LangGraph 垂直领域智能体实战:从入门到构建高效AI工作流
基于LangGraph的智能体开发完全指南,涵盖流程控制、六种构建块与完整项目实战
前言
随着大模型技术的快速发展,基于LLM的智能体(Agent)已成为AI应用开发的热点方向。本文将分享基于LangGraph构建垂直领域智能体的实战经验,帮助读者掌握从基础入门到复杂应用开发的完整技能栈。
一、课程目标与学习路径
本课程适用于对大模型和智能体设计有初步概念的同学。通过本课程,你将达成以下目标:
| 目标 | 描述 |
|---|---|
| 环境搭建 | 独立配置LangGraph开发环境 |
| 掌握工具 | 掌握LangGraph核心概念(图、节点、边、状态、流程控制) |
| 基础开发 | 完成基本的对话系统/工作流搭建 |
| 设计模式 | 理解和实践六种主流智能体设计模式 |
| 完成项目 | 使用LangGraph构建具备实战能力的智能体 |
二、LangGraph快速入门
2.1 什么是智能体?
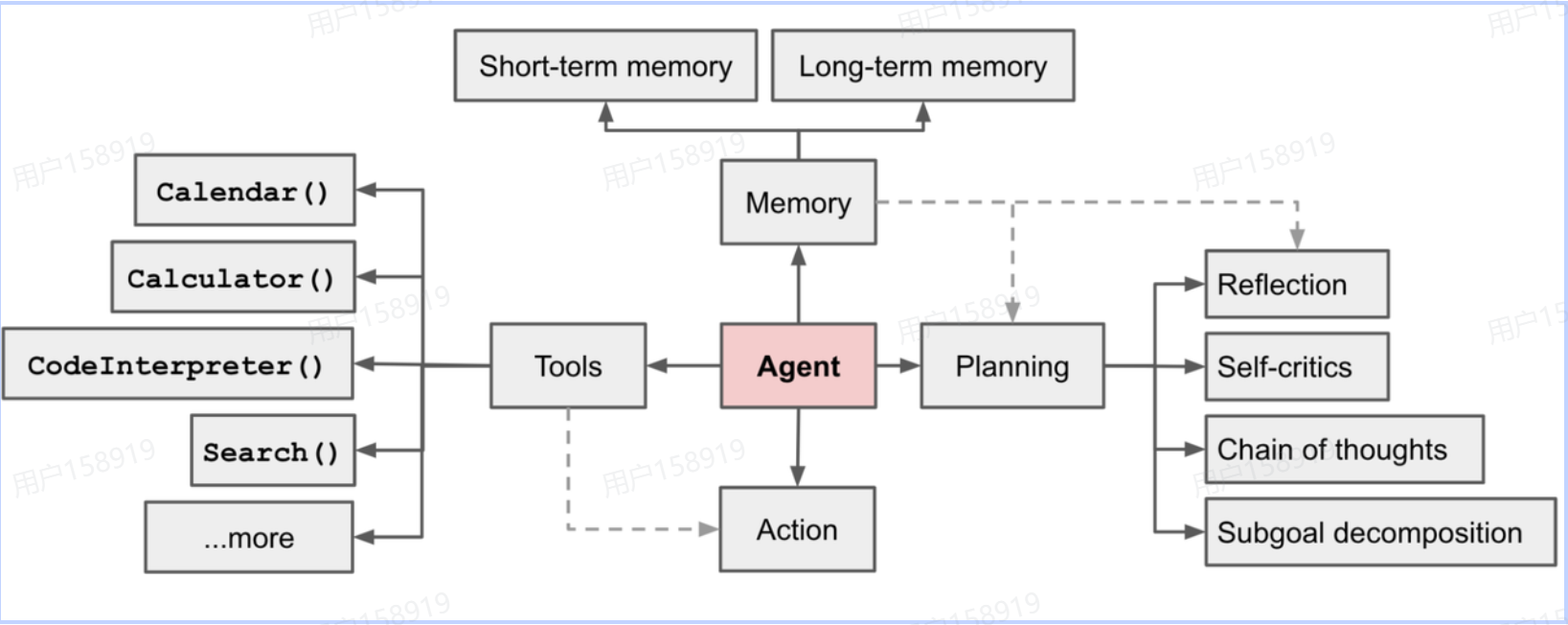
智能体(Agent)是指能够感知环境并采取行动以实现特定目标的代理体。基于大模型的智能体以LLM为核心控制器,通过整合感知、规划、记忆与工具调用等模块,实现复杂任务的自动化处理。
核心架构:
-
🧠 大脑模块:LLM作为决策中枢,负责任务分解和逻辑推理
-
👁️ 感知模块:处理多模态输入,将环境信息转化为模型可理解表征
-
🎯 行动模块:调用外部工具(搜索引擎、API等)执行具体操作
-
💾 记忆机制:通过短期记忆(对话上下文)和长期记忆(向量数据库)实现状态持久化
2.2 为什么选择LangGraph?
