记录我的webgis项目(1):从零开始,构建电子地图网站 spring boot3 +vue3 + leaflet
(叠甲,我也是菜鸟,悉知我的功力还很浅薄,如果有哪里做的不行欢迎批评指正,大部分代码都是借助AI辅助编写的,可能会有些问题,遇到可留言指正)
Day 1:
一、从零做一个项目,我们先想我们的目标还有该怎么做
1、项目开发目标
本项目旨在从零搭建一款中文版中国历史地理电子地图网站,对标哈佛大学世界历史地理电子地图经典案例。(案例404了,就不放地址了)
2、产品界面与功能拆解
整体页面分为四大模块,采用循序渐进的开发模式逐步实现:
- 主地图区域:核心展示区,加载通用底图 + 历史点位、行政边线、行政区面、文字注记等地理要素;
- 左侧图层栏:提供图层选择开关,复选框控制历史覆盖物显隐,单选框切换多版本底图;
- 底部搜索模块:支持地名、行政编码检索,实现地图精准定位跳转;
- 顶部操作控件:集成图层添加、地图操作、项目介绍、功能设置等拓展控件。
3、开发规划
基于全新开发环境,从软件安装、数据处理、后端开发、前端搭建到部署上线,完整记录全流程实现过程。
1. 技术软件与技术栈
- 后端:TREA(老师用的IntelliJ IDEA) + Java + Spring Boot
- 数据处理:TREA(老师用的PyCharm )+ Python(GIS 数据清洗、格式转换)
- 前端开发:TREA(老师用的Sublime) + JavaScript + Vue 前后端分离架构
- 空间数据库:PostgreSQL + PostGIS(存储历史地理矢量数据)
- 地理可视化:QGIS(shp 数据查看、图层编辑、数据预处理)
- 运行调试:Chrome 谷歌浏览器
2. GIS 数据获取与入库
采用哈佛 CHGIS 官方开源历史地理数据集,作为项目核心数据源:
- 数据来源:China Historical GIS 公开数据集
- 下载地址:https://chgis.fas.harvard.edu/CHGIShttps://chgis.fas.harvard.edu/
- 核心数据:CHGIS V6 时间序列历史地理矢量数据
- 处理流程:下载 shp 格式原始数据 → 数据清洗、编码统一 → 通过 PostGIS 导入数据库,为后端查询提供数据支撑。
3. 项目开发流程
- 环境搭建:全开发软件、数据库、运行环境安装配置;
- 数据层:历史 GIS 数据处理、入库、空间字段适配;
- 服务端:基于 Spring Boot 快速搭建 Web 后端,编写数据查询、空间要素接口;
- 可视化:Vue 搭建前端页面,结合地图开源组件,实现历史地理数据渲染;
- 项目部署:依托阿里云 / 腾讯云服务器,完成项目打包与线上发布;
- 迭代测试:采用阶段性测试,每完成一个模块功能,即时调试排错,保障项目稳定迭代。
二、软件安装
主要讲一下gis相关软件,其他软件安装教程挺多的,也可以问一下AI
1、PostgreSQL + postgis
安装地址:EDB: Open-Source, Enterprise Postgres Database Management
安装之后会让设置密码和端口,端口默认的5432就行
postgis可以用Stack builder下载,但是不知道为啥我会一下载就卡死,这里推荐找安装程序直接下
下载地址:Index of /postgis/windows/pg18/
点开安装程序,一路next
创建空间数据库可选可不选,然后一路next
三、处理数据
1、查看数据
我们下好的数据长这样
可以先用QGIS查看一下数据
就是看看数据这个是选做步骤
2、连接数据库
1、连接数据库
使用Navicat连接pg库 参考:参考
用navicat打开数据库postgres,就是初始化的数据库。
新建查询,执行CREATE EXTENSION postgis,为数据库添加空间扩展。
会发现数据库中多了一个表spatial_ref_sys。
2、postgis处理数据
用PostGIS Shapefile Import/Export Manager工具上传shp。(我们后续会用python处理数据,因为postgis没有索引之类的还会压缩名字)
我们把utf8编码格式、wgs84坐标系的文件上传数据库,因为数据库一般都是utf-8编码的。
v6_time_cnty_pts_utf_wgs84.shp
v6_time_pref_pts_utf_wgs84.shp
v6_time_pref_pgn_utf_wgs84.shp
首先打开PostGIS Shapefile Import/Export Manager,点击View connection details,打开PostGIS connection,输入账号密码,连接数据库。
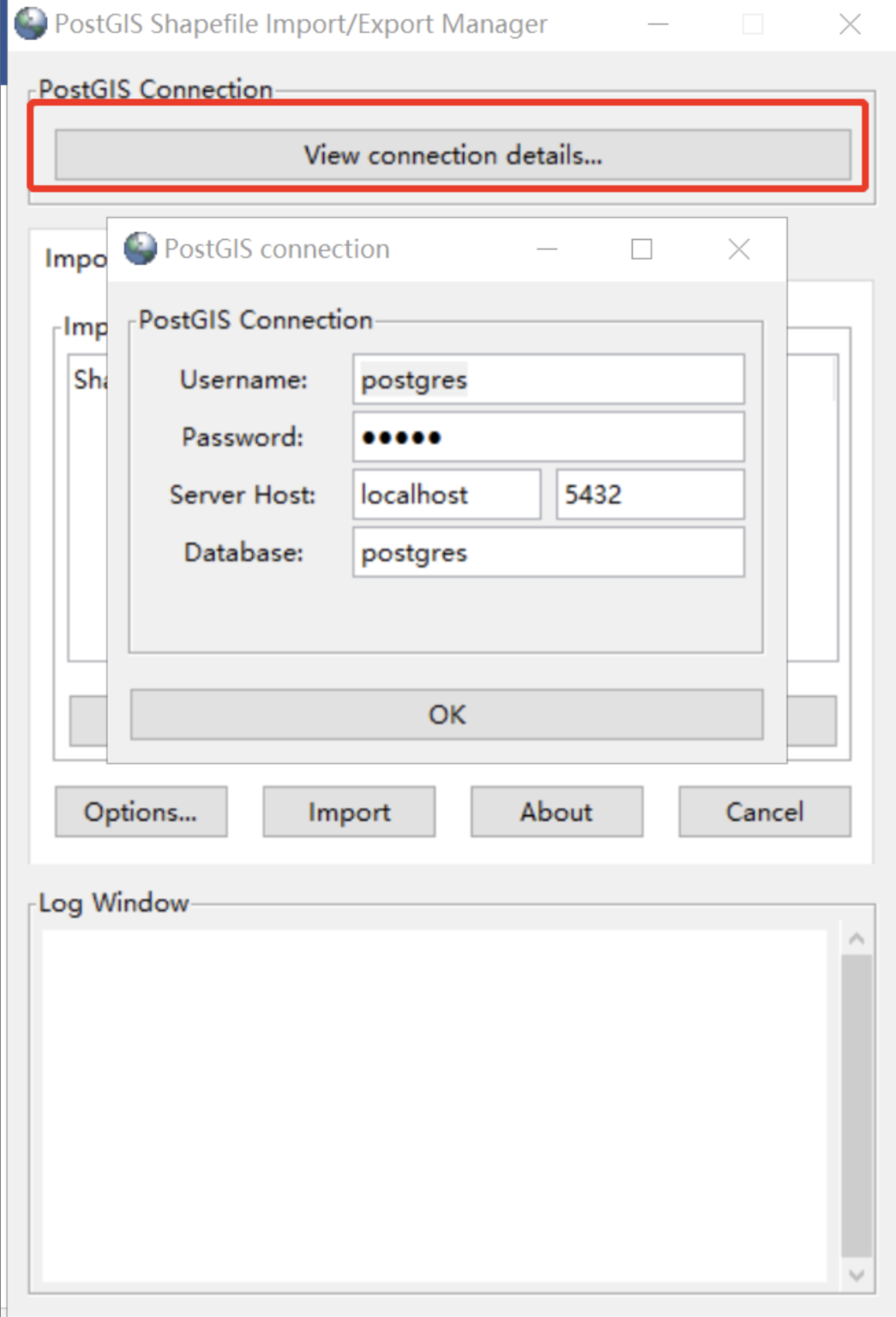
Import——Add File,选择3个shp文件,然后点击Import。数据就导入pg库了。
然后Navicat打开一个表,看geom列,都是这样的内容:0101000000A265DD3F16C55B4088963C9E96814340,geometry对象是geohash编码的。
写个sql看看:SELECT st_astext(geom) FROM v6_time_cnty_pts_utf_wgs84 LIMIT 1
至少知道坐标了:POINT(111.079483 39.012409)
其他表再看看。
SELECT st_astext(geom) FROM v6_time_pref_pgn_utf_wgs84 LIMIT 1
MULTIPOLYGON(((113.549411712145 36.7545434898289,113.543285553768 36.7521524539279,113.560044728209 36.7134634435762,113.55651873219 36.7287158304727,113.552914744172 36.7456842597138,113.549411712145 36.7545434898289)))
