CVPR 2023 | Consistent-Teacher:面向半监督目标检测中不一致伪目标的消减方法
论文信息
- 论文题目:Consistent-Teacher: Towards Reducing Inconsistent Pseudo-targets in Semi-supervised Object Detection
- 论文作者:Xinjiang Wang,Xingyi Yang,Shilong Zhang,Yijiang Li,Litong Feng,Shijie Fang,Chengqi Lyu,Kai Chen,Wayne Zhang
- 发表会议:CVPR 2023
- 代码链接 : https://github.com/Adamdad/
ConsistentTeacher
论文主要贡献
- 首次对半监督目标检测(SSOD)中存在的
伪目标不一致问题进行了研究,该问题会引发严重的过拟合问题。 - 引入了
自适应样本分配方法,以稳定带噪声的伪边界框与锚点之间的匹配,从而使学生模型训练更鲁棒。 - 开发了
三维特征对齐模块(FAM-3D)来校准分类置信度和回归框质量,从而提升伪边界框的质量。 - 采用
高斯混合模型(GMM)灵活确定每个类别的阈值。该自适应阈值会随训练阶段变化,从而减少阈值不一致问题。 - Consistent-Teacher 在各类评估中取得了显著提升,成为了半监督目标检测领域一个新的可靠基准模型。
问题
半监督目标检测中的伪目标不一致问题。
不稳定的伪目标会破坏模型训练,向学生网络注入噪声,并导致严重过拟合。
具体问题主要表现在:
- 教师模型生成的伪框不稳定。教师模型输出微小变化会导致伪边界框的边界产生强烈噪声;