LangGraph是由LangChain团队开发的开源框架,专为构建基于LLM的有状态、多参与者应用程序而设计。其核心创新在于采用图结构作为计算模型,突破传统DAG的限制,支持循环工作流和动态状态管理。
💡 通俗理解:LangGraph是专门构建"AI工作流"的工具包,帮你把复杂的AI任务拆成步骤,像搭积木一样组装起来。
三、基本组件详解
LangGraph的核心组件包括:
| 组件 | 概念 | 作用 |
|---|---|---|
| 图(Graph) | 工作流的整体结构 | 定义节点之间的执行路径 |
| 状态(State) | 在节点间传递的数据 | 使用TypedDict定义,支持自定义合并策略 |
| 节点(Node) | 执行单元 | 可以是LLM调用、工具函数或普通Python函数 |
| 边(Edge) | 节点间的连接 | 包括普通边、条件边、起始边和结束边 |
| 记忆(Memory) | 状态持久化 | 使用Checkpointer实现,支持中断恢复 |
四、流程控制实战:冲咖啡案例
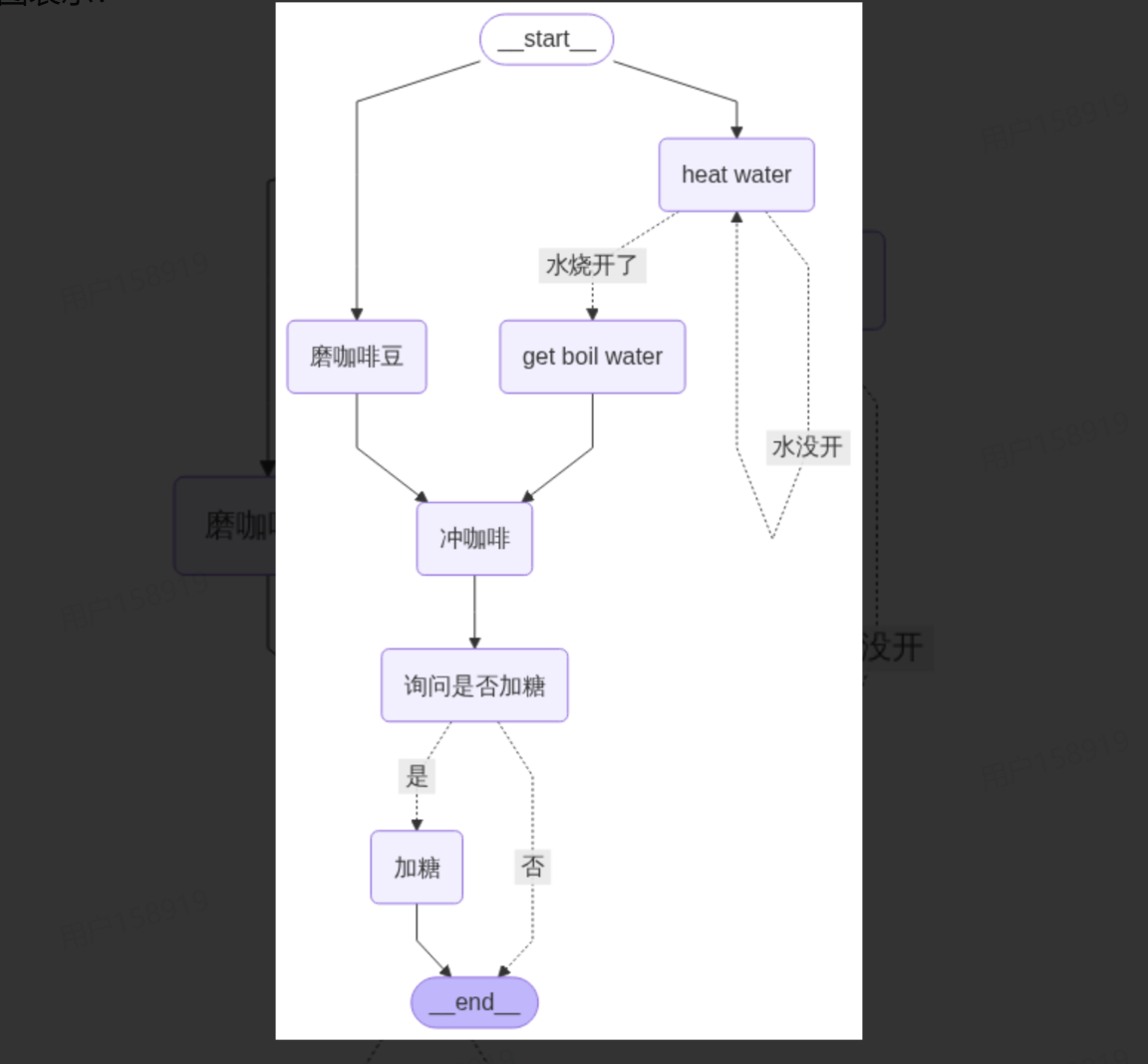
4.1 案例需求与流程图
冲咖啡需要完成以下步骤:
-
磨咖啡豆
-
烧热水(分支+循环:水温不够继续加热直到烧开)
-
冲咖啡(合并前两步结果)
-
决定是否加糖(人工介入:根据用户反馈调整输出)
流程图如下:
4.2 完整代码实现
# 导入 LangGraph 核心组件:起始节点、状态图构建器、结束节点
from langgraph.graph import START, StateGraph, END
# 导入 TypedDict 用于定义状态结构
from typing_extensions import TypedDict
# 导入 Annotated 用于为状态字段添加元数据(如合并策略)
from typing import Annotated
# 导入中断机制和命令控制类型
from langgraph.types import interrupt, Command
# 导入内存检查点保存器,用于支持工作流的中断与恢复
from langgraph.checkpoint.memory import InMemorySaver
# 导入用于可视化流程图的辅助模块
from Agent.courseCode import showGraph
# 合并温度值的方式:取两者中的较大值
def updateTempreture(left, right):
return max(left, right)
# 合并产物的方式:优先保留工序靠后的产物(优先级:加糖咖啡 > 咖啡 > 开水 > 温水 > 凉水)
def updateProduct(left, right):
if left == "加糖咖啡" or right == "加糖咖啡":
return "加糖咖啡"
elif left == "咖啡" or right == "咖啡":
return "咖啡"
elif left == "开水" or right == "开水":
return "开水"
elif left == "温水" or right == "温水":
return "温水"
else:
return "凉水"
# 合并咖啡固体的方式:优先保留工序靠后的产物(咖啡粉优于咖啡豆)
def updateSolid(left, right):
if left == "咖啡粉" or right == "咖啡粉":
return "咖啡粉"
else:
return "咖啡豆"
# 合并是否加糖的状态:只要有一方为“是”,结果即为“是”
def updateSugur(left, right):
if left == "是" or right == "是":
return "是"
else:
return "否"
# 定义状态类,包含水温、产物、咖啡固体、是否加糖四个字段,并指定各自的合并策略
class State(TypedDict):
水温: Annotated[int, updateTempreture]
产物: Annotated[str, updateProduct]
咖啡固体: Annotated[str, updateSolid]
是否加糖: Annotated[str, updateSugur]
# 磨咖啡豆函数:将咖啡固体从“咖啡豆”更新为“咖啡粉”
def 磨咖啡豆(state):
print("*" * 80)
print("磨咖啡豆之前:" + str(state))
state["咖啡固体"] = "咖啡粉"
print("磨咖啡豆之后:" + str(state))
return state
# 烧水函数:每次调用水温增加 10 度,超过 100 度则设为 100 并将产物标记为“开水”
def 烧水(state):
print("*" * 80)
print("烧水之前:" + str(state))
state["产物"] = "没烧开的水"
state["水温"] = state["水温"] + 10
if state["水温"] > 100:
state["水温"] = 100
state["产物"] = "开水"
print("烧水之后:" + str(state))
return state
# 按照温度处理水的条件函数:判断水是否烧开,返回对应分支标签
def 按温度处理水(state):
if state["水温"] == 100:
return "水烧开了"
else:
return "水没开"
# 得到开水函数:占位函数,无实际操作,仅用于流程图结构展示
def 得到开水(state):
return state
# 冲咖啡函数:将产物更新为“咖啡”
def 冲咖啡(state):
print("冲咖啡之前:" + str(state))
state["产物"] = "咖啡"
print("冲咖啡之后:" + str(state))
return state
# 中断节点函数:触发用户交互中断,等待用户输入是否加糖
def 询问是否加糖(state):
human_response = interrupt("")
state["是否加糖"] = human_response
return state
# 根据用户是否加糖的反馈,决定流程走向的分支函数
def 是否加糖分支(state):
# print(state)
if state["是否加糖"] == "是":
return "是"
elif state["是否加糖"] == "否":
return "否"
# 加糖函数:将产物更新为“加糖咖啡”
def 加糖(state):
print("加糖之前:" + str(state))
state["产物"] = "加糖咖啡"
print("加糖之后:" + str(state))
return state
def buildGraph5():
# 初始化状态图构建器
graphBuilder = StateGraph(State)
# 创建内存检查点器,用于支持中断恢复
checkpointer = InMemorySaver()
# 添加各个功能节点
graphBuilder.add_node("heat water", 烧水)
