【StoryEcho】大模型API接入与LangGraph状态图集成
目录
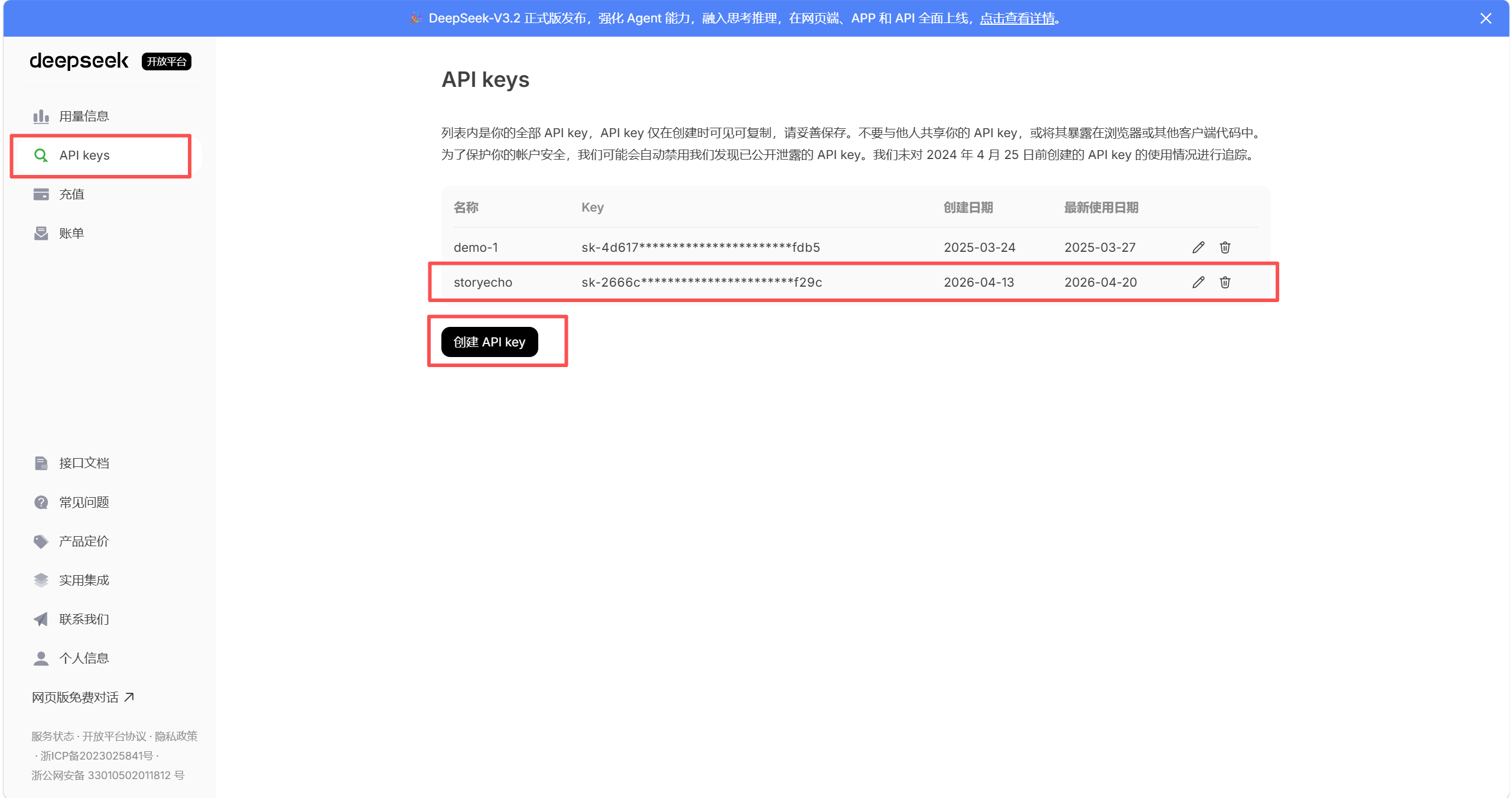
一、Deepseek API接入流程与配置
- 在DeepSeek官网(DeepSeek 开放平台)注册账号并申请API Key。进入控制台后,点击“创建API Key”,系统会生成一串以“sk-”开头的密钥,这个密钥需要妥善保存,因为后续页面不会再完整显示。
- story_engine.py 中新增的 LLMClient 类
# backend/story_engine.py import requests class LLMClient: def __init__(self, api_key: str = None, base_url: str = None, model: str = None): self.api_key = api_key or os.getenv("DEEPSEEK_API_KEY", "sk-")#填入自己的api key self.base_url = base_url or os.getenv("LLM_BASE_URL", "https://api.deepseek.com/v1") self.model = model or os.getenv("LLM_MODEL", "deepseek-chat") self.headers = {"Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json"} def generate(self, messages: List[Dict[str, str]], temperature: float = 0.8) -> str: url = f"{self.base_url}/chat/completions" payload = {"model": self.model, "messages": messages, "temperature": temperature, "max_tokens": 800} try: resp = requests.post(url, headers=self.headers, json=payload, timeout=30) resp.raise_for_status() return resp.json()["choices"][0]["message"]["content"] except Exception as e: print(f"LLM 调用失败: {e}") return "(大模型暂时无法响应,请稍后再试。)"这段代码定义了一个 LLMClient 类,用于与 DeepSeek 大模型 API 进行交互。类的 __init__ 方法接收可选的 API Key、服务地址和模型名称,如果没有传入则从环境变量读取,并提供了一个硬编码的默认 Key(仅作临时测试用)。它构造了请求头,包含认证信息。generate 方法是核心功能:接收一个消息列表(通常包含 system 和 user 角色)和 temperature 参数,向 DeepSeek 的 /chat/completions 端点发送 POST 请求,等待模型返回生成的文本。如果请求成功,从响应的 JSON 中提取出 choices[0].message.content 作为结果返回;如果发生任何异常(网络错误、超时、API 报错等),则捕获异常并打印错误信息,同时返回一个友好的降级提示字符串,保证程序不会因 API 调用失败而崩溃。
-
StoryEngine 类初始化时接收 llm_client 参数并存储