- 基于 IoU 的分配策略不可行。在学生网络中,一些未被模型激活的候选框被错误地分配为正样本,从而导致过拟合;
- 分类任务与回归任务不匹配。置信度不能准确反映边界框的质量。因此,两个得分相近的锚点可能生成差异显著的预测伪边界框,进而导致更多错误预测;
- 固定阈值的不合理性。固定置信度阈值无法随训练动态调整,伪框数量忽多忽少,监督信号不可靠。
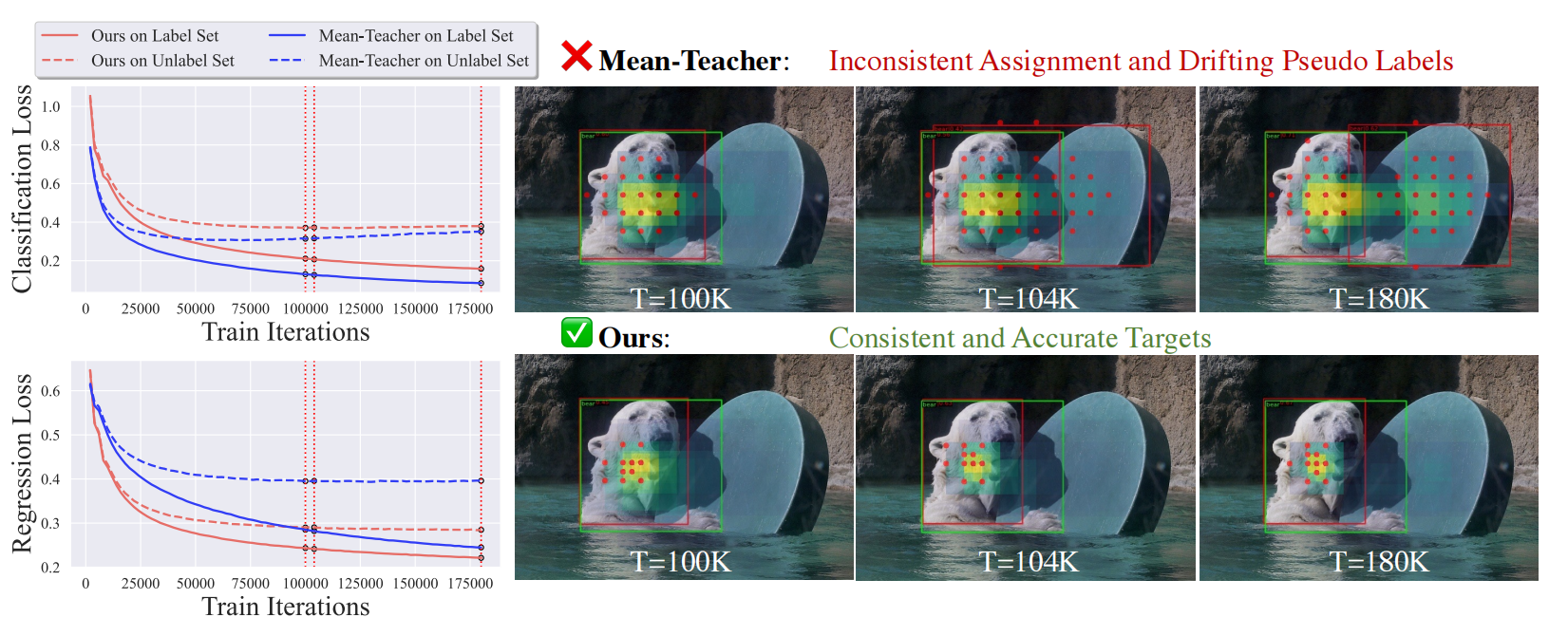 COCO 10% 评估集上单阶段目标检测(SSOD)中不一致问题的示意图。
COCO 10% 评估集上单阶段目标检测(SSOD)中不一致问题的示意图。
左图对比了均值教师(Mean-Teacher)与本文提出的一致教师(Consistent-Teacher)的训练损失。在均值教师模型中,不一致的伪目标会导致分类分支过拟合,同时回归损失也难以收敛。相比之下,本文方法为学生模型设定了一致的优化目标,有效平衡了分类与回归两项任务,避免了过拟合。
右图为伪标签与分配策略动态变化的快照。绿色和红色边界框分别代表北极熊的真实边界框和伪边界框。红点为伪标签分配的锚框。热力图展示了教师模型预测的密集置信度分数(颜色越亮分数越高)。基线方法最终将附近的一块木板误分类为北极熊,而本文的自适应分配策略则避免了这一过拟合问题。
论文创新点
提出Consistent-Teacher的系统性解决方案,以降低伪目标不一致性。
自适应样本分配(ASA):替代了传统的IoU静态交并比策略,使学生网络能够抵抗噪声伪边界框的干扰;三维特征对齐模块(FAM-3D):在空间和特征尺度维度对子任务预测结果进行校准;高斯混合模型(GMM):动态修正伪边界框的分数阈值,既在训练初期稳定了真实样本的数量,又弥补了训练过程中监督信号不可靠的缺陷。
