2026年程序员必用的6种AI大模型
一、2026年进入“神仙打架”模式
在开始之前,我们先花30秒看懂当前格局。
下面这张图展示了六大模型的“血统”和擅长的领域:

划重点:2026年3月的AI编程战场,已经不是“谁更便宜”的初级较量,而是进入了“长上下文、Agent能力、多模态理解”的硬核肉搏战。
资源分享
我整理了大模型和人工智能入门到实战的资料和学习路线以及面试题

要的小伙伴可以按照这个图的方式免费获取
二、Claude Opus 4.6 / Sonnet 4.6:AI编程的天花板再次被捅破
有些小伙伴可能还在用Claude 3.5 Sonnet写代码,觉得已经很爽了。
但3月中旬Anthropic的这一波更新,直接把编程助手的能力拉到了另一个次元。
2.1 王炸更新:100万Token上下文,统一价格
2026年3月13日,Anthropic干了一件大事——Claude Opus 4.6和Sonnet 4.6的100万Token上下文窗口,正式全面上线,并且是统一价格,零溢价!
100万Token是什么概念?大约相当于750万个英文单词,或者一整套《哈利·波特》系列的7倍。
更重要的是,Anthropic这次没有搞价格歧视——90万Token的请求和9000 Token的请求,每个Token价格一模一样。
此前Beta阶段,超过20万Token的请求输入价格翻倍、输出乘以1.5倍。现在这个门槛彻底没了,长上下文从奢侈品变成了标配。
2.2 多模态能力翻6倍
除了文本长度,Claude这次还扩展了多模态输入能力——单次请求最多支持600张图片或600页PDF。
相比之前的100个媒体文件,直接提升了6倍。一份长达数百页的合同扫描件、一整套设计系统的截图,现在可以一次性塞进去。
2.3 实测数据:大海捞针能力第一
在专门考验超长文本“大海捞针”能力的MRCR v2测试中,Opus 4.6拿到了78.3%的高分,同等上下文长度的前沿大模型中排名第一。
这意味着模型可以在海量上下文中找到关键细节,正确关联信息,从而进行复杂推理。作为对比,上一代的Sonnet 4.5在同一个测试中只拿到了18.5%。
2.4 开发者体验:取消Beta Header
还有一个很受开发者欢迎的更新——超过20万Token的请求自动生效,不再需要添加anthropic-beta: 1m-context这个Beta请求头。
如果代码里仍然保留旧的Beta Header,系统会自动忽略,不需要修改代码。
这一点看似小改动,但对于开发者来说非常重要——因为它意味着百万上下文已经从“实验功能”变成了默认能力!
2.5 缺点:价格依然是硬伤
不过,Opus 4.6的价格依然是目前最贵的。
1百万Token的输入、输出价格分别是5美元、25美元,Sonnet 4.6分别是3美元、15美元。
这样的价格很多程序员都觉得肉疼,写代码也不敢全部使用这两个模型,要搭配其他廉价模型一起用。
2.6 适用场景
-
复杂系统设计:一次性读完整套代码库做架构分析
-
Agent式编程:配合Claude Code做多步自动化开发
-
长文档处理:分析数百页的技术文档或合同
一句话总结:编程能力天花板,贵得有道理。如果追求代码质量极致,预算充足,Claude Opus 4.6是当之无愧的首选。
三、GPT-5.4:OpenAI的“全能战士”正式登场
就在Claude升级的几天前,OpenAI在3月5日发布了GPT-5.4。
这次更新有一个极其炸裂的新能力——原生电脑操控。
3.1 首次引入:原生电脑操控能力
GPT-5.4最大亮点之一是OpenAI首次在通用模型中引入原生电脑操控能力。
模型不仅可以生成文本或代码,还能根据屏幕截图直接操作电脑软件、浏览网页,并通过控制鼠标和键盘完成任务,同时还可与电子表格、金融分析工具等企业应用进行深度整合。
在计算机操控基准测试OSWorld-Verified中,GPT-5.4取得了**75.0%的任务成功率,超过人类平均水平72.4%**,相较GPT-5.2的47.3%实现了大幅提升。
3.2 极限推理与100万上下文
GPT-5.4带来了两个版本:
-
GPT-5.4 Thinking:更擅长复杂推理任务,面向付费用户
-
GPT-5.4 Pro:性能更强,面向企业高端需求
在API中,GPT-5.4支持最高100万Token的上下文窗口,是OpenAI迄今提供的最大上下文容量。
3.3 编程效率提升
编程能力方面,在Codex开启快速模式后,GPT-5.4的Token生成速度可提升约1.5倍,大幅提高代码编写和调试效率。有测试者报告,甚至一次提示可生成6000+行代码!
