《从入门到实战:大模型与智能体开发全栈指南》
一、大模型介绍
1.大模型的核心定义
(1) 大模型本质上是一个强大的数学函数,通过神经网络构建,旨在解决通用问题。
大模型 = 超大参数神经网络 + 海量数据训练
通过预测下一个词,靠预训练、微调、对齐变强大。
💫大语言模型(LLM)
本质:超大规模语言模型,核心是根据上文预测下一个词 / Token。
流程:文本编码 → Transformer 计算 → 输出词概率 → 生成句子。
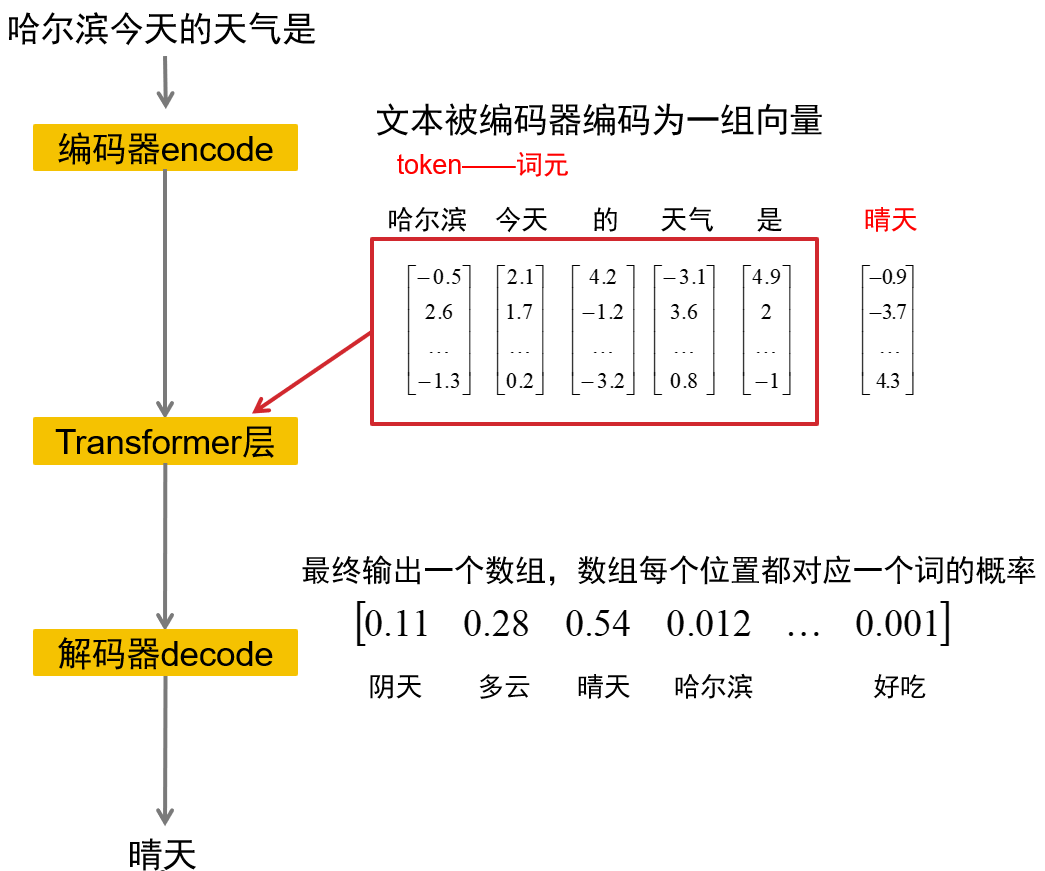
Token:模型处理文字的最小单位,对应词表中的编号。
(2) 技术本质:
是一个数学函数f和参数θ的组合,f:描述计算方法, θ:参与计算的参数(模型权重)
给一个输入数据x,得到一个输出结果y,y= f(x,θ)
- 推理:用训练好的模型算结果。
- 训练:用数据拟合、调整参数 θ,让模型更准。
💫机器学习:把θ从f中分离出来,可以专注θ的优化或者学习
定义好f之后,随机初始化θ
利用训练数据不断优化θ
💫神经网络
由输入层、隐藏层、输出层组成。
不用人工假设函数形式,可拟合任意复杂规律,是大模型的基础。
(3)“大”的含义: 指模型参数的总数量巨大,通常在10亿级别以上。
(4) 大模型的f :采用深度学习中的 Transformer 架构,拥有庞大的神经网络结构,该器件具备极强的复杂度和学习能力。
(5) 开发者视角:对程序员而言,大模型核心就是一个功能强大的HTTP API。
2.大模型训练三步曲
a.预训练(通识教育)
用海量无标注文本(百科、新闻、代码等)学习语言、推理、常识、事实知识
模型知识广,但不专业、易 “胡说”
b.微调(专业教育)
用高质量问答数据,让模型擅长特定任务
分全量微调(效果好、成本高)和轻量微调 LoRA(主流、高效)
c.对齐(守规矩)
让模型安全、有用、符合人类价值观
方式:RLHF 人类反馈打分、红队测试(找漏洞、教拒答)
3.资源获取
(1)国内:阿里 (Qwen)、字节 (豆包)、腾讯 (混元)、智普 (GLM)、月之暗面 (Kimi)、稀宇科技 (Minimax)、华为 (盘古)、百度 (文心) 等。
(2)国外:GPT(openai)、Gemini(google)、Claude(Anthropic)、Llama(亚马逊) 等。
(3)模型分类:
按模态:文本、多模态、语音、计算机视觉;
按参数规模:小 / 中 / 大 / 超大型模型。
(4)选型思路
性价比 = 任务成功率 × 响应速度 / 成本 + 维护 + 风险,不只看单价
(5)对开发者来说就是使用大模型API服务(针对文本、图像、音频、视频、代码等可以分别调用对应专项处理大模型的API去针对每一类使用)
使用流程:
在对应的官网云平台登录→开放平台 → 创建 API Key( 用于身份验证 + 计费,严禁泄露)→ 配置 base_url 和 api_key,用 Python/Java 调用
阿里云百炼https://bailian.console.aliyun.com/cn-beijing/?tab=model#/model-market/all
火山方舟大模型服务平台(字节)https://www.volcengine.com/docs/82379/1330310?lang=zh
