【Python 实战】高中生偏科深度数据分析全流程(偏科建模 + 交叉分析 + 机器学习预警)
偏科是高中阶段最影响成绩、最容易被误判的问题!只看分数补课、不挖根源,往往越补越糟。本文基于 Python + Pandas + Matplotlib + Seaborn + 孤立森林机器学习,对某中学近 70 万条脱敏真实数据(成绩、考勤、消费、住宿、违纪、教师任教)做全流程偏科分析,包含:
- 偏科系数建模 + 自动三级打标(均衡 / 轻度 / 重度)
- 数据清洗:异常成绩、缺考、作弊一键剔除
- Z 分数 / T 分数标准化(跨学科公平对比)
- 性别 × 住宿高危群体精准定位
- 教师任教 / 更替对班级偏科影响分析
- 消费层级 + 作息规律度关联挖掘
- 缺考 / 违纪负面行为预警
- 偏科时间演化拐点追踪
- 雷达图映射行为风险
- 全自动输出结果表 + 高清图表
全程保姆级步骤,小白可直接运行,适合:高中生家长、班主任、学科老师、数据分析爱好者、数智化教育项目!
目录
1. 项目背景与数据说明
2.技术栈选型
3.环境准备
4.数据读取与脱敏处理
5. 数据清洗(核心!异常成绩 + 伪偏科过滤)
6. 偏科识别模型(偏科系数 + 三级打标)
7. 性别 × 住宿交叉分析(高危人群定位)
8. 师资维度:教师影响与更替分析
9. 消费习惯 + 作息规律度分析(孤立森林)
10. 考试负面行为:缺考 / 违纪预警
11. 偏科随时间演化:分化拐点追踪
12. 考勤违纪雷达图映射
13.核心结论与干预建议
14. 踩坑总结
15. 项目优化方向
1️⃣ 项目背景与数据说明
1.1 业务背景
