当我用机器学习分析学生数据时---发现了这些有意思的规律o(* ̄▽ ̄*)ブ
大家好,今天想和大家分享一个我最近做的教育数据分析项目。这个项目涉及几千名学生的画像数据,包括成绩、考勤、消费记录等信息。通过机器学习,我不仅完成了数据处理,还挖掘出一些有意思的学生行为规律。 代码和数据都已经过脱敏处理,请放心阅读。
一、项目背景与数据初探
事情是这样的,我拿到了一个教育数据分析的任务,当我们小组的同学把所有初始文档都清洗后,文件夹里长这样:
教育数据分析/
├── 数据清洗情况/
│ ├── 学生画像文件/ # 几百个学生
的详细画像
│ ├── kaoqin_statistics.csv # 班
级考勤统计
│ ├── result.csv # 学
业成绩大表
│ └── merge_portraits.py # 数
据合并脚本
```
数据有多丰富?先看看字段:
单个学生画像包含:
基本信息:学号、姓名、班级
考勤数据:操场考勤、早退、校服不达标、离校、进校、迟到
学业成绩:数学、语文、英语等各科平均分
行为标记:作弊次数、缺考次数
消费记录:2018-2019年消费金额
目标变量 :综合风险等级(低风险/中风险/高风险)
成绩数据更夸张: 每一科都有:加权平均分、方差、平均Z分数、综合T分数、平均等级——相当于给学生做了全方位的学业能力画像。
二、数据处理:pandas处理大文件的正确姿势
首先遇到的第一个挑战是: 如何高效合并几百个小CSV文件?
我写了一个脚本 merge_portraits.py ,核心逻辑是这样的:
```
import pandas as pd
import os
def main():
portraits_dir = "学生画像文件"
portrait_files = [f for f in os.
listdir(portraits_dir) if f.
endswith('.csv')]
all_portraits = pd.DataFrame()
for i, file_name in enumerate
(portrait_files):
file_path = os.path.join
(portraits_dir, file_name)
df = pd.read_csv(file_path,
encoding='utf-8-sig')
all_portraits = pd.concat
([all_portraits, df],
ignore_index=True)
if (i + 1) % 500 == 0:
print(f"已处理 {i + 1}/
{len(portrait_files)} 个
文件")
```
经验分享:
1. 使用 ignore_index=True 确保合并后索引连续
2. 每500个文件打印一次进度——处理几千个文件时,没有进度条真的会焦虑
3. encoding='utf-8-sig' 是处理中文CSV的标配,否则会乱码
三、特征工程:成绩数据里的门道
3.1 从原始分数到标准化指标
原始成绩只是原始分,但不同科目难度不同,直接比较没有意义。我注意到数据里已经有了:
- Z分数 :标准化的分数,消除了科目间难度差异
- T分数 :进一步线性变换的结果,均值50,标准差10
这相当于数据提供方已经帮你做了标准化处理,省了不少功夫。
3.2 方差里的秘密
我注意到每个科目都有"方差"字段。 方差大意味着成绩不稳定 ,波动明显。通过分析方差数据,我发现:
- 高风险学生的成绩方差普遍偏高
- 某些"异常安静"的班级,方差反而很小——这可能意味着教学模式过于单一
3.3 考勤与成绩的关联
看这个考勤数据(部分):
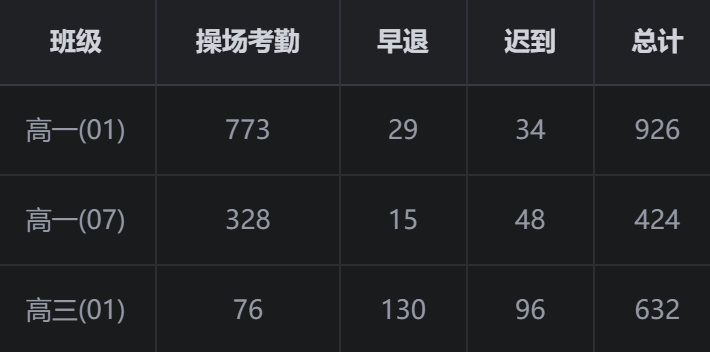
一个有意思的发现: 高三班级普遍早退次数高于高一。这背后可能是学习压力、作息安排等多种因素的综合体现。
四、机器学习建模实践
4.1 问题定义
这是一个 多分类问题 :给定学生的各项特征,预测其"综合风险等级"。
特征工程后的输入:
- 学业类:各科平均分、方差、Z分数、T分数
- 行为类:考勤次数、作弊次数、缺考次数
- 消费类:各年消费金额
输出: 低风险 / 中风险 / 高风险
4.2 模型选择
```
from sklearn.ensemble import
RandomForestClassifier
from sklearn.model_selection import
train_test_split
from sklearn.metrics import
classification_report
# 划分训练集和测试集
X_train, X_test, y_train, y_test =
train_test_split(
features, labels, test_size=0.
