神经网络基础:从 RNN 的局限到 Transformer 的巅峰
前言
在第一课和第二课中,我们掌握了全连接网络和卷积网络(CNN)。全连接层擅长处理静态特征,卷积层擅长处理空间特征(图像)。
然而,当面对序列数据(如一句话、一段音频)时,数据之间的顺序和上下文关系变得至关重要。今天我们通过对比传统 RNN 结构,深度拆解目前 AI 界的统治级架构——Transformer。
一、 为什么抛弃 RNN?(背景与动机)
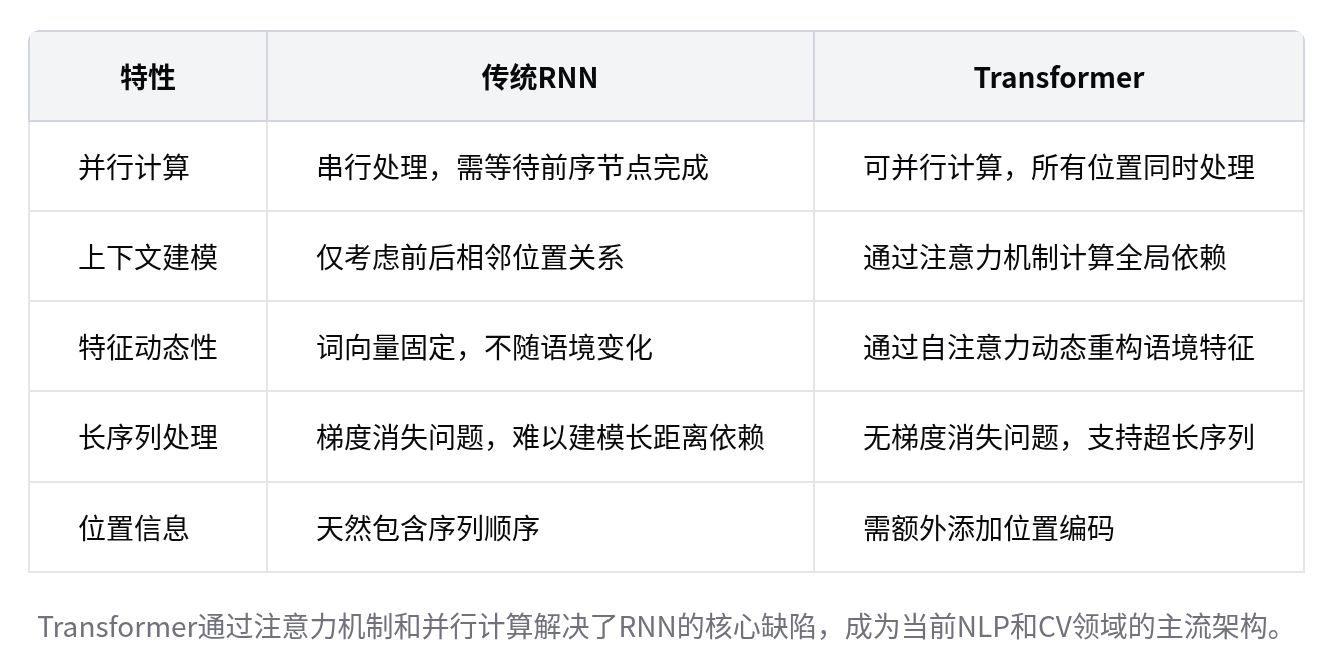
在 Transformer 问世之前,RNN(循环神经网络)是处理序列的主力,但它存在三大致命缺陷:
-
串行计算效率低:RNN 必须等前一个词算完才能算下一个,无法利用 GPU 并行加速,不适合大模型训练。
-
长距离依赖困境:RNN 仅考虑相邻位置关系。如果句首和句尾有强关联,RNN 很难捕捉到。
-
特征固定:词向量初始化后基本不变,无法根据语境“重构”含义(无法实现一词多义)。
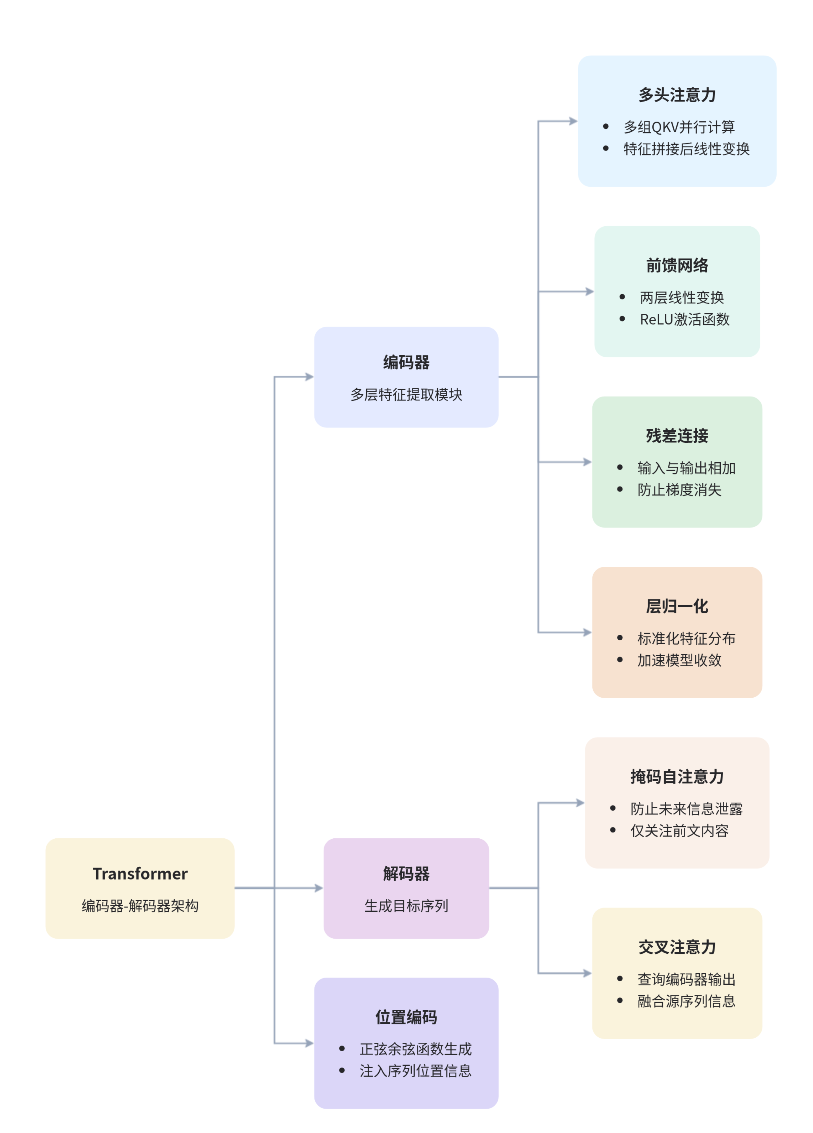
二、 Transformer 整体架构
Transformer 彻底抛弃了循环结构,改用完全并行的编码器-解码器(Encoder-Decoder)架构。
-
输入格式:输入为 Batch × 序列长度 × 特征个数 的矩阵。
-
编码器:负责对输入进行深层特征提取。
-
解码器:利用编码器特征进行预测(如翻译、生成)。
三、 注意力机制(Attention):Transformer 的灵魂
注意力机制的目的是让模型学会“区分重点”:多关注重要特征,忽略无用背景。
1. Q、K、V 的直观理解