高中偏科不只是 “单科差”,而是学习习惯、生活节律、师资匹配、心理状态共同导致的系统性问题。传统干预痛点:
- 只看单次分数,误判假性偏科
- 只补课,不纠正作息与行为
- 找不到真正高风险群体
- 干预滞后,等到高三难以挽回
目标:用数据科学定位 谁易偏科、为何偏科、何时恶化、如何干预,实现精准预警、科学治理。
1.2 数据集说明
- 数据来源:宁波某中学真实脱敏教育数据
- 数据规模:近 70 万条记录
- 涉及表:
- 学生信息表(性别、班级、住宿)
- 成绩表(多次考试、7 选 3 科目)
- 考勤表(迟到、违纪、缺席)
- 消费表(刷卡时间、金额)
- 教师任教表(任课、换师记录)
- 脱敏处理:删除姓名、隐私,仅保留分析字段
2️⃣ 技术栈选型
- Python 3.8+
- Pandas:数据读取、清洗、分组、聚合、交叉表
- NumPy:标准差、极差、熵值计算
- Matplotlib/Seaborn:绘图、热力图、雷达图、小提琴图
- Scikit-learn:孤立森林(异常检测 / 规律度评分)
- 正则表达式:违纪文本结构化提取
3️⃣ 环境准备
一键安装依赖:
pip install pandas numpy matplotlib seaborn scikit-learn4️⃣ 数据读取与脱敏处理
# 中文字体设置
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取核心宽表数据
df = pd.read_csv("全维度综合成绩宽表.csv", low_memory=False)
