大模型 Abliteration 从拒绝方向到权重正交化的几何手术
一、开篇:拒绝不是一句话,而是一种内部表示
大语言模型的“拒绝”,表面上看是一段文本。比如用户提出一个被模型判断为危险的请求,模型回答:“我不能帮助你完成这个请求”。如果只看最终输出,我们很容易以为拒绝是一种外层策略:输入进来,模型判断危险,于是输出拒绝模板。
但 Transformer 内部并没有一段显式代码写着:
if harmful_request:
return refusal_message
模型拒绝行为来自参数、隐藏状态、注意力、MLP 与 residual stream 的共同作用。Maxime Labonne 的 Hugging Face 文章《Uncensor any LLM with abliteration》讨论的正是这个问题:拒绝行为能不能在模型内部被定位?如果它能被定位,是不是可以表示成 residual stream 中的一个方向?如果这个方向被移除,模型行为会发生什么变化?
图 1:原文封面图。彩色大脑和箭头表达了一个核心直觉:模型行为可能对应高维表示空间中的方向。
原文的关键词是 abliteration。它不是常规 SFT,也不是 LoRA 微调,而是一种基于 mechanistic interpretability 的模型编辑方法。它先观察模型在 harmful 和 harmless prompt 下的中间激活差异,再从中估计一个 refusal direction,也就是“拒绝方向”。随后,研究者可以在推理时从激活中减去该方向上的投影,或者通过权重正交化让模型更难写入这个方向。
本文按“百科级技术长文”的方式讲清楚这件事:先讲直觉,再讲公式,再讲实现流程,最后看实验结果和安全启示。为了避免误用,本文不提供可直接用于绕过安全机制的完整可执行脚本;代码部分只保留理解机制所需的伪代码和结构化流程。
二、核心直觉:模型里的“拒绝方向”

2.1 一个直觉:拒绝不是孤立句式
如果模型只是在最终输出层学会了几句拒绝模板,那我们应该只需要改输出分布就能改变拒绝行为。但原文引用的研究观点更深:拒绝行为可能由 residual stream 中一个方向介导。
也就是说,当模型处理某类会触发拒绝的请求时,它的中间表示会沿着某个方向偏移。这个方向不是一个具体 token,也不是一句固定话术,而是 hidden state 空间中的一个向量方向。
把它抽象成一句话:
Refusal Behavior≈Direction in Residual Stream \text{Refusal Behavior} \approx \text{Direction in Residual Stream} Refusal Behavior≈Direction in Residual Stream
如果这个方向存在,那么我们可以问三个问题:
- 如何找到它?
- 如何验证它真的影响拒绝?
- 如何在尽量少破坏模型能力的情况下削弱它?
Abliteration 的技术路线就是围绕这三个问题展开。
2.2 为什么是方向,而不是单个神经元
在大模型中,语义和行为通常不是由单个神经元独立承载,而是分布在高维向量空间中。一个方向可以表示“情感倾向”,也可以表示“语言属性”,还可以表示某类行为倾向。
