唯众人工智能视觉实训平台:从基础到实战,全链路视觉AI实训干货解析
在高校人工智能、电子信息这些专业的教学里,“理论和实践两张皮”绝对是个老大难问题——不少学生背熟了机器视觉、AI算法的基础概念,真要动手做个实际项目,就彻底懵了;老师们也头疼,找不到一套标准化、全链路的实训工具,没法系统锻炼学生的工程实操能力。而唯众这款人工智能视觉实训平台,刚好踩中了这个痛点,是专门给高校教学、实训和创新实践量身打造的软硬一体化系统。
1 人工智能视觉实训平台
1.1 产品简介
先简单说下这款平台的定位:面向高校教学、实训和创新实践的软硬一体化综合实训系统,核心就是围绕机器视觉、人工智能算法、嵌入式开发和运动控制这四个方向,把图像采集、视觉处理、目标检测、图像识别、双目视觉、三维重建,还有AI模型的训练与部署这些关键技术,都整合到一起,形成一套完整的视觉AI技术链路。

平台的载体是智能小车,搭配了多种视觉传感器和AI加速器,能实现从算法建模→训练优化→硬件部署→实车验证的全流程闭环,不管是基础实验,还是综合项目开发,不同层次的教学和科研需求都能满足。
很多刚入门的朋友都会问:“视觉AI项目从写代码到实车落地,到底要走哪些步骤?”其实这款平台的闭环逻辑,就是工业级视觉AI项目的缩影,结合它的硬件软件设计,我给大家拆解开讲,一看就懂:
-
算法建模层:主要在PC端用Python开发,借助OpenCV、PyTorch这些常用框架,完成图像预处理、模型搭建——比如目标检测用的YOLOv8,图像识别用的ResNet,核心就是把视觉任务转换成能训练的算法模型。平台自带预训练模型和数据集,不用我们从零开始,大大降低了建模门槛,当然也支持自定义开发模型,灵活度很高。
-
训练优化层:这一步就靠平台配套的AI加速器了,它内置NPU算力核心,算力至少4TOPS,还支持INT8/FP16混合精度推理。我们训练模型时,常会遇到“模型过拟合”“推理速度慢”这些问题,而这个加速器就能帮我们迭代优化,比如用迁移学习微调预训练模型,适配平台传感器采集的数据,原本普通PC要训练几小时的模型,用它几十分钟就能搞定,效率提升特别明显。
-
硬件部署层:PC端和嵌入式端能无缝衔接,我们把训练好的模型,导出成ONNX或者TensorRT格式(适配嵌入式Linux环境),烧录到AI加速器里,就能实现“模型轻量化部署”。这里有个关键技术——模型量化,把FP32模型量化成INT8,体积能缩小4倍,推理速度也能提升3-5倍,而且平台已经内置了量化工具,不用我们手动写代码,省了不少事。
-
实车验证层:智能小车作为运动载体,通过视觉传感器采集实时图像,AI加速器运行部署好的模型,输出目标坐标、距离这些推理结果,再通过运动控制单元驱动小车完成避障、跟踪这些动作,形成“数据采集→模型推理→动作执行”的闭环,这其实就是自动驾驶、智能机器人的核心工作逻辑,练熟了对后续就业也有帮助。
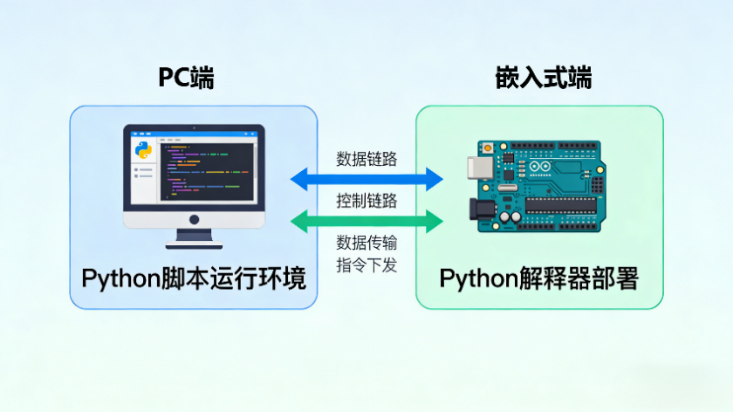
另外,平台采用的是PC端建模训练+实验平台执行的双端协同架构,核心开发语言是Python,这就意味着PC开发和嵌入式开发能无缝衔接,跨平台开发的门槛一下子就降下来了。硬件方面,集成了AI加速器、多种摄像头、多维度传感器和运动控制单元;软件方面,驱动、工程代码、实验数据集、教学文档一应俱全,既兼顾了高集成度和易用性,又足够开放——既能支撑标准化的课程实验,也能让学生自主做创新项目,真正把理论教学和工程实践衔接起来,是培养机器视觉和嵌入式AI工程实践能力的好工具。
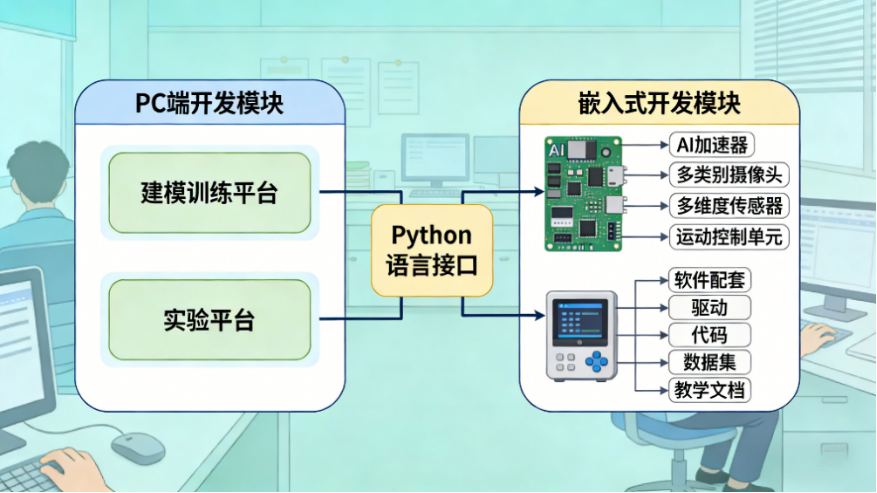
这里给大家说几个实操中会用到的技术细节:
1. 通信链路:PC端和嵌入式端是通过Type-C接口实现高速通信的,用的是TCP/IP协议传输模型文件和推理数据,通信延迟能控制在10ms以内,这样才能保证实车验证的实时性——要是延迟太高,小车动作就会滞后,实验很容易失败。
2. 开发环境统一:PC端推荐配置Python 3.8+OpenCV 4.5+PyTorch 1.12,嵌入式端搭载的是嵌入式Linux(Ubuntu 20.04 LTS),而且已经预装了numpy、matplotlib、torchvision这些Python依赖库,不用我们手动配置环境,开箱就能上手开发。
3. 跨端调试技巧:平台支持“远程调试”,PC端能实时查看嵌入式端的传感器数据、模型推理日志,不用拆硬件就能定位问题——比如摄像头采集异常、模型推理报错,直接在PC端就能排查,这种调试方式在工业开发中很常用,提前熟悉对培养工程调试思维特别有帮助。
1.2 产品特点
1.2.1 全栈AI技术融合,覆盖视觉核心应用场景
平台集成了人工智能的主流组件,把机器视觉、多传感器感知、电机控制这三大技术模块深度融合,像图像采集、视觉处理、目标检测、图像识别、双目测距、三维重建、模型训练与推理这些全链路功能,它都能支持,相当于一站式覆盖了视觉AI的核心应用场景,不用再额外搭配其他设备。
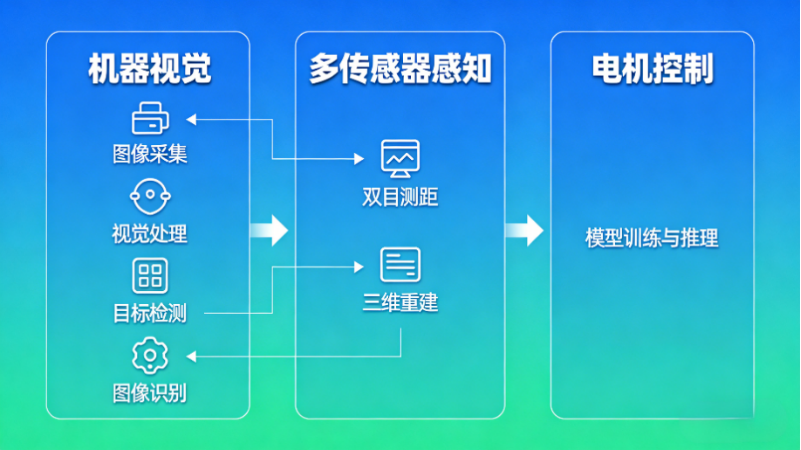
(1)图像采集与预处理(基础必备)
原理很简单:通过平台的单目高清摄像头(分辨率1920×1080,帧率30fps,支持自动对焦)采集图像,预处理主要是解决“图像噪声”“光照不均”这些问题,核心操作就是灰度化、高斯模糊、阈值分割,步骤不多,但都是基础中的基础。
import cv2
import numpy as np
# 1. 初始化摄像头(平台摄像头默认索引为0)
cap = cv2.VideoCapture(0)
# 设置摄像头分辨率
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)
while True:
# 2. 采集图像
ret, frame = cap.read()
if not ret:
break
# 3. 预处理:灰度化→高斯模糊→阈值分割
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 灰度化,降低计算量
blur = cv2.GaussianBlur(gray, (5,5), 0) # 高斯模糊,去除噪声
ret, thresh = cv2.threshold(blur, 127, 255, cv2.THRESH_BINARY) # 阈值分割,提取目标
# 4. 显示图像(平台支持实时显示)
cv2.imshow("Original Frame", frame)
cv2.imshow("Processed Frame", thresh)
# 退出按键(ESC键)
if cv2.waitKey(1) & 0xFF == 27:
break
# 释放资源
cap.release()
cv2.destroyAllWindows()(2)双目测距(核心进阶功能)
这个功能是平台的重点实训内容,也是自动驾驶、机器人避障的核心技术之一。原理是这样的:平台的双目摄像头(基线距离12cm,焦距f=5mm)通过左右两个镜头,采集同一物体的两张图像,先计算像素视差(Disparity),再用三角测量原理(公式是Z = (f×B)/d,其中Z是距离,f是焦距,B是基线距离,d是视差),就能算出物体的实际距离。
平台配套了2块标定棋盘(规格12×9,方格大小20mm),用来给双目摄像头做内外参标定。内参(焦距、主点坐标)是用来矫正镜头畸变的,外参(旋转矩阵、平移向量)是用来计算左右镜头相对位置的,标定之后,测距精度能达到±1cm的误差范围,不管是教学还是轻量级科研,都完全够用。
