大模型的核心护城河:面向LLM的清洗、去重、脱敏、溯源全链路数据治理实战
大模型产业已从技术验证期全面迈入规模化商用深水区,行业的核心矛盾早已从“能否做出大模型”,转变为“能否做出安全可控、效果稳定、合规可用的大模型”。但绝大多数企业在大模型落地过程中,都陷入了重算力、重参数、轻数据的认知误区,投入巨额资源优化模型结构、扩大训练规模,却忽略了决定大模型能力上限的底层基建——面向大模型的全链路数据治理。最终导致模型幻觉频发、合规风险高企、训练效率低下,甚至陷入知识产权纠纷,大量大模型项目停留在Demo阶段,无法真正落地到业务场景。
面向大模型的数据治理,绝非传统数仓数据治理的简单迁移,而是一套适配大模型全生命周期的全新体系化工程。传统数据治理以结构化业务数据为核心,目标是保障数据一致性与准确性,支撑业务决策分析,治理边界集中在数仓ETL流程内。而面向大模型的数据治理,覆盖预训练、微调、RAG推理全场景,治理对象涵盖文本、文档、多模态等非结构化数据,核心目标聚焦三个维度:一是从根源上提升模型生成质量,降低幻觉发生概率;二是构建全流程合规屏障,规避数据泄露与知识产权风险;三是实现数据全链路可追溯,保障模型行为可控可解释。
一、大模型落地的核心瓶颈,本质是数据治理的缺失
大模型的能力上限由数据质量决定,而非参数规模。行业实践早已证明,用高质量治理后的1万亿token数据训练的模型,效果远超用未经治理的3万亿token数据训练的同规模模型。当前多数企业大模型落地遇到的核心问题,本质都是数据治理缺失引发的连锁反应。
低质量数据是模型幻觉的核心根源。预训练数据集、RAG知识库中充斥的错误信息、矛盾内容、垃圾文本,会让模型学习到错误的知识与逻辑,最终在推理过程中生成看似合理、实则偏离事实的内容。重复冗余数据则会引发模型过拟合,高度重复的文本与指令会让模型过度学习特定表述,泛化能力大幅下降,同时成倍增加训练算力消耗,造成资源的无效浪费。
敏感数据泄露是商用落地不可触碰的合规红线。训练数据、企业知识库中包含的个人隐私信息、商业秘密、涉密内容,未经脱敏处理直接用于模型训练或推理,会导致模型在生成过程中直接泄露敏感信息,触犯个人信息保护法、数据安全法等相关法律法规,给企业带来巨额处罚与品牌损失。而数据来源不可追溯,则埋下了知识产权与安全审计的双重隐患,开源数据的版权归属不清晰、来源不明,一旦用于商用模型,极易引发侵权纠纷,同时无法追溯有害数据的注入链路,难以完成模型安全合规审计。
二、全链路治理核心实战:清洗、去重、脱敏、溯源四大模块
面向大模型的数据治理,核心是构建覆盖数据全生命周期的四大核心能力模块,四大模块环环相扣,形成从数据接入到应用落地的完整治理闭环,同时适配预训练、微调、RAG三大核心场景的差异化需求。
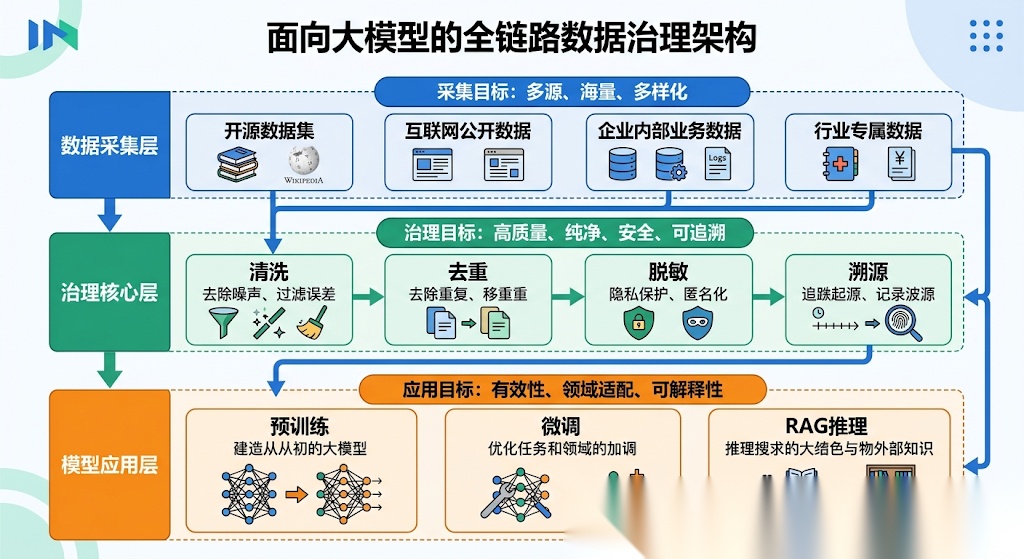
数据清洗:大模型效果保障的第一道防线