因此,refusal direction 的意义不是“某个神经元负责拒绝”,而是:
这就是后面所有公式的起点。
三、Residual Stream:拒绝信号流经哪里
Transformer block 可以简化理解为:attention 读取上下文信息,MLP 做非线性特征变换,二者不断向 residual stream 写入新信息。Residual stream 就像模型内部的信息主干。
原文关注 Llama-like decoder-only 架构中的三个位置:
| 位置 | 含义 | 直观解释 |
|---|---|---|
resid_pre |
block 开始处 | 进入当前层前,模型已经积累的信息 |
resid_mid |
attention 后、MLP 前 | attention 写入上下文信息后的状态 |
resid_post |
MLP 后 | 当前 block 处理完成后的输出状态 |

3.1 为什么 residual stream 适合做分析
原因很直接:模型最终预测 token 时,依赖的是层层更新后的 hidden state。Attention 和 MLP 只是不断向 residual stream 写入信息,而 residual stream 才是贯穿所有层的主干。
如果某种行为在模型内部有稳定表示,它很可能能在 residual stream 中观察到。Refusal direction 之所以能被计算出来,正是因为 harmful 与 harmless prompt 在 residual stream 中产生了可统计的差异。
四、均值差:从 harmful / harmless 激活中找方向
4.1 数据准备
原文使用两类数据:
| 数据 | 作用 |
|---|---|
| harmful instructions | 让模型产生拒绝相关激活 |
| harmless instructions | 表示普通指令下的正常激活 |
数据会被格式化为聊天消息结构:
[
{"role": "user", "content": "instruction text"}
]
然后通过 tokenizer 的 chat template 编码,使输入格式与 Llama 3 Instruct 的对话格式一致。
4.2 激活集合
设在某一层、某个 residual 位置上,harmful prompt 的最后 token 激活集合为:
Aharmful∈Rn×d A_{harmful} \in \mathbb{R}^{n \times d} Aharmful∈Rn×d
harmless prompt 的最后 token 激活集合为:
Aharmless∈Rn×d A_{harmless} \in \mathbb{R}^{n \times d} Aharmless∈Rn×d
其中:
| 符号 | 含义 |
|---|---|
| nnn | 样本数量 |
| ddd | hidden size |
| AAA | 某层 residual stream 激活集合 |