class StoryEngine: def __init__(self, llm_client: LLMClient = None): self.story_templates = self.load_story_templates() self.llm = llm_client or LLMClient() # 新增 self.memory = MemorySaver() self.graph = self.build_graph() - intent_parser 节点改为使用 LLM
def intent_parser(self, state: StoryState) -> StoryState: user_input = state["messages"][-1]["content"] system_prompt = """你是一个游戏意图识别器。用户输入一段自然语言,你需要判断用户的意图(intent)和目标(target)。 意图必须是以下之一:attack, talk, explore, use, move, check。 目标是从输入中提取的关键对象(如敌人名、物品名、方向等),如果没有明确目标则为空字符串。 输出格式:{"intent": "attack", "target": "哥布林"} 只输出 JSON,不要有其他内容。""" user_prompt = f"用户输入:{user_input}" try: resp = self.llm.generate([{"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt}], temperature=0.2) data = json.loads(resp.strip()) state["intent"] = data.get("intent", "explore") state["intent_target"] = data.get("target", "") except: # 降级为关键词匹配 state = self._fallback_intent_parser(state) return state这段代码的作用是将玩家输入的自然语言转换为结构化的游戏指令。首先从状态中提取用户最新的一条消息作为输入,然后构造一个系统提示词,要求大模型从“attack、talk、explore、use、move、check”六种意图中选择一种,并提取出目标对象(如敌人名、物品名),输出格式为严格的 JSON。接着调用 self.llm.generate 发送给大模型,temperature 设为 0.2 以保证输出的确定性。如果成功解析 JSON,就将意图和目标存入状态中;如果解析失败(例如大模型返回了非 JSON 内容或网络异常),则捕获异常并降级到关键词匹配的 _fallback_intent_parser 方法,确保游戏在任何情况下都能识别玩家意图。最后返回更新后的状态,供后续的逻辑裁判节点使用。
- narrative_director 节点改为使用 LLM 生成叙事(包含上下文、历史压缩、摘要更新)