# 读取偏科标签结果
df_bias = pd.read_csv("学生偏科标签特征库.csv", encoding="utf-8-sig")5️⃣ 数据清洗(核心!)
原始数据非常脏,必须清洗,否则直接导致 “伪偏科”:
# 1. 转为数值,剔除异常
df['mes_T_Score'] = pd.to_numeric(df['mes_T_Score'], errors='coerce')
# 2. 剔除缺考、作弊、无效分
df = df[(df['mes_Score'] > 0) & (~df['mes_Score'].isin([-1, -2, -3]))].copy()
# 3. 去空
df = df.dropna(subset=['mes_T_Score', 'mes_sub_name', 'mes_StudentID'])
# 4. 剔除有效科目<4的学生,避免伪偏科
sub_cnt = df.groupby('mes_StudentID')['mes_sub_name'].nunique()
valid_ids = sub_cnt[sub_cnt >= 4].index
df = df[df['mes_StudentID'].isin(valid_ids)]6️⃣ 偏科识别模型(三级自动打标)
核心思路:
- 计算每个学生各科 Z 分标准差作为偏科系数
- 按分位数划分:均衡 / 轻度偏科 / 重度偏科
# 按学生+科目求平均Z分
stu_sub = df.groupby(['mes_StudentID','mes_sub_name'])['mes_Z_Score'].mean().reset_index()