graphBuilder.add_node("get boil water", 得到开水)
graphBuilder.add_node("磨咖啡豆", 磨咖啡豆)
graphBuilder.add_node("冲咖啡", 冲咖啡)
graphBuilder.add_node("询问是否加糖", 询问是否加糖)
graphBuilder.add_node("加糖", 加糖)
# 添加边:从起点并行启动磨豆和烧水
graphBuilder.add_edge(START, "磨咖啡豆")
graphBuilder.add_edge(START, "heat water")
# 添加条件边:根据水温判断是否继续烧水或进入下一步
graphBuilder.add_conditional_edges("heat water", 按温度处理水,
{"水烧开了": "get boil water", "水没开": "heat water"})
# 当热水准备好且咖啡豆磨好后,进入冲咖啡环节
graphBuilder.add_edge(["get boil water", "磨咖啡豆"], "冲咖啡")
# 冲完咖啡后询问是否加糖
graphBuilder.add_edge("冲咖啡", "询问是否加糖")
# 根据用户选择决定是否加糖或直接结束
graphBuilder.add_conditional_edges("询问是否加糖", 是否加糖分支, {"是": "加糖", "否": END})
# 加糖完成后结束流程
graphBuilder.add_edge("加糖", END)
# 编译图并绑定检查点器
graph = graphBuilder.compile(checkpointer=checkpointer)
return graph
def buildGraph6():
# === 构建烧水子图 ===
# 初始化子图构建器
heatWaterSubGraphBuilder = StateGraph(State)
# 添加烧水和得到开水节点
heatWaterSubGraphBuilder.add_node("heat water", 烧水)
heatWaterSubGraphBuilder.add_node("get boil water", 得到开水)
# 添加边:从起点开始烧水
heatWaterSubGraphBuilder.add_edge(START, "heat water")
# 添加条件边:根据水温判断循环烧水或完成
heatWaterSubGraphBuilder.add_conditional_edges("heat water", 按温度处理水,
{"水烧开了": "get boil water", "水没开": "heat water"})
# 编译烧水子图(无需检查点器,因无中断)
heatWaterSubGraph = heatWaterSubGraphBuilder.compile()
# === 构建加糖子图 ===
# 初始化子图构建器
addSugurSubGraphBuilder = StateGraph(State)
# 初始化记忆检查点器:此子图包含人工中断,必须配备检查点器以支持恢复
checkpointer = InMemorySaver()
# 添加询问和加糖节点
addSugurSubGraphBuilder.add_node("询问是否加糖 1", 询问是否加糖)
addSugurSubGraphBuilder.add_node("加糖", 加糖)
# 添加边:从起点开始询问
addSugurSubGraphBuilder.add_edge(START, "询问是否加糖 1")
# 添加条件边:根据用户选择进入加糖或结束
addSugurSubGraphBuilder.add_conditional_edges("询问是否加糖 1", 是否加糖分支, {"是": "加糖", "否": END})
# 编译加糖子图,绑定检查点器
addSugurSubGraph = addSugurSubGraphBuilder.compile(checkpointer=checkpointer)
# === 构建总图 ===
# 初始化总图构建器
graphBuilder = StateGraph(State)
# 添加节点:将已编译的子图作为独立节点加入总图
graphBuilder.add_node("得到热水子图", heatWaterSubGraph)
graphBuilder.add_node("磨咖啡豆", 磨咖啡豆)
graphBuilder.add_node("冲咖啡", 冲咖啡)
graphBuilder.add_node("加糖子图 1", addSugurSubGraph)
# 添加边:并行启动烧水子图和磨豆
graphBuilder.add_edge(START, "得到热水子图")
graphBuilder.add_edge(START, "磨咖啡豆")
# 两者完成后进入冲咖啡
graphBuilder.add_edge(["得到热水子图", "磨咖啡豆"], "冲咖啡")
# 冲完后进入加糖子图(含中断)
graphBuilder.add_edge("冲咖啡", "加糖子图 1")
# 编译总图,绑定检查点器以支持子图中的中断恢复
graph = graphBuilder.compile(checkpointer=checkpointer)
return heatWaterSubGraph, addSugurSubGraph, graph
if __name__ == "__main__":
"""
# 以下为 buildGraph5 的测试代码(已注释)
graph = buildGraph5()
# 打印图
showGraph.showGraphInCode(graph, "复杂流程.jpg")
"""
# 使用 buildGraph6 构建包含子图的完整流程
heatWaterSubGraph, addSugurSubGraph, graph = buildGraph6()
# 分别绘制烧水子图、加糖子图和总图
showGraph.showGraphInCode(heatWaterSubGraph, "images/烧热水子图.jpg")
showGraph.showGraphInCode(addSugurSubGraph, "images/加糖子图.jpg")
showGraph.showGraphInCode(graph, "images/总图.jpg")
# 初始化初始状态:水温 58 度,产物为凉水,咖啡固体为咖啡豆
state: State = {"水温": 58, "产物": "凉水", "咖啡固体": "咖啡豆"}
# 配置线程 ID,用于检查点追踪
config = {"configurable": {"thread_id": "some_id"}}
# 首次调用图执行流程,将在“询问是否加糖”处中断
state = graph.invoke(state, config)
# 中断后,接收用户输入
userDecision = input("先生您好,请问您的咖啡需要加糖吗?(是/否):")
# 验证输入合法性
while userDecision not in {"是", "否"}:
userDecision = input("先生您好,请问您的咖啡需要加糖吗?(是/否):")
# 使用 Command 函数向图提供用户输入,恢复执行流程
result = graph.invoke(Command(resume=userDecision), config=config)
print(result)
五、智能体的六种构建块
5.1 构建智能体的两种思路
| 思路 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| 工作流(Workflow) | 通过预先构建的代码路径完成任务 | 可控性强、一致性高 | 需要为特定任务定制 |
| 智能体(Agent) | LLM动态生成工作流程并自主纠偏 | 灵活、无需定制 | 可控性不足、复杂任务表现不稳定 |
5.2 构建块①:提示链(Prompt Chaining)
优势:将复杂任务分解为多个简单步骤,效果远好于单次完成。
# 导入必要的库:StateGraph 用于构建状态图,START 和 END 定义图的起止点
from langgraph.graph import StateGraph, START, END
# 导入 ChatOllama 用于调用本地 Ollama 模型
from langchain_ollama import ChatOllama
# 导入 TypedDict 用于定义状态数据结构
from typing_extensions import TypedDict
# 定义工作流的状态结构,包含主题、大纲、草稿和最终论文四个字段
class State(TypedDict):
topic: str # 用户输入的分析主题
outline: str # LLM 生成的分析报告大纲
draft: str # 基于大纲生成的完整草稿
paper: str # 经过润色后的最终报告
# 初始化大语言模型,使用 qwen2.5:7b 模型
llm = ChatOllama(model="qwen2.5:7b")
# 第一步:写大纲
# 根据输入的主题,调用 LLM 生成包含历史、现状、原因、解决办法及趋势评估的分析报告大纲
def getOutline(state):
prompt = """针对“""" + state["topic"] + """”这个主题,写一份分析报告的大纲,包括历史由来,现状分析,原因分析,解决办法,趋势评估等几个主要部分。"""
state["outline"] = llm.invoke(prompt).content
print("outline " + "*" * 80)
print(state["outline"])
return state
# 第二步:根据大纲写草稿
# 接收上一步生成的大纲,调用 LLM 撰写一份约 2000 字的完整分析报告草稿
def getDraft(state):
prompt = """根据【大纲】,写一份完整的分析报告,要求语言流畅,逻辑清晰,主要内容围绕大纲展开,内容 2000 字左右。
【大纲】
""" + state["outline"]
state["draft"] = llm.invoke(prompt).content
print("draft " + "*" * 80)
print(state["draft"])
return state
# 第三步:对草稿进行润色
# 接收上一步生成的草稿,调用 LLM 进行全文润色,优化语法、用词和句式,使其风格自然流畅
def getPaper(state):
prompt = """请对下面的【分析报告】进行全文润色,包括语法检查,用词优化和句式调整,要求文章语言风格自然流畅,逻辑清晰,表达生动而简洁,避免生硬而刻板的 AI 习作风格,与原文的主要意思保持不变。
【分析报告】
""" + state["draft"]
state["paper"] = llm.invoke(prompt).content
print("paper " + "*" * 80)
print(state["paper"])
return state
# 构建 LangGraph 工作流图
def buildGraph():
# 初始化状态图,指定状态类型为 State
graphBuilder = StateGraph(State)
# 添加三个处理节点:生成大纲、生成草稿、润色论文
graphBuilder.add_node("getOutline", getOutline)
graphBuilder.add_node("getDraft", getDraft)
graphBuilder.add_node("getPaper", getPaper)
# 定义执行顺序:从起点开始,依次经过大纲、草稿、润色,最后到达终点
graphBuilder.add_edge(START, "getOutline")
graphBuilder.add_edge("getOutline", "getDraft")
graphBuilder.add_edge("getDraft", "getPaper")
graphBuilder.add_edge("getPaper", END)
# 编译图并返回实例
graph = graphBuilder.compile()
return graph
if __name__ == "__main__":
# 构建工作流图
graph = buildGraph()
# 导入绘图工具并将工作流图保存为图片
from Agent.courseCode import showGraph
showGraph.showGraphInCode(graph, "graph.jpg")
# 初始化状态,设定分析主题为“墨西哥毒品泛滥情况报告”
state: State = {"topic": "墨西哥毒品泛滥情况报告"}
# 执行工作流并获取结果
result = graph.invoke(state)
print("final " + "*" * 80)
print(result)
5.3 构建块②:分支(Routing)
适用场景:根据输入类型将任务路由到专门的处理器,提升输出质量。
from langgraph.graph import StateGraph, START
from langchain_ollama import ChatOllama
from typing_extensions import TypedDict
# 定义状态结构,包含话题、观点倾向、学派和辩论内容
class State(TypedDict):
topic: str # 讨论的话题
aspect: str # 对话题的倾向性描述(如“正确”或“错误”)
faction: str # LLM 判断出的学派(儒家/法家/道家)
debate: str # 对应学派的详细论证内容
# 初始化本地大语言模型
llm = ChatOllama(model="qwen2.5:7b")
def getFraction(state):
"""
根据输入的话题和观点倾向,调用 LLM 判断最可能支持该观点的学派。
返回更新后的 state,其中 faction 字段被填充为学派名称。
"""
prompt = """你是一位国学大师,你认为“""" + state["topic"] + """”这个观点是 """ + state[