def narrative_director(self, state: StoryState) -> StoryState: template = self.story_templates.get(state["story_id"], self.story_templates["fantasy_001"]) # 构建完整的历史对话(如果太长,使用摘要) full_history = state.get("messages", []) history_text = self._compress_history(full_history, state.get("summary", "")) # 构造系统提示词 system_prompt = f"""你是《{template['title']}》的叙事导演。 【世界观】{template['background']} 【当前场景】{state.get('current_description', template['scene_description'])} 【主线任务】{state['task_progress'].get('main', '')} 叙事要求: - 使用第二人称“你”,语言生动细腻。 - 包含“五要素”:心理活动、动作细节、环境变化、对话、状态提示。 - 严格基于以下给出的【行动结果】和【角色状态】来描写,不要自己编造数值变化。 - 保持奇幻或科幻风格一致。 - 回复长度150~300字。""" user_prompt = f"""【用户行动】{state['messages'][-1]['content']} 【意图】{state['intent']} → 目标:{state['intent_target']} 【行动结果】{state.get('action_result_desc', '')} (判定:{state['last_action_result']}) 【角色状态】 - 生命: {state['attributes'].get('hp', 100)}/{state['attributes'].get('mp', 100) if 'mp' in state['attributes'] else state['attributes'].get('energy', 100)} - 力量:{state['attributes'].get('strength',0)} 智力:{state['attributes'].get('intelligence',0)} 金币:{state['attributes'].get('money',0)} - 背包: {', '.join(state['inventory']) if state['inventory'] else '空'} - NPC好感: {state['relationships']} 【剧情回顾】 {history_text} 请续写一段剧情。""" llm_messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt} ] narrative = self.llm.generate(llm_messages, temperature=0.8) # 附加状态条(规则生成,非LLM) hp = state['attributes'].get('hp', 100) hp_emoji = "alive" if hp > 50 else "dead" status_bar = f"\n\n【状态】{hp_emoji}生命:{hp} | 力量:{state['attributes'].get('strength',0)} | 智力:{state['attributes'].get('intelligence',0)} | 金币:{state['attributes'].get('money',0)}" full_narrative = narrative + status_bar # 更新状态 