终于把 CNN 算法搞懂了!!
今天给大家分享一个超强的算法模型,卷积神经网络算法
卷积神经网络(Convolutional Neural Network, CNN)是一类专门处理具有网格结构数据(如图像、语音、视频)的深度学习模型,广泛应用于计算机视觉、语音识别等任务。
它的核心思想来源于对生物视觉系统的模拟,通过“局部感受野 + 权重共享”的机制,高效提取数据中的空间或结构特征。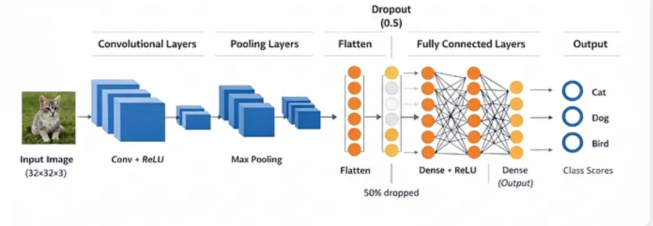
CNN 的三大核心思想
在处理图像等高维数据时,传统的全连接网络(MLP)会面临“参数爆炸”和“丢失空间结构”的问题。CNN 通过模拟人类视觉系统,引入了三个关键机制。
-
局部感受野:卷积层的每个神经元仅与前一层的局部区域连接,捕获局部特征(如边缘、纹理)。这模仿了人类视觉系统的机制。
-
权值共享:同一个卷积核在整张图像上移动时,使用的是同一组参数。这不仅大幅减少了参数量,还保证了平移不变性。
-
空间下采样:通过池化层降低维度,增加模型对位置偏移的鲁棒性。
核心架构组件
1.卷积层
卷积层是 CNN 的灵魂,其目的是从输入数据中提取局部特征(如边缘、纹理、形状等)。
它通过一组可学习的卷积核(Filter/Kernel)在输入数据上滑动,进行点积求和运算,生成特征图。
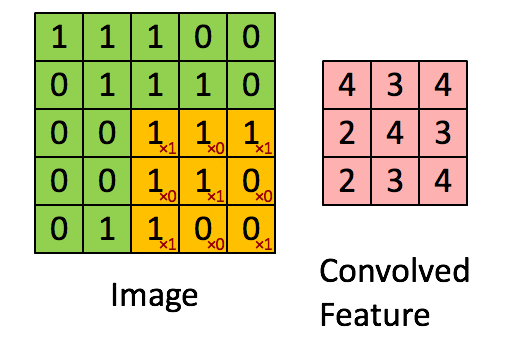
这个过程可以看作是一个特征提取的过程,不同的卷积核能捕捉图像中不同的特征,例如边缘、纹理或几何形状。
关键超参数
-
卷积核:一个小的权重矩阵,常见的有3*3或 5*5,用于提取特征。
-
步长:卷积核滑动的步长。步长越大,输出特征图越小。
-
填充:为了防止边缘信息丢失或强制控制输出尺寸,通常在输入边缘填充 0。
2.激活函数
卷积是线性运算,为了让网络具备拟合复杂函数的能力,必须引入非线性激活函数。
最常用的是 ReLU,数学公式为![]()
它能有效缓解梯度消失问题,并加速模型收敛。
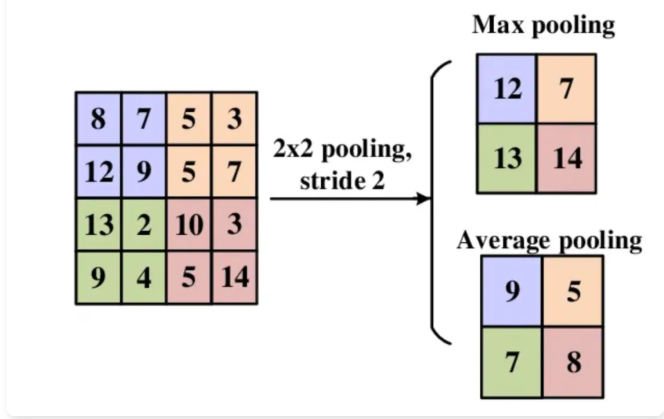
3.池化层
池化用于降低特征图的空间维度,减少计算量,并增强模型对微小位移的鲁棒性。
常见是池化操作有最大池化和平均池化。
-
最大池化 Max Pooling:取区域内的最大值,能有效保留最显著的特征并提供一定的平移鲁棒性。
-
平均池化 Average Pooling:取区域内的平均值,更倾向于保留全局背景信息。
4.全连接层
在经过多轮卷积和池化后,网络提取到了高层语义特征。
我们将高维的特征图 “展平” 为一维向量,送入全连接层进行非线性组合,用于最后的分类或回归任务。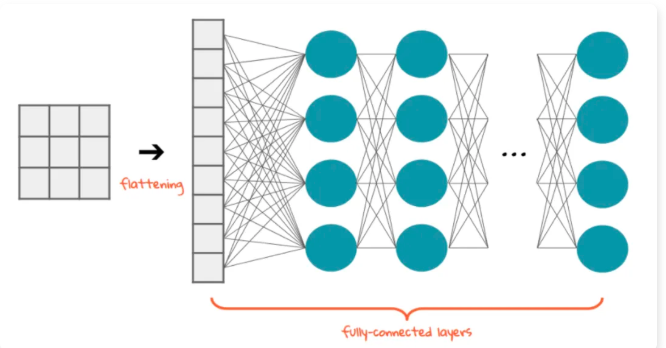
CNN 的执行过程
一个完整的 CNN 通常遵循以下链路
-
输入层:如
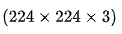 的 RGB 图像。
的 RGB 图像。 -
卷积+激活:提取初级特征(线条、颜色)。
-
池化层:压缩特征图。
-
多层堆叠:随着深度增加,感受野扩大,提取高级语义特征(眼睛、轮子、甚至整个物体)。
-
全连接层 (FC):将二维特征图展平(Flatten),进行非线性组合。
-
输出层:通过 Softmax 进行分类。
训练过程
卷积神经网络的训练过程本质上是一个寻找最优参数(卷积核权重和偏置)的过程,目标是最小化预测输出与真实标签之间的差异。