(3)三维重建(高阶拓展功能)
原理是基于运动恢复结构(SfM,Structure from Motion)技术,通过单目或双目摄像头采集多帧图像,用ORB算法提取特征点(兼顾速度和精度),匹配特征点并计算相机位姿,再通过三角测量生成稀疏点云,最后完成稠密重建和表面网格化,就能从2D图像还原出3D模型。而且平台支持把重建结果导出为PLY格式,后续做模型分析和优化也很方便。
三维重建的核心难点,就是“特征点匹配精度”和“重投影误差优化”,很多新手卡就卡在这。好在平台内置了光束法平差(BA)算法,能自动优化相机位姿和3D点坐标,把重投影误差控制在1像素以内,大大降低了高阶实训的难度。
1.2.2 软硬一体高集成度,支持AI应用快速创新
这款平台采用的是“硬件模组+软件系统”的一体化设计,把AI加速器、智能小车、多种视觉传感器和通用外设都集成到一起,开箱就能用,不用我们自己组装、调试,省了很多麻烦。而且它配套了完善的底层驱动和上层应用框架,不管是搭建人工智能应用,还是验证、迭代想法,都能快速完成,创新效率提升特别明显。
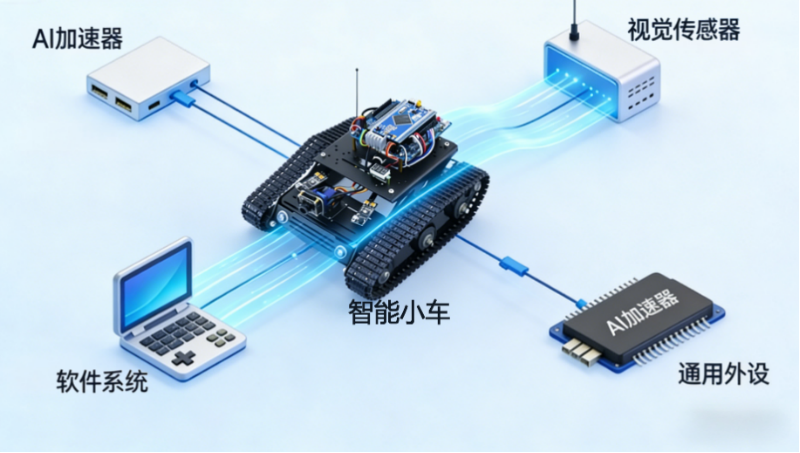
1. 硬件模组选型逻辑:
-
AI加速器:选的是低功耗、高算力的嵌入式NPU,支持TensorFlow Lite、PyTorch Mobile这些轻量化框架,算力≥4TOPS,功耗却≤5W,刚好适配小车的12V电源供电,不会因为功耗太高导致续航不足——实测下来,一次实训能撑4-6小时,完全够用。
-
视觉传感器:搭配了多种摄像头,覆盖不同的实训场景,特别实用:单目高清摄像头用来做基础图像操作、目标识别;双目摄像头用来做测距、三维重建;红外夜视摄像头(支持夜间成像,帧率25fps),弱光环境下的目标检测实训也能搞定;深度摄像头(采用TOF技术,测距范围0.3-5m),用来做高精度深度感知实训。
-
运动控制单元:用的是直流减速电机,转速可调,扭矩≥1.5N·m,还搭配了PID调速算法,小车匀速行驶、转向、避障这些动作都能实现。而且PID参数能通过PC端实时调节,学生能直观理解“控制算法和硬件执行”的联动关系。
2. 软件框架分层(工业级架构,方便教学和开发):
-
底层驱动层:把所有硬件的驱动程序(摄像头、AI加速器、电机等)都封装好了,提供统一的API接口,学生不用关注底层硬件的细节,只要调用API就能控制硬件,嵌入式开发的门槛一下子就降下来了。
-
中间核心层:包含视觉处理模块、AI推理模块、运动控制模块,模块之间用消息队列(MQTT协议)通信,支持独立调试、替换——比如想把目标检测模块换成图像分割模块,直接替换就行,不用改动整个项目代码,特别灵活,能快速实现不同的实训项目。
-
上层应用层:有PC端的可视化界面(基于PyQt5开发),模型训练、数据采集、实时监控、参数调节这些功能都有,而且支持自定义界面开发,能培养学生的应用开发能力。
1.2.3 传感器丰富,拓展性强,开放兼容
平台的传感器配置真的很全面,不仅有红外夜视、单目高清、双目、深度这些不同类型的摄像头,还搭配了温湿度、超声波等通用传感器,硬件拓展性特别强。而且平台性能够劲,接口也都是开放的,绝大多数视觉类实验和综合教学应用需求,都能满足。
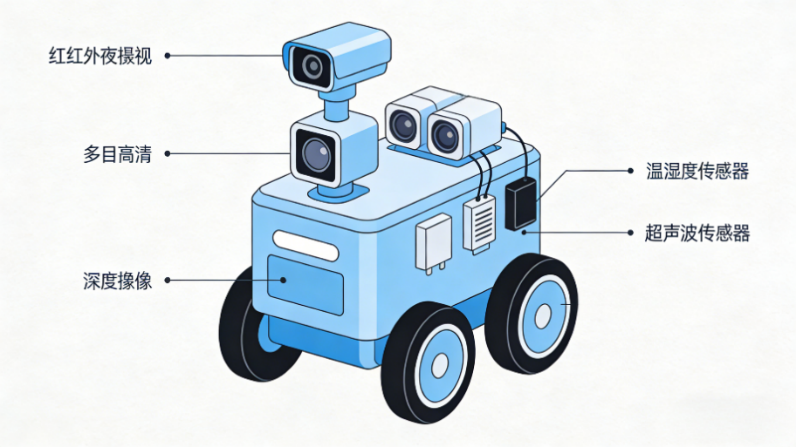
-
内置传感器接口详情:
-
摄像头接口:用的是MIPI CSI接口,传输速率≥1Gbps,还支持热插拔,要是觉得自带的摄像头不够用,还能换成4K摄像头,灵活性拉满;
-