state["messages"].append({"role": "assistant", "content": full_narrative, "timestamp": datetime.now().isoformat()}) state["current_description"] = full_narrative if "action_result_desc" in state: del state["action_result_desc"] # 定期更新摘要(每5轮) if state["turn_count"] % 5 == 0: state["summary"] = self._update_summary(state) return state这段代码用于生成沉浸式的剧情描述。它首先获取故事模板和当前状态,将历史对话压缩或摘要以避免超长。然后构造系统提示词(设定叙事风格、世界观、当前场景和任务)和用户提示词(包含玩家行动、意图、逻辑裁判的结果、角色属性和剧情回顾),一起发送给大模型生成 150~300 字的叙事文本。生成后,再附加一条由规则生成的状态条(生命值、力量、智力、金币)。最后将完整的回复存入消息历史,更新当前场景描述,并每隔 5 回合调用大模型生成一次剧情摘要,用于后续的上下文压缩。
- 新增辅助方法 _compress_history 和 _update_summary
def _compress_history(self, messages: List[Dict], existing_summary: str = "") -> str: full_text = "\n".join([f"{m['role']}: {m['content']}" for m in messages]) if len(full_text) < 4000: return full_text recent = messages[-10:] recent_text = "\n".join([f"{m['role']}: {m['content']}" for m in recent]) if existing_summary: return f"【历史摘要】{existing_summary}\n\n【最近剧情】{recent_text}" else: return recent_text def _update_summary(self, state: StoryState) -> str: history = "\n".join([f"{m['role']}: {m['content']}" for m in state["messages"]]) prompt = f"请用200字以内总结以下游戏剧情的关键发展、获得的重要物品、遇到的主要NPC和做出的重要选择:\n{history}" try: summary = self.llm.generate([{"role": "user", "content": prompt}], temperature=0.5) return summary except: return ""_compress_history 方法首先将所有消息拼接成完整文本,如果总长度小于 4000 字符就直接返回;否则只保留最近 10 条消息,并判断是否存在已有的摘要,若有则将摘要与最近剧情拼接返回,从而避免超出模型上下文窗口。_update_summary 方法在每 5 个回合被调用,它把全部对话历史发送给大模型,要求用 200 字以内总结关键剧情发展、获得的重要物品、遇到的主要 NPC 和重要选择,生成的摘要会存入状态供后续压缩使用。如果调用失败则返回空字符串,不影响游戏继续运行。
-
app.py 中初始化 LLM 客户端并传入故事引擎