它包括前向传播、损失计算、反向传播以及参数更新四个核心阶段。
-
前向传播
前向传播是将输入数据 送入网络,逐层进行数学变换,最终得到输出预测值 的过程。
-
损失函数
损失函数(Loss Function)用于衡量预测值 与真实值 之间的差距。
对于分类任务,最常用的是交叉熵损失
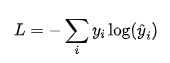
对于回归任务中,常用均方误差
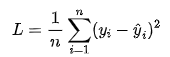
-
反向传播
这是训练最核心的部分。其本质是利用链式法则,计算损失函数 对网络中每一个参数(权值 和偏置 )的梯度。
-
输出层梯度:首先计算损失对输出层神经元的梯度
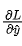 。
。 -
误差反向传递:梯度从后往前传递。对于第 层的权重 ,其梯度计算为:
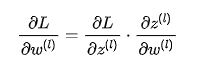
-
-
权重更新
一旦计算出了梯度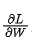 ,我们就可以利用优化算法(如 SGD、Adam 等)来更新权重,从而降低损失。
,我们就可以利用优化算法(如 SGD、Adam 等)来更新权重,从而降低损失。最基础的方法是随机梯度下降 (SGD)
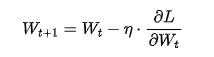
其中 是学习率,它决定了更新的步长。
案例分享
以下是使用 PyTorch 实现卷积神经网络算法(CNN)对 MNIST 手写数字数据集进行分类的完整示例代码。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# 1. 加载真实数据集 (MNIST)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 2. 定义 CNN 架构
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 卷积层 1: 输入通道 1, 输出 16, 核大小 3
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
# 卷积层 2: 输入 16, 输出 32, 核大小 3
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
# 全连接层
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x))) # 输出: 16x14x14
x = self.pool(self.relu(self.conv2(x))) # 输出: 32x7x7
x = x.view(-1, 32 * 7 * 7) # Flatten
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
# 3. 设置训练配置
model = SimpleCNN()
criterion = nn.CrossEntropyLoss() # 损失计算: 交叉熵
optimizer = optim.Adam(model.parameters(), lr=0.001) # 参数更新: Adam
# 4. 训练过程
epochs = 5
loss_history = []
acc_history = []
print("开始训练...")