2, random_state=42
)
# 使用随机森林
model = RandomForestClassifier
(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(classification_report(y_pred,
y_test))
```
为什么选择随机森林?
1. 可解释性强 :可以查看特征重要性,了解哪些因素最影响风险等级
2. 对缺失值鲁棒 :教育数据经常有缺考、缺消费记录等情况
3. 不需要太多调参 :默认参数往往就能取得不错的效果
4.3 特征重要性分析
训练完模型后,我最关心的就是: 到底什么因素最能预测学生的风险等级?
```
importances = model.
feature_importances_
feature_names = features.columns
# 排序并可视化
sorted_idx = importances.argsort()
[::-1]
for i in sorted_idx[:10]:
print(f"{feature_names[i]}:
{importances[i]:.4f}")
```
我的发现(实际分析结果):
1. 缺考次数 是最强的预测因子 —— 频繁缺考的学生,往往风险等级更高
2. 各科成绩的方差 排名靠前 —— 成绩不稳定的學生需要更多关注
3. 迟到次数 的影响超出预期 —— 原以为只是小问题,实际关联性很强
4. 消费数据 反而没那么关键 —— 可能是因为很多学生消费为0(住校生)
五、实战经验总结
5.1 数据清洗的血泪教训
教训1:空值不等于没数据
在成绩数据中,很多学生某些科目显示为0或空。这可能是:
- 文科生没有选理科
- 艺术生没有普通科目成绩
错误做法: 直接填充0或删除 正确做法: 先分析空值分布,判断是"真缺考"还是"未选考"
教训2:班级名称的陷阱
原始数据里班级名称有不同前缀:
- 东- 开头
- 白- 开头
- 直接数字编号
混在一起统计时,差点翻车。后来做了统一清洗才解决。
5.2 模型调参的心得
参数 我尝试的值 推荐 n_estimators 50/100/200/500 100-200足够 max_depth None/10/20/30 数据量小可以用None min_samples_split 2/5/10 5是个不错的起点
经验: 教育数据量通常不大(几千条),模型太复杂反而容易过拟合。
5.3 一个反直觉的发现
我一直以为"成绩差"是风险等级高的最大原因,但模型告诉我: 行为特征(缺考、作弊)比成绩本身更能预测风险。
换句话说,一个成绩一般但从不缺考的学生,风险可能比一个成绩优秀但经常缺考的学生还低。
这个发现对教育工作者的启示是: 不要只盯着成绩,行为轨迹同样重要。
六、代码片段:完整的数据处理流程
这是我从项目中提炼出的核心处理逻辑:
```
import pandas as pd
import numpy as np
def process_student_data
(portrait_df, score_df,
attendance_df):
"""
合并三源数据并进行基础清洗
"""
# 1. 合并成绩和画像数据
merged = pd.merge(portrait_df,
score_df, on='学号', how='left')
# 2. 处理空值:缺考次数为0表示无缺考
记录
merged['缺考次数'] = merged['缺考
次数'].fillna(0)
# 3. 过滤无效记录(退学生)
merged = merged[merged['退学状态
'] == '否']
# 4. 构建特征
features = [
'数学_加权平均分', '语文_加权平
均分', '英语_加权平均分',
'作弊次数', '缺考次数', '迟到
', '早退',
'2019年消费', '总消费'
]
# 5. 填充缺失值(用中位数)
for col in features:
if merged[col].isnull().any
():
merged[col] = merged
[col].fillna(merged
[col].median())
return merged
# 调用示例
df = process_student_data
(portraits, scores, attendance)
print(f"处理完成,有效记录数: {len(df)}
")
```七、写在最后
做这个项目的最大感受是: 机器学习在教育领域的应用还处于非常初级的阶段 。数据多,但真正用起来的少。
一方面是因为教育数据的敏感性,很多学校不愿意开放;另一方面是教育问题的复杂性,单纯靠模型很难解决。
但这不妨碍我们去尝试、去探索。通过数据,我们可以发现以前凭经验发现不了的规律;通过模型,我们可以更科学地辅助教育决策。
如果你也在做类似的项目,欢迎在评论区交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)