"aspect"] + """ 的,那么在["儒家","法家","道家"]这三个学派中,你最可能持哪一派的观点?只允许使出学派的名称,不允许输出其他字符。"""
state["faction"] = llm.invoke(prompt).content
print("faction " + "*" * 80)
print(state["faction"])
return state
def selectFraction(state):
"""
根据 state 中的 faction 字段,返回对应的节点名称字符串,用于条件分支路由。
"""
if state["faction"] == "儒家":
return "Confucian"
elif state["faction"] == "法家":
return "Legalists"
elif state["faction"] == "道家":
return "Taoism"
def getDebateFromConfucian(state):
"""
使用儒家思想对给定话题进行详细论证,并将结果存入 state["debate"]。
"""
prompt = """你是一位国学大师,你认为“""" + state["topic"] + """”这个观点是 """ + state[
"aspect"] + """ 的,这是儒家的观点,请使用儒家思想对这个问题详细展开论证。"""
state["debate"] = llm.invoke(prompt).content
print(state["debate"])
return state
def getDebateFromLegalists(state):
"""
使用法家思想对给定话题进行详细论证,并将结果存入 state["debate"]。
"""
prompt = """你是一位国学大师,你认为“""" + state["topic"] + """”这个观点是 """ + state[
"aspect"] + """ 的,这是法家的观点,请使用法家思想对这个问题详细展开论证。"""
state["debate"] = llm.invoke(prompt).content
print(state["debate"])
return state
def getDebateFromTaoism(state):
"""
使用道家思想对给定话题进行详细论证,并将结果存入 state["debate"]。
"""
prompt = """你是一位国学大师,你认为“""" + state["topic"] + """”这个观点是 """ + state[
"aspect"] + """ 的,这是道家的观点,请使用道家思想对这个问题详细展开论证。"""
state["debate"] = llm.invoke(prompt).content
print(state["debate"])
return state
def buildGraph():
"""
构建并编译 LangGraph 状态图:
- 添加四个节点:getFraction 和三个学派论证节点
- 从 START 连接到 getFraction
- 根据 selectFraction 的返回值,条件路由到对应的学派论证节点
"""
graphBuilder = StateGraph(State)
graphBuilder.add_node("getFraction", getFraction)
graphBuilder.add_node("getDebateFromConfucian", getDebateFromConfucian)
graphBuilder.add_node("getDebateFromLegalists", getDebateFromLegalists)
graphBuilder.add_node("getDebateFromTaoism", getDebateFromTaoism)
graphBuilder.add_edge(START, "getFraction")
graphBuilder.add_conditional_edges("getFraction", selectFraction,
{"Confucian": "getDebateFromConfucian", "Legalists": "getDebateFromLegalists",
"Taoism": "getDebateFromTaoism"})
graph = graphBuilder.compile()
return graph
if __name__ == "__main__":
# 构建工作流图
graph = buildGraph()
# 导入可视化工具并保存图为 JPG 文件
from Agent.courseCode import showGraph
showGraph.showGraphInCode(graph, "graph.jpg")
# 初始化测试状态:话题为“地法天,天法道,道法自然”,观点倾向为“正确”
state: State = {"topic": "地法天,天法道,道法自然", "aspect": "正确"}
# 执行工作流
result = graph.invoke(state)
# 打印最终结果
print("final " + "*" * 80)
print(result)
5.4 构建块③:并行化(Parallelization)
适用场景:同时执行互不依赖的任务,提高效率。
from langgraph.graph import StateGraph, START
from langchain_ollama import ChatOllama
from typing_extensions import TypedDict
from typing import Annotated
import random
def updateReceiveDate(left, right):
"""
自定义状态更新函数:取两个日期中的最大值。
用于处理并行节点产生的 receiveDate 冲突,确保保留最晚的日期。
"""
return max(left, right)
class State(TypedDict):
"""
定义 LangGraph 的状态结构。
sendDate: 发货日期(9 月的第几天)
transTime: 运输所需天数
receiveDate: 预计收货日期,使用 Annotated 指定冲突解决策略为 updateReceiveDate
returnMessage: LLM 生成的回复消息
"""
sendDate: int
transTime: int
receiveDate: Annotated[int, updateReceiveDate]
returnMessage: str
# 初始化 Ollama 聊天模型,使用 qwen2.5:7b
llm = ChatOllama(model="qwen2.5:7b")
def getSendData(state):
"""
生成随机发货日期(1-25 日),并更新到状态中。
模拟工厂确定最早发货日期的过程。
"""
sendData = random.randint(1, 25)