# 计算偏科指标
bias = stu_sub.groupby('mes_StudentID')['mes_Z_Score'].agg(['std','max','min']).reset_index()
bias['range'] = bias['max'] - bias['min']
# 分位数打标
t1 = bias['std'].quantile(0.5)
t2 = bias['std'].quantile(0.85)
def label(x):
if x['std'] >= t2: return '重度偏科'
elif x['std'] >= t1: return '轻度偏科'
else: return '均衡发展'作用:
- 看相对排名,不看绝对分数
- 跨科目公平比较强弱
- 消除考试难度差异
7️⃣ 性别 × 住宿交叉分析(最高危人群)
采用多维特征交叉组合运算(Multi-dimensional Cross-tabulation),将两类二分类特征(性别 × 住宿状态)相乘组合出四类细分客群矩阵。
# 交叉表
cross = pd.crosstab([df['bf_sex_label'], df['bf_zhusu_label']], df['bias_type'], normalize='index')*100
# 热力图
plt.figure(figsize=(9,6))
sns.heatmap(cross, annot=True, fmt='.1f', cmap='YlOrRd', linewidths=0.5)
plt.title('性别×住宿偏科占比热力图', fontweight='bold', fontsize=14)
plt.tight_layout()
plt.savefig('图表_3_多维综合_热力分布图.png', dpi=300)
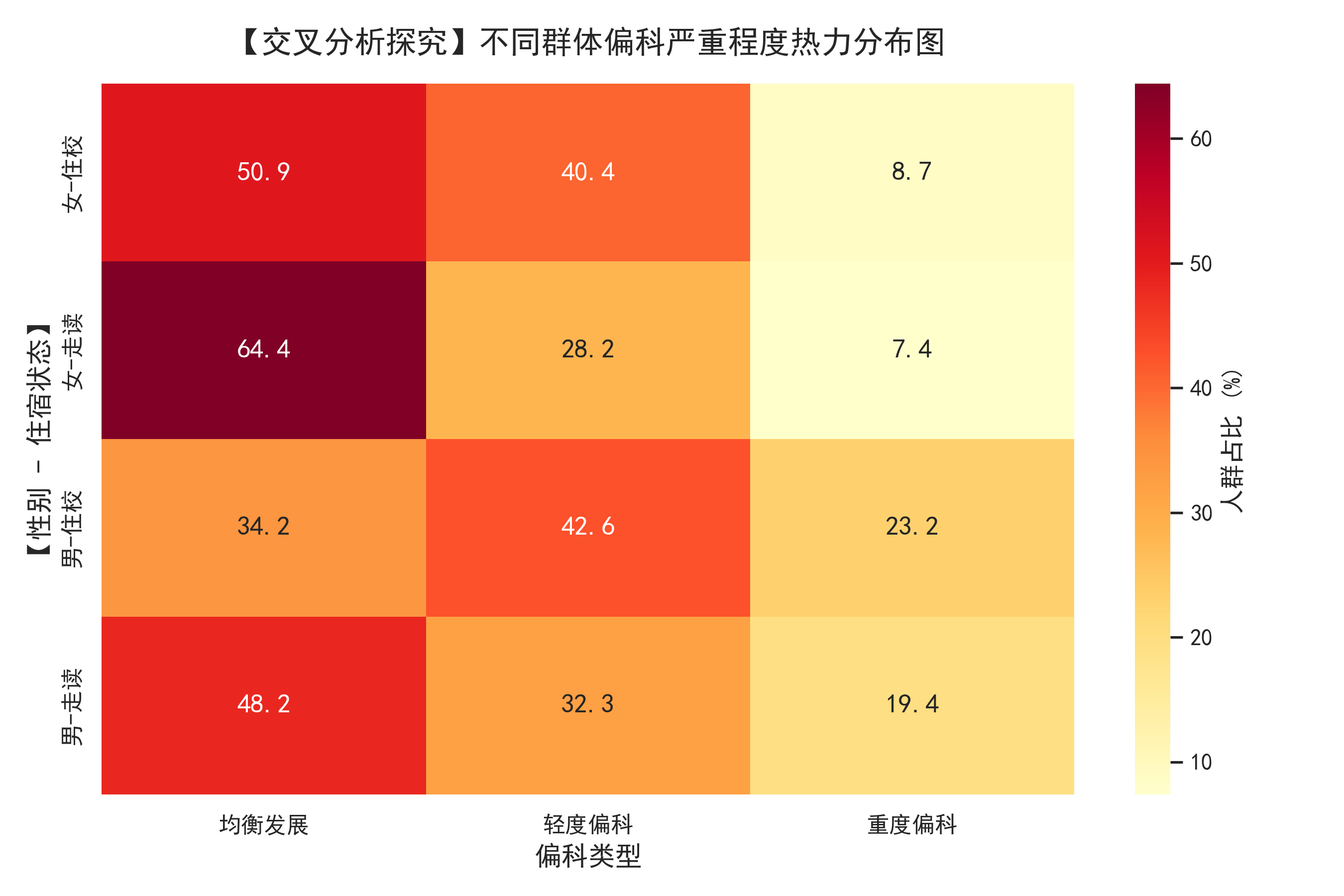
关键结论:
- 女走读:均衡率 64.4%,重度偏科仅 7.4%
- 男住校:均衡率 34.2%,重度偏科 23.2%(最高危)
- 住校显著提升偏科风险
8️⃣ 师资维度:教师影响与换师拐点
基于班级学科偏科系数分析发现,不同教师对班级整体学科表现具有显著影响。
# 班级偏科系数 = 班均分 - 年级均分
grade_avg = df.groupby(['exam_number','mes_sub_name'])['mes_T_Score'].mean().reset_index()
class_avg = df.groupby(['exam_number','mes_sub_name','cla_Name','bas_Name'])['mes_T_Score'].mean().reset_index()
final = class_avg.merge(grade_avg, on=['exam_number','mes_sub_name'])
final['bias_coef'] = final['mes_T_Score_x'] - final['mes_T_Score_y']
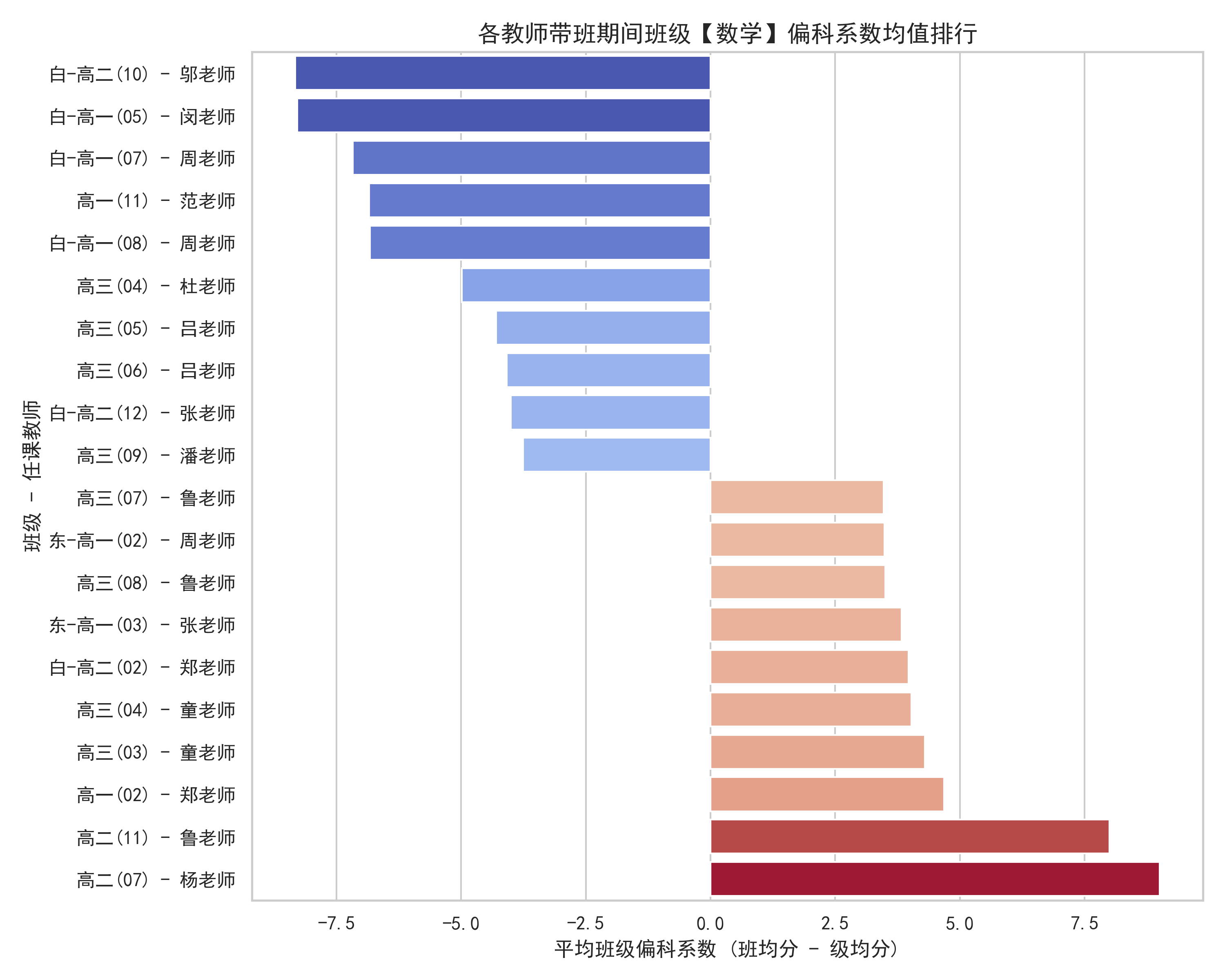
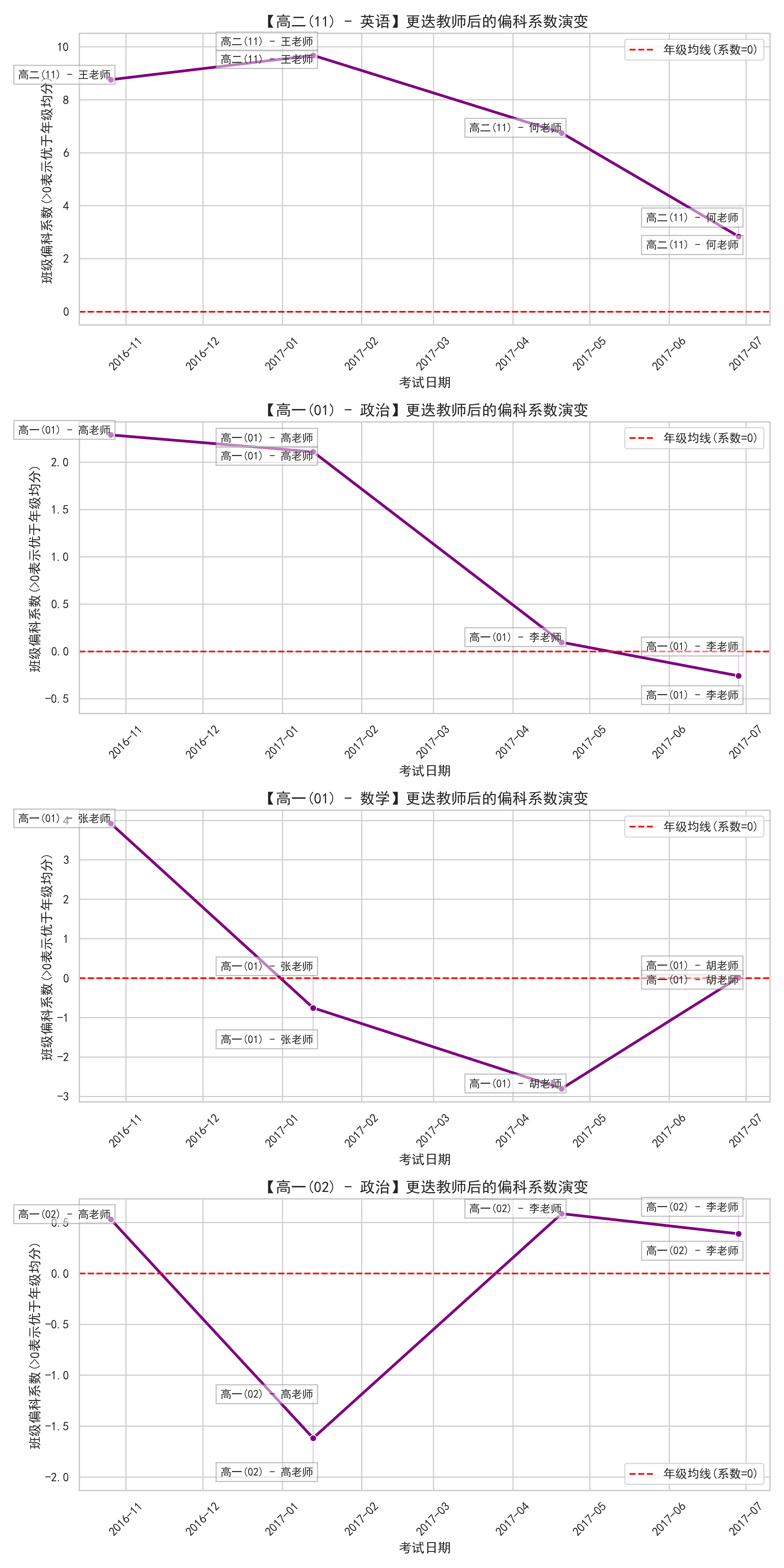