超声波模块:用的是GPIO接口,数据格式是数字信号,测量范围2-400cm,直接就能用来做小车避障实验,平台配套的代码能直接调用,不用自己写;
-
温湿度模块:用的是I2C接口,输出数据是ASCII码,能结合视觉数据做“环境感知+视觉识别”的综合项目——比如温湿度异常时,让摄像头自动捕捉异常区域,这样的项目既简单又有创新性。
-
-
外接拓展实操:
-
拓展第三方传感器(比如GPS模块、IMU惯性测量单元):通过平台内置的USB扩展器,连接USB转TTL模块,就能采集传感器数据了,而且平台支持自定义数据解析函数,不管是什么传感器的数据格式,都能适配;
-
拓展执行器(比如机械臂、LED灯带):通过GPIO接口连接,利用平台的运动控制模块,写一段控制代码,就能实现“视觉识别→动作执行”的联动——比如识别到目标后,让机械臂抓取目标,这样的综合项目,用来做课程设计或者竞赛都很合适。
-
3. 兼容性说明:平台支持Windows 10/11、Ubuntu 20.04/22.04这些常用操作系统,和OpenCV、PyTorch、TensorFlow等主流视觉AI框架也都兼容。而且支持Python/C++双语言开发,零基础的同学可以从Python入手,有基础的同学可以学C++嵌入式开发,适配不同的编程基础,特别人性化。
1.2.4 跨端开发无缝衔接,技术栈统一
这款平台最省心的一点,就是用Python作为核心开发语言,把PC端和嵌入式端的数据、控制链路都打通了,开发环境统一,学习成本很低,不管是零基础入门,还是做高阶项目开发,都能适配,不用来回切换开发语言和环境,省了很多麻烦。
(1)常见坑点及解决方案
-
坑点1:PC端训练好的模型,部署到嵌入式端后,推理速度特别慢——解决方案很简单:用平台内置的模型量化工具,把FP32模型量化成INT8,再裁剪一下模型的冗余层(比如把ResNet50裁剪成ResNet18),适配嵌入式端的算力,速度立马就上来了;
-
坑点2:PC端和嵌入式端通信失败——遇到这种情况,先检查Type-C线缆有没有插紧,再确认PC端和嵌入式端在同一个局域网,关掉PC端的防火墙,重新启动平台的通信服务,基本就能解决;
-
坑点3:摄像头采集的图像模糊——这大概率是镜头畸变或者焦距没调好,用平台配套的标定棋盘,重新标定摄像头内参,矫正镜头畸变,再手动调整一下摄像头焦距,避开光照直射镜头,图像就清晰了。
(2)跨端开发实操案例(目标检测模型部署)
给大家举一个最常用的实操案例——目标检测模型部署,步骤很简单,跟着做就能成功:
步骤1:在PC端训练YOLOv8目标检测模型,数据集直接用平台配套的“交通标志检测数据集”,里面有10000+张标注图片,涵盖20种交通标志,不用自己标注,省了很多时间;
步骤2:用平台内置的模型导出工具,把训练好的模型导出为ONNX格式(适配嵌入式端推理),导出代码很简单,如下:
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO("best.pt") # 平台训练好的模型文件
# 导出为ONNX格式,指定输入尺寸(适配平台摄像头分辨率)
model.export(format="onnx", imgsz=(1920, 1080))步骤3:通过PC端的可视化界面,把ONNX模型烧录到嵌入式端的AI加速器里,配置一下推理参数(置信度阈值0.5,IOU阈值0.3),参数不用改太多,默认值也能用;
步骤4:启动智能小车,摄像头会采集实时图像,AI加速器运行模型,推理结果(交通标志类别、坐标)会通过通信链路传到PC端,同时驱动小车完成对应动作——比如识别到禁止通行标志,小车就会自动停止行驶,整个流程很顺畅。
1.2.5 实训体系完善,配套资源齐全