state["sendDate"] = sendData
return state
def getTransTime(state):
"""
生成随机运输时间(3-5 天),并更新到状态中。
模拟物流运输所需的时间估算。
"""
transTime = random.randint(3, 5)
state["transTime"] = transTime
return state
def sendMessage(state):
"""
根据状态中的发货日期、运输时间和客户期望收货日期,构造提示词并调用 LLM 生成回复。
模拟销售员给客户发送通知消息的过程。
"""
prompt = "你是江南机械厂的销售员王钟期,顾客张董事长在我厂预定了一批机器设备,希望能 9 月" + str(
state["receiveDate"]) + "日收到货物,厂里最早的发货日期是 9 月" + str(state["sendDate"]) + "日,运输时间是" + str(
state["transTime"]) + "天,给客户发出适当的回复。"
print(prompt)
# 调用 LLM 生成回复内容
state["returnMessage"] = llm.invoke(prompt).content
print("returnMessage " + "*" * 80)
print(state["returnMessage"])
return state
def buildGraph():
"""
构建并编译 LangGraph 状态图。
包含三个节点:getSendData, getTransTime, sendMessage。
其中 getSendData 和 getTransTime 并行执行,完成后共同触发 sendMessage。
"""
graphBuilder = StateGraph(State)
# 添加节点
graphBuilder.add_node("getSendData", getSendData)
graphBuilder.add_node("getTransTime", getTransTime)
graphBuilder.add_node("sendMessage", sendMessage)
# 添加边:START 并行触发两个节点,两者完成后汇聚到 sendMessage
graphBuilder.add_edge(START, "getSendData")
graphBuilder.add_edge(START, "getTransTime")
graphBuilder.add_edge(["getSendData", "getTransTime"], "sendMessage")
# 编译图
graph = graphBuilder.compile()
return graph
if __name__ == "__main__":
# 构建工作流图
graph = buildGraph()
# 导入可视化工具并保存图为 JPG
from Agent.courseCode import showGraph
showGraph.showGraphInCode(graph, "graph.jpg")
# 初始化状态,设定客户期望收货日期为 9 月 23 日
state: State = {"receiveDate": 23}
# 执行工作流
result = graph.invoke(state)
# 输出最终结果
print("final " + "*" * 80)
print(result)
5.5 构建块④:计划-执行(Orchestrator-Workers)
为什么需要? 当工作体量较大无法一次完成,且各部分之间有强关联时使用。
"""
计划-执行工作流 - 小说批量创作示例
流程:规划章节 → 并行分配worker创作 → 汇总成书
"""
from langgraph.graph import StateGraph, START, END
from langchain_ollama import ChatOllama
from langgraph.types import Send
from typing_extensions import TypedDict
from typing import Annotated
from pydantic import BaseModel, Field
import operator
# ==================== 数据结构定义 ====================
class Section(BaseModel):
"""章节结构"""
num: int = Field(description="章节序号")
name: str = Field(description="章节标题")
description: str = Field(description="章节描述")
class Sections(BaseModel):
"""章节列表"""
sections: list[Section]
class State(TypedDict):
"""主图状态"""
storyLine: str # 故事梗概
sections: list[Section] # 章节规划列表
completedSections: Annotated[list, operator.add] # 已完成的章节
novel: str # 完整小说
class WorkerState(TypedDict):
"""Worker状态"""
section: Section # 当前要写的章节
completedSections: Annotated[list, operator.add] # 完成的章节
llm = ChatOllama(model="qwen2.5:7b")
# ==================== 主图节点函数 ====================
def getWholeStory(state):
"""步骤1:生成故事梗概"""
prompt = "你是一位著名小说家,正在创作一部精彩的侦探小说,首先给出故事梗概,1000字左右。"
state["storyLine"] = llm.invoke(prompt).content
print("\n📖 故事梗概:")
print(state["storyLine"][:300] + "...")
return state
def orchestrate(state):
"""步骤2:规划章节(Orchestrator角色)"""
planner = llm.with_structured_output(Sections)
result = planner.invoke(f"""你是一位著名小说家,根据下面的【故事梗概】,将小说分成10个章节,
并给出章节的剧情发展。
【故事梗概】
{state['storyLine']}""")
state["sections"] = result.sections
print("\n📑 章节规划完成:")
for section in state["sections"][:3]:
print(f" {section.name}: {section.description[:50]}...")
print(" ...")
