000x1000,并将数据集按照 8:1:1 的比例划分为训练集、验证集和测试集:
data_dir = "dataset1/zhongyiyao"
train_data, val_data, test_data = create_data_splits(data_dir)
3. 定义数据加载Pipeline
为了增加数据的多样性,我们使用MindSpore的数据变换(Transforms)接口,加入了随机裁剪、随机水平翻转、调整图像尺寸(Resize)、图像标准化等操作。
运行相关代码加载数据后,我们可以把处理好的图片打印出来看看:
data_iter = next(dataset_val.create_dict_iterator())
images = data_iter["image"].asnumpy()
labels = data_iter["label"].asnumpy()
# 绘制数据可视化图表...
第四步:模型构建
数据准备就绪,接下来我们要搭建ResNet50网络了。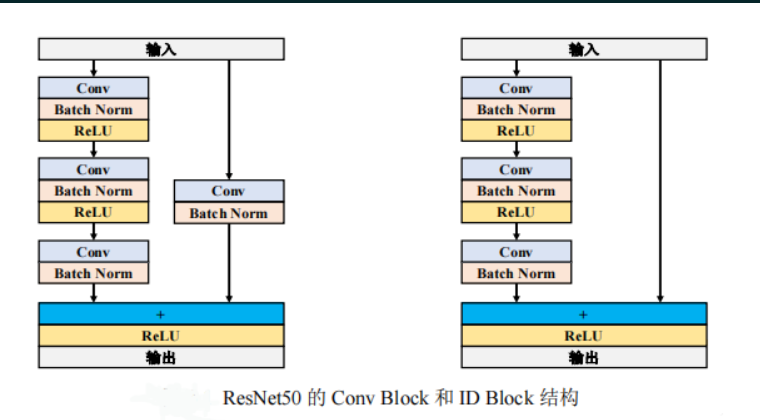
ResNet(残差网络)通过引入“残差结构”(Residual Block)有效解决了深层网络容易出现的退化问题。我们依次定义了 ResidualBlockBase、ResidualBlock(即Bottleneck结构),并构建出完整的 ResNet 分类网络。
为了加速训练并获得更好的效果,我们会加载一个官方提供的ResNet50预训练模型权重,并将其全连接层(fc)的输出修改为我们的类别数:12类。
network = resnet50(pretrained=True)
num_class = 12
in_channel = network.fc.in_features
fc = mint.nn.Linear(in_features=in_channel, out_features=num_class)
network.fc = fc
第五步:模型训练
最激动人心的训练环节到了!我们设置训练轮数(Epoch)为50次,使用 Momentum 优化器和 SoftmaxCrossEntropyWithLogits 损失函数。同时加入了早停机制(Early Stopping):如果连续5轮验证集准确率没有提升,就提前结束训练并保存最佳权重,防止过拟合。
# 开始训练
no_improvement_count = 0
acc_list = []
loss_list = []
stop_epoch = num_epochs
for t in range(num_epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(network, dataset_train, loss_fn, opt)
acc,loss = test_loop(network, dataset_val, loss_fn)
# ... 早停和保存最佳模型逻辑
训练结束后,我们可以调用定义好的画图函数 plot_training_process(acc_list, loss_list) ,把训练集上的Loss和验证集上的Accuracy变化过程画成曲线图:
第六步:模型推理
模型训练好了,效果到底怎么样?是骡子是马,拉出来溜溜。我们加载刚才保存的最佳模型参数,并在测试集上进行推理验证。
num_class = 12
model = resnet50(num_class)
best_ckpt_path = 'BestCheckpoint/resnet50-best.ckpt'
# 加载最佳模型参数
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(model, param_dict)
# 执行可视化预测
visualize_model(dataset_val, model)
看到图片上方标注的预测标签和真实标签,如果大部分颜色是蓝色,那就说明我们的AI“老药工”已经学有所成了!
今天的实操演示就到这里,大家快去自己的实验平台上动手试试吧!我们下期再见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)