3.4 价格体系
API接口中GPT-5.4的定价较GPT-5.2略有上涨:每百万输入Token为2.5美元,输出Token为15美元。
至于更高性能的GPT-5.4 Pro,每百万输入Token价格为30美元,输出价格为180美元——这基本是给企业级客户准备的。
3.5 适用场景
-
自动化办公:让AI帮你操作Excel、PPT
-
Agent式任务:多步骤的复杂业务流程自动化
-
大规模代码生成:需要一次性输出数千行代码的场景
一句话总结:OpenAI的野心不止于聊天,它想让AI真正“替你干活”。如果你需要AI不仅能写代码,还能操作软件,GPT-5.4是唯一选择。
四、Gemini 3.1 Pro:谷歌的“推理之王”低调反超
就在2月20日,谷歌推出了Gemini 3.1 Pro。虽然宣传没有OpenAI和Anthropic那么高调,但实力不容小觑。
4.1 核心提升:推理能力翻倍
Gemini 3.1 Pro最大的提升是推理能力。
在评估模型处理全新逻辑模式能力的ARC-AGI-2基准测试中,Gemini 3.1 Pro取得77.1%的实测得分,推理性能达到上一代Gemini 3 Pro的两倍以上。
在科学知识、代码开发、多模态理解推理、长上下文处理等多个维度的测试中,也均展现出优异表现。
4.2 编码实战能力
Gemini 3.1 Pro在Terminal-Bench Hard和SciCode等编码基准测试中均取得显著提升。
谷歌还展示了实用性案例——仅通过文本提示生成可用于网站的动画SVG,由于是用代码而非视频生成,文件体积保持很小且画质清晰。
4.3 幻觉率降低
Google表示,与之前的预览版本相比,幻觉率已显著降低,这对需要高可靠性的编程场景尤为重要。
4.4 适用场景
-
数学/科研推理:复杂公式推导、科学计算
-
多模态理解:同时处理文本、图像、视频的分析任务
-
前端可视化:生成SVG动画、图表等
一句话总结:谷歌在“思考”这件事上下了苦功。如果你需要模型进行深度逻辑推理,Gemini 3.1 Pro值得一试。
五、DeepSeek:中国开源力量的双线出击
国产模型这边,DeepSeek(深度求索)绝对是2026年最值得关注的选手。
5.1 DeepSeek V4:架构重构,万众期待
如果说2025年是DeepSeek的破圈之年,2026年就是它的登顶之年。
1月底,DeepSeek在GitHub代码库中意外曝光了代号为“MODEL1”的全新模型线索。
综合泄露代码片段来看,“MODEL1”似乎绝非简单的版本迭代,而是一次全方位的架构重构。
关键变化包括:
-
KV Cache布局调整:优化键值缓存存储方式
-
稀疏性处理机制升级:支持稀疏与稠密并行计算
-
FP8解码支持:针对英伟达Blackwell GPU架构专项优化
-
MLA结构重新设计:参数维度从576维切换至512维
-
VVPA(价值向量位置感知):解决长文本位置信息衰减
-
Engram记忆印记机制:推测与分布式存储优化相关
据传,DeepSeek V4的代码表现已超越Claude和GPT系列,并且具备处理复杂项目架构和大规模代码库的工程化能力。
目前外界对DeepSeek的能力期待值越来越高。
有业内观察者认为,Engram模块可能会成为DeepSeek V4的重要组成部分,并预示DeepSeek下一代模型会在记忆和推理协同上实现架构级提升。
5.2 DeepSeek-V3.2:性价比之王依然能打
在V4正式到来之前,V3.2依然是目前市场上性价比最高的编程模型之一。
DeepSeek-V3.2被描述为提供与OpenAI GPT-5相当的性能。此前R1模型的成功已经证明,DeepSeek能用极低的成本实现顶级的推理能力。
一句话总结:如果你是个人开发者或中小团队,追求极致性价比,V3.2是目前的最优选。而V4一旦发布,很可能重塑整个AI编程的竞争格局。