数据清洗的核心目标,是过滤噪声数据、低价值数据与错误数据,保留高信息密度、高事实准确性、高语义完整性的有效内容,从源头筑牢模型质量的基础。区别于传统结构化数据清洗,大模型场景的清洗需要兼顾质量与数据多样性,同时适配不同场景的差异化要求。
清洗流程分为三个递进层级,第一层是粗粒度基础过滤,这是所有场景的通用前置步骤,核心是去除文本中的乱码、无效特殊符号、重复换行、无意义灌水内容,同时过滤非目标语言文本、广告内容、垃圾邮件等完全无价值的内容,快速完成数据的初步规整,大幅降低后续处理的数据量。第二层是细粒度质量过滤,这是大模型场景的核心环节,针对预训练数据,采用轻量级语言模型计算文本困惑度,过滤逻辑混乱、语句不通的低质量文本,同时通过信息密度算法,去除无实质内容的口水话与重复表述;针对RAG知识库与微调指令集,增加事实准确性校验环节,通过多源数据交叉验证,过滤包含错误事实、过时信息的内容,从根源上减少幻觉诱因。第三层是结构化适配处理,针对微调指令集,规范指令与回答的格式,保障指令的完整性与合理性;针对RAG场景,完成文档分块、段落规整、无效页眉页脚与注释内容去除,让数据适配检索与推理的要求。
该方案的核心优势是从源头提升数据质量,可将模型幻觉发生率降低40%以上,同时大幅提升训练与推理效率;其局限性在于,过度过滤会导致数据多样性不足,造成模型泛化能力下降,需要在质量与多样性之间找到精准平衡。该模块是所有大模型场景的必备环节,无明确场景限制,是数据治理的基础能力。
数据去重:解决过拟合与算力浪费的核心手段
大模型场景的去重,绝非简单的完全重复内容删除,核心是解决精确重复、近重复、语义重复三个层级的冗余问题,避免模型因重复数据出现过拟合,同时降低无效算力消耗。当前行业内多数方案仅停留在精确去重层面,无法解决语义重复带来的深层问题,这也是很多模型训练后泛化能力不足的核心原因。
去重体系分为三个递进层级,第一层是精确去重,针对完全一致的文本与文档,通过计算文本的MD5、SimHash值生成唯一标识,快速过滤完全重复的内容,该方法计算效率高、资源消耗低,是海量数据集的基础去重手段。第二层是近重复去重,针对内容高度相似、仅存在语序调整、少量词语替换的文本,采用MinHash结合LSH局部敏感哈希算法,实现海量文本的快速相似性检测,过滤相似度超过预设阈值的内容,该方法适配预训练海量数据集的处理需求,在效率与精度之间实现了良好平衡。第三层是语义去重,这是大模型场景的进阶核心能力,针对语义完全一致但表述完全不同的内容,比如同一个问题的不同问法、同一个知识点的不同表述,通过文本嵌入模型将文本转化为高维向量,计算向量间的余弦相似度,过滤语义高度重叠的内容,该方法尤其适配微调指令集与RAG知识库的去重,可有效避免指令重复导致的模型过拟合,同时解决RAG检索结果重复冗余的问题。
不同场景需匹配差异化的去重策略,预训练数据以精确去重+近重复去重为主,最大限度保留语义多样性;微调指令集以语义去重为核心,保障指令的多样性与覆盖度;RAG知识库以文档级精确去重+片段级近重复去重为主,避免检索结果重复。该方案的核心优势是可降低30%以上的训练算力消耗,同时大幅提升模型的泛化能力;其局限性在于语义去重的计算成本较高,阈值设置不当会导致有效数据被误删。该模块适配预训练全量数据治理、微调指令集优化、RAG知识库规整全场景,尤其适配数据规模大、重复率高的开源数据集治理。