结论:
- 教师直接决定班级学科强弱
- 换师后常出现深 V 反弹 / 断崖下滑
- 师资匹配比绝对能力更重要
9️⃣ 消费 + 作息:生活失控→学业失衡
使用孤立森林 + 信息熵计算作息规律度:
from sklearn.ensemble import IsolationForest
# 住校/走读分开建模
iso = IsolationForest(random_state=42)
df['regularity_score'] = iso.fit_predict(X)
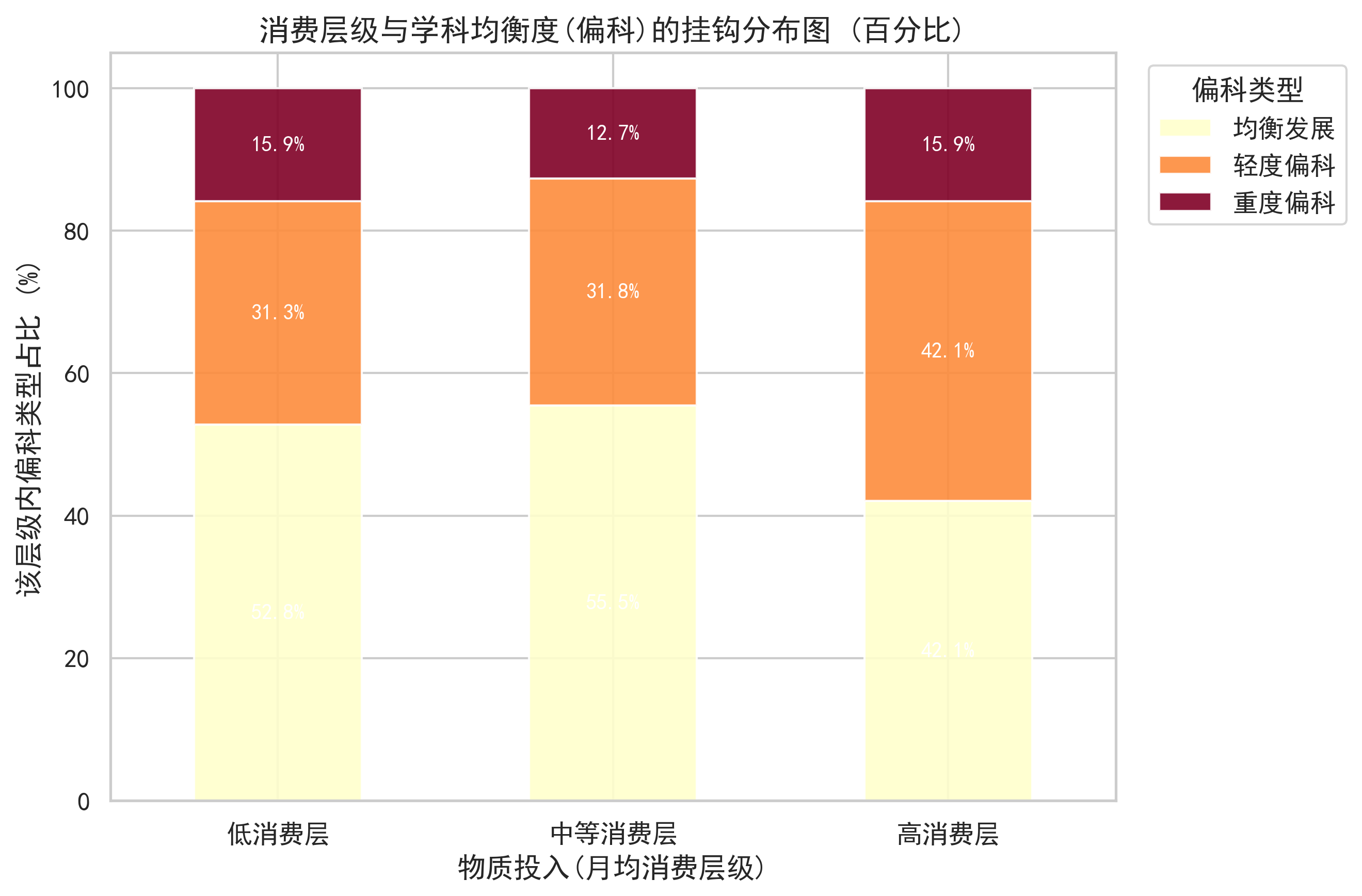
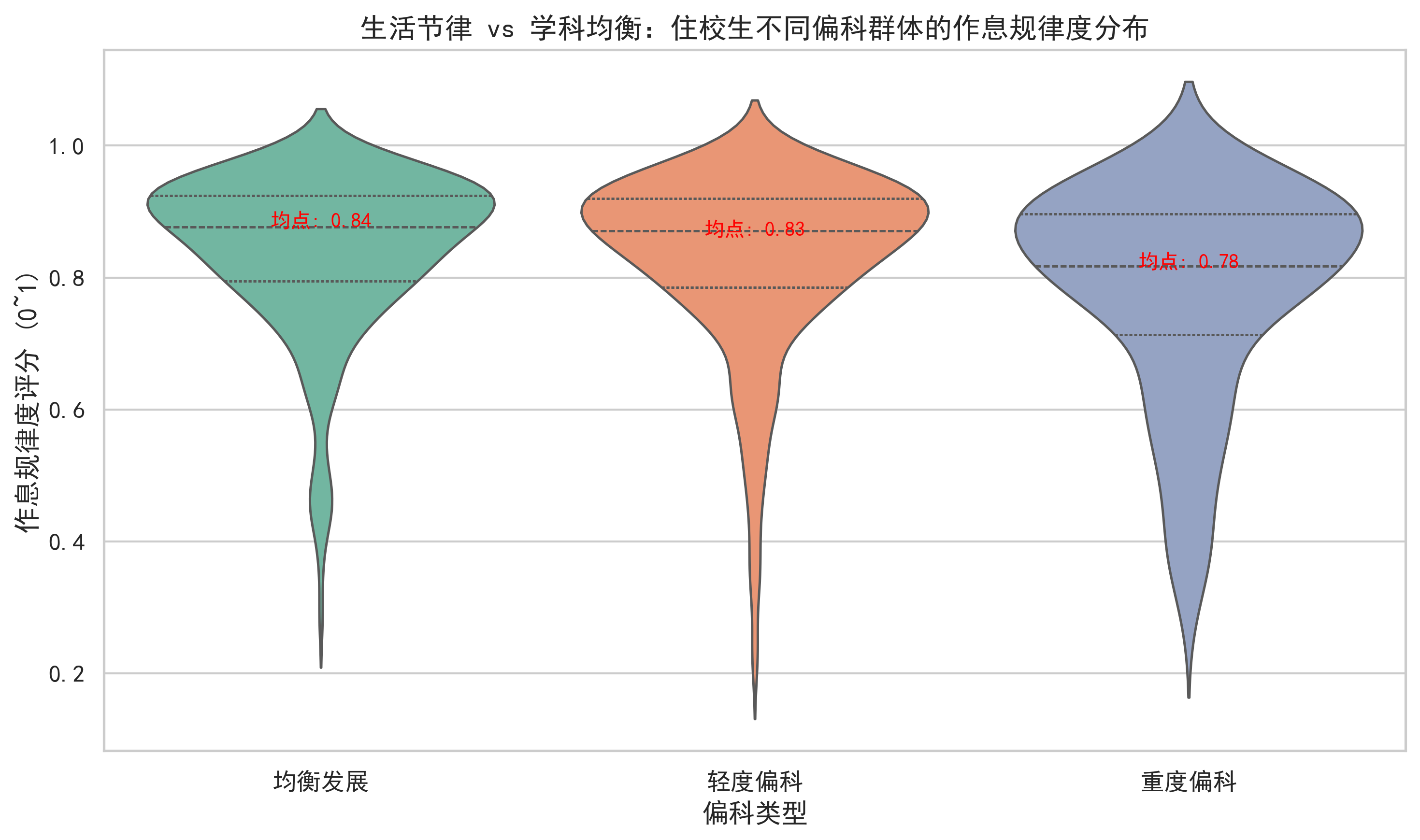
结论:
- 中等消费最稳定,高消费易分心
- 作息越乱,偏科越严重
- 生活节律是前置预警信号
🔟 考试负面行为:缺考 = 学习逃避
重度偏科伴随习惯性逃避
neg = df[df['mes_Score'].isin([-1,-2,-3])].copy()
neg['type'] = neg['mes_Score'].map({-1:'作弊',-2:'缺考',-3:'免考'})
# 热力图
pivot = neg.pivot_table(index=['bias_type','type'], columns='mes_sub_name', values='mes_Score', aggfunc='count')
sns.heatmap(pivot, annot=True, fmt='d', cmap='OrRd')