# backend/app.py import os from story_engine import StoryEngine, LLMClient # 导入新增的 LLMClient # 硬编码 API Key(当前做法) DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY", "sk-") #填入自己的api key llm_client = LLMClient(api_key=DEEPSEEK_API_KEY) engine = StoryEngine(llm_client=llm_client)
二、改用 .env 文件管理 API Key 的做法
考虑到我们目前只是临时接入大模型 API 进行效果验证,尚未获得老师提供的正式密钥,而项目的最终架构是基于 LangGraph 的多智能体协同框架,不同节点(如意图解析、叙事导演、历史摘要等)可能会调用不同的大模型甚至不同厂商的服务。如果继续将 API Key 硬编码在代码中,不仅会导致密钥泄露风险,未来也难以灵活切换模型或管理多个密钥。因此,我们决定改用 .env 文件来集中管理所有环境变量(包括 API Key、服务地址、模型名称等),并通过 python-dotenv 加载。这种方式既符合开发规范,也为我们后续扩展多模型协同打下了基础。
-
在项目根目录创建 .env 文件(注意等号前后不要有空格)
DEEPSEEK_API_KEY=sk-xxx #填写自己的密钥 LLM_BASE_URL=https://api.deepseek.com/v1 LLM_MODEL=deepseek - 修改 app.py 和 story_engine.py 中的加载方式
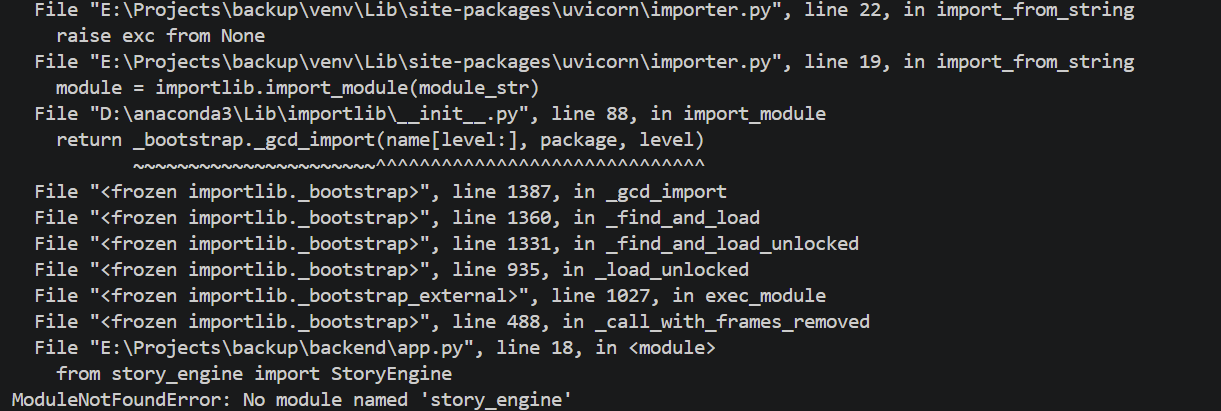
在 app.py 中添加:import os from dotenv import load_dotenv from .story_engine import StoryEngine load_dotenv() DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY") if not DEEPSEEK_API_KEY: raise ValueError("请在 .env 文件中设置 DEEPSEEK_API_KEY") def serialize_state(state: Dict) -> Dict: # 返回更多字段,包括 generation_source, generation_error, generation_model, generation_usage def to_legacy_ending_key(ending_key: str) -> str: # 映射结局类型注意其中的 story_engine 需要使用相对导入,若使用直接导入将出现以下错误:
在 story_engine.py 中添加:import os from dotenv import load_dotenv from typing import TypedDict, List, Dict, Any, Optional from langgraph.graph import StateGraph, END try: from langgraph.checkpoint.memory import MemorySaver except ImportError: from langgraph.checkpoint import MemorySaver import requests class