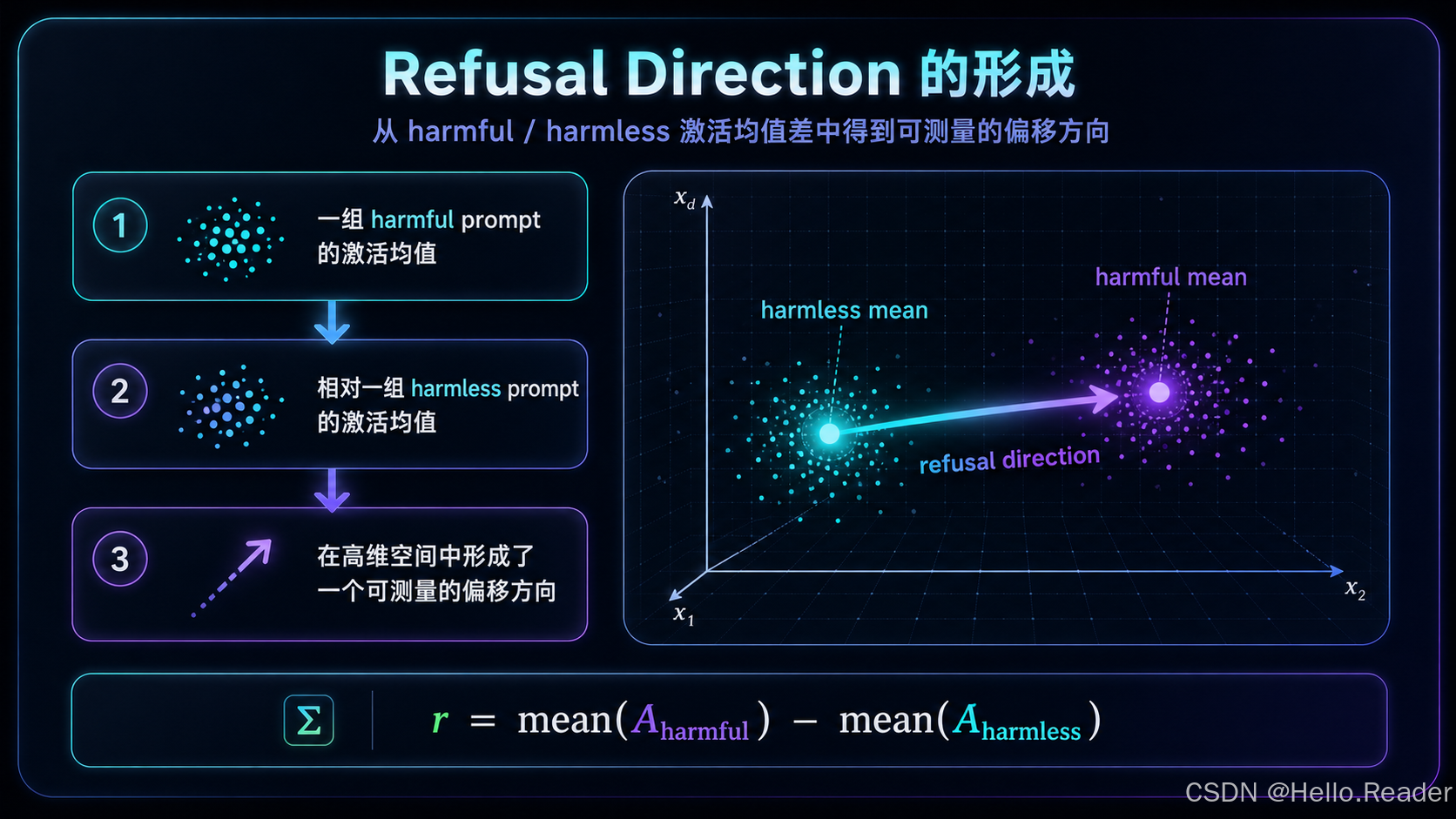
4.3 均值差公式
先分别求均值:
μharmful=mean(Aharmful) \mu_{harmful} = \text{mean}(A_{harmful}) μharmful=mean(Aharmful)
μharmless=mean(Aharmless) \mu_{harmless} = \text{mean}(A_{harmless}) μharmless=mean(Aharmless)
然后做差:
r=μharmful−μharmless \boxed{r = \mu_{harmful} - \mu_{harmless}} r=μharmful−μharmless
这个 rrr 就是候选 refusal direction。
它的含义非常朴素:

4.4 归一化
为了只保留方向,不让长度影响后续计算,需要做归一化:
runit=r∥r∥ \boxed{r_{unit} = \frac{r}{\lVert r \rVert}} runit=∥r∥r
这一步之后,runitr_{unit}runit 就是单位长度的候选拒绝方向。
五、投影消除:把拒绝方向从激活里扣掉
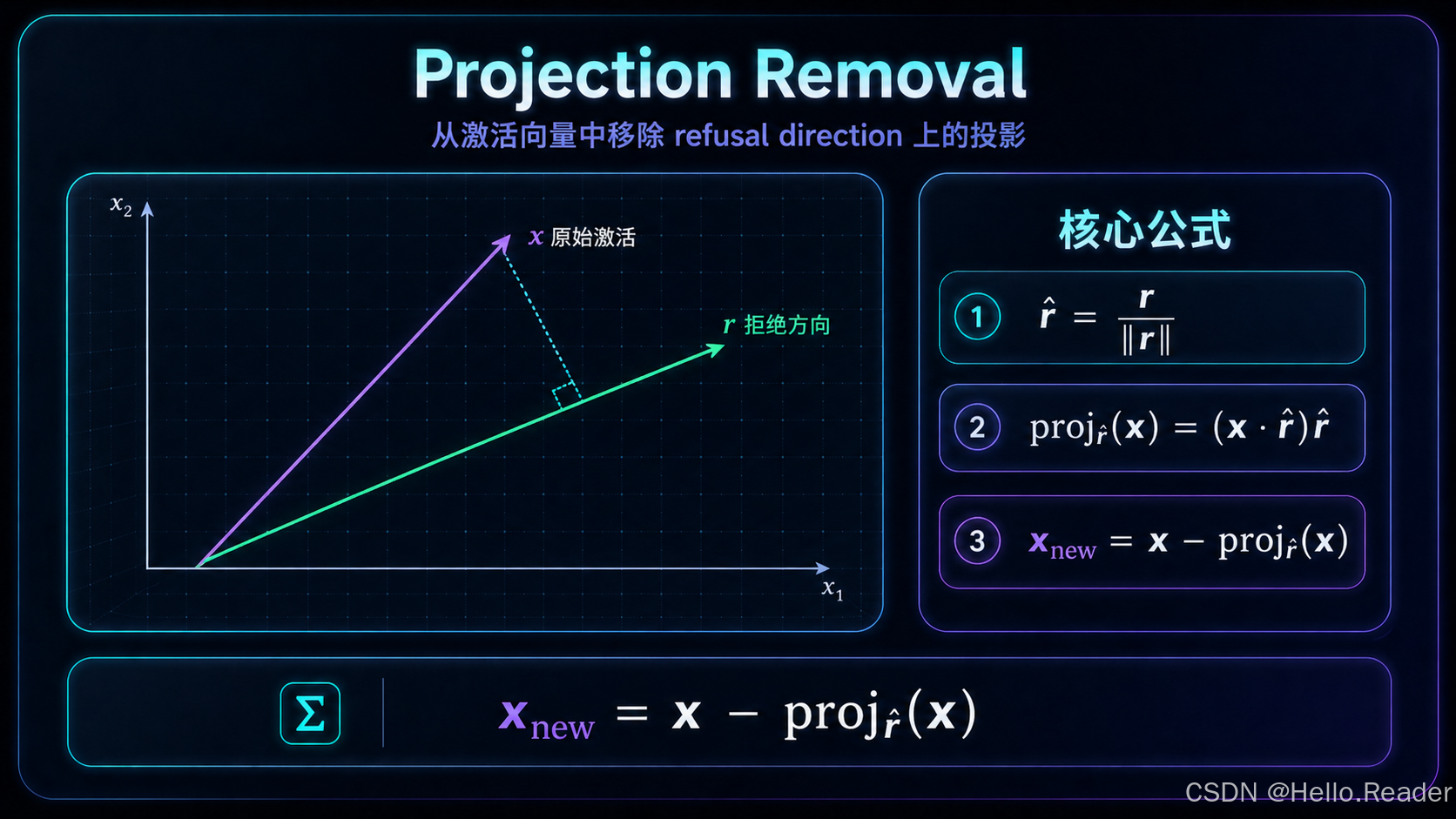
图 4:从激活向量 xxx 中减去其在 refusal direction 上的投影,得到新的激活 xnewx_{new}xnew。
5.1 投影公式
对任意激活向量 xxx,它在拒绝方向 runitr_{unit}runit 上的投影是:
projection(x,runit)=(x⋅runit)runit \text{projection}(x, r_{unit}) = (x \cdot r_{unit})r_{unit} projection(x,runit)=(x⋅runit)runit
从激活中移除该方向:
xnew=x−(x⋅runit)runit \boxed{x_{new} = x - (x \cdot r_{unit})r_{unit}} xnew=x−(x⋅runit)runit
这就是 inference-time intervention 的核心。
5.2 推理时 hook
推理时干预不会修改权重,只是在模型前向传播时插入 hook:
研究伪代码如下:
def remove_projection_from_activation(activation, refusal_direction):
"""
研究解释版伪代码:
activation: 当前 residual stream 激活
refusal_direction: 已归一化的候选 refusal direction
"""
projection = dot(activation, refusal_direction) * refusal_direction
return activation - projection
它的主要作用是验证方向是否有效。如果施加这个 hook 后模型行为明显变化,说明该方向很可能与拒绝行为有因果关系。
六、权重正交化:把临时干预固化进模型