硅基流动https://www.siliconflow.cn/models/
Hugging Facehttps://huggingface.co/model
魔搭社区(ModelScope)(阿里巴巴达摩院)https://modelscope.cn/models
核心API调用类型:
(1)文本输入(基础对话)
messages包含system设定 AI 身份(助手 / 翻译 / 老师)/user/assistant模型回复 三角色
例:阿里千问系列qwen-plus/qwen-max
(2)流式输入(边生成边输出)
关键参数:stream=True、stream_options={"include_usage": True}
遍历 chunk,逐段拼接 / 打印
(3)图像输入(视觉理解)
支持:在线 URL / 本地图片(Base64 编码)
例:qwen-vl-plus、qwen3.5-plus
(4)视频输入(输入格式是视频文件/图像序列)
通过Base64 编码或文件路径传入,需要依赖DashScope SDK ≥1.24.6
💫SDK(软件开发工具包)
一个完整的SDK通常包含多种资源的组合,旨在帮助处理从开发到测试的各个层面:
API(应用程序编程接口):是SDK的核心部分,允许你的代码与目标平台(如AWS、iOS、Android)进行“对话”。
代码库(Libraries):预先写好的代码片段,你可以直接调用来实现特定功能(例如加密、网络请求、图像处理等),而不需要自己重新造轮子。
开发文档:这是“说明书”,详细解释了如何使用 SDK 中的各个功能。
示例代码:提供一些简单的模板,让你能够快速上手。
调试和开发工具:包括编译器、调试器、模拟器等,用于辅助测试和优化你的应用。
(5)联网搜索
需要开启extra_body={"enable_search": True}
例:qwen-plus(支持实时检索)
(6)异步调用(长文本 / 复杂任务,减少等待)
实现 async/await + asyncio,适配 Windows:设置事件循环策略
(7)文档理解
上传文件→获取 file_id→放入 system prompt→提问总结
例:qwen-long
💫推荐一个vscode好用的插件continue,装好插件后,win+R输入%userprofile%\.continue,如果没有就新建一个config.json(这里推荐json格式,但.yaml去配置也是ok,不同后缀的文件写配置格式都不同,这里演示.json配置格式
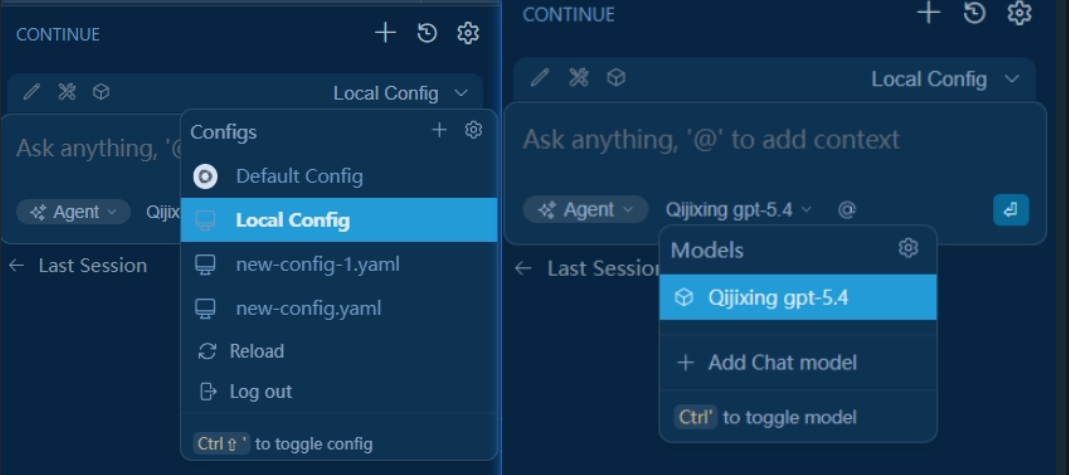
配置完点击Reload刷新或重新进入vscode就可以看到刚刚配置好的模型
类似这样好用的Agent插件,还推荐GitHub Copilot (相当于付费订阅套餐,能够使用当下流行的大模型),像claude系列Opus4.7、gpt5.4等
4.大模型的应用场景
大模型已展现出跨行业的应用潜力,能处理多项任务,如问答、翻译、代码编写、图片生成与处理、文献阅读等。
二、智能体
多模态
(1)定义:能同时处理文本、图片、音频、视频等多种信息。