LLMClient: def __init__(self, api_key: str = None, base_url: str = None, model: str = None): # 初始化LLM客户端 def generate_narrative(self, prompt: str, max_tokens: int = 500) -> Optional[str]: # 直接调用DeepSeek HTTP接口生成故事叙述 class StoryEngine: def intent_parser(self, state: Dict) -> Dict: # 将用户输入转换为结构化指令 def narrative_director(self, state: Dict) -> Dict: # 调用LLM生成沉浸式剧情描述需要注意的是,仅调用大模型没办法得到我们想要的回答,还需要将故事本身的背景和用户的交互传入,具体的修改代码如下:
prompt = f"""你是一个沉浸式角色扮演游戏的故事叙述者。请根据以下信息生成一段引人入胜的故事描述(2-3句话,不超过100个字):修改为:
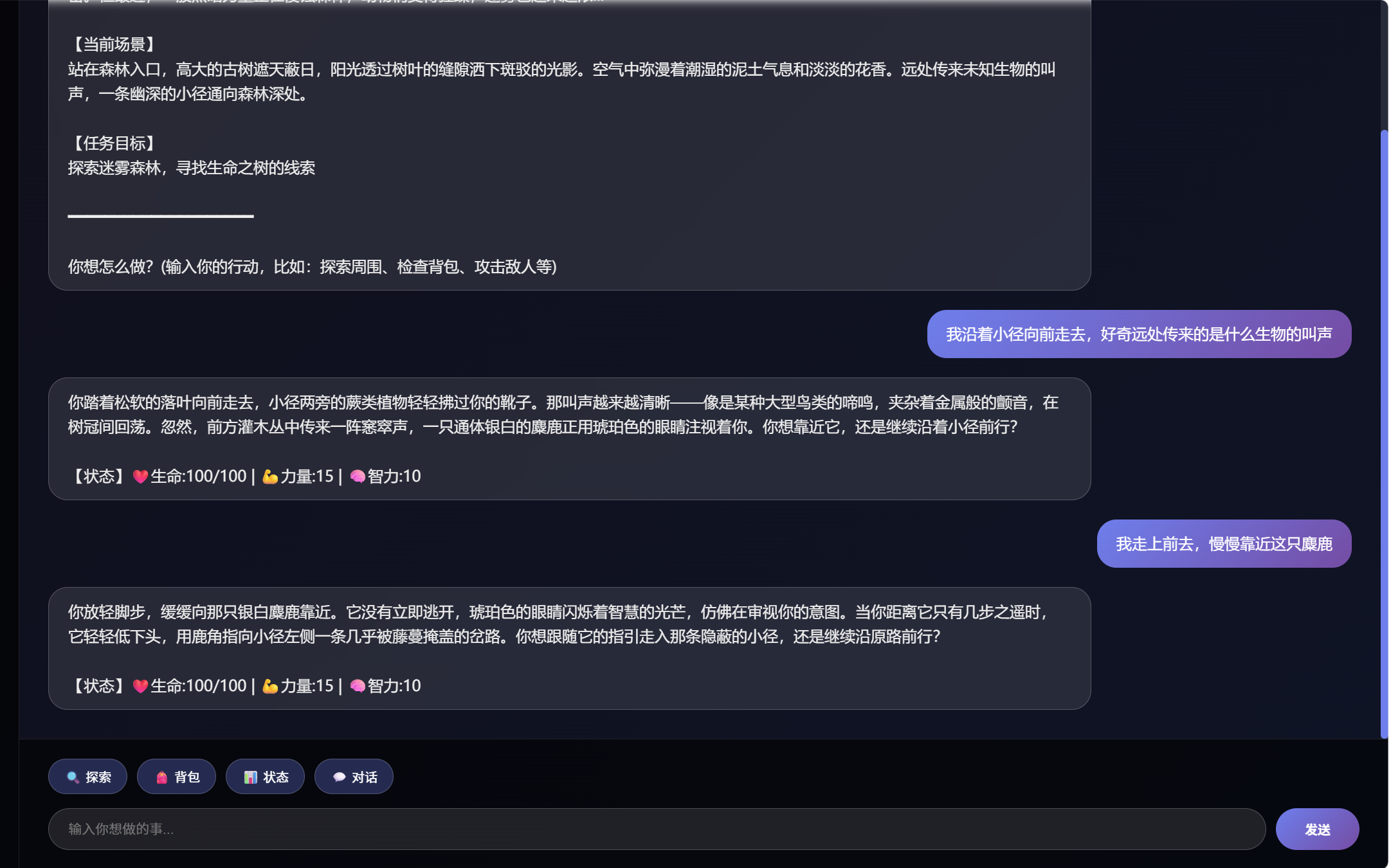
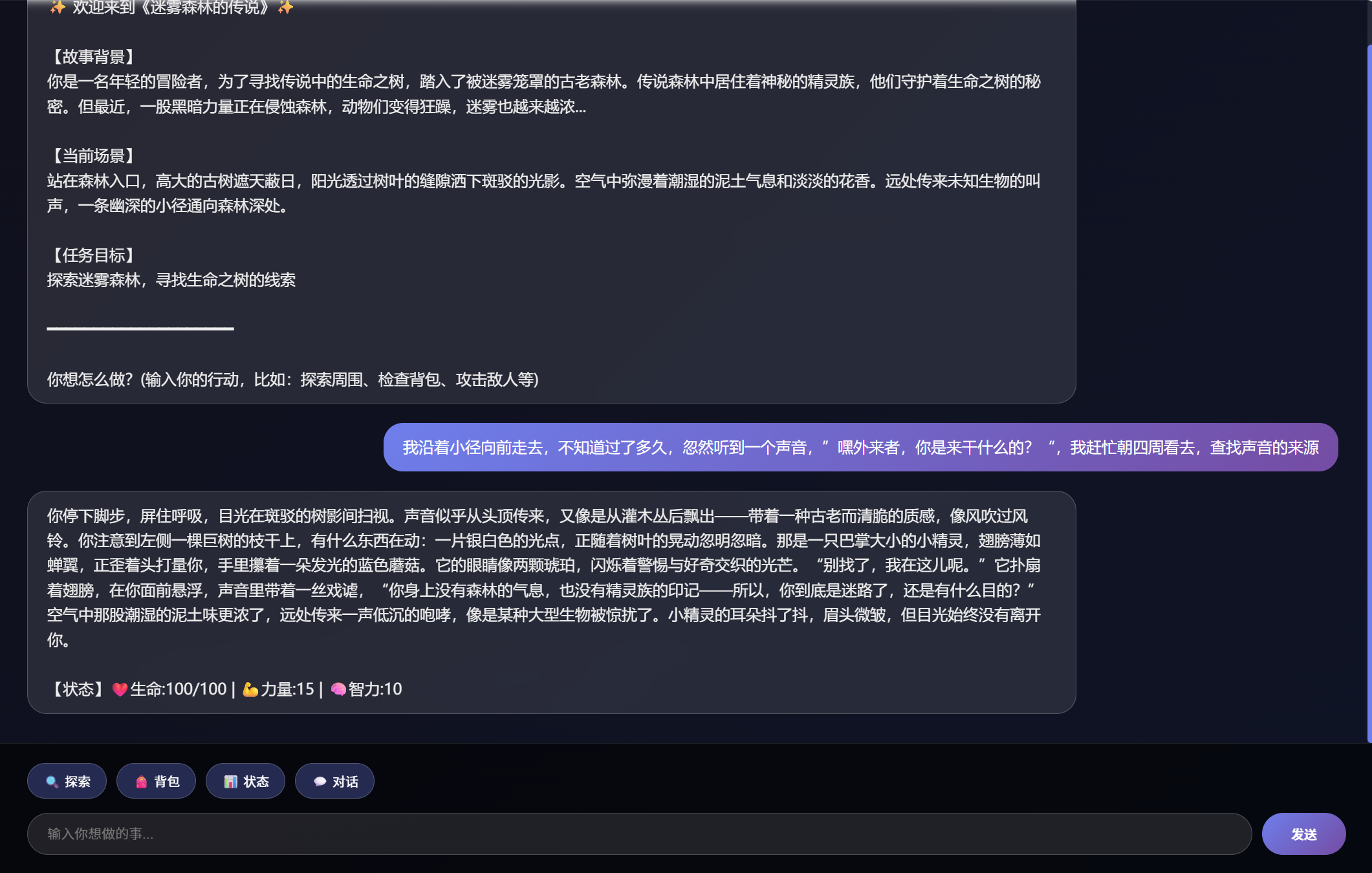
# 收集最近对话上下文,帮助模型保持剧情连续性 history_lines = [] for msg in state.get("messages", [])[-6:]: role = "玩家" if msg.get("role") == "user" else "系统" content = str(msg.get("content", "")).replace("\n", " ").strip() if content: history_lines.append(f"{role}: {content[:120]}") recent_history = "\n".join(history_lines) if history_lines else "无" player_input = "" if state.get("messages"): last_msg = state["messages"][-1] if last_msg.get("role") == "user": player_input = str(last_msg.get("content", "")).strip() prompt = f"""你是一个沉浸式角色扮演游戏的故事叙述者。请根据以下信息生成下一段剧情。通过修改 narrative_director 方法中调用大模型的提示词(设定不同的输出要求,提供更详细的提示词等等),或者添加方法来限制大模型的输出,可以得到不同的回答,如下图所示:
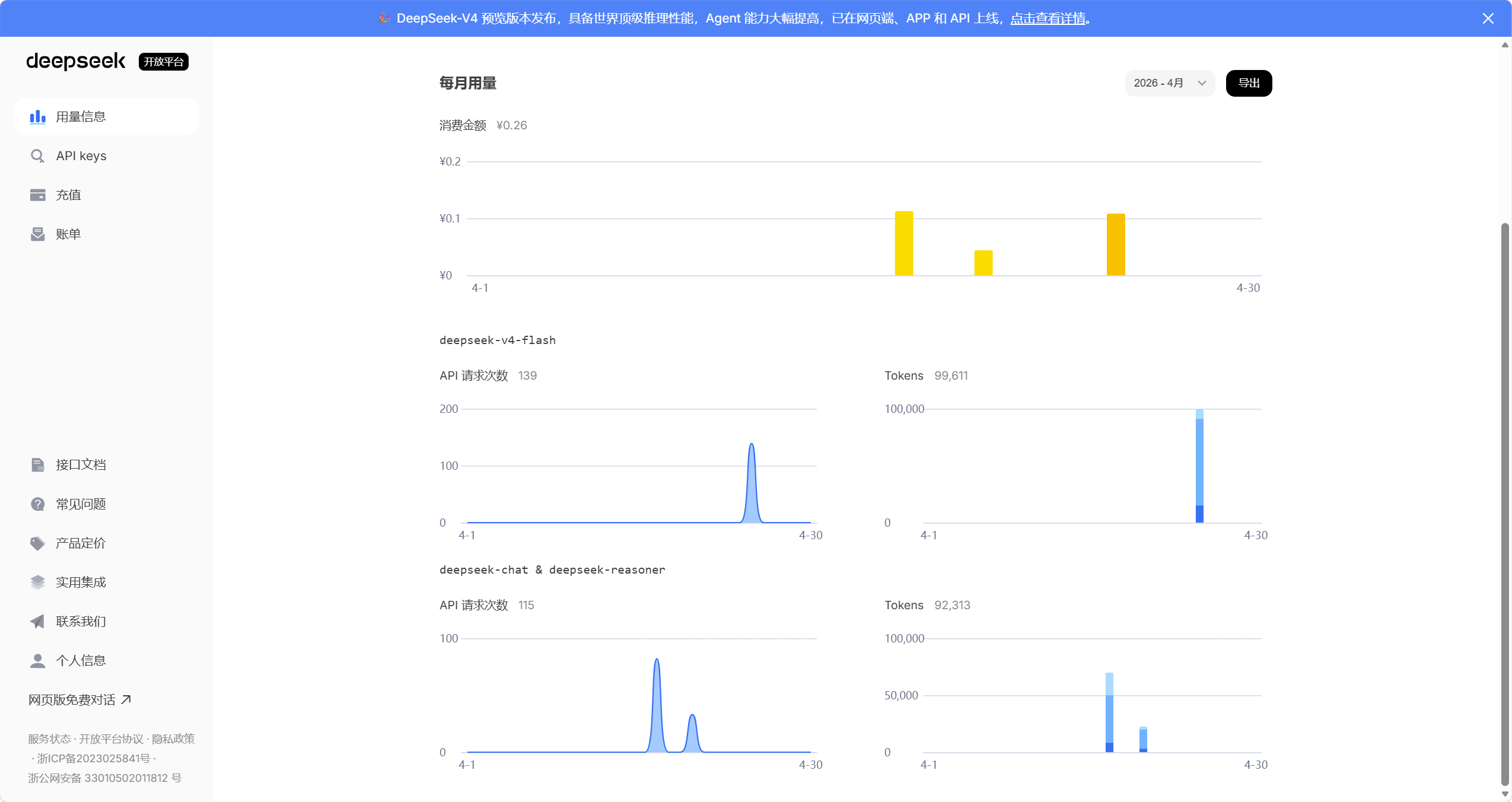
- 检查用量信息可以看到是否真正调用大模型,如下图所示:
- 如果要同时支持另一个大模型,也就是添加另一个大模型的 api key,需要在 .env 中添加新模型的变量,具体的形式与添加 deepseek api 时相同(例如,添加千问的 api 可以写Qwen_API_KEY=sk-xxx等);然后修改 LLMClient 类,增加 provider 参数,或创建新的客户端类(如 QwenClient)。接着在 StoryEngine 中初始化多种客户端(self.llm_deepseek = LLMClient(provider="deepseek") self.llm_qewn = QwenClient()),在具体的节点中选择使用哪个客户端。例如,intent_parser 想用 deepseek,narrative_director 想用 qwen,则在对应方法中调用 self.llm_deepseek.generate() 或 self.llm_qwen.generate()。