这款平台的实训体系做得很完善,支持25个标准化视觉实训案例,每个项目都配套了完整的实验手册、可直接运行的代码、实测数据集。而且实验手册做得很详细,从问题提出、方案设计、环境配置、资源清单,到实验步骤、代码实现、实验结论,一步步写得明明白白,形成了一套规范化、可落地的实训体系,不管是老师教学,还是学生自学,都很方便。
很多同学关心,这25个实训案例到底涵盖了哪些内容?是不是贴合高校课程大纲?我们给大家分类拆解一下,每个类别选几个核心案例,补充一下技术重点,大家可以按需学习:
-
图像基本操作(3个案例):主要是图像读取与显示、图像裁剪与旋转、图像融合,核心技术点就是OpenCV基础API调用、像素操作、色彩空间转换(BGR→RGB、BGR→HSV),都是入门必学的基础;
-
图像检测(4个案例):包括边缘检测(Canny、Sobel算法)、角点检测(Harris、Shi-Tomasi算法)、轮廓检测、目标检测(YOLOv8),核心技术点是特征提取、阈值调节、模型推理优化,是视觉AI的核心内容;
-
图像变换(3个案例): affine变换、透视变换、图像缩放,核心技术点是变换矩阵计算、图像畸变矫正,刚好对应摄像头标定后的图像预处理环节,实用性很强;
-
图像修复(2个案例):噪声去除、图像补全,核心技术点是高斯滤波、中值滤波、基于深度学习的图像修复(如U-Net模型),适合做进阶练习;
-
图像识别(4个案例):数字识别、人脸识别、交通标志识别、物体分类,核心技术点是CNN模型搭建、迁移学习、数据集扩充(数据增强),是AI落地的常用场景;
-
图像跟踪(3个案例):均值漂移跟踪、KCF跟踪、YOLOv8跟踪,核心技术点是目标特征匹配、跟踪框更新、抗遮挡处理,在自动驾驶、监控领域很常用;
-
双目视觉(4个案例):双目标定、视差计算、双目测距、双目图像拼接,核心技术点是内外参标定、三角测量原理、视差图优化,是平台的重点实训内容;
-
三维图像(2个案例):点云生成、三维重建,核心技术点是SfM算法、光束法平差、表面网格化,属于高阶拓展内容,适合做创新项目。
1.3 产品组成
平台整体由硬件设备、软件系统、实训配套资源三大模块构成,具体明细如下,我给大家补充了一些技术参数,方便大家更全面地了解:
1.3.1 核心硬件设备
|
类别 |
具体设备 |
技术参数(补充干货) |
|
核心控制与 AI 单元 |
AI 加速器 1 个 |
算力≥4TOPS,支持INT8/FP16混合精度推理,内置TensorFlow Lite/PyTorch Mobile框架,接口:MIPI CSI、GPIO、I2C |
|
运动载体 |
智能小车 1 辆、12V 电源 1 个、电池充电器 1 个 |
小车尺寸:20cm×15cm×10cm,直流减速电机,转速0-30cm/s可调,电源容量5000mAh,续航4-6小时 |
|
视觉采集设备 |
红外夜视摄像头 1 个、单目高清摄像头 1 个、双目摄像头 1 个、深度摄像头 1 个 |
单目:1920×1080分辨率,30fps;双目:基线12cm,焦距5mm;红外:夜视距离0.5-5m,25fps;深度:TOF技术,0.3-5m测距范围 |
|
通用传感器 |
超声波模块 1 个、温湿度模块 1 个 |
超声波:2-400cm测量范围,GPIO接口;温湿度:测量范围0-50℃、20%-90%RH,I2C接口,精度±0.5℃、±5%RH |
|
交互与指示设备 |
LED 发光模块 1 个、遥控器 1 块、无线键鼠套装 1 个 |
LED:红色/绿色可切换,GPIO接口;遥控器:无线距离10m,支持小车手动控制 |
|
标定与辅助工具 |
标定棋盘 2 块、安装工具 3 把 |