3、python处理数据
1、环境搭建
1.安装gdal
直接安会有问题,先去下个安装程序,https://www.lfd.uci.edu/~gohlke/pythonlibs/#gdalReleases · cgohlke/geospatial-wheelshttps://www.lfd.uci.edu/~gohlke/pythonlibs/#gdal
如果不知道python的版本,可以打开cmd,输入python,回车。
根据python的版本选择程序。
然后pip install(文件位置)GDAL-3.0.1-cp37-cp37m-win32.whl(你的下的文件)
2,3、shapely、psycopg2下载
直接pip install就行
2、处理数据
首先确定电脑的编码。
打开cmd,输入chcp,我的电脑返回“活动代码页:936”,这说明我的电脑默认编码格式是gbk的。
以下代码是读shp文件,返回一个list的方法,再把list写入一个文本文档的方法。第二个是以处理出的text文件(处理出的文本文档)写入pgsql。
# coding=gbk
try:
from osgeo import gdal
from osgeo import ogr
except ImportError:
import gdal
import ogr
# pathStr,shp文件的全路径
def ReadVectorFile(pathStr):
# 返回结果是一个list
result=[]
# 支持中文路径
gdal.SetConfigOption("GDAL_FILENAME_IS_UTF8", "NO")
# 属性表字段支持中文
gdal.SetConfigOption("SHAPE_ENCODING", "")
strVectorFile = pathStr
# 注册所有的驱动
ogr.RegisterAll()
# 打开数据
ds = ogr.Open(strVectorFile, 0)
# 获取该数据源中的图层个数,一般shp数据图层只有一个,如果是mdb、dxf等图层就会有多个
iLayerCount = ds.GetLayerCount()
# 获取第一个图层
oLayer = ds.GetLayerByIndex(0)
# 对图层进行初始化
oLayer.ResetReading()
# 获取图层中的属性表表头并输出,可以定义建表语句
print("属性表结构信息:")
oDefn = oLayer.GetLayerDefn()
iFieldCount = oDefn.GetFieldCount()
for iAttr in range(iFieldCount):
oField = oDefn.GetFieldDefn(iAttr)
print("%s: %s(%d.%d)" % ( \
\
oField.GetNameRef(), \
\
oField.GetFieldTypeName(oField.GetType()), \
\
oField.GetWidth(), \
\
oField.GetPrecision()))
# 输出图层中的要素个数
print("要素个数 = ", oLayer.GetFeatureCount(0))
oFeature = oLayer.GetNextFeature()
# 下面开始遍历图层中的要素,将对象都作为string输出
while oFeature is not None:
# 获取要素中的属性表内容
lineStr=[]
for iField in range(iFieldCount):
lineStr.append(oFeature.GetFieldAsString(iField))
# 获取要素中的几何体
oGeometry = oFeature.GetGeometryRef()
lineStr.append(str(oGeometry))
# print(lineStr)
result.append(lineStr)
# 循环
oFeature = oLayer.GetNextFeature()
print("数据集关闭!")
return result
if __name__ == '__main__':
result=ReadVectorFile(r'D:\gismap\data\v6_time_cnty_pts_utf_wgs84\v6_time_cnty_pts_utf_wgs84.shp')
f_new=open(r'D:\gismap\data\v6_time_cnty_pts_utf_wgs84\v6_time_cnty_pts_utf_wgs84.txt','a',encoding='utf-8')
for r in result:
for p in r:
f_new.write(p+'\t')
f_new.write('\n')
f_new.close()--建表
CREATE TABLE public. v6_time_cnty_pts_utf_wgs84(
gid SERIAL8 PRIMARY KEY NOT NULL,
name_py varchar(40),
name_ch varchar(45),
name_ft varchar(45),
x_coor float8,
y_coor float8,
pres_loc varchar(60),
type_py varchar(15),
type_ch varchar(15),
lev_rank varchar(1),
beg_yr int8,
beg_rule varchar(1),
end_yr int8,
end_rule varchar(1),