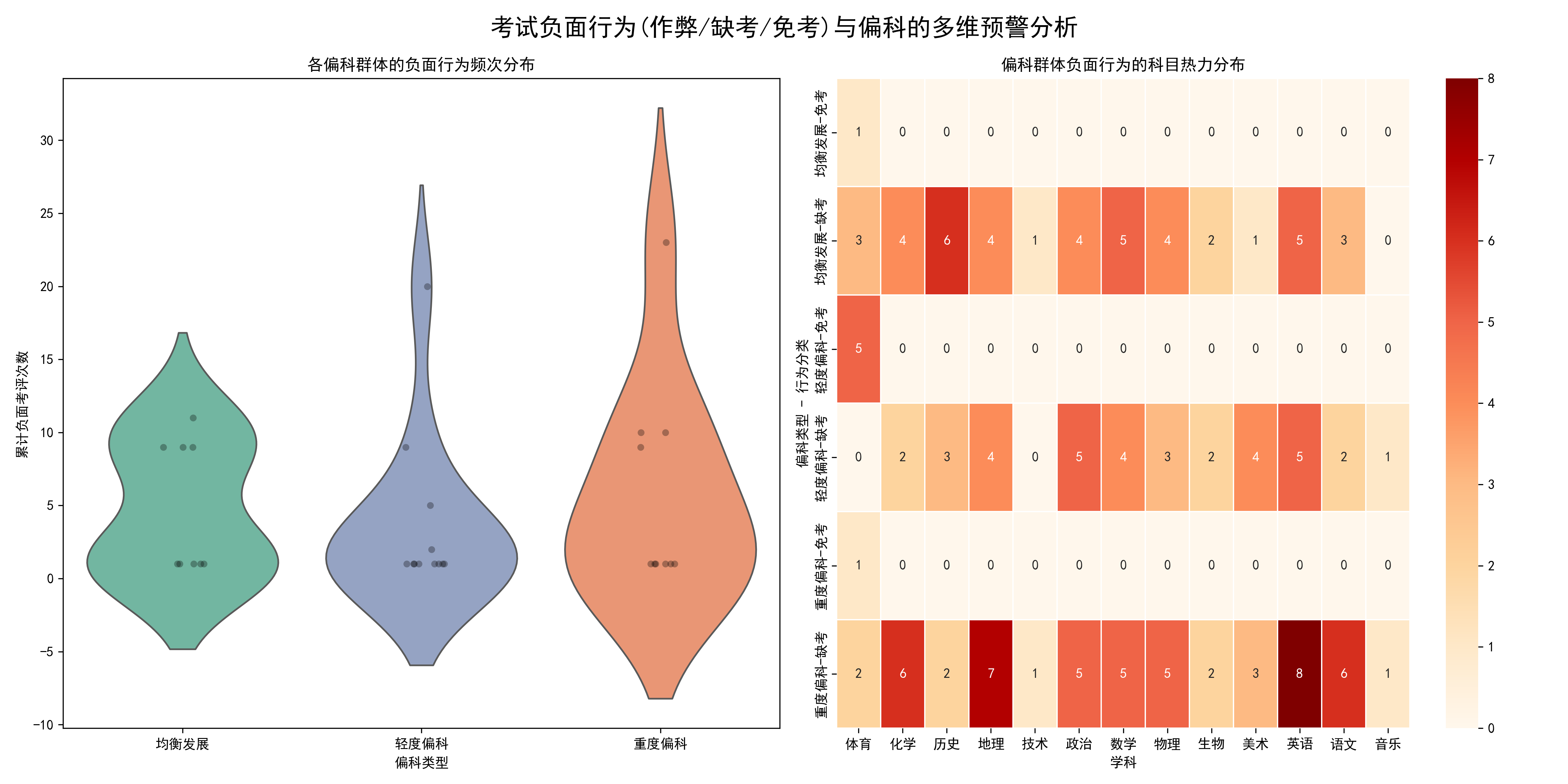
结论:
- 重度偏科高频缺考:英语、地理、化学、语文
- 缺考不是失误,是习惯性逃避
-
这些科目要么依赖长期积累,要么存在较高理解与记忆门槛。
1️⃣1️⃣ 偏科时间演化:高一下快速恶化
偏科并非天生,而是逐渐分化并在后期恶化。在入学初期,均衡发展、轻度偏科与重度偏科三类学生的学科波动水平接近,差异并不显著;进入高一下学期至高二阶段后,重度偏科群体的学科极差与变异系数开始快速上升,并逐渐与均衡发展群体拉开差距。
# 按时间计算极差/变异系数
exam_agg = student_exam_stats.groupby(['bias_type','exam_sdate']).agg({'t_range':'mean','t_cv':'mean'}).reset_index()
sns.lineplot(data=exam_agg, x='exam_sdate', y='avg_t_range', hue='bias_type', marker='o')
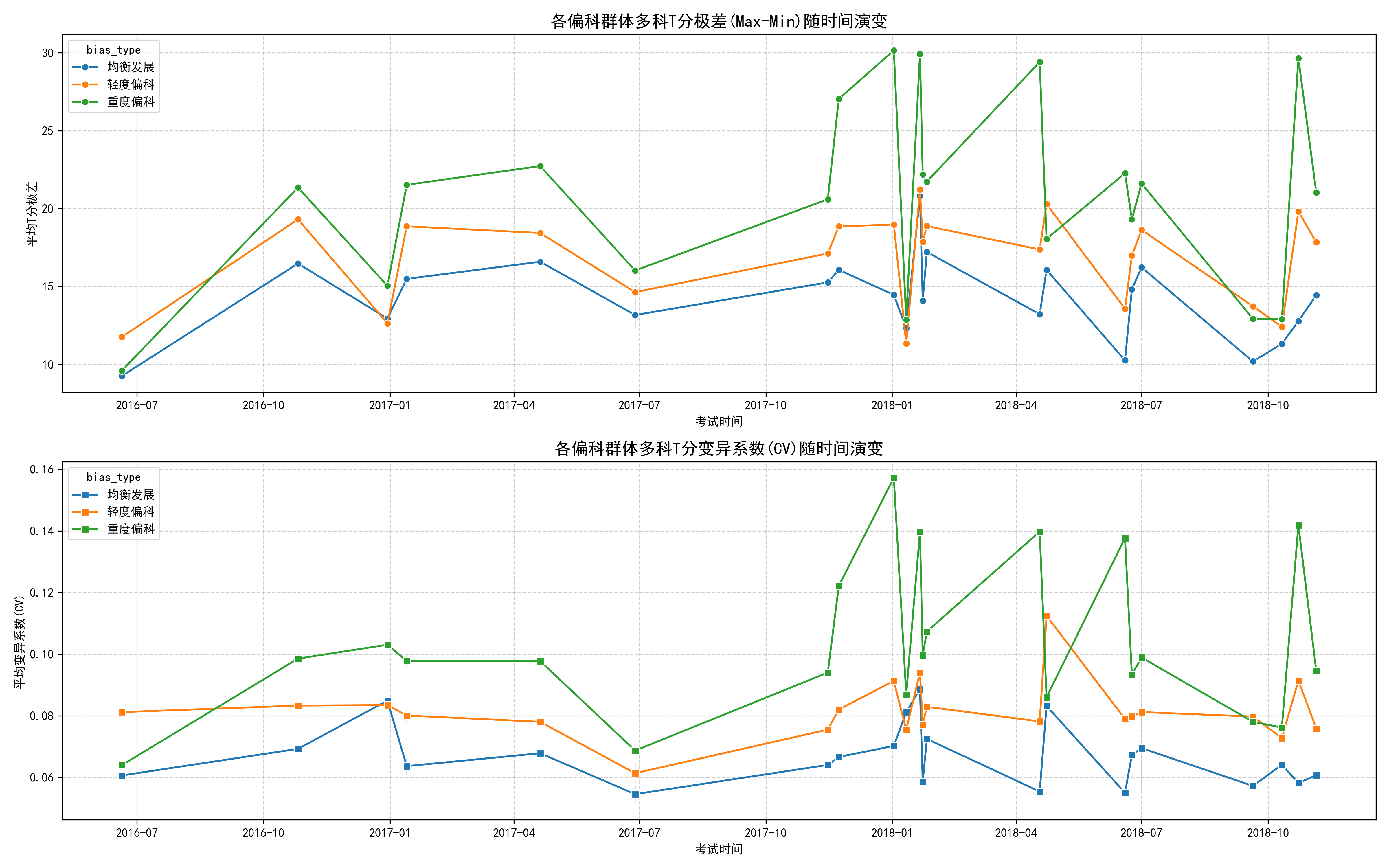
结论:
- 高一:差异很小
- 高一下 — 高二:偏科急剧分化(关键干预期)
- 高三:波动剧烈,难以挽回
1️⃣2️⃣ 考勤雷达图:早读迟到最强预警
严重偏科学生往往同时伴随时间管理失效、早晨起床困难及对学习任务的潜在抗拒。早读迟到缺席并非孤立纪律问题,而是学生对高压学习日程产生逃避心理的重要外显信号。
# 正则提取违纪类型:早读迟到、晚自习违纪、仪容不整
viol = kaoqin_full.dropna(subset=['violation_type'])