方法
Consistent-Teacher 半监督目标检测架构
整体框架
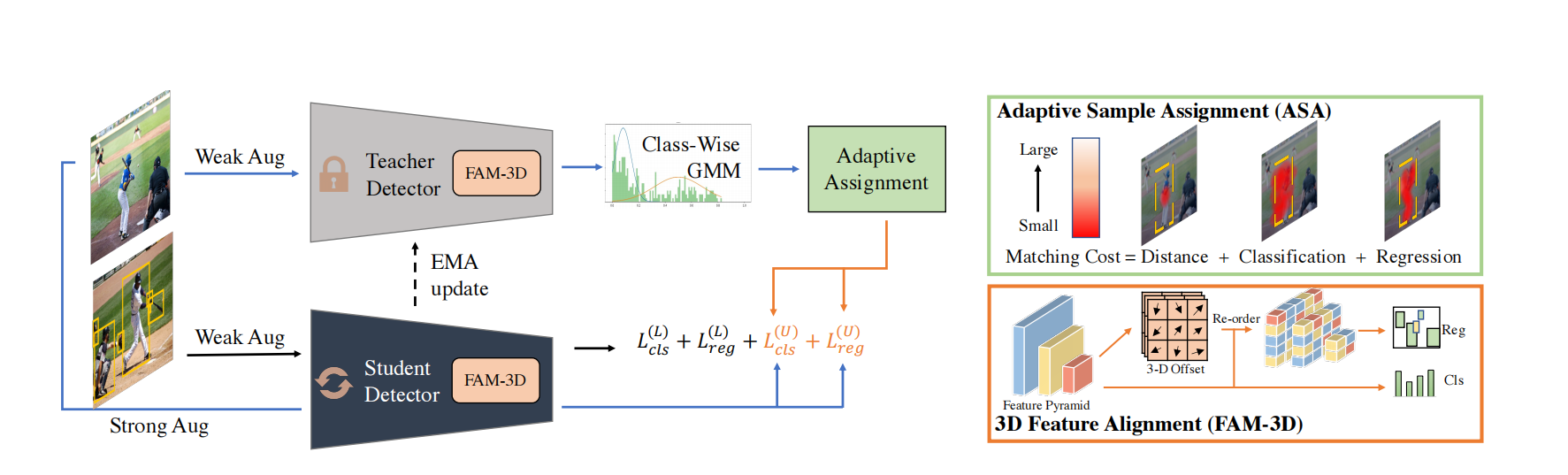
教师:对未标注图像做弱增强,传入内置FAM-3D的教师检测器(Teacher Detector),教师输出原始预测,经过Class-Wise GMM训练全程自适应动态更新筛选阈值,保证不同阶段、不同类别都能筛选出数量足质量优的伪框。Adaptive Assignment自适应样本分配前置处理,输出稳定的正负样本匹配结果,作为学生模型的伪监督标签。教师模型被锁定,参数不参与梯度更新,依靠 EMA(指数移动平均)从学生模型更新而来
学生:一路带标签的弱增强图像输入,保证基本检测能力稳定,方便做一致性约束;一路强增强图像,防止模型过拟合,提升泛化能力。强弱增强图像进入内置 FAM-3D的学生检测器,输出学生自身的分类、回归预测结果。
带循环箭头,主动训练、反向更新参数的主体
GMM高斯混合模型
对教师模型输出的、逐类别的所有候选检测置信分数用 二元高斯混合模型 拟合:
高斯1代表有效高质量正伪样本(置信整体偏高)
高斯2代表背景噪声、误检负样本(置信整体偏低)
EM 算法求解
用期望最大化 EM 算法迭代估计两个高斯分布的均值、方差、混合权重,分离正负置信分布,得到两条高斯曲线。
动态自适应阈值计算
计算每个置信样本属于真正正样本分布的后验概率(有多大概率是真目标,多大概率是噪声),求取两类分布的最优分界点,为每一个类别、每一次训练迭代,单独生成置信阈值。