note_id int8,
obj_type varchar(7),
sys_id int8,
geo_src varchar(10),
compiler varchar(12),
gecomplr varchar(10),
checker varchar(10),
ent_date varchar(10),
beg_chg_ty varchar(21),
end_chg_ty varchar(30),
geom geometry
);
--建立索引
CREATE INDEX v6_time_cnty_pts_utf_wgs84_index ON v6_time_cnty_pts_utf_wgs84 USING btree(gid);
--表说明
COMMENT ON TABLE public.v6_time_cnty_pts_utf_wgs84 IS '第6版中国历史地理时间序列点数据';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.gid IS '主键ID';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.name_py IS '拼音名称';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.name_ch IS '简体中文名称';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.name_ft IS '繁体中文名称';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.x_coor IS '经度';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.y_coor IS '纬度';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.pres_loc IS '现所在地';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.type_py IS '建制类型拼音';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.type_ch IS '建制类型简体中文';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.lev_rank IS '建制等级';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.beg_yr IS '建制开始时间';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.beg_rule IS '开始时间精度';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.end_yr IS '建制结束时间';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.end_rule IS '结束时间精度';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.note_id IS '系统id';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.obj_type IS 'geometry对象类型';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.sys_id IS '系统id';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.geo_src IS 'geometry数据来源';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.compiler IS '编辑人员';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.gecomplr IS '绘制人员';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.checker IS '审核人员';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.ent_date IS '结束时间';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.beg_chg_ty IS '建制开始原因';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.end_chg_ty IS '建制结束原因';
COMMENT ON COLUMN public.v6_time_cnty_pts_utf_wgs84.geom IS 'geometry对象';照着这个思路一共写六个,大家可以直接用大佬写过的 地址:yimengyao13/historygismappython: python脚本
只需要改一下文件地址和数据库密码
(编码出现问题的可以问一下ai)
OK,今天就到这了,主要就是配了一些环境,处理一些数据,下篇开始配置后端环境,进行后端搭建,大家心急的可以先看大佬的教程,我们下篇见,拜拜!
该项目并非原创(侵权了私聊删QAQ),而是翻新一个知乎上的大佬的spring boot 2 + vue 2 的项目, 项目教程:知乎的才华横溢吴道简 大佬的教程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)