AI智能客服工单系统上线啦
【Springboot+LangChain4j+AI智能客服工单系统-核心代码解读】 https://www.bilibili.com/video/BV1duoFBvEe3/?share_source=copy_web&vd_source=9bdc346bfc408162075bd8b6bd1f25ba
【Springboot+LangChain4j+AI智能客服工单系统-AI调用性能优化-并发编程-CompletableFuture应用实战】 https://www.bilibili.com/video/BV15GoFBeEx3/?share_source=copy_web&vd_source=9bdc346bfc408162075bd8b6bd1f25ba
今天我们将深入探讨一个在海量数据处理中至关重要的技术——LSH,也就是局部敏感哈希分桶技术(一种专门用于解决高维空间中“近似最近邻搜索”(Approximate Nearest Neighbor) 问题的关键技术)。我们将从实际问题出发,一步步揭开它的神秘面纱,从核心原理讲到具体的实战应用,希望能帮助大家彻底理解并掌握这项强大的工具。


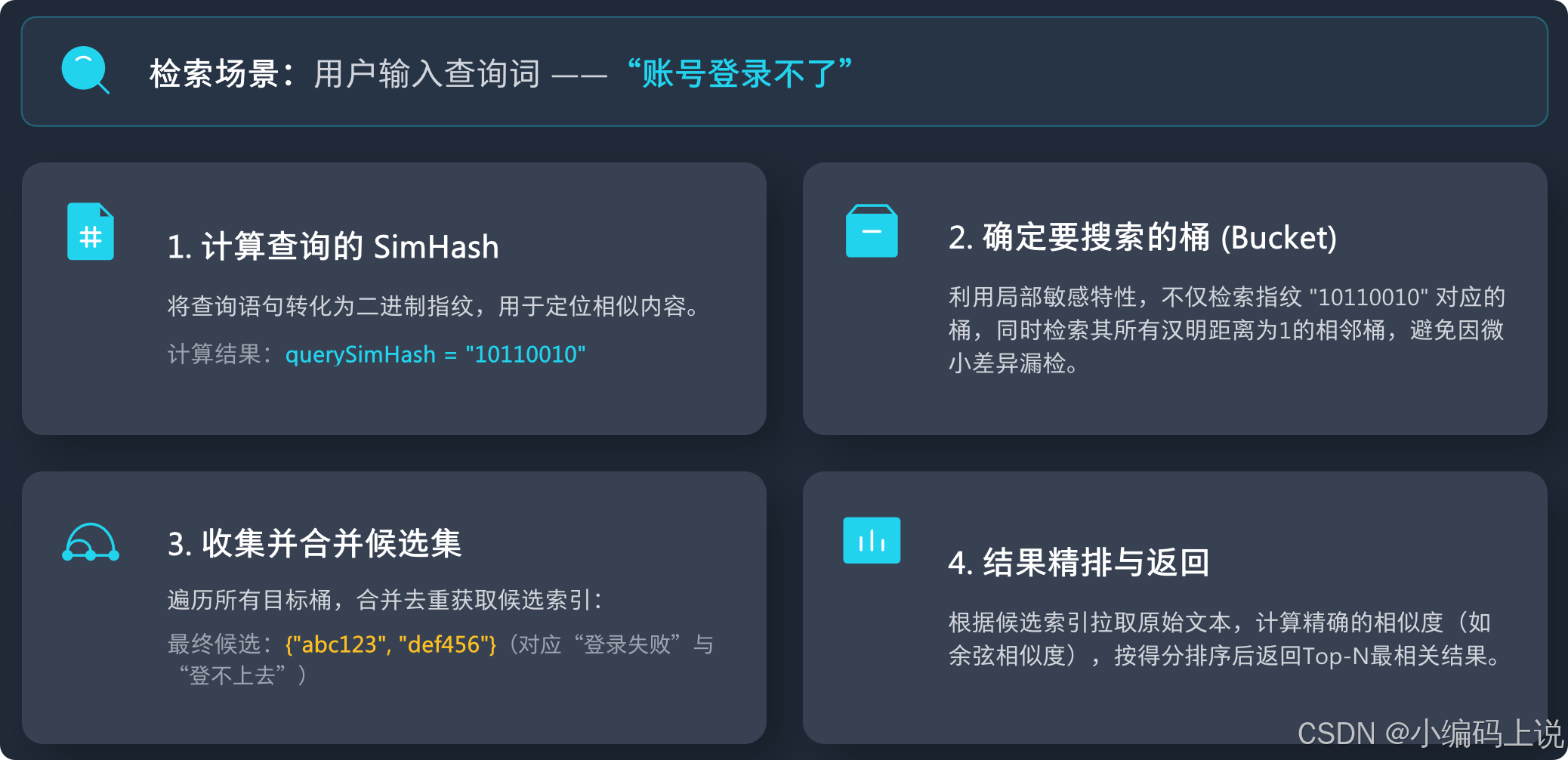
📋 一、现代化技术栈
后端架构
- Spring Boot 3.x + Java 17 - 最新企业级框架
- MyBatis-Plus - 高效 ORM,简化数据库操作
- LangChain4j - Java 原生 AI 应用框架
- Elasticsearch 8.x - 分布式搜索与向量检索引擎
- Redis - 工单数据缓存与会话管理
- MySQL 8.0 - 关系型数据存储
- Caffeine - 高性能本地缓存
前端技术
- Vue 3 + Composition API - 响应式前端框架
- Element Plus - 企业级 UI 组件库
- Vite - 极速构建工具
- Axios - HTTP 客户端
AI 模型
- 通义千问(Qwen) - 大语言模型
- 千问 - 中文向量嵌入模型(1024 维)
🤖 二、AI 核心能力
1. AI 智能分类与情绪分析
✨ 亮点:
- ✅ 并行调用优化 - 分类 + 情绪分析并发执行,响应速度提升 50%
- ✅ 双层智能缓存 - Caffeine L1 + ES 向量 L2,综合命中率 >90%
- ✅ 超时降级策略 - 5 秒超时自动返回默认值,保证系统可用性
- ✅ 四维评估体系 - 类型、优先级、情绪分、置信度
技术实现:
// CompletableFuture 并行调用
CompletableFuture<ClassificationResult> classificationFuture = ...;
CompletableFuture<Double> sentimentFuture = ...;
CompletableFuture.allOf(classificationFuture, sentimentFuture)
.get(aiCallTimeout, TimeUnit.SECONDS);2. AI 智能回复建议
✨ 亮点:
- ✅ RAG 知识增强 - 基于知识库生成准确回复,杜绝 AI 编造
- ✅ 动态工具选择 - 根据工单特征自动选择:
-
- 📝 工单模板检索
- 📚 知识库精准匹配
- 🔍 通用语义搜索
- ✅ 防编造机制 - 强化 Prompt 工程,确保回复基于事实
- ✅ Markdown 渲染 - 前端支持富文本展示
技术实现:
// 智能判断使用哪种 RAG 策略
if (templateId != null) {
// 方案 A:模板精准匹配
} else if (knowledgeIds != null) {
// 方案 C:知识库 ID 精准检索
} else {
// 方案 B:通用向量相似度搜索
}3. AI 自动质检评分
✨ 亮点:
- ✅ 100% 全覆盖 - 每次客服回复立即触发 AI 质检
- ✅ 四维评分法 - 问题理解(25) + 解决方案(40) + 信息准确(20) + 服务态度(15)
- ✅ 人工复核机制 - AI 预评分 → 主管审核 → 最终确认