(2)应用:图文理解、音乐生成、视频生成(Sora、Seedance、可灵 AI)。
(3)特点:像人一样 “看、听、说、理解”,但目前在细节(如手指数量)上仍易出错。
Agent& Subagent
趋势:从 “问答 AI” 走向能自主办事的 Agent,是程序员和普通人的超级工具。
(1)定义:LLM + 工具调用(搜索、代码、浏览器、插件),自主完成复杂任务。
(2)能力:自动查信息、写代码、做报表、处理订单、修 Bug。
(3)本质:会思考 + 调用工具 + 执行的 AI 助手。
为什么需要 Subagent
1.原有 Agent 工具调用会把支线执行记录混入主线对话,导致上下文混乱、精度下降。
Subagent 思路:任务拆分 + 上下文隔离,像函数调用一样独立执行、执行完销毁上下文。
2.版本演进
v0:基础子代理,任务派发给子 Agent,隔离对话历史
v1:拆分为 ParentAgent + ChildAgent 独立类
v2:按任务类型分发(日常 / 数学 / 文件 / 命令),专用子 Agent 处理专用任务
v3:抽象 BaseAgent 父类,统一结构
v4:接入 MCP 远程工具(天气、快递等)
3.最终架构
主 Agent:理解意图 → 拆解任务 → 分发子 Agent
子 Agent:执行具体工具 → 返回结果
优势:干净、稳定、可扩展、易维护
💫推荐开源项目
learn-claude-code:12 步从零实现 Agent + Subagent,是业界标准学习案例。
智能体设计模式
1.核心思想:Harness Engineering(驾驭工程)
把大模型比作 “烈马”,用架构、规则、反馈控制它,稳定、安全、可复现。
2. 四大设计模式
反思:先生成草稿 → 再评估 / 纠错 → 优化输出(翻译、写作、代码都适用)
工具使用:调用能力外挂:计算、命令、文件、MCP、数据库。
规划:复杂任务自动拆解为有序子任务,生成可执行 Prompt,按步骤执行
多智能体协同:主管 Agent + 多个专业 Agent 分工协作,类似团队作业
3.常用框架
LangGraph、CrewAI、Google ADK
💫LangChain vs LangGraph
LangChain
帮你快速搭 LLM 应用:
调模型、写 Prompt
做 RAG(文档加载→切片→向量库→检索)
简单工具调用、基础记忆
一句话组合出聊天 / 总结 / 翻译机器人
LangGraph
解决 LangChain Chain 做不了的复杂智能体:
能循环思考(思考→行动→观察→反思)
能分支决策(满足条件才走某步)
能多 Agent 分工(主 Agent+SubAgent)
能断点恢复、人工审核、持久化记忆
适合做真正能干活的 Agent 系统
SKILL
1.SKILL 是什么
一套标准化能力包:
SKILL.md:任务规则、命令格式、示例
scripts/:可执行脚本(py/sh)
统一用 命令行 exec_cmd 调用,扩展无需改代码
2.为什么需要SKILL
原生工具调用不稳定:匹配不准、流程不确定、难以扩展。
SKILL = 把固定任务流程固化,让 Agent 稳定复现。
3.优势
统一入口:所有能力都走命令行,无限扩展
稳定复用:任务流程固化,不会乱调用工具