Transformer 引入了三组向量来模拟“匹配”过程:
-
Q (Query - 查询向量):我要找什么?
-
K (Key - 键向量):我有什么特征可以提供参考?
-
V (Value - 值向量):我自身的实际特征内容是什么?
2. 计算流程:内积匹配与特征重构
-
计算关系分数:Q 与 K 进行内积计算。内积越大,表示两个词关系越近。
-
归一化(Softmax):将分数转化为总和为 1 的权重。
-
加权求和:用权重去乘以 V,得到融合了上下文信息的新特征。

四、 进阶细节:多头注意力与位置编码
为了让 Transformer 更加鲁棒,还加入了两个关键设计:
-
多头注意力(Multi-Head Attention):
-
通过初始化多组 QKV,让模型从多个维度(视角)去提取特征(类似于 CNN 的多个卷积核)。
-
最后将多组特征拼接,增强特征的多样性。
-
-
位置编码(Positional Encoding):
-
Transformer 本身不识别顺序(认为“我打你”等于“你打我”)。
-
通过给每个词加上一个特定的“位置向量”,让相同的词在不同位置产生不同的特征,解决置换不变性问题。
-
五、 解码器中的 Mask 机制
解码器在生成序列时,有一个特殊要求:不能偷看未来。
-
Mask 机制:在训练时遮盖掉当前词之后的词。例如预测第 3 个词时,Q 只能看前 2 个词的 K 和 V,确保模型是根据已知信息进行预测。

如果你觉得这篇文章有启发,欢迎点赞、收藏并在评论区留下你的思考!我们下期见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)