刷 AI 工具时总看到token?这篇用人话讲清楚
你是不是也经常在 AI 工具里看到这些说法:
“本次消耗 800 tokens”
“上下文支持 128K tokens”
“按 token 计费”
但 token 到底是什么?
这篇就用更容易理解的方式聊聊,不讲复杂技术👇

先说结论:token 可以理解成“AI 眼里的文字单位”
我们平时读一句话,通常是按“字”“词”“句子”来理解。
但 AI 处理文字时,不一定是一个汉字一个汉字地看。
它会把文字拆成一小块一小块的单位,这些小块就叫 token。
你可以先粗略理解成:
- token ≈ AI 用来读懂内容的“小颗粒”
- 输入给 AI 的内容会变成 token
- AI 回复你的内容也会消耗 token
- token 越多,通常代表内容越长、处理成本越高
举个生活化例子
比如你跟 AI 说:
帮我写一段小红书文案
这句话在 AI 看来,不一定是作为一整句话直接处理的。
它可能会被拆成几个 token。
如果你丢给它一篇很长的文档、聊天记录、合同、论文,token 数就会明显增加。
所以很多 AI 工具才会提示:
- 这次对话用了多少 token
- 最多支持多少 token
- 超出 token 限制需要删减内容
token 跟费用有什么关系?
很多 AI 工具背后都是按 token 计费的。
可以这样理解:
你让 AI 读得越多、写得越多,消耗就越多。
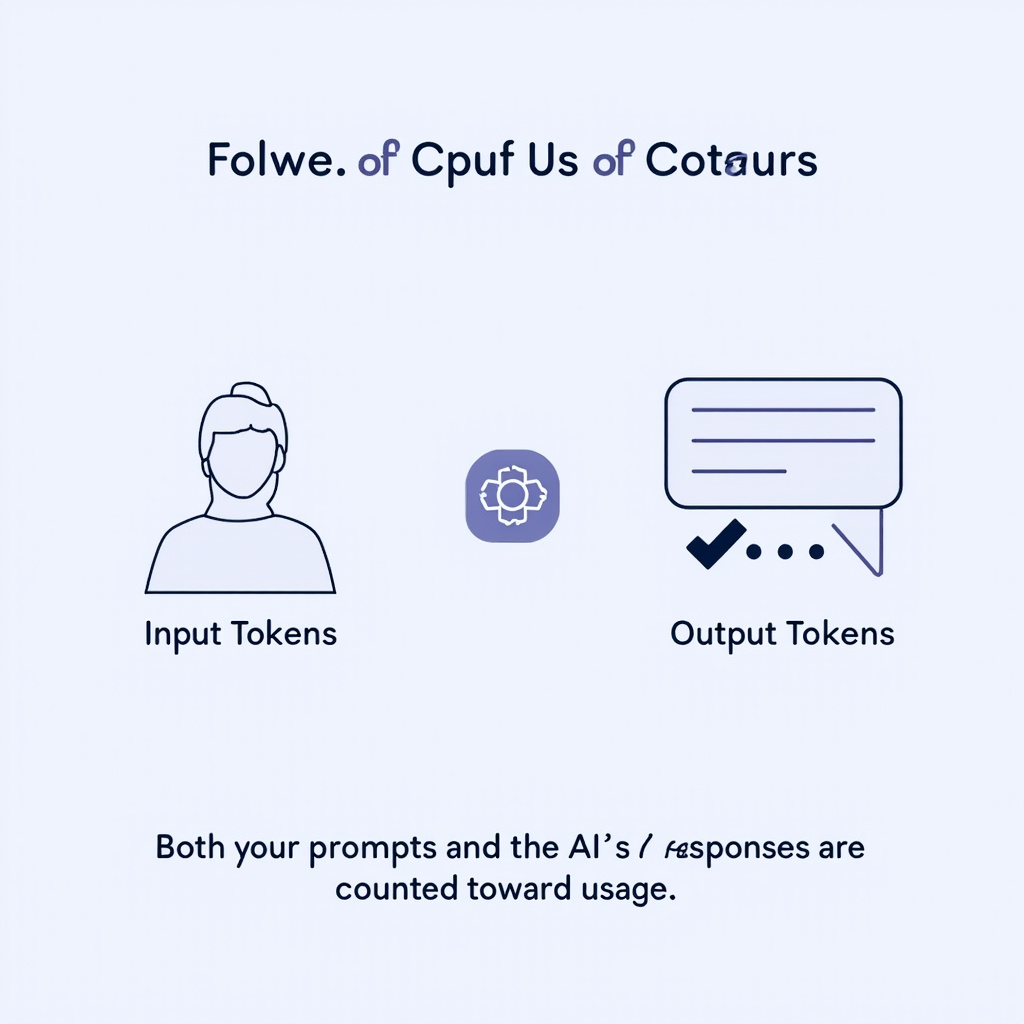
一般会分成两部分:
-
输入 token
你发给 AI 的内容,比如问题、文档、提示词。 -
输出 token
AI 回复你的内容,比如答案、文案、总结。
所以,并不是只有 AI 回复才算消耗,你发过去的内容也算。
这一点很多人刚开始用 AI 时容易忽略。
“上下文 128K token”是什么意思?
这个说法也很常见。
你可以把它理解成:
AI 一次最多能“记住和处理”的文字容量。
比如一个模型支持 128K tokens,意思是它能在一次对话里容纳比较多的信息。
这对下面这些场景很有用:
- 总结长文档
- 分析会议记录
- 阅读论文
- 处理长篇小说
- 连续多轮聊天不容易忘前文
但要注意:
并不是上下文越大就一定越好。
如果你塞进去一大堆无关内容,AI 也可能抓不到重点。
就像你让一个人看 200 页资料,却不告诉他重点在哪,他也会懵。
普通用户需要特别懂 token 吗?
其实不用研究得太深入。
你只要记住这几个判断就够了:
- 问题越长,token 越多
- 资料越多,token 越多
- AI 回答越详细,token 越多
- 多轮聊天越久,累计 token 越多
- 超过限制时,需要删掉无关内容或分段处理
日常使用时,token 更像是一个“容量”和“成本”的概念。
不用把它想得太神秘。
我自己常用的省 token 小技巧
如果你经常用 AI 写东西、总结资料,可以试试这些方法:
1. 先说清楚目标
不要一上来就丢一大堆资料。
可以先写:
请帮我总结这段内容,重点提炼适合普通人理解的 5 点。
目标越清楚,AI 越不容易跑偏,也越不容易说废话。
2. 长内容分段发
特别长的文章、会议纪要、论文,不一定要一次性全塞进去。
可以分成几段处理:
- 第一段:让 AI 先总结
- 第二段:继续总结
- 最后:让 AI 合并提炼
这样更稳,也更方便你检查结果。
3. 不相关的内容先删掉
比如你只想让 AI 改一段文案,就没必要把整个聊天记录都复制进去。
保留必要背景就行。
4. 控制回答长度
如果你不想让 AI 写太长,可以直接说:
- “控制在 200 字以内”
- “用 5 个要点回答”
- “不要展开太多”
这样输出 token 也会少一些。
一句话总结
token 就是 AI 处理文字时使用的基本单位。
它会影响:
- AI 能读多少内容
- AI 能记住多少上下文
- 使用成本大概是多少
- 长文档能不能一次处理完
普通用户不用研究得太深。
你只要知道:
内容越多,token 越多;让 AI 读和写,都会消耗 token。
下次再看到 token,就不会一脸懵啦。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)