数据脱敏:大模型商用落地的合规红线屏障
数据脱敏是企业大模型商用落地的必备环节,核心目标是识别并处理非结构化文本中的敏感信息,在保障文本语义完整性的前提下,彻底规避敏感数据泄露风险,确保模型落地符合法律法规要求。区别于传统结构化数据脱敏,大模型场景的脱敏需要处理海量非结构化文本中的碎片化、口语化敏感信息,对识别精度与处理能力提出了更高要求。
脱敏体系分为三个核心环节,第一环节是全维度敏感信息识别,采用优化后的命名实体识别模型,结合正则表达式规则,精准定位非结构化文本中的敏感实体,覆盖个人敏感信息、企业商业秘密、涉密内容三大类别,同时针对大模型场景优化了口语化、碎片化文本的识别能力,最大限度降低漏检概率。第二环节是分级脱敏处理,根据内容的敏感级别采用差异化策略,高敏感信息采用全量替换法,将身份证号、银行卡号、完整住址等内容替换为对应的脱敏标识,彻底删除敏感信息;中低敏感信息采用掩码法,保留部分可识别内容,比如将姓名替换为张*、手机号替换为138****1234,兼顾脱敏效果与文本语义完整性;针对涉密内容、违法违规信息,直接执行全量过滤删除。第三环节是脱敏效果校验,通过自动化检测+人工抽检的方式,验证脱敏后的文本无敏感信息残留,同时通过大模型推理测试,确保脱敏后的内容不会触发模型生成敏感信息,同时不影响文本的语义连贯性。
该方案的核心优势是彻底规避敏感数据泄露风险,保障大模型落地符合数据安全相关法律法规要求;其局限性在于,过度脱敏会破坏文本的语义完整性,影响模型训练与推理效果,同时敏感信息识别的准确率直接决定脱敏效果,对技术能力有较高要求。该模块是所有包含敏感信息的企业内部数据、行业数据治理的必备环节,尤其适配金融、政务、医疗等强监管行业的大模型落地。
数据溯源:大模型可控可解释的核心支撑
数据溯源是当前行业内最容易被忽略的治理环节,却是大模型合规商用、安全可控的核心支撑。其核心目标是记录每一条数据的来源、版权归属、处理过程、使用范围,实现数据从采集、治理、训练到推理的全链路可追溯,彻底解决知识产权纠纷、有害数据定位、模型安全审计三大核心问题。
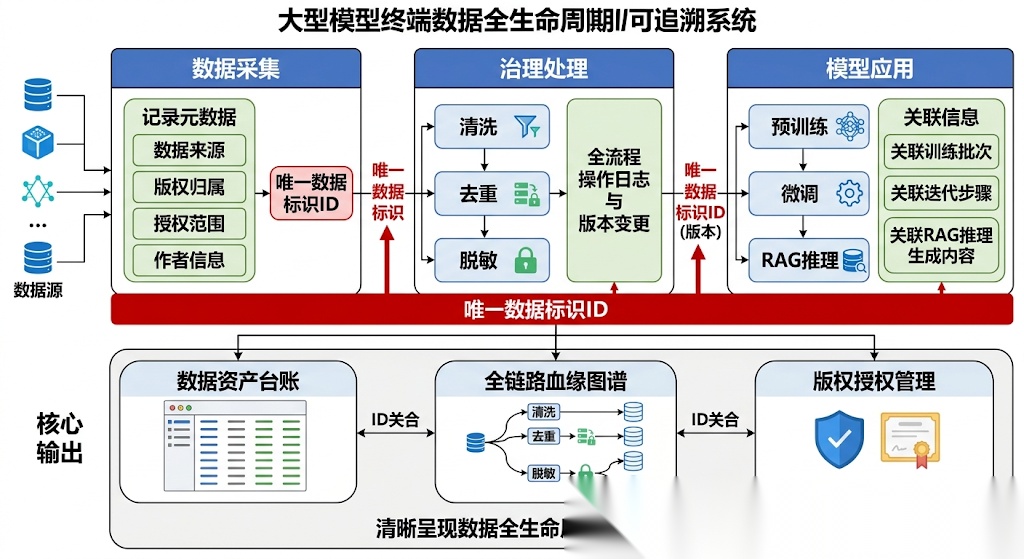
溯源体系的构建分为四个核心步骤,第一步是全量元数据采集,为每一条数据、每一个文档生成全局唯一的标识ID,同步记录数据来源、版权归属、作者信息、采集时间、开源协议、商用授权范围等核心元数据,建立企业级数据资产台账。第二步是处理过程全链路追踪,记录数据在清洗、去重、脱敏、分块等所有治理环节的操作日志,包括处理时间、处理规则、内容变更、处理前后的版本信息,实现数据变更的全流程可追溯。第三步是模型应用链路关联,将数据标识与模型训练的批次、迭代步骤深度关联,实现模型能力的数据源可追溯;在RAG场景中,将检索到的文档片段与模型生成的回答一一对应,实现生成内容的来源可查,既可以定位幻觉内容的来源,也可以解决生成内容的版权归属问题。第四步是版权与授权全生命周期管理,针对每一条数据建立授权台账,明确商用范围、使用限制、有效期,自动拦截超出授权范围的数据使用行为,从根源上规避知识产权侵权风险。