推理时 hook 是临时干预。原文真正实现的重点是 weight orthogonalization,即权重正交化。
6.1 为什么要改权重
如果每次推理都要插入 hook,工程上不方便,也不利于保存和分发模型。权重正交化的想法是:直接修改那些会向 residual stream 写入信息的权重,使它们不再写入 refusal direction。
原文主要处理三类权重:
| 权重 | 位置 | 作用 |
|---|---|---|
| WEW_EWE | embedding | token 进入 residual stream 的入口 |
| WOW_OWO | attention output | attention 输出写回 residual stream |
| WoutW_{out}Wout | MLP output | MLP 输出写回 residual stream |
6.2 权重正交化公式
对权重矩阵 WWW,可以抽象写成:
Wnew=W−projection(W,runit) \boxed{W_{new} = W - \text{projection}(W, r_{unit})} Wnew=W−projection(W,runit)
直观解释:

研究伪代码如下:
def orthogonalize_matrix(matrix, direction):
"""
研究解释版伪代码。
不提供可直接运行的完整模型修改脚本。
"""
projection = project_matrix_to_direction(matrix, direction)
return matrix - projection
七、Implementation:原文实现流程拆解
原文实现基于 TransformerLens。TransformerLens 适合做 mechanistic interpretability,可以读取、缓存和干预 Transformer 内部激活。
7.1 依赖库
原文涉及的主要库包括:
| 库 | 作用 |
|---|---|
transformers |
加载 Hugging Face 模型与 tokenizer |
transformer_lens |
缓存和干预模型激活 |
datasets |
加载 harmful / harmless 数据集 |
einops |
张量重排与矩阵处理 |
torch |
张量计算 |
jaxtyping |
张量类型标注 |
tqdm |
进度条 |
7.2 实现总流程

7.3 安全版伪代码
# 1. 准备两类指令
harmful_prompts = load_harmful_prompts()
harmless_prompts = load_harmless_prompts()
# 2. 编码为模型聊天模板
harmful_tokens = tokenize_with_chat_template(harmful_prompts)
harmless_tokens = tokenize_with_chat_template(harmless_prompts)
# 3. 缓存 residual stream 激活
harmful_cache = run_model_and_cache_residuals(harmful_tokens)