可分享:像插件一样安装、共享、使用别人的 SKILL
4.运行方式
Agent 加载 SKILL → 解析指令 → 执行命令行脚本 → 返回结果
5.举例
https://github.com/JinGuYuan/jinguyuan-dumpling-skill
三、Prompt:为Agent提供提示词的模板
1.使用Prompt的2种目的
(1)获得questions具体的results
(2)固化一套Prompt到程序中【基于公司知识库问答】
2.如何对Prompt进行调优(投其所好)
举例:openAI Gpt对markdown格式友好,claude对xml友好
高质量的Prompt具备:具体、丰富、少歧义
(1)一般由角色 指示 上下文(背景) 例子(one_shot learning/few_shot learning /context learning) 输入 输出
(2)优化思路
a.明确任务和角色
定义输入输出,输出格式(json、markdown等)、风格、长度限制等
b.给例子(像情感分析类的大模型要给正反两类)
c.分解复杂任务(一步步思考)
d.设定边界 (在接入RAG向量检索生成库后)
e.进行评估优化,构建输入输出(优质测试用例),定义评估指标,A/B测试(对照+实验组)
四、RAG(Retrieval-Augmented Generation)检索增强生成
RAG 要解决什么问题
大模型天生 3 个短板:
- 知识过时:训练数据截止到过去,不知道最新政策、校内信息
- 没有私有知识:无法回答企业文档、个人笔记、专业资料
- 容易幻觉:没见过的内容会一本正经瞎编
RAG = 给大模型装知识外挂,让它先查资料再回答。
RAG 基本概念
1.先从外部知识库检索相关内容,再把资料给大模型生成准确答案

2.核心优势
时效性强:随时更新知识库
准确性高:基于原文回答,几乎不幻觉
成本低:不用重新训练模型(对比微调)
💫RAG vs 微调
微调:闭卷考试,把知识灌进模型,难更新、成本高
RAG:开卷考试,现场翻书查资料,随时更新、更稳定
3.RAG 标准工作流程
a.多源知识汇聚 + 语义切片收集文档 → 清洗 → 按语义切分成小片段
b.向量嵌入 + 入库用 Embedding 模型把文本转成向量 → 存入向量数据库
c.精准语义召回用户提问 → 向量化 → 检索最相似片段
d.上下文重构 + 生成答案把检索片段拼进 Prompt → 大模型按资料回答
4.关键技术细节
a.文档切片
太碎:语义断裂、拼不出完整答案
太厚:噪声大、关键信息淹没
推荐:递归切片(先按章节 / 段落,再细分,带重叠)
b.向量嵌入
把文字变成一串数字,语义相近 → 向量距离近
首选:BGE-M3(中文强、免费开源)
相似度计算:用余弦相似度
c. 向量数据库
学习 / 小项目:Chroma、FAISS(轻量免费)
企业项目:Milvus、PostgreSQL+pgvector
d.检索优化
TopK:召回 3~5 条最相关片段
相似度阈值:低于阈值拒答,避免乱答
混合检索:向量检索 + BM25 关键词检索
Rerank 精排:让结果更准
5.Python 实现 RAG
ingest.py:文档读取 → 切片 → 向量化 → 存入 Chroma