三、LangGraph状态图集成
当前的 story_engine.py 已经写了三个独立的节点函数(意图解析、逻辑裁判、叙事导演),并且在 process_action 中手动按顺序调用它们。这种方式虽然能运行,但存在几个问题:首先,如果将来想在中间加入条件分支(比如生命值过低时直接跳转到结局),就需要修改 process_action 的代码,添加一堆 if 判断,节点之间的耦合会越来越紧。其次,每个玩家的游戏状态都存储在内存字典中,一旦服务重启就会丢失,无法实现真正的“存档/读档”。最后,节点之间只能线性执行,无法支持循环或并行。
因此,我们使用 LangGraph 来解决这些问题。它允许将每个节点定义为一个独立的函数,然后用一张“图”来描述节点之间的连接关系(顺序、条件跳转、循环等)。图编译后,只需要调用 graph.invoke(state, config),它会自动按照你定义的规则执行节点,并维护状态。更重要的是,LangGraph 内置了 MemorySaver 检查点机制,只要传入一个 thread_id,它就能自动保存和恢复这个会话的状态——相当于免费获得了存档功能。所以,所谓的“LangGraph 状态图集成”,就是把现有的三个节点函数“注册”到一张图上,然后用 invoke 来驱动整个流程。
具体的构建步骤如下:
- 导入 LangGraph 相关模块,在 story_engine.py 文件的顶部添加:
from typing import TypedDict, Dict, Any, Optional, List from langgraph.graph import StateGraph, END from langgraph.checkpoint.memory import MemorySaver - 定义 StoryState 类:
class StoryState(TypedDict): story_id: str scene_id: str messages: List[Dict[str, str]] current_description: str attributes: Dict[str, int] inventory: List[str] relationships: Dict[str, int] task_progress: Dict[str, str] intent: str intent_target: str last_action_result: str turn_count: int ending_triggered: Optional[str] user_id: Optional[str] last_generation_source: Optional[str] last_generation_error: Optional[str] last_generation_usage: Optional[Dict] last_generation_model: Optional[str] action_result_desc: Optional[str] - 在 StoryEngine.__init__ 中初始化 MemorySaver 并构建图:
self.memory = MemorySaver() self.graph = self.build_graph() - 编写 build_graph 方法:
def build_graph(self): workflow = StateGraph(StoryState) # 添加三个节点 workflow.add_node("intent_parser", self.intent_parser) workflow.add_node("logic_referee", self.logic_referee) workflow.add_node("narrative_director", self.narrative_director) # 设置入口 workflow.set_entry_point("intent_parser") # 添加顺序边 workflow.add_edge("intent_parser", "logic_referee") workflow.add_edge("logic_referee", "narrative_director") workflow.add_edge("narrative_director", END) # 编译图,并传入 checkpointer 以支持状态持久化 return workflow.compile(checkpointer=self.memory) - 修改 process_action 方法,使用 graph.invoke,将原来的手动循环代码替换为:
def process_action(self, state: Dict, user_input: str, thread_id: str = None) -> Dict: # 添加用户消息 state["messages"].append({ "role": "user", "content": user_input, "timestamp": datetime.now().isoformat() }) # 如果没有提供 thread_id,则生成一个 if not thread_id: thread_id = f"{state.get('user_id', 'anonymous')}_{state.get('story_id', 'default')}" config = {"configurable": {"thread_id": thread_id}} # graph.invoke 需要传入配置,并且返回更新后的状态 result = self.graph.invoke(state, config=config) return result - 修改 app.py 中调用 process_action 的方式:
new_state = engine.process_action(state, req.user_input, thread_id=req.session_id) -
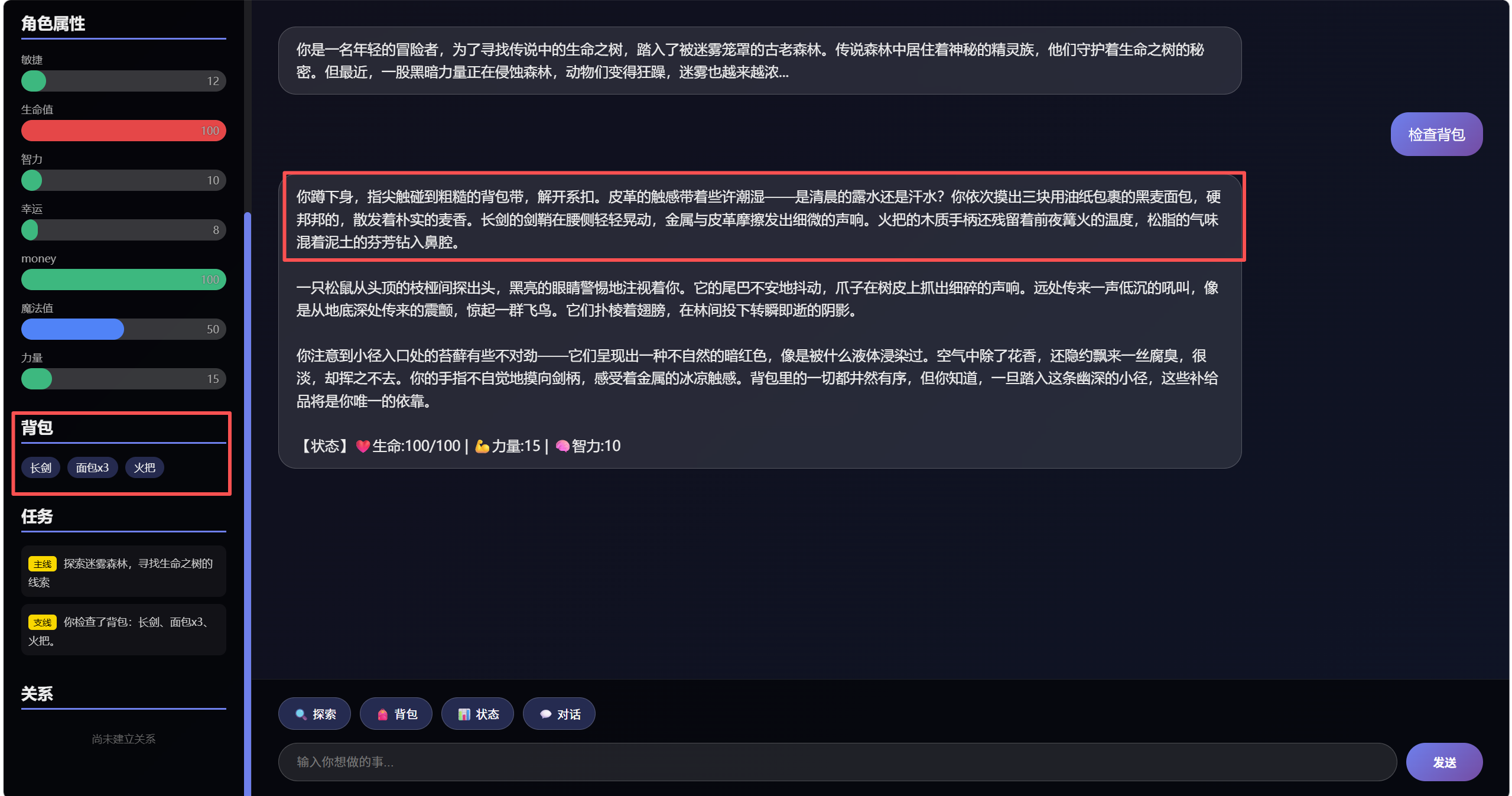
运行代码,可以看出大模型输出的内容与角色属性建立连接:
四、后续计划
完成了大模型 API 接入与 LangGraph 状态图集成后,当前的故事引擎已经具备了智能叙事和工作流管理的基础能力。但整体功能还比较基础,比如角色的差异化体验、长期的养成与成长反馈几乎还是空白。接下来,我们将进入功能细化阶段,我会重点实现角色成长模块,包括角色创建、属性系统、天赋与出身选择、多周目数据继承以及配套的成就体系。这些内容需要完成完整的前后端开发与数据库设计,让玩家真正拥有属于自己的游戏历程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)