伪标签筛选
高于该动态阈值的伪框才会被保留。
FAM-3D
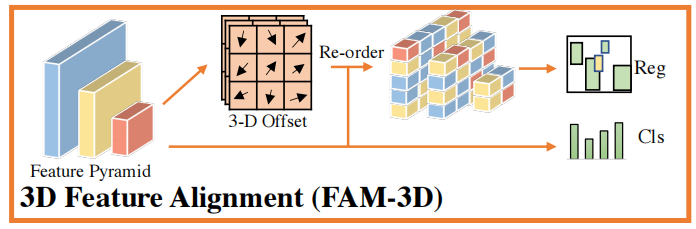
输入:特征金字塔(Feature Pyramid)
最左侧FPN多尺度特征图,包含大、中、小不同尺寸的多层特征,分别对应检测不同大小的目标,是目标检测的基础特征输入。
计算3D偏移量(3-D Offset)
模块对三维特征空间(空间高度H、空间宽度W、多尺度层级S),预测每个特征点的三维偏移矢量,箭头代表每个位置需要校正的位移方向,定位分类特征和定位特征的偏差位置。
特征重排列(Re-order)
根据计算得到的3D偏移场,对整个三维特征张量做重排列,把原本错位的特征点校正到匹配的正确位置,完成跨空间、跨尺度的全局特征对齐。
校正后的对齐特征分为两路输出:
- Reg(回归分支):输出物体边界框定位结果,定位精度提升;
- Cls(分类分支):输出物体类别预测,分类特征同时具备精准位置感知。
ASA自适应样本分配

核心匹配代价公式:匹配代价(Matching Cost) = 距离(Distance) + 分类得分(Classification) + 回归精度(Regression)
空间位置距离(Distance):候选锚点与标注框中心点之间的距离,优先选择落在目标物体中心区域的锚点(距离越小),远离边缘、背景锚点
分类可信度(Classification):模型当前对该锚点输出的目标类别置信得分
回归定位质量(Regression):该锚点预测的边界框,和教师伪标注真实框之间的定位误差
黄色框:教师模型输出的伪框
红色热力区域:代表每个候选样本和目标框之间的综合匹配代价,红色部分和目标贴合好、位置准、分类置信高、定位误差小。