return state
def synthesizer(state):
"""步骤4:汇总所有章节成书(Synthesizer角色)"""
completedSections = sorted(state["completedSections"], key=lambda x: x["num"])
novel = "\n\n".join([section["content"] for section in completedSections])
state["novel"] = novel
print(f"\n📚 小说汇总完成!总字数:{len(novel)}字")
return state
# ==================== Worker节点函数 ====================
def work(state: WorkerState):
"""Worker:创作单个章节"""
prompt = f"""你是一位著名小说家,根据下面提供的【章节标题】和【章节概述】,
完成其中的一个章节。最前面是章节标题(格式:【第X章】 标题),后面是章节内容。
章节序号:{state['section'].num}
章节标题:{state['section'].name}
章节概述:{state['section'].description}
本章节长度1500字左右。"""
result = llm.invoke(prompt)
print(f"✍️ 第{state['section'].num}章完成:{state['section'].name}")
return {
"num": state['section'].num,
"name": state['section'].name,
"content": result.content,
"completedSections": [{"num": state['section'].num, "content": result.content}]
}
def assignWorkers(state: State):
"""分配任务:为每个章节创建一个Worker"""
return [Send("work", {"section": s}) for s in state["sections"]]
# ==================== 构建图 ====================
def buildOrchestratorGraph():
"""构建计划-执行工作流"""
graphBuilder = StateGraph(State)
graphBuilder.add_node("getWholeStory", getWholeStory)
graphBuilder.add_node("orchestrate", orchestrate)
graphBuilder.add_node("work", work)
graphBuilder.add_node("synthesizer", synthesizer)
graphBuilder.add_edge(START, "getWholeStory")
graphBuilder.add_edge("getWholeStory", "orchestrate")
# 条件边:规划完成后分配所有Worker
graphBuilder.add_conditional_edges("orchestrate", assignWorkers, ["work"])
# 所有Worker完成后汇总
graphBuilder.add_edge("work", "synthesizer")
graphBuilder.add_edge("synthesizer", END)
return graphBuilder.compile()
# 执行示例
if __name__ == "__main__":
graph = buildOrchestratorGraph()
state = {}
result = graph.invoke(state)
print(f"\n✅ 小说创作完成!共{len(result['completedSections'])}章")5.6 构建块⑤:生成-评估(Evaluator-Optimizer)
适用场景:通过反馈循环不断优化输出质量。
"""
生成-评估工作流 - 文章质量优化示例
流程:生成文章 → 评估质量 → 不合格则反馈修改 → 循环直到合格
"""
from langgraph.graph import StateGraph, START, END
from langchain_ollama import ChatOllama
from typing_extensions import TypedDict
import json
# ==================== 定义状态 ====================
class State(TypedDict):
topic: str # 文章主题
article: str # 文章内容
feedback: str # 修改意见
qualified: str # 是否合格(是/否)
count: int # 生成次数
llm = ChatOllama(model="qwen2.5:7b")
# ==================== 节点函数 ====================
def generate(state):
"""生成文章(考虑之前的反馈意见)"""
if state.get("feedback"):
prompt = f"""根据提供的主题写一篇论证文章。
主题:{state['topic']}
同时你需要考虑如下修改建议:{state['feedback']}"""
else:
prompt = f"""请写一篇关于以下主题的论证文章,确保逻辑严密、有说服力。
主题:{state['topic']}"""
result = llm.invoke(prompt)
state["count"] += 1
state["article"] = result.content
print(f"\n🔄 第{state['count']}次生成完成")
return state
def evaluate(state):
"""评估文章质量,给出修改意见"""
prompt = f"""判断【论证文章】是否很好地论证了【主题】,是否逻辑严密、有说服力。
如果不合格,给出具体的修改意见。
请严格按照以下JSON格式输出:
{{"是否合格": "", "修改意见": ""}}
【主题】{state['topic']}
【论证文章】{state['article']}"""
result = llm.invoke(prompt)
resultJson = json.loads(result.content)
state["qualified"] = resultJson["是否合格"]
state["feedback"] = resultJson["修改意见"]
print(f"📊 评估结果:{state['qualified']}")
if state['qualified'] != '合格':
print(f"💡 修改意见:{state['feedback'][:100]}...")
return state
def judgement(state):
"""判断是否继续优化"""
if state["count"] >= 3: # 最多优化3次
print("⚠️ 已达最大优化次数,接受当前版本")
return "accept"
elif state["qualified"] == "合格":
print("✅ 文章质量合格!")
return "accept"
else:
print("🔄 需要继续优化...")
return "reject"
# ==================== 构建图 ====================
def buildEvaluatorGraph():
"""构建生成-评估工作流"""
graphBuilder = StateGraph(State)
graphBuilder.add_node("generate", generate)
graphBuilder.add_node("evaluate", evaluate)
graphBuilder.add_edge(START, "generate")
graphBuilder.add_edge("generate", "evaluate")
# 条件边:根据评估结果决定是否重新生成
graphBuilder.add_conditional_edges(
"evaluate",
judgement,
{"accept": END, "reject": "generate"}
)
return graphBuilder.compile()
# 执行示例
if __name__ == "__main__":
graph = buildEvaluatorGraph()
state = {"topic": "日本经济会在未来再次崛起", "count": 0}
result = graph.invoke(state)
print(f"\n🎉 最终文章质量:{result['qualified']},共优化{result['count']}次")5.7 扩展:辩论赛模式(生成-评估变体)
"""
辩论赛模式 - 让两个大模型左右互搏
"""
from langgraph.graph import StateGraph, START, END
from langchain_ollama import ChatOllama
from typing_extensions import TypedDict
class State(TypedDict):
topic: str # 辩论主题
pos: str # 正方发言
neg: str # 反方发言
count: int # 辩论轮次
llm = ChatOllama(model="qwen2.5:7b")
def poser(state):
"""正方发言"""
if state.get("neg"):
prompt = f"""你是一位辩论高手,现在担任正方,根据【论题】和【反方发言】,
用口语化的风格说出你的观点,驳斥【反方发言】。500字以内。
【论题】{state['topic']}
【反方发言】{state['neg']}"""
else:
prompt = f"""你是一位辩论高手,现在担任正方,用口语化的风格说出你的观点。
【论题】{state['topic']}"""
result = llm.invoke(prompt)
state["count"] += 1
state["pos"] = result.content
print(f"\n🎤 【正方第{state['count']}轮】:\n{state['pos'][:200]}...")