六、GLM-5.1(智谱):首个在编程实测中超越Sonnet的国产模型
就在两天前(3月28日),智谱发布了GLM-5.1,距离5.0发布仅一个多月。这次的更新非常“短平快”,但含金量十足。
6.1 实测数据:首次超越Sonnet 4.5 Thinking
智谱官方公布的测试中,GLM-5.1的编程能力从GLM-5.0的35.4分提升到了45.3分,距离最强的Opus 4.6只有2.6分差距。
但更让人兴奋的是第三方实测。
知乎程序员大佬“Toyama nao”搞了一个LLM Benchmark Dashboard,涉及桌面端、移动端及前端等多个项目的开发。测试结果非常炸裂:
GLM-5.1成为第一个通过他全部测试工程的国产模型,也是第一个正式超越Sonnet 4.5 Thinking的国产模型。
他评价道:“GLM-5.1大幅扩展了编程的适应范围,不再是前端only战神,也不只是oneshot样子货,是可以在复杂工况下充当编程主力。”
6.2 长上下文问题
当然,GLM-5.1也不是完美的。评测者提到的问题是超长上下文时容易“幻觉爆炸”:如果遇到2轮改不好一个问题,不要抱有侥幸,直接重开。
6.3 适用场景
-
复杂全栈开发:需要兼顾前端、后端、数据库的场景
-
国产替代首选:在国内使用网络稳定,中文理解天然优势
-
多轮复杂任务:需要连续修改和调试的项目
一句话总结:智谱正在以肉眼可见的速度追赶国际顶流。如果你需要国产模型且对编程能力有高要求,GLM-5.1是目前最强选择。
七、Qwen3.5-Plus(阿里千问):代码Agent的旗舰
最后来说说阿里的千问系列。
根据阿里云官方3月更新的模型列表,Qwen3.5-Plus是当前Qwen系列的旗舰模型。
7.1 核心能力:代码Agent
Qwen3.5-Plus在语言理解、逻辑推理、代码生成、智能体任务、图像理解、视频理解等多种任务中表现卓越。
它尤其擅长智能体编程与工具调用,能够精准地调用外部工具,适合场景更加复杂的智能体需求。
7.2 家族完整
除了旗舰版,Qwen3.5还提供了多个版本供开发者选择:
|
模型规格 |
定位 |
适用场景 |
|---|---|---|
|
Qwen3.5-Plus |
旗舰版 |
复杂任务、智能体开发 |
|
Qwen3.5-Flash |
速度最快 |
简单任务、实时响应 |
|
Qwen3.5-Coder-480B |
代码专用 |
Coding Agent、工具调用 |
7.3 适用场景
-
阿里云生态内开发:与百炼平台、函数计算无缝集成
-
智能体应用:需要工具调用和环境交互的场景
-
企业级RAG:结合阿里云向量检索服务
一句话总结:如果你在阿里云上开发,Qwen3.5-Plus是最自然的选择。
八、终极对比与选型指南
8.1 核心参数对比表
|
模型 |
上下文窗口 |
输入价格($/MT) |
输出价格($/MT) |
核心优势 |
SWE-bench得分 |
|---|---|---|---|---|---|
|
Claude Opus 4.6 |
100万 |
5 |
25 |
编程质量第一 |
~72% |
|
GPT-5.4 Pro |
100万 |
30 |
180 |
电脑操控 |
~70% |
|
Gemini 3.1 Pro |
100万 |
约3 |
约15 |
推理能力 |
~68% |
|
GLM-5.1 |
未公布 |
较低 |
较低 |
国模最强编程 |
~45%* |
|
Qwen3.5-Plus |
100万 |
较低 |
较低 |
Agent能力 |
未公布 |
|
DeepSeek-V3.2 |
100万 |
极低 |
极低 |
极致性价比 |
未公布 |
*注:GLM-5.1的45.3分是内部测试分,与SWE-bench体系不同,仅供参考排名趋势。
8.2 如何选择?