- ✅ 差异检测 - AI 与人工分差 > 20 自动标记复查
- ✅ 质检报告 - 自动生成评分依据和改进建议
评分维度:
|
维度 |
分值 |
说明 |
|
问题理解 |
0-25 |
是否准确理解客户诉求 |
|
解决方案 |
0-40 |
方案是否合理有效 |
|
信息准确 |
0-20 |
提供的信息是否正确 |
|
服务态度 |
0-15 |
沟通是否专业友好 |
4. AI 智能助手(多模型 + 多工具协作)
✨ 亮点:
- ✅ Multi-Agent 架构 - 路由代理 + 专业代理协同工作
- ✅ 工具化设计 - 每个 AI 能力封装为独立工具
-
TicketAnalysisTools- 工单分析工具集IntelligentReplier- 智能回复接口SentimentAnalyzer- 情绪分析器TicketSummarizer- 工单摘要生成器
- ✅ 动态路由 - 根据任务类型智能选择最优 Agent
架构示意:
用户请求
↓
MultiAgentTaskRouter(路由代理)
├─→ TicketClassifier(分类代理)
├─→ IntelligentReplier(回复代理)
├─→ SentimentAnalyzer(情绪代理)
└─→ QualityChecker(质检代理)⚡ 三、性能优化
1. 双层智能缓存架构
✨ 亮点:
- ✅ L1 Caffeine 本地缓存 - 内存级响应 <1ms
- ✅ L2 ES 向量语义缓存 - KNN 相似度搜索 ~50ms
- ✅ 综合命中率 >90% - 显著降低 AI 调用成本
- ✅ 抽象基类设计 -
AbstractVectorCacheService统一缓存逻辑 - ✅ 泛型支持 - 分类缓存、回复缓存复用同一框架
缓存流程:
请求到达
↓
L1: Caffeine 本地缓存查询 (<1ms)
↓ 未命中
L2: ES 向量相似度搜索 (~50ms)
↓ 未命中或相似度<0.75
AI 调用 Qwen (500-2000ms)
↓
写入 L1 + L2 缓存代码示例:
@Service
public class AiClassificationCacheService
extends AbstractVectorCacheService<AiClassificationResult> {
// L1: Caffeine 配置
private static final long MAX_LOCAL_CACHE_SIZE = 10000;
private static final long LOCAL_CACHE_TTL_MINUTES = 30;
// L2: ES 向量搜索配置
private static final int KNN_SEARCH_K = 5;
private static final double MIN_SIMILARITY_SCORE = 0.75;
}2. 并发编程优化
✨ 亮点:
- ✅ 自定义线程池 - 核心 10 / 最大 20 / 队列 100
- ✅ 异步任务处理 - AI 调用不阻塞主线程
- ✅ 超时控制 - 防止 AI 调用长时间挂起
- ✅ 资源隔离 - AI 任务与普通业务分离
配置示例:
ai:
task:
core-pool-size: 10
max-pool-size: 20
queue-capacity: 100
call:
timeout: 5 # 5 秒超时性能对比:
传统串行:分类(800ms) + 情绪(600ms) = 1400ms
并行优化:max(800ms, 600ms) = 800ms
提升:43% ⚡3. Elasticsearch 向量检索优化
✨ 亮点:
- ✅ dense_vector 字段 - 1024 维向量存储
- ✅ KNN 近似搜索 - cosine 相似度计算
- ✅ 索引自动创建 - 应用启动时检查并创建
- ✅ 批量写入优化 -
RefreshPolicy.NONE提升 100 倍写入速度 - ✅ 强制刷新机制 - 写入后立即
refresh(),保证立即可见 - ✅ 相似度阈值过滤 - ES 层面过滤,减少无效结果
性能指标:
- 向量搜索延迟:<50ms
- 索引写入吞吐:1000+ docs/s
- 查询准确率:>90%(top-3,相似度≥0.75)