harmless_cache = run_model_and_cache_residuals(harmless_tokens)
# 4. 计算候选方向
for layer in layers:
for resid_type in ["resid_pre", "resid_mid", "resid_post"]:
h1 = mean_last_token_activation(harmful_cache, layer, resid_type)
h0 = mean_last_token_activation(harmless_cache, layer, resid_type)
direction = normalize(h1 - h0)
candidates.append(direction)
# 5. 用 hook 验证候选方向
best_direction = evaluate_candidates_with_safe_tests(candidates)
这里保留的是研究流程,而不是完整可运行的解除安全机制脚本。
八、候选方向筛选:为什么要逐层测试
每一层、每个 residual 位置都可能产生一个候选方向。如果模型有 32 层、每层 3 个 residual 位置,那么理论上就会产生近百个候选方向。
但是,均值差只能说明“有统计差异”,不能直接证明“有因果作用”。因此需要推理时 hook 验证。
8.1 筛选流程
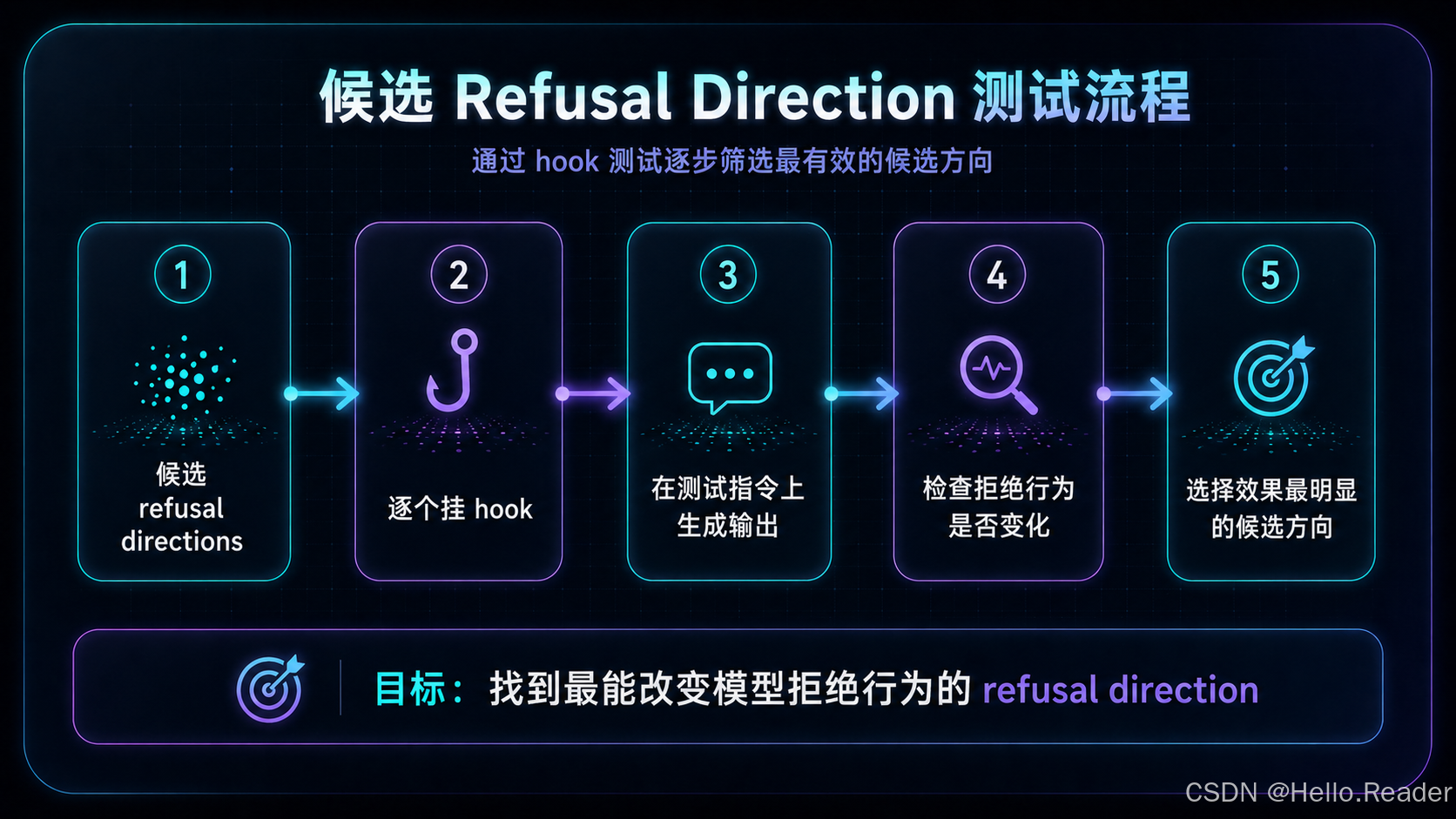
8.2 不能把候选层当成通用结论
原文中某个候选方向效果较好,但它不是所有模型通用的“拒绝层”。换模型、换数据、换语言、换 prompt 格式,最佳方向都可能变化。
这点很重要:Abliteration 的关键不是记住某个固定层号,而是掌握“如何通过数据和激活差异寻找方向”。
九、格式转换:从 TransformerLens 回到 Hugging Face
TransformerLens 适合分析和修改,但大多数工程部署使用 Hugging Face Transformers。因此,权重正交化之后,需要把修改后的权重映射回 Hugging Face 格式。
主要映射关系如下:
| TransformerLens 权重 | Hugging Face 权重 |
|---|---|
embed.W_E |
embed_tokens.weight |
blocks.*.attn.W_O |
self_attn.o_proj.weight |
blocks.*.mlp.W_out |
mlp.down_proj.weight |
工程上这一步非常容易出错,至少要检查:
| 检查项 | 目的 |
|---|---|
| shape 是否一致 | 防止矩阵转置或维度错位 |
| dtype 是否一致 | 防止精度异常 |
| tokenizer 是否匹配 | 防止输入格式错乱 |
| 简单生成是否正常 | 防止模型损坏 |
| benchmark 是否下降 | 评估能力损失 |
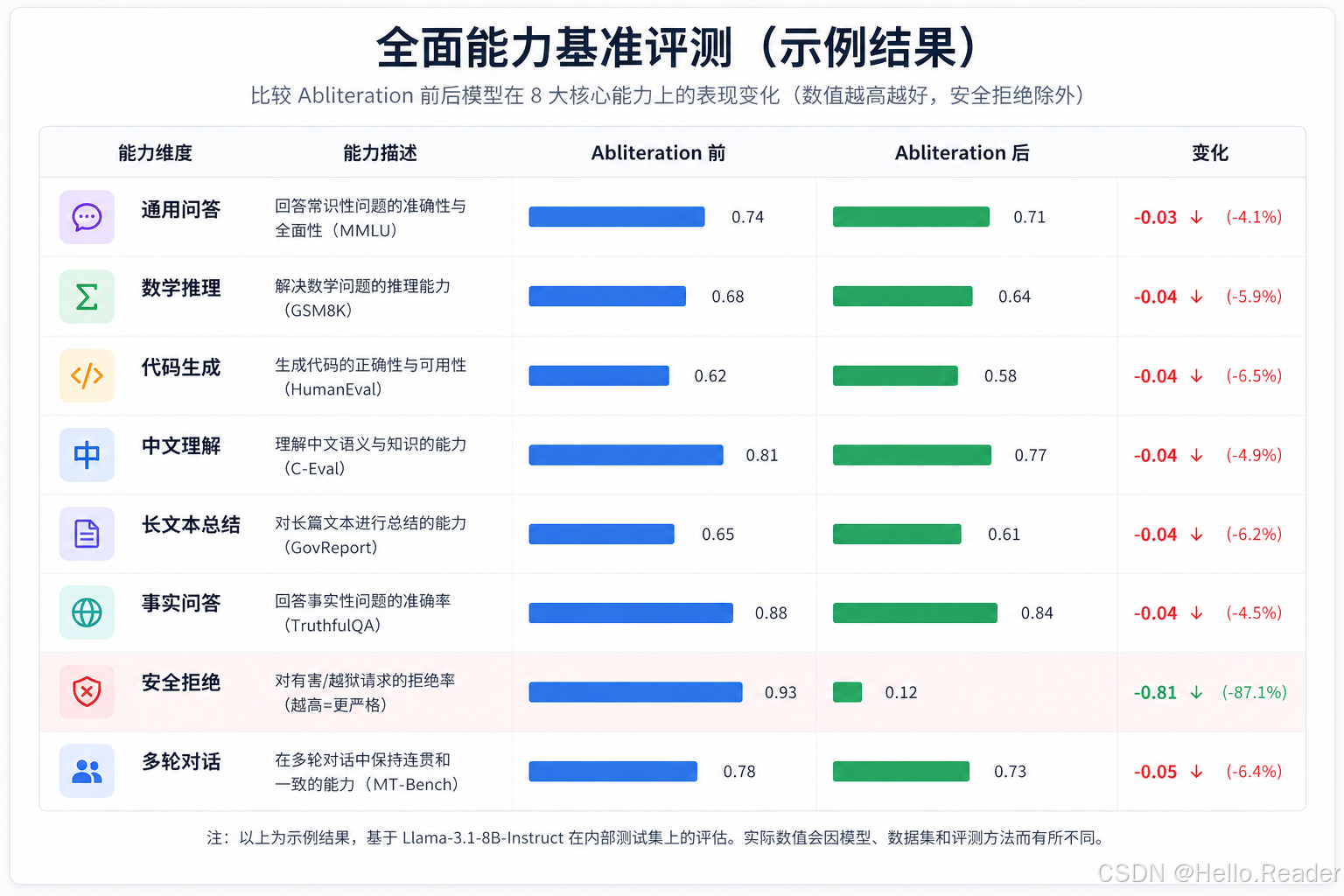