return state
def neger(state):
"""反方发言"""
prompt = f"""你是一位辩论高手,现在担任反方,根据【论题】和【正方发言】,
用口语化的风格驳斥【正方发言】。500字以内。
【论题】{state['topic']}
【正方发言】{state['pos']}"""
result = llm.invoke(prompt)
state["neg"] = result.content
print(f"\n🎤 【反方第{state['count']}轮】:\n{state['neg'][:200]}...")
return state
def judgement(state):
"""判断是否继续辩论(最多10轮)"""
return "finish" if state["count"] >= 10 else "proceed"
def buildDebateGraph():
graphBuilder = StateGraph(State)
graphBuilder.add_node("poser", poser)
graphBuilder.add_node("neger", neger)
graphBuilder.add_edge(START, "poser")
graphBuilder.add_edge("poser", "neger")
graphBuilder.add_conditional_edges("neger", judgement, {"finish": END, "proceed": "poser"})
return graphBuilder.compile()
if __name__ == "__main__":
graph = buildDebateGraph()
state = {"topic": "高彩礼是造成结婚率下降的主要原因", "count": 0}
result = graph.invoke(state)
print(f"\n🏆 辩论结束!共进行{result['count']}轮")5.8 构建块⑥:智能体(Agent)
终极形态:LLM + 工具集,动态决策完成复杂任务。
"""
智能体模式 - 旅行助手示例
Agent自主决策调用哪些工具来完成用户请求
"""
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
# ==================== 定义工具函数 ====================
def getTrainSchedule(queryDate: str, start: str, end: str) -> str:
"""查询列车班次
Args:
queryDate: 查询日期
start: 起点城市名称
end: 终点城市名称
Returns:
列车班次信息字符串
"""
print(f"\n🚆 [工具调用] 查询火车票:{start} → {end},日期:{queryDate}")
# 模拟返回的列车数据
result = [
["D81", "12:24", "14:30", "北京西站", "540"],
["K4427", "15:38", "21:30", "北京站", "220"]
]
resultStr = f"您查询的在 {queryDate} 从 {start} 到 {end} 的列车共 {len(result)} 班:\n"
for res in result:
resultStr += f" {res[0]}次:{res[1]}发车 → {res[2]}到达,{res[3]},票价{res[4]}元\n"
return resultStr
def getAvailableHotel(queryDate: str, location: str) -> str:
"""查询可用的酒店
Args:
queryDate: 查询日期
location: 城市名称
Returns:
酒店信息字符串
"""
print(f"\n🏨 [工具调用] 查询酒店:{location},日期:{queryDate}")
# 模拟返回的酒店数据
result = [
["丽晶酒店", "五星级", "大床房", "1200"],
["丽晶大宾馆", "二星级", "标准间", "300"]
]
resultStr = f"您查询的 {queryDate} 在 {location} 可预定的酒店共 {len(result)} 家:\n"
for res in result:
resultStr += f" {res[0]}({res[1]}):{res[2]},{res[3]}元/晚\n"
return resultStr
# ==================== 创建Agent ====================
toolList = [getTrainSchedule, getAvailableHotel]
agent = create_agent(
model=ChatOllama(model="qwen2.5:7b"),
tools=toolList,
system_prompt="你是一位可靠的个人AI助理,擅长帮助用户规划旅行。"
)
# ==================== 执行 ====================
if __name__ == '__main__':
prompt = "我要在6月15日从北京到青岛旅游,请帮我安排一下车次和酒店。这次旅行要求尽可能舒适。"
print("=" * 60)
print(f"👤 用户:{prompt}")
print("=" * 60)
result = agent.invoke({"messages": [{"role": "user", "content": prompt}]})
print("\n" + "=" * 60)
print("🤖 智能体回复:")
print("=" * 60)
print(result["messages"][-1].content)六、最佳实践建议
是否需要使用框架?
| 场景 | 建议 |
|---|---|
| 简单LLM调用 | 直接使用大模型即可 |
| 少量业务逻辑 | 尽量不用框架,避免增加复杂度 |
| 复杂智能体 | 使用框架,从基础功能开始逐步增加 |
📌 核心原则:如无必要,勿增实体
六种构建块对比总结
| 构建块 | 核心模式 | 最佳应用场景 |
|---|---|---|
| 提示链 | 顺序处理 | 任务可清晰分解为多个步骤 |
| 分支 | 条件路由 | 输入类型多样,需专门处理 |
| 并行化 | 同时执行 | 多任务互不依赖,需要高效处理 |
| 计划-执行 | 分解+汇总 | 大规模任务,需协调多个Worker |
| 生成-评估 | 迭代优化 | 对输出质量要求高,可多次优化 |
| 智能体 | 自主决策 | 任务复杂,无法预定义流程 |
七、总结
本文系统介绍了基于LangGraph的智能体开发:
-
核心概念:理解了图、状态、节点、边和记忆的基本用法
-
流程控制:掌握了分支、循环、并行、人工介入和子图的实现方式
-
构建块:学习了六种智能体设计模式及其适用场景,并提供完整代码
-
实战能力:通过冲咖啡案例和完整代码示例具备了实际开发能力
LangGraph为我们提供了强大的工作流编排能力,但记住——简单、可组合的设计往往比复杂的框架更有效。
📚 延伸阅读:Building Effective Agents - Anthropic官方文章
🔗 参考资料:LangGraph官方文档 | LangSmith监控平台
本文为学习笔记,所有代码均已测试通过。欢迎在评论区交流讨论!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)