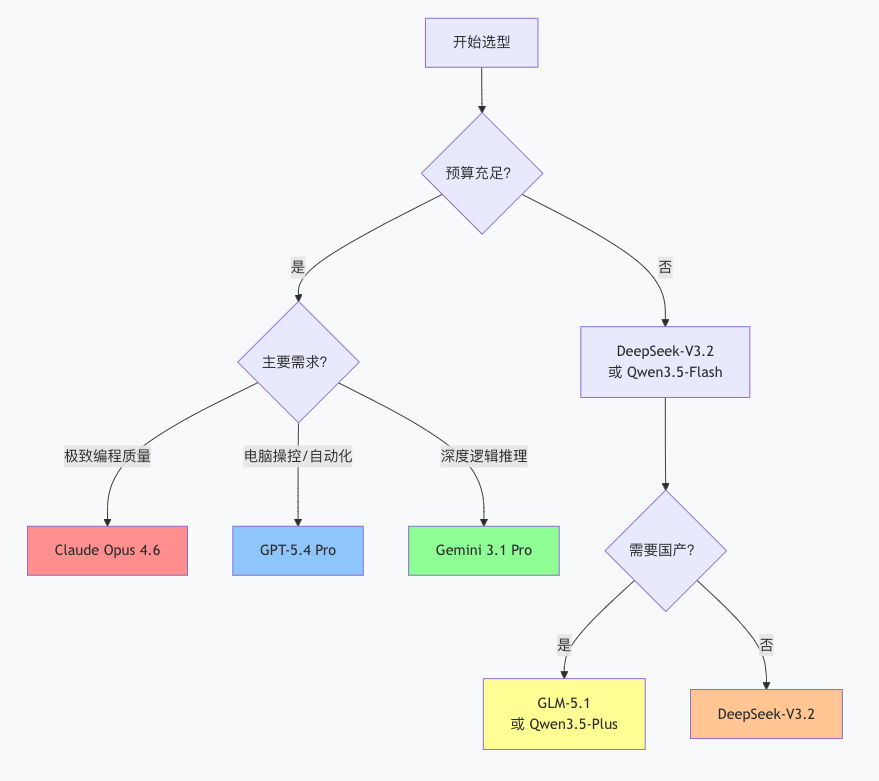
8.3 场景化建议
场景一:追求代码质量,预算充足→ Claude Opus 4.6 + Sonnet 4.6混合使用:复杂逻辑用Opus,日常编码用Sonnet,节省成本。
场景二:需要AI帮你操作电脑/软件→ GPT-5.4 Pro:目前唯一具备原生电脑操控能力的模型,在OSWorld-Verified测试中超越人类平均水平。
场景三:数学、科研推理→ Gemini 3.1 Pro:ARC-AGI-2得分77.1%,推理能力翻倍提升。
场景四:国产替代,国内网络环境→ GLM-5.1:首个在复杂工况测试中超越Sonnet 4.5 Thinking的国模。
场景五:阿里云生态开发→ Qwen3.5-Plus:与百炼平台、函数计算深度集成。
场景六:个人开发者/中小团队→ DeepSeek-V3.2:极致性价比,等待V4发布后有望进一步提升。
场景七:需要处理超长文档/代码库→ Claude Opus 4.6或GPT-5.4:均支持100万Token上下文,可一次性处理整套代码库。
九、写在最后
2026年的AI编程战场,正在进入白刃战阶段。
Anthropic靠100万Token上下文和顶尖编程能力守住王座,OpenAI用电脑操控能力开辟新赛道,谷歌在推理能力上持续深耕,而国产模型则以肉眼可见的速度缩小差距——GLM-5.1超越Sonnet 4.5 Thinking,DeepSeek V4架构重构蓄势待发。
未来已来,只是分布不均。
选对工具,你的编程效率可以翻倍;选错工具,你可能会被时代甩下。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)