标定棋盘:12×9规格,方格大小20mm,用于摄像头内外参标定;安装工具:螺丝刀、剥线钳、镊子,适配硬件安装 |
|
线缆与转接配件 |
Type-C 线 1 根、USB 线 1 根、USB 转 TTL 下载器 1 个、USB 扩展器 1 个 |
Type-C:高速传输,支持数据+供电;USB转TTL:用于嵌入式端调试,波特率115200;USB扩展器:4口,支持外接第三方设备 |
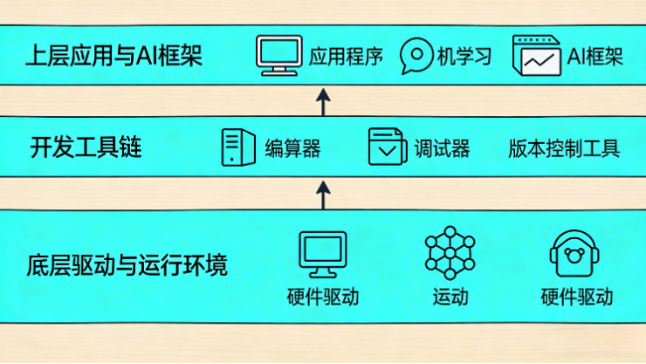
1.3.2 软件系统
(1)底层驱动与运行环境:全硬件设备的驱动程序、嵌入式端运行框架、硬件通信协议栈都包含在内,还兼容嵌入式Linux等平台,不用额外安装驱动,很省心;
底层驱动采用的是模块化设计,每个硬件都对应独立的驱动程序,支持热插拔,不用担心驱动冲突。核心驱动有三个:摄像头驱动(基于V4L2框架,支持图像采集、参数调节)、AI加速器驱动(支持模型加载、推理调度)、电机驱动(支持PID调速、方向控制)。而且驱动源码是开放的,学生可以查看、修改源码,真正理解底层驱动的原理,而不是只停留在调用API的层面。
(2)上层应用与 AI 框架:包含PC端视觉建模与训练工具、嵌入式端推理部署程序、数据可视化工具、云台/小车控制程序,覆盖了从建模到部署的全流程;
-
PC端视觉建模工具:集成了OpenCV、PyTorch、TensorFlow这些常用框架,支持图像标注、模型训练、参数调优,还内置了TensorBoard模型可视化工具,训练过程中的损失、准确率,实时就能看到,方便我们调整参数;
-
嵌入式端推理部署程序:支持ONNX、TensorRT、TensorFlow Lite等多种模型格式,内置推理优化引擎,能自动适配AI加速器的算力,不用我们手动优化,推理速度就能拉满;
-
数据可视化工具:能实时显示传感器数据、模型推理结果、小车运动状态,还能导出CSV格式的数据报表,不管是实验分析,还是写实验报告,都能直接用。
(3)开发工具链:包含Python环境配置包、视觉/AI依赖库、工程编译模板、多版本AI推理框架部署脚本,还有烧录与调试工具,一站式配齐,不用自己到处找资源。
这里给大家说几个实操中的小技巧,帮大家快速上手开发工具链:
1. Python环境配置:平台配套了.sh格式的环境配置包,一键就能安装Python 3.8+所有依赖库(opencv-contrib-python、numpy、torch、ultralytics等),不用手动安装,也不用担心版本冲突,新手也能轻松搞定;
2. 工程编译模板:提供了C++/Python双语言的工程模板,里面包含了硬件调用、模型加载、数据传输等基础代码,学生可以基于模板快速开发自己的项目,不用从零开始写代码,节省大量时间;
3. 调试工具:支持GDB远程调试(嵌入式端)、串口调试(波特率115200),能实时查看程序运行日志,快速定位代码错误。同时还支持摄像头调试、传感器调试,硬件出问题了,不用拆设备就能排查,特别方便。
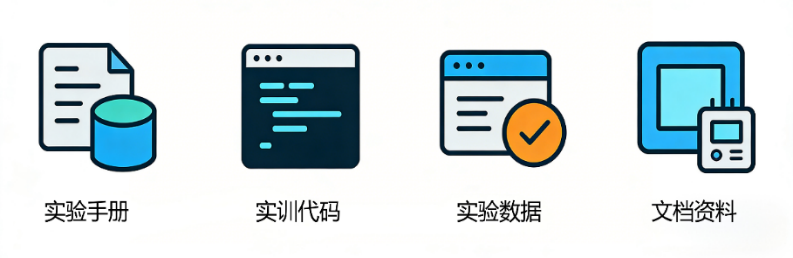
1.3.3 实训配套资源
(1)实验手册:25个实验项目的标准化手册,问题、方案、环境、资源、步骤、代码、结论,每一步都写得很详细,跟着手册做,就能顺利完成实验;
(2)实训代码:所有项目的可运行源码都有,支持直接编译、烧录与部署,不用自己写代码,也能修改源码,适合不同基础的学生;
实训代码采用的是模块化结构,分成了“硬件控制模块”“视觉处理模块”“AI推理模块”“运动控制模块”,每个模块都是独立封装的,修改其中一个模块,不会影响其他模块——比如想修改视觉处理模块的预处理算法,只要修改对应函数就行,不用改动整体代码,特别灵活。而且源码里有详细的注释,初学者也能轻松理解代码逻辑,比如这个图像预处理函数:
# 视觉处理模块:图像预处理函数
def image_preprocess(frame):
"""
功能:对采集到的图像进行预处理,用于后续模型推理
参数:frame - 原始图像(BGR格式)
返回:processed_frame - 预处理后的图像(灰度图)
"""
# 灰度化,降低计算量
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 高斯模糊,去除噪声(kernel_size=(5,5),sigma=0)
blur = cv2.GaussianBlur(gray, (5,5), 0)
# 阈值分割,提取目标(二值化)
ret, thresh = cv2.threshold(blur, 127, 255, cv2.THRESH_BINARY)
return thresh(3)实验数据:包含标注数据集、测试图片/视频、模型权重文件,不用自己找数据、训练模型,直接就能用;
数据集里的图像都标注好了,是XML格式的标注文件,适配YOLO、SSD等常用模型。而且平台内置了数据增强工具,能实现图像翻转、缩放、旋转、噪声添加等操作,用来扩充数据集,提升模型的泛化能力。模型权重文件包含两部分:预训练权重(比如YOLOv8预训练权重、ResNet预训练权重)和微调后的权重(适配平台的实训场景),学生可以直接使用权重文件进行推理,也能基于预训练权重进行微调,大大缩短训练周期。
(4)文档资料:产品手册、硬件连接图、软件部署指南、技术参数说明书都很齐全,不管是硬件安装,还是软件部署,遇到问题查文档就能解决。
1.4 功能应用
1.4.1 专业教学实训
这款平台适配的专业特别多,比如人工智能、电子信息、物联网工程、自动化、机器人工程等,不管是课程实验、综合实训,还是课程设计,都能满足。它覆盖了25个标准化视觉实验,分成图像基本操作、图像检测、图像变换、图像修复、图像识别、图像跟踪、双目视觉、三维图像八大类别,形成了一套完整的机器视觉教学体系,能帮助学生真正掌握视觉AI与嵌入式开发的核心技能,而不是只学一些理论知识。

1. 分层教学设计:针对不同基础的学生,设计三层教学方案,这样能兼顾所有人的学习进度——
-
基础层:重点讲OpenCV基础、Python编程、硬件认知,让学生完成图像基本操作、简单目标检测这些基础实验,先入门,建立信心;
-
进阶层:重点讲AI模型搭建、迁移学习、跨端开发,让学生完成双目测距、图像识别这些进阶实验,提升实操能力;
-
高阶层:重点讲创新项目开发、模型优化、技术落地,让学生完成三维重建、自动驾驶模拟这些综合项目,适配课程设计与毕业设计,为就业或深造做准备。
2. 课程衔接建议:可以和《机器视觉》《人工智能导论》《嵌入式开发》《Python编程》这些课程衔接起来,把实训平台作为课程实践载体,实现“理论授课+实操训练”的一体化教学,让学生学完理论就能动手实践,真正提升工程实践能力。
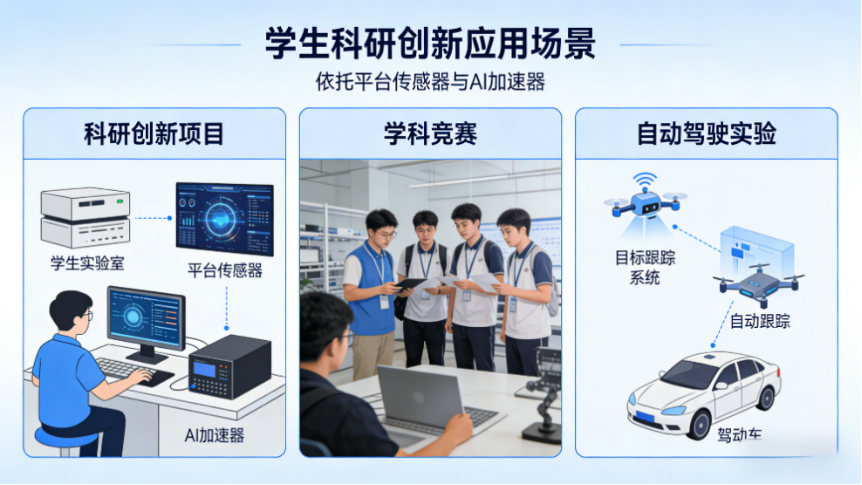
1.4.2 科研与创新项目
依托平台丰富的传感器和强算力AI加速器,学生可以开展科研创新项目,也能参加学科竞赛——比如全国大学生智能车竞赛、全国大学生物联网设计竞赛,都能用这款平台快速搭建参赛作品。而且它能拓展很多创新应用,比如目标跟踪、自动驾驶、人脸识别、手势控制、双目测距、三维重建等,还支持轻量化AI模型嵌入式部署,用来开展前沿技术研究,也完全没问题。
-
基于双目视觉的智能小车避障系统:
-
核心技术:双目标定、视差计算、距离判断、PID避障算法,都是平台实训中会学到的内容,上手难度低;
-