该方案的核心优势是彻底解决大模型数据版权问题,实现有害数据快速定位与模型安全合规审计,大幅提升模型的可控性与可解释性;其局限性在于全链路溯源会增加治理的存储与计算成本,需要配套的元数据管理平台,对企业的工程化能力有一定要求。该模块适配商用大模型预训练数据管理、企业级RAG知识库建设、强监管行业的大模型安全审计,尤其适配需要对外提供商用服务的大模型产品。
三、差异化场景选型与落地避坑指南
面向大模型的数据治理不存在一刀切的通用方案,企业需要结合自身的应用场景、数据规模、技术能力,匹配差异化的治理策略,同时规避行业内高频出现的落地坑点,确保治理体系真正服务于模型效果提升与合规落地。

从场景适配来看,预训练场景的数据规模极大,治理核心是大规模基础清洗、全局去重、基础合规过滤,优先级是保障数据整体质量与多样性平衡,降低训练成本,提升模型基础能力;微调场景的数据规模小但精度要求高,治理核心是指令语义清洗、深度去重、全量脱敏、指令溯源,优先级是保障指令的高质量、多样性与合规性,避免模型过拟合;RAG落地场景的治理核心是文档结构化清洗、知识库去重、事实准确性校验、敏感信息全量脱敏、生成内容溯源,优先级是保障检索内容的准确性,规避回答幻觉与合规风险。
企业落地过程中,需要重点规避四大高频坑点。其一为过度治理,为了追求极致的数据质量,过度过滤、过度去重,导致数据多样性严重不足,最终造成模型泛化能力大幅下降,出现严重过拟合;其二为治理与模型应用脱节,只做一次性数据预处理,没有结合模型效果反馈、业务场景需求持续优化治理策略,治理与模型应用变成两张皮,无法实现持续迭代;其三为重技术轻合规,只关注数据质量提升,忽略脱敏与溯源环节,最终引发数据泄露、知识产权侵权等合规风险,给企业带来不可逆的损失;其四为一刀切的治理策略,没有区分不同场景的差异化需求,用同一套规则处理所有数据,导致要么治理不足,要么过度治理,无法实现效果与成本的最优平衡。
四、结语
大模型的竞争,本质上是高质量数据资产的竞争。参数规模、算力投入只是大模型的入场券,而高质量、合规、可控的数据资产,才是企业大模型真正的核心护城河。
面向大模型的数据治理,从来不是可有可无的辅助环节,而是贯穿大模型全生命周期的核心基建,是解决模型幻觉、规避合规风险、实现规模化商用的根本前提。只有构建体系化、全链路、可闭环的数据治理能力,将清洗、去重、脱敏、溯源四大核心能力深度融入大模型的每一个环节,才能真正释放大模型的技术价值,让大模型在安全、可控、合规的前提下,真正赋能业务创新与企业数字化升级。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献143条内容
已为社区贡献143条内容

所有评论(0)