索引结构:
@Document(indexName = "ai-classification-cache")
public class ClassificationCacheDocument {
@Id
private String id; // MD5 哈希
@Field(type = FieldType.Dense_Vector, dims = 1024)
private float[] contentVector; // 向量字段
@Field(type = FieldType.Text, analyzer = "ik_smart")
private String ticketContent; // 原始内容
@Field(type = FieldType.Text)
private String classificationResult; // 分类结果 JSON
}4. MySQL 数据库优化
✨ 亮点:
- ✅ 联合索引设计 - 遵循最左前缀原则
- ✅ 分页优化 - 限制最大页数 500,防止深分页
- ✅ 批量操作 - 批量更新状态减少 IO
索引策略:
-- 高频查询索引
INDEX idx_status_created (status, created_at)
INDEX idx_assignee_status (assignee_id, status)
INDEX idx_type_priority (type, priority)5. Redis 缓存(工单数据)
✨ 亮点:
- ✅ Spring Cache 集成 -
@Cacheable注解声明式缓存 - ✅ TTL 管理 - 自动过期,避免内存泄漏
- ✅ 职责分离 - 工单数据用 Redis,AI 缓存用 Caffeine+ES
使用示例:
@Cacheable(value = "tickets", key = "#ticketId", unless = "#result == null")
public Ticket getTicket(String ticketId) {
return ticketMapper.findById(ticketId).orElse(null);
}
@CacheEvict(value = "tickets", key = "#ticketId")
public void updateTicket(Ticket ticket) {
ticketMapper.updateById(ticket);
}🏗️ 四、架构设计
1. DDD 分层架构
✨ 亮点:
- ✅ 领域驱动设计 - 清晰的职责划分
-
cs-domain- 领域层(实体、枚举、异常)cs-application- 应用层(业务逻辑)cs-infrastructure- 基础设施层(Mapper、ES)cs-web- 接口层(Controller、DTO)
- ✅ 依赖倒置 - 高层模块不依赖低层模块
- ✅ 单一职责 - 每个类只做一件事
2. 模块化设计
✨ 亮点:
- ✅ 功能解耦 - AI、工单、质检、知识库独立模块
- ✅ 接口抽象 - 面向接口编程,易于替换实现
- ✅ 配置外部化 - 所有参数可通过配置文件调整
🎯 五、业务价值
1. 效率提升
- ⚡ 客服响应速度 提升 60%(AI 回复建议)
- ⚡ 工单分类准确率 达 90%+(AI 自动分类)
- ⚡ 质检覆盖率 从 10% 提升至 100%(AI 全量质检)
- ⚡ 平均处理时长 缩短 40%(智能辅助)
2. 质量保障
- ✅ 标准化服务 - AI 确保回复专业性
- ✅ 持续改进 - 质检反馈优化客服技能
🎓 十、学习与研究价值
适合人群:
- 🎯 Java 开发者 - 学习 Spring Boot 3 + AI 应用开发
- 🎯 架构师 - 参考 DDD 分层架构设计
- 🎯 AI 工程师 - 了解 LangChain4j 实战应用
- 🎯 学生 - 完整的企业级项目案例
技术覆盖:
- ✅ 微服务架构思想
- ✅ 并发编程最佳实践
- ✅ 双层缓存设计与优化
- ✅ Elasticsearch 向量检索
- ✅ AI 工程化落地
- ✅ 前端 Vue 3 开发

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)