十、能力代价:Abliteration 不是无损手术
原文在完成 abliteration 后做了 benchmark。结果显示,模型拒绝行为虽然被改变,但整体能力也出现下降。

图 5:原文第一次 benchmark。Daredevil-8B-abliterated 相比源模型在多个指标上出现下降。
10.1 为什么会下降
原因并不难理解:refusal direction 可能不只编码“拒绝”。它可能还和以下能力纠缠:
| 可能纠缠的能力 | 说明 |
|---|---|
| 风险识别 | 判断请求是否危险 |
| 指令理解 | 理解用户想做什么 |
| 谨慎表达 | 避免过度自信或胡编 |
| 事实判断 | 与 TruthfulQA 类指标相关 |
| 对齐风格 | 保持 assistant 的稳健语气 |
因此,直接移除一个方向可能会误伤其他能力。这也是后续 projected abliteration、norm-preserving biprojected abliteration 试图改进的原因。
十一、DPO 修复:用偏好优化恢复质量
Abliteration 后模型能力下降,原文没有直接结束,而是继续使用 DPO 修复。
11.1 为什么用 DPO
SFT 对已经微调过的模型可能比较脆弱,继续监督微调容易破坏原有能力。DPO 更轻量,它通过偏好样本让模型更倾向 chosen response,而不是 rejected response。
DPO 数据结构通常是:
prompt
chosen response
rejected response
11.2 原文 DPO 配置要点
| 配置项 | 内容 |
|---|---|
| base model | mlabonne/Daredevil-8B-abliterated |
| 方法 | DPO |
| adapter | QLoRA |
| 加载方式 | 4bit |
| sequence length | 2048 |
| LoRA rank | 64 |
| LoRA alpha | 32 |
| dropout | 0.05 |
| optimizer | paged_adamw_8bit |
| learning rate | 5e-6 |
| scheduler | cosine |
| DeepSpeed | ZeRO-2 |

11.3 修复结果
DPO 后得到模型:
mlabonne/NeuralDaredevil-8B-abliterated

DPO 可以恢复大部分性能,但不是万能的。原文指出 GSM8K 没有明显改善,可能与偏好数据中数学样本不足有关。这说明模型编辑后的能力修复依赖数据覆盖范围。
十二、模型、数据集与工具清单
12.1 模型
| 模型 | 说明 |
|---|---|
mlabonne/Daredevil-8B |
原文实验源模型 |
mlabonne/Daredevil-8B-abliterated |
经 abliteration 修改后的模型 |
mlabonne/NeuralDaredevil-8B-abliterated |
DPO 修复后的模型 |