medical_mcp_server.py:提供 MCP 检索工具
client.py:调用 MCP → 检索知识 → 传给大模型生成答案
强规则:没查到就拒答,不瞎编
6.Java 实现 RAG(基于 spring-ai-alibaba)
引入 POM 依赖→加载文档(MD/PDF)→文档切片→文本向量化→存入向量库→检索 + 问答
五、实操
大模型构造聊天系统 (简洁回答 + 历史存档)
1.聊天系统核心特点
多轮交互,角色化对话,话题聚焦,可打断可扩展支持图文表情工具调用等
2.实现时注意
(1)原生 API 是无状态的,不会保存历史,一问一答会丢失上下文,我们可 手动维护 messages 数组,每轮把用户提问与 AI 回答追加进去,一起传给大模型。
💫关键代码逻辑
初始化messages,包含system角色
循环接收用户输入
追加user消息 → 调用 API → 获取回答
追加assistant消息 → 实现多轮记忆
输入exit退出循环 </aside>
(2)修改system prompt→控制回答长度→角色化定制(可外部化配置)
💫角色化定制
把system prompt写到独立 .md 文件(如translator.md、news.md)
代码加载 md 文件内容作为系统提示
运行时传入 md 路径,一键切换角色,无需改代码 </aside>
大模型调用工具
大模型为什么需要工具调用
1.天生缺陷:
无实时感知能力:不知道当前时间、最新新闻、实时数据
无精准计算能力:复杂数学、排序、大数运算易出错
无操作执行能力:不能读写文件、执行命令、操作数据库
无外部交互能力:不能调用 API、控制设备、访问系统
2.调用的核心思想(大模型做决策 + 代码做执行)
让大模型决定什么时候用、用哪个工具,代码负责真正执行,弥补能力短板。
MCP协议
1.核心概念(Model Context Protocol)
作用:AI 模型与外部工具 / 数据的标准化通信协议
形态:基于 HTTP 的远程工具调用服务
2.为什么用MCP
解决工具重复开发、维护难、无法复用问题
工具集中部署在服务器,客户端只需调用
实现创建与使用分离,像 USB 接口即插即用
3.快速开发MCP
安装:pip install fastmcp
服务端:用@mcp.tool装饰器定义工具
客户端:异步连接、调用远程工具
可部署在 Linux/Windows/ 云服务器
4.MCP 两种传输协议
Streamable HTTP:接口以/mcp结尾
SSE:接口以/sse结尾,适合长连接、流式返回
5.第三方MCP服务使用
魔搭社区 MCP 广场:网页抓取、必应搜索、天气、12306
阿里云百炼 MCP 广场:快递查询、图文生成、地图、文档处理
使用方式:
(1)选择支持 SSE/Streamable HTTP 的服务
(2)获取远程 URL
(3)客户端配置 URL 与鉴权(API Key)
(4)大模型自动发现并调用远程工具
💫多 MCP 聚合
用Responses API一次性接入多个 MCP 服务,自动级联完成复杂任务(如查天气 + 查高铁 + 订车票)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)