不再只看 IoU 重叠单一标准,而是全局综合评估,动态选出最合适的正样本。
损失函数
L = 1 N ∑ i [ L c l s ( f s ( T ( x i l ) ) , y i l ) + L r e g ( f s ( T ( x i l ) ) , y i l ) ] + λ u 1 M ∑ j [ L c l s ( f s ( T ′ ( x j u ) ) , y ^ j u ) + L r e g ( f s ( T ′ ( x j u ) ) , y ^ j u ) ] \begin{aligned} \mathcal{L}= & \frac{1}{N} \sum_{i}\left[\mathcal{L}_{c l s}\left(f_{s}\left(T\left(x_{i}^{l}\right)\right), y_{i}^{l}\right)+\mathcal{L}_{r e g}\left(f_{s}\left(T\left(x_{i}^{l}\right)\right), y_{i}^{l}\right)\right] \\ & +\lambda_{u} \frac{1}{M} \sum_{j}\left[\mathcal{L}_{c l s}\left(f_{s}\left(T'\left(x_{j}^{u}\right)\right), \hat{y}_{j}^{u}\right)+\mathcal{L}_{r e g}\left(f_{s}\left(T'\left(x_{j}^{u}\right)\right), \hat{y}_{j}^{u}\right)\right] \end{aligned} L=N1i∑[Lcls(fs(T(xil)),yil)+Lreg(fs(T(xil)),yil)]+λuM1j∑[Lcls(fs(T′(xju)),y^ju)+Lreg(fs(T′(xju)),y^ju)]
有监督分类、回归损失+无监督分类、回归损失
实验分析
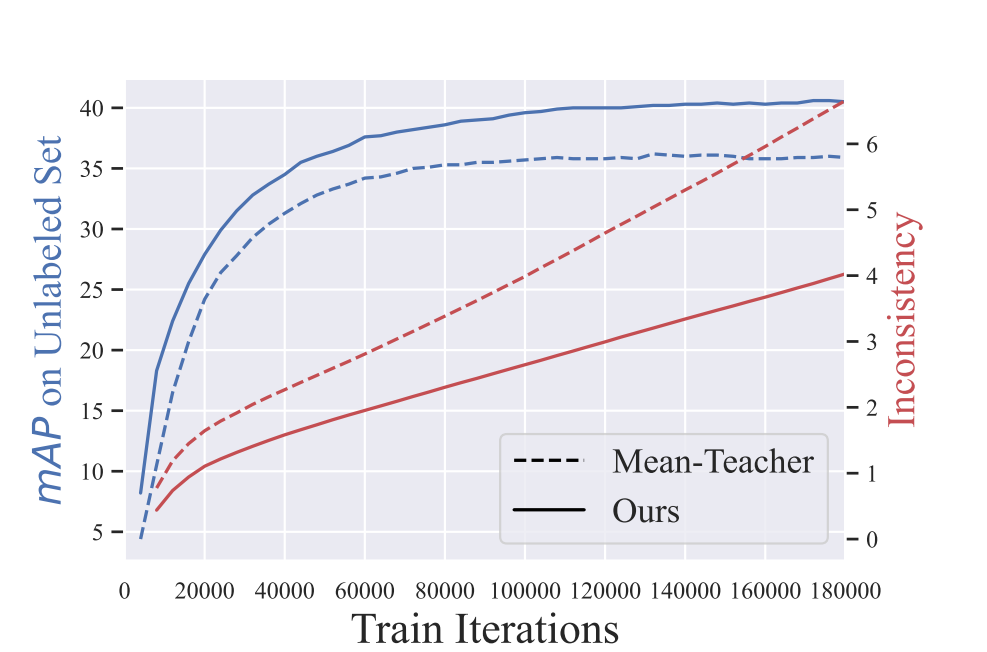
一致教师模型提升了SSOD中的训练一致性。左轴为不同时间下未标记集的平均精度均值(mAP)。右轴为伪标签的不一致性。
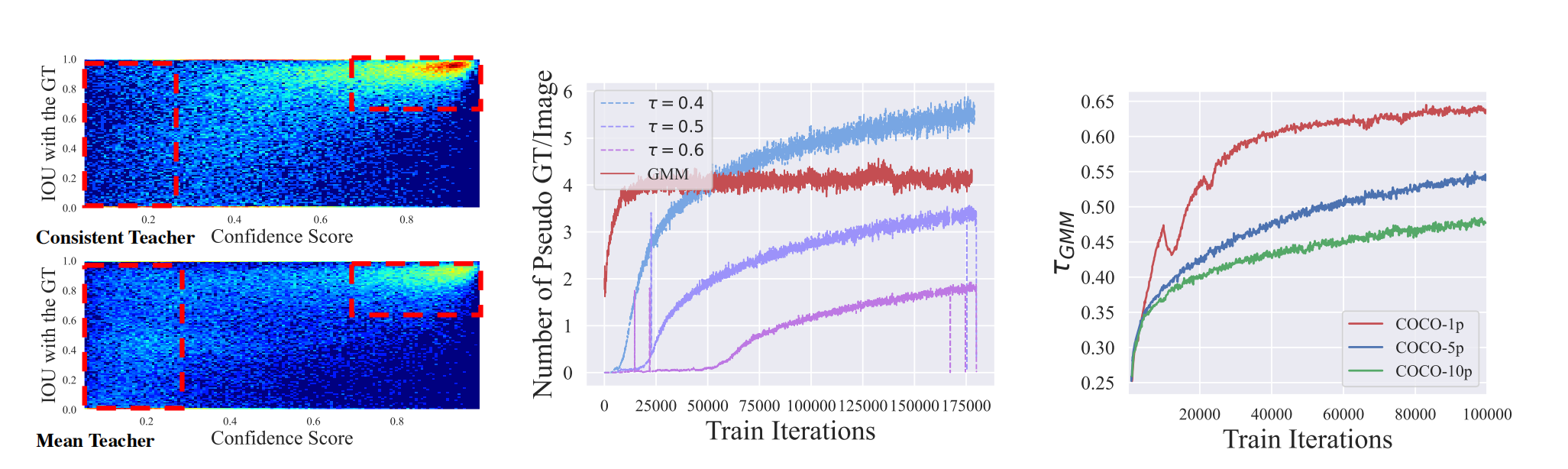
左图:可视化了COCO val2017数据集上所有预测边界框的置信度-交并比(IoU)热力图。如红色方框所示,Mean-Teacher模型会预测出低置信度但高交并比的边界框,而本文模型生成的预测结果则集中在高置信度、高交并比的区域,能生成校准度更高的预测结果。
中图:展示了在未标记数据上,使用不同阈值设定方案时每张图像的伪真实标签数量。采用静态置信阈值时,随着检测器置信度的提升,伪标签数量会持续下降。而基于高斯混合模型(GMM) 的方法则会根据模型容量自适应调整最优阈值,真实标签数量基本保持恒定,从而减少了时间上的不一致性。
右图:高斯混合模型在COCO数据集1%/5%/10%标记数据比例下得到的估计阈值曲线。随着训练的进行,阈值数值稳步上升。在标记样本数量更少的情况下,高斯混合模型会根据更严重的过拟合问题设置更高的置信阈值。
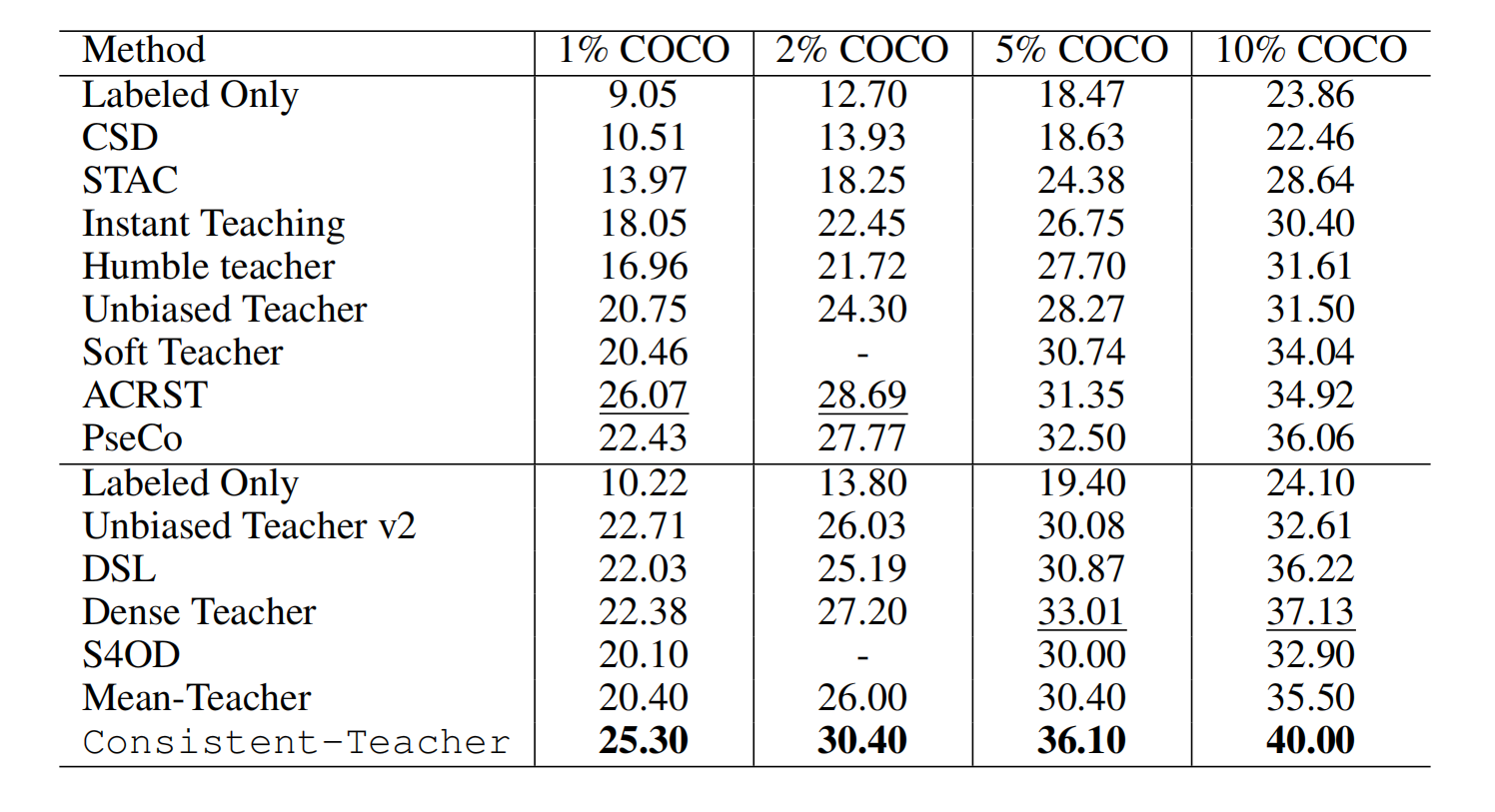