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for i, (inputs, labels) in enumerate(train_loader):
# --- 阶段 1: 前向传播 ---
outputs = model(inputs)
# --- 阶段 2: 损失计算 ---
loss = criterion(outputs, labels)
# --- 阶段 3: 反向传播 ---
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
# --- 阶段 4: 参数更新 ---
optimizer.step() # 更新权重
# 统计数据
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / len(train_loader)
epoch_acc = 100 * correct / total
loss_history.append(epoch_loss)
acc_history.append(epoch_acc)
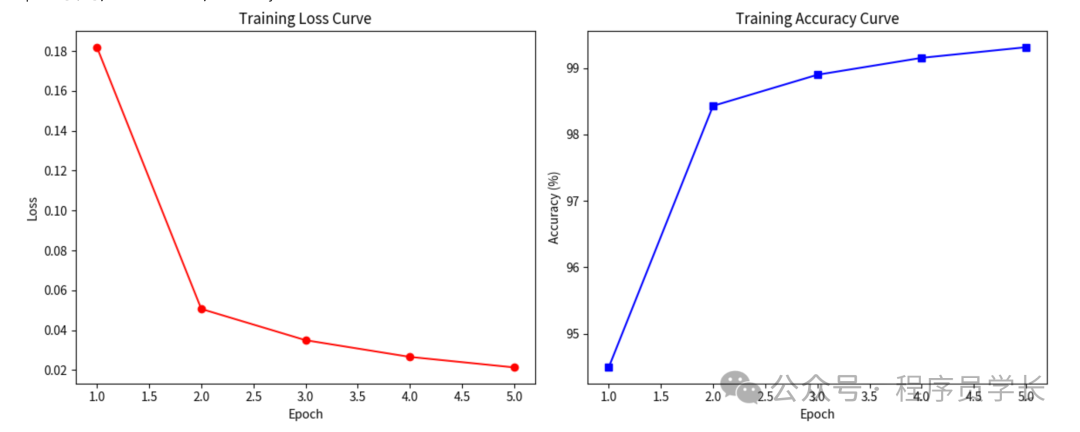
print(f"Epoch [{epoch+1}/{epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.2f}%")
# 5. 绘制函数图像
plt.figure(figsize=(12, 5))
# 绘制 Loss 曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs+1), loss_history, marker='o', color='red')
plt.title('Training Loss Curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
# 绘制 Accuracy 曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs+1), acc_history, marker='s', color='blue')
plt.title('Training Accuracy Curve')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.tight_layout()
plt.show()
# 6. 测试阶段:评估模型泛化能力
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
model.eval() # 切换到评估模式(关闭 Dropout 和 BatchNorm 的训练特性)
test_correct = 0
test_total = 0
# 记录一些样本用于展示
samples, sampled_labels, sampled_preds = [], [], []
with torch.no_grad(): # 核心:测试阶段不需要计算梯度,节省内存和计算资源
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
# 收集前 6 个样本用于可视化
if len(samples) < 6:
samples.extend(images[:6-len(samples)])
sampled_labels.extend(labels[:6-len(labels)])
sampled_preds.extend(predicted[:6-len(predicted)])
print(f"\nFinal Test Accuracy: {100 * test_correct / test_total:.2f}%")
# 7. 可视化测试结果
plt.figure(figsize=(10, 4))
for i in range(6):
plt.subplot(2, 3, i+1)
# 反标准化以便观察图像
img = samples[i].squeeze().numpy() * 0.3081 + 0.1307
plt.imshow(img, cmap='gray')
color = 'green'if sampled_preds[i] == sampled_labels[i] else'red'
plt.title(f"Pred: {sampled_preds[i]} (True: {sampled_labels[i]})", color=color)
plt.axis('off')
plt.suptitle("Test Samples and Predictions", fontsize=16)
plt.tight_layout()
plt.show()

CSDN粉丝独家福利
这份完整版的 AI系统资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)