# 雷达图绘制
ax = plt.subplot(111, polar=True)
ax.plot(angles, values, linewidth=2, label=bias)
ax.fill(angles, values, alpha=0.1)
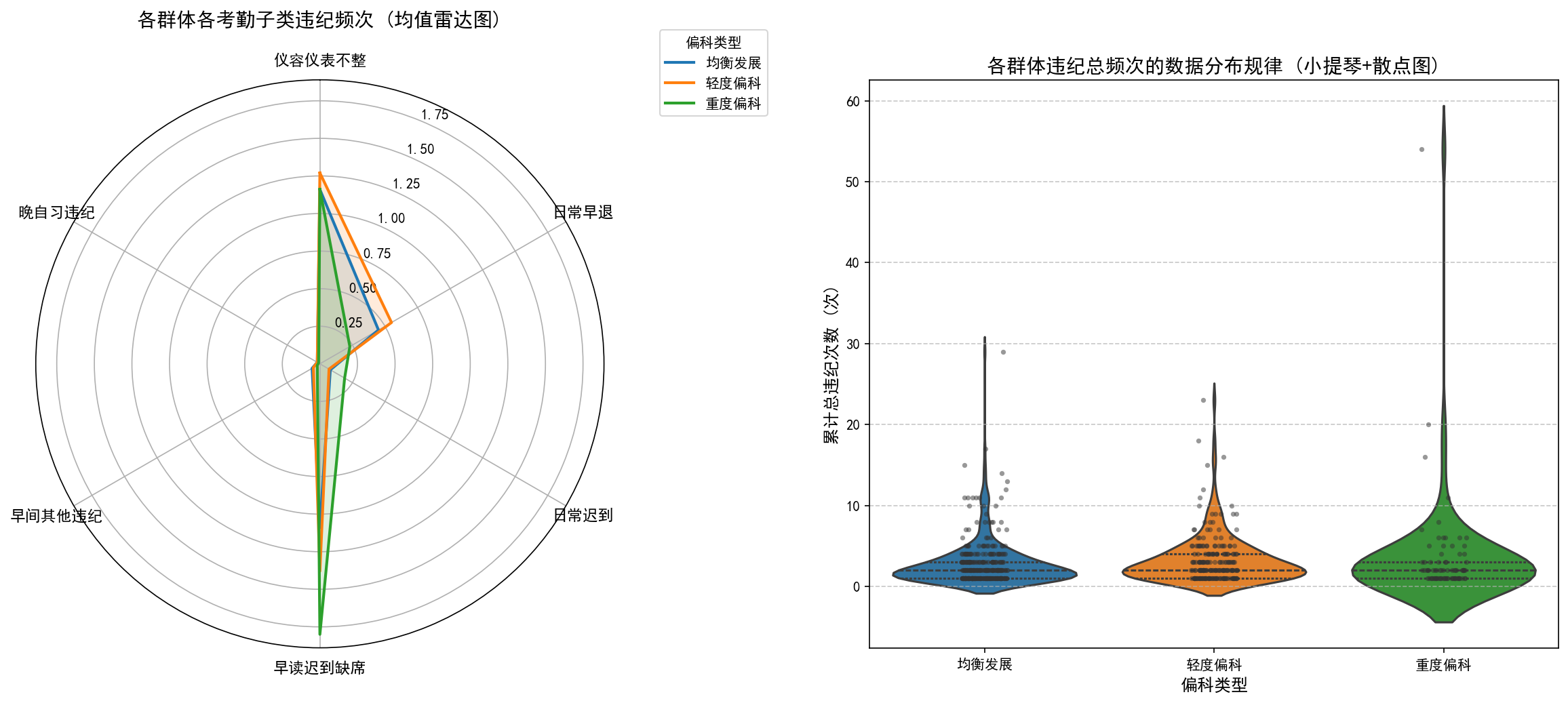
结论:
- 重度偏科:早读迟到缺席最突出
- 纪律问题 = 学习抗拒的外显信号
1️⃣3️⃣ 核心结论
- 男住校生是偏科第一高危群体
- 住校显著提升偏科风险,需强化早晚管理
- 偏科不是单科问题,是生活 + 行为 + 教学共同导致
- 早读迟到、作息混乱、高频缺考是最有效前置预警
- 最佳干预期:高一下学期 — 高二上学期
- 教师更替是成绩拐点关键诱因,必须平稳过渡
1️⃣4️⃣ 踩坑总结(必看!)
- 不做 Z/T 分数标准化 → 偏科判定完全错误
- 不剔除缺考 / 作弊 /-1/-2/-3 → 大量伪偏科
- 不筛选有效科目≥4 → 结果失真
- 住校 / 走读用同一规律度模型 → 误判严重
- 图表不设中文字体 → 方格乱码
- 只看分数不看行为 → 找不到根源
1️⃣5️⃣ 项目优化方向
- 接入心理测评数据,完善情绪预警
- 构建实时 BI 看板,自动推送高危名单
- 加入选科关联度,实现偏科 + 选科联动推荐
- 生成个人 PDF 干预报告(家长版 / 学生版)
- 长期跟踪干预效果,形成闭环管理

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)