不同半监督目标检测方法在COCO数据集上、不同标注数据占比下的检测精度(mAP)对比。
本文所提出的Consistent-Teacher方法,在1%、2%、5%、10%四种标注率设置下均展现出高性能,尤其在标注数据极度稀缺的低数据场景中优势显著。
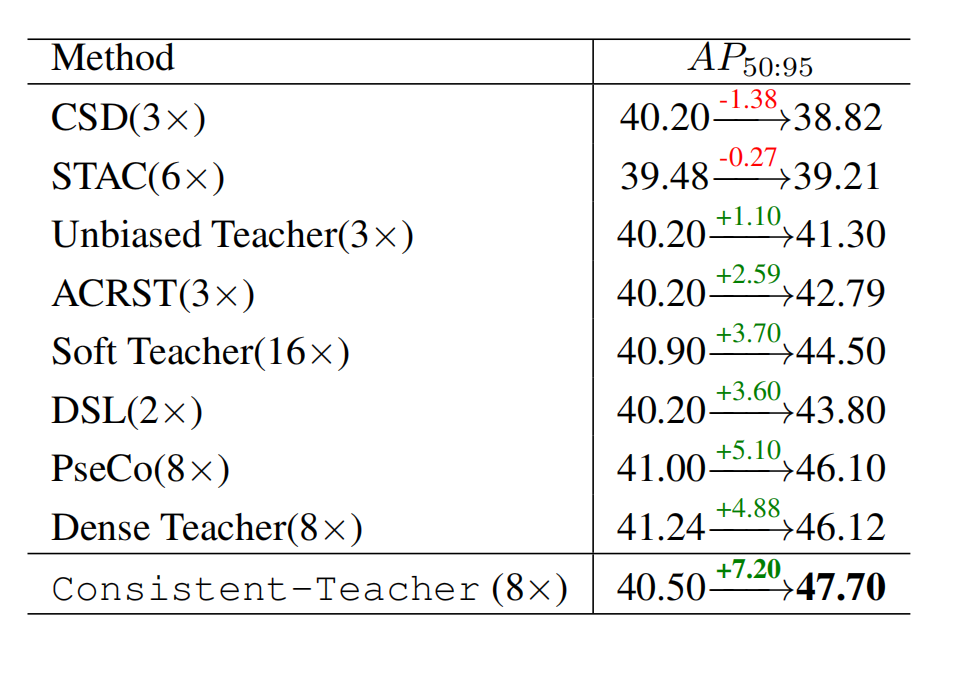
对比各半监督检测方法的AP精度提升:
Consistent-Teacher涨幅最大, A P 50 : 95 AP_{50:95} AP50:95达到47.70,远超所有对比方法,模块有效性与性能优势突出。
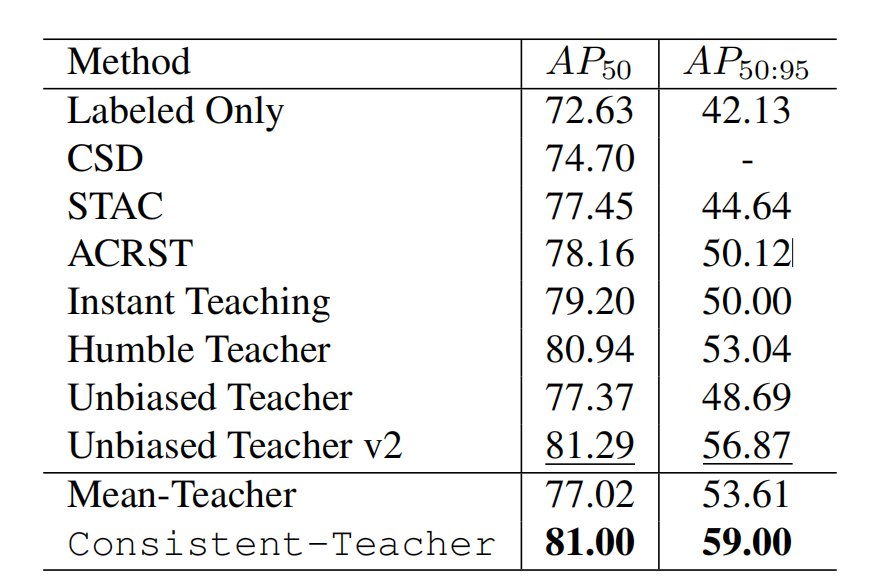 半监督检测方法精度对比:
半监督检测方法精度对比:
本文方法综合指标最优,整体检测能力领先现有所有SOTA算法。
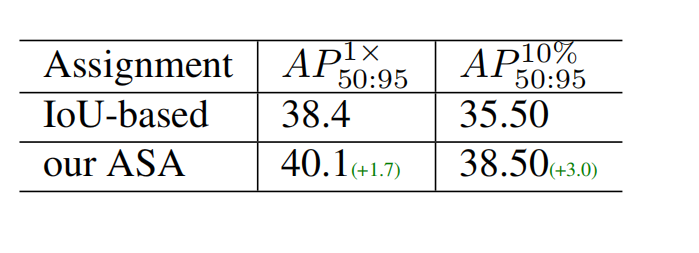
与传统IoU匹配基线相比,本文ASA方法在常规设置下涨+1.7AP,低标注稀缺场景大幅涨+3.0AP,模块增效显著。
消融实验
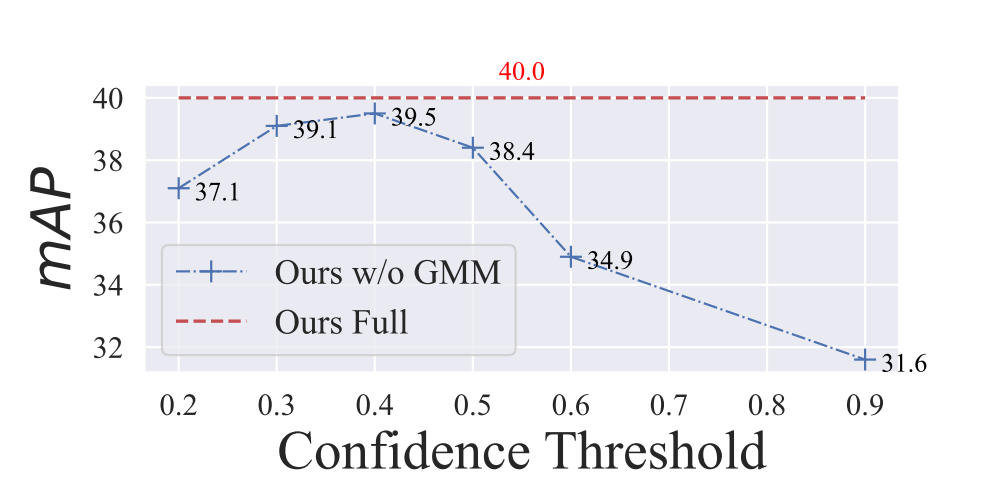
固定阈值与本文GMM消融:
- 无GMM(蓝色曲线):性能随置信阈值变动剧烈,鲁棒性差。
- 完整模型(红色虚线,含GMM动态阈值):全程不受阈值取值影响。
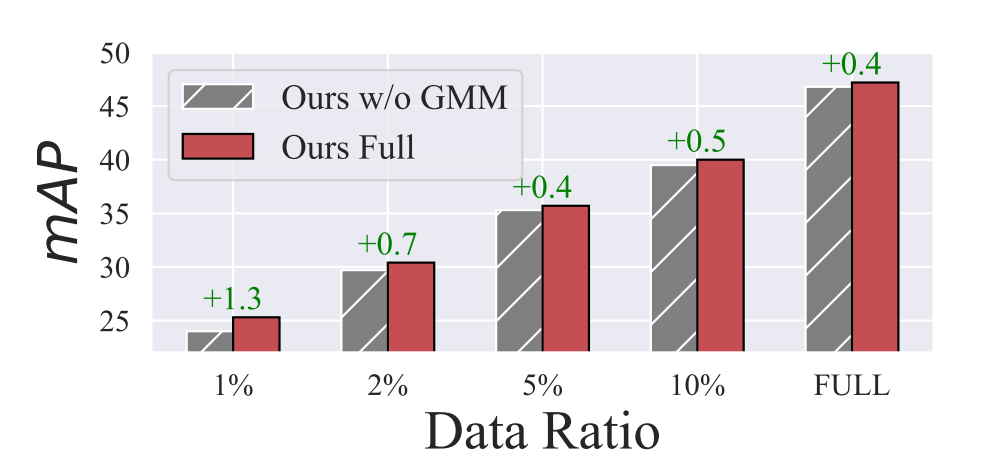
横轴为标注数据占比,灰色为移除GMM,红色为完整模型(含GMM)。
- 标注数据越少,GMM增益越显著
- 标注量充足时仍有稳定正向提升。
证明GMM动态阈值机制,在低标注、数据稀缺的半监督场景下增效能力最强,提升模型泛化与检测精度。