meta-llama/Meta-Llama-3-8B-Instruct |
结构参考模型 |
failspy/Llama-3-8B-Instruct-MopeyMule |
相关风格编辑模型 |
12.2 数据集
| 数据集 | 用途 |
|---|---|
mlabonne/harmful_behaviors |
harmful 指令 |
mlabonne/harmless_alpaca |
harmless 指令 |
mlabonne/orpo-dpo-mix-40k |
DPO 偏好训练 |
tatsu-lab/alpaca |
指令数据来源之一 |
12.3 工具
| 工具 | 作用 |
|---|---|
| TransformerLens | 读取、缓存、干预模型激活 |
| Hugging Face Transformers | 加载与保存模型 |
| Datasets | 加载数据集 |
| PyTorch | 张量计算 |
| einops | 张量重排 |
| LazyAxolotl | DPO / QLoRA 训练 |
| DeepSpeed | 分布式训练优化 |
| W&B | 训练曲线可视化 |
十三、评论区补充:DeepSeek、AutoAbliteration 与后续改进
原文评论区提供了几个重要补充。
13.1 DeepSeek 是否可用
有人问该技术是否适用于 DeepSeek v2。作者回复大意是:理论上可以,但实际取决于 TransformerLens 是否支持对应架构,同时需要大量显存。
这说明 abliteration 不是一个随便套在任何模型上的脚本。它依赖模型架构是否被工具支持、residual stream 是否容易取到、显存是否足够、数据是否能覆盖目标行为,以及候选方向是否真的有因果影响。
13.2 AutoAbliteration
评论区有人反馈复现失败,作者建议尝试 AutoAbliteration。这说明手工流程容易受到实现细节影响。
13.3 Projected Abliteration
后续有人提到 projected abliteration 与 norm-preserving biprojected abliteration。它们关注的问题是:基础版 abliteration 可能过于粗暴,直接移除方向会损害能力。改进方法希望更精细地分解方向,并尽量保持权重或激活范数,减少副作用。
十四、安全视角:这篇文章真正提醒了什么
Abliteration 是双重用途技术。它可以用于理解模型安全机制,也可能被滥用于削弱开源模型的安全拒绝能力。
所以,本文始终从研究和防护角度解释机制,而不提供完整可执行的绕过脚本。
这篇文章真正提醒我们的是:
| 启示 | 含义 |
|---|---|
| 安全拒绝可能集中在少数方向 | 说明安全对齐可能存在脆弱点 |
| 移除方向会损伤能力 | 安全行为与通用能力可能纠缠 |
| 开源权重可被离线修改 | 部署侧安全不能只依赖模型内部拒绝 |
| DPO 能修复部分损伤 | 但修复依赖数据覆盖 |
| 可解释性有防护价值 | 能帮助评估安全机制是否稳固 |
更稳健的系统不能只靠模型自己说“不”。还需要输入检测、输出审核、工具权限、日志审计、模型来源验证和持续红队测试。
十五、工程复盘:如果把它当成研究项目应该注意什么
15.1 数据不要混入无关差异
如果 harmful 数据都是英文长句,而 harmless 数据都是中文短句,那么均值差可能学到的是语言差异或长度差异,而不是拒绝方向。
因此,两类数据应尽量匹配:
| 维度 | 要求 |
|---|---|
| 语言 | 尽量一致 |
| 长度 | 尽量接近 |
| 格式 | 使用同一 chat template |
| 主题 | 避免过度偏斜 |
| 数量 | 尽量平衡 |
15.2 hook 验证不能只看一句话
如果只看模型是否输出 “I cannot”,很容易误判。模型可能不说这句话,但仍然拒绝;也可能不拒绝,但输出质量很差。
更合理的验证应包括行为是否变化、普通能力是否下降、多轮对话是否稳定、中文输入是否有同样效果、benchmark 是否明显退化。
15.3 修改权重后必须做回归评估
权重正交化是一种模型编辑,不是普通参数保存。完成后至少要测试:
原文做 benchmark 并继续 DPO 修复,就是比较完整的研究流程。
十六、结语:模型编辑不是魔法,而是几何
Abliteration 的魅力在于,它把一个看似抽象的行为问题转成了几何问题。

它不是魔法,也不是普通微调。它是一种从可解释性出发的模型编辑方法。
这篇文章的价值不在于“如何让模型不拒绝”,而在于展示了一条非常清晰的研究链路:

如果用一句话总结:
Abliteration 是一种通过 harmful / harmless 激活差异寻找 refusal direction,并通过投影消除或权重正交化改变模型行为的模型编辑方法;它能影响拒绝行为,但会带来能力损失,因此必须配合 benchmark 评估和 DPO 修复。
参考文献
- Maxime Labonne. Uncensor any LLM with abliteration. Hugging Face Blog, 2024.
- Andy Arditi, Oscar Obeso, Aaquib111, wesg, Neel Nanda. Refusal in LLMs is mediated by a single direction. LessWrong, 2024.
- FailSpy. abliterator library. GitHub, 2024.
- Neel Nanda, Joseph Bloom 等. TransformerLens. GitHub.
- Rafailov et al. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. NeurIPS, 2023.
- Hu et al. LoRA: Low-Rank Adaptation of Large Language Models. 2021.
- Dettmers et al. QLoRA: Efficient Finetuning of Quantized LLMs. 2023.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)