创新点:结合超声波传感器,实现“视觉+超声波”双重避障,提升避障精度,还能适配弱光、遮挡这些复杂场景,比单一避障方式更实用;
-
落地步骤:先完成双目测距实训,再添加超声波数据融合代码,优化避障算法,最后实车验证,一步步来,很容易成功。
-
-
基于YOLOv8的实时人脸识别与门禁控制:
-
核心技术:YOLOv8人脸检测、ArcFace人脸识别、嵌入式模型部署、GPIO接口控制,都是当下热门的AI技术;
-
创新点:把人脸识别模型轻量化部署到平台的AI加速器,推理速度能达到30fps以上,实现实时识别,再结合LED模块和继电器,就能实现门禁开关控制,实用性很强;
-
落地步骤:用平台配套的人脸数据集训练模型,量化模型后部署,再写一段识别与控制联动的代码,就能完成。
-
-
基于三维重建的物体建模系统:
-
核心技术:SfM算法、特征点匹配、光束法平差、点云处理,属于高阶技术,但平台已经做了优化,新手也能尝试;
-
创新点:结合深度摄像头,提升三维重建的精度,实现“单目+深度”混合重建,缩短重建时间,能用于文物建模、工业零件建模,应用价值很高;
-
落地步骤:用摄像头采集多帧物体图像,用平台的三维重建工具生成点云,优化点云精度,最后导出PLY格式的模型,就完成了。
-
-
基于视觉跟踪的智能小车跟随系统:
-
核心技术:YOLOv8跟踪算法、目标特征提取、运动控制联动,结合了视觉AI和运动控制,综合性很强;
-
创新点:能实现多目标跟踪,还能选择指定目标进行跟随,结合红外摄像头,夜间也能正常跟随,适用场景更广泛;
-
落地步骤:训练目标跟踪模型,部署到嵌入式端,写一段跟踪与小车控制联动的代码,再实车调试优化,就能实现跟随功能。
-
1.4.3 技术验证与原型开发
除了教学和科研,这款平台还能给科研团队、创客和企业提供快速验证平台——不管是图像检测、目标识别,还是双目视觉、三维重建,这些算法的落地效果,都能在平台上快速验证。而且它支持拓展智能监控、机器人视觉、工业检测、智能家居等应用型项目,能加速技术成果转化,实用性特别强。
1. 算法验证流程:平台有“快速验证模式”,不用完整开发项目,直接加载算法代码,调用传感器数据,就能实时查看算法的运行效果——比如想验证一个新的目标检测算法,只要把算法代码替换到平台的视觉处理模块,就能快速测试算法的精度和速度,省了很多时间;
2. 原型开发技巧:利用平台的模块化设计,快速组合硬件和软件模块,就能搭建项目原型——比如开发智能监控原型,把“单目摄像头+AI加速器+LED模块”组合起来,就能实现“目标检测→异常报警”的核心功能,再逐步优化细节,很快就能完成原型开发;
3. 工业级适配:平台的硬件接口、软件框架都兼容工业标准,把验证通过的算法和原型,快速迁移到工业设备中,比如把工业检测算法(如零件缺陷检测)部署到工业机器人,就能加速技术成果转化,节省企业的开发成本。
总结:从实训到实战,一款平台搞定视觉AI全链路
说实话,用过这么多实训平台,唯众这款人工智能视觉实训平台,真的让我眼前一亮。它的核心优势,就是“全链路、软硬一体、高开放”——不仅有完整的硬件设备和软件系统,还覆盖了从基础实验到科研创新的全场景需求,而且源码、接口、技术文档都开放,让学生、教师、科研人员都能真正“动手实操”,掌握视觉AI与嵌入式开发的核心技能。
对于高校教学来说,它解决了“理论与实践脱节”的痛点,提供了标准化的实训体系,老师教学更省心,学生学习更高效;对于学生来说,它提供了从零基础入门到高阶创新的完整路径,通过实操掌握工业级开发技能,不管是就业还是深造,都更有竞争力;对于科研与企业来说,它提供了快速验证平台,能加速算法落地与技术成果转化,性价比很高。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)