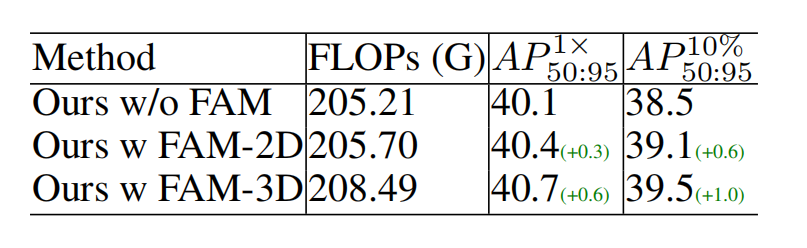 3D 特征对齐的 FAM 模块,能以极低算力成本,高效显著提升检测性能,效率与精度兼顾。
3D 特征对齐的 FAM 模块,能以极低算力成本,高效显著提升检测性能,效率与精度兼顾。
结论
本文对半监督目标检测(SSOD)中出现的不一致性问题进行了系统研究,并提出了一种简单有效的半监督目标检测器——Consistent-Teacher 作为解决方案。该方法采用自适应样本分配策略,选取匹配代价最低的正锚点;同时引入特征对齐模块(FAM),通过回归三维特征金字塔偏移量来对齐分类与回归任务。为解决伪框中的阈值不一致问题,研究采用高斯混合模型(GMM) 动态调整自训练的阈值。通过整合这三个模块,所提出的 Consistent-Teacher 在各类 SSOD 基准测试上实现了相较于当前最优方法的显著性能提升,验证了其鲁棒的锚点分配能力与一致的伪框生成效果。
局限性与未来工作:尽管Consistent-Teacher方法效果显著,但它目前主要基于传统的单阶段检测器开发。该方法在两阶段检测器以及近期基于DETR的检测器[2]上的应用仍有待验证。此外,带有伪标签的半监督学习在自循环过程中,会因不准确的先验信息和人工启发式规则而累积误差。自适应样本分配策略替代了部分人工启发式规则(如基于锚框的分配方式),为半监督目标检测(SSOD)带来了额外增益。可以认为,探索更多端到端的半监督学习方法也可能获得类似优势